
一种CPU-GPU协同计算的三维地形实时渲染算法
2018-04-13 10:03郭向坤刘继申王鸿亮
小型微型计算机系统 2018年4期
郭向坤,林 浒,刘继申,王鸿亮
1(中国科学院大学,北京 100049) 2(中国科学院 沈阳计算技术研究所,沈阳 110168) E-mail:guoxiangkun@sict.ac.cn
1 引 言
大规模三维地形场景的实时渲染是虚拟现实领域研究的热点,广泛应用于战场环境仿真、计算机游戏及虚拟现实等领域.三维地形场景绘制综合了数据采集、网格简化、海量数据处理、纹理映射和实时渲染等多项技术.普通计算机和图形处理器的性能无法满足大规模地形场景的实时渲染的要求.在复杂的地形场景中,模拟出高度逼真的三维地形效果是计算机图形学领域研究的难点问题.
对大规模地形数据的实时渲染,当前的研究热点主要集中在大规模数据块的数据调度、网格简化、裂缝消除和视域裁剪等方面.在网格简化方法中,细节层次 (Level Of Detail,LOD) 模型是近年来学者们的重点研究方向.对多分辨率LOD模型的研究早期多是面向CPU顶点级LOD方法[1-3]和基于块的批LOD方法[4-6],对于串行执行的CPU来说执行此操作需要消耗较长的处理时间;在GPU中渲染场景时,CPU和GPU之间频繁通信也消耗大量时间[7].近年来,凭借GPU的高浮点计算能力、高度并行处理和可编程能力的提高,国内外一些学者利用OpenGL中的着色器在GPU上进行数据块的网格简化[7,8].这类方法可有效减轻CPU处理数据的压力,但是把非图形的大量计算任务交给OpenGL着色器处理,编程实现比较困难且具有局限性.随着GPGPU技术迅速发展,涌现出一些GPU编程平台,例如CUDA和OpenCL.在OpenCL平台上可以对GPU进行编程完成通用的数据处理,可减轻CPU的计算负载.
本文提出一种基于OpenCL的CPU-GPU协同计算的三维地形实时绘制框架.将大规模地形块进行数据分块,在CPU中进行必要的预处理,通过多级缓冲机制加载数据块和视域裁剪技术,各个地形块在GPU流处理器中并行简化和批量渲染,能够有效提高场景渲染的帧率和减轻CPU工作负载.
2 多分辨率的细节层次模型
2.1 构建四叉树结构的LOD模型
在本文中,我们采用高度图作为地形数据,假设每块高度图的大小都是(2n+1)×(2n+1),采用基于视点相关和局部地形粗糙程度相结合的误差评价准则来自顶向下的构建多分辨率四叉树.为了能够把四叉树的计算过程从CPU移到GPU中,将高度图地形块直接加载到显存中,保存为二维的图像对象或纹理对象,在OpenGL或OpenCL中可直接访问这些数据对象.
图1(a)为9×9地形块,可细分成3层LOD,每个空心圆代表地形块中的一个顶点,顶点等间距的规则分布.图1b为地形块的四叉树简化过程,以每个地形块的中心顶点表示地形块,实心圆代表需要向下细分,空心圆表示不需要继续细分.本文采用地形块中心点到视点的距离和局部地形粗糙度相结合的准则[9,10]来确定节点是否需要细分.其中每个非叶子节点都有四个子节点,子节点将父节点的地形块均等细分成4部分,自上而下细节层次逐渐提高,地形表面由粗到细而逐渐细化.
数据块内的数据集可用公式(1)表示为:
pl={yi,j|yi,j=H(x,z),0≤i,j≤psize,
x=pxoff+2l·i,y=pzoff+2l·j}
(1)
公式(1)中H(x,z)为高程表示函数,x、z为采样顶点的空间物体坐标,yi,j为顶点坐标对应的高程值,pxoff、pzoff为地形块内的层内偏移量,i、j为块内网格坐标,2l为采样空间间隔.
