
对等通信辅助下抗攻击的位置隐私保护方法
2018-05-08 07:51孙丹丹罗永龙范国婷郭良敏郑孝遥
计算机工程与应用 2018年9期
孙丹丹,罗永龙,范国婷,郭良敏 ,郑孝遥
SUN Dandan1,2,LUO Yonglong1,2,FAN Guoting1,2,GUO Liangmin1,2,ZHENG Xiaoyao1,2
1.安徽师范大学 计算机科学与技术系,安徽 芜湖 241003
2.安徽师范大学 网络与信息安全工程技术研究中心,安徽 芜湖 241003
1.Department of Computer Science and Technology,Anhui Normal University,Wuhu,Anhui 241003,China
2.Engineering Technology Research Center of Network and Information Security,Anhui Normal University,Wuhu,Anhui 241003,China
1 引言
移动通信的通讯质量不断提高以及移动定位技术越来越精确,使得基于位置的服务(Location-Based Service,LBS)得到高速发展。移动用户只需提供自身准确、实时的位置信息给位置服务器,便可获得相关服务,例如:查找离我最近的餐厅、休闲场所、购物场所等。然而盲目地发送位置信息给服务器必然会造成自身信息的泄露,将给用户带来巨大的风险。因此,位置隐私保护越来越受到人们的重视。
在位置隐私保护研究领域中,Gruteser等[1]首先引入k-匿名模型:通过搜索查询用户周边的k-1个相互之间不能区别的用户,用覆盖它们的匿名区域代替查询用户真实的位置,即使发送的位置信息被攻击者获取,也不能准确地从k个用户中定位到该用户,从而达到保护真实用户位置隐私的目的。现有很多方法都是以k-匿名为基础。
多数研究通常采用第三方中心服务器架构[2-4],但作为核心的位置匿名服务器容易成为受攻击的对象,且该架构还存在如下不足:(1)需通过大量用户的注册使用,才能实现匿名区域的构建,并且要求注册用户诚实可信;(2)仅支持静态快照定位;(3)匿名服务器承担生成匿名区和过滤结果集的工作,若大量用户频繁请求查询,必然导致计算量急剧上升,造成系统瓶颈,限制了位置服务更好的发展。
针对中心服务器存在的上述不足,诸多研究者开始采用无中心服务器的结构。文献[5]首先提出一种分布式算法,但效率并不高;Chow等[6]率先提出P2P模式下使用匿名算法的思想,通过对等点查询算法构建匿名区域。用户自组织通信形成用户组,然后计算组内最小边界矩形,查询节点随机选取组内成员作为代理,由代理代替查询节点发起查询,最后返回结果。但Chow在匿名组选择成员时没有考虑用户的移动性,且往往导致查询节点位于匿名区中心处,导致区域中心攻击。文献[7]对文献[6]作了改进,通过随机扩大匿名区来避免匿名区中心攻击,但仍存在查询节点分布不随机等问题。Pingley等[8]提出一种不需要可信第三方的方法,该方法避免攻击者从查询内容中推断用户的兴趣和习惯。
另外,传统方法由于使用匿名区域易受攻击[9],因此部分研究不再使用匿名区域。Yiu等[10]提出了SpaceT-wist方法,用户使用锚点代替自身真实位置向服务器发起增量近邻查询,直至供应空间包含需求空间为止。但该方法无法达到位置k-匿名,隐私保护度不高。Gong等[11]在文献[10]基础上提出了一种改进算法,能达到k-匿名,但使用了中心服务器。黄毅等[12]提出了一种用户协作无匿名区域的CoPrivacy方法,通过用户协作形成匿名组,组内用户用该组的密度中心代替真实位置,增量地从服务器获得近邻查询结果,再通过近邻查询结果与自身位置之间的距离计算得到精确的查询结果。但该方法要求周边用户全部诚实可信,无法防止恶意攻击者冒充用户节点发起攻击的情况。张国平等[13]使用了代理转发查询的方法,避免了用户隐私在服务器端泄露,但无法避免攻击者伪装成代理用户获取用户隐私;杨松涛等[14]提出了一种位置隐私保护模型并设计了一种基于伪随机置换的位置隐私保护方案,实现了完美匿名和位置盲查询,但无法抵抗恶意节点的主动攻击;徐建等[15]提出了在动态P2P环境下基于匿名链的位置隐私保护算法,但不能有效抵御连续查询攻击[16-17]。以上基于用户协作的方法通常无法抵御不诚实用户的攻击行为。近年来,还出现了基于私有信息检索的位置隐私保护方法[18-20],虽然隐私保护度较高且可避免多种攻击,但此类方法预计算开销和运行时计算开销比较大,还无法广泛应用。
