
三维视频的深度图快速编码算法*
2018-03-21 00:56:17韩雪,冯桂
通信技术 2018年3期
韩 雪,冯 桂
(华侨大学 信息科学与工程学院,福建 厦门 361021)
0 引 言
近年来,3D设备越来越多地应用于生活的方方面面。3D视频的数据量大大增加,给编码和传输带来了难题。如何高效编码三维视频,已经成为研究的热点。联合视频编码小组(Moving Picture Expert Group,MPEG)基于传统2D视频编码标准——高性能视频编码(High Efficient Video Coding,HEVC),以多视点加深度图(Multi-view Video plus Depth,MVD)为编码格式,在HEVC编码标准基础上,提出了编码3D视频的3D-HEVC编码标准[1-2]。MVD的格式需要编码几个不同视点的纹理图及其对应的深度图,再利用基于深度图的绘制(Depth-Image-Based Rendering,DIBR)技术,合成任意位置的视频信息[3]。
不同视点的采集通过一系列同样高度、角度不同的摄像头完成。3D-HEVC标准测试平台的测试序列使用三视点[4]。根据编码时是否参考其他视点,分为一个独立视点和两个非独立视点。在非独立视点,根据采集视图与独立视点视频的相对位置,分为左视点和右视点。编码独立视点主要利用空域和时域的冗余性降低编码复杂度,非独立视点的编码还存在视点间的冗余性。深度图反映了物体与相机的距离,是灰度图像。灰度值大,表示距离相机较近;灰度值小,表示距离相机较远[5]。图1、图2依次展示了分辨率为1 028×768的一组3D-HEVC测试序列Balloons的纹理图及其对应的深度图。对比纹理图和深度图,发现平坦区域在深度图占据的比例更大,但物体的边界处较锋利,物体与背景的交界常呈锯齿状[6]。针对深度图的特性,3D-HEVC改进深度图的帧内预测过程,不仅沿用HEVC编码标准对CU的四叉树分割方式和35种帧内预测模式,还增加了两种深度建模模式(Depth Modeling Mode,DMM),分别是楔形分割(Wedgelet Partition,DMM1)和轮廓分割(Contour Partition,DMM4)。以上两种模式采用不规则的划分方式,能更精确地表示深度图的锯齿状边缘,但增加了编码复杂度[7]。

图1 序列Balloons的纹理图

图2 序列Balloons的深度图
