
不一致邻域粗糙集的不确定性度量和属性约简
2018-04-13 10:16姚晟,汪杰,徐风,陈菊
小型微型计算机系统 2018年4期
姚 晟,汪 杰,徐 风,陈 菊
1(安徽大学 计算智能与信号处理教育部重点实验室,合肥 230601) 2(安徽大学 计算机科学与技术学院,合肥 230601) E-mail:wangjiechn@126.com
1 引 言
粗糙集理论[1]是Pawlak在1982年提出的用于处理不精确、不确定性问题的一种数据分析工具.目前已经广泛应用于机器学习、数据挖掘、模式识别、特征选择和图像分割等研究领域[2-5].
经典粗糙集理论基于等价关系,它通常适用于处理符号型数据.然而在现实应用(如科研、医疗、金融、工程应用领域)中,数值型数据广泛存在.研究人员在处理这类数据时通常采用离散化方法将数值型数据转化为符号型数据[6].这一转换必然会造成某些信息的损失.为了解决这类问题,林等[7]通过拓展经典粗糙集中的等价关系,提出了邻域粗糙集模型,该模型通过邻域关系来刻画对象之间的相似程度.胡等[8,9]通过定义邻域关系,构造了一种统一的邻域分类理论体系,并针对数值型属性和符号型属性并存的混合数据提出了一种基于邻域依赖度的特征选择算法.
不确定性度量作为粗糙集理论中描述系统分类能力和提高分类精度的重要依据,国内外众多学者对此进行了研究.Pawlak提出利用上下近似集,用精度和粗糙度来度量信息系统的不确定性,用近似精度和近似粗糙度来度量决策系统的不确定性[1].由于精度和粗糙度依赖的是正区域和边界域,会导致不确定性度量不够精细的情况.因此,部分学者从其它不同角度进行了研究,目前主要的研究方法主要有基于信息熵的方法以及基于信息熵的变种方法.比如信息熵[10]、粗糙熵[11]、混合熵[12,13]等方法都可以有效的应用于粗糙集的不确定性度量.模糊熵也是一种研究比较多的方法,它是通过将粗糙集转化为模糊集来度量集合的不确定性[14].然而,以上不确定度量方法主要是基于等价关系,只适用于处理具有符号型属性的数据.邻域粗糙集是基于邻域关系,适用于处理数值型数据,但是邻域关系并不具有严格的等价关系,因此,这些不确定度量方法难以适用于邻域决策系统.
属性约简是粗糙集理论研究的核心内容之一,是指在保持原有信息系统或决策表分类能力不变的情况下,剔除其中不重要、不相关的冗余属性的过程.近些年来,基于邻域粗糙集模型的属性约简算法不断被提出.文献[8]在经典粗糙集属性约简的基础上,提出了以依赖度为启发式函数的属性约简算法.文献[15]将信息论中的互信息引入邻域粗糙集模型中,提出了以互信息为启发式函数的属性约简算法.文献[12]考虑了代数观点下的精度和信息论观点下的信息熵,提出了混合度量的属性约简算法.文献[16]提出邻域软间隔度量方法.以上约简算法考虑的主要是条件属性和决策属性之间的关系,判断一个条件属性是否是冗余属性的依据是该属性是否会影响决策属性中的确定信息或者不确定信息,然而并没有充分考虑到条件属性之间的关系也会影响约简结果和分类精度.在实际情况中,条件属性之间通常不是独立的,它们之间具有某种关联.如穿衣指数和气温是有关联的,气温高,穿衣指数减小,气温低,穿衣指数增加;城市空气污染指数与汽车保有量也具有某种关联,汽车保有量多,空气污染指数增加,汽车保有量少,空气污染指数减小.在实际的属性约简中,将关联很大的属性都放入约简结果中必然会造成数据冗余,显然这是不必要的.
本文通过深入研究粗糙集的不确定性度量方法,针对数值型数据的特点,分析了不一致邻域粗糙集的相关性质,定义了邻域条件熵的不确定度量方法用来评价约简属性的质量.同时考虑了条件属性之间的关联程度会对约简结果和分类精度产生影响,提出了基于相关系数的不一致邻域粗糙集属性约简算法.其主要思想是通过引入统计学中秩相关系数的概念来度量条件属性之间的关联程度,并将相关系数融入到邻域粗糙集属性约简算法中来剔除冗余属性,最终的约简结果可以根据实际问题的需要,灵活选择合适的相关系数阈值.实验结果表明,本文提出的算法能够获得较小的约简和较高的分类精度.