综合上述问题,本文提出一种对等通信辅助下抗攻击的位置隐私保护方法(以下简称P2P AG算法)。该方法不使用中心服务器,未生成匿名区域,解决P2P结构中用户不诚实协作问题。它在k-匿名思想的基础上使用构建匿名组的方式混淆身份信息与位置信息的对应关系,以此隐藏用户身份与位置信息的关联性,达到隐私保护的目的;将速度引入匿名组的构建,并通过缓存机制增加匿名组的可重用性,以此抵御一般恶意攻击和连续查询攻击,且减少系统开销。
2 P2P AG位置隐私保护方法
2.1 相关定义
定义1(速度夹角θ)两个移动节点的当前速度矢量所形成的夹角(规定大小为0的速度矢量以其所在道路方向为速度方向),如图1所示,n1和n2是两个移动节点,速度分别为V1、V2,则当前的速度夹角θ为:

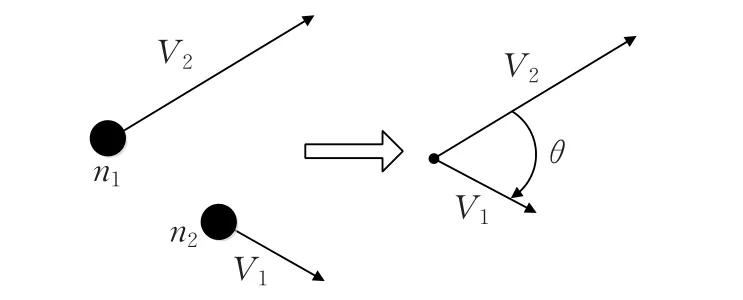
图1 速度夹角
定义2(速度分类)指以速度为标准的分类方法,具体而言,以查询用户的速度方向为中心轴,周边区域边界夹角为90°的区域范围为移动用户的类别,速度方向与查询用户速度方向的夹角在这个范围内的节点均为查询用户的同类节点,如图2所示。

图2 速度分类
定义3(节点Node)在一定范围内的移动用户,可用数据结构Node(IP,Loc,vec,k,List,Lt,t0,v)加以表示,其中:
IP为节点唯一的身份标识;
Loc表示当前位置坐标;
vec为当前速度,由节点自身设定一个时间片不停更新;
k为节点要求的匿名度,即匿名组内节点的个数,由节点决定,显然k越大,匿名组内成员个数越多,隐私保护程度越高[21];
List为缓存内周边节点的信息表,包含周边k-1个节点的信息,该信息包括序号、位置坐标以及速度,初始为空;
Lt表示匿名组的生存时间,超过这个时间段,缓存内的List将不能再被使用;
t0表示记录下来的上一次构建List表时的时间点;
v表示记录下来的上一次构建List表时的节点速度。
定义4(查询节点)查询节点q指发起位置查询服务请求的移动节点。
定义5(代理节点)代理节点a指代替查询节点向位置服务提供商发出查询请求、并将返回的结果集返回给查询节点的节点,它是查询节点从产生的匿名组中随机选择出的一个节点。
定义6(组内节点)组内节点I指除查询节点、代理节点以外的匿名组内节点。
定义7(伪代理节点)伪代理节点w由于查询节点q在匿名组中选中的代理节点a可能是其他周边节点p的List表中的节点,查询节点q无法与这类节点(即a)建立通信连接,所以选择List表中含a的这个周边节点p作为伪代理节点,由它承担代理节点a的任务。
定义8(匿名组)匿名组ano_group指一个由查询节点、代理节点(或伪代理节点)、若干组内节点组成的节点集合。可形式化地表示为:
ano_group(q,a,I1,I2,…,In),q为查询节点,a为代理节点,Ii为第i个组内节点。
定义9构建匿名组的请求信息Req查询节点广播至周边节点的信息,用以请求协助构建匿名组,可形式化地表示为Req(RID,vec,min),其中RID为请求序列号,是由节点唯一身份标识IP和自身当前请求信息的序号数N(指第N次请求)确定;vec为当前查询节点的速度;min为请求回复信息数,初始时为1。
定义10查询信息Query代理节点(或伪代理节点)代替查询节点向位置服务器发送的查询信息,可形式化地表示为Query(ano_group,Q_Info),其中Q_Info为查询节点输入的查询内容。
定义11(位置更新)当缓存中的List可用时,查询节点使用该List中各个节点的历史位置信息和速度估算当前的位置信息,并构成匿名组,如图3所示,将当前所有节点的新位置坐标近似表示为List内历史位置坐标加上其速度和时间差的乘积的和,即:


图3 位置的近似估算
