
基于NIRS的茶籽调和油脂肪酸品质快速检测方法研究
2018-09-10 01:53:18张菊华朱向荣尚雪波卞建明阳秀莲
食品研究与开发 2018年18期
张菊华,朱向荣,尚雪波,卞建明,阳秀莲
(1.湖南省农业科学院,湖南省食品测试分析中心,湖南长沙410125;2.湖南大学研究生院隆平分院,湖南长沙410125)
纯植物油如茶籽油、菜籽油等脂肪酸含量如饱和脂肪酸(saturated fatty acid,SFA)、单不饱和脂肪酸(monounsaturated fatty acid,MUFA)、多不饱和脂肪酸(polyunsaturated fatty acid,PUFA)有固定的区间值,难以改变;而植物调和油可以调节不同的原料油比例,有效地改善普通植物油营养成分单一的缺点,达到营养均衡的目的[1]。因此,脂肪酸是否均衡是衡量植物调和油是否营养合理的指标,调和油的升级换代都是以脂肪酸均衡的程度为基础[2]。目前调和油消费占到了食用油市场的三分之一,其市场份额还在上升,已占到农村市场的90%以上。茶籽调和油,是指包含茶油的2种及2种以上的食用植物油配制而成的食用油脂。据调查,市场上茶籽调和油的包装上只是标注了调和用油品种,如菜籽油、玉米油、大豆油等,绝大多数茶籽调和油并没有标明各油脂所占比例,生产企业可随意调制,这样存在的问题是没有从脂肪酸平衡这一根本的营养目标来生产调和油。我国建议膳食油脂所含SFA∶MUFA∶PUFA的比例以(≤0.4)∶1.2∶1为宜[3],国内研究者开展了一系列基于脂肪酸平衡的营养调和油的调制[4-6]。因此快速测定三种脂肪酸含量对于评价茶籽调和油营养有重要意义。
茶籽调和油脂肪酸含量的测定方法主要是采用气相色谱法[7-9]或气质联用法[10-11],色谱法定量成本高,耗时且对样品具有破坏性,同时对实验人员技术要求较高[12],限制了对大批量样本的快速测定。因此建立茶籽调和油的脂肪酸含量快速检测方法对于快速评价茶籽调和油品质具有重要作用。近红外光谱法(near infrared spectroscopy,NIRS)具有分析速度快、产出多,不破坏样品、不用试剂、不污染环境等特点[13],在分析测定中具有明显的优势。王铎开展NIRS技术应用于大豆及植物油单脂肪酸含量测定[14]。本研究拟采用NIRS技术结合化学计量学方法测定茶籽调和油脂肪酸含量,从而达到茶籽调和油质量安全科学监管的目的。
1 材料与方法
1.1 仪器与试剂
GC 2010气相色谱仪:日本Shimadzu公司;Nicolet AntarisⅡ傅里叶变换近红外光谱仪:美国Thermo公司;数据处理软件:Matlab7.8软件:Mathwork Inc。
37种脂肪酸甲酯混标:SIGMA-ALDRICH公司;甲醇(色谱纯):TEDIA公司;异辛烷(色谱纯):KERMEL公司;KOH(分析纯):汕头市西陇化工有限公司;NaHSO4(分析纯):上海市振兴化工有限公司。
1.2 方法
1.2.1 样本选取
本试验样本选取从自配的不同调配比例的二元体系调和油中选择样本28个(茶油×大豆油6个、茶籽油×棉籽油6个、茶籽油×菜籽油6个、茶籽油×玉米油5个、茶籽油×棕榈油5个),三元体系调和油样本56个(茶籽油×菜籽油×大豆油14个、茶籽油×菜籽油×棕榈油14个、茶籽油×菜籽油×棉籽油14个、茶籽油×菜籽油×玉米油14个),多元体系调和油4个,市场购买的茶籽调和油样本13个,茶籽调和油样本总数共计101个。
1.2.2 气相色谱方法
