
基于Spark的时间序列并行分解模型*
2018-07-13 08:54黄齐川李天瑞
计算机与生活 2018年7期
李 勇,滕 飞,2+,黄齐川,李天瑞
1.西南交通大学 信息科学与技术学院,成都 611756
2.轨道交通工程信息化国家重点实验室(中铁第一勘察设计院),西安 710043
1 引言
时间序列是指在生产和科学研究等过程中,按照时间顺序记录得到的一系列观测值,反映了现象的发展变化规律。随着信息技术的快速发展,各个行业应用系统产生的时间序列呈爆炸式增长,已远远超出了现有传统的信息系统的处理能力[1-2]。寻求有效的大数据处理技术成为现实世界的迫切需求。
现实中的时间序列一般是比较复杂的、广义平稳或者非平稳的,由多种因素共同作用的结果,不容易直接对其进行观察分析,而需要首先对其分解。本文根据时间序列分解算法每个处理过程输入数据的独立性,将时间序列分解算法分为两种操作类型:(1)局部相关。这种操作类型的时间序列算法具有良好的并行性,因为切分得到的时间子序列具有一定的独立性,处理节点之间进行少量的通信、数据交换就可以达到较好的处理效果,例如STL(seasonaltrend decomposition using LOESS)[3]、EMD(empirical mode decomposition)[4]、X-12-ARIMA(autoregressive integrated moving average model)[5]等。STL算法可将时间序列分解为低频率的趋势项、高频率的季节项及不规则变化的残差项[3]。因为STL使用LOESS[6](locally weighted regression and smoothing)作为平滑器,所以具有良好的数据并行特性。(2)全局相关。时间序列的每个时间点的处理过程都有很强的相关性,这种类型的时间序列分析算法难以取得较好的并行效果,例如 SSA(singular spectrum analysis)[7]、WD(wavelet decomposition)[8]等。SSA是一种时间序列分解算法,具有插值、去噪、识别趋势和周期信号以及建立预报模型的功能[9-10]。SSA算法分解过程为:首先将时间序列转换成轨迹矩阵,然后对轨迹矩阵进行奇异值分解,分解之后再对每个分量进行分组和重构,从而得到分解结果[7]。SSA分解过程中各时间点之间具有很强的相关性,序列分段计算会造成信息损失,数据并行性较差。
现如今成熟的数据挖掘平台主要有SAS、SPSS、Matlab、R等,它们当中包含丰富的时间序列分析软件包,不过这些都不是分布式的,无法高效处理大规模时间序列数据。Spark是目前最活跃的开源分布式计算框架之一,其基于内存计算的特点,提高了大数据环境下处理数据的实时性,同时也保证了高容错性和高可伸缩性,并且允许用户将Spark部署在大量廉价的硬件上,形成集群[11]。研究人员相继提出了基于Spark平台的并行算法。文献[12]设计了基于Spark平台的DNA基因序列拼接算法,在保证拼接准确性的前提下提升了拼接效率。文献[13]借助Spark平台对道路交通管理分析平台的海量系统日志进行查询、分析,相比传统的分析方法更加高效。文献[14]提出了基于Spark的序列模式挖掘算法,打破了传统串行算法不能处理大规模数据集的局限,并在真实数据集上验证了算法效率。文献[15]提出了基于Spark平台的随机并行森林算法,算法从数据和任务两个角度设计并行方案,在分类准确性、扩展性等方面都优于现有的随机森林并行算法。对于分布式算法的研究虽然包括了丰富的机器学习算法,但是对于时间序列分解算法鲜有涉及。
鉴于传统的单机数据挖掘平台无法处理大规模的时间序列,对于并行的时间序列分解算法国内外研究成果较少,目前流行的分布式机器学习平台未涉及时间序列分解算法的原因,本文提出一种基于Spark平台的时间序列分解模型。模型的核心思想为:首先将完整的时间序列切分成一系列的子序列,通过对子序列去冗余的方式保护内部数据免受端点数据污染,然后将带有冗余的时间子序列分发给Spark集群的计算节点,每个节点独立进行序列分解,最后去除结果的冗余部分,再将其合并。本文针对两种(局部和全局相关)分解特点的算法,给出模型的两个实例,在基于内存计算的计算框架Spark上实现STL(局部相关)和SSA(全局相关)。