其中L1(x,y)为某节点历史位置坐标,V为该节点的速度,t为当前时间,t0为List创建时间。
定义12(结果集)结果集R指位置服务器返回给代理节点(或伪代理节点)的查询结果,对应ano_group内k个节点的位置,即生成的k个结果。
2.2 系统框架
本文采用的系统结构如图4所示,由两个部分组成,即位置服务器和移动节点。位置服务器是提供位置服务的服务器,要求有计算功能,可完成大量的定位、查询并返回结果。移动节点是具备定位、计算功能的移动设备。系统主体主要包括两个模块:通信模块及查询模块。

图4 系统框架
在通信模块中,每个移动节点需要支持两种通信方式,一种用于与位置服务提供商之间的通信,包括发起查询及获得查询结果,可使用2G、3G或4G网络;另一种用于用户之间进行自组织的P2P通信,可采用无线局域网(WLAN),例如IEEE 802.11等方式实现[22-23]。显然,无线局域网覆盖范围越广,可搜索到的节点就越多,匿名成功率越高,匿名效果越好。
在查询模块中,移动节点被分为三类:查询节点、组内节点和代理节点(或伪代理节点)。首先,查询节点q构建匿名组,利用匿名组内节点的位置来隐匿q的真实位置,以此实现k-匿名;然后由q从匿名组中选出代理节点(或伪代理节点)A,并将匿名组和查询信息发给A,由A向位置服务器完成查询;最后当A从位置服务器获得结果集R后,会将R返回给q,q通过R获得自己所需要的信息。
2.3 查询过程
移动节点请求一次位置服务就是一次查询过程,包括发起请求、响应阶段、匿名处理和查询处理4个步骤。
步骤1发起请求
当查询节点q需要请求位置服务时,首先查看自身缓存内的List表是否可用,即检查如下两个条件:(1)当前系统时间与上一次参与匿名的时间差t是否小于其自身规定的缓存生存时间;(2)当前节点速度vec与上一次匿名时记录下的节点速度v的类别是否一致(可用classify()函数进行判断,若返回1,表示速度一致,否则表示速度不一致),然后根据检查结果分为以下两种情况进行处理:
(1)q.Lt≥t-t0and classify(q.vec,q.v)==1,此时直接调用自身List表并进行处理(见算法1中第3~6行)。由于此时List表内各个节点的新位置未知,且考虑多数节点是移动的,因此需要计算出各个节点的近似位置来代替新位置,即位置更新(见定义11)。处理完所有的节点后,节点q将自身位置信息隐匿于上述节点的位置信息中,构成一个包含k个节点的匿名组,并直接转向步骤4。
对于List表的生存时间,节点可自行规定它的大小:生存时间越短,新位置估算的越精确,越符合实际情况,但可重复使用的次数越少,再次搜索及构建的可能性增大,增加系统的负荷;生存时间越长,使用List表越多,可减少搜索及构建的次数,减轻运算负载。由于节点移动方向的不确定性,计算所得的新位置可能与真实位置存在少许偏差,会使真实位置模糊化,可更好地保护匿名组内用户的真实位置,但生存时间不可过长,否则也会导致与实际情况差别太大,可能使部分估算的位置信息不合理,降低隐私保护度[24]。
(2)q.Lt<t-t0or classify(q.vec,q.v)!=1,此时需要重新构建匿名组(见算法1中第5~11行)。首先,节点q清空List、初始化构建请求信息Req(RID,vec,min),并广播Req,然后等待周边节点的回应,接收到Req的合适节点最终将返回响应,(响应阶段处理过程具体见步骤2),搜索过程结束。
算法1描述了查询节点请求构建匿名组时的初始处理过程,具体如下:
算法1 Initial processing of query node


步骤2响应阶段
当周边节点 p收到查询节点q发送的构建请求消息时,它检查此请求是否为新的请求,若不是新请求,则抛弃该消息,否则,继续检查速度类别,若q的类别与 p的类别不一致,则抛弃,否则就检查q.Req.min的值,根据q.Req.min的值来返回响应结果(一般情况下,节点 p首先是为了满足自身查询需求而开启位置服务,因此p.List通常不会为空),响应结果用于查询节点构建匿名组:
当q.Req.min==1时,节点 p将随机抽取 p.List内的一条节点信息,即 p.List内某个节点 p′的速度及位置信息(见算法2第4~6行),然后返回给q;