2 背景知识
在本节中,我们主要介绍粗糙集理论的基本概念和性质以及邻域粗糙集的基本知识.
2.1 粗糙集理论
在粗糙集理论中,知识被认为是分辨对象的能力.粗糙集采用等价关系将论域粒化为若干等价类,利用上下近似逼近的方式刻画未知概念,通过知识约简来发现数据当中潜在的知识和规律[1].
定义1[1].设决策信息系统DT=(U,A,V,f),其中U={x1,x2,…,x|U|}是有限非空集,称为论域或对象空间,U中的元素称为对象;A也是一个有限非空集,A中的元素称为属性,且A=C∪D,C∩D=φ,其中C中的属性称为条件属性,D中的属性称为决策属性;V=∪Va,Va是属性a的值域;f:U×A→V是一个信息函数,它为每个对象的每个属性赋予一个值,即f(x,a)∈Va.
在决策信息系统DT中,对于任意的x,y∈U(x≠y).若f(x,C)=f(y,C)∧f(x,D)≠f(y,D).则称DT为不一致决策表,x,y为不一致对象.否则称DT为一致决策表.
定义2[1].设DT=(U,A,V,f)和B⊆C.B上的不可分辨关系定义为
IND(B)={(x,y)∈U×U|∀a∈B,f(x,a)=f(y,a)}.
(1)
定义3[1].设DT=(U,A,V,f)和B⊆C.对论域上的一个对象子集X⊆U,定义X在条件属性子集B上的下近似、上近似和边界域分别为

其中:[x]B是x在条件属性集B上的等价类.
2.2 邻域粗糙集及其相关性质
邻域粗糙集通过邻域关系来粒化论域,解决了离散化数据带来的某些信息损失,可以有效的处理数值型数据[8].下面简要介绍基本性质.
定义4[8].设〈U,Δ〉为非空度量空间,我们称Δ为〈U,Δ〉上的距离函数,如果Δ满足
1)Δ(x1,x2)≥0,Δ(x1,x2)=0,当且仅当x1=x2;
2)Δ(x1,x2)=Δ(x2,x1);
3)Δ(x1,x3)≤Δ(x1,x2)+Δ(x2,x3).
目前常用的距离函数有曼哈顿距离、欧氏距离和切比雪夫距离,本文采用的是欧氏距离.欧氏距离Δ定义为
(5)

定义6[8].设邻域决策系统NDT.对于U中任意对象xi,定义其δ邻域为
δ(xi)={x∈U|Δ(x,xi)≤δ}.
(6)
其中,δ≥0,Δ为距离函数.
定义7[8].设邻域决策系统NDT.若由B⊆C生成U上的邻域关系NB.则对X⊆U,X关于B的下近似、上近似和边界域分别定义为
3 不一致邻域粗糙集的不确定性度量
经典粗糙集的不确定性度量方法通常只能处理符号型数据,难以应用于邻域粗糙集的不确定性度量.下面首先给出不一致邻域粗糙集的相关性质,然后给出邻域条件熵的不确定性度量方法,证明了其满足不确定度量的基本要求.并分析证明了相关的性质定理.
3.1 不一致邻域粗糙集模型
定义8.设邻域决策系统NDT和条件属性子集B⊆C.其中,U/D={[x1]D,[x2]D,…,[xn]D}.则δB(x)表示对象x在属性集B下的邻域,[x]D表示对象x在决策属性D上对应的决策类.如果存在x∈U,使得δB(x)⊄[x]D.那么称NDT为不一致邻域决策系统.其中δB(x)∩[x]D表示对象x的决策一致邻域.δB(x)-[x]D表示对象x的决策不一致邻域.
性质1.设邻域决策系统NDT和条件属性子集B⊆C.其中,U/D={[x1]D,[x2]D,…,[xn]D}.则决策属性D关于B的正区域定义为
POSB(D)={xi∈U|δB(xi)-[xi]D=Ø}.
