
网络小说IP的隐含价值量预测分析
——来自起点网的证据
2018-03-12 05:51:23赵礼强唐金环沈阳航空航天大学经济与管理学院沈阳110136
沈阳航空航天大学学报 2018年1期
赵礼强,姜 崇,唐金环 (沈阳航空航天大学 经济与管理学院,沈阳 110136)
知识产权(Intellectual Property)简称IP,是时下最为流行且备受关注的名词。网络小说IP的改编在国外已有先例,J·K·罗琳创作的《哈利波特》、英国作家约翰·罗纳德·鲁埃尔·托尔金的史诗奇幻小说《指环王》,苏珊·柯林斯创作的《饥饿游戏》等小说改编的电影都获得了巨大的成功。2015年国内IP热潮开始,改编网络文学IP在影视圈掀起了热潮,许多网络小说改编成了影视剧,因此2015年也被称为“IP元年”。2015年年初《何以笙箫默》、《花千骨》、《瑯琊榜》,以及年尾上映的《芈月传》等几大网络文学改编剧轮流坐拥电视收视率排行榜第一。同时,由《鬼吹灯之寻龙诀》、《九层妖塔》、《匆匆那年》等网络小说改编的电影也大获成功。网络文学IP借助其天然的独特优势,成为了影视业、游戏业等诸多行业的新宠,版权价值也在水涨船高。凯撒股份于2016年3月22日公告称以总额1亿元授权金,获得腾讯动漫《从前有座灵剑山》、《银之守墓人》、《我的双修道侣》等若干个IP的改编授权。
判断一部网络小说拥有的隐含价值量是决定改编成功的关键,但网络小说有其特殊的持续消费特征,隐含价值量并非稳定不变,对隐含价值量的错误估计会严重影响运营商的运营计划,增加无形成本,降低商业利润。基于以上问题的考虑,本文运用大数据对网络小说隐含价值量进行预测,希望为网络小说运营商提供指导借鉴。
目前,国内外一些专家针对电影票房和电视剧热度等进行了预测研究。比如RameshSharda[1]等通过美国各大院线公司获取样本数据,采用对电影票房分类的方式,使用分类正确率来判断模型分类的性能,对比回归算法得到了更好的结果。王炼[2]等根据网络搜索与电影票房之间的关联展开研究,验证了网络搜索对电影票房的预测作用,提高了预测的准确性。同时Kulkarni G[3]也通过对网络搜索数据建立销售预测验证两者之间的关联关系,说明网络搜索数据在电影票房的预测是一个关键而有显著影响的变量。Sawhney M S[4]等建立电影预测模型分析评论正向情感倾向对电影票房的关联影响,研究表明,只有第三周的在线影评正向情感倾向显著影响电影票房,且影响程度大于影评数量。