
协同推荐研究前沿与发展趋势的知识图谱分析
2018-04-13 10:03陈海蛟努尔布力
小型微型计算机系统 2018年4期
陈海蛟,努尔布力
(新疆大学 信息科学与工程学院,乌鲁木齐 830046) E-mail :1179919160@qq.com
1 引 言
第一个真正意义上的推荐系统由Goldberg、Nichols、Oki以及Terry在1992年首次提出的,应用于Tapestry系统[1],协同过滤的概念由此提出,同时协同过滤推荐的相关期刊和文献陆续在国际学术领域被发表.直至2001年~2002年先后,我国才渐渐出现协同推荐的文献期刊,2001年国内发表1篇.
从2001年开始,我国开始关注协同过滤推荐,积极探索在推荐领域的有效应用.运用WOS工具分析,发现近年来我国在该领域的文献期刊等的发文量在快速增长,研究队伍在不断壮大,这表明现在的“信息过载”问题不断加剧,推荐系统的关注度在不断上升.其中,WOS发文量统计如图1所示.
图2、图3分别以“Collaborative filtering”和“协同过滤”为关键词在Foamtree中查询,展示前100项结果.国内对协同过滤算法的研究起步比较晚,对推荐的关注点,相比国外,有着明显相似共性和局部差异性.
本文研究动机在于,运用CiteSpace[2]可视化工具的计量学方法指导,对相关期刊文献进行分析,整理国内外近15年的推荐算法的研究脉络,并构建知识图谱.我们的目标为定量地解决以下问题:
1)国内近15年在协同过滤算法领域的关注点有哪些?
2)国内的协同过滤算法的研究脉络的发展有什么规律?

图1 WOS协同过滤推荐算法发文量前10的国家/地区Fig.1 WOS collaborative filtering recommendation algorithm number before the 10 country/region
3)国外近15年的协同过滤算法研究与国内的研究的对比差异性有哪些?
本文的具体工作如下:首先说明了数据来源和研究方法,接下来对协同过滤算法描述分析,得出该领域的研究热点和研究脉络.最后,通过国内国外近15年在协同过滤推荐方面的对比分析,构建知识图谱,有力论述二者存在的共性和差异性,力图客观形象地展示国内外研究现状,为我国研究人员在该领域进一步深层研究提供有力参考.

图2 基于Foamtree中Web搜索前100项英文结果Fig.2 Based on Foamtree Web search Top 100 english results

图3 基于Foamtree中Web搜索前100项中文结果Fig.3 Based on Foamtree Web search in the top 100 chinese results
2 数据来源与研究方法说明
2.1 数据源与可视化工具
本文数据分中文英文两部分,中文数据取自CNKI的核心期刊,通过主题词 “协同过滤推荐算法”,检索区间为2002年-2016年,得到核心期刊260篇.以及WOS数据库中以“Collaborative filtering recommendation algorithm”为检索条件的459篇核心合集论文.按年进行时间切片,将知识图谱节点分别设置“主题”、“关键词”、“机构”、“作者”等.目前用于可视化的软件有很多,本研究选用美国德雷克塞尔大学的陈超美教授开发的文献数据处理与可视化软件CiteSpace[2].
2.2 研究方法说明
本文基于可视化理论基础,借助信息可视化软件,将引文分析、聚类分析、网络分析等在知识单元分析的基础上结合并集成起来,实现了主题词共现网络分析、作者和国家的共现网络分析等,探测和分析推荐领域的关键技术、前沿与热点及发展态势.
目前的诸多研究工作都是基于单一指标,在对关键节点的精确分析和计量存在一定的不准确性.为了使研究计量更加准确,接下来要综合分析多项指标,如:频数(Freq)、中介中心性(Centrality)、激增(Burst)指数、Σ(Sigma).频数[2]:指不同节点类型在某一领域的分析数据中出现的次数.中介中心性[2]:社会网络分析的主要指标之一,是由Freeman提出用于测量网络中个体地位的计量指标.激增指数[2]:Burst Detection算法被用于判断节点在某时段内的突发增长率,依据其数值的波动变化,判断某一节点的激增时段和激增程度.Σ指数[2]:Σ是由陈超美于2009年提出来的测度科学创新能力的一个计量指标,用于确定有创新性的科学文献.研究方法流程如图4所示.
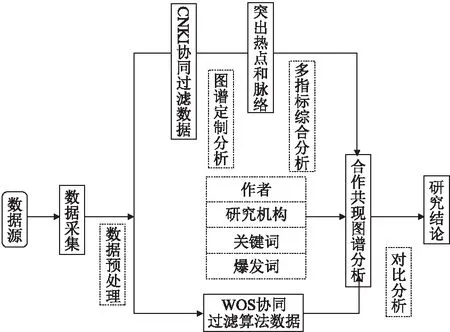
图4 研究方法流程Fig.4 Research method process
3 研究进展分析
3.1 国内协同过滤算法研究脉络分析
3.1.1 主要研究机构及研究作者网络分析
通过研究机构聚类分析,国内对于协同过滤算法的研究起步比较晚,从2001~2002年才正式开始研究,且相互之间合作比较少,研究机构分布相对分散,发文量前10 的研究机构分别为重庆大学(13)、中山大学(9)、燕山大学(8)、南京航空航天大学(6)、大连理工大学(6)、上海理工大学(5)、中国科学技术大学(5)、同济大学(5)、重庆邮电大学(5)、上海第二工业大学(4),如图5,其中节点的大小表示频度,冷色调表示时间越早,暖色调表明时间越近.

