
一种基于隐树模型的满足差分隐私的高维数据发布算法
2018-04-13 10:16苏炜航
小型微型计算机系统 2018年4期
苏炜航,程 祥
1(中国人民大学 附属中学,北京 100080) 2(北京邮电大学 网络与交换技术国家重点实验室,北京 100876) E-mail:chengxiang@bupt.edu.cn
1 引 言
随着大数据时代的到来,不同部门、不同地区间的信息共享需求逐步增加.数据发布是打破信息孤岛,实现信息共享的一种重要手段.由于高维数据(例如,医疗健康数据、金融数据等)中蕴含着丰富的信息,分析或挖掘高维数据能够提供有效的决策支持.现如今,高维数据已经成为数据发布的重要数据类型.然而,如果所发布的高维数据涉及个人敏感信息,直接发布这些数据会造成严重的个人隐私泄露.
近年来提出的差分隐私[1](Differential Privacy)技术为解决数据分析、数据发布带来的个人隐私泄露问题提供了一种可行的方案[2-6].与传统的基于匿名的隐私保护模型(例如,k-匿名[7]和l-多样性[8])不同,差分隐私提供了一种严格、可量化的隐私保护手段,并且所提供的隐私保护强度并不依赖于攻击者所掌握的背景知识.差分隐私通过在数据处理过程中添加随机噪音以达到隐私保护的目的,并确保在数据集中插入或删除某一条记录不会显著地影响输出结果.因此,即使攻击者获得了数据集中除一条记录之外的其他所有记录的信息,差分隐私仍可以保证攻击者不能通过所掌握的其他记录信息推断出该条记录中蕴含的敏感信息,从而有效地保护了数据集中包含的个人隐私信息.正是因为上述优点,差分隐私技术已经得到了学术界和工业界的广泛关注.
本文提出了一种基于隐树模型的满足差分隐私的高维数据发布算法(记为LTMDP).该算法通过隐变量生成、隐树结构学习、隐树参数学习和数据生成四个阶段实现了满足差分隐私的高维数据发布.特别地,在该算法中,为了在显变量分组及生成隐变量的过程中保护隐私,本文提出了一种满足差分隐私的隐变量生成方法(记为DPLAG).此外,为了在构建隐树的过程中保护隐私,我们提出了一种满足差分隐私的隐树模型结构学习方法(记为DPSL).理论分析表明所提出的LTMDP算法满足ε-差分隐私.实验结果表明,与现有研究工作相比,所提出的LTMDP算法可以在保证相同隐私强度的情况下获得更好的数据效用.
2 相关工作
针对满足差分隐私的数据发布问题,国内外研究人员已经取得了一定成果. 其中,Qi[2]等人提出了PCA-based PPDP算法,该算法采用拉普拉斯机制,直接分解原始数据的协方差矩阵,随后在投影矩阵上添加噪音,并基于线性判别分析对发布数据的分类问题进行了优化.然而,使用该方法所发布的数据集只支持分类任务.Day[9]等人提出了DPSense算法,该算法引入低敏感度质量函数,将敏感度限制在一定的范围内,并引入了一个比例因子,用于纠正限制敏感度所引起的误差.然而,该算法只适用于发布数据的统计信息,因此,并不适用于本文的问题场景.
特别地,针对满足差分隐私的高维数据发布问题,Zhang[10]等人提出了PrivBayes算法,该算法在满足差分隐私的条件下使用贝叶斯网络模型近似高维数据属性间的联合概率分布,然后利用所学习的贝叶斯网生成高维数据集.此外,Chen[11]等人提出了JTree算法,该算法利用高维数据属性间的依赖关系构建属性依赖图,并根据该图所确定的边际分布表来估计属性间的联合概率分布.与上述两种算法不同,本文基于隐树模型提出了一种满足差分隐私的高维数据发布算法LTMDP.与上述两种算法相比,采用隐树模型对高维数据进行建模可以大量减少所需计算关联强度的属性对数量,从而减少噪音的摄入量,获得更好的数据效用.
3 预备知识
3.1 差分隐私
给定任意两个数据集D和D′,假设D和D′相差且仅相差一条记录,称这两个数据集为相邻数据集.差分隐私保护模型的具体定义如下.
定义1(ε-差分隐私).给定算法A,假设数据集D和D′为任意相邻数据集.对于算法A的任意可能输出结果S,如果算法A在数据集D中输出S的概率与算法A在数据集D′中输出S的概率的比值满足
Pr[A(D)∈S]≤exp(ε)×Pr([A(D′)∈S])
(1)
我们称算法A满足ε-差分隐私.
