
线程交互不变量的原子性违例错误并发检测*
2018-07-13 08:54李兰英孙建达朱素霞
计算机与生活 2018年7期
李兰英,孙建达,朱素霞
哈尔滨理工大学 计算机科学与技术学院,哈尔滨 150080
1 引言
目前计算机并发体系结构已成为主流,软件中也广泛使用了多线程技术。与传统的单线程顺序执行程序相比,对并发程序中出现的错误的分析检测不但难度高,而且代价大。并发程序有多个线程,多个线程的执行顺序依赖于系统调度,由于这种调度是不确定的,在运行并发程序时,即使输入相同,输出却不能保证相同,正确性难以保障。例如2003年的美加大停电(The 2003 Northeast blackout),仅仅由于电力管理系统中的一个小小的并发错误,导致美国及加拿大东北部停电近3天,造成了300多亿美元的损失[1]。
并发错误常见的有数据竞争、原子性违例、时序违例等[2]。对于并发程序来说,程序的原子性比数据竞争和顺序违例有更强的正确性保证[3],并发程序的原子性特征对于判断其是否正确运行极为重要。若某个线程对于一个共享变量的访问序列具有整体性和不可拆分性,即原子性,则在这个访问序列中不能有其他线程对这个共享变量实施写操作,写操作会破坏这个访问序列的原子性,违背程序原子性而导致出错就属于原子性违例错误。这种错误经常出现在一些著名软件中,例如Apache、MySQL等[4]。Lu等人[5]针对实际应用中的并发错误进行了详细的分析和研究,得出了以下结论[6]:
(1)在所有与数据相关的并发错误中,有大约65%的并发错误是原子性违例错误。
(2)在所有原子性违例的错误中,有大约2/3的原子性违例只涉及到单个共享内存。
(3)并发错误的出现是因为两个线程的交互而引起的。
很多研究人员专门针对原子性违例错误检测进行了研究,例如 AtomRace[7]、AVIO[8]和 MC-AVIO[9]等方案。AtomRace在每个共享变量访问的前后插桩,在运行时根据插桩信息检测原子性违例。该方法无人工干预,漏检率较低,但由于使用静态分析确定原子性区域,导致其扩展性一般,同时由于控制线程调度,其执行开销较大。AVIO通过对正确测试用例的训练提取访问交错不变量,访问交错不变量即线程内未被其他线程的指令交错的指令对。MC-AVIO通过对测试用例的训练,得到程序的原子性迁移对,并利用这些迁移对完成检测[10]。
当前的检测工具多数是在线检测。在线检测通过软件模拟一个CPU,令程序在其上运行,获取相关的程序运行信息,例如Valgrind[11]。在线检测能够动态检测并发错误,但是其时间开销较大,而离线检测方法速度较快,并且易于多线程或多进程技术融合,提高其检测速度。
在相关的离线并发错误检测的研究中,需要获取程序运行的相关信息以及程序的运行踪迹。获取方法主要分为硬件实现和软件实现两类。基于硬件实现的踪迹提取工具有低开销、高性能等优点,但需要修改硬件,增加额外成本。基于软件实现的二进制插桩工具具有信息量大,开销大,对原有系统性能影响大等问题,但因为其使用灵活方便,无需对系统和硬件做出修改,所以受到广大科研人员的欢迎[12]。
针对离线原子性违例错误检测中程序运行踪迹记录大,冗余多,运行速度较慢的问题,本文对两类原子性违例错误提出了一个基于线程交互不变量的原子性违例错误并发检测算法。该算法首先提取程序的运行踪迹,去除重复读、重复写等冗余数据,并使用基于无序映射的散列表将程序运行踪迹按照访存地址快速分块。利用进程池和栈,离线地并发分析多个独立的踪迹块,快速找出线程交互不变量,并判断程序中是否出现了原子性违例错误。
2 线程交互不变量