证明:假设存在x∈POSB(D),使得δB(x)-[x]D≠Ø.根据定义7可知当x∈POSB(D),容易得到δB(x)⊆[x]D,所以δB(x)-[x]D=Ø.与假设不符,所以POSB(D)={xi∈U|δB(xi)-[xi]D=Ø}成立.
性质1说明正域为决策不一致邻域为空集的对象集合.
性质2.设邻域决策系统NDT和条件属性子集B⊆C.其中U/D={[x1]D,[x2]D,…,[xn]D}且xi∈POSB(D).如果∀xj∈U-POSB(D),那么xi∉δB(xj)-[xj]D.
证明:根据题设可知xi∈POSB(D)所以δB(xi)⊆[xi]D.
当xj∉δB(xi),此时显然xi∉δB(xj)-[xj]D.当xj∈δB(xi),可得xi∈δB(xj).又由xj∈[xi]D得xi∈[xj]D.由此可得xi∉δB(xj)-[xj]D.故性质得证.
性质2说明正域中的任意对象不属于非正域对象的决策不一致邻域.
3.2 邻域条件熵及其相关性质
定义9.设邻域决策系统NDT和条件属性子集B⊆C.那么关于B的邻域信息熵定义为
.
(10)
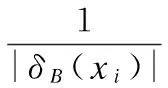
定义10.设邻域决策系统NDT.∀M,N⊆C,条件属性集M,N的联合熵定义为
(11)
定义11.设邻域决策系统NDT和条件属性子集B⊆C.其中,U/D={[x1]D,[x2]D,…,[xn]D}.则决策属性D关于属性集B的条件熵定义为
(12)
定理1.设邻域决策系统NDT和条件属性子集B⊆C.其中,U/D={[x1]D,[x2]D,…,[xn]D}.则Eδ(D|B)=Eδ(B)-Eδ(D,B).
证明:Eδ(D|B)

=Eδ(B)-Eδ(D,B).
粗糙集的不确定性度量通常应该满足以下几个约束条件[17]:1)单调性;2)不变性;3)非负性.
下面分别进行证明:
定理2.(单调性) 设邻域决策系统NDT.其中U/D={[x1]D,[x2]D,…,[xn]D}.如果M⊆N⊆C,那么Eδ(D|M)≤Eδ(D|N).
证明:由文献[18]中的定理12和引理4.1得出.

证明:不变性显然成立.
定理4.(非负性) 设邻域决策系统NDT和B⊆C.其中U/D={[x1]D,[x2]D,…,[xn]D}.那么Eδ(D|B)≥0.
证明:当∀xi∈U,δB(xi)=xi.可得Eδ(D|B)=0.当∀xi∈U,δB(xi)=U,[xi]D=xi,可得Eδ(D|B)=log2|U|.由此可得0≤Eδ(D|B)≤log2|U|.所以Eδ(D|B)≥0一定成立.
通过定理2、3、4可得Eδ(D|B)满足不确定度量的基本条件,因此可以用做不确定性度量工具.
定理5.设邻域决策系统NDT和M,N⊆C.其中U/D={[x1]D,[x2]D,…,[xn]D}.如果∀xi∈U,δB(xi)⊆[xi]D,则NDT是一致邻域决策系统.那么Eδ(D|B)=0.
证明:根据题设∀xi∈U,δB(xi)⊆[xi]D可得∀xi∈U,δB(xi)∩[xi]D=δB(xi),又根据定义11可得Eδ(D|B)=0.
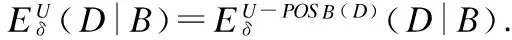
证明:对任意xi∈U,δB(xi)⊆[xi]D可知
δB(xi)∩[xi]D=δB(xi).
对任意xi∈U,δB(xi)⊄[xi]D可知
δB(xi)∩[xi]D≠Ø.