当q.Req.min!=1,则从 p.List中随机抽取 Minist(number(p.List),q.Req.min)(表示 p.List中的节点数值和q.Req.min值相比较,返回最小值)条节点信息,返回给q(见算法2第7~14行)。算法2描述了在构建匿名组时,构建请求信息接收端的处理过程,具体如下:
算法2 Response of receiver

步骤3匿名处理
当返回的节点信息总数不小于k-1时,查询节点q便可从中随机挑选k-1个节点作为匿名组的成员,并将自身信息隐匿其中,形成一个有k个节点的匿名组,并存入List中,其中保存了所有组内节点的位置信息和速度。若返回响应的节点总数小于k-1,说明一次单跳搜索无法满足查询节点q的匿名需求。此时节点q将修改Req中的min值:

其中,q.k为查询节点q的匿名度,k'为首次请求返回的节点个数,并再次向周边节点发出构建请求,以此获得更多周边节点List表中的节点信息来完成此次匿名。若再次返回的节点信息数目仍不足k-1,说明当前周边节点过少,构建匿名组失败,这时节点q需要等待一段时间,待网络覆盖范围内的节点数增多时再重新构建。为防止恶意攻击,查询节点q将List做了如下处理:表内不使用移动节点的真实IP,而是使用编号用以标识区分,这样即使该表被恶意攻击者截获,由于表内采用的编号标识使其无法准确定位到某个用户,为保持通信,查询节点q还需保留组内节点的通信地址与编号的对应关系。构建ano_group时,为了防止将q暴露于表头或表尾,节点的顺序是随机打乱的,如表1所示。
表1 构建完成的匿名组
算法3描述了构建过程中节点q的匿名处理过程:
算法3 Anonymity Processing

步骤4查询处理
经过步骤3后,ano_group已经构成。为防止被恶意攻击者追踪定位,查询节点不直接发起查询,而是在ano_group内随机挑选一个节点作代理节点,由代理节点实现转发查询。不失一般性,查询节点自身也有可能会被选中,因而,在排除自身节点的集合中随机选择代理节点。另外,由于被选中的代理节点可能是周边节点pi(i=1,2,…,n)中List表中存储的节点,而它可能没有与查询节点q建立通信连接,此时,依据定义7,用伪代理节点转发查询请求,也就是说伪代理节点可能未被归入匿名组内,但是充当了代理节点的角色。查询节点将ano_group和Q_Info发送给代理节点(或伪代理节点)a,a再将已被匿名化的查询信息发送给位置服务器。位置服务器接收到查询信息后经过计算返回一系列结果集。代理节点(或伪代理节点)接收到结果集后将其转发给查询节点,查询节点筛选出所需要的结果,整个查询过程结束。由上文可知,不论ano_group是通过步骤1直接获得、还是经过步骤2及步骤3重新构建的,查询用户得到的都是准确的结果。
2.4 算法复杂度及服务质量分析
移动客户端计算能力有限,因此算法不能过于复杂。而直接在查询端生成一组假位置的方法将导致大量的计算开销,且生成的假位置可能受语义攻击[24],因此利用多个真实的接收端协作完成匿名,且使用的是其List表内更接近真实情况的位置信息,以避免语义攻击带来的危害。在整个过程中,发起查询的节点需要选择多个其他节点信息以构成包含k个成员的匿名组,因此查询端的时间复杂度为O()k,k为查询端指定的匿名度;其他节点接收消息,经选择后发出消息,因此接收端的时间复杂度为O()k*,k*为接收端指定的匿名度。
服务质量方面,本文使用隐匿的位置信息向位置服务器发起查询。在缓存中已有的List表不可用时,节点是使用当前真实位置进行构建匿名组并查询,查询结果是精确的;当缓存中已有的List表可用时,将查询节点的真实位置混在一系列虚假位置中进行查询,查询结果也是精确的,因此,在保护用户位置隐私的情况下并未牺牲服务质量。
3 实验及分析
3.1 实验环境
模拟实验采用Java实现,在Q9500 2.83 GHz处理器、2 GB内存的Windows 7平台上运行。移动节点的位置模拟数据由移动数据管理研究业界广泛使用的Thomas Brinkhoff路网数据生成器[25]生成。取城市Oldenburg的交通路网中一块1 000 m×1 000 m的空间作为模拟器的输入,如图5所示,从而生成模拟的移动节点数据集。