不变量就是一些逻辑断言,用于描述在程序运行时程序的性质保持不变,它经常出现在形式化描述和断言声明中[13]。每条语句执行时都会伴随着读写存储器的操作,而在多线程程序中,有些变量就会在不同线程中被使用,而原子性违例错误往往就发生在对这些共享变量的访问过程中。因此,本文选取程序运行中对内存访问的依赖关系作为不变量。对内存访问的依赖关系包括写后读(RAW)、写后写(WAW)、读后写(WAR)和读后读(RAR)。这些依赖关系中显然RAW能够标识多线程程序是否正确运行,因为写操作有可能会破坏原子性操作,并且只有在读取修改后的变量时才有可能发生错误。WAW中只有写操作,并没有读取修改后的值,这样的操作不会影响程序的正确性,当WAW后面又有读操作,则能够将WAW拆分为两个RAW。WAR是读取变量值后再修改,不会对程序造成影响,只有读取修改后的数据才可能会出现问题。因此,本文选取对共享变量先写后读的依赖作为线程交互不变量,用来标记线程间及线程内的先写后读的交互顺序[14]。
本文基于线程交互不变量对并发程序原子性违例错误进行检测,采用<W,R>有序对的方式记录该不变量,W代表写操作,R代表读操作。R只有一种情况,LcRd,代表本地读操作。所有写操作的类型都是相对于读操作的,因此W分为两类,LcWr和RmWr。LcWr代表和读操作处于相同线程(本地写操作),而RmWr代表和读操作处于不同线程(远程写操作)。
本文将线程交互不变量分为两类:<LcWr,LcRd>和<RmWr,LcRd>。<LcWr,LcRd>表示本地线程向共享变量写的数据由本地线程读出;<RmWr,LcRd>表示远程线程向共享变量写的数据由本地线程读出。如果写操作和读操作在同一线程,则发生<LcWr,LcRd>,如果写操作和读操作在不同线程,则发生<RmWr,LcRd>。例如图1中,实线表示的是<LcWr(10),LcRd(14)>,虚线表示的是<RmWr(4),LcRd(14)>。
如图1所示的模仿银行存取款的Bank程序,展示了一个可能发生原子性违例错误的例子。该程序运行时可能会出现这种情况:主线程main运行到pthread_create时切换到线程ClearMoney中执行,等到ClearMoney线程结束后,main继续执行。由于nDeposit被ClearMoney线程修改为0,最后输出结果是0,与预期结果999不符,发生错误。注意到代码第10行对变量nMoney进行了写操作,代码第14行对该变量进行了读操作,形成了<LcWr(10),LcRd(14)>,但是在运行过程中,ClearMoney线程改写了变量nMoney,形成了<RmWr(4),LcRd(14)>,这两个线程交互不变量相互交错,发生了原子性违例,致使程序产生了原子性违例错误。虽然其中也包含了WAW依赖,但是由于14行的读操作,将其拆成了相互交错的两个RAW依赖,从而判定错误。本文将这种类型的原子性违例错误称为WWR错误。
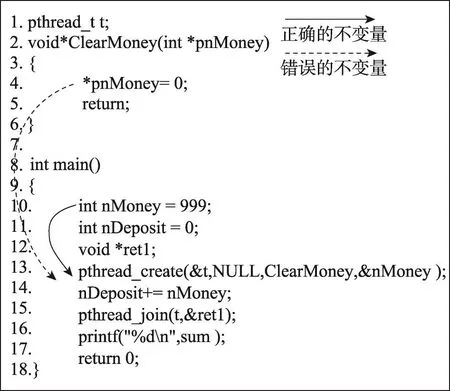
Fig.1 Aprogram named Bank with atomicity bugs图1 带有原子性违例错误的程序Bank
另一种原子性违例错误形式如图2所示。该程序会产生两个线程交互不变量,分别为<RmWr(I1),LcRd(J1)>和<RmWr(I2),LcRd(J2)>。其中由于I2的执行,导致本应在J1执行完执行的J2在I2执行后执行,破坏了线程2的if语句的完整性,发生了原子性违例,致使程序出现错误。本文将这种在一定范围内发生了至少两个<RmWr,LcRd>类型的原子性违例错误称为ReWR错误。
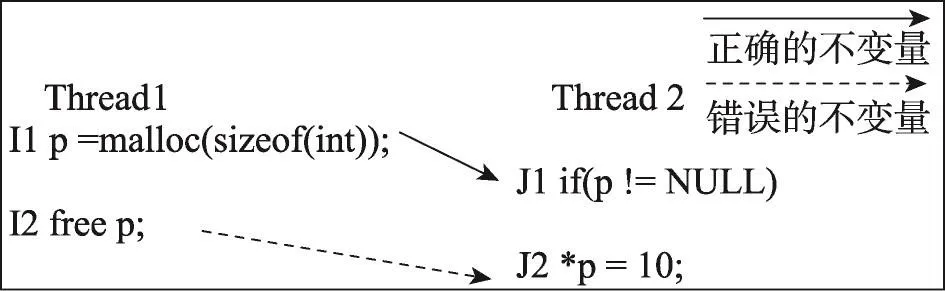
Fig.2 Aprogram segment with atomicity bugs图2 有原子性违例错误的程序片段