针对深度图帧内预测的快速算法,大致可分为两类,一类是减少帧内预测模式的检测数目,一类是针对四叉树分割模型的CU尺寸快速决策算法。化简帧内模式数目的快速算法有:文献[8]根据哈达玛变换后的矩阵判断当前CU是否含有水平或者垂直边缘;文献[9]利用Canny算子判断当前CU的方向性,对35种帧内模式和DMM模式先做分类,目的是减少需要遍历的模式数目。化简四叉树分割的算法有:文献[10]利用已编码纹理图的CU编码信息,对当前CU的帧内模式数目和四叉树分割方式做简化;文献[11]把CU是否继续分割建立成逻辑回归函数模型;文献[12]获取帧内预测中不同模式下的率失真代价,根据阈值预估计CU的分割深度。然而上述算法都未利用3D-HEVC的视点间相关性。针对CU的空域和时域相似性的快速算法效率不高,且对快速运动的序列的效果较差。利用算子对平坦CU提前判决的算法,准确度受选取的检测方法和阈值影响很大。
本文主要研究深度图中CU的特点和不同视点的相关性,分析和检测Otsu’s算子对深度图CU的适用性,提出了基于Otsu’s算子的CU尺寸提前决策算法。具体地,先用Otsu’s算子计算CU的最大类间方差,对平坦CU提前决策最佳尺寸和跳过其他深度的遍历。利用视点相关性,编码非独立视点中的CU时,参考独立视点的已编码CU的深度信息和最佳预测模式。实验结果表明,本文算法在合成视点质量基本不变的情况下,有效降低了深度视频帧内编码的复杂度。
1 深度图帧内预测过程
1.1 帧内预测和复杂度分析
3D-HEVC采用四叉树的编码结构,即待编码图像以64×64大小的最大编码单元(Largest Coding Unit,LCU)作为四叉树分割的起始,不断递归分割成4个相同尺寸的子CU,直到分割为最小尺寸8×8的CU。以自下而上的顺序依次比较不同层的CU与四个子CU的率失真代价,选择率失真代价最小的CU尺寸作为LCU的最终分割结果。图3显示了深度图CU的四叉树分割方式。一个64×64大小的LCU需要逐级分割到尺寸8×8,对应深度级分别从0到3,并对每层的所有CU遍历帧内模式,计算率失真代价。深度图中,由于大面积为平坦区域,大部分LCU的最大分割深度为0或者1,只有纹理复杂的或是包含边缘的LCU会分割成更小的16×16尺寸或者8×8尺寸。由上述分析可知,如果能提前判断当前CU是否平坦,就能跳过一些不必要的分割过程。

图3 LCU四叉树分割方式