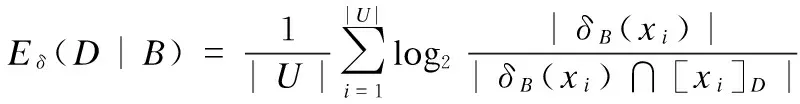
定义12[8].设邻域决策系统NDT和条件属性子集B⊆C.∀a∈C-B,则条件属性a相对于B的重要度定义为
SIG(a,B,D)=Eδ(D|B∪a)-Eδ(D|B)
(13)
定义13[8].设邻域决策系统NDT和条件属性子集B⊆C.称B是C的一个约简,如果B满足
4 秩相关系数及其性质
条件属性与决策属性之间的关系会影响属性约简的特征数量和分类精度,条件属性之间同样也存在着某种关系,这种关系也会影响属性约简的结果.通常可以将属性之间的关系用相关系数来表示.目前常用的度量属性之间相关系数的方法主要有二元正态分布、独立性卡方检验,秩相关系数等[19-21].其中,二元正态分布可以度量数值型数据中的属性相关系数,独立性卡方检验可以度量符号型数据中的属性相关系数.而在实际应用中,数值型与符号型共同存在的混合数据广泛存在.二元正态分布和独立性卡方检验都难以适用于处理混合数据.
秩相关系数也称,Spearman 秩相关系数,是一个非参数性质(与分布无关)的秩统计参数.它将两属性的属性值按数据的一定顺序排列位次,以各属性的属性值的位次代替实际数据而求得的一种统计量.因此,秩相关系数不仅可以处理符号型数据和数值型数据,还可以处理数值型与符号型共同存在的混合数据.本文将秩相关系数的概念引入到邻域粗糙集模型中.

定义15.设邻域决策系统NDT.∀ai,aj∈C,第k个对象在ai,aj属性下对应的秩次分别记为Rk和Sk,则所有对象可得|U|对秩组合(R1,S1),(R2,S2),…,(R|U|,S|U|),其中,|U|对秩可能完全相同,也可能完全相反,或者不完全相同.
定义16.设邻域决策系统NDT.∀ai,aj∈C,对象U在ai,aj下有|U|对秩组合(R1,S1),(R2,S2),…,(R|U|,S|U|),则属性ai,aj的相关系数rij定义为
(16)

且rij满足如下性质:
1)0≤rij≤1;
2)当rij越接近1时,表示条件属性ai,aj之间的相关程度越高.当rij越接近0时,表示条件属性ai,aj之间的相关程度越低.
下面举例简要进行说明.
例1.给定决策表S如表1所示.其中U={x1,x2,x3,x4},C={a,b}.
①获取表1中所有对象在属性a下的对应的属性值序列为Aa={x1=0.1,x2=0.6,x3=0.4,x4=0.5}.
②将Aa根据属性值从小到大的顺序进行排序,得到一个有序对象序列{x1,x3,x4,x2},并进行编秩得到序列{x1=1,x3=2,x4=3,x2=4}.

⑥根据公式(16)计算相关系数为0.8.
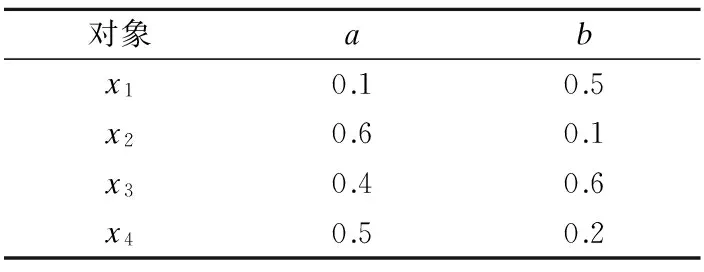
表1 决策表STable 1 Decision table S
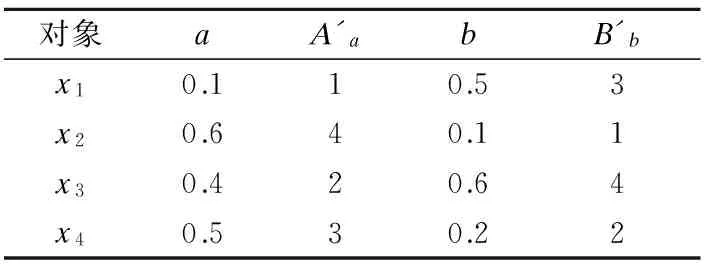
表2 秩次表S1Table 2 Rank table S1
5 属性约简算法
下面分别介绍计算相关系数算法,计算邻域条件熵算法以及基于相关系数的不一致邻域粗糙集属性约简算法.