但是原子性违例并不一定会导致原子性违例错误的发生,有些时候还是必要的,这种原子性违例称作良性原子性违例。在检测原子性违例错误时要对它们区别对待,否则会出现很多误报。
如图3所示为WWR错误的反例。J1执行完毕,J2正要执行,但是线程1的I1抢先执行完毕,J1和J2形成了<LcWr(J1),LcRd(J2)>,而I1和 J2形成了<RmWr(I1),LcRd(J2)>,虽然满足了WWR错误的条件,但是并没有引发原子性违例错误,而是符合了程序员的预期,可以通过类似这种做法保证线程的执行顺序,其机制类似于自旋锁。

Fig.3 Aprogram segment with benign atomicity violations图3 含有良性原子性违例的程序片段
如图4所示为ReWR错误的反例。I1执行完毕,线程2正常运行,这时I2执行,线程2正常结束。程序运行中会产生两个线程交互不变量,分别是<RmWr(I1),LcRd(J1)>和<RmWr(I2),LcRd(J1)>。这样的结果正是程序员们所期待的,可以通过类似这种做法保证线程的执行顺序。虽然满足了ReWR错误的条件,但程序是正确的。
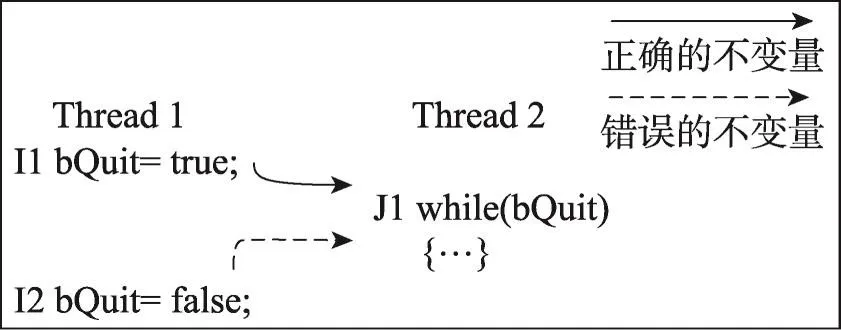
Fig.4 Aprogram with benign atomicity violations图4 带有良性原子违例的实例
对于这两类原子性违例错误,由于其特征较为清晰,故本文未采用机器学习的方式检测这两类原子性违例错误。
3 算法设计
3.1 总体架构
检测流程如图5所示,原子性违例错误检测系统按顺序依次分为踪迹提取、踪迹分析、错误检测3个模块。踪迹提取模块主要是使用Pin工具对测试用例动态插桩,提取出原始踪迹,然后传递给踪迹分析模块,重点是在提取过程中对重复读和重复写踪迹的去除。踪迹分析模块分析踪迹提取模块传来的原始踪迹,并对其进行分类,这其中主要利用了基于无序映射的散列表完成分类操作。错误检测模块将分类后的踪迹加入任务队列,进程池动态地为任务分配和调度进程,每个进程独立运行,在提取线程交互不变量的同时,检测WWR和ReWR两类原子性违例错误。
3.2 踪迹提取
踪迹提取模块使用自己编写的Pin工具对测试用例进行插桩,提取出原始踪迹。Pin是Intel公司提供的一个程序插装工具,它允许在可执行程序的任何地方插入任意代码(用C或C++编写),这些代码在程序运行时动态添加(修改内存映像)[15]。
本文对原子性违例错误进行的检测主要依赖于对程序运行踪迹的分析,因此踪迹中应包含对错误检测有益的信息,其中线程号(TID)是必不可少的,它主要用来标识踪迹所属线程,有利于记录线程间的交互顺序。指令计数器(PC)能够标识指令,用来判断程序运行状况,是循环亦或是顺序执行。时间戳(T)能够记录指令的执行时刻。指令操作(R/W)用来标识该条指令对内存的读写操作。访存地址(ADDR)用来标识该条指令对某个具体的变量进行操作。
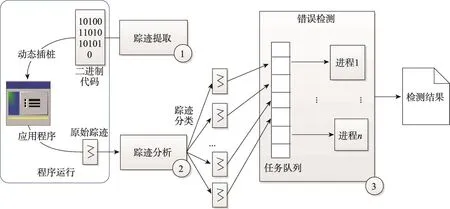
Fig.5 System architecture of atomicity violation detection图5 原子性违例错误检测系统架构
原始踪迹中会包含许多重复读、重复写这样的数据。当程序中包含了重复操作时,有可能会发生对同一变量连续重复读写的情况。
重复读如图6所示,当a<10时,不存在重复读,但是当a≥10时,程序就会继续判断a<50是否满足,如果还不满足,则会继续判断a≥50,由此导致连续重复读取同一变量。这些重复的读取操作对于提取线程交互不变量没有益处,记录全部踪迹与记录一条踪迹的效用是相同的,这样的数据就是冗余数据,即当线程1的I1指令先于线程2的J1指令执行时,只会提取出<RmWr(I1),LcRd(J1)>一条线程交互不变量,记录全部踪迹反而会增大算法的搜索空间,降低错误检测效率。因此,当遇到重复读操作,并且处于同一线程时,算法只记录第一条读指令的踪迹信息。