最佳帧内模式的决策,首先是粗略的模式选择。遍历35种预测模式,分别是Planar模式、DC模式和33种角度模式,计算每种模式对应的低复杂度的率失真代价,取率失真代价最小的3个或者8个帧内模式组成粗选模式列表——RMD列表(Rough Mode Decision,RMD)。RMD列表加入候选模式列表,根据左侧和上方相邻的已编码CU的最佳预测模式,推测三种最可能的预测模式(Most Probable Mode,MPM),并加入候选模式列表。遍历两种DMM模式,计算每种分割方式对应的最小均方误差SSE(Sum of Squared Error),从中选出最佳的DMM分割方式,并加入候选模式列表。对候选模式列表中的所有帧内模式分别计算率失真代价,将最小率失真代价对应的帧内预测模式作为当前CU的最佳帧内预测模式。深度图中,缓慢变化或平坦的CU较多,最佳帧内模式用Planar模式和DC模式的比例很大,新增的DMM模式则通常用于编码物体的边缘。DMM模式的编码时间占深度图编码总时间的20%,但选择DMM模式为最佳预测模式的CU约为1%。所以,如果能够提前判定当前CU是平坦的或者包含边缘,然后对不含边缘的CU跳过DMM模式的检测,将大大降低计算复杂度。
1.2 视点间相关性分析
多视点加深度的编码结构,采用先独立视点后非独立视点的顺序编码。不同的视点是由一组摄像机在不同的水平位移和不同角度下获取的,所采集的图像为相同场景,所以不同视点间的深度图具有很强的相关性。图4显示了序列Balloons的纹理图和深度图在第一帧时的三个视点的视频信息。从图4可以看出,三个视点展示同样场景,但有不同方向上的偏移,而不同视点间的相似程度很高。

图4 序列Balloons的纹理图和深度图第一帧的三视点图像
表1显示了对高分辨率的序列Poznan_Hall、Poznan_Street和低分辨率的序列Balloons、Kendo,统计非独立视点中LCU最终分割深度与独立视点相同位置的LCU分割深度相等的比例。从表1可以看出,相邻视点有70%以上的LCU分割深度相等。以上结果表明,相邻视点间存在很强的相关性。

表1 非独立视点LCU与对应独立视点LCU分割深度相等的概率
2 提出的算法