Byeng-Hee Chang[5]等通过建立预测模型成功预测北美地区电影票房,为电影产业的市场风险提供具有现实指导意义的风险安全规避决策。De′Ath G[6]等采用四分位对数据进行等级划分,建立评价标准的思想具有很好的借鉴性。张虹[7]等基于小波多尺度分析,根据不同信号的话题借用神经网络建立不同的预测模型,随后组合获得最终预测,预测精度表现良好。赵妍妍[8等将微博倾向性分析作为一个分类问题,与小波多尺度分析有着相似的思想,目的是希望判断评论的总体情感倾向性,对电影票房的预测有很好的指导作用。张源漳[9]基于读者浏览行为建立狭义点击流数据进行读者需求可视化分析,创建出多条关联规则得出读者信息需求规律,为图书馆决策和创新服务提供科学依据。易明[10]等研究的点击流与网络小说的点击量存在相似的意义,对点击流的站点信息组织优化可以为网络小说隐含价值量的定义提供借鉴。Igmcio Redondo[11]等认为明星的关注数量、过去电影票房收入、艺术成就对电影票房的收入有着很强的关联关系,可以通过对明星影响力的量化可以对电影票房收入进行建模预测。利用分类技术,可以通过对系统相似电视剧的点播量来预测电视剧的点击量,Pinto H[12]基于此种思想展开研究并获得较好的预测效果。S.Asur[13]等借助Twitter电影相关话题的创建速率等对电影的票房进行预测,获得了较好的预测效果,发现以美国为主的Twitter用户数据与中国网络用户数据之间存在着地域文化差异。Henrique Pinto[14]借助分类技术,搜寻出待预测电视剧早期点播“相近”电视剧的点播情况,与数据库中已经存在的电视剧数据做关联分析,对电视剧后期点播量加以预测。
网络小说IP与电影有着类似的特征,但又有其自身的特点。目前国内外还鲜有学者针对网络小说IP的潜在隐含价值进行预测。网络小说与电影票房预测主要存在以下不同:首先,网络小说在完结前处于持续消费状态,根据内容的变化,读者基群会出现读者流失与新读者加入的现象,隐含价值量处于不断变化的状况,而电影票房则是属于一次性消费,观众流失影响并不显著;其次,网络小说的隐含价值量是一个综合指标,包含网络小说本身的阅读消费和潜在改编电影或者游戏的潜在商业价值关联作用,而电影票房则较为单一。因此,通过数据挖掘分析,分析网络小说IP存在的潜在隐含价值,分析网络IP热潮背后隐藏的关联关系,帮助网络小说运营商发现黑马小说,挖掘其商业潜力,准确预测网络小说IP价值,对网络小说运营商具有重要的决策指导意义。
1 数据收集与模型构建
1.1 数据收集