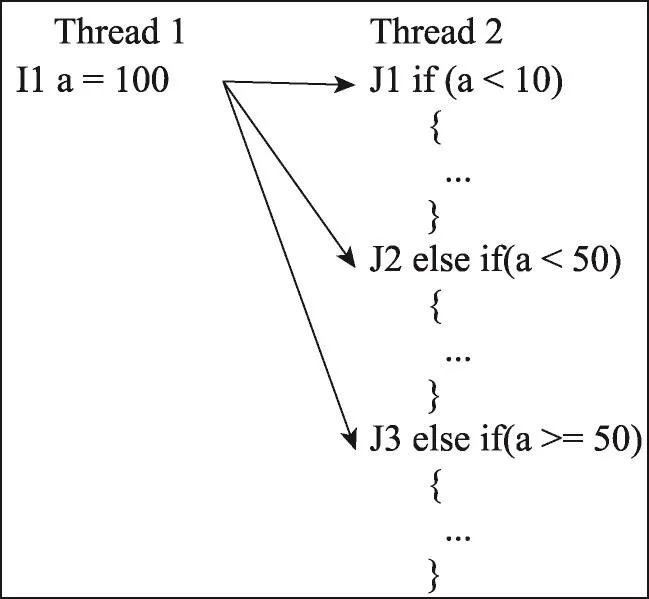
Fig.6 Program with repeated read图6 重复读
重复写如图7所示,图中对指针变量pnCount进行了多次写操作,同理于重复读,连续重复的写操作对于判断程序是否出现了原子性违例错误也没有益处,故当遇到重复写操作,且处于同一线程时,只记录最后一条写指令的踪迹信息。
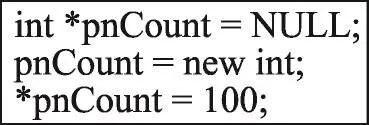
Fig.7 Program with repeated write图7 重复写
去除重复读指令踪迹的算法如下:首先申请一个变量,用于保存上一次读指令的踪迹。第一条读指令踪迹保存到该变量并输出保存。之后每一次新提取的读指令的踪迹都与上一次的比较,如果它们的TID和ADDR一致,则不输出保存当前新提取的读指令的踪迹,否则,输出保存当前新提取的读指令的踪迹。最后更新用于保存上一次读指令的踪迹的变量。重复以上操作,直到踪迹提取完毕。
去除重复写指令踪迹的算法如下:首先申请一个变量,用于保存上一次写指令的踪迹。第一条写指令踪迹保存到该变量。之后每一次新提取的读指令的踪迹都与上一次的比较,如果它们的TID和ADDR一致,则不输出保存当前新提取的写指令的踪迹,否则,将用于保存上一次写指令的踪迹的变量输出保存。最后更新用于保存上一次写指令的踪迹的变量。重复以上操作,直到踪迹提取完毕。
3.3 踪迹分析
离线检测需要获取程序的运行踪迹,记录大量的相关指令信息,在大量的信息中找到错误检测需要的特定数据是十分困难的,因为原子性违例错误往往就发生在对某一共享变量的访问过程中,而访存地址能很好地标记某一共享变量以及对变量的操作,所以本文将踪迹以变量的地址为标志,将原始踪迹分成不同的踪迹集合,每个集合都代表对某一变量的全部操作,这有利于下一步提取线程交互不变量时减小搜索空间,提高提取效率,也能够避免因踪迹文件过大导致的内存溢出。
Hash由于其高效性、不可逆性以及唯一性,能够满足当前的需求,最重要的是Hash不会随数据量的增大而降低搜索效率,使其在数据存储与访问中占有重要的地位[16]。它将关键字直接映射为存储地址,达到快速寻址的目的,即Addr=Hash(key),其中Hash为哈希函数[17]。
散列表按照有无排列顺序可分为两类,一种是普通映射(map),另一种是无序映射(unordered map),无序映射已被C++11标准纳为新特性。它们的原理不同,适用范围也不同,普通映射内部由二叉平衡树(红黑树)实现,在其插入时根据Key值进行排序,并对树进行旋转操作,使其满足红黑树的特性,其中的处理十分复杂。当对其进行频繁的插入操作时,需要频繁地调整红黑树的结构,耗费时间。无序映射内部是一个向量,通过Hash函数决定插入位置,当发生冲突时,采用分离链接法在相应的向量元素结点下挂接链表来解决冲突。无序映射相比于普通的映射方式省去了红黑树调整的时间,因此当不需要对数据排序时,对频繁的插入和查找,使用无序映射效率更高。基于无序映射实现的散列表的基本结构如图8所示。
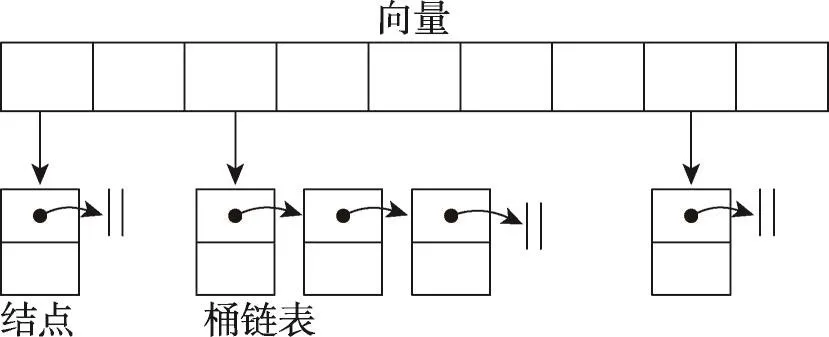
Fig.8 Hash table based on unordered map图8 基于无序映射的散列表结构
由于对踪迹的分析需要频繁地查找和插入结点,且不需要排序,从而使用基于无序映射的散列表能更好地提升性能,同时为了提升错误检测的效率,除了将踪迹分类,还会生成一个踪迹集合的检索,检索中包含访存地址和对应的集合元素数量。
