
基于机器视觉检测印刷码的改进模板匹配算法研究
2018-05-02 03:42钱俞好李少辉
机电工程 2018年4期
钱俞好,周 军,田 胜,李少辉
(河海大学 机电工程学院,江苏 常州 213022)
0 引 言
视觉检测是机器视觉中的一个重要领域,涉及到计算机、图像处理、模式识别等多个领域。近几年随着印刷产业的快速发展,机器视觉检测技术逐渐在印刷检测中得到广泛应用,检测识别结果的准确性以及识别效率已成为关键性的衡量标准[1]。
国外开始对字符识别的技术的研究相对较早,在理论和产品上都比较成熟。俄罗斯的ABBYY Finereader以及美国的Nuance Omnipage Professional都是当今世界上比较出色的OCR识别检测系统软件,支持多国语言,且识别率都能达到99%以上。我国于上世纪70年代末开始对OCR技术方面的研究,经过近30年的努力已取得了重大进展。现已出现一些性能比较出众的产品成果,如清华TH-OCR97综合集成汉字识别系统,对中等质量的样本识别对象,识别率能够达到98%或者更高。字符识别常用的算法有模板匹配、KNN、SVM、神经网络等。
本研究将基于模板匹配算法,提出一种改进的模板匹配算法。
1 传统模板匹配算法
模板匹配是模式识别中的一个基本方法,属于一种统计思想的识别算法[2]。该方法原理简单、识别过程直观、计算方便,因此得到较为普遍的应用。字符模板匹配目前采用简单的二值图像模板,0表示黑(背景),1表示白(目标)[3]。原匹配图像S、模板T、覆盖的目标区域Sij,如图1所示。
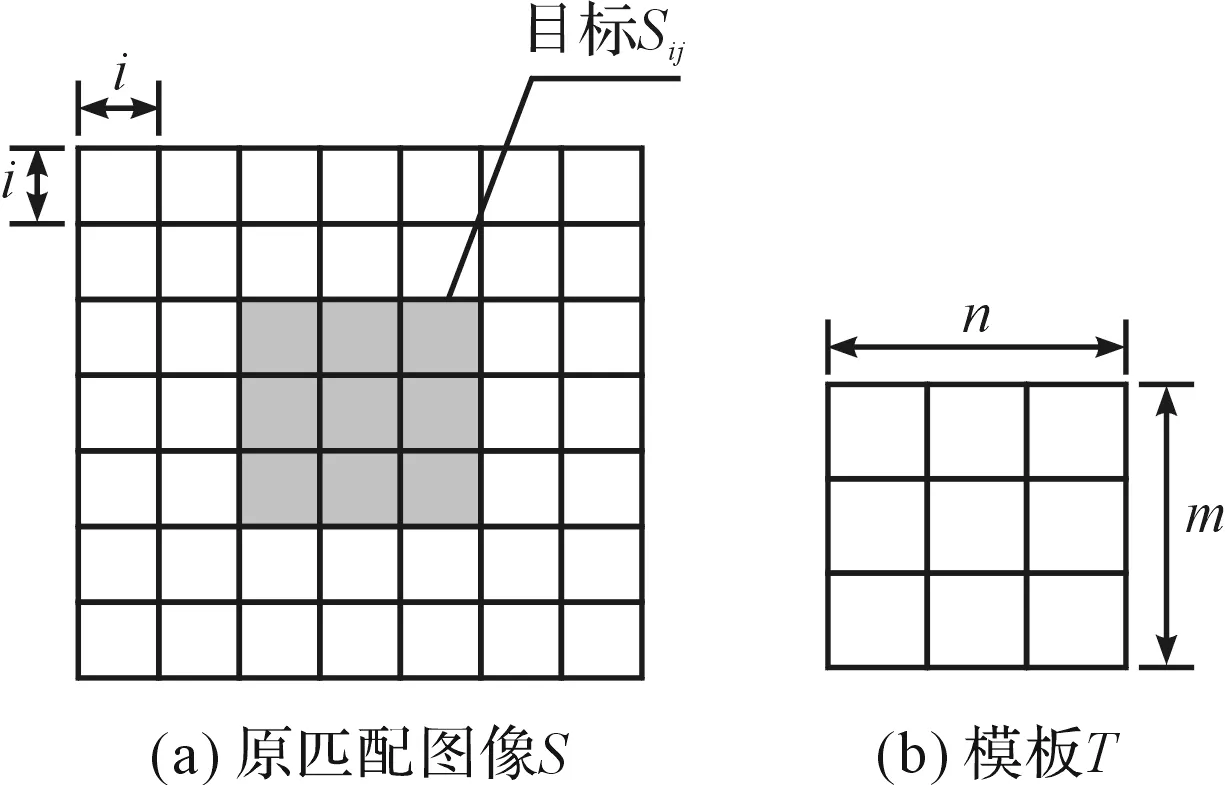
图1 原匹配图S及模板T
模板T(m,n)和所覆盖目标区域Sij(i,j)之间的相似性D(i,j)的数学表达式为:
(1)