在数据集D中加入或者删除一条记录后,函数f输出结果的最大改变量称为函数f的敏感度,其定义如下.
定义2(敏感度).对于函数f,其敏感度为:
Δf=max‖f(D)-f(D′)‖
(2)
其中,数据集D和D′是任意相邻数据集.
定理1(拉普拉斯机制).对于敏感度为Δf的函数f,随机算法A(D)=f(D)+Lap(λ)满足ε-差分隐私,其中Lap(λ)是服从λ=Δf/ε的拉普拉斯分布.
定理2(指数机制).给定数据集D,输出空间R和打分函数u,对于一个随机算法A,如果
(3)
则算法A满足ε-差分隐私,其中Δu是打分函数u的敏感度.
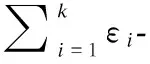
定理4(并行性质).给定k个满足差分隐私的算法A1,…,Ak.其中,任意算法Ai满足εi-差分隐私.如果算法A1,…,Ak分别作用于不相交的数据集D1,…,Dk上,那么算法A1,…,Ak构成的组合算法满足max{ε1,…,εk} -差分隐私.
3.2 隐树模型
隐树模型[12]是一种树状的概率图模型,它能够体现一系列随机变量的联合概率分布情况.在隐树模型中,叶子节点代表数据中的可见属性(即显变量),内部节点代表隐含属性(即隐变量).显变量X={X1,…,Xm}和隐变量Y={Y1,…,Yn}所代表的节点一起组成了顶点集V={V1,…,Vn,Vn+m},顶点之间的边E代表了顶点之间的依赖关系.如果顶点Vj到顶点Vi之间存在一条有向边,那么定义顶点Vj是顶点Vi的父节点,Vj也可以用Πi表示.图1给出了一个隐树模型的例子.树结构T满足以下独立性假设:对于每个节点Vi,给定父节点Πi,Vi与Πi的他的子节点独立.隐树模型中涉及的所有变量的联合概率分布可以表示为:
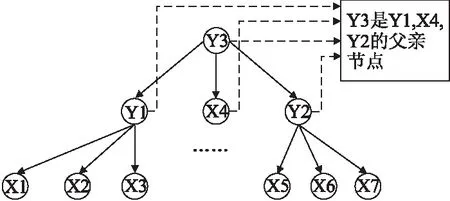
图1 隐树模型示例图 Fig.1 Example latent tree model
(4)
通过公式(4),可以进一步得到显变量之间的联合概率分布
PrT(X)≈∑y1∈ΩY1…∑ym∈ΩYmPr(V)
(5)
其中ΩYi是Yi的取值空间.
学习隐树模型的基本步骤如下:1)根据显变量之间的关联强度对显变量进行分组,并为每一个分组产生一个隐变量;2)根据隐变量之间的关联强度构建隐树;3)对于隐树中除根节点外的每一个节点Vi,计算条件概率分布Pr(Vi|Πi).
我们通常把步骤2称为隐树模型的结构学习阶段,把步骤3称作隐树模型的参数学习阶段.
给定高维数据集D和其属性集X,通过在D上学习隐树模型可以近似表示数据集D上所有属性的联合概率分布.
4 LTMDP算法
4.1 LTMDP算法概述
为了降低在高维数据发布过程中加入的噪音量,提高所发布数据的效用,同时满足差分隐私保护,我们提出了一种基于隐树模型的满足差分隐私的高维数据发布算法(记作 LTMDP).
LTMDP算法由隐变量生成、隐树结构学习、隐树参数学习、数据生成四个阶段组成.其中前三个阶段需要直接或者间接地访问原始数据集,因此需要在这三个阶段中提供差分隐私保护.特别地,我们将总体隐私参数ε分为三个部分(ε1=ε2=ε3=ε/3),分别用于这三个阶段.LTMDP算法四个阶段的概述如下.
1)隐变量生成.在此阶段中,我们首先计算显变量X={X1,…,Xm}之间的互信息作为它们之间的关联强度,对显变量进行分组,然后为每一个分组生成一个隐变量,从而得到隐变量组成的数据集D*.为了在满足差分隐私的条件下对显变量进行分组并生成隐变量,我们提出了一种满足差分隐私的隐变量生成方法(记作DPLAG),详见章节4.2.