气相色谱法(Gas Chromatography,GC)前处理方法[7]。称取油样0.06 g于10 mL具塞试管中,用移液枪移取4 mL异辛烷溶解,再加入2 mol/L的氢氧化钾甲醇溶液200 μL,盖上玻璃塞旋涡混合30 s后静置至澄清。再向溶液中加入1 g硫酸氢钠,旋涡混合中和氢氧化钾。待盐沉淀后,将上层甲酯溶液倒入进样瓶中上GC分析。
GC色谱条件为色谱柱:HP-88(100 m×0.25 mm×0.25 μm);进样口:260 ℃;柱流速:氮气 1.1 mL/min;程序升温140℃(5 min)4℃/min 240℃(20 min);检测器FID:250℃;氢气 40.0 mL/min;空气 400 mL/min;尾吹30.0 mL/min;分流比 10 ∶1。
1.2.3 近红外光谱方法
以美国Thermo公司的Nicolet AntarisⅡ傅里叶变换近红外光谱仪作为采样设备,其配有FOSS公司金反射板的样品杯,在样品杯中倒入2 mL的油样,然后用金反射板小心盖压在样品杯中,以消除气泡对光程的影响;近红外光谱仪采用透反射检测系统对各个茶籽调和油样本进行光谱采集,条件参数为如下:NIR光谱扫描波数10 000 cm-1~4 000 cm-1,扫描次数为64次,分辨率设为8 cm-1,以内置背景为参照。每个茶籽调和油样本进行4次平行试验,取其平均光谱作为该样品的标准光谱。
1.2.4 数据处理软件
应用Matlab 7.1定量分析软件中的偏最小二乘法(partial least-squares,PLS)进行建模。
2 结果与讨论
2.1 茶籽调和油样本近红外光谱采集
图1为茶籽调和油代表性样本的近红外光谱图,记录了10 000 cm-1~4 000 cm-1波数下样本的NIR光谱。油脂中不同脂肪酸所属的近红外光谱波数,饱和脂肪酸位于 5 682 cm-1;C18:1,C18:2 和 C18:3在5 797、5 824、5 868 cm-1处有最大吸收[12]。
2.2 茶籽调和油脂肪酸含量测定
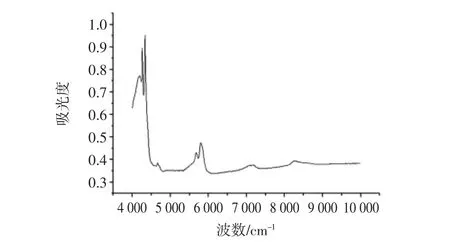
图1 茶籽调和油样本的近红外光谱图Fig.1 The representative NIR spectrum of camellia blend oil sample
本试验共收集101个茶籽调和油样本,首先按照GB5009.168-2016《食品安全国家标准食品中脂肪酸的测定》测定了样品中 SFA(C16:0+C18:0)、MUFA(C18:1),PUFA(C18:2+C18:3)的相对百分含量。37种脂肪酸甲酯标样各组分色谱图如图2。

图2 37种脂肪酸甲酯标样气相色谱图Fig.2 The GC chromatography of mixed fatty acid methyl ester standards
2.3 MUFA(C18:1)近红外模型的建立与结果分析
2.3.1 光谱预处理优化
采用不处理(None)、均值中心化[15](mean centering,MC)、多元散射校正[16](multiple scatter correction,MSC)、标准正态变量变换[17](standard normal variate,SNV)、最大最小归一化[18](min-maxnormalization,MMN)、一阶导数法(first derivative,FD)、二阶导数法(second derivative,SD)光谱处理方法,以及几种预处理相互结合,共15种光谱预处理手段。以训练集预测标准差(standard error of prediction,SEP) 值和决定系数(Rc2,coefficient of determination)为模型评价指标,处理结果如表1所示。