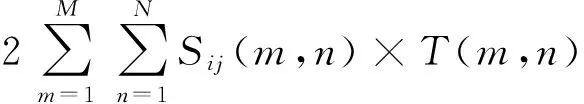
(2)
本研究计算目标图像与所有的模板库中的相关系数,选取系数中最大的对应的模板图像即为识别内容。
1.1 图像的采集及阈值分割
按经过多次实验发现,在一般条件下,选取自然光源的阴面采集图像所呈现的效果最为理想,采集瓶盖原始图像如图2所示。

图2 采集瓶盖原始图像
阈值分割法是运用最为广泛的图像分割技术。常用的阈值分割算法有以下几种:迭代法、最大类间误差法、最大熵法等[4],该实验着重研究基于最大类间误差的阈值分割法。
根据图像的灰度特性,将图像分为背景和目标两个部分,运用最大类间误差阈值算法的步骤:
(1)计算图像中每个灰度值的概率Pi;
(2)通过计算目标和背景的分布概率ω1、ω0以及各自的平均灰度值μ1、μ0来计算方差σ02、σ12;
σ02、σ03的计算公式如下:
(3)
式中:K—背景像素集合的最大容量。
(4)
式中:L—目标像素集合的最大容量。
(3)计算每个灰度值的类间差;
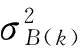
(5)
式中:μT=(μ0+μ1)/2,k=0,1。
(4)则所有类间差中最大的所对应的灰度值即为阈值。
本研究利用Matlab中提供的阈值分割法的函数im2bw()进行分割,效果如图3所示。

图3 阈值分割图
1.2 图像增强
图像增强技术是进行正确检测识别字符的必要保证[5]。目标字符主要位于图像中的圆形区域内,在图像处理中常用Hough变换的圆检测的方法[6]。
圆检测区域效果如图4所示。

图4 圆检测目标图像
由图4可以看出:通过圆检测出来的图像包含了字符和部分的噪声点。常用的去噪滤波方法有高斯滤波法、均值滤波发、中值滤波发、双边滤波法等[7]。在Matlab软件环境中分别用这几种滤波方法对图像进行处理,效果如图5所示。