5.1 计算相关系数算法
在邻域粗糙集模型中,大部分属性约简算法主要是通过基于依赖度或者基于熵的启发式函数来刻画条件属性对决策属性的重要度.然而,这些算法仅仅只考虑了条件属性对决策属性的影响,并没有考虑条件属性之间的相互影响会对约简结果产生影响.在实际应用中,条件属性之间相互影响的情况广泛存在,当两个条件属性之间的相关系数较大时,二者同时在约简集中会导致数据冗余.因此在约简算法中只考虑条件属性和决策属性之间的关系远远不够,本文通过引入秩相关系数的概念,通过计算条件属性之间的相关系数,来剔除冗余的条件属性.
根据前面的研究,下面给出计算相关系数的算法.
算法1.计算相关系数
输入:NDT=〈U,A,V,f,N〉,ai,aj;
输出:相关系数rij.
Step1.获取所有对象在ai,aj下的属性值序列Ai,Bj;
Step2.将Ai,Bj根据属性值从小到大的顺序进行排列,并分别进行编秩,若属性值相等时取平均数;
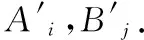
Step4.fork=1to|U|do:

Step5.fork=1to|U|do
计算r(ai,aj);
Step6.计算rij;
Step7.返回相关系数rij.
5.2 计算邻域条件熵算法
算法2.计算邻域条件熵
输入:邻域决策系统NDT=(U,A,V,f,N)和B⊆C.其中,邻域半径为δ,U/D={[x1]D,[x2]D,…,[xn]D}.
输出:邻域条件熵Eδ(D|B).
Step1.初始化.令Eδ(D|B)=0;
Step2.对于每个1≤i≤|U|,循环执行:
①计算对象xi的邻域类δB(xi);
②获取对象xi的决策类[xi]D;
③计算邻域条件熵
Step3.计算邻域条件熵
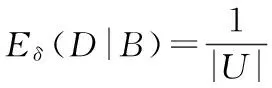
;
Step4.返回邻域条件熵Eδ(D|B).
5.3 基于相关系数的不一致邻域粗糙集属性约简算法(RNRS)
RNRS算法从空集开始,首先计算条件属性集中任意属性的邻域关系;然后遍历约简集之外的所有条件属性计算相应的属性重要度并从中选择属性重要度最大的条件属性与约简集中的所有属性进行相关系数计算;如果条件属性之间的相关系数都小于预先设定的相关系数阈值λ时,则对当前的属性进行判断,如果加入该属性后属性重要度大于0,则将该属性加入到约简集中后继续遍历约简集之外的属性;如果加入该属性后属性重要度等于0,直接输出约简结果;如果条件属性之间的相关系数存在大于等于相关系数阈值λ时,将该属性从候选条件属性中删除,继续遍历约简集之外的属性直到属性重要度为0结束.
下面给出算法详细步骤.
算法3.RNRS算法
输入:NDT=〈U,A,V,f,N〉;
输出:约简red.
Step1.初始化,令red=Ø,标记集合flag=Ø;
Step2.对条件属性集C中任意属性a,计算邻域关系Na;
Step3.对于任意ai∈C-(red∪flag),循环执行:
①利用算法2计算ai的属性重要度
SIG(ai,red,D)=Eδ(D|red∪a)-Eδ(D|red);
//其中Eδ(D|Ø)=0
②选择一个属性ak满足条件:
SIG(ak,red,D)=max{SIG(ai,red,D)}.
Step4.for ∀aj∈red,循环执行:
①利用算法1计算
aj和ak之间的相关系数rjk;
② ifrjk≥λ;
令flag=flag∪ak;
跳转到Step3;
else
跳出此次循环.
Step5.ifSIG(ak,red,D)>0;
令red=red∪ak;
跳转到Step 3;
else
跳转到Step 6.
Step6.返回约简red.
6 实验分析
6.1 实验准备
为了更好的验证算法的有效性,本文从UCI数据集中选用了4组数据,具体描述见表3.同时为了在计算邻域时消除量纲的影响,实验所用的所有数值型数据全部被标准化到[0,1]区间.属性约简的结果会受到邻域半径的影响.因此,为了求解问题必须先进行实验选取合适的邻域半径,然后再进行属性约简算法的比较.本次实验我们通过相关实验分析后设置邻域半径为0.35.

