
基于GATE的中文事件抽取方法
2017-11-04 07:30张海玉
山东农业工程学院学报 2017年5期
黄 海,张海玉
(1.广东培正学院教务处,广东 广州 510830;2.太原理工大学财经学院信息系,山西 太原 030024)
基于GATE的中文事件抽取方法
黄 海1,张海玉2
(1.广东培正学院教务处,广东 广州 510830;2.太原理工大学财经学院信息系,山西 太原 030024)
事件抽取是信息抽取领域的重要研究方向,针对目前网页文档中文事件抽取的关键问题,提出利用开源的通用文本处理框架(GATE)进行中文事件抽取的方法,设计GATE中文事件处理流程,开发GATE插件,解决中文分词与词性标注、领域词典、中文抽取规则设计等关键技术,实现了中文事件的类型识别和元素抽取。并以四类政治事件为例,进行中文事件抽取实验。实验结果表明,基于GATE的中文事件抽取具有良好的通用性,能够取得了较好的抽取效果。
信息抽取;GATE;事件抽取;中文分词;规则匹配
引言
随着互联网技术的快速发展,网络数据呈现爆炸式的发展态势,大量的信息以文本的形式呈现在人们面前。为了应对信息爆炸带来的挑战,迫切需要一些自动化的技术帮助人们在海量数据中迅速找到其所需要的信息。信息抽取成为了从文本中自动获取信息的一种重要手段,它是指从一段文本中抽取指定的数据、事实等信息,形成结构化的数据并存入数据库中,供用户查询和使用的过程[1]。事件抽取(Event Extraction)是信息抽取的一个重要研究方向,主要研究如何从含有事件信息的自由文本中抽取出用户所需要的事件信息,将文本中描述的事件以结构化的形式呈现出来[2]。
事件抽取的常见方法之一是模式匹配法,它利用模式规则集进行事件类型或事件元素的匹配,事件抽取模式体现了语言知识和领域知识的融合。Chinatsu Aone[3]利用可配置的模式生成模块和基于模式的标注工具设计了一个大规模点对点关系和事件抽取系统;Ernest Arendarenko等[4]利用本体作为GATE词典,设计基于JAPE的事件识别规则,进行了商业领域的事件抽取;梁晗[5]提出了一种基于框架的信息抽取模式并建立统一的灾难性事件框架,利用框架的继承-归纳特性简化系统实现过程。吴平博[6]等人利用句型模板的抽取规则从文本中抽取时间短语、空间短语和事件信息,并讨论了事件的合并的问题。孙荣[7]等提出一种基于抽取规则对句子中的事件信息进行抽取的方法,利用本体对动词与事件角色匹配规则、事件角色抽取规则、时间信息抽取规则和地点信息抽取规则进行定义,然后应用这些规则抽取句子中的动词词义信息、事件角色信息、时间信息和地点信息。
本文提出利用文本工程通用框架GATE来进行中文事件抽取工作,研究自然文本处理框架GATE的基本结构和基于GATE的事件抽取流程,分析GATE在中文事件抽取领域中的不足,并构建了基于ICTCLAS的中文分词组件、领域词表和事件抽取规则。以四类国际政治事件为例,进行了中文政治事件抽取实验。
1 信息抽取及GATE概述
1.1 信息抽取
信息抽取是一种文本处理技术,它通过对非结构化的自由文本数据进行处理,获得结构化的信息数据。信息抽取能够帮助人们快速获取所需要信息,同时能够对信息进行分析和组织,提高文本数据的可用性[8]。
人类是以事件为单位认识和理解客观世界的,事件是随着时间变化的具体事实,涉及到多方面的事物概念,事件间具有内在的联系,事件由动作、概念、关系组成。事件数据在国际关系、地缘政治、地理信息应用等领域中有着广泛的应用[9,10],因此从互联网文本抽取领域事件数据具有重要意义。
1.2 GATE概述
GATE(General Architecture for Text Engineering,文本工程通用框架)项目开始于1995年英国的谢菲尔德大学,经历了十多年的不断发展,凭借其优秀的组织架构和开源的优势,GATE已经被应用于广泛的研究和项目开发,在科研、教育、商业等领域获得广泛应用[11]。