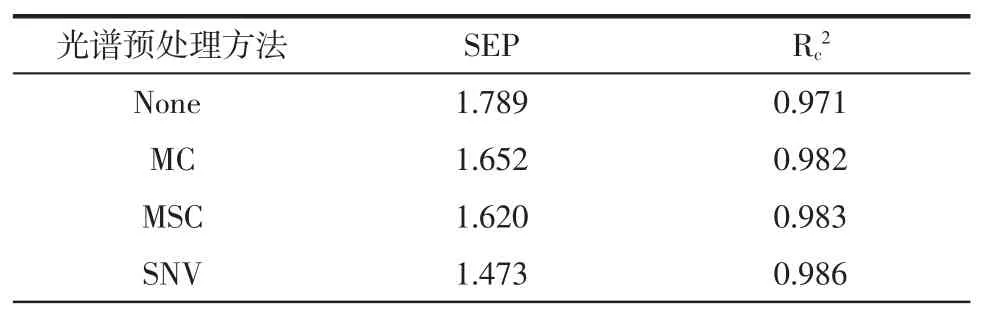
表1 采用不同光谱预处理方法得到的预测误差Table 1 Prediction error obtained by different spectral pretreatment methods
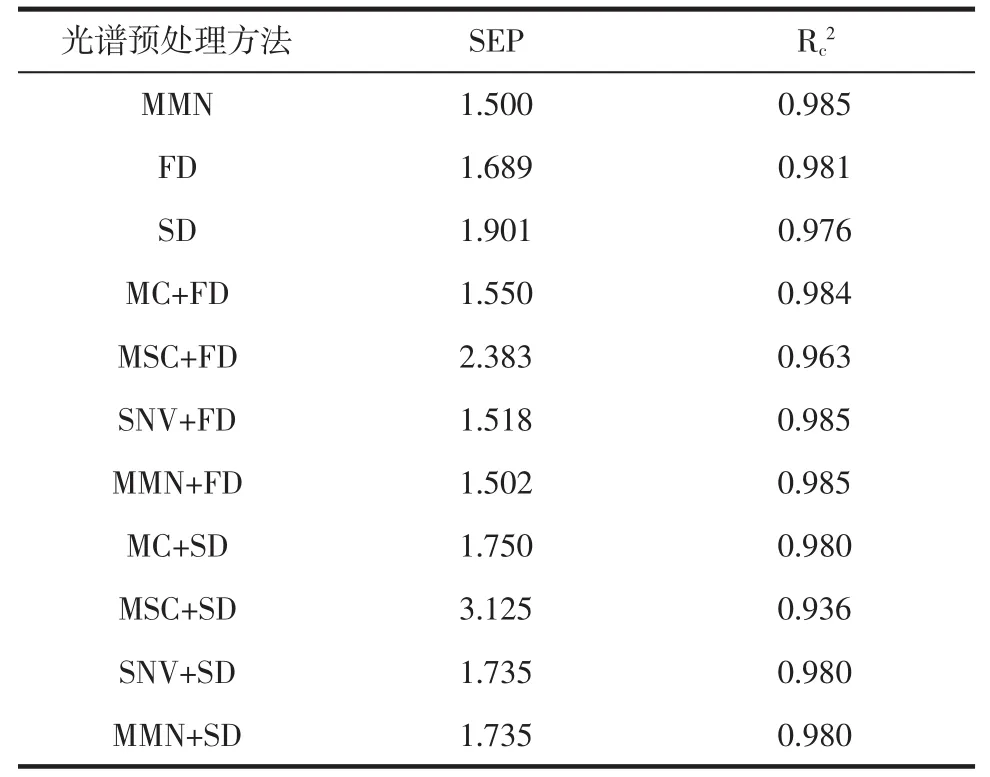
续表1 采用不同光谱预处理方法得到的预测误差Continue table 1 Prediction error obtained by different spectral pretreatment methods
可以看出,导数处理前后,SEP值差异不多,主要是由于油脂内部基质组成复杂,采用导数处理,在消除斜坡背景的同时,噪声的响应值也得到了放大,信噪比下降较多,最终导致了模型结果较差。SNV可以克服近红外光谱变量多、共线性强等缺点,消除表面散射以及光程变化对漫反射光谱的影响[19],最后确定采用SNV进行处理得到最优结果。
图3为采用SNV处理得到预测结果误差图。训练集误差在PLS主因子数为11个时最小,此时,SEP值为 1.473,PRESS 为 162.77。
2.3.2 outlier奇异值剔除

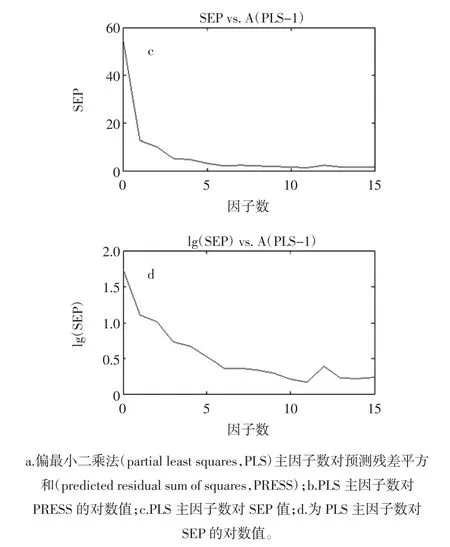
图3 采用SNV处理得到的主因子分析图Fig.3 The main factor analysis by SNV treatment
奇异值的存在会在一定程度上影响甚至改变整体数据的分布趋势,从而影响模型的准确性,所以奇异值的有效剔除是提高校正模型精度的关键[20-21]。通过交叉验证[22],确定了11个主成分为油脂C18:1值PLS模型的最佳主成分。以浓度F值和光谱残差F值作为评价指标,采用Haaland法[23]对C18:1值进行奇异值的剔除,结果如图4所示。

图4 训练集outlier整体F比值图Fig.4 F ratio plot of training set showing outliers
图 4(a)中,36 号样本的 F 值为 4.033,42 号样本的F值为1.032,55号样本的F值为13.018,均超过了设定阈值1。图4(b)中,36、42以及55号样本的光谱残差均超过了设定值10,所以这3个样本是奇异值,予以剔除。
为了验证Haaland法的可靠性,比较异常值剔除前后均方根值(root mean square,RMS)值的变化。未剔除前,训练集的SEP值为1.07,Rc2为0.986,预测集的预测误差均方根差(root mean square error of prediction,RMSEP)值为 2.50,Rp2为 0.972;剔除后,训练集 SEP值为0.773,Rc2为0.996,预测集RMSEP值为0.768,Rp2为0.999。由此可见,经过奇异值剔除处理后,模型的总体误差都得到了降低,校正性能和预测性能均得到了提高,特别是校正模型的误差幅度。这可能是由于奇异样本影响了整个样本集的数据结构,从而导致了整个模型的预测精度降低。