图5 城市Oldenburg交通路网及节点的仿真
实验中假设每个移动节点在组内使用半双工无线通道进行通信,带宽为2 Mb/s。当某节点发出通信请求时,需要等待其他成员的回应,若响应节点数不足,它将再次发出请求,若多次请求无果且超过节点可容忍的等待时间,则该节点请求失败。首先使用该模拟器产生1 000个不同节点的运动信息,模拟器各项参数设置如表2所示,为列出的表示为默认值。其中,obj./begin(M)为初始状态下产生的运动对象数,obj./begin(E)则为外部对象数;obj./time(M)为每个时间戳下产生的移动对象数,obj./time(E)则为外部对象数;classe(sM)为移动对象类的个数,classe(sE)则为外部对象类的个数。

表2 参数设置
3.2 结果分析
规定N为当前无线网覆盖范围内的节点总数,n为请求查询的节点数目,即查询节点数,k为节点要求的匿名度,缓存生存时间设置为30 s。接下来将从算法性能和安全性两个方面来评估。
3.2.1 算法性能
本文从匿名成功率、平均响应时间及消息数量三方面分析算法性能,并与文献[12]的CoPrivacy方法做了一定比较。
(1)匿名成功率
匿名成功率是指在查询过程中实现成功匿名的节点在发起查询的节点中所占的比例,计算公式为:匿名成功率=匿名成功节点数/查询节点数。
图6是节点总数相同N=1 000,n和k值不同的情况下P2P AG方法的匿名成功率。随机选择50~200个节点作为查询节点,并在随机的时间戳下发起查询。查询分为四类:k=10、20、30和40,每类执行100次后记录匿名成功的节点数,计算出平均成功率。如图所示,当k和n越小,匿名成功率越高且越稳定,最佳情况几乎达到100%,当k和n增大,匿名成功率将有所降低,但整体成功率仍较高。
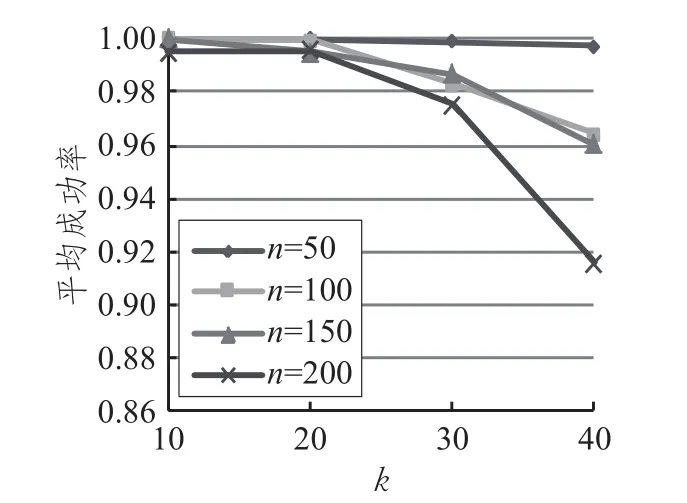
图6 基于不同n和k值的匿名成功率(N=1 000)
图7为k和n相同、N不同时,P2P AG方法与CoPrivacy方法匿名成功率的对比结果。分别产生50~400个节点,随机定义20个节点发起k=10的查询,各自模拟10次查询。从图中可看出,前者在节点总数较少时,匿名成功率较低,这是由于此时符合构建匿名组条件的节点数较少。节点数越多,匿名成功率就越高,当N=400时,已基本达到100%。对于后者,匿名成功率也是随节点总数的增加而增加,但并不是很稳定,当请求查询的次数增加,匿名成功率会降低,特别是节点总数较少时,下降是明显的,这是因为查询次数增多时周边可用的节点会越来越少。而P2P AG方法一直保持着波动不大的匿名成功率,因此比较稳定,且在多数节点同时进行查询时匿名效果较好,符合实际需求。
(2)平均响应时间及消息数量
图8是P2P AG方法关于平均响应时间及消息数量与CoPrivacy方法对比的结果。实验中,设n=20,k=10,节点总数N=50~400。如图8(a)所示,随着节点总数增加,CoPrivacy方法的系统响应时间出现较大增长,而P2P AG方法虽有所增加,但较平缓,未出现很大幅度的增长,说明系统是稳定的。从图8(b)可以看出,随着节点总数增加,两者的平均消息数量会逐渐降低。对CoPrivacy方法而言,节点总数增加使其不需要通过多跳搜索其他节点;而对于P2P AG方法,随着节点总数增加,匿名成功率也会增加,不需要多次广播构建请求消息,且由于缓存的使用,会减少消息数量。但CoPrivacy方法需要搜索节点且实现增量近邻查询,导致大量的通信,因此平均消息数量的总趋势高于P2P AG方法。
3.2.2 安全性分析
本文主要分析一般恶意攻击和连续查询攻击的情况。攻击者感兴趣的信息是节点与其位置信息的对应关系,即确定某一个节点及其所在的位置,因此需要对节点与位置信息之间的关联关系进行保护。
(1)一般恶意攻击
主要考虑两种一般恶意攻击:一是恶意节点是匿名组内节点,获取匿名组信息;二是窃听者监听匿名组内的通信或代理节点与LBS服务器之间的通信。