起点中文网隶属于国内最大的数字内容综合平台—阅文集团旗下,是国内最大文学阅读与写作平台之一,也是目前国内领先的原创文学门户网站,确立了行业领导地位,具有很高的影响力。本文以起点中文网为平台,运用八爪鱼数据采集工具对起点中文网排名榜上的网络小说网页数据进行抓取,从2016年05月24日至25日历时32小时抓取3 118部小说,总计7万余条数据,对数据进行整理后,将数据文档输出为 ARFF格式,在Weka平台进行数据处理及挖掘分析。
1.2 变量选择
网络小说的隐含价值量是一个多元综合性概念,但网络小说价值的基础是观众受众的大小,所有的商业价值都源于观众的喜爱。由于网络小说的点击量是一个直观而具有说服力的重要指标,反映了一部网络小说的受欢迎度,点击量越大说明观众受众越多。因此,本文选择通过点击量来刻画网络小说的隐含价值量,即因变量,而选取总推荐量、总字数、总评论数、总回复数4个指标为自变量进行预测,变量选择及涵义如表1所示。

表1 网络小说预测数据变量定义
1.3 数据预处理
网络小说具有一个较长的成长周期,而点击量等数据也会随着时间的迁移逐渐变大,对于优秀且成功的网络小说,这个数值的增长速度和最终的数值都是非常巨大的。因此,本文对整个实例集在WEKA平台上进行规范化数据预处理。针对以上变量的取值进行数据预处理后的数据格式如图1所示。
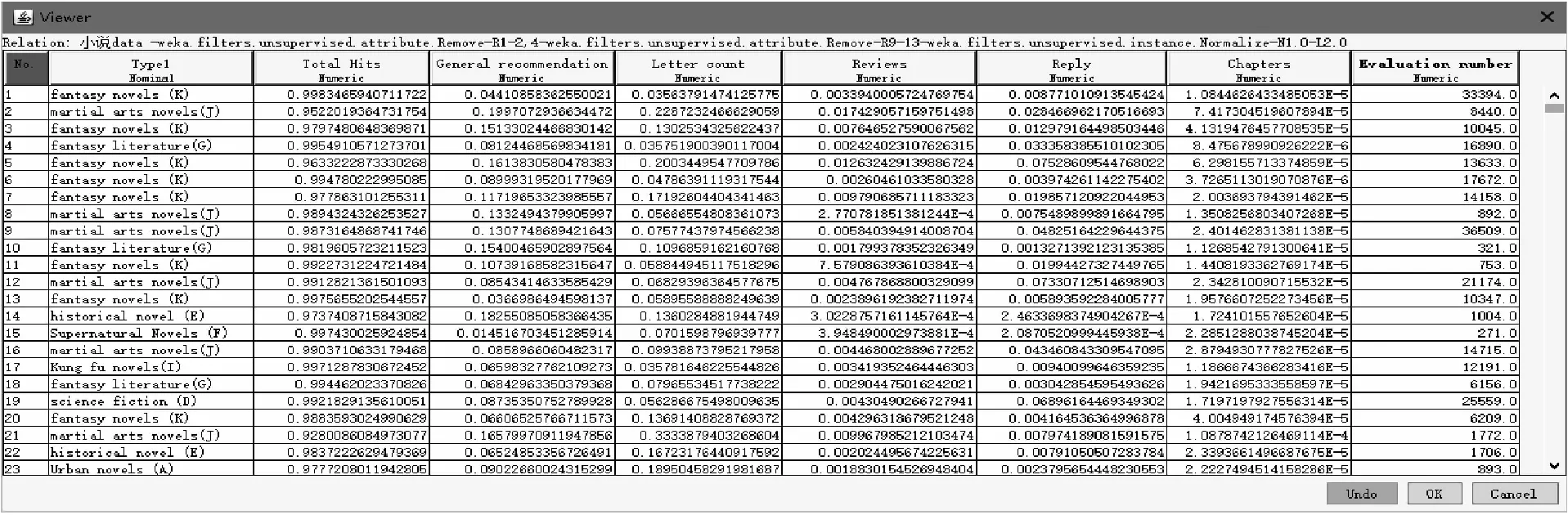
图1 网络小说变量数据预处理结果图
1.4 模型构建
最早将树结构应用到回归预测问题的是1984年Breiman[15]等提出的分类回归树-CART,这种树结构输出的是每个叶子结点目标属性的平均值,尽可能地逼近回归。1992年,在分类回归树的基础上,Quinlan[16]提出了分段式多元线性回归树即M5模型树,为了进一步解决预测问题,1997年Wang[17]等人对M5模型树进行重构改进,形成了M5模型树。考虑到对点击量的预测是一个数值预测而且由于M5模型树拥有效率高、鲁棒性好等优点,该模型可以进行有效的学习,同时本模型处理输入属性数据可以达到几百维的范围,基于此本文采用M5模型树算法建立模型进行预测。M5模型树组合了树结构和线性回归模型,每个叶子节点是一个线性回归模型,用一系列分段线性模型组合起来的全局模型,为处理问题带来了所需的非线性。
本文选择的3118部网络小说大多已经完结,或是更新至少一年以上,其点击量达到一定规模,增长速度相对稳定,并达到了预测的要求,因此选择作为点击量的预测数据具有说服力。将筛选后的数据在WEKA平台进行建模预测,得到的M5模型树如图2所示。