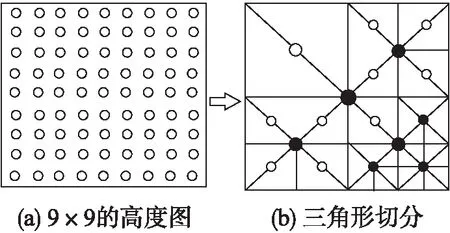
图1 四叉树构建过程Fig.1 Process of quad tree
2.2 多级缓冲的数据块调度
由于大规模或超大规模地形块数量巨大,不可能把所有地形数据全部调入内存,本文采用动态调度技术把一些必要的数据块调入内存,把需要渲染的数据块调入GPU显存中.由于外存到内存的数据传输速度远低于内存到显存的传输速度,需要在内存中建立一个缓冲区,作为装载高度图和纹理图像的二级缓冲区.根据漫游时视点的当前位置和运动方向,采用动态加载地形块到缓冲区中[11].数据块调度原理如图2所示.
图2(a)中V为当前视点,以V为中心的四个数据块为一级缓冲区域Cache1,以一级缓冲区域为中心向周围各扩展一个数据块,即为二级缓冲区Cache2,箭头的方向为视点将要移动的方向,随着视点的移动,同时要更新一级和二级缓冲区的数据块.图2(b)为因视点的移动而更新加载的地形块.每个地形块的大小要适中,如果过大,数据块调度到缓冲区的时间就会过长,当视点移动较快时,引起数据块不能及时加载到内存;若过小,会导致数据块的频繁调度,增加I/O数据传输的负担,则缓冲效果不明显.本文采用513×513大小的数据块.

图2 数据块调度原理图Fig.2 Data block scheduling
2.3 裂缝消除
对于两个相邻数据块的LOD模型,如果二者的分辨率层级不同,如果不进行特殊处理可能会出现裂缝.图3(a)中的阴影部分就是裂缝,p1p2为两个不同LOD模型的相邻公共边,p3为顶点p1和p2中点的高程采样点.假设y1、y2和y3为采样点p1、p2和p3的高程值,由公式(1)可得:
y1=H(x1,z1),y2=H(x2,z2),y3=H(x3,z3)
(2)
如果公式(2)成立,Δp1p2p3就是会产生裂缝.为了方便处理裂缝,本文设定相邻地形块的层级差不能超过1,裂缝处理过程如图3(b)所示.通过检测相邻的数据块的分辨率层级,如果相邻块层级比当前低,则删除相应的顶点,否则,相邻块间就不会产生裂缝而会正常渲染.数学表示如公式(3)所示.
(3)
其中,l,ln为当前地形块及相邻地形块的细节层级,如果当前地形块细节层级比相邻块高,则将φ(l,ln)的值设为1表示需要删除顶点,否则,置为0表示不做任何处理.

图3 裂缝消除Fig.3 Crack eliminating
对于每个地形块,可能会产生上、下、左和右四个方向的裂缝.当四叉树结构构建完成之后,真正渲染地形之前,利用GPU实现地形块的裂缝并行检测和消除.在四叉树构建过程中,采用二维矩阵标记地形块的LOD模型层级,则可以根据这个二维矩阵来检测相邻地形块的细节层级,采用这种方法实现四个方向的裂缝处理.
2.4 LOD层次间的平滑过渡原理
不同LOD层次的变换过程中,由于某些顶点的突然出现或消失,视觉上会产生顶点的突跳现象.Morphing平滑过渡思想是解决突跳现象的典型方法[2,6,12],其通过两个LOD层次顶点属性的平滑插值使一个LOD层级过渡到另一个层级.图4为针对顶点位置B实现平滑插值的过程,过渡过程中顶点B′的位置变化如公式(4)所示:
B′=v·B+(1-v)·B0v∈[0,1]
(4)
其中B0=(L+R)/2代表较低细节LOD模型中顶点位置,B代表较高细节LOD模型顶点位置,v代表过渡权值.