表3 数据集描述Table 3 Data set description
实验测试环境为一台i3 3.7GHz(4GB 内存,Windows 10 操作系统),采用Java语言实现所有算法,通过Matlab语言进行绘图.同时本文将RNRS算法与以下几个算法进行了比较:
1)基于依赖度的算法(DNRS)[9];
2)基于互信息的算法(MNRS)[15];
3)基于信息熵的方法(INRS)[22].
6.2 算法有效性验证
为了更好的比较约简属性的分类能力,实验引入流行的CART和SVM两种分类器,并以10折交叉验证的分类精度来评价所选属性的质量.
6.2.1 相关系数阈值选取
图1-图4分别展示了4组数据集在约简后,RNRS算法在CART和SVM两种分类器下的分类精度随相关系数阈值λ的变化情况.其中λ的取值以0.05为步长从0到1变化.图1展示的是wine数据集的变化情况,当λ较小时,RNRS算法在两种分类器下的分类精度明显较小;随着λ的增长RNRS算法的分类精度逐渐提高,当λ值在0.65附近时,RNRS算法在CART和SVM分类器下的分类精度波动较为稳定并且获得较高的分类精度.当λ接近1时,分类精度不再变化.图2-图4中也能得出相似的结果.这与实际情况是相符合的,当λ较小时,对筛选冗余属性的要求过于严格,导致分类精度的下降;当λ过大时,对筛选冗余属性的要求又过于宽松,所以在数值型数据中分类精度没有明显变化.综合考虑,本文选择的相关系数阈值为0.65.

图1 wine数据集Fig.1 winedataset图2 iono数据集Fig.2 ionodataset


图3 wdbc数据集Fig.3 wdbcdataset图4 wpbc数据集Fig.4 wpbcdataset
6.2.2 约简属性数量比较
首先比较不同算法的约简属性数量.表4中展示的是4种算法约简后的属性数量与数据集原始属性数量的比较.从实验的结果可以看出,4种算法都可以约简掉冗余的属性.其中,RNRS算法在大部分数据集中属性数量都小于其它3中对比算法.从约简结果的平均数来看,本文的RNRS算法获得的平均属性数为10,而DNRS、MNRS和INRS算法分别为20、12和11,因此从总体来看,本文的算法同样能够获得较少的属性数量.
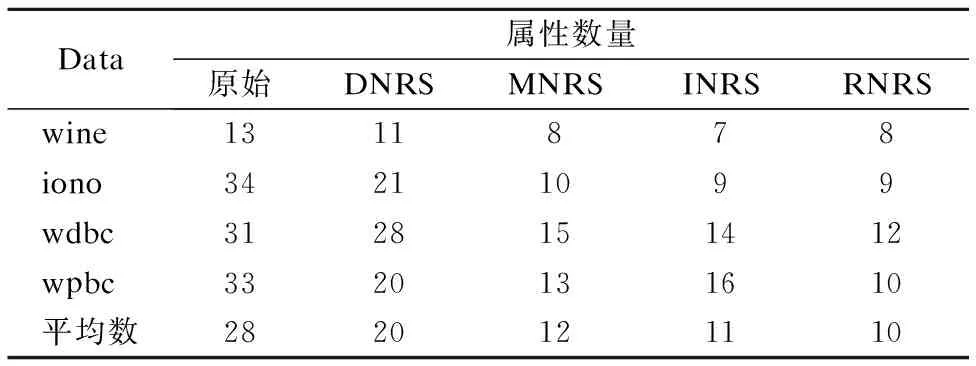
表4 特征数量比较Table 4 Comparison of feature number
6.2.3 分类精度比较
表5展示了在CART分类器下4种约简算法约简后的分类精度和原始精度的比较.观察表5中的数据发现,在wine数据集中,RNRS算法的分类精度略低于其它3种算法的分类精度;在wdbc数据集中,RNRS算法的分类精度略低于INRS算法,但是高于DNRS和MNRS算法;在iono和wpbc这2个数据集中,RNRS算法的分类精度略高于其它3种对比算法.从分类精度的平均数综合来看,RNRS算法的平均精度高于原始精度和其它3种算法的精度.这说明RNRS算法在CART分类器下在剔除冗余的条件属性后还能够获得较好的分类精度.