2.3.3 预测结果
采用 Kennard Stone(KS)法[24-25]以及 Haaland 法对C18:1值的进行样本划分和奇异值剔除,使用SNV对光谱进行预处理,建立了C18:1值的PLS模型并进行了预测。图5为模型预测的决定系数图。采用SNV预处理,预测集的RMSEP值与Rp2分别为0.768和0.999,相关性较好,该方法能够较好地逼近试验值。

图5 单不饱和脂肪酸预测集相关图Fig.5 Correlation plot of predicting set for MUFA
2.4 SFA(C16:0+C18:0)近红外模型的建立与结果分析
采用MC处理,利用PLS建模,确定12个主成分。建模及预测如图6所示。


图6 饱和脂肪酸训练集和预测集相关图Fig.6 Correlation plot of training set and predicting set for SFA
此时,交叉验证均方根(root mean square error of cross validation,RMSECV)=0.232,RMSEP 值为 0.274,训练集决定系数Rc2为0.999,预测集决定系数Rp2为0.997。
2.5 PUFA(C18:2+18:3)近红外模型的建立与结果分析
剔除1个异常值,采用kennard-stone法对100个样本进行划分,训练集为75个样本,预测集为25个样本。采用MC处理,利用PLS建模,确定12个主成分。建模及预测如图7所示。

图7 多不饱和脂肪酸训练集和预测集相关图Fig.7 Correlation plot of training set and predicting set for PUFA
此时,RMSECV=0.873,RMSEP 值为 0.963,训练集决定系数Rc2为0.994,预测集决定系数Rp2为0.995。训练集平均相对误差(average relative error,ARE)为2.1%,预测集ARE为2.0%。
3 结论
本文采用近红外光谱技术结合化学计量学方法建立茶籽调和油中SFA、MUFA和PUFA含量预测的PLS模型,预测结果良好。SFA、MUFA和PUFA预测集的 RMSEP 别为 0.274、0.768、0.963,Rp2分别为 0.997、0.999、0.995。研究结果表明,NIRS法可以作为一种简单、快速、准确和无损的检测方法来定量分析油茶籽油中SFA、MUFA和PUFA含量,从而鉴别茶籽调和油脂肪酸是否平衡,达到快速评价茶籽调和油品质的目的。本研究所建立方法在茶籽调和油品质快速检测将具有广泛的应用前景。
猜你喜欢
中国粮油学报(2023年11期)2024-01-13 03:06:30
放学后(2023年11期)2023-08-04 21:35:44
老友(2020年10期)2020-10-26 09:19:37
浙江农业科学(2020年6期)2020-06-23 11:49:08
消费者报道(2019年5期)2019-11-22 10:29:28
四川轻化工大学学报(自然科学版)(2019年5期)2019-11-12 02:19:40
中国粮油学报(2019年7期)2019-08-19 07:48:08
福建农业科技(2018年5期)2018-09-10 12:36:48
消费导刊(2017年12期)2017-09-29 01:04:26
天然产物研究与开发(2016年6期)2016-06-05 10:29:26