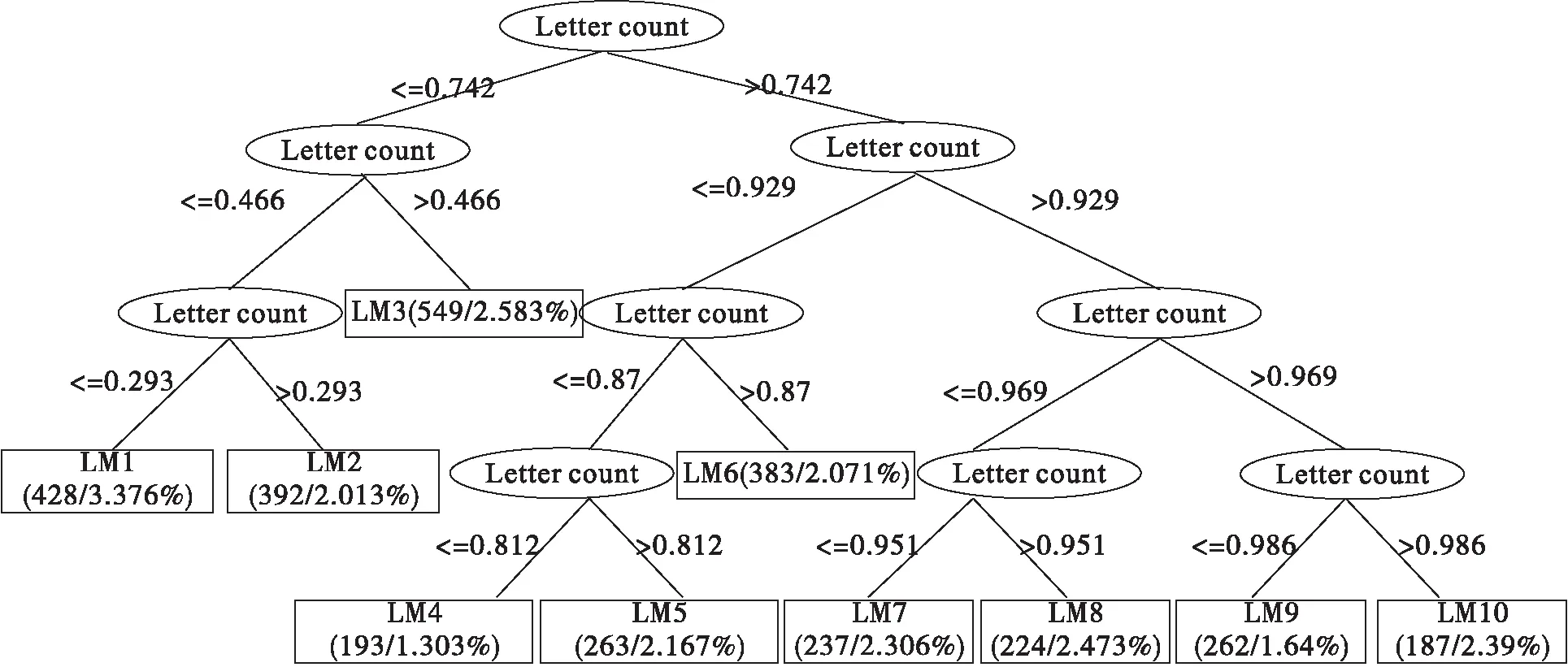
图2 M5模型树预测模型结果图
在模型树的每一个叶节点都有一个线性回归模型,共有LM1—LM10 10个线性回归模型,具体模型展示如表2所示。
2 结果分析
建立M5决策树模型后的识别结果如表3所示。
为了进一步确认M5模型树的模型精度,本文同时采用线性回归算法和梯度下降分类树算法对以上问题建立模型进行了预测,与M5模型树结果进行对比分析。通过采用十折交叉验证的方式评估模型的误差率,运用关联度R、绝对差值率MAE、均方根误差率RMSE等指标对模型精度进行评估,具体结果见表4。其中关联度R反映了模型与真实关联函数的相似度,该值越接近1,表明模型越接近真实关联函数;MAE用于评判预测值与实际值之间的差异度,反映个体样本的预测效果程度,越小越好。RMSE与MAE 类似,但RMSE更侧重于反映样本总体的预测效果程度,值越小越好。
关联度:
(1)
绝对差值:
(2)
均方根误差:
(3)

表2 M5模型数叶节点线性回归模型展示
根据表4三种算法的模型评估指标结果,我们可以看到M5模型树在MAE、RMSE、标准误差和绝对平均误差的评估指标都优于线性回归模型与梯度下降分类树的模型,相关系数更是接近1,说明M5模型树的精度很高,具有很强的准确性和解释性。
3 进一步分析及启示
通过对M5模型树建立的模型识别结果可以看到,本文建立的预测模型具有很好的预测精度,在MAE和RMSE的指标反馈都较好,误差在理想范围内。从M5模型树的树结构可以看出,树结构的分支是通过总字数来进行划分的,可以认为整个树结构是对网络小说从开始创作到整本完结的整个过程不同创作阶段的划分,由开始创作、逐渐成长、成熟稳定到整本完结。通过分析模型结果,我们得到以下启示。
(1)总推荐量负面影响。总推荐量是由读者对网络小说投出的推荐票积累所得数据,其目的是为了帮助小说吸引更多的读者,起到推荐推广的作用。从研究结果可以看出,10个叶节点以上的线性模型中,总推荐量的权重系数全部为负,相对权重较小。说明总推荐量在网络小说整个创作的不同阶段对总点击量的增加总是起到负相关影响,总推荐量不仅没有存在的意义,反而成为总点击量提升的障碍,成为一个耐人寻味的问题。
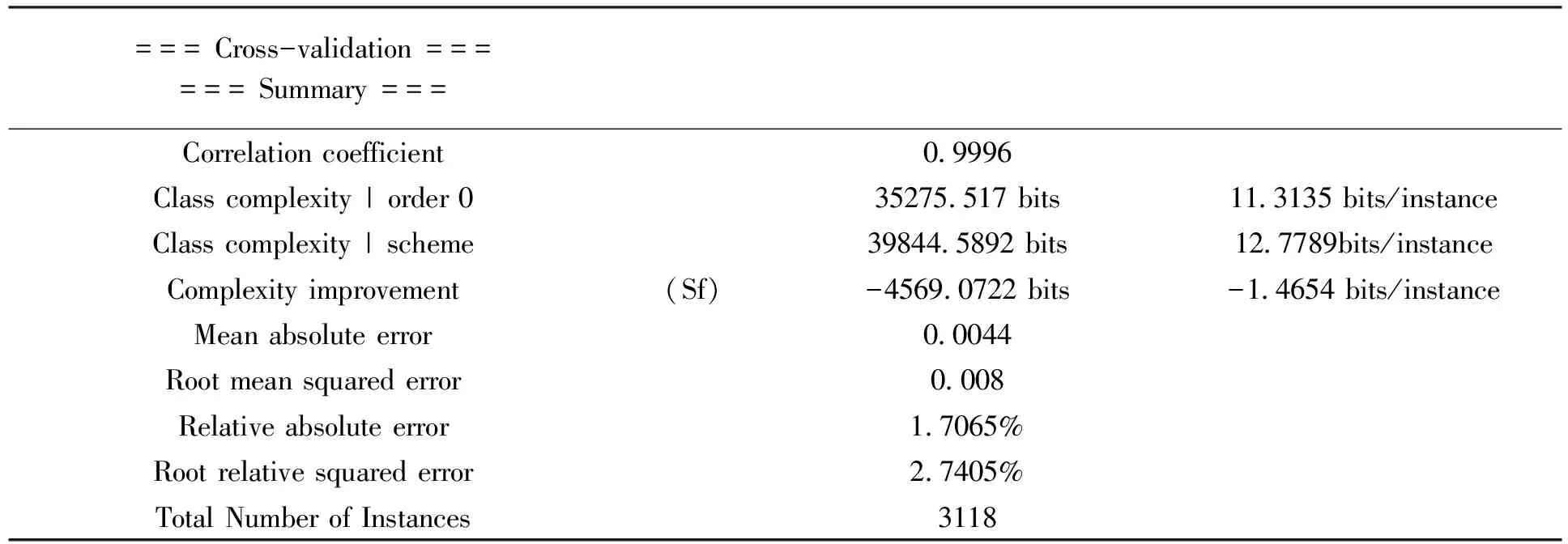
表3 M5模型树模型识别结果

表4 算法模型评估指标对比