本文组织结构如下:第2章结合具体的时间序列分解算法STL、SSA详细介绍模型的框架结构;第3章针对模型实例进行实验测试,验证模型的有效性和高效性;第4章对全文进行总结。
2 模型设计
本文模型的主要目标是在保证正确性的前提下高效地分解大规模时间序列。因此目标主要定位在以下两方面:(1)着眼于集成两种类型计算特点的时间序列分解算法。对于第二种类型的时间序列分析算法并行难度较大,不同的算法需要特定的并行方式才能达到较好的效果,本文旨在通过数据并行的方式得到一个近似结果,并通过冗余数据的方式提高准确性。(2)模型能够架构在Spark的集群上。
模型构架主要包括3个模块,如图1所示。

Fig.1 Model framework图1 模型架构
(1)时间序列切分冗余。考虑到将时间序列切分后的时间子序列之间的关联操作是局部相关的,也就是说对某个时间点的计算只需要用到附近一定数量的数据点,因此考虑通过对时间子序列冗余部分数据以提高分布式处理时间序列的准确性。
(2)时间序列分解。该模块的功能是将时间序列分解算法应用到每个Spark计算节点,得到每个带冗余的时间子序列的分析结果。
(3)时间序列结果合并。将每个计算节点的分析结果去除冗余部分直接合并。
本文将以STL算法为例介绍模型实现过程。
2.1 模型实例
2.1.1 冗余数量选取
时间子序列之间是局部相关的,因此冗余的数据越多,序列切分处理后的结果就越接近完整序列处理的结果。为了方便理解,本文以一个周期(T)的数据为单位对时间子序列进行冗余。
STL的计算过程由内循环和外循环两部分组成。内循环要进行3次窗口长度为 ns、nl、nt的LOESS[3]平滑和3次窗口长度为 np、np、3的移动平均,其中np为时间序列的周期。外循环是一个不断迭代内循环的过程。
假设某个时间序列T的子序列Tn中的一个时间点为tm,想要保证在一次内部循环的过程中,独立处理子序列Tn和完整处理时间序列T时tm时间点的计算结果相近,就必须算出3次LOESS平滑过程和3次移动平均过程计算tm时所需要前后时间点的数据量,即冗余数据量。
分析STL算法的执行过程,冗余数据量为以下两部分冗余量的加和(np为周期长度):
(1)3次LOESS平滑。对于某个时间点tm的LOESS平滑使用到前后时间点的数量为窗口长度的一半。周期子序列平滑中的LOESS平滑是在周期层面的平滑,需要窗口长度一半数量的周期数据,低通滤波、趋势平滑过程中的LOESS平滑是在时间点层面上的平滑,只需要窗口长度一半数量的时间点数据。例如,对于一个以年为周期的月度时间序列,假设分别对某个时间点进行窗口长度为5的周期层面和时间点层面上的平滑需要时间点前后的数据量为24个月(2个周期)和2个月(2/12个周期)。因此,周期子序列平滑中LOESS平滑过程需要冗余的数据量为ns/2,低通滤波平滑过程需要冗余的数据量为nl/2×np,趋势平滑过程中LOESS平滑需要冗余的数据量为nt/2×np。
(2)3次移动平均。移动平均为在时间点层面上的操作,3次窗口长度为np、np、3的移动平均过程中需要的数据冗余量分别为 (np-1)/np、(np-1)/np、2/np。
STL算法是一个迭代的过程,由多次内循环和多次外循环组成,因此序列切分处理即使冗余数据也不可能和完整时间序列处理的结果完全一致,冗余数据的作用是在一定程度上保护内部的数据不受端点数据的污染,从而使得序列分块处理的结果尽可能地接近完整序列处理的结果。
综合以上分析,本文使用如下公式(两部分冗余数量的加和)来计算冗余量:

例如当 ns=7,nl=np,nt=1.5np时 R=7,即冗余数据量为7个周期。
对于STL算法切分后的时间子序列之间是局部相关的,因此可以分析算法执行过程得到合适的冗余数量。而SSA算法是全局相关的,因此本文通过实验确定冗余数量来达到较优的分解效果。
2.1.2 时间序列切分
主要包括对时间序列切分时的几种特殊情况的处理:(1)对于STL算法为了达到较好的分解效果,周期子序列平滑窗口必须大于等于7,因此当时间子序列的长度小于7个周期时,默认其为7个周期。(2)时间子序列长度大于完整序列长度时,将时间序列划分成一个子序列,即处理完整时间序列。(3)时间序列不一定能等分,最后一个子序列应包含剩下所有时间点。
