
倾向评分匹配法在横断面资料处理中的应用价值研究*
2018-07-16 10:07贺倩倩张军锋
中国卫生统计 2018年3期
贺倩倩 张军锋
【提 要】 目的 探讨心血管疾病与骨关节炎疾病患病情况之间的相关性,进而评价倾向评分匹配法在横断面资料处理中的应用价值。方法 对山西省阳城县和偏关县农村社区7126名16岁以上常住居民进行心血管疾病与骨关节炎的相关调查,根据心血管患病情况分为2组进行比较;利用Stata14.0对组间协变量进行倾向评分卡钳匹配,计算2组的倾向评分,对匹配前后心血管疾病组与非心血管疾病组发生骨关节炎的危险性进行评估。结果 心血管疾病组与非心血管疾病组各有1123例匹配成功,匹配前2组骨关节炎患病率比较差异有统计学意义(P<0.001);经倾向评分匹配后,年龄、性别、职业、口味、BMI、吸烟情况等协变量达到了均衡,2组骨关节炎患病率比较差异仍有统计学意义(P<0.001)。 结论 心血管疾病与骨关节炎患病之间有一定的相关性,但具体机制仍需进一步的研究证实。倾向评分匹配法能有效降低观察性研究组间的混杂偏倚,在横断面资料数据处理中有广阔的应用前景。
随着人口老龄化问题的日益加重,心血管疾病(CVD)、骨关节疾病(OA)等慢性非传染性疾病的患病率逐年升高,Hochberg 等[1]研究发现,在心血管疾病的合并症中伴有骨关节炎的患者比无骨关节炎的患者更容易患高血压(40% vs 25%)。美国一项关于关节炎流行率、危险因素分析以及与心血管疾病关联性的研究也表明,在一般人群中CVD与OA密切相关[2]。目前关于CVD和OA相关性的研究甚少,且大多来自临床试验,混杂因素较多难以控制,其结论存在一定争议[3]。而观察性研究具有特征客观,对目标人群不采取干预措施,纳入和排除标准相较于随机对照试验来说相对宽泛等优点,使其研究结果外推性更强,更具有说服力。但是在观察性研究中也存在着许多缺陷,例如研究对象无法实现随机化分组,研究中不可避免存在大量偏倚等问题都影响着研究结果的准确性[4]。而倾向评分法(propensity score,PS)以其运用简单方便、不增加匹配难度、研究步骤标准化程度高等优势被广泛地应用于大量的非随机化研究中[5]。本研究应用倾向评分法对山西省农村地区骨关节炎流行病学调查资料进行了分析,以探讨CVD与OA患病情况之间的相关性,进而评价倾向评分法在横断面资料处理中的应用价值。
资料与方法
1.资料来源
数据来源于山西省农村社区人群骨关节疾病流行病学调查资料,调查点位于山西省阳城县和偏关县,对当地农村社区16岁以上常住居民进行有关心血管疾病与骨关节炎的流行病学调查。所有参与者在问卷调查前均要签署知情同意书。根据实际调查情况,共收集到7126份合格资料。
2.诊断标准
膝骨关节炎诊断采用美国风湿病学会(ACR)1986年标准,手和髋骨关节炎采用ACR 1990年和1991年标准。其他部位骨关节炎采用临床症状加X线标准。本研究所指的心血管疾病主要包括高血压病、高脂血症和冠状动脉粥样硬化[6]。
3.PS模型建模过程
倾向评分法由 Rosenbaum 和 Rubin 在 1983年首次提出,是将研究中所有的混杂因素或协变量综合成一个变量,使对照组和处理组达到均衡化,从而减少研究中的偏倚[7]。
(1)倾向评分法的基本原理
倾向评分的定义为:在给定一组变量(xi)条件下,将任意一个研究对象i(i=1,2,…,N)划分到处理组(Zi=1)或者对照组(Zi=0)的条件概率。也就是说倾向评分,即P(x)是所有观察到的协变量的函数,表示处理组(Z=1)和对照组(Z=0)的分布情况。
为了使倾向评分得到正式有效的调整,必须考虑处理组的样本分布情况,因此将第i个研究对象被分配到处理组的概率可以表达为:
e(xi)=P(Zi=1|xi)
假设分组变量Zi与特征变量xi相互独立,则对任意一个观察变量xi:
其中,e(xi)即P,被称为倾向评分[8]。
可以具体解释为P(x)为经模型计算得出的倾向评分理论值,Z为处理变量,即研究中存在的混杂因素,当Z=1时表示样本接受处理。假设处理组研究对象为i,那么P(xi)=P(Z=1|xi);对照组研究对象为j,那么P(xj)=P(Z=1|xj),当P(xi)=P(xj),即处理组与对照组的倾向性评分相同或相近时,可认为两组的混杂因素相同,以此保证研究的均衡性。但是当研究中某些重要的混杂因素未纳入到倾向评分模型中时,倾向评分法的应用可能会受到一定的限制。在实际研究中,协变量的入选不仅仅要根据统计学显著性来判定,更重要的是要根据临床专业知识和经验尽可能全面收集混杂因素。
(2)研究方法
倾向评分法可大致分为四种,分别是匹配法、分层法、协变量调整法和加权法[9]。这四种方法因其各自特点不同,在各种研究中都有着不同程度的应用。其中大多数的医学研究常采用倾向评分匹配法。而匹配法又具体分为最近邻匹配法(nearest-neighbor matching)、卡钳匹配(caliper matching)、分层匹配法(stratification matching)、基于马氏距离的匹配法等方法[9]。本研究主要采用卡钳匹配的方法对两组间个体进行匹配。
(3)卡钳匹配的具体步骤
①以分组变量及心血管的患病情况为因变量,协变量及研究中基于基线信息中可能的混杂因素(年龄、性别、BMI、口味、职业等) 为自变量,通过logistic模型计算每个心血管疾病患者的PS得分;
②以倾向评分为依据,采用卡钳匹配。首先随机排列处理组与对照组成员,选择第一个处理组成员i,如果i与对照组成员j之间的倾向值差的绝对值落入预先设定的卡尺范围ε,且此差值的绝对值是该卡尺范围内i和其他j形成所有配对的倾向值差的绝对值中最小的一个,那么,j就可以作为i的一个匹配。
③检验组间匹配效果,即协变量的均衡性比较,对于定量资料采用t检验,对于定性资料采用χ2检验;
④对匹配后的数据进行统计分析,研究心血管疾病的发生与骨关节炎之间的联系。
4.统计分析
建立Epidata 3.1数据库,录入采用双人双份录入的方式,严格进行质量控制。形成规范的数据集后再利用Stata14.0对组间协变量进行PS卡钳匹配,然后进行相应的统计学分析,即定量资料采用t检验,定性资料采用χ2检验,以P<0.05为差异有统计学意义。
结 果
1.偏关、阳城两地区人群基本情况
此次两地调查的有效人数为7126例,其中男性3609例(占50.6%),女性3517例(占49.4%);平均年龄为43.90±16.56岁(范围为16~90岁)。阳城县调查人数为4378例,偏关县调查人数为2748例。
2.两组匹配前后协变量比较
倾向评分匹配前,心血管疾病患者有1734例,未患该病者有5392例;两组协变量资料中年龄、性别、BMI、吸烟、取暖设备、职业等的比较差异有统计学意义(P<0.05);通过倾向评分法对组间数据进行卡钳匹配后,两组各有1123例,成功匹配率为31.52%;倾向评分匹配后,协变量年龄、性别、BMI、吸烟、取暖设备、职业等在组间分布均达到均衡(P>0.05),结果见表1、表2。
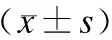
表1 倾向评分匹配前后协变量分布
*:定量变量资料采用t检验
3.心血管疾病与骨关节炎患病情况相关性分析
倾向评分匹配前,心血管疾病组中骨关节炎的患病率高达47.6%;而在未患心血管疾病组中,只有22.3%的居民患骨关节炎;经χ2检验得出心血管疾病与骨关节炎相关性有统计学意义(P<0.001)。经倾向评分处理后,心血管疾病组骨关节炎的患病率为64.4%,对照组中患病率为54.7%,检验得出心血管疾病与骨关节炎相关性仍有统计学意义(P<0.001),结果见表3。
讨 论