图4 Morphing原理示意图Fig.4 Morphing principle
为了便于计算,令ΔB=B-B0,代表两个相邻LOD模型中过渡顶点的高度差.令ω=1-v为新的过渡权值,则可将公式(4)改写为公式(5):
B′=B-ω·ΔBω∈[0,1]
(5)
过渡权值ω与地形块到当前视点的距离相关,在某个距离范围内实现相邻LOD模型的平滑切换.ω权值的计算可由公式(6),得:
(6)
Dmin和Dmax分别表示平滑过渡过程中地形块到当前视点的最小距离和最大距离,当D∈[Dmin,Dmax]实现顶点B的平滑过渡,当D∉[Dmin,Dmax]时,此时ω等于0或1,不进行平滑过渡插值.
3 基于GPU的并行构建LOD模型
3.1 CPU-GPU协同构建LOD模型
在四叉树结构的地形块简化模型方面,国内外学者把大量计算任务交给CPU处理,GPU只负责地形网格的渲染任务.近年来,GPU作为独立的硬件处理器,其计算性能飞速提高,使GPU浮点计算能力远远超过CPU,而且GPU还具有高数据带宽和高度并行处理等显著优势;随着GPU的可编程性不断增强,涌现出一些主流的GPU编程平台,例如OpenCL和CUDA.OpenCL是一个面向异构系统的免费的、开放的并行编程标准,可以支持对CPU、GPU和DSP等处理器进行编程.OpenCL同时支持AMD和NVIDIA等不同厂商的GPU编程.随着OpenCL开发平台的逐渐成熟,更多的硬件支持OpenCL标准对GPU进行通用计算会更加容易.OpenCL编程平台可以发挥CPU和GPU各自的优势提高系统的整体性能.
本文提出CPU-GPU协同计算的大规模地形实时渲染的算法模型,该模型的原理图如图5所示.根据视点位置,利用CPU实时加载相应的数据块到内存中,并把将要渲染的地形块加载到GPU的显存中;然后,在OpenCL平台上,利用GPU流处理器并行构建多分辨率的LOD模型.LOD模型构建完成之后,紧接着就进入地形的渲染阶段.为了避免地形中裂缝的产生和消除地表的突跳现象,四叉树构建完成后进行裂缝处理和顶点平滑过渡.最后,把需要渲染的顶点数据送往OpenGL的着色器中完成地形绘制.
根据视点位置和局部地表粗糙度作为综合评价准则[13,14],通过在GPU中执行OpenCL内核函数来并行构建地形块的四叉树结构,形成多分辨率的LOD模型.其中GPU流处理器独立构建地形块的四叉树结构,并采用二维矩阵标记地形块的四叉树,这样能够利用GPU进行裂缝消除和平滑过渡.本算法将大量的计算都交给GPU处理,CPU只负责少量的计算,大大减轻CPU的负担.
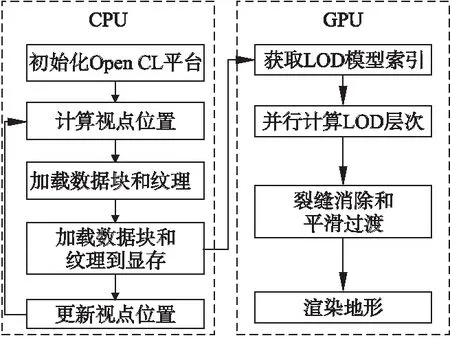
图5 CPU-GPU协同计算的三维地形渲染原理图Fig.5 3D terrain rendering of CPU-GPU Coupled computation
综上所述,CPU-GPU协同并行计算的LOD模型算法具有以下优点:
1)GPU负责四叉树结构的并行构建,大大减轻CPU工作负载,则CPU可以做其他任务处理.
2)GPU有成百上千个可高度并行工作的处理器核心,低耦合的地形块LOD模型构建交由GPU并行处理,比在串行执行的CPU上计算效率更高,缩短了整个系统的处理时间.