常用的纹理复杂度的检测方法有:文献[9]采用Canny边缘检测算子,边缘检测算子计算量较大,对图像噪声敏感;文献[13]利用角点检测算子,以LCU起始,对包含角点的区域继续分割,对不含角点的区域终止分割。角点检测算子能较大程度降低计算复杂度,但深度图的失真较大,合成视点的质量损失最大。文献[14]计算当前CU的方差,再与阈值比较,方差的方法计算量较小,但对编码时间的减小程度和准确率与阈值的选取有较大相关性,若CU中不同区域的像素值差异较小,则该CU的方差值可能非常小,用阈值难以区分平坦CU;文献[15]利用灰度共生矩阵分析LCU的纹理复杂度,根据矩阵中0的个数跳过DMM模式的检测,缺点是灰度共生矩阵的计算量太大,且编码时间减少较小。本文采用Otsu’s算子计算当前CU的最大类间方差,能很好地区分平坦区域和非平坦区域,检测准确率优于上述三种算子,且直方图经过均衡化处理,图像的噪声对Otsu’s算子的计算结果影响较小,是一种理想的检测CU纹理复杂度的方法。
2.1 基于Otsu’s算子的CU提前终止分割算法
Otsu’s算子广泛应用于图像分割领域,能够最佳地分离出图片中地背景和物体,其计算结果称为最大类间方差。最大类间方差代表图片的差异程度。最大类间方差值越大,代表图片内部像素分布的差异较大;最大类间方差值越小,代表图像内部像素分布接近。计算方法:图像根据灰度值k分成背景和物体两类,灰度值为[0,1,…,k]的所有像素组成类C1,灰度值为[k+1,…,255]的所有像素组成类C2[16]。遍历从0到255的阈值,求出一个最佳分割出来的类C1和类C2的阈值,使类间方差值最大。不同阈值下的类间方差的计算公式如下:
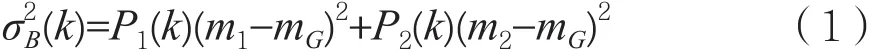
其中,P1(k)和P2(k)分别代表类C1和类C2在图像中所占的比例。m1、m2、mG分别代表类C1的平均灰度、类C2的平均灰度和整幅图像的平均灰度。有一种特殊情况,当最大类间方差值等于0时,代表图片中的像素值都相等。深度图表现了物体的相对距离,平坦区域所占比例最大,对于相对距离较近的物体,在深度图中表现为灰度差异小。所以,Otsu’s算子能够较好地检测出内部变化不明显的CU,更适应深度图的特征。
根据Otsu’s算子的特征,本文对深度帧中的独立视点的64×64到8×8尺寸的CU,用Otsu’s算子计算最大类间方差值把小于1的CU定义为平坦的。终止该CU继续分割,把当前尺寸作为最终分割结果。表2显示了深度图独立视点中不同尺寸CU的最大类间方差小于1时,CU终止继续分割的正确率。可以看出,本文提出的CU提前终止分割算法的正确率很高。
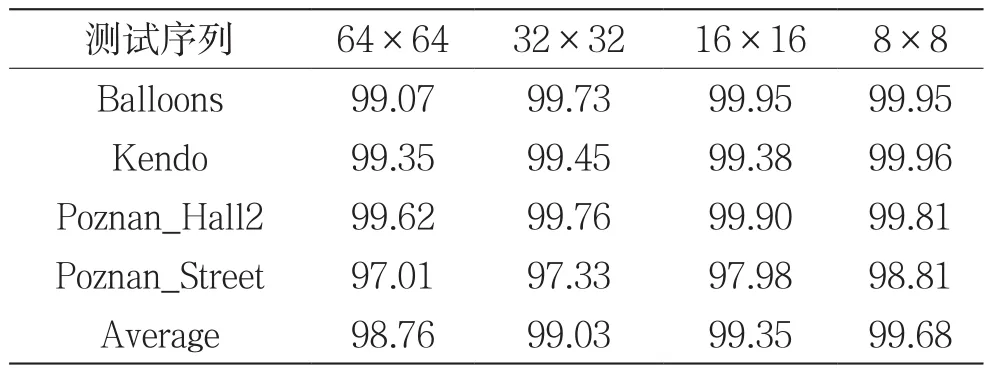
表2 深度图独立视点的CU在不同尺寸下提前终止分割算法的正确率(单位:%)