2)隐树模型结构学习.此阶段完成隐树模型结构的构建.为此,我们提出了一种满足差分隐私的隐树模型结构学习方法(记作DPSL).在该方法中,我们首先在满足差分隐私的条件下计算隐变量Y={Y1,…,Yn}之间的互信息作为它们之间的关联强度,然后以隐变量之间的关联强度作为隐变量间所连边的权值,构建一棵最大生成树.最后,我们随机选择一个隐变量作为根节点,并根据各个隐变量与根节点的距离确定各个隐变量之间的父子关系,从而得到隐树结构,详见章节4.3.
3)隐树模型参数学习.在满足差分隐私的条件下,对于隐树中的每一个显变量节点,我们计算在给定其父节点条件下的概率分布.特别地,我们首先统计每个显变量节点与其父节点的联合概率分布,并在计算过程中加入拉普拉斯噪声.然后,我们利用带有噪音的联合分布计算出除根节点外的每一个节点在给定其父节点条件下的概率分布.
4)数据生成.通过学习到的隐树模型,我们采用自顶向下的方式对隐变量和显变量的取值进行采样,从而生成满足差分隐私保护的高维数据集.
4.2 满足差分隐私的隐变量生成方法
为了在满足差分隐私的条件下生成隐变量,我们提出了满足差分隐私的隐变量生成方法(记作DPLAG).该方法在满足差分隐私的条件下,对显变量X={X1,…,Xm}进行分组,并生成隐变量Y={Y1,…,Yn}.
在不考虑隐私保护的场景下,Steeg等人[13]提出了Corex方法来生成隐变量.对于一组显变量X,Corex方法通过计算它们之间的互信息来度量它们之间的关联强度TC(X):
(6)
其中H(·)代表了熵值计算函数,m为X中显变量的个数.对于一组显变量X,在给定一个隐变量Yj的条件下,它们之间的关联强度为:
(7)
隐变量Yj与一组显变量X之间的关联强度可以通过以下方式计算:
(8)
为一组显变量X={X1,…,Xm}生成隐变量Y={Y1,…,Yn},可以看作是对式(8)的优化过程:
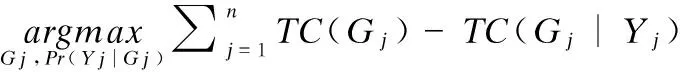
(9)
其中,Gj是X的一个子集,它对应于隐变量Yj.
Corex方法的目标是为每个显变量找到合适的分组Gj和相应的隐变量Yj,使得隐变量Yj能够很好的表示Gj中的显变量.Corex方法交替更新分组关系{G1,…,Gn}和隐变量{Y1,…,Yn},多次迭代直至式(9)的值达到收敛.
为了使上述过程满足差分隐私,一种简单的方法是在迭代的过程中直接加入拉普拉斯噪音.然而,由于高维数据集属性数量多,该方法需要多次访问原始数据集,并在每次访问过程中加入噪音来保证差分隐私.因此,这种简单的方法会严重影响数据效用.
我们观察到,由于对于每一个显变量Xi∈Gj,Xi和Gj中其它节点的关联强度应比Xi和其他分组中节点的关联强度高,因此,我们可以依据显变量之间的关联强度提前确定分组关系.基于以上观察,我们提出了满足差分隐私的隐变量生成方法(记作DPLAG).在DPLAG方法中,我们不再交替优化显变量分组结果和隐变量生成结果,而是将生成隐变量的过程分为确定显变量分组和隐变量生成两个步骤.算法1给出了满足差分隐私的隐变量生成方法DPLAG的细节.