GATE将其框架内所有的自然语言处理软件资源划分为不同的几种组件,这些组件是通过Java Beans的形式来实现的,其集合被称为CREOLE(a Collection of Reusable Objects for Language Engineering)。CREOLE在GATE中分为三种形式:语言组件(LR),处理组件(PR)和可视化组件(VR):语言组件是指仅仅与数据相关的资源,如词表、文档和本体等;处理组件指数据处理程序或者算法,如产生器、转换器、分析器和语言识别器等。可视化组件指构成GATE的可视化界面GUI的相关资源。
JAPE(a Java Annotation Patterns Engine,Java标注模式引擎)是GATE的规则定义语言,它能够利用GATE生成的Token、LookUp、Person、Date等标注,使得其可以更精确、更广泛的覆盖面抽取信息[12]。一个JAPE语法由一系列的语句组成,每个语句都是一个由模式/行为规则组成的集合。这些语句按顺序运行,形成了一组标注有限状态机的转换[13]。语句的左侧部分(LHS:Left Hand Side)由一些标注匹配模式组成,右侧部分(RHS:Right Hand Side)是匹配后执行的操作,LHS和RHS以-->符号隔开。JAPE的匹配操作能够使用Java代码描述,这在很大程度上扩展了JAPE对规则的复杂处理能力。
2 基于GATE的中文事件抽取关键技术
GATE为英文文档资源提供了信息处理流程实例ANNIE,它是基于规则的信息抽取系统,使用有限状态算法和 JAPE语言来实现各种不同的信息抽取任务[14]。ANNIE采用流水线工作方式,严格按照顺序经过分词 (Tokeniser)、词表查询(Gazetteer Lookup)、 分句 (Sentence Splitter)、 词性标注(POS Tagger)、 语义标注 (Semantic Tagger)、 共指消解(Ortho Matcher)、代词消引(Pronominal Coreferencer)之后,实现英文文档的信息抽取[15]。
但ANNIE并不能有效处理中文文档,它在解决中文信息抽取有以下不足:1)缺乏对中文分词处理的良好支持,目前的版本并不能实现真正意义上的中文分词;2)中文词表不够完善,缺少特定领域内的专有名词词表;3)命名实体识别过程中,针对英文特点的JAPE规则不能有效支持中文的命名实体识别。
针对以上不足,基于GATE的中文事件抽取系统需要完成以下三项关键技术:1)有效处理中文分词与词性标注的问题;2)设计专业、完善的中文领域词表;3)针对中文特点重写JAPE抽取规则,提高事件识别和抽取的准确率。
2.1 中文分词与词性标注
与英文等以空格作为词间天然分隔符的语言不同,汉语中词与词之间不存在明确的分隔标记,而是形成一个连续的汉字字符串,因此必须对中文文本进行分词处理。中文分词就是将连续的汉字序列按照一定的规范重新组合成词序列的过程,中文词性标注是指为中文文本中的每一个词增添一个合适的标记,用以说明它的词性,如名词、动词、形容词等,因此,中文词法分析是中文信息处理的基础与关键。
中文分词是中文事件抽取的基础,目前已有相关论文[13,16,17]对GATE的中文分词问题进行了研究,但其解决方法都是使用中文分词工具提前对文档进行分词预处理,以空格将各个词分隔,组成英文文本的空格分割格式,然后使用GATE默认的Unicode Tokeniser分词器根据空格对文档重新分词。这种方法需要提前对文档进行预处理,增加了人工操作的复杂度,而且以空格划分的分词文档无法获取每个词的词性信息,因此无法在抽取规则中使用词的POS属性,影响了信息抽取的精度。