3)采用OpenCL实现的算法具有较好的代码移植性,无需修改源代码只需重新编译就能在不同厂商的GPU上运行.
4)OpenCL和OpenGL之间可共享数据,OpenCL内核函数处理后的结果可以直接用于OpenGL的顶点数据,避免了两种数据类型的转换和拷贝,提高了场景渲染性能.
3.2 OpenCL内核并行构建LOD模型原理
为进行大量的数据处理,OpenCL内核就需要进行大量的数据划分操作,数据划分处理的越合理,数据处理时间越短.在OpenCL中能够独立执行的最小单元是工作项,若干个工作项组成一个工作组,工作组内的工作项可以共享工作组内的资源,并在工作组内并发执行,不同工作组在不同的计算单元上并行执行[15].
OpenCL利用clEnqueueNDRangeKernel函数把具体任务放入队列中执行,通过设置参数对任务进行分割,不同的工作项针对不同的数据完成不同的任务,且工作项之间并行执行.OpenCL可采用数据并行编程模型实现并行构建地形块的四叉树结构.clEnqueueNDRangeKernel的NDRange参数为一个数组,此数组可以为一、二和三维.如图6(a)所示,NDRange为一个二维数组,数组中的一个元素就是一个工作组,一个工作组中包含固定数量的工作项,每一个工作项可以独立构建某个地形块的四叉树.本文把每个物理地形块在逻辑上划分为大小为129×129(像素×像素)的逻辑块,即每个LOD模型最多可以分为7个等级.由于GPU型号不同其性能亦不同,所支持的最大工作组数量也不同,若要发挥GPU最好性能,需寻找最佳工作组数量来发挥GPU最佳性能.本文实验采用256个工作组,每个工作组有512个工作项发执行内核函数.

图6 OpenCL并行构建LOD模型原理Fig.6 OpenCL building LOD models in parallel
4 实验结果与分析
本实验的硬件配置为CPU Intel Core(TM)i3-4160 3.6GHz,四核处理器,内存为4GB,显卡型号为NVIDIA GeForce GT610,显存为1GB,显存位宽为64位DDR3.
软件平台为Windows 7旗舰版64位操作系统,开发语言为C++,开发工具为Visual Studio 2013,OpenGL 4.3版本,OpenCL 1.1版本,NVIDIA驱动版本号为R320.49.该实验地形渲染时的屏幕窗口大小为1024×768.
算法的测试数据为辽宁某地区DEM数据,先把DEM数据转换为高度图数据,把大规模地形块预处理成每个地形块大小为513×513.并在逻辑上进一步划分为129×129的数据块来分别构建LOD模型,地形块的索引存储在一个数组中.

图7 地形渲染效果图Fig.7 Terrain rendering view
如图7(a)是渲染三角面片的三维地形截图,从图中可知,离视点越近,地表特征越复杂,LOD模型越精细,绘制的三角面片越多.离视点较远,地形特征越平稳,渲染的LOD模型越粗糙.图7(b)为添加纹理贴图后的三维地形截图.该实验的测试数据结果如表1所示,基于传统CPU实现的LOD模型算法就是在CPU上进行大量的计算,在GPU上渲染三维场景.传统GPU实现的LOD模型算法是Adrien Bernhardt[8]提出的在CPU上进行少量的浮点计算,把地形块送入OpenGL着色器中在GPU上构建LOD模型的四叉树,并进行渲染.
从表1可以看出,在帧率和每帧绘制的三角面片数量上,本文提出的基于OpenCL实现的LOD模型算法比传统CPU实现的LOD模型算法渲染效果更好.与传统CPU实现的算法相比较,本文提出的算法CPU的占用率大大降低,而GPU占用率大1倍左右;采用本算法CPU和GPU的利用率比较均匀,通过把LOD模型的计算移植到GPU中计算,大大降低CPU计算负载,帧率能够达到每秒130帧左右.传统GPU实现的LOD模型算法与本算法相比性能相差不大.但传统GPU实现的LOD模型编程复杂,建立模型困难,不容易实现.