具体算法流程如下:
首先,以共享变量的地址为关键字,建立散列表,将踪迹分到不同的集合中,这些集合相互独立,如下所示,其中I是测试用例中所有指令的集合。
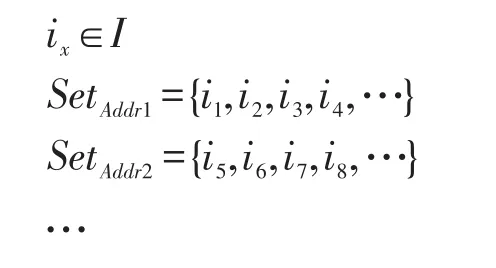
检测踪迹是否分类完毕,如果完毕,则生成检索,算法结束;否则继续处理下一条踪迹。
综上,经过踪迹分块后,原始踪迹被分为大大小小不同的集合,每个集合都是对某个访存地址的全部操作。
3.4 基于线程交互不变量的原子性违例错误并发检测
在应用程序运行时,最有可能发生原子性违例错误的往往是邻近的一个或几个操作,因此在错误检测时,不需要过多考虑全文的关系,只要考虑当前指令踪迹邻近的上下文即可。故在提取不变量时,栈的优势便体现出来,而栈的特点是后进先出,适用于提取线程交互不变量。因此本文利用栈解决不变量提取的问题。由于各个踪迹集合相互独立,并发处理每个集合中的元素能够大幅提高检测速度。
在错误检测阶段,根据第2部分提出的两类原子性违例错误,下面给出基于线程交互不变量的原子性违例错误并发检测算法。
对WWR原子性违例错误的分析可知:当两个不变量发生交错时,可能会发生原子性违例错误。但在如图3所示的反例中,虽然两个不变量也发生了交错,但同一个读操作指令却发生在不同的时间点上,可根据这点对是否真正发生了WWR原子性违例错误加以甄别。
算法描述如下:算法的输入是当前的线程交互不变量和不变量栈,不变量栈中存放着当前已检测过的本踪迹集合内的不变量。首先判断当前的线程交互不变量的写操作与读操作是否处于同一线程,如果处于同一线程,则形成了<LcWr,LcRd>形式的不变量,该形式的不变量不会单独引发WWR类型的错误,只有后面跟着<RmWr,LcRd>形式的不变量才有可能引发错误。如果当前栈为空,则未发生错误。如果当前栈非空,则取栈顶元素,但不出栈。这么做的原因是在每次得到新的不变量时,都是先检测WWR错误,再检测ReWR错误,如果在检测WWR错误时进行了出栈操作,则有可能会造成ReWR错误的漏报。如果当前栈顶元素是<LcWr,LcRd>且当前不变量是<RmWr,LcRd>,并且这两个不变量的读操作是同一个(PC一致且T一致),则说明发生了WWR类型的原子性违例错误,这一步也去除了WWR良性原子性违例的情况。
算法的伪代码表示如下:


对后文的伪代码进行如下定义:Invariant表示当前的线程交互不变量;stackInvar表示不变量栈,用于存放当前已检测过的本踪迹集合内的不变量;Result表示判断结果。由于不变量是由一条写操作的踪迹和一条读操作的踪迹组合而成,故包含了写操作的线程号Wtid、指令计数器Wpc、时间戳Wt、写操作W,以及读操作的线程号Rtid、指令计数器Rpc、时间戳Rt、读操作R,以及共用的共享变量地址ADDR。
通过对ReWR原子性违例错误的分析可知:在一定范围内,如果存在两个对同一共享变量操作的不变量,它们的读操作在同一线程,且在不同指令上(PC不同),如果它们的写操作与读操作不在同一线程,例如<RmWr,LcRd><RmWr,LcRd>,则有可能发生了原子性违例错误。但在图4提出的反例中,不变量虽然满足<RmWr,LcRd><RmWr,LcRd>,它们的读操作却是同一指令(PC相同且T不同),根据这点能够判断出这段程序包含了循环判断,因此这段程序是正确的。
