
面向特定划分的主题模型的设计与实现*
2018-07-13 08:54周凯文杨智慧马会心何震瀛荆一楠王晓阳
计算机与生活 2018年7期
周凯文,杨智慧,马会心,何震瀛,荆一楠,王晓阳
复旦大学 计算机科学技术学院,上海 201203
1 引言
主题模型是文本分析中的重要研究问题之一。在2010年前,不同的主题模型层出不穷,2010年后由于神经网络概念的火爆,文本的研究中心逐渐转移。不过主题模型由于其较好的效果以及较为简易的实现在文本分类等领域依旧具有很强的生命力。不同的主题模型建模的角度各有不同,如关联主题模型(correlated topic model,CTM)[1]就从主题之间可能存在相互关联的角度用一个逻辑高斯分布进行建模,动态主题模型(dynamic topic model)[2]用高斯分布建模主题的演化过程。不过这些模型依旧是从单篇文档的角度进行建模,而未考虑文本主题分布之间的关联性。
同时,对于模型推断方式的研究也层出不穷。以LDA(latent Dirichlet allocation)为例,先后就有变分贝叶斯推断法、Gibbs采样法、收缩Gibbs采样法、EP(expectation propagation[3])法以及收缩变分贝叶斯推断等方法被提出。各种推断方法各有利弊,整体来看,可以分为随机的采样法和确定性的变分推断法两类。变分推断法效率高,但存在偏差;采样法理论上可以收敛到真实的后验分布,但收敛速度慢且难以判断收敛性。因此在考虑推断方法时还要权衡不同方法的利弊和模型的实际情况进行选择。
2016年1月,习近平总书记在重庆推动长江经济带发展座谈会上指出,“长江病了”,而且病得还不轻。“当前和今后相当长一个时期,要把修复长江生态环境摆在压倒性位置,共抓大保护,不搞大开发”。2018年4月视察湖北时,习近平总书记再次强调,“保护好长江中华民族母亲河”“治好‘长江病’,要科学运用中医整体观,追根溯源、诊断病因、找准病根、分类施策、系统治疗”。
将LDA应用于分布式的环境,以处理更加庞大的文本数据规模也是针对主题模型的研究热点之一,2008年提出了分布式模型推断[4],之后各类分布式实现不断涌现,例如PLDA(parallel latent Dirichlet allocation)[5]分别设计并实现了利用MapReduce API以及MPI的分布式LDA,Spark-LDA[6]则将LDA的Gibbs采样算法应用于Spark框架中,这些研究成果丰富了LDA的应用情景。
同时,对主题模型应用的研究也有许多成果,例如2D-LDA将LDA应用于图像矩阵,进行图像的特征提取[7],用LDA分类卫星图像[8],以及在医疗、生物等领域也可以利用主题模型的特征提取能力对大量的数据进行挖掘。因此主题模型的意义已经远远超过了一个贝叶斯模型的范畴,主题也不再局限为文本的主题,而成为一个抽象的概念。
文本数据库中的文本可以由一些结构化的属性划分为一些子集,每个子集之中的文本存在共性,而这些共性是被如LDA这类假设文本间独立的主题模型所忽略的。因此,本文针对文本数据库的特定划分,在主题模型中加入了子集的概念,并依据子集之中的共性对文本进行建模。本文将这个全新的主题模型命名为DbLDA(LDAover text database)。
由于是全新的主题模型,对DbLDA的模型推断也是本文的主要工作之一。模型近似推断的方法有很多,本文将对几种不同的推断方法进行分析,并选取一种比较合适的且较优的方法对本文提出的模型进行近似推断。同时,DbLDA模型基于划分引入了子集的概念,因此模型中也会引入更多的随机变量,这些随机变量在数据挖掘的角度上存在一定的意义,本文也将对此进行分析。本文的实验部分选取了一种语言模型评估方式,对DbLDA相比于LDA的模型效果进行了测试,实验还包含对模型运行速度的测试,同时最后也对一些模型参数以及相关的模型性质进行了详细的讨论。
本文组织结构如下:第1章介绍研究背景,如当今主题模型研究成果、模型推断方式等;第2章介绍相关工作;第3章介绍DbLDA模型,即本文提出的新的主题模型,包括相关随机变量的意义及模型的物理意义;第4章阐述了近似推断算法,包括现有近似推断算法的介绍与比较,对DbLDA的近似推断过程;第5章为实验分析部分,与LDA、CTM对比,对DbLDA的模型效果进行评估,包括对模型参数设置的讨论与分析;第6章对本文工作进行了总结。
2 相关工作
2.1 LDA主题模型
LDA是2003年由Blei等人提出的主题模型,它基于PLSA(probability latent semantic analysis)等先前的模型,结合贝叶斯网络的思想,提出了如图1所示的主题模型[9]。
根据LDA的图模型,文本中词的生成首先从Dirichlet先验中生成主题分布再生成每个词所选的主题编号,接着从同样是由Dirichlet先验生成的K个主题中选出相应的主题生成一个词[9]。需要注意的是主题是一个V维的向量,即主题是一个词汇表上的多项分布,而主题分布是一个K维向量,表示一个主题上的多项分布。
由于加入了贝叶斯先验,LDA的模型相较当时的PLSA更为复杂,对模型的近似推断工作较为复杂。
2.2 LDA近似推断
为了进一步探究子集大小划分带来的影响,重复进行图7中的第二组实验,即数据集为两个月的Reuters数据,子集大小为15天新闻文本或30天新闻文本,目的是减少随机初始化等不稳定因素带来的波动,结果如图8所示。
精武体育会的这种对外传播是持续不断的。例如1923年10月,又有广高精武旅行团乘港轮龙山号出发,转轮前往南洋。他们“先到星架坡,以次及南洋各属。荷属爪哇,法属安南等埠。沿途以滑稽舞、武化舞、剑舞、凤舞、音乐新剧、国操、幻灯活动、精武影片等,贡献于侨胞” [11]。
2.3 CTM主题模型
CTM主题模型[1]是Lafferty等人在2005年提出的主题模型,它将LDA主题模型中的先验分布替换为逻辑高斯分布,用以建模主题之间的关联,其生成过程如图2所示。
19世纪末工业文明兴起,机械设备的高速批量生产替代传统缓慢手工制作,让木地板得以普及.德式历史建筑室内木地板的使用非常普遍.在较高等级的居住建筑室内使用相对高档的镶花木地板与边框(Parquetry Floors and Borders),用多种颜色的木材拼成图案,使用木条镶花地板或者镶嵌细木条可以取得与石材拼花类似的效果.在一般等级的建筑室内中,木地板的铺装较多采用简单形式,直线型、人字型最为普遍,沿袭同时期同类型德国本土建筑室内地板的铺装方式(图6).