表1 各种算法性能比较
Table 1 System performance of algorithms

各项指标算法帧率/fpsCPU占用率/%GPU占用率/%三角形个数/每帧面向CPU算法7560284200面向GPU算法11325605250本文的算法12815556500
5 结束语
本文提出的基于OpenCL的三维地形生成模型算法,把多分辨率的LOD模型转到GPU上并行计算,降低了LOD模型的计算时间,同时可以把计算的顶点数据直接用于GPU的渲染,有效减少了内存和显存之间的数据传输,提高三维场景的渲染速度.另外,利用OpenCL框架编写的代码可以运行在不同厂商的GPU上,代码的移植性好.
本算法还存在待改进的方面:首先,本文算法中裂缝的检测和消除比较复杂,需要改进简单易行的方法.其次,OpenCL平台还不是很成熟,与OpenGL的数据共享效率不高,尚有改进的空间.
[1] Lindstrom P,Pascucci V.Visualization of large terrains made easy[C].Proceedings of the International Conference on Visualization,2001:363-371.
[2] Larsen B D,Christensen N J.Real-time terrain rendering using smooth hardware optimized level of detail[J].Journal of World Society for Computer Graphics,2003,11(1):267-276.
[3] Duchaineau M,Wolinsky M,Sigeti D E,et al.ROAMing terrain:real-time optimally adapting meshes [C].Proceedings of the International Conference on Visualization,1997:81-88.
[4] Levenberg J.Fast view-dependent level-of-detail rendering using cached geometry[C].Proceedings of IEEE Visualization,2002:259-265.
[5] Ulrich T. Rendering massive terrains using chunked level of detail control[C].Proceedings of the 29th International Conference on Computer Graphics and Interactive Technique Conference,2002:1-14.
[6] Losasso F,Hoppe H.Geometry clipmaps:terrain rendering using nested regular grids[J].Association for Computing Machinery Transactions on Graphics,2004,23(3):769-776.
[7] Zhang Bing-qiang,Zhang Li-min,Zhang Jian-ting.GPU-Based real-time terrain rendering algorithm using batched LOD[J].Journal of Image and Graphics,2012,17(4):582-588.
[8] Bernhardt A,et al.Real-time terrain modeling using CPU-GPU coupled computation [C].Proceedings of IEEE SIBGRAPI Conference on Graphics,Patterns and Images,2011(24):64-71.
[9] Wang Wen-bo,Yin Hong,Xie Wen-bin,et al.Real-time terrain tessellation on GPU using tessellation shaders[J].Computer Technology and Development,2015,25(12):105-109.
[10] Boer W H D.Fast Terrain rendering using geometrical MipMapping[C].Proceedings of World Wide Web Conference Series,2000:1-7.
[11] Liu Hao,Zhao Wen-Ji,Duan Fu-zhou,et al.High performance navigation of large-scale terrain based on GPU programming[J].Application Research of Computers,2011,28(10):3775-3777.
[12] Zhang Yan-yan,Jiang Hong-zhou,Han Jun-wei.Smooth terrain rendering algorithm based on GPU[J].Journal of University of Electronic Science and Technology of China,2009,38(6):1006-1010.
[13] Yin Chang-lin,Zhan Qing-ming,Xu Wen-qiang,et al.Simplification technology for real-time rendering of large-scale 3D terrain[J].Geomatics and Information Science of Wuhan University,2012,37 (5):555-559.
[14] Valdetaro A,Nunes G,Raposo A,et al.LOD terrain rendering by local parallel processing on GPU[C].Proceedings of Games and Digital Entertainment (SBGAMES),2010 Brazilian Symposium on,2010:182-188.
[15] Matthew Scarpino.OpenCL in action[M].USA:Manning Publications Co,2011.
附中文参考文献:
[7] 张兵强,张立民,张建廷.面向GPU 的批LOD 地形实时绘制[J].中国图象图形学报,2012,17(4):582-588.