2.2 利用视点间相关性提前终止CU分割
因为3D-HEVC编码标准先编码独立视点,所以在编码非独立视点时可以参考独立视点的已编码CU。为了提前判决非独立视点中的平坦CU,不必对所有CU计算最大类间方差,可以参考独立视点对应CU的Otsu’s算子计算结果,节省编码时间,降低编码比特率。对于左视点,独立视点中相同位置的CU与左邻近CU与当前CU的相似程度较大;对于右视点,独立视点中相同位置的CU与右邻近CU与当前CU的相似程度较大。
本文深度图非独立视点CU的快速算法如下。若当前CU属于左视点,参考CU为独立视点相同位置的同位CU和左邻近CU。若当前CU属于右视点,参考CU为独立视点相同位置的同位CU和右邻近CU。若两个参考CU的最大类间方差值都小于1,则认定当前CU为平坦的,终止继续分割。表3统计了非独立视点中不同尺寸CU的提前终止分割算法的正确率。从表3可以看出,从64×64到8×8尺寸的CU的终止分割的正确率分别为93.61%、98.72%、99.48%和99.72%。对于小尺寸的CU,本文提出的算法的正确率较高。但是,对于64×64尺寸的LCU,本文算法的正确率较低。可见,仅以独立视点的相邻CU的最大类间方差与阈值的比较,不足以准确判断出平坦CU。所以,需要增加参考条件,提高对非独立视点的LCU提前终止分割算法的正确率。
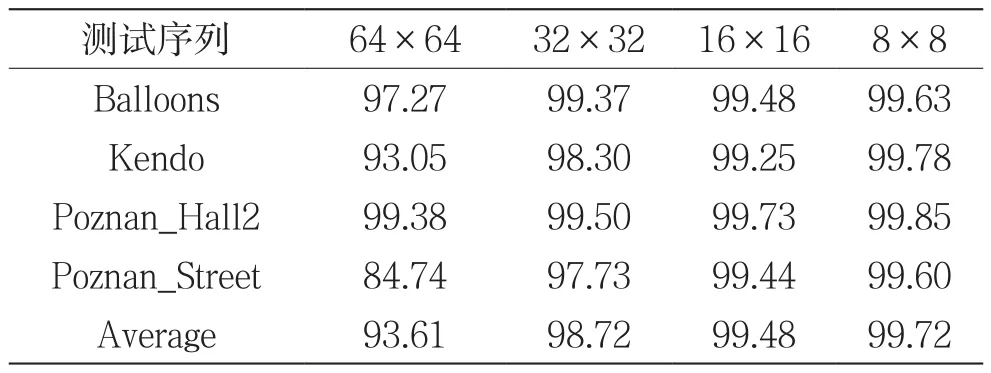
表3 深度图的非独立视点的不同尺寸CU提前终止分割算法的正确率(单位:%)
具体地,对于深度图非独立视点的64×64大小的LCU,仅用其对应独立视点的两个邻近CU的Otsu’s算子值同时小于1,不足以把当前CU判决为平坦。需要根据最佳帧内模式进一步做判断。若当前LCU经过帧内预测得到的最佳帧内模式为Planar模式或者DC模式,则当前CU判定为平坦的,终止其继续分割,而当前CU的尺寸为最佳分割尺寸。
基于以上分析和论述,对本文提出的算法进行整理,算法流程图如图5所示。
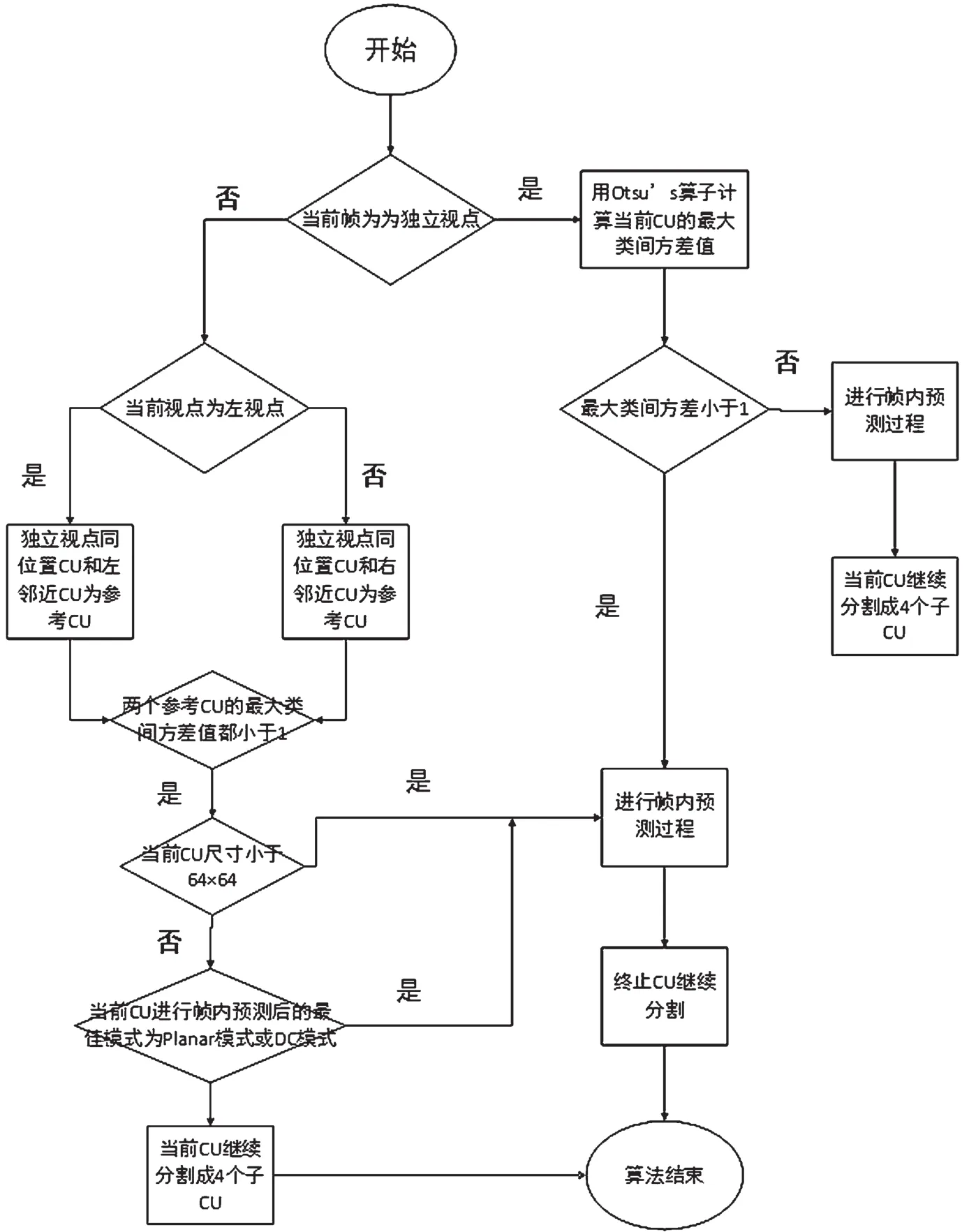
图5 算法流程
2.3 算法步骤
步骤1:判断当前视点是否为独立视点,如果是独立视点,执行步骤2;如果为非独立视点的左视点,执行步骤3。
步骤3:当前编码的CU属于左视点,且CU尺寸小于64×64,取对应的独立视点中相同位置的CU及左邻近CU作为参考块。若上述两个参考CU的σ2max值都小于1,则终止四叉树分割过程,把当前尺寸作为最佳分割尺寸;如果当前CU为64×64大小的LCU,则执行步骤4。