算法1. 满足差分隐私的隐变量生成
输入:高维数据集D和其属性集X,每个分组中变量的最大个数c,隐私参数ε1
输出:显变量分组集合G,隐变量集合Y,隐变量数据集D*
1:初始化X′=X,G=Ø,Y=Ø;
2:m=|X|,n=「m/c⎤,k=0,j=0;
3:whilej≤ndo
4:Gj=Ø;
5:j++;
6:endwhile
7:j=0;
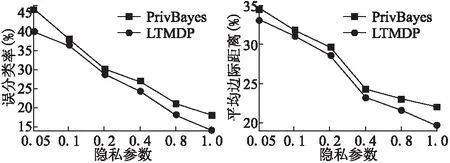
8:whilek 9:ifk可以被c整除then 10:j++; 11: 从X′中随机选出显变量Xr; 12:else 13:for每一个显变量Xi∈X′do 14: 计算Xi与Gj的互信息I(Xi;Gj); 15:endfor 17:endif 18:Gj=Gj∪{Xr}; 19:G=G∪Gj; 20:X′=X′/{Xr}; 21:k++; 22:endwhile 23:根据G,生成隐变量所对应的数据集D*; 24:returnG,YandD*; 在DPLAG 算法的第一阶段(第8 行到第22 行),我们首先以显变量之间的互信息作为衡量指标,将数据集中的显变量X={X1,…,Xm}分为多组,并使得同一组内的显变量之间具有较高的关联强度.为了满足ε-差分隐私保护,我们在对显变量进行分组的过程中应用差分隐私指数机制.在DPLAG 算法的第二阶段(第23 行),我们基于拉格朗日优化方法,为每个确定的显变量分组Gj∈G,生成一个对应的隐变量Yj,从而得到隐变量对应的集合D*. 为了在满足差分隐私的条件下,利用已生成的隐变量构建隐树,我们提出一种满足差分隐私的隐树模型结构学习方法(记作DPSL).在DPSL 方法中,我们采用互信息作为隐变量间关联强度的衡量标准,并在隐变量互信息计算过程中加入拉普拉斯噪声来保证差分隐私.特别地,对于每个显变量,我们将其所在分组对应的隐变量作为它的父节点;对于任意两个隐变量,我们将它们之间的互信息作为它们之间连接边的权值.接着,我们采用最大生成树算法得到隐树结构T,并随机选择一个隐变量作为T的根节点.算法2给出了满足差分隐私的隐树模型结构学习方法DPSL的细节. 算法2. 满足差分隐私的隐树模型结构学习 输入:隐变量数据集D*和其属性集Y,隐私参数ε2 输出:隐树模型的结构T 1:for每两个隐变量Yi,Yj∈Ydo 3: 根据Pr(Yi,Yj)计算Yi与Yj的互信息I(Yi;Yj) ; 4:endfor 5: 将所有隐变量之间边的权值设置为它们的互信息; 6: 采用最大生成树算法生成隐树模型的结构T; 7: 从Y中随机选择一个隐变量做为T的根节点R; 8:returnT; 引理1.隐变量生成方法DPLAG 满足ε1-差分隐私. 引理2.隐树模型结构学习方法DPSL满足ε2-差分隐私. 证明:隐树模型结构学习方法包括隐变量互信息计算和隐树结构生成两个阶段.其中,隐树结构生成这一阶段并不需要访问原始数据集D或隐变量数据集D*,因此无须提供差分隐私保护D*.然而,在隐变量互信息计算阶段,我们需要访问隐变量数据集 获得任意两个隐变量的联合分布.在此过程中,我们需要提供差分隐私保护. 给定一个转换函数Γ:D*=Γ(D),和一个统计函数S:Pr(Y)=S(D*),存在一个函数满足φ=s∘Γ且Pr(Y)=φ(D),其中,D和D*分别由显变量X={X1,…,Xm}的取值和隐变量Y={Y1,…,Yn}的取值组成.因此,隐变量的联合分布可以通过在数据集D上执φ行函数来得到.对于任意两个相邻数据集D和D′,函数φ的敏感度是: S(φ) =‖φ(D)-φ(D′)‖ =‖Pr(Y|D)-Pr(Y|D′)‖ =∑y∈ΩY|Pr(y|D)-Pr(y|D′)|≤4/|D*| (10) 引理3.隐树模型参数学习阶段满足ε3-差分隐私. 定理5.所提出的算法LTMDP 满足ε-差分隐私. 证明:LTMDP 算法由四个阶段组成,其中数据生成阶段不需要访问原始数据集D或隐变量数据集D*,因此不需要提供差分隐私保护.由引理1、引理2 和引理3 可知,LTMDP算法的隐变量生成阶段、隐树模型结构学习阶段和隐树模型参数学习阶段分别满足ε1-差分隐私、ε2-差分隐私和ε3-差分隐私.根据差分隐私的串行性质,LTMDP满足ε-差分隐私,其中ε=ε1+ε2+ε3. 为了验证LTMDP算法的性能,本文将文献[10]中提出的PrivBayes算法作为对比算法,并分别在TPC-E[14]和Big5[14]两个真实数据集上对这两个算法进行了性能测试.TPC-E数据集共含有40000条记录,每条记录包含24个属性的信息,其中,一部分属性的取值是离散值,另一部分属性的取值是连续值;Big5数据集共含有19719条记录,每条记录包含57个属性的信息,每个属性反映某一个体对问卷调查中的相关问题的态度,共有五种可能的取值:同意,轻微同意,中立,轻微反对,反对. 在实验之前,本文进行了以下预处理过程:采用文献[15]中的方法将非二进制属性转换为多个二进制属性.经过转换,TPC-E和Big5两个真实数据集中每条记录包含的二进制属性个数分别为77个和175个.因为该转换操作只与属性的公共取值空间有关,因此,转换过程中没有涉及任何敏感信息,不需要考虑隐私泄露问题. 为了评估算法所生成数据集的效用,本文在生成的数据集上测试了两种分析任务的性能.第一个分析任务是α-边际分布(α-way marginal)计算.在实验中,本文分别在两个数据集上进行了2-边际分布测试.具体地讲,我们计算生成数据集中各属性与原始数据集中各属性的2-边际分布的总边际距离[16](total variation distance),并将所有属性的2-边际分布的平均边际距离(average variation distance)作为衡量标准,来评估生成数据集的α-边际分布的准确性.