本文基于中科院计算所的中文分词工具ICTCLAS,开发了GATE的中文分词组件来进行中文文档的分词与词性标注。ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System)是中国科学院计算技术研究所在多年研究工作积累的基础上研制出的汉语词法分析系统,它由C++编写,主要功能包括中文分词、词性标注、命名实体识别、新词识别、同时支持用户词表,分词正确率高达97.58%,未登录词识别召回率均高于90%,其中中国人名的识别召回率接近98%,处理速度为31.5Kbytes/s。
GATE调用ICTCLAS进行中文分词的流程如下:
(1)读取GATE中的文档内容
GATE中待处理的文本以文档(Document)对象保存,文档对象的内容(context)以纯文本的形式记录了文档的原始信息,这些原始文本是分词软件输入的数据流。
(2)调用ICTCLAS库
ICTCLAS是纯C++开发的库,为了在Java环境的GATE中使用,本文使用JNI技术来调用ICTCLAS库,JNI(Java Native Interface)是一个本机编程接口,它允许Java代码使用以其它语言编写的代码和代码库。ICTCLAS工具提供了ParagraphProcessing()和FileProcessing()两个接口,分别处理文本段落或者文件,本文使用ParagraphProcessing()接口来处理GATE中的文档内容。
(3)解析ICTCLAS处理结果
ICTCLAS的ParagraphProcessing()函数对输入的句子进行分词并输出,输出结果为“单词/POS”形式。例如句子“中国是世界上人口最多的国家。”的分词结果为 “中国/ns是/v世界/n上/f人口/n最/d多/a的/u国家/n。/w”,需要根据数据格式来解析每个分词的起始位置、结束位置和POS词性信息。
(4)增加Token标注和Feature值
GATE的文档标注集包含起始节点(start Node)、结束节点(end Node)、ID、类型(type)以及特征键值对(FeatureMap)等信息,根据(3)中解析的结果,利用GATE的接口函数在Document中增加相应的Token标注,并设置起始节点、结束节点和特征值。
2.2 领域词表设计
词表是GATE进行事件抽取的重要资源,词表的丰富完整影响着抽取的效果。词表是一组包含了事物名词的集合,如城市名称、组织名称、日期等等。词表一方面描述了领域内的专有名词,另一方面可以表达各类概念名词之间的关系,并将其映射到领域本体中。
词表是事件抽取的重要元素,词表的丰富和准确程度直接关系着事件抽取的效果。事件抽取需要使用的词表包括命名实体词表和事件触发词词表两类,事件触发词(Event Trigger)是指用来清晰地表示所发生的事情的词,通常为动词。
GATE中的词表由*.lst文件、mappings.def文件和lists.def文件三类文本文件组成。*.lst文件定义实体,每个*.lst文件代表一个实体类型,以“词表”的形式对应领域知识中的概念实例。mapings.def描述*.lst文件和领域本体概念之间的关系。lists.def为*.lst文件的索引文件,指明每个*.lst文件所对应的主类(majorType)和子类(minorType)类型,以“:”分割。在GATE中进行命名实体标注的时候,这些文件将会被编译成有限状态自动机,有限状态自动识别出的文本片段将会以Lookup标签标注出,并增加相应的特征值[18]。
2.3 抽取规则设计
事件抽取主要包含事件类型识别和事件元素抽取两部分内容,其中,事件类型识别是事件元素抽取的基础,事件元素抽取是事件抽取的主要内容。事件类别识别是指从文本中检测出事件句,并依据一定的特征判断其所归属的类别。事件类别识别是典型的分类问题,其重点在于事件句的检测和事件句的分类[19]。现有的检测事件句的方法主要是基于触发词的方法。触发词是指在文本中清晰的表示事件发生的词语。在自然文本中,除句子中的谓语动词外,其他成分的动词也有可能作为事件触发词。事件元素抽取是事件抽取的核心任务,它从众多命名实体(Entity)、时间表达式(Time Expression)和属性值(Value)中识别出真正的事件元素,并给予其准确的角色标注。事件要素限定在事件范围(Event Extent)之内,事件范围通常以具有完整意义的句子或者分句为边界。