图5 研究机构合作网络共现分析Fig.5 Co-occurrence analysis research cooperation network
作者合作网络分析反应作者对研究领域的贡献及合作情况,通过分析得到了网络基本布局和作者论文的产量分布,研

表1 高频作者及首次发文时间Table 1 High frequency authors and dispatch time for the first time
究论文共涉及作者中,发文量4篇及以上的有36位,发文量5篇以上的有13位,表格仅收集部分数据,从年度分布上来看,高产作者的集中发文时间在2010年左右,2002-2010年之间属于研究人员慢慢摸索的阶段,协同过滤推荐算法的研究热度在不断升高.
3.1.2 基于共词分析的研究热点
研究热点[2]反应了主流研究内容,主题词是一篇文章的核心内容的高度概括和提炼.为了直观地了解2002-2016年期间国内协同过滤推荐领域的研究热点,通过设定工具阈值和相关系数后,进行关键词共现网络聚类归并,如图6,其中多层分色同心圆表示共引关键词,深浅层次不同的圆环表示在不同年份被引,同心圆中心出现深色的圆代表凸显关键词,即从检索年份开始新兴研究领域或是重要领域.比如,图6中比较明显的同心圆分别有协同过滤、推荐算法、推荐系统、个性化推荐等,由此看出,国内的研究热点大都集中在协同过滤

图6 关键词共现网络图谱Fig.6 Keywords co-occurrence network graph
推荐算法、推荐算法、个性化推荐等等.其中数据稀疏性、冷启动、相似性、平均绝对偏差等关键词凸显,这些凸显的关键词正是协同过滤推荐本身存在的问题,也正是研究者们为之努力需要解决的问题.
1)频数(Freq)指标计量分析
近15年推荐领域研究频度较高前15个主题见表2,从2003年开始,国内开始关注电子商务,它最早起步在1990年,直到2003年开始兴起.随之协同过滤推荐技术逐渐成了电子商务领域应用最重要的技术之一.“相似度”、“相似性”等的关注,可以发现国内研究人员关注相似度算法的理论细节的研究;“云模型”由李德毅[3]院士提出的一种定性定量转换模型,在此基础上,张光卫[4]等提出一系列基于云模型的相似度度量方法;“hadoop”作为大数据时代的产物,新用户新项目不断加入系统,产生海量数据,给数据的存储和计算的速度带来极大的挑战,已有研究者在Hadoop平台设计分布式的协同过滤推荐算法.“平均绝对偏差”、“平均绝对误差”均属于系统性能评测指标,研究人员在关注算法本身的同时,也要考虑推荐系统的性能.
2)中介中心性(Centrality)指标计量分析
主要描绘的是某个节点在网络图谱中的影响力及重要程度.排名越高的关键词说明其越重要,影响力越大.其中,2003、2004年是关键词出现比较集中的年份,推荐相关的算法研究,相似度计算,平均绝对误差等凸显重要程度;2010年之前的2007、2008、2009年更加注重具体问题的研究,如冷启动、数据稀疏性、可扩展性、相似性度量等问题的提出,接下来会具体阐述作者们提出的良好的解决方法;近几年的研究侧重于个性化推荐,个性化推荐理论、个性化技术、推荐策略等等,更加注重用户行为的分析,从中挖掘有用而高效的信息,为用户提供体验良好的推荐结果清单.
3)Burst指标计量分析
频数描绘了主题词的增长势头.而激增( Burst)指数的关注点是单个主题的自身发展变化过程,可以很容易的展示热点主题的凸显性和关键技术的识别.表2中激增指数的统计表明2010年以后,研究重点在用户群体上,关注“用户兴趣”、“用户特征”、“用户等级”、“用户行为”等,更好地实现个性化推荐,同时用户兴趣的时效性成为有待解决的关键性问题.2013年开始,突发新词涌现,“相异度”、“判断力”、“局部活跃指数”等,这些突发词来自一篇融合多因素的专家组评分协同过滤推荐算法[5],该算法综合考虑全局专业指数和局部活跃指数,用以定义专家的条件,再按照一定的比例从中抽取组成专家组,然后根据专家的判断以及与目标用户的相异度来分配评分权重,最后定义预测评分选出最佳推荐.