第二个分析任务是SVM分类.具体地讲,本文在生成的数据集上训练多个SVM分类器,在每个SVM分类器中,取一个属性作为分类结果,并用其他所有属性作为特征来训练SVM分类器,从而对该属性的取值进行预测.另外,对于每个分类任务,我们采用生成数据集中80%的数据作为训练集,剩下20%的数据作为测试集.进一步,本文采用误分类率(misclassification rate)作为衡量标准,来评估生成数据集的SVM分类任务的准确性. 所有的实验在一台配置为Intel Core I7 2.7GHZ CPU、12GB RAM的PC机上运行.由于测试算法均为随机算法,本文将每种分析任务运行20次,并将每次输出结果的平均值作为最终的实验结果. 图2和图3分别展示了PrivBayes算法和LTMDP算法在TPC-E数据集上的2-边际分布的平均边际距离结果和误分类率结果.TPC-E数据集的属性个数有24个,对非二进制属性进行二进制转化之后,二进制属性共有77个.随着属性个数的增加,LTMDP算法的优势逐渐显现了出来,在隐私参数相同时,LTMDP算法的平均边际距离和误分类率均小于PrivBayes算法.这说明LTMDP算法可以获得更高的数据效用. 图2 TPC-E数据集上SVM分类结果Fig.2 ResultsofSVMonTPC-E图3 Big5数据集上SVM分类结果Fig.3 ResultsofSVMonBig5 图4和图5分别展示了PrivBayes算法和LTMDP算法在Big5数据集上的2-边际分布的平均边际距离结果和误分类率结果.与TPC-E数据集相比,Big5数据集维度更高,属性个数有57个,对非二进制属性进行二进制转化之后,二进制属性共有175个.可以看出,在更高维度的数据集上,LTMDP算法的优势更加明显,平均边际距离和误分类率明显小于PrivBayes算法.这是因为随着属性个数的增加,PrivBayes算法在构建贝叶斯网络结构(结构学习阶段)时,构造出的属性-父节点对(attribute-parent pair)的数量呈平方级增长,而在构造每个属性-父节点对时,都需要访问原始数据集计算其关联强度,这个过程中需要添加大量的噪声,导致数据效用偏低.而对于LTMDP算法,在结构学习阶段构建隐树模型时,只需要确定少量隐含属性的连接结构,进一步使参数学习阶段需要计算关联强度的属性对数量大大减少,从而保证了良好的数据效用. 图4 TPC-E数据集上2-边际分布结果Fig.4 Resultsof2-waymarginalsonTPC-E图5 Big5数据集上2-边际分布结果Fig.5 Resultsof2-waymarginalsonBig5 隐私保护的高维数据发布具有重要的理论和现实意义.基于隐树模型,本文提出了一种新的满足差分隐私的高维数据发布算法LTMDP.分析结果表明LTMDP算法满足-差分隐私.在真实数据集上获得的实验结果表明,与现有算法相比,本文提出的算法能够在相同的隐私保护强度下获得更好的数据效用. [1] Dwork C,McSherry F,Nissim K,et al.Calibrating noise to sensitivity in private data analysis[C].Theory of Cryptography Conference,2006:265-284. [2] Qi Ming-yu,Huang Liu-sheng,Lu Xiao-rong,et al.Differential privacy data publish algorithm with compont analysis[J].Journal of Chinese Computer Systems,2017,38(3):437-443. [3] Lu Ye,Lu Jing.Differential privacy and prefix tree based research for search log privacy protection[J].Journal of Chinese Computer Systems,2016,37(3):540-544. [4] Ye Yun,Yu Yong,Huang Liu-sheng,et al.Privacy-preserving top-m DK-Outlier based outlier detection[J].Journal of Chinese Computer Systems,2016,37(12):2638-2642. [5] Gan Wen-yong,Wu Ying-jie,Sun Lan,et al.Frequent pattern mining with differential privacy based on transaction truncation[J].Journal of Chinese Computer Systems,2015,36(11):2583-2587. [6] Li Yang,Hao Zhi-feng,Xiao Yan-shan,et al.Multidimensional data visualization using aggregation method of differential privacy equipartition k-means[J].Journal of Chinese Computer Systems,2013,34(7):1637-1640. [7] Sweeney L.K-Anonymity:a model for protecting