算法描述如下:算法的输入是当前的线程交互不变量和不变量栈,不变量栈中存放着当前已检测过的本踪迹集合内的不变量。首先判断当前的线程交互不变量的写操作与读操作是否处于同一线程,如果处于同一线程,则形成了<LcWr,LcRd>形式的不变量,不会引起ReWR类型的错误,结束算法。否则判断不变量栈是否为空,如果为空,未发生ReWR错误,算法结束。如果不变量栈不为空,依次从栈中弹出5个元素,分别与当前的线程交互不变量做对比,如果弹出的元素是<RmWr,LcRd>,并且由于当前的不变量也是<RmWr,LcRd>,同时它们的读操作位于相同线程且不是同一条指令(读操作的TID相同且PC不同),则说明发生了ReWR原子性违例错误,同时这一步也去除了ReWR良性原子性违例的情况。
算法的伪代码表示如下:


本文的不变量提取与错误检测算法采用Python实现,分别实现了多线程和多进程两个版本。使用线程池时,运行效率反而比不使用线程池的效率低。原因是由C语言编写而成的Python的某个机制导致其对多线程的支持并不好,不同线程同时访问资源时,需要使用保护机制,由C语言编写的Python中使用的是GIL(解释器全局锁),这意味着对于任何Python程序,不管有多少处理器,任何时候总是只有一个线程在执行,解释器工作时反而因为需要频繁切换线程导致程序运行缓慢[18]。而进程池与线程池类似,进程池通过动态分配多个进程处理任务,但在多进程下没有GIL的限制。因此本文采用进程池完成对错误检测算法的并发处理。
算法实现时,对检错和进程调度进行了优化。一是利用3.3节提到的踪迹集合检索,若检索对应的踪迹集合中的元素少于3个,无需对其进行错误检测操作。其原因是:如果WWR原子性违例错误发生,则至少集合内会存在3条踪迹,分别是LcWr、RmWr和LcRd;同理,如果ReWR原子性违例错误发生,则集合内至少会存在4条踪迹,分别是RmWr、LcRd、RmWr、LcRd,所以当元素个数少于3个时,不会发生原子性违例错误。二是使各个进程负载均衡,系统在创建进程、销毁进程和调度进程时会消耗大量时间,其中创建进程和销毁进程的时间是不可避免的,因此为了提升算法的效率,就要减少过于频繁的进程调度。当一个集合中的元素较少时,进程调度的时间远比检测错误的时间长,这导致程序的运行效率不升反降。因此给进程分配任务时,以集合为单位,一次分配多个集合,并记录所有分配进来的集合的元素总数,当总数到达一定值,即完成对该进程的任务分配。优化之后可以使得各个进程负载均衡,减少因进程的频繁调度导致的速度下降。
原子性违例错误并发检测算法的关键在于对栈的操作,由于每个踪迹集合相互独立,每个集合都描述了对某一个程序运行变量的全部操作,以单进程单集合为例进行描述。
算法的伪代码如下:


其中输入是一个踪迹集合traceSet即对某一个共享变量的全部操作。输出是该踪迹集合中错误的个数nWrongNum以及由线程号、指令计数器、变量地址等构成的出错信息链表lstWrong。中间变量szContent存放一条当前读写指令的踪迹信息,字符串#eof代表踪迹集合的结束,栈stack中元素存放写指令的踪迹信息,函数mkInvariant则是将符合条件的读写指令的踪迹信息拼接成一条线程间交互不变量,栈stackInvar用于存放已检测过的不变量。
算法描述如下:每次读取集合内的一条踪迹,如果读取到了结束字符串,则关闭当前的踪迹集合,并清空栈stack和栈stackInvar。否则,如图9(a)所示,当I4是写指令时,如果栈为空,则入栈。否则,如图9(b)所示,如果与栈顶元素I3位于同一线程,则舍弃I3,I4入栈,因为记录相同线程的写指令信息并不会影响错误检测所检测出的错误个数,即本算法只记录踪迹中能够标识出的最邻近发生的原子性违例错误个数及其影响的变量。如图9(c)所示,如果I4与栈顶元素I3位于不同线程,I4入栈。
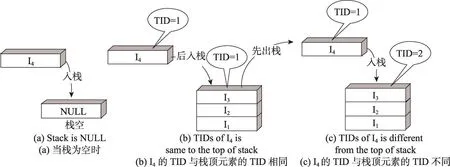