表2 关键词top15排名统计和首次出现年份Table 2 Keywords top15 rank statistics,and for the first time in years
4)∑指标计量分析
从统计结果分析,近几年,“hadoop”、“mapreduce”等词成为创造性较强的关键词,分布式计算,提高推荐效率成为现在的研究主流.图7为2002-2016年主题词共现网络图谱,通过共现聚类,产生11个协同过滤算法的改进算法.每种改进算法的立足点各不相同,分别在一定领域提高了推荐的准确度,并一定程度上解决了推荐算法存在的问题.

图7 主题词共现网络图谱Fig.7 Keywords co-occurrence network graph
基于贝叶斯理论的协同过滤算法[6],对用户爱好进行学习,分析用户对项目的固有特征的爱好度,采用一种新颖的相似度度量方法计算项目相似度,得到更有效的邻居集合,能够获得较好的推荐精度;利用社交关系的实值条件受限玻尔兹曼机协同过滤推荐算法,利用社交网络中的好友信任关系有助于缓解评分数据的稀疏性问题;基于矩阵分解的协同过滤算法[5],通过对传统的矩阵分解模型进行正则化约束来防止模型过度拟合训练数据,并通过迭代最小二乘法来训练分解模型,有效缓解可扩展性和稀疏性问题.
3.1.3 基于关键词、主题词共现的国内研究趋势分析
为了解协同过滤算法的研究热点的发展脉络和发展趋势,我们在共现网络分析的基础上,按照时间序列统计关键词、主题词词频,利用CiteSpace软件的关键词时区视图.视图的演进路径是学科知识领域中知识基础和前沿随时间演进的动态过程.其中,关键词、主题词聚类时区图如图8所示.
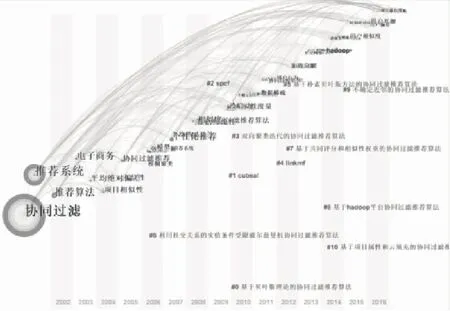
图8 关键词、主题词聚类时区图Fig.8 Keywords,keywords clustering time zone map
国内对于协同推荐的研究更加注重理论,通过对算法本身的不断改进,用以更好地缓解数据稀疏性、冷启动和可扩展等问题.2010年前后,大家把关注点瞄准了个性化需求,为了更好地实现个性化,用户特征、用户行为等因素的研究变得举足轻重.“信息过载”不断加剧,数据量剧增,基于分布式的推荐研究变得尤为重要.推荐研究不断深入,多学科多分支的结合成为可能,将人工智能、神经网络、数据挖掘等相结合,实现基于优化模型的可训练的智能推荐系统将成为未来研究的主流方向.
3.2 国内外协同过滤算法研究热点、研究趋势对比分析
为了清晰了解国内外在研究热点和研究趋势的差异性,使用CiteSpace工具对中英文期刊进行相关聚类,结合关键词、主题词共现和聚类分析,爆发词分析,得到国内外在协同过滤算法方面研究的基本图谱.综合图9(a)、图9(b)、表3,可发现,国内对于协同过滤推荐算法的研究起步比较晚,对比国外关注热点和研究方向,两者作为知识基础比较相似,国内更加注重理论创新,对算法的改进上更加侧重,而国外更加关心实际应用中的问题的分析和解决,不断地推出新模型,强调用户体验,提升个性化定制需求,注重用户偏好的实证研究.对比分析国内外靠前的主题词和爆发词(见图10),可以发现,目前典型的主要有两大类协同过滤算法:基于记忆的和基于模型的.基于记忆的协同过滤算法又包括基于用户的和基于项目的.其中基于用户的推荐更社会化一点,在一些社交网络中有重要应用;而基于项目的推荐更加侧重于个性化,因此多被应用于电子商务网站等.随着移动互联网的快速发展,非结构化的数据比例逐渐提升,面对海量的信息资源,协同过滤推荐面临着一些难以解决的问题,国外同样面临着这样的问题:数据稀疏性、冷启动、算法的可扩展性、用户兴趣的时效性、信任计算、隐私保护等等.