步骤4:对于左视点的LCU,检测在步骤3中提到的两个参考CU的值。若都小于1,则先对当前LCU进行帧内预测过程,获取最佳预测模式记为mode0_v1。若mode0_v1为Planar模式或DC模式,终止当前LCU的继续分割;否则,执行步骤7。
步骤5:当前编码的CU属于右视点,且CU尺寸小于64×64时,取对应的独立视点中相同位置的CU及其右邻近CU作为参考块。若上述两个CU的值都小于1,则终止四叉树分割过程,把当前尺寸作为最佳分割尺寸;如果当前CU为64×64大小的LCU,则执行步骤6。
步骤6:对于右视点的LCU,检测在步骤5中提到的两个参考CU的值。若都小于1,则先对当前LCU进行帧内预测过程,获取最佳预测模式记为mode0_v2。若mode0_v2为Planar模式或DC模式,终止当前LCU的继续分割;否则,执行步骤7。
步骤7:对当前CU进行传统的CU四叉树分割和帧内预测。
3 实验结果及分析
本文提出的算法在3D-HEVC测试平台HTM15.0上进行测试。在通用测试条件(Common Test Conditions,CTC)配置下,使用All-Intra配置文件,分别测试分辨率为1 024×768的3组序列Balloons、Kendo、Newspaper1,和分辨率为 1 920×1 088的5 组 序 列 GT_Fly、Poznan_Hall2、Poznan_Street、Undo_Dancer、Shark[17]。纹理图和深度图使用的量化参数为(25,34)、(30,39)、(35,42)、(40,45)。测试序列如表4所示。表5显示了文献[15]和本文提出的算法,分别与原始测试平台在编码复杂度和合成视点质量方面的对比。其中,∆BD-rate表示合成视点平均比特率的变化,∆T表示深度图的总编码时间减少。具体计算公式如下:
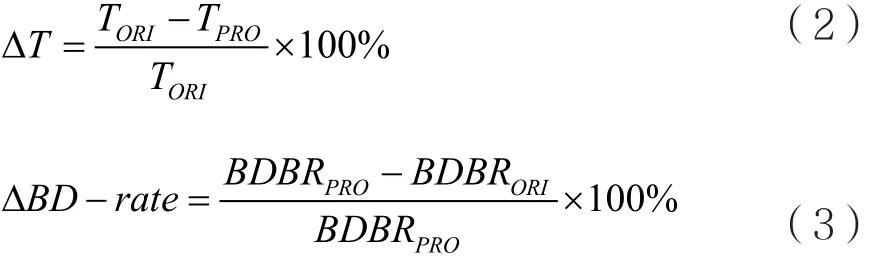
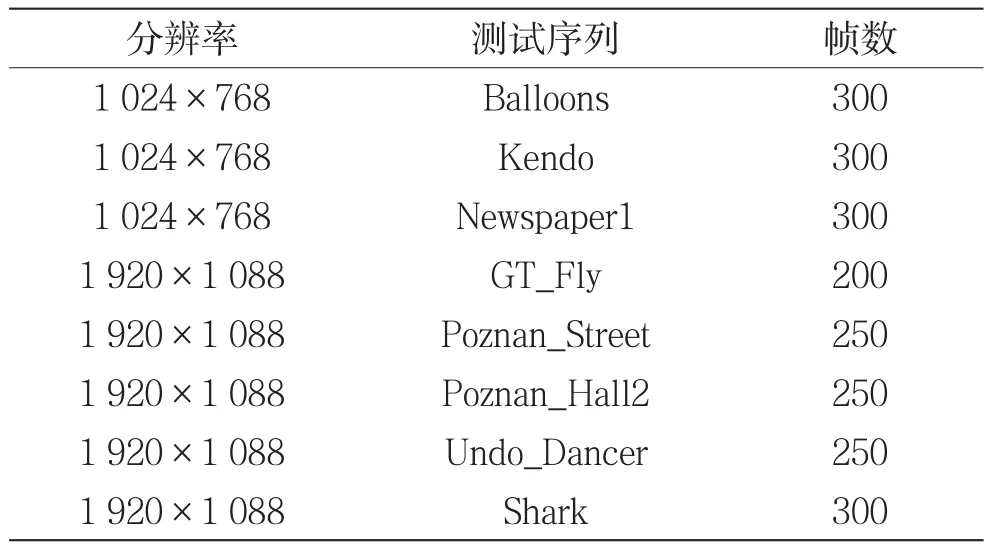
表4 标准测试序列
其中,BDBRPRO和BDBRORI分别表示本文提出的算法和原始算法的合成视点的平均比特率,TPRO和TORI分别表示本文提出的算法与原始算法的深度图编码时间。