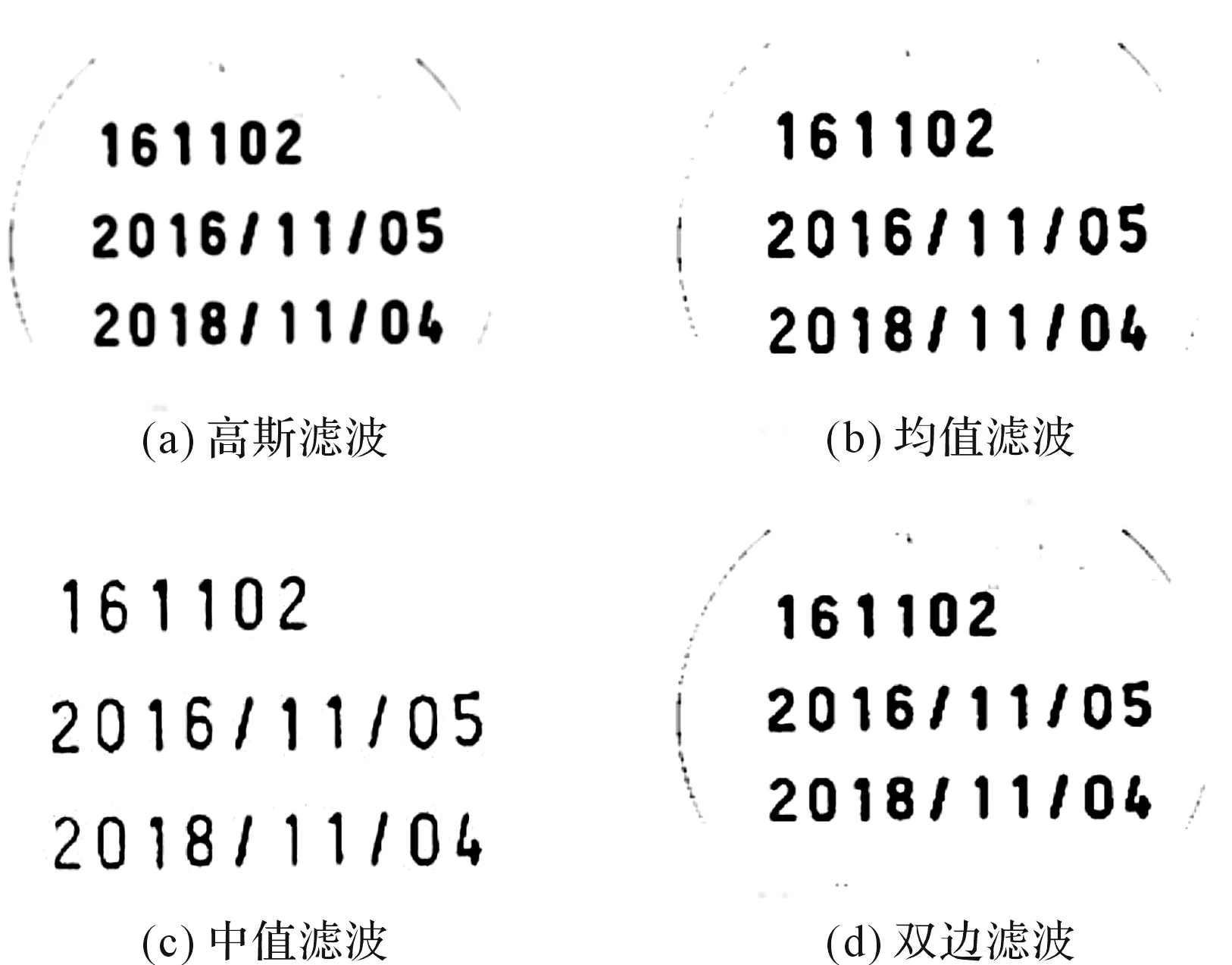
图5 几种滤波方法效果图
从以上4种滤波方式可以看出:相对于其他3种方法,中值滤波在该实验中有更好的图像增强效果。
1.3 字符分割
常用的字符分割方法有CFS分割、投影分割、基于最小外接矩形框分割等[8],本文中采用的基于最小外接矩形及连通区域相结合的分割法。
(1)通过最小外接法选定出包含全部字符的最小矩阵区域;
最小外界矩形框如图6所示。

图6 最小外界矩形框
(2)遍历图中的最小矩形区域,去除像素值之和为0的行,得到所有的有效字符区域条;有效字符条区域如图7所示。
图7 有效字符条区域
(3)通过Matlab中提供的bwlabel()函数遍历图7中的每一个有效字符区域,确定出每一个连通字符区域,即为每一个需要待分割的字符。
由于该实验中的字符之间的区分度较好,没有粘连现象,字符之间的分割结果较满意。
分割结果图如图8所示。
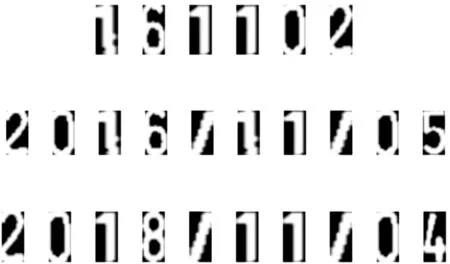
图8 字符分割图
2 改进模板匹配算法
积分图像是一种快速计算图像目标矩形区域内像素之和的数据处理方法,在图像滤波二值化图像处理较为常见[9]。
积分图像的数学公式为:
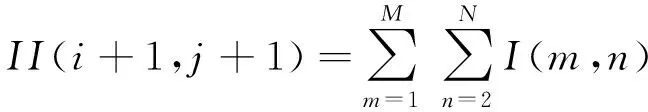
(6)
式中:I—原始图像;II—积分图象。
某一图像区域的积分图像示意图如图9所示。
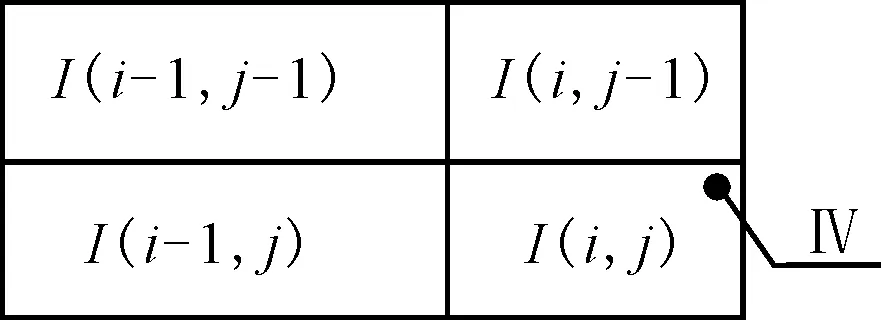
图9 积分图像用法示意图
则区域Ⅳ的像素值之和为:
IⅣ=I(i,j)+I(i-1,j-1)-I(i,j-1)-I(i-1,j)
(7)