图9 中文/英文主题词共现聚类图谱Fig.9 Chinese/English keywords co-occurrence clustering map

表3 主题词top15的频度排名和首次出现年份Table 3 Subject headings top15 frequency ranking and for the first time in years
目前,国内外为解决数据稀疏性等问题的有效方法有采用预测评分填充用户-项目评分矩阵,主要有:BP神经网络、Naïve Bayesian分类方法等.还有基于矩阵降维技术—奇异值分解.另外冷亚军[8]等总结出空值填补、新相似性方法、结合基于内容的推荐、推荐结果融合、图论和其他方法.为了解决冷启动问题,普遍采用基于内容的最近邻居查找技术.而可扩展性问题通常采用聚类技术来解决,典型方法有:K-means聚类算法、EM(Expectation-Maximization)算法、Gibbs Sampling方法和模糊聚类等,当然还有数据集缩减、矩阵分解、主成分分析、增量更新等.个性化推荐系统的性能评价是根据用户对推荐结果的满意度来决定的.而对于推荐质量的评价标准主要有统计精度度量和决策支持精度度量两类,统计精度度量方法中常用的是平均绝对偏差;决策支持精度度量方法中主要有召回率、准确率等方法.

图10 国内外爆发的热点主题词和起始时间区间对比图Fig.10 Outbreak of the hot subject at home and abroad and starting time interval comparison chart
4 总 结
本文基于分析研究简单阐述了国内外近15年在推荐领域的相关算法的关注点,以及国内在协同过滤算法领域的研究脉络和研究趋势,并通过国外研究的对比分析,我们总结如下:
为了更加直观地了解国内外研究的差异,现总结概括为(如表4所示):
1)近年来国内对协同过滤算法存在的数据稀疏性、冷启动、可扩展性等问题进行着深入的研究,并提出了诸多改进方法.为解决数据稀疏性问题的有效方法是采用预测评分对用户-项目评分矩阵进行填充,主要有:BP神经网络、Naïve Bayesian分类方法等.另一种方法是基于矩阵的降维技术.为了解决冷启动问题,普遍采用基于内容的最近邻居查找技术.而可扩展性问题通常采用聚类技术来解决,典型方法有:K-means聚类算法、EM(Expectation-Maximization)算法、Gibbs Sampling方法和模糊聚类等.这些方法只是在特定场合特定领域行之有效,并且这些问题会随着“信息过载”的加剧而更加凸显.而且协同过滤还会面临一些新的问题和挑战,例如隐私保护问题,安全问题等等.另外随着改进算法的不断增多,对算法的评估标准的研究也会越来越重要.
2)推荐技术的应用涉及电子商务、社交网络、广告、视频领域等方方面面,推荐系统面临的诸多未被很好解决的问题或难题,成为信息检索、数据挖掘、机器学习和人工智能等领域的研究热点.研究者们提出了的多种方案解决协同过滤算法面临的数据稀疏、冷启动、可扩展性等问题,针对这些难题,
研究领域的一个明显的趋势是其他领域的一些技术正被