表5是本文算法与文献[15]的对比。由实验结果分析可知,本文算法与HTM15.0平台的原始算法相比,深度图的平均编码时间减少25.68%,合成视点的平均比特率增加0.07%。其中,序列Poznan_Hall和Kendo的编码时间减少最多,分别减少了43.51%和35.57%。究其原因,在于上述两个序列对应的深度图的CU比较平坦,满足最大类间方差小于1的CU数目较多。此外,与文献[15]相比,本文算法在深度图编码时间上有较大改善。
图6和图7分别显示了分辨率为1 024×768的序列Newspaper1和分辨率为1 920×1 088的序列Poznan_Street,在量化参数为25时的合成视点质量的主观比较结果。图6是序列Newspaper1的主观质量比较。其中,图6(a)是原始算法的合成视点图像,图6(b)显示了加入本文算法后的合成图像。图7是序列Poznan_Street的主观质量比较结果。其中,图7(a)是原始算法的合成视点图像,图7(b)显示了加入本文算法后的合成图像。从主观比较的结果可以看出,本文提出的算法的合成视频图像能保持较高质量,与原始算法的合成视频基本无差异。
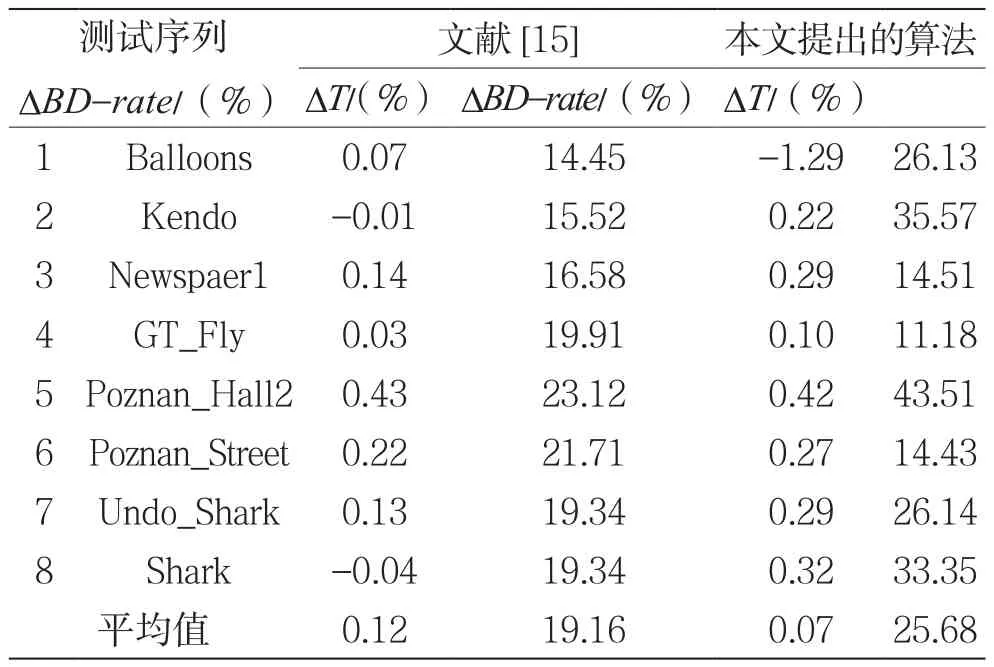
表5 本文算法与参考文献[15]的比较
4 结 语
本文基于深度图的特点,提出CU提前终止分割算法。用Otsu’s算子计算CU的最大类间方差,判断当前CU是否平坦,并结合视点间的关联性,用独立视点的CU分割信息判断非独立视点中的CU是否平坦,对平坦的CU跳过继续分割的过程。实验结果表明,本文算法与3D-HEVC参考模型HTM15.0的原始算法相比,时间减少25.68%。利用Otsu’s算子检测CU的纹理复杂度和利用多视点相似性具有一定创新性,且Otsu’s算子对平坦CU的判断准确率高于方差、边缘检测算子、灰度共生矩阵等一些常用方法,同时本文的实验结果与其他快速算法相比具有一定优势。此外,通过分析可知,本文算法对于序列GT_Fly和Poznan_Street的减少时间不多,因为上述序列的深度图存在大面积深度值缓慢变化的区域。因此,如何对包含渐变区域的CU编码做优化,将是下一步的工作重点。
[1] Ying C,Ye W.The Emerging MVC Standard for 3D Video Services[J].Eurasip Journal on Advances in Signal Processing,2009,2009(01):1-13.