由于构建匿名组时组内节点和代理节点的选择是随机的,即使存在恶意节点,其被选中的可能性也很小。若整个区域内的响应节点数为p,匿名度为k(k<p),恶意节点数为c(一般情况下,参与构建的用户都是诚实或半诚实的,因此可假设c≪p),则整个过程中查询节点选中恶意节点的概率为:


图7 不同节点总数的匿名成功率(n=20,k=10)

图8 平均响应时间及消息数量(n=20,k=10)
当c远小于 p时,这个概率值将很小。此外,即使恶意节点是组内节点,它只能获取查询节点的速度类别,并不能获取其位置信息。只有恶意节点是代理节点时,才会获取一张包括组内节点信息的ano_group。但是,ano_group中的用户名是使用编号进行隐匿的,即使恶意节点获得了ano_group,只能得到一系列位置信息和速度信息,是无法将位置信息与某个确定的用户关联起来的,即保护了用户与其位置信息的关联关系;另一方面,代理节点充当的是查询节点与位置服务器间的中间件,且每次请求查询时都会随机选出一个用来实现转发查询,即便知晓谁是查询节点,但这是在查询节点进行搜索周边节点时就已经知晓的,而搜索过程中查询节点广播的Req只包括RID、vec和min,并没有确切的位置信息,因此查询节点的位置信息并未暴露。
若恶意节点伪装成查询节点期望获得大量其他节点的信息。然而在算法2中,其他节点返回的响应信息是其List内的某一条节点信息,即并不是自身的信息,即使恶意节点伪装成查询节点获取了这些信息,也无法准确判断与某个节点的对应关系。同理,若窃听者截获到查询节点发送给代理节点的ano_group或代理节点发送至LBS服务器的查询信息,也是无法将位置信息与确切的用户IP关联起来,保护了匿名组内节点的隐私。
通过抵御以上两类恶意攻击,P2P AG算法便可避免受到传统k-匿名方法中的多数攻击[26]。例如对于区域密度攻击:当查询节点周边的用户较多时构建的匿名区域较小,导致直接缩小查询用户的真实位置范围,增加了位置暴露的风险。而P2P AG算法构建的匿名组内的位置信息是真实信息和虚假信息的混合,攻击者并不能有效定位到查询用户的真实位置范围,因此可较好地抵御区域密度攻击。
(2)连续查询攻击
此类攻击主要由查询节点在连续查询周期内匿名集合的频繁变化引起。一种简单的解决方案就是保持查询节点的匿名集合尽可能的不变[27],然而这会使匿名区域随集合内成员的分散移动而逐渐增大或减小。若匿名区域过大,则降低了服务质量;若匿名区域过小,则较容易泄露隐私。本文舍弃匿名区域,并使用缓存,使匿名组尽量保持不变。假设缓存中的List生存时间较长,连续的几次查询中都将使用同一组节点构成的匿名组,使得攻击者无法确定真实的查询节点。为尽可能保证节点不会出现大量的添加、删除且保持组内通信顺畅,将速度分类,组内节点属于同一个类。由于节点沿着道路移动,短时间内发生类别变化的可能性不大,ano_group将保持不变,当发起连续查询时,即使攻击者截获了ano_group,仍无法准确确定查询节点及其位置信息。
图9说明了保持匿名组不变的可行性。实验中记录了节点总数N=1 000时在不同的情况下使用缓存所占成功匿名节点数的比例。分别随机使100、200、300个节点发出匿名度k=20~100的查询。可以看出:当查询节点数较多或要求匿名度较大时,使用缓存的可能性较大,因此占比例较大,符合实际应用,可有效满足隐私需求且节省系统开销。

图9 缓存使用率(N=1 000)
由于多数位置隐私保护方法的研究重点各异,因此本文与用户协作的位置隐私保护经典算法P2P Spatial Cloaking[6](简称P2P SC)做比较。若在多个匿名度为k的匿名集合内连续出现的节点个数为m,则查询节点被暴露的概率为:

对于P2P SC算法,当某个或某几个成员在多个匿名区域内连续出现,则说明查询节点必是该成员或存在于这多个成员中,使算法无法达到位置k-匿名,增大暴露的可能性,即受到连续查询攻击的威胁。而P2P AG利用缓存,尽可能使连续构建的匿名组不变,降低了暴露的可能性。实验使40个节点在连续的多个时间戳t内发出查询请求,匿名度k=10,匿名组生存时间不小于1个时间戳,记录节点暴露率,并计算平均值。结果如图10所示,P2P SC的查询节点暴露率基本高于P2P AG,且前者随连续时间戳的增加而大幅增长。考虑到P2P AG会在节点速度类别发生改变时构建新的匿名组,为了模糊新旧匿名组间的联系,算法将组内的用户名用编号代替,且随机产生顺序,使攻击者无法识别出两次查询是否为同一个查询节点发出,即一次构建,多次使用,再次构建,全组更名,以更好地抵御连续查询攻击。因此P2P AG方法在连续查询时的安全性优于P2P SC方法。