究其原因,本文发现网络小说得到读者的认可,是促使读者投出推荐票的动机,但一千个读者就有一千个哈姆雷特,一部网络小说无法满足所有读者喜好。推荐票的增加是忠实读者贡献所得,存在重复性,受个人对网络小说喜好程度影响。正是这种内心喜好的偏移,读者只会保留推荐票赠给自己喜好的网络小说,投推荐票的行为无形中转变成了网络小说对读者的“观念绑架”,这种观念绑架的出现不仅不会吸引新的读者,提升点击量,反而固化了读者基群的流动性,不利于新读者的加入,因此产生了对网络小说点击量的负面影响。
与此同时,网络小说的总推荐量的负面影响同时反映了读者的理性阅读,说明读者并不会盲目相信总推荐量。读者会根据自我喜好对网络小说的内容进行预判之后阅读。网络小说的作者应当将更多的注意力放在情节设置、文笔等文章内容的提升上,当文章内容得到读者认可时,忠实读者数量的提高将会促进总推荐量与总点击量的提高。
(2)总字数负面影响。网络小说的总字数一方面反映了网络小说的更新时长,另一方面反映了网络小说内容的丰富性与可读性。一般认为,更新时长越长点击量的累积越多。网络小说内容越丰富,其对读者的吸引力越强。但从研究结果可以看到,总字数的权重系数全部为负,权重相对较大。说明总字数在整个创作过程中与总点击量的影响关系总是负相关,且影响程度较大,这是一个与我们常识认知相悖的现象。
究其原因,在创作初期,由于总字数过少无法满足读者阅读需求,读者会选择等到章节积攒到一定数目时再选择阅读,因此在这个阶段,总字数对总点击量起到了负相关的影响作用。当网络小说进入成熟稳定的阶段后,由于网络小说是由情节描述和情感描述及其他场景描述为主要写作内容,在情节长度相同的情况下,网络小说总字数越多,说明与情节无关的描述性语言过多,而读者更在意的是情节的发展,对其他描述性语言关注程度并不高。由于网络小说更类似于一种快餐文学,过多的无关描述拖沓了情节的推进,导致读者不满情节发展过慢而流失,从而导致点击量的下降。因此,情节发展长度相似的情况下,总字数越多,读者流失越多,对点击量形成负面影响。
因此,这提醒网络小说作者应当调整写作方式,加快情节推进速度,同时减少不必要的描述性语言,适当控制总字数,可以为点击量的提升提供保障。同时,人们过于崇尚快餐文学导致网络小说更新速度过快,文章内容文学性降低,削弱了可读性,这种现象应当引起社会的广泛注意及思索。无论是网络文学或是线下文学,同时满足文学性和可读性才能成为脍炙人口的优秀文学作品,为中国文化的发展开枝散叶,过分追求利益的文学必定无法长久留存和发展。