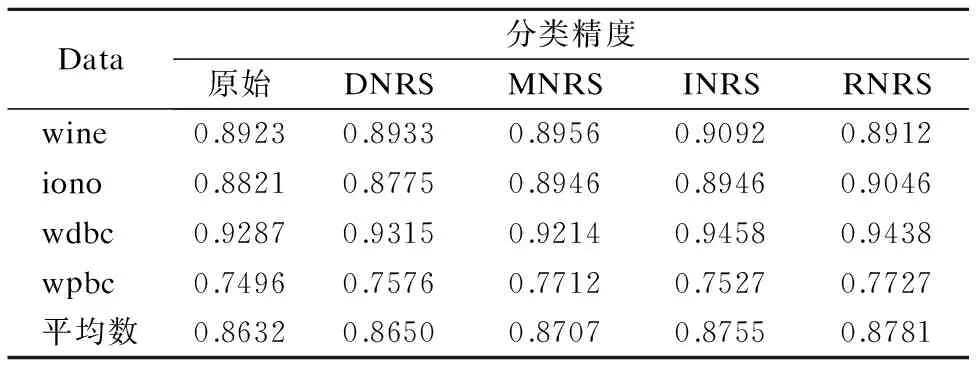
表5 CART分类器下分类精度比较Table 5 Comparison of classification accuracy in CART classifier
表6展示了在SVM分类器下4种约简算法约简后的分类精度和原始精度的比较,通过观察表6中的数据发现,在iono数据集中,RNRS算法的分类精度略低于DNRS和MNRS算法,但是高于INRS算法.在wpbc数据集中,RNRS算法的分类精度略低于MNRS算法,但是高于DNRS和INRS算法.在wine和wdbc数据集中RNRS算法的分类精度高于其它3种算法.从平均分类精度来看,RNRS算法的平均精度为0.9097,高于其它3种算法和原始属性的分类精度.这说明RNRS算法在SVM分类器下在剔除冗余的条件属性后也能够获得较好的分类精度.

表6 SVM分类器下分类精度比较Table 6 Comparison of classification accuracy in SVM classifier
通过以上的几组实验对比,表明本文的算法是有效的.充分说明考虑了条件属性之间的影响后,引入相关系数的约简算法能够在属性约简中既保持较少的属性特征,又能获得更好的分类精度.
7 结论与展望
本文首先分析了不一致邻域粗糙集的相关性质,针对目前已有的不确定性度量方法难以应用到邻域粗糙集中,提出邻域条件熵的不确定度量方法,分析证明了相关的性质定理.同时考虑到条件属性之间的关系会影响约简属性数量和分类精度,将统计学中秩相关系数的概念用到邻域粗糙集属性约简算法中,提出基于相关系数的属性约简算法.该算法通过计算属性之间的相关系数来剔除冗余属性.从而保证了约简结果既能表达原数据所包含的信息,又减少了结果的冗余程度.并通过实验展示了该算法在属性约简中的作用.实验结果表明,本文提出的算法具有较好的效果.下一步的工作是如何在属性约简过程中选择合适的相关系数阈值.
[1] Pawlak Z.Rough sets[J].Int J of Computer and Information Sciences,1982,11(5):341-356.
[2] Sarah Vluymans,Lynn D′eer ,Yvan Saeys,et al.Applications of fuzzy rough set theory in machine learning:a survey[J].Fundamenta Informaticae,2015,142(1-4):53-86.
[3] Rahman Ali,Muhammad Hameed Siddiqi,Sungyoung Lee.Rough setbased approaches for discretization:a compact reviews[J].Artificial Intelligence Review,2015,44(2):235-263.
[4] Wang De-lu,Song Xue-feng,Yuan Jing-ying.Forecasting core business transformation risk using the optimal rough set and the neural network[J].Journal of Forecasting,2015,34(6):478-491.
[5] Chen Li-fei,Tsai Chih-Tsung.Data mining framework based on rough set theory to improve location selection decisions:a case study of a restaurant chain[J].Tourism Management,2016,53(4):197-206.
[6] Jensen R,Shen Q.Semantics-preserving dimensionality r-eduction:rough and fuzzy-rough-based approaches[J].IEEE Trans.On Knowledge and Data Engineering,2004,16(12):1457-1471.