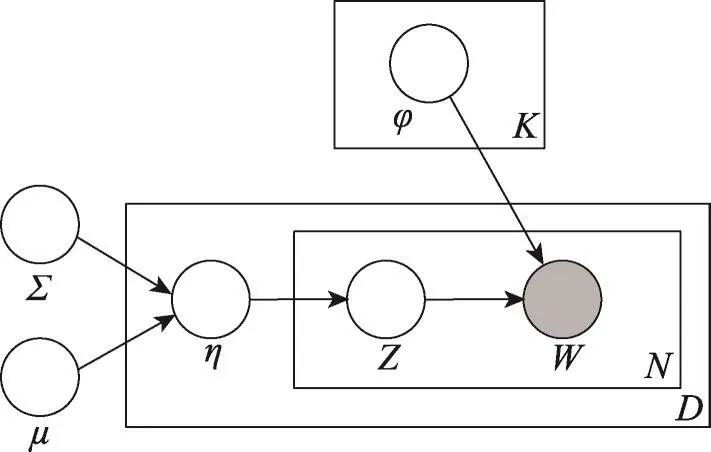
Fig.2 CTM graphic model图2 CTM图模型
相比LDA主题模型的生成过程,CTM将先验分布改为逻辑高斯分布,因此建模时多出了一个参数,图2所示的图模型为原始论文中的图模型(省略了对主题矩阵的平滑化处理)。在本文提出的DbLDA主题模型中,同CTM一样利用了逻辑高斯分布进行建模,但是建模的角度有所不同,下一节将展开分析。
3 DbLDA模型介绍
本章基于LDA的模型提出了全新的DbLDA模型,DbLDA融入了子集的概念。3.1节详细介绍DbLDA模型,3.2节深入分析该模型及其物理意义。
3.1 生成过程及图模型
首先,回顾一下LDA中的文本生成过程:通过从Dirichlet分布生成一个分布作为文章的主题分布,从主题分布中生成这篇文章的主题,然后从相应的主题中生成一个单词,从而获得文档中的单词[9],因此每篇文章的主题分布是独立的。
基于LDA的模型,本文根据某种给定的划分方式,加入子集的概念,例如对于一些文本数据库,像新闻数据库,某个时间片段中的文本的主题分布具有一定的相似性,特别是那些报告相同事件的不同新闻频道的文本,利用时间片段的属性就可以对数据库进行划分,分成一个个的子集。因此,介绍一个新的文本数据库上的主题模型DbLDA。
表1列出了本文提出的DbLDA所用到的所有标识。在DbLDA中,每个文档都来源于以下生成过程:
(1)生成主题矩阵φk~Dir(β)。
(2)对一个子集生成主题分布θs~L(Dir(α))。
(3)对子集中的文章,生成主题分布θs,d′|θs~N(θs,Σs)。
对于变分法而言,由于真实后验不可求,变分法通过下式将问题转化为一个最大化问题。事实(文本)的概率对数等于KL散度加上事实下界(evidence lower bound,ELBO),因此最小化KL散度是通过最大化ELBO做到的。
①选择一个主题zs,d,n~Mult(π(θs,d′))。
②选择一个单词ws,d,n|zs,d,n~Mult(φk)。
谷振诣、刘壮虎认为:“令人担忧的不是学生的批判性思维能力,而是教师的批判性思维能力。”[10]在创新创业教育中引入批判性思维教学模式,势必要建立专职合理的教研体系,通过集体备课、集体培训有针对性的提高相关教师的批判性思维,提升其开展批判性思维教育的能力,从而提升创新创业教育的质量。
其中L是从多项分布参数向量到自然向量的映射:
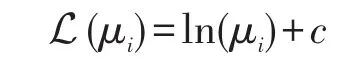
c是一个常数,因此每个多项分布参数向量对应有一个自然参数向量族。π是从自然参数向量映射回多项分布参数向量,

Table 1 Symbols associated with DbLDA表1 和DbLDA相关的标识
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高一使用)(2021年9期)2021-12-02
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
南京大学学报(数学半年刊)(2020年1期)2020-03-19
中国水运(2017年9期)2017-09-15
科技视界(2017年7期)2017-07-26
现代电子技术(2017年11期)2017-06-12
湖南大学学报·自然科学版(2017年4期)2017-05-18
高中生学习·高三版(2016年9期)2016-05-14