20世纪90年代,倾向评分法日益受到人们的关注。相对于样本量较少、花费上涨的随机化试验,观察性研究应用倾向评分均衡组间协变量的不均衡性不失为一种好的方法[9]。PS特别适用于大样本的观察性的研究,近年来国内医学界应用倾向评分法的研究越来越多,主要应用于非随机干预研究资料、观察性研究中的病例对照研究、队列研究等,但在横断面研究方面鲜有应用。横断面研究是流行病学研究中重要的方法之一,不经过处理的横断面资料直接进行统计分析得出的统计结论错误率较高,主要原因是混杂因素的干扰导致偏倚的存在,但经PS处理后,可以明显降低结论出现错误的概率。若PS模型中包含了所有的混杂因素,那么我们就可以得到平均处理效应的无偏估计, 相当于“事后随机化”[10]。但其局限性也在于能平衡已知的混杂因素,对于某些未知的混杂变量仍然会对研究的最终结果造成一定的影响。
*:定性变量资料采用χ2检验。

表3 心血管疾病与骨关节炎患病关系(n,%)
众所周知,OA是一种高度流行的慢性病,是导致老年人致残的主要疾病。CVD是全球导致死亡的头号杀手[11]。近年来,关于OA与CVD相关性的研究也逐渐增加,但是大多数研究是依据收集到的资料直接进行分析比较,并未考虑到两组协变量之间的均衡性,其是否存在内部联系还存在争议。本文主要通过比较心血管患者与非患者间骨关节炎的患病频率来评价CVD与OA患病之间的关系。原始数据直接分析结果表明CVD与OA相关性有统计学意义,经过倾向评分处理后,均衡掉基线资料的11个不均衡的影响因素,结果显示CVD与OA相关性仍有统计学意义,说明CVD与OA之间存在相关性。
CVD发生导致OA患病风险增加的一种可能的解释是这两种疾病具有共同的危险因素,例如年龄、吸烟和饮酒等因素[12]。本研究中均衡了心血管疾病组与对照组在这些因素间的不平衡性后,仍观察到两种疾病间存在相关性。同时Pfister[13]等人的队列研究对这些因素和其他明确的心力衰竭的危险因素进行校正后,仍能观察到在骨密度和心力衰竭风险之间存在着显著的相关性;因此,传统的危险因素似乎没有促成所观察到的相关性。
对研究结果的另一种解释是共同的潜在的生物学进程可能导致了CVD和OA的伴随发生。在Rahman[14]等人在心血管疾病患者导致骨关节疾病的前瞻性纵向研究中发现,OA的发生与CVD的患病风险增加有关。但是Hoeven[15]等人发现,在年龄大于55岁的4868名受试者中,OA与CVD没有显著性关联,即说明CVD没有使其发生OA的风险增加。对于这些研究之间存在的差异性,可能存在以下一些原因:首先,在这些研究中,参与者的年龄存在着差异性;第二,CVD的判断标准不同导致不同的结果;第三,诊断临床OA的标准不同也可能导致不同的结果;最后,这些研究中都未提及参与者身体素质的水平以及使用药物的情况,这些因素可能是估计OA与CVD之间相关性的重要因素。
综上所述,本研究结果提示心血管疾病与骨关节炎患病之间有一定的相关性,但具体机制仍需进一步的研究证实。就本研究而言,其不足主要表现为无法保证已完全排除所有可能存在的混杂因素,仍需进一步进行多地区大样本调查研究以明确CVD与OA之间的关系。但可以确认的是倾向评分匹配法能有效降低观察性研究组间的混杂偏倚,在横断面资料数据处理中有广阔的应用前景。
猜你喜欢
心血管病防治知识(2022年22期)2022-11-11
心血管病防治知识(2022年24期)2022-11-11
心血管病防治知识(2022年23期)2022-11-10
现代临床医学(2022年3期)2022-06-06
中老年保健(2021年5期)2021-12-02
今日农业(2020年19期)2020-12-14
科学(2020年3期)2020-11-26
医学新知(2019年4期)2020-01-02
中医研究(2014年11期)2014-03-11
中学英语之友·上(2010年8期)2010-09-20