(3)评论回复数的负影响分析。在10个叶节点的线性模型中,当总字数权重小于0.742时,总回复数在线性模型中的权重系数均为负值。当总字数权重大于0.742后,总回复数在线性模型中的权重系数均为正值。说明当总字数超过一个临界值后,总回复数才会对总点击量起到促进作用,而在临界值之前,总回复数对总点击量起到抑制作用。
究其原因,一部网络小说从开始创作至整本终结,整个过程经历不同的时期,从开始创作到逐渐成熟稳定的过程,这个成长过程在M5模型树中是通过总字数来进行划分。在创作初期的LM1至LM3阶段,由于作品的知名度较低,阅读基群较小,对网络小说的回复内容主要表现出支持鼓励作者创作的情感,这类评论可以带给作者自信心和鼓励,但却无法对读者起到很好的吸引作用从而加以阅读。在这个时期,读者并不会过多关注文章内容,而会主观认为文章的水平还显稚嫩,因此,在这段时期的总回复数在线性模型中对总点击量的影响是抑制作用。
随着网络小说度过初期阶段,阅读基群不断增长,读者将更多关注文章内容,同时文章的回复内容也会出现褒贬不一的情感。在这个时期,无论是对文章的赞扬还是贬低,都会引发读者对文章的好奇心,想要一探究竟[18-19]。因此,当度过初期阶段,总回复数对总点击量起到促进作用。
因此,当度过初期的创作阶段,及时回复评论可以促进点击量的提升,提示作者可以通过加强与读者的互动回复,通过积极的评论和回复与读者建立信任友好的关系,可以帮助提升网络作品成绩[20]。但同时应当注重言语文明,作者有义务监督评论区言论走向,尽量减少负面回复的泛化恶化,尽力营造文明的阅读氛围,这样能够提升小说的潜在价值。
4 结论
本文针对网络小说的隐含价值量进行预测,选择点击量刻画网络小说的隐含价值量,选取总推荐量、总评论数等指标,采用M5模型树建立预测模型,预测模型的识别结果显示模型具有很好的精度。透过叶节点中的线性模型,针对模型结果进行分析。结果显示网络小说的总字数、总推荐量对总点击量均形成负面影响。论文分析了其产生的原因并给出了合理的建议和启示,有效预测网络小说IP,通过关联分析挖掘网络小说的潜在价值,可以为网络小说运营商提供有效的决策依据和借鉴,将帮助运营商在众多网络小说中甄别出有潜力价值量的网络小说,从而抑制由于IP热潮引发的运营商盲目跟风的社会现状。
[1] RAMESH SHARDA,DURSUN DELEN.Predicting box-office success of motion pictures with neural networks[J].Expert Systems with Plications,2006,30(2):243-254.