2.2 模型实现
图2展示了Spark实现并行分解算法的状态转移图。结合并行状态转移图可以将并行过程描述如下:首先从HDFS(Hadoop distributed file system)上读取数据,并将数据重新分区(分区数为参数slice)生成RDD1。然后调用Spark中的mapPartitions算子获取每个分区的迭代器,调用切分冗余函数rdSplit()将每个分区中的时间序列切分和冗余生成一系列时间子序列,结果返回格式为ArrayBuffer(ArrayBuffer(object))的RDD:RDD2。随后再利用RDD2.map算子将stl()、ssa()分解算法应用到每个时间子序列,每个时间子序列分解后直接删除冗余,结果返回格式为ArrayBuffer(ArrayBuffer(T,S,R))的三元组集合(一个时间子序列分解结果)组成的集合(一个分区中所有时间子序列分解结果),再调用flatMap算子将RDD中每个分区每个集合中的元素合并成一个集合,即RDD3的格式为ArrayBuffer((T,S,R))。最后利用Spark提供的saveAsTextFile算子将RDD3持久化存储到HDFS的指定目录。

Fig.2 Parallel state transition diagram图2 并行状态转移图
3 实验设计与结果分析
本文设计了两部分实验来验证模型实例的结果:设计了并行一致性验证实验来证明时间序列切分、冗余的并行方式的有效性;设计了性能验证实验来证明基于Spark平台实现的性能优势。
3.1 一致性验证
3.1.1 数据集描述
本文采用两种类型的数据集:(1)苏黎世1749—1983年太阳黑子月度数据,共2 820个观测;(2)添加了噪声的正弦模拟信号,y=50×sin(43×π×t)+20×sin(52×π×t),采样频率为1 000。
3.1.2 实验环境
实验中使用的计算机配置如表1所示。

Table 1 Computer environment表1 计算机配置信息
3.1.3 实验方案
本文使用相似度函数来衡量序列分布式处理和完整序列处理结果的相似程度。相似度函数[16]定义如下:设xn和yn是两个能量有限的确定性信号,并假定它们是因果的,则定义xn和yn的相关系数为:

由公式可知,当xn=yn时,ρxy=1,表明两个信号完全相关(相等);当它们完全无关时,ρxy=0。
本实验在单机上进行,使用R语言中提供的STL、SSA算法包。实验方案是对两个类型不同的时间序列,分别采用不同的处理方式:(1)单机处理方法,完整时间序列直接分解;(2)分布式处理方法,时间序列切分、冗余后分解、合并,然后对实验结果进行对比。其中合并时间子序列分解结果时,冗余处理方式有两种:冗余部分取平均和冗余直接去除。实验选取了不同长度的时间子序列,不同的长度反映了时间序列切分带来的端点对内部数据的污染程度。
3.1.3.1 局部相关分解算法一致性验证(STL)
主要包括3组对比实验:(1)对于分布式处理方式,冗余取平均和冗余直接去除的效果对比;(2)对于分布式处理方式,采取不同时间子序列长度的效果对比;(3)对于前两组对比实验使用不同类型时间序列处理结果对比。两种处理方式结果对比评价指标为式(2)。
分布式处理方式将时间序列分成多个时间子序列,由式(1)计算冗余估计量(ns=7,nl=np,nt=1.5np,参数选择参考文献[3]),R=7。实验中选取了6个长度不同的冗余量:0T(不冗余),1T,3T(R/2),7T(R),10T(3R/2),14T(2R),T表示一个周期采样点数量。
表2给出了完整时间序列数据分解结果和分布式时间序列分解结果的相似度,分解结果主要包括季节项(S),趋势项(T),季节项和趋势项的和(S+T)。太阳黑子1、2数据集中时间子序列的长度分别是3T、78T。分解结果的冗余处理方式为直接去除。太阳黑子3数据集中时间子序列长度为78T,冗余处理方式为冗余部分取平均。正弦模拟信号序列长度为3T,冗余处理方式为直接去除。(3T,78,冗余去除)表示每个子序列长度为3周期,共78个序列,冗余直接去除。