Fig.9 Status what would happen when I4is write instruction图9 当I4是写指令时会发生的情况
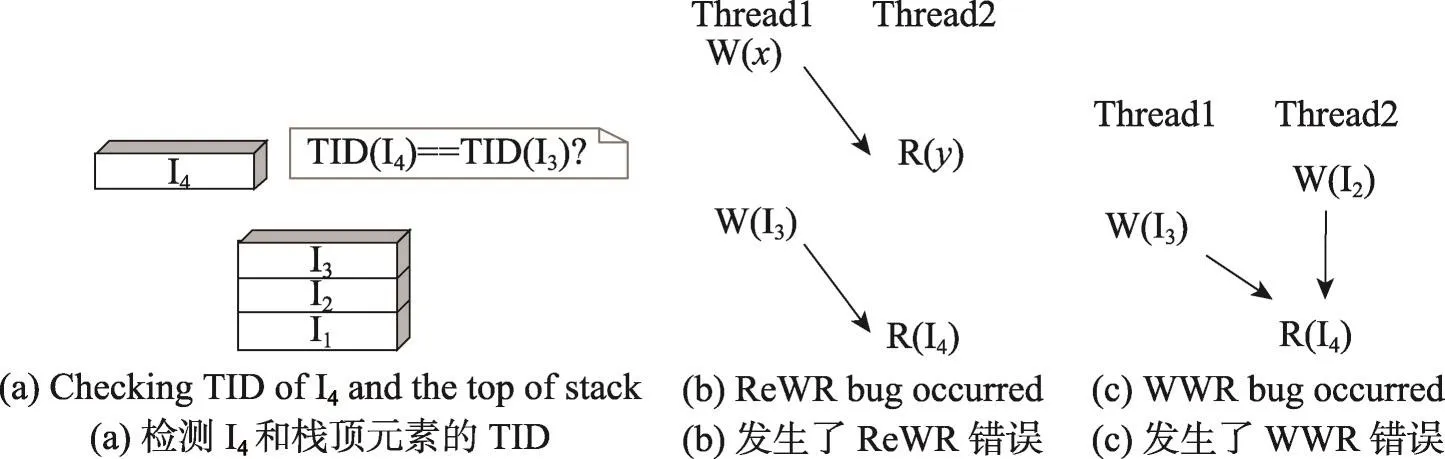
Fig.10 Status what would happen when I4is read instruction图10 当I4是读指令时会发生的情况
相反地,当I4是读指令,则会导致栈中元素出栈,当栈空时,显然没有必要检测该条踪迹,故舍弃。否则,如图10(a)所示,判断I4与栈顶元素I3是否位于相同线程,如果处于相同线程,则提取出线程交互不变量<LcWr(I3),LcRd(I4)>,这个不变量十分安全,不必担心会引起原子性违例错误。反之,如果位于不同线程,I3出栈,并提取出线程交互不变量<RmWr(I3),LcRd(I4)>,这个不变量十分危险,有可能会引起本文提出的两种原子性违例错误,因此暂时将这个不变量与之前记录的线程交互不变量比较,如果之前记录的不变量是<RmWr(x),LcRd(y)>,并且这两个不变量的读指令PC不同,如图10(b)所示,则ReWR原子性违例错误发生。继续令栈内元素出栈,如果在这个过程中遇到一个不变量<LcWr(I2),LcRd(I4)>,I2与I4位于相同线程,如图10(c)所示,则两个不变量相互交错,发生了WWR原子性违例错误。之后清空栈,避免栈中剩余元素与新来元素产生新的依赖关系。如果没有这样的一条指令,则直到栈空后,继续下一条指令踪迹的处理。
4 实验评估
本文分别对5个测试用例进行原子性违例错误检测,这5个程序分别是测试程序Bank以及Splash2中的FFT、LU、RADIX和CHOLESKY。
测试环境如表1所示。

Table 1 Testing environment表1 测试环境
踪迹总量与程序的复杂程度呈正比,程序的复杂程度与变量的数量、运用的数据结构、算法都相关。程序越复杂,所得到的踪迹总量就会越大。使用本文算法对这5个测试用例进行错误检测,所得到的优化前后踪迹总量的对比如图11所示。
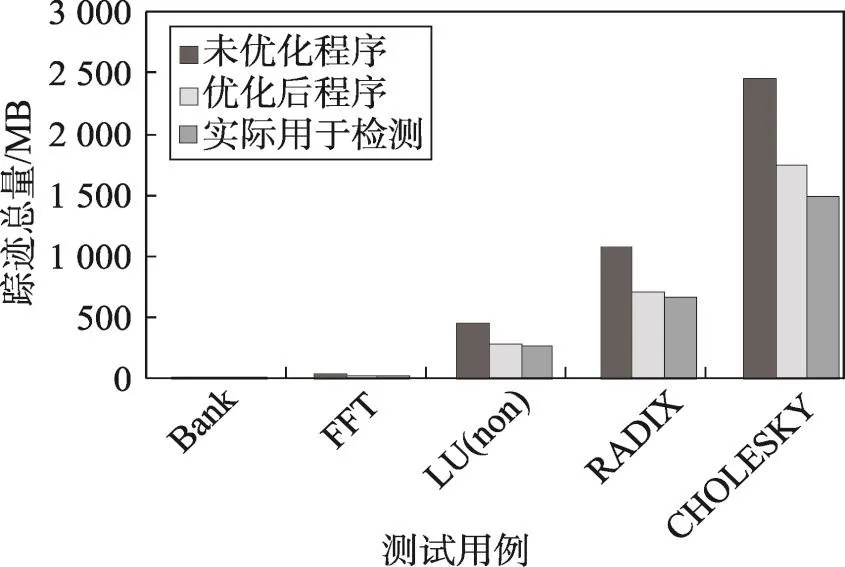
Fig.11 Comparative analysis of total number of traces before and after optimization图11 优化前后踪迹总量对比
优化后程序踪迹总量比优化前减少了约30%,而实际用于检测的踪迹总量平均要比优化后程序运行踪迹的总量又减少约14%,即实际用于检测的踪迹总量比未优化程序踪迹总量减少了约40%,这既缩小了磁盘和内存的占用量,又大大减少了错误检测时的搜索空间,且随着被检测程序复杂度的提高,减少的踪迹量会更多,能够大大提升踪迹检测的效率。
编程人员在编写多线程程序时有时会忘记对共享变量加锁或者忘记线程同步的事情经常遇到,从而导致的问题也多种多样,因此本文选择注入这种类型的错误,并对比注入错误前后对结果的影响,以排除干扰。注入错误的方法是在程序的源代码中,将加锁部分去除或进行适当修改,如图12所示,注释掉的部分就是注入错误的部分。在图12(a)中对源代码做出了更改,去掉线程间的同步措施,在图12(b)中去掉了锁。

Fig.12 Examples of injecting bug图12 注入错误示例
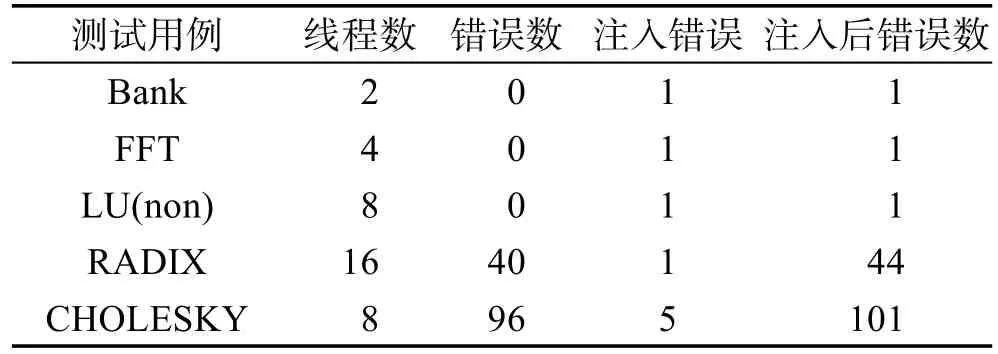
Table 2 Comparison of test results before and after injecting bugs表2 注入错误前后错误检测结果对比