[2] 王炼,贾建民.基于网络搜索的票房预测模型-来自中国电影市场的证据[J].系统工程理论与实践,2014,34(12):3079-3090.
[3] KULKARNI G,KANNAN P K,MOE W.Using online serach data to forecast new product sales[J].Decision Support Systems,2012,52(3):604-611.
[4] SAWHNEY M S,ELLIASHBERG J.A parsimonious model for forecasting gross box-office revenues of motion picture[J].Marketing Science,1996 ,15(2):113-131.
[5] BYENG-HEE CHANG,EYUNJUNG KI.A practical model for predicting theatrical movies success:focusing on the experience good property[J].Journal of Media Economics,2009,18(4):247-269.
[6] DE'ATH G, FABRICUS K E.Classification and regression trees:a powerful yet simple technique for ecological data analysis ecology [J].Ecology,2000,81(11):3178-3192.
[7] 张虹,钟华,赵兵.基于数据挖掘的网络论坛话题热度趋势预报[J].计算机工程与应用,2007,43(31):159-161+174.
[8] 赵妍妍,秦兵,刘挺.文本情感分析[J].软件学报,2010,21(8):1834-1848.
[9] 张源漳.基于WEKA点击流数据的读者需求可视化分析[J].图书馆论坛,2007,27(04):67-69.
[10]易明,邓卫华,曹高辉.基于“点击流”数据的站点信息组织优化[J].现代图书情报技术,2006 ,22(1):51-54.
[11]IGNACIO REDONDO,MORRIS B.HOLBROOK.Modeling the appeal of movie features to demographic segments of theatrical demand[J].Journal of Cultural Economics,2010, 34(4):299-315.
[12]PINTO H,ALMEIDA J M,GONCALVES M A.Using early view patterns to predict the popularity of youtube videos[C].Proceedings of the sixth ACM international conference on Web search and data mining.NewYork,2013.
[13]S.ASUR,B.A.HUBERMAN.Predicting the future with social media[C].WebIntelligence and Intelligent Agent Technology.Toronto:IEEE,2010,7(2):492-499.
[14]HENRIQUE PINTO,JUSSARA M.ALMEIDA,MARCOS A.GONYALVES.Usingearly view patterns to predict the popularity of youtube videos[C].Proceedings ofthe sixth ACM international conference on Web search and data mining.ACM,NewYork,NY,USA,2013.
[15]BREIMAN L , FRIEDMAN J H, OLSHEN R A, et al.Classification and regression trees[M].Belmont:Wadsworth Statistical Press,1984.
[16]QUINLAN R J.Learning with continuous classes[C].5th Australian Joint Conference on Artificial Intelligence, Singapore,1992:343-348.
[17]WANG Y,WITTEN I H.Induction of model trees for predicting continuous classes[C].The 9th European Conference on Machine Learning,Prague,1997.
[18]艾瑞咨询,艾瑞视点:2010年8月用户产品评论促进46%美国网民的购买行为[EB/OL].下载地址:http://ec.iresearch.cn/17/20101109/127426.shtml.2010-12-01.
[19]AINSLIE A,DREZE X,ZUFRYDEN F.Modeling movie life cycles and market share[J].Marketing Science,2005,24(3):508-517.
[20]RESNICK P,ZECKHAUSER R.Trust among strangers in internet transactions:empirical analysis of eBay’s reputation system[M].Wagon Lane:Emerald Group Publishing Limited,2002:127-157.
猜你喜欢
作文小学中年级(2022年1期)2022-03-03 08:30:50
家庭影院技术(2021年2期)2021-03-29 07:19:06
家庭影院技术(2020年11期)2020-12-28 01:23:04
家庭影院技术(2020年10期)2020-12-14 07:54:20
网络文学评论(2019年6期)2019-12-13 05:23:56
家庭影院技术(2019年8期)2019-08-27 02:45:02
网络文学评论(2017年1期)2017-07-22 05:36:50
网络文学评论(2017年1期)2017-07-22 05:36:40
快乐语文(2016年32期)2016-04-10 10:47:25
数学教学通讯·初中版(2013年9期)2013-04-29 00:44:03