Table 2 Consistency test result for local correlation based decomposition algorithm表2 局部相关分解算法一致性验证结果(STL)
对于两种不同类型的时间序列数据,分析表2中的数据可以得到如下结论:
(1)时间子序列冗余数量越多,与完整序列处理的结果相似程度越高,太阳黑子1和模拟信号中时间子序列的长度为3个周期,这是一种极端情况即端点数据最大程度地污染内部数据,当冗余量达到7个周期的数据时,季节项和趋势项的相似度都达到了91%,说明了本文时间序列分布式处理方法和传统的单机处理结果对比具有较高的一致性。
(2)对比太阳黑子和模拟信号分解结果,可以说明对于不同类型的时间序列,通过冗余的方式,分布式处理都能达到较好的处理效果。
(3)对比太阳黑子2和3数据集得出结论,时间子序列分解结果合并时,冗余部分直接去除具有更好的效果,这是因为冗余部分取平均值会把边缘的误差传递到内部。
(4)分布式处理时间序列的方式,冗余的数据造成了额外的计算开销,但是极大地提升了计算结果的精确度。假设时间子序列长度为s,冗余数据长度为r,则分布式处理方式增加的计算量为a=r/s(%)。对于同一个时间子序列来说,子序列长度越大造成的额外开销就越小。例如,表2中当时间序列的长度为78T时端点数据对内部污染很小,即使不冗余数据也可以达到90%的相似度,冗余数据为7T时增加了17.9%计算量,相似度提高了4.8%。表4中当时间子序列的长度为3T时,冗余7T的数据时增加了466%计算量,相似度提高了59.2%。
3.1.3.2 全局相关分解算法一致性验证(SSA)
首先将太阳黑子数据和模拟信号时间序列分为不同段长,然后采取不同冗余长度进行分解,最后对实验结果进行对比,结果对比评价指标为式(2)。算法参数:SSA算法的窗口长度为序列一半,SSA算法分组参数参考文献[13]。实验使用SSA将两个序列都分解成两个分量F1和F2,太阳黑子数据分解后得到趋势项和周期项,模拟信号中不包含趋势,因此分解后得到两个正弦分量。
表3给出了分解结果的相似度,可以发现:(1)随着冗余数量增多,结果的相似度不断提升,对于太阳黑子数据段长为3周期这种极端情况,F2分量的分解效果很不理想,这是因为SSA分解过程中各时间点的操作是全局相关的,时间序列切分得太短,导致损失信息太多,信号周期信息不全,所以分解结果很不理想。因为F1分量能量较强,即使段长很短,也能取得较好的效果。模拟信号比较平稳,在这种极端情况下表现良好。(2)对于太阳黑子2和模拟信号数据,当冗余数量为2个周期采样点时相似度达到了91%以上,说明本文方法与单机处理方式具有较高的一致性,当冗余数据超过2个周期采样点,效果提升不明显。
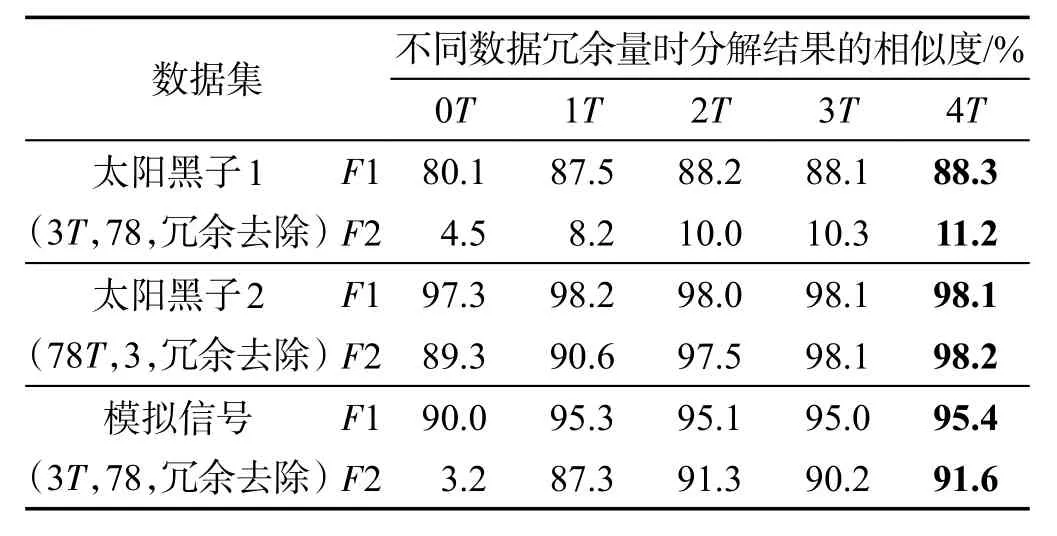
Table 3 Consistency test result for global correlation based decomposition algorithm表3 全局相关分解算法一致性验证结果(SSA)
3.2 性能提升验证
3.2.1 数据集描述
本实验采用的数据是高铁轨检车采集的轨道状态真实数据。轨检车是一列装有专用检测设备,对轨道、供电、信号、周边环境等影响列车安全运行和舒适性的技术指标和相关信息进行实时检测。轨检车每0.25 m采集一个数据点,本实验只验证算法效率,因此设置高铁轨检数据周期T为500 m的采样点数,每个块的大小为10个周期数据。STL实验使用6个数据集32 MB(约500万采样点)、64 MB、128 MB、256 MB、512 MB、1 024 MB。由于SSA计算时间较长,使用5个较小的数据集8 MB、16 MB、32 MB、64 MB、128 MB。
3.2.2 实验方案
为了方便分析实验结果,将本文模型的实例基于Spark的STL、SSA算法标记为STL-Spark、SSASpark。为证明STL-Spark的效率提升和串行单机算法的局限性,本实验同R语言软件包中的STL、SSA算法进行比较,该算法标记为STL-R、SSA-R,Scala语言实现的串行STL算法记为STL-S。为了公平起见,Spark实现的参数都参照R的设置。