要计算任意区域的像素和,通过3次加减法对一次内存读取4个区域的像素和进行运算,从而避免了传统方法中逐点累加的繁琐求和过程。一幅大小为N×M的二值图中去统计K个区域内的像素和,时间复杂度为K×(N×M-1),内存读取开销为K×N×M。在二值图的基础上利用积分图像的思想进行后续计算,时间复杂度和内存读取开销仅为3×K和4×K,理论上大大缩短了图像处理的时间[10]。
2.1 积分图像与模板的快速匹配
模板匹配中一般以原图像与模板之间的相关系数来衡量,相关系数表示原图像向量与模板图像向量之间的夹角。设Amn和Bmn为积分图像和模板图像在标准处理后的二值矩阵,μ0、μ1和σ02、σ12分别为积分图像和模板图像在标准处理后的均值和方差,则相关系数r(A,B)可用下式来表示:
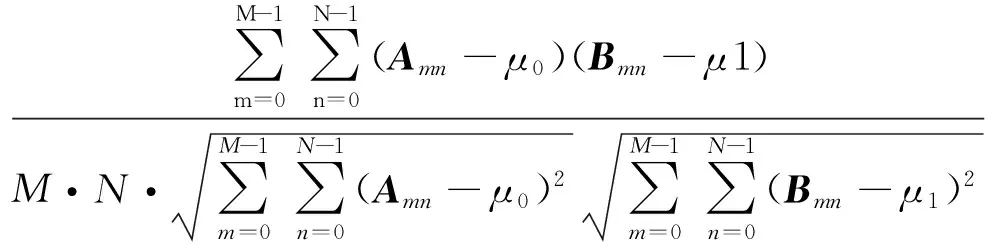
(8)
对上式进行近似处理:
(9)
比较上述两式,改进后的式(9)在实现过程中只需遍历一次目标图像和模板图像,计算得出均差、方差,计算开销明显减小。
3 实验结果
3.1 两种方式结果比较
原分割后字符图像经过归一化后的大小均为24×42,模板库由0~9这10个数字的模板组成,每一个数字搜集了50个模板,大小均为24×42。对0~9这10个数字分别在传统模板匹配算法与改进的图像积分模板匹配算法下进行60组识别实验,传统模板匹配算法的识别结果如表1所示。
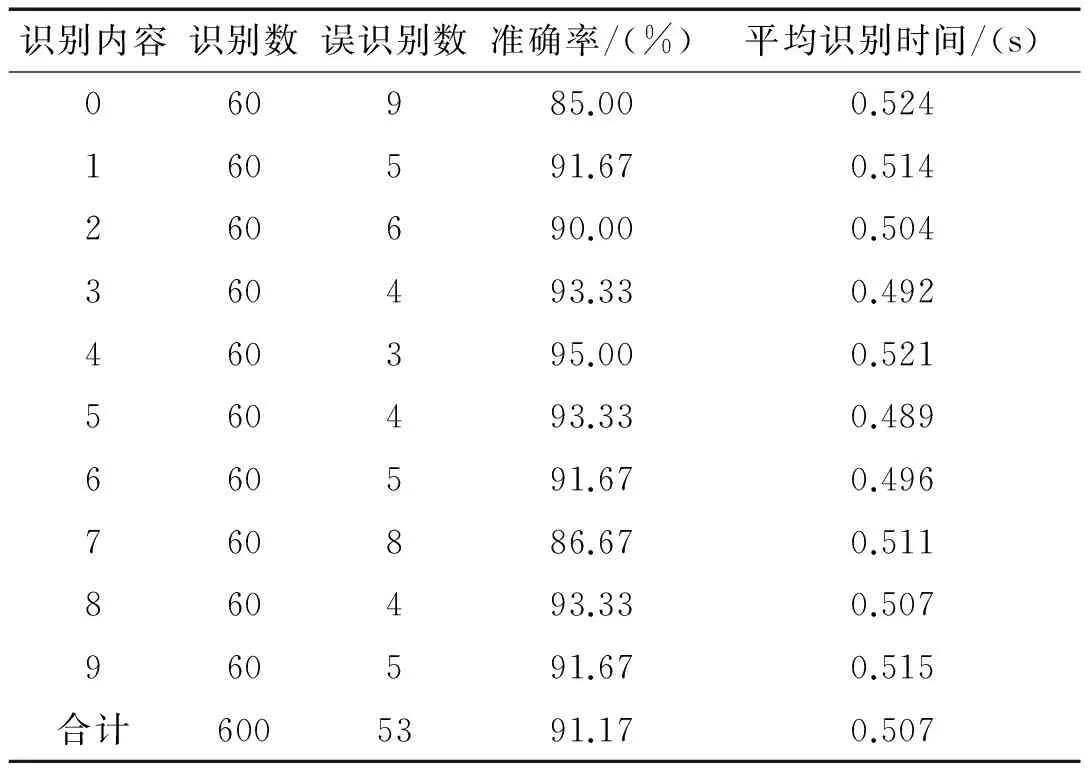
表1 传统模板匹配识别结果
改进之后的模板匹配算法的识别结果如表2所示。
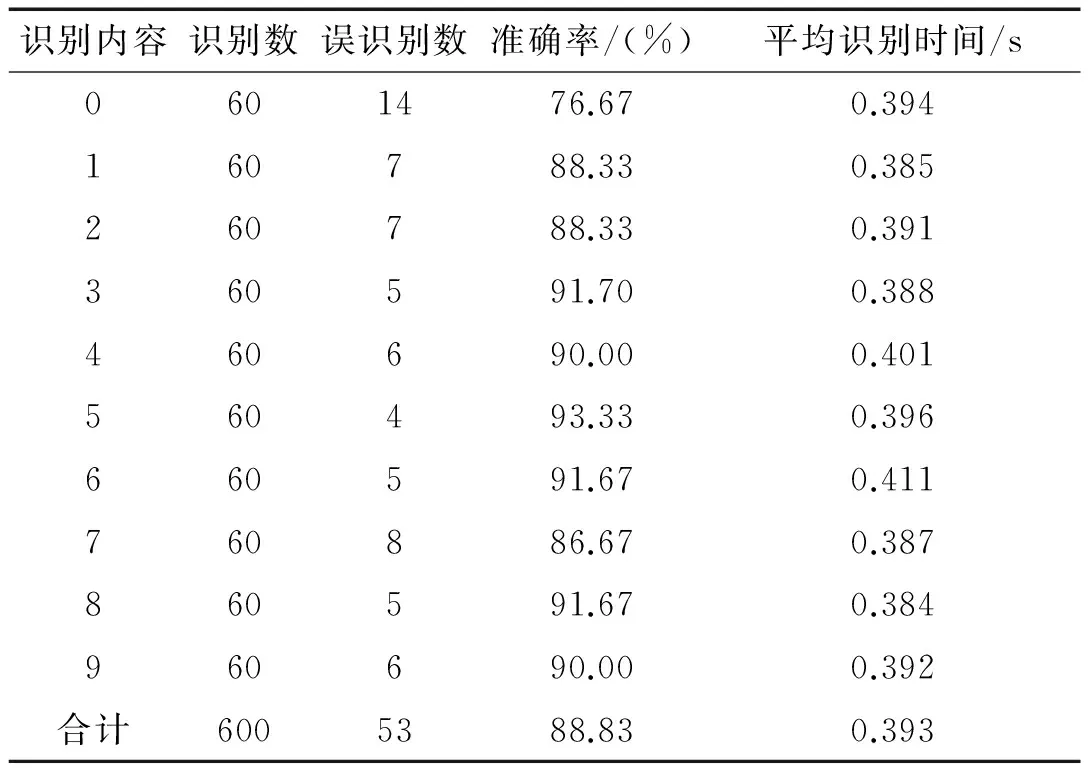
表2 改进模板匹配识别结果
两种方式的比较结果,如表3所示。

表3 两种方式的比较结果