privacy[J].International Journal of Uncertainty,Fuzziness and Knowledge-Based Systems,2002,10(5):557-570. [8] Machanavajjhala A,Gehrke J,Kifer D,et al.L-Diversity:Privacy beyond k-anonymity[J].ACM Transactions on Knowledge Discovery from Data,2007,1(1):3. [9] Day W,Li N.Differentially private publishing of high-dimensional data using sensitivity control[C].Symposium on Information,Computer and Communications Security,2015:451-462. [10] Zhang J,Cormode G,Procopiuc C,et al.Privbayes:private data release via bayesian networks[C].Special Interest Group on Management of Data,2014,1423-1434. [11] Chen R,Xiao Q,Zhang Y.Differentially private high-dimensional data publication via sampling-based inference[C].International Conference on Knowledge Discovery and Data Mining,2015:129-138. [12] Choi M,Tan V,Anandkumar A,et al.Learning latent tree graphical models[J].Journal of Machine Learning Research,2011,12(5):1771-1812. [13] Steeg G V,Galstyan A.Discovering structure in high-dimensional data through correlation explanation[C].Annual Conference on Neural Information Processing Systems,2014:577-585. [14] Bache K,Lichman M.Uci machine learning repository[C].The Principles of Database Systems Symposium,2013. [15] Yaroslavtsev G,Cormode G,Srivastava D.Accurate and efficient private release of datacubes and contingency tables[C].International Conference on Data Engineering,2013:745-756. [16] Tsybakov A.Introduction to nonparametric estimation[M].Springer Series in Statistics,Berlin,Springer,2009. 附中文参考文献: [2] 戚名钰,黄刘生,陆潇榕,等.采用成分分析的差分隐私数据发布算法[J].小型微型计算机系统,2017,38(3):437-443. [3] 陆 叶,卢 菁.基于差分隐私与前缀树的搜索日志隐私保护研究[J].小型微型计算机系统,2016,37(3):540-544. [4] 叶 云,余 勇,黄刘生,等.一种基于top-m DK-Outlier的隐私保护异常数据检测算法[J].小型微型计算机系统,2016,37(12):2638-2642. [5] 甘文勇,吴英杰,孙 岚,等.基于事务截断的差分隐私频繁模式挖掘算法[J].小型微型计算机系统,2015,36(11):2583-2587. [6] 李 杨,郝志峰,肖燕珊,等.差分隐私DPE k-means数据聚合下的多维数据可视化[J].小型微型计算机系统,2013,34(7):1637-1640.
4.3 满足差分隐私的隐树模型结构学习
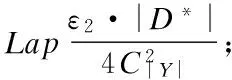
4.4 隐私分析
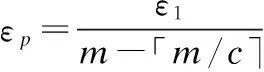
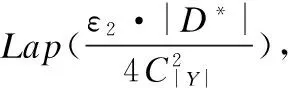
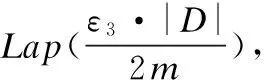
5 实验评估
5.1 实验设置
5.2 实验结果


6 结束语
猜你喜欢
数学杂志(2022年5期)2022-12-02
湘潭大学自然科学学报(2022年2期)2022-07-28
计算技术与自动化(2022年1期)2022-04-15
计算机技术与发展(2020年2期)2020-04-15
小学生学习指导(低年级)(2019年3期)2019-04-22
小学生学习指导(低年级)(2018年9期)2018-09-26
世界知识画报·艺术视界(2017年7期)2017-07-27
小学生导刊(低年级)(2017年1期)2017-06-12
计算机应用(2016年10期)2017-05-12
今日中国(2017年3期)2017-03-31