[7] Lin T Y.Granular computing on binary relations[C].Rough Sets and Current Trends in Computing,Third International Conference,RSCTC 2002,Malvern,PA,USA,Oct-ober 14-16,2002,Proceedings,DBLP,2002:296-299.
[8] Hu Qing-hua,Yu Da-ren,Xie Zong-xia.Numerical attrib-ute reduction based on neighborhood granulation and rough approximation [J].Journal of Software,2008,19(3):640-649.
[9] Hu Qing-hua,Yu Da-ren,Liu Jin-fu,et al.Neighborhood rough set based heterogeneous feature subset selection[J]. Information Sciences,2008,178(18):3577-3594.
[10] Miao Duo-qian.Information representation of the conce-pts and operations in rough set theory[J].Journal of Soft-ware,1999,22(2):113-116.
[11] Beaubouef T,Petry F E,Arora G.Information-theoretic measures of uncertainty for rough sets and rough relation-al databases[J].Information Sciences,1998,109(1-4):185-195.
[12] Chen Yu-ming,Wu Ke-shou,Chen Xu-hui,et al.An ent-ropy-based uncertainty measurement approach in neighbo-rhood systems [J].Information Sciences,2014,279(9):239-250.
[13] Qian Yu-hua,Ling Ji-ye.Combination entropy and com-bination granulation in rough set theory[J].International Journal of Uncertainty Fuzziness and Knowledge-Based Systems,2011,16(2):179-193.
[14] Lu Juan,Li De-yu,Zhai Yan-hui,et al.A model for type-2 fuzzy rough sets[J].Information Sciences,2016,328(C):359-377.
[15] Hu Qing-hua,Zhang Lei,Zhang David,et al.Measuring relevance between discrete and continuous features based on neighborhood mutual information[J].Expert Systems with Applications,2011,38(9):10737-10750.
[16] Hu Qian-hua,Che Xun-jian,Zhang Lei,et al.Feature evaluation
and selection based on neighborhood soft margin[J].Neurocomputing,2010,73(10-12):2114-2124.
[17] Huang Guo-shun,Zeng Fan-zhi,Wen Han.Uncertainty measures of rough set based on conditional possibility[J].Control and Decision,2015,30(6):1099-1105.
[18] Wang Guo-yin.Rough reduction in algebra view and information view[J].International Journal of Intelligent Systems,2003,18(6):679-688.
[19] Gao Hui-xuan.Applied multivariate statistical analysis[M].Beijing:Beijing University Press,2005:218-228.
[20] Wang Jing-long,Liang Xiao-yun.Nonparametric statistical analysis[M].Beijing:Higher Education Press,2006.
[21] Jia Jun-ping,He Xiao-qun,Jin Yong-jin.Statistics[M].Beijing:Renmin University of China Press,2012:226-230.
[22] Chen Yu-ming,Zeng Zhi-qiang,Tian Cui-hua.Uncertainty measures using entropy and neighborhood rough sets[J].Journal of Frontiers of Computer Science and Technology,2016,10(12):1793-1800.
附中文参考文献:
[8] 胡清华,于达仁,谢宗霞.基于邻域粒化和粗糙逼近的数值属性约简[J].软件学报,2008,19(3):640-649.
[17] 黄国顺,曾凡智,文 翰.基于条件概率的粗糙集不确定性度量[J].控制与决策,2015,30(6):1099-1105.
[19] 高惠璇.应用多元统计分析[M].北京:北京大学出版社,2005:218-228.
[20] 王静龙,梁小筠.非参数统计分析[M].北京:高等教育出版社,2006.
[21] 贾俊平,何晓群,金勇进.统计学[M].北京:中国人民大学出版社,2012:226-230.
[22] 陈玉明,曾志强,田翠华.邻域粗糙集中不确定性的熵度量方法[J].计算机科学与探索,2016,10(12):1793-1800.
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
聊城大学学报(自然科学版)(2022年5期)2022-10-29
农业工程学报(2022年7期)2022-07-09
闽南师范大学学报(自然科学版)(2022年1期)2022-03-28
逻辑学研究(2021年3期)2021-09-29
波谱学杂志(2021年3期)2021-09-07
计算机应用(2021年4期)2021-04-20
小型微型计算机系统(2019年10期)2019-11-11
小型微型计算机系统(2019年9期)2019-09-09
计算机与数字工程(2019年8期)2019-09-03