Spark RDD是被分区的,在生成RDD时,一般可以指定分区的数量,如果不指定分区数量,当RDD从集合创建时,则默认为该程序所分配到的资源的CPU核数,如果是从HDFS文件创建,默认为文件的Block数。分区的个数决定了并行计算的粒度,本实验是从HDFS上读取文件,HDFS上默认的Block大小为64 MB,粒度太粗,为了能够充分利用计算资源,需要对RDD进行重新分区。Spark官方建议每一个CPU核(core)分配2~3个任务,本实验最多使用8个节点共32个核,因此Spark读HDFS上的时间序列数据时分区数目设置成96。STL、SSA实验中冗余数量为1个周期数据,冗余处理方式采用的是直接去除。
表4展示的是单机处理方式(STL-R和STL-S)和基于Spark的分布式处理方式的运行时间,表中“NA”表示内存溢出程序崩溃。分析表中数据可以得到如下结论:(1)STL-S运行效率低且数据处理能力较差,最多只能处理128 MB的数据,产生这种情况的原因是当数据量增大时,JVM(Java virtual machine)垃圾回收时间较长。(2)STL-R数据处理能力较强但是受内存限制,数据量较大(1 024 MB)时程序崩溃,此时STL-Spark表现出较大优势。
表5展示的是SSA算法单机处理方式SSA-R和基于Spark的分布式处理方式的运行时间。分析表中数据可以得出结论:R语言数据处理能力较强但是受内存限制,数据量较大(32 MB)时程序崩溃,此时Spark表现出较大优势。对于实验中最大的数据集128 MB,8个节点相对于1个节点效率提升了7倍,极大地提升了效率。
4 结束语
为了应对大数据时代下因时间序列规模急剧增长导致的传统单机算法无法快速进行时间序列分解的问题,本文提出了一种基于Spark平台的时间序列分解模型。模型对特定计算特点(局部相关和全局相关)的时间序列分析算法进行并行,使其能架构在Spark计算集群上。针对模型实例(STL、SSA)进行实验,结果证明了局部和全局相关分解算法通过冗余数据的方式都能够保证分布式分解的正确性,同时基于Spark平台的实现,极大地提高了时间序列分解效率。对于段长和冗余数量参数的选取,局部相关分解算法通过分析算法的执行过程可以计算出合适的冗余数量,即使段长很短的极端情况也可以达到一个较优的效果(相似度90%以上)。全局相关分解算法分解过程中各时间点之间具有很强的相关性,序列分段计算会造成信息损失,通过冗余数据的方式难以达到局部相关分解算法的效果,但是通过实验选择合适的段长和冗余数量也可以得到一个较优的结果。未来的工作:(1)对于SSA这种全局相关计算特点的算法,需要做更多的探索来确定分段的长度以及冗余数据的数量;(2)可以考虑将更多的时间序列分解算法融入到模型中,以形成一个分布式的时间序列分解工具。

Table 4 Running time for different processing methods(series and distributed)with different data sizes(STL)表4 STL串行和分布式处理方式、不同大小数据集的运行时间

Table 5 Running time for different processing methods(series and distributed)with different data sizes(SSA)表5 SSA串行和分布式处理方式、不同大小数据集的运行时间
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16
小学生学习指导(低年级)(2020年10期)2020-11-26
电脑爱好者(2020年19期)2020-10-20
电子制作(2019年22期)2020-01-14
作文大王·低年级(2017年11期)2017-12-05
制导与引信(2017年3期)2017-11-02
学苑创造·A版(2017年1期)2017-01-19
燕山大学学报(2015年4期)2015-12-25
科技与创新(2014年11期)2014-08-21
汽车电器(2014年5期)2014-02-28