注入错误前和注入错误后的实验结果对比如表2所示。在对Bank、FFT、LU(non)、CHOLESKY的检测中未出现异常,所注入的错误都能够有效地检测出来,但在对RADIX的测试中,发现检测结果与注入错误的数量不相符,经检查,是由于除去锁的部分在程序中多次调用所引起的。通过实验证实算法能够有效检测出原子性违例错误。
图13为利用基于无序映射的散列表对踪迹进行分类后错误检测与不对踪迹进行分类的错误检测的效率对比。
两个算法都在单进程模式下运行。从算法的运行时间上看,随着踪迹的增加,对踪迹分类后的错误检测时间远远少于不对踪迹进行分类的错误检测时间。其原因在于,如果不对踪迹进行分类,在提取不变量时,就会检测许多与该共享变量不相关的其他变量的踪迹,极大地降低错误检测的效率。
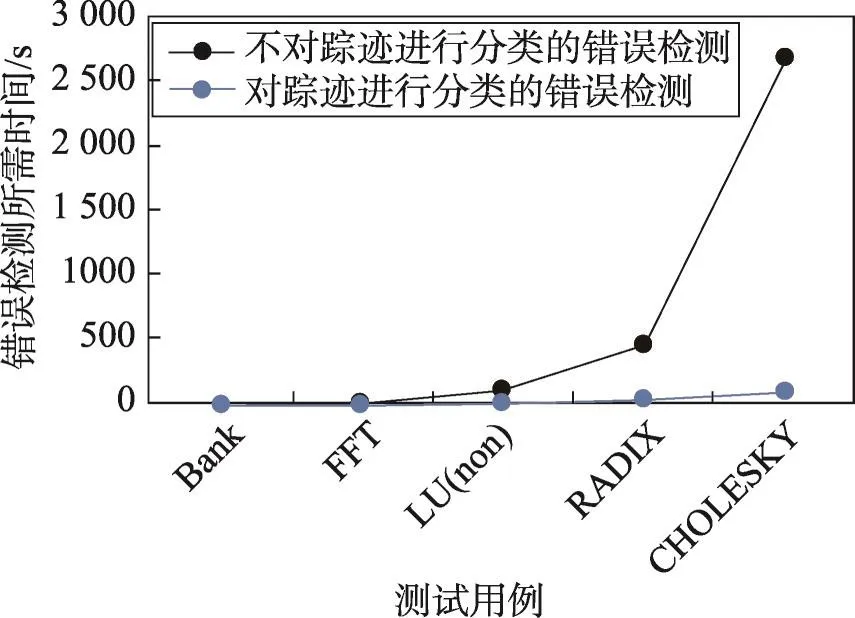
Fig.13 Efficiency comparison between trace classification and non-classified detection algorithms图13 踪迹分类与不分类的检测算法的效率对比
图14为多进程错误检测所需时间的对比。这组对比测试程序均已完成优化(O3级别),从中能够看出:在当前的实验环境下,当踪迹总量较小即测试用例较简单时,进程数量对于错误检测的时间没有过多影响,但是当踪迹总量达到一定数量即测试用例较复杂时,多进程的优势就能体现出来。由于测试环境限制,当其达到8个进程时,运行效率达到最优,相比1个进程的运行效率有了大幅提高。但当进程个数超过CPU所能同时运行的极限时,进程会发生状态切换,导致其运行效率下降。
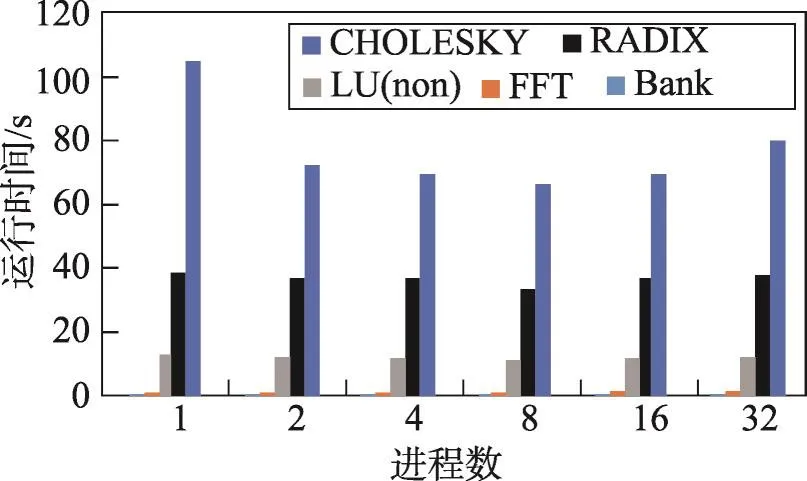
Fig.14 Running time comparison of multiprocess bug detection图14 多进程错误检测运行时间对比
5 总结
本文针对现有原子性违例错误检测中出现的问题,对于两类特定的原子性违例错误提出了一种基于线程交互不变量的原子性违例错误并发检测算法。本文算法采用Pin提取程序的原始踪迹并去除冗余;利用基于无序映射的散列表对踪迹分类,大大缩小了错误检测的搜索空间,避免了踪迹过大导致的内存溢出;利用栈快速匹配交互不变量来标记线程交互;利用多进程技术,同时并发处理每类踪迹,提升了错误检测效率;对检错和进程调度进行了优化,进一步减小了由踪迹过大所带来的影响,使得各个错误检测进程负载均衡,同时解决了因进程调度频繁导致的速度下降问题。实验结果表明,本文算法能够较好地规避踪迹较大的问题并能快速有效检测出原子性违例错误。由于算法使用离线的方式检测错误,会记录程序的运行信息,通过这些信息能够实现对错误的重演,检错和重演相结合能够提高算法的扩展性和实用性。目前实现的算法还存在缺陷,主要针对WWR和ReWR两类原子性违例错误进行检测,不能够检测到所有原子性违例错误,同时原子违例并不能够说明一定出现错误,存在误报的可能。并且本文算法属于踪迹敏感的错误检测算法,要全面检测所有可能出现的并发错误,就需要多次重复执行本算法,这会导致程序执行许多重复操作,降低其运行效率,在以后的研究中会进一步完善算法。
猜你喜欢
计算机应用与软件(2022年9期)2022-10-10
现代电子技术(2022年8期)2022-04-13
体育科技文献通报(2022年1期)2022-01-15
小学阅读指南·低年级版(2020年9期)2020-10-12
现代装饰(2020年8期)2020-08-24
中国外汇(2019年20期)2019-11-25
中国外汇(2019年8期)2019-07-13
文史春秋(2017年12期)2017-02-26
民主与科学(2014年3期)2014-02-28
俄罗斯问题研究(2012年1期)2012-03-25