从表1和表2的结果可以看出:总体上在两种匹配方式下除了个别字符,如“0”和“7”的识别率与平均识别率相差较大,大部分的字符识别率能在90%以上;从表3可以得出:改进模板匹配算法的识别率略低于传统模匹算法,但是在识别速度比传统方法提高了20%多。从张宏涛、龙翀,汤茂斌,谢渝平等人做的字符识别的结果来看,在满足当今普遍研究结果的识别率在83%到94%的范围条件下,本文提出的改进模板匹配算法能够在满足识别率在平均范围内的前提下,提高了识别检测的速度。
3.2 瓶盖印刷码识别结果
笔者利用本文提出的基于图像积分的改进模板匹配算法,从结果来看能够正确地识别检测出瓶盖印刷码中的所有字符,验证该算法用来检测瓶盖印刷码字符的可行性。
4 结束语
本研究介绍了一种基于图像积分的改进模板匹配的算法,并与传统模板匹配算法进行了比较,结果表明:改进之后的匹配算法在识别速率上能够提高20%以上,为以后的研究提供了重要参考依据。
但该算法存在着个别字符识别结果不理想的情况,在下一阶段,需要从识别算法上加以完善,在保证识别速度的同时,提高识别的准确率,减小实验误差。
参考文献(References):
[1] 张宏涛,龙 翀,朱小燕,等.印刷体汉字识别后处理方法的研究[J].中文信息学报,2009,23(6):67-71.
[2] 刘云峰,杨小冈,齐乃新,等.基于模板匹配的前视自动目标识别模型[J].兵工自动化,2016,35(7):4-6.
[3] 李新良.模式识别理论的研究与应用[J].北京电子科技学院学报,2011,19(4):75-79.
[4] 刘 佳,傅卫平,王 雯,李 娜.基于改进SIFT算法的图像匹配[J].仪器仪表学报,2013,34(5):47-51.
[5] 汤茂斌,谢渝平,李就好.基于神经网络算法的字符识别研究[J].微电子学与计算机,2009,26(8):91-93.
[6] 张勇红.基于霍夫变换的铭牌OCR图像旋转矫正方法[J].电测与仪表,2015,52(8):125-128.
[7] 戴宪策,刘昌锦.模板匹配的一种快速算法[J].信息科学与控制工程,2016,36(1):23-25.
[8] TAVAKOL A, SOLTANIAN M. Fast feature-based template matching, based on efficient keypoint extraction[J].AdvancedMaterialsResearchr,2012,17(21):798-802.
[9] WANG Y W, LIANG H,LI J,et al. An improved difference template matching algorithm[J].AdvancedMaterialsResearch,2012,22(13):117-121.
[10] JING J, DAUWELS J, RAKTHANMANON T, et al. Rapid annotation of interictal epileptiform discharges via template matching under dynamic time warping[J].Elsevier,2016,33(4):114-119.
猜你喜欢
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
数字通信世界(2019年3期)2019-04-19
中国交通信息化(2018年3期)2018-06-13
中国交通信息化(2016年2期)2016-06-06
火控雷达技术(2016年3期)2016-02-06
海军航空大学学报(2015年1期)2015-11-11