表4 国内外研究对比Table 4 Research at home and abroad
应用到推荐技术中来并将进一步长久地被应用,BP神经网络技术很好地解决数据稀疏性问题,但是随着数据量的不断增加,这些问题会更加凸显,分布式的应用将成为一种趋势,领域外技术的结合使用会变得更加地普遍和重要.
3)国内对协同过滤推荐的研究晚于国外,但二者研究的知识基础比较相似,只是侧重点存在差异性,国内更加注重理论研究和算法改进,国外更加关心实际应用中的问题的分析和解决.通过国内外爆发热点主题词的对比分析,推测出未来数年的推荐研究将更加关注于个性化推荐和智能化推荐.多学科的交叉结合,人工智能、数据挖掘、机器学习、推荐技术等的结合会促进推荐领域的革新.
推荐系统的应用领域会愈加广泛,推荐技术面临的应用难题会愈加艰巨和复杂,技术革新的推动作用,使得推荐技术的研究存在巨大的价值和广阔的发展空间.
[1] Goldberg D,Nichols D,Oki B M,et al.Using collaborative filtering to weave an information tapestry[J].Communications of the ACM.December,1992,35(12):61-70.
[2] Chen C M.CiteSpace II:detecting and visualizing emerge-ng trends and transient patterns in scientific literature[J].Journal of the American Society for Information Science and Technology,2006,57(3):359-377.
[3] Li De-yi,Liu Chang-yi,Du Yi,et al.Artificial intelligence with u-Ncertainty[J].Journal of Software,2004,15(11):1583-1594.
[4] Zhang Guang-wei,Kang Jian-chu,Li He-song,et al.Context based collaborative filtering recomm-endation algorithm[J].Journal of System Simulation,2006,18(S2):595-601.
[5] Li Gai,Li Lei.Collaborative filtering algorithm based on matrix decomposition[J].Computer Engineering and Applications,2011,47(30):4-7.
[6] Meng Xian-fu,Chen Li.Collaborative filtering recomm-endation algorithm based on bayesian theory[J].Journal of Computer Applications,2009,29(10):2733-2735.
[7] Wang Ming-wen,Tao Hong-liang,Xiong Xiao-yong.A collaborative filtering recommendation algorithm based on iterative bidirectional clustering[J].Jiangxi N-ormal University,2008,22(4):61-65.
[8] Leng Ya-jun,Lu Qing,Liang Chang-yong.Survey of recommendation based on collaborative filtering[J].Pattern Recognition and Artificial Intelligence,2014,27(8):720-734.
[9] Liu Lu,Ren Xiao-li.Review and perspective of the reco-mmender systems[J].China Journal of Information Systems,2008,2(1):82-90.
[10] Shi Kun,Yu Qiang,Zhu Qiu-yue.A collaborative filter-ing algorithm of weighted information entropy and rating of us-er interests[J].Computer and Digital Engineering,2017,45(2):338-342.
[11] Wang Qiao,Xie Ying-hua,Yu Shi-cai.Collaborative filtering algorithm combined with the user clustering and item types[J].Computer Systems &Applications,2016,25(12):132-137.
[12] Li Zhuang.The design and implementation of collaborat-ive filtering recommendation system based on Hadoop[D].Nanjing:Nanjing University of Posts and Telecommunications,2016.
[13] Li Yi-chen,Chen Li,Shi Chen-chen,et al.Enhanced collaborative filtering adopting trust network[J].Application Research of Computers,2018,35(1):1-7.
[14] Wang Qiao,Xie Ying-hua,Yu Shi-cai.Collaborative filtering algorithm combined with the user clustering and item types[J].Application of Computer System,2016,25(12):132-137.
附中文参考文献:
[3] 李德毅,刘常昱,杜 鹢,等.不确定性人工智能[J].软件学报,2004,15(11):1583-1594.
[4] 张光卫,康建初,李鹤松,等.面向场景的协同过滤推荐算法[J].系统仿真学报,2006,18(S2):595-601.
[5] 李 改,李 磊.基于矩阵分解的协同过滤算法[J].计算机工程与应用,2011,47(30):4-7.
[6] 孟宪福,陈 莉.基于贝叶斯理论的协同过滤推荐算法[J].计算机应用,2009,29(10):2733-2735.
[7] 王明文,陶红亮,熊小勇.双向聚类迭代的协同过滤推荐算法[J].中文信息学报,2008,22(4):61-65.
[8] 冷亚军,陆 青,梁昌勇.协同过滤推荐技术综述[J].模式识别与人工智能,2014,27(8):720-734.
[9] 刘 鲁,任晓丽.推荐系统研究进展及展望[J].信息系统学报,2008,2(1):82-90.
[10] 石 坤,余 强,朱秋月.融合信息熵与兴趣度的协同过滤算法[J].计算机与数字工程,2017,45(2):338-342.
[11] 王 巧,谢颖华,于世彩.结合用户聚类和项目类型的协同过滤算法[J].计算机系统应用,2016,25(12):132-137.
[12] 李 状.基于Hadoop的协同过滤推荐算法的设计与实现[D].南京:南京邮电大学,2016.
[13] 李熠晨,陈 莉,石晨晨,等.采用信任网络增强的协同过滤算法[J].计算机应用研究,2018,35(1):1-7.
[14] 王 巧,谢颖华,于世彩.结合用户聚类和项目类型的协同过滤算法[J].计算机系统应用,2016,25(12):132-137.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2022年6期)2022-07-02
新班主任(2022年4期)2022-04-27
汽车观察(2019年2期)2019-03-15
汽车文摘(2019年3期)2019-03-04
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
民生周刊(2017年19期)2017-10-25
互联网天地(2016年1期)2016-05-04
档案管理(2014年6期)2014-10-30