[2] Merkle P,Smolic A,Muller K,et al.Multi-View Video Plus Depth Representation and Coding[C].IEEE International Conference on Image Processing,2007:201-204.
[3] Fehn C.Depth-Image-Based Rendering(DIBR),Compression,and Transmission for a New Approach on 3D-TV[J].Proceedings of SPIE-The International Society for Optical Engineering,2004(5291):93-104.
[4] Tech G,Chen Y,Müller K,et al.Overview of the Multiview and 3D Extensions of High Efficiency Video Coding[J].IEEE Transactions on Circuits & Systems for Video Technology,2016,26(01):35-49.
[5] Vetro A,Chen Y,Mueller K.HEVC-Compatible Extensions for Advanced Coding of 3D and Multiview Video[C].Data Compression Conference IEEE,2015:13-22.
[6] Muller K,Schwarz H,Marpe D,et al.3D High-Efficiency Video Coding for Multi-View Video and Depth Data[J].IEEE Transactions on Image Processing,2013,22(09):3366-3378.[7] Muller K R,Merkle P,Tech G,et al.3D Video Coding with Depth Modeling Modes and View Synthesis Optimization[C].Signal & Information Processing Association Summit and Conference IEEE,2012:1-4.
[8] Park C S.Edge-based Intramode Selection for Depthmap Coding in 3D-HEVC[J].IEEE Transactions on Image Processing,2015,24(01):155.
[9] Shi Y Y,Cao T F,Liang S Y.Intra Prediction Mode Selection for HEVC Based on Canny Operator[J].Computer Systems& Applications,2016,25(08):176-181.
[10] Han H M,Peng Z J,Jiang G Y.Region Segmentationbased Fast CU Size Decision and Mode Decision Algorithm for 3D-HEVC Depth Video Intra Coding[J].Opto-Electronic Engineering,2015,42(08):47-53.
[11] Hu Q,Shi Z,Zhang X,et al.Fast HEVC intra mode decision based on logistic regression classification[C].IEEE International Symposium on Broadband Multimedia Systems and Broadcasting IEEE,2016:1-4.
[12] Liu P,He G,Xue S,et al.A Fast Mode Selection for Depth Modelling Modes of Intra Depth Coding in 3D-HEVC[C].Visual Communications and Image Processing IEEE,2017:1-4.
[13] Zhang H B,Fu C H.Fast Coding Unit Decision Algorithm for Depth Intra Coding in 3D-HEVC[J].Journal of Electronics and Information Technology,2016,38(10):2523-2530.
[14] Peng K K,Chiang J C,Lie W N.Low Complexity Depth Intra Coding Combining Fast Intra Mode and Fast CU Size Decision in 3D-HEVC[C].IEEE International Conference on Image Processing IEEE,2016:1126-1130.
[15] Guo L,Tian X,Chen Y.Simplified Depth Intra coding for 3D-HEVC Based on Gray-level Co-occurrence Matrix[C].IEEE International Conference on Signal and Image Processing,2017:328-332.
[16] Cheriet M,Said J N,Suen C Y.A Recursive Thresholding Technique for Image Segmentation[J].IEEE Transactions on Image Processing A Publication of the IEEE Signal Processing Society,1998,7(06):918-921.
[17] Mueller K,Vetro A.Common Test Conditions of 3DV Core Experiments[S].Joint Colllaborative Team on 3D Video Coding Extensions (JCT-3V) of ITU_T VCEG and ISO/IEC MPEG,2014.
猜你喜欢
无线互联科技(2020年22期)2021-01-11 13:52:34
弹箭与制导学报(2020年2期)2020-09-01 02:08:56
计算机应用(2019年3期)2019-07-31 12:14:01
传感器与微系统(2018年7期)2018-08-29 00:44:42
自动化学报(2017年4期)2017-06-15 20:28:55
软件导刊(2016年9期)2016-11-07 22:22:57
科技视界(2016年2期)2016-03-30 11:17:03
河南电力(2016年5期)2016-02-06 02:11:24
新闻前哨(2015年2期)2015-03-11 19:29:22
中国水利(2015年5期)2015-02-28 15:12:40