图10 安全性比较(N=1 000,n=40,k=10)
4 结束语
大部分传统的位置隐私保护方法是基于第三方可信中心服务器结构而建立的,因此必然导致中心服务器成为整个系统性能的瓶颈。本文提出一种在对等通信辅助下可抗攻击的位置隐私保护方法,该方法通过多用户协作实现位置k-匿名,未生成匿名区域,避免传统k-匿名模型常见的攻击。考虑用户的移动性,引入速度作为构建匿名组的要素之一,组内成员保持模糊的连通性,以此解决组内成员不可信问题,并可抵御一般恶意攻击。同时,加入了缓存机制,增加匿名组的可重用性,使匿名组在一段时间内保持不变,以此抵御连续查询攻击,并可减少系统开销。该方法保证了用户的隐私,在降低系统开销的基础上满足了匿名需求,并能够较好地抵御一般性恶意攻击和连续查询攻击。由于用户协作的模式需要建立在用户相对集中且用户数多的基础上,当周围可搜索到的用户较少或可协助进行查询的用户较少时,该方法的实现将可能会受到一定影响。因此,该方法较适用于用户相对集中且足够多的密集区域,未来的工作可以在松散用户或少量用户上展开。
参考文献:
[1]Gruteser M,Grunwald D.Anonymous usage of locationbased services through spatial and temporal cloaking[C]//Proceedings of the 1st International Conference on Mobile Systems,Applications and Services,2003:31-42.
[2]Gedik B,Liu L.Protecting location privacy with personalized k-anonymity:Architecture and algorithms[J].IEEE Transactions on Mobile Computing,2008,7(1):1-18.
[3]Xu T,Cai Y.Feeling-based location privacy protection for location-based services[C]//ACM Conference on Computer and Communications Security(CCS 2009),Chicago,Illinois,USA,November 2009:348-357.
[4]Wang Y,Xu D,He X,et al.L2P2:Location-aware location privacy protection for location-based services[J].Proceedings-IEEE INFOCOM,2012,131(5):1996-2004.
[5]Kido H,Yanagisawa Y,Satoh T.An anonymous communication technique using dummies for location-based services[C]//ProceedingsInternationalConferenceon Pervasive Services,2005(ICPS’05),2005:88-97.
[6]Chow C Y.A peer-to-peer spatial cloaking algorithm for anonymous location-based service[C]//Proceedings of the 14th Annual ACM International Symposium on Advances in Geographic Information Systems,2006:171-178.