[9] 王文博,殷 宏,解文彬,等.GPU细分着色器中的地形无缝自适应细分[J].计算机技术与发展,2015,25(12):105-109.
[11] 刘 浩,赵文吉,段福州,等.利用可编程GPU实现大规模地形场景的高性能漫游[J].计算机应用技术研究,2011,28(10):3775-3777.
[12] 张燕燕,姜洪洲,韩俊伟.基于GPU的平滑地形可视化算法[J].电子科技大学学报,2009,38(6):1006-1010.
[13] 尹长林,詹庆明,许文强,等.大规模三维地形实时绘制的简化技术研究[J].武汉大学学报(信息科学版),2012,37 (5):555-559.
关于不法分子冒充《小型微型计算机系统》
名义诈骗的严正声明
近期,互联网上的一些论文代写代发机构和个人,以冒充《小型微型计算机系统》刊名、邮箱、网站等方式,发布征稿投稿启事、索要"审稿费用"、发送"录用通知",并索取数千元版面费,以及盗用《小型微型计算机系统》名义进行其他诈骗行为.上述诈骗行为严重损害了《小型微型计算机系统》的声誉和合法权益.为此,我刊特别声明:
《小型微型计算机系统》是严肃的学术期刊,始终秉持依法办刊,视出版质量为生命.多年来《小型微型计算机系统》的收稿、审稿、退稿、退修、录用、编校、出版、发行、传播等编辑出版传播流程规范合理.绝不会以高价收取版面费的方式追求经济效益.我刊对于稿件收稿、审稿直至录用的全部流程,均在投稿系统http://xwxt.sict.ac.cn中处理.所有作者均应通过我刊投稿系统查询文章流程,核实文章是否录用.对于投稿过程中的任何疑问,请广大作者朋友直接致电《小型微型计算机系统》编辑部(024-24696120),或致函我刊电子信箱:
公共信箱:
xwjxt@sict.ac.cn
以下为编辑个人信箱:
fuyan@sict.ac.cn
liuxuan@sict.ac.cn
peining@sict.ac.cn
zhangchi@sict.ac.cn
作者向本刊投稿或了解稿件处理动态信息可选择以下途径:
http://xwxt.sict.ac.cn作者在线投稿中直接登录
我刊从来没有,也决不会把编辑出版业务委托给其他机构和个人代理;从来没有,也决不会委托其他机构和个人发送电子邮件.凡打着"《小型微型计算机系统》编辑部"或"《小型微型计算机系统》编辑"或"与《小型微型计算机系统》关系很熟"等旗号进行的文章代写代发,高价发表等行为, 都是非法行为,都与"《小型微型计算机系统》主管单位-中国科学院"无关;与"《小型微型计算机系统》主办单位-中国科学院沈阳计算技术研究所无关.如果作者朋友收到或发现相关诈骗信息, 请及时与我们联系,以维护作者和我刊的合法权益.
凡打着"《小型微型计算机系统》编辑部"或"《小型微型计算机系统》编辑"或与《小型微型计算机系统》关系很熟"等旗号进行文章代写代发、高价发表等的机构和个人,必须立即停止相关非法行为, 并向我刊公开道歉!我刊将委托公安部门就此严重侵犯本刊权益,危机本刊声誉和形象的非法行为展开调查, 并将依法追究相关侵权机构和个人的法律责任!
《小型微型计算机系统》
编辑部
猜你喜欢
中等数学(2021年9期)2021-11-22
中等数学(2021年8期)2021-11-22
小型微型计算机系统(2019年2期)2019-12-21
作文中学版(2019年5期)2019-11-27
英语文摘(2019年3期)2019-04-25
计算机教育(2016年10期)2016-12-19
环境(2016年7期)2016-05-14
新闻前哨(2015年2期)2015-03-11
中学生数理化·高一版(2009年6期)2009-08-31
中国校外教育(上旬)(2009年6期)2009-08-04