[7]Chow C Y,Mokbel M F,Liu X.Spatial cloaking for anonymous location-based services in mobile peer-to-peer environments[J].GeoInformatica,2011,15(2):351-380.
[8]Pingley A,Zhang N,Fu X,et al.Protection of query privacy for continuous location based services[C]//IEEE INFOCOM,2011:1710-1718.
[9]Wernke M,Skvortsov P,Dürr F,et al.A classification of location privacy attacks and approaches[J].Personal and Ubiquitous Computing,2014,18(1):163-175.
[10]Yiu M L,Jensen C S,Huang X,et al.Spacetwist:Managing the trade-offs among location privacy,query performance,and query accuracy in mobile services[C]//IEEE International Conference on Data Engineering,2008:366-375.
[11]Gong Z,Sun G Z,Xie X.Protecting privacy in locationbased services using K-anonymity without cloaked region[C]//2010 Eleventh International Conference on Mobile Data Management(MDM),2010:366-371.
[12]黄毅,霍峥,孟小峰.CoPrivacy:一种用户协作无匿名区域的位置隐私保护方法[J].计算机学报,2011,34(10):1976-1985.
[13]张国平,樊兴,唐明,等.面向LBS应用的隐私保护模型[J].华中科技大学学报:自然科学版,2010(9):45-49.
[14]杨松涛,马春光,周长利.面向LBS的隐私保护模型及方案[J].通信学报,2014,35(8):116-124.
[15]徐建,黄孝喜,郭鸣,等.动态P2P网络中基于匿名链的位置隐私保护[J].浙江大学学报:工学版,2012,46(4):712-718.
[16]Dewri R,Ray I,Whitley D.Query m-invariance:Preventing query disclosures in continuous location-based services[C]//2010 Eleventh International Conference on Mobile Data Management(MDM),2010:95-104.
[17]Chen X,Pang J.Exploring dependency for query privacy protection in location-based services[C]//Proceedings of the Third ACM Conference on Data and Application Security and Privacy,2013:37-48.
[18]Ghinita G,Kalnis P,Khoshgozaran A,et al.Private queries in location based services:Anonymizers are not necessary[C]//Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data,2008:121-132.
[19]Papadopoulos S,Bakiras S,Papadias D.Nearest neighbor search with strong location privacy[J].PVLDB,2010,3(1):619-629.
[20]Khoshgozaran A,Shahabi C,Shirani-Mehr H.Location privacy:Going beyond K-anonymity,cloaking and anonymizers[J].Knowledge and Information Systems,2011,26(3):435-465.
[21]张建明,赵玉娟,江浩斌,等.车辆自组网的位置隐私保护技术研究[J].通信学报,2012(8):180-189.
[22]Chow C Y,Leong H V,Chan A T S.Distributed groupbased cooperative caching in a mobile broadcast environment[C]//Proceedings of the 6th International Conference on Mobile Data Management,2005:97-106.
[23]Papadopouli M,Schulzrinne H.Effects of power conservation,wireless coverage and cooperation on data dissemination among mobile devices[C]//Proceedings of the 2nd ACM International Symposium on Mobile Ad Hoc Networking&Computing,2001:117-127.
[24]Brinkhoff T.A framework for generating network-based moving objects[J].GeoInformatica,2002,6(2):153-180.
[25]Damiani M L,Bertino E,Silvestri C.The PROBE framework for the personalized cloaking of private locations[J].Transactions on Data Privacy,2010,3(2):123-148.
[26]司超.基于Casper的位置隐私保护模型与算法研究[D].广州:华南理工大学,2012.
[27]Chow C Y,Mokbel M F.Enabling private continuous queries for revealed user locations[M]//Advances in Spatial and Temporal Databases.Berlin Heidelberg:Springer,2007:258-275.
猜你喜欢
当代水产(2022年6期)2022-06-29
中国生殖健康(2020年8期)2021-01-18
课程教育研究(2020年7期)2020-04-21
趣味(数学)(2018年12期)2018-12-29
中国生殖健康(2018年3期)2018-11-06
现代营销(创富信息版)(2018年8期)2018-09-08
现代教育科学·中学教师(2015年2期)2015-10-21
现代教育科学·中学教师(2015年3期)2015-10-21
海峡姐妹(2015年5期)2015-02-27
天津市教科院学报(2015年2期)2015-02-13