事件触发词是决定事件类别的重要特征,因此事件类别识别任务可以转换为事件触发词类别的识别。在抽取事件信息时,根据触发词确定所属事件类别,并调用相应的规则进行匹配。
基于规则的事件抽取方法的核心是寻找事件模板。模板指自然语言中描述事件的模式特征。在设计事件规则时,首先整理出语句的模式特征,然后将模式转换为JAPE规则描述语言。例如“2014年9月11日,国家主席习近平在杜尚别会见俄罗斯总统普京。”这一会见事件,其模式为“时间短语+标点符号+名词+人名+介词+地名+会见动作+国家+名词+人名”,其中事件发生的时间为“2014年9月11日”,地点为“杜尚别”,主语为“习近平”,宾语为“普京”,按照JAPE语言其匹配规则表示为:
Rule:MeetingRule1
(
({Date.kind=="date"}):tagdate
{Token.category=="wd"}
({Token.category=="n"})+
({Person}):tagSubject
{Token.category=="p"}
({Location}):tagLoc
{Lookup.majorType==diplomacy}
{Country}
{Token.category=="n"}
({Person}):tagObject
{Token.category=="wj"}
):tag
-->
:tagdate.Politic={element=Date,rule=MeetingRule1},
:tagSubject.Politic={element=Subject,rule=MeetingRule1},
:tagLoc.Politic={element=Location,rule=MeetingRule1},
:tagObject.Politic={element=Object,rule=MeetingRule1},
:tag.Politic={type=Meet,rule=MeetingRule1}
图1展示了外交部网站新闻“习近平会见俄罗斯总统普京”一文中的会见事件抽取结果,事件抽取结果保存在EVENT标注集中,标注名称“Politic”表明事件为政治事件,事件子类使用type属性标识,事件元素使用element属性标识,共包括时间(Date)、地点(Location)、主体(Object)、客体(Subject)四个元素。

图1 会见事件抽取结果Figure1 Meeting Event Extract Result
3 实验及评估
为了验证GATE在中文事件抽取中的作用,设计了国际政治中四类常见事件抽取进行实验:访问、会见、抗议、冲突,这四类事件代表了国际关系中常见的事件,是研究国际关系、地缘政治的重要数据资源。
本文分别从外交部、新华网、凤凰网等权威新闻门户网站收集了访问、会见、抗议和冲突四类事件数据语料,将各类语料数据分成标注语料和测试语料两部分,基于标注语料来总结整理规则、设计触发词词典。各类事件的语料情况和触发词情况如表1所示。

表1 四类事件语料情况
实验结果采用MUC在自然语言处理领域的三大评测指标进行衡量,即准确率(P)、召回率(R)和综合值(F),具体定义如下:

各类事件抽取的准确率、召回率和综合值结果如表3所示。
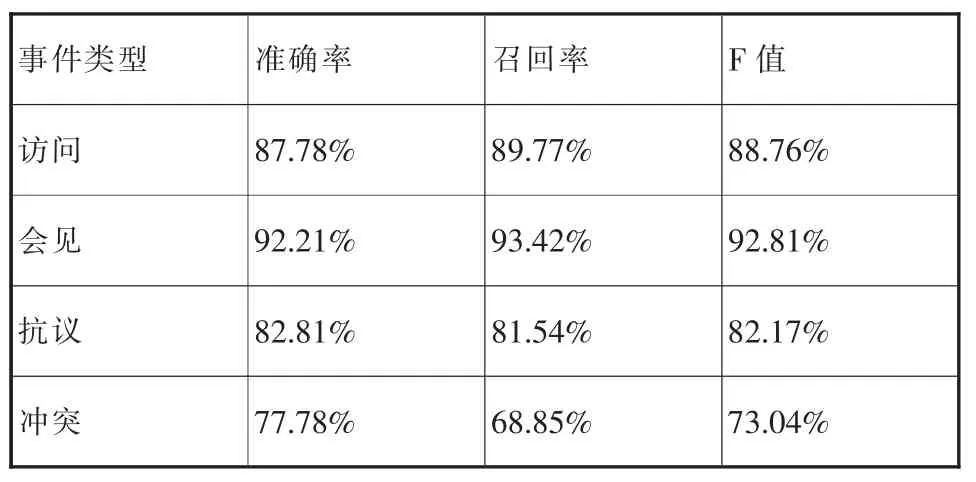
表2 事件抽取结果
通过表3可以看出:(1)使用GATE能够很好地进行中文事件抽取,访问、会见、抗议三类事件的抽取结果正确率和召回率都在80%以上;(2)事件抽取的效果主要受规则的覆盖程度影响。试验中的冲突事件比较分散,涉及的规则模式也比较多,语料中的规则不能完全覆盖全部的冲突事件,造成冲突事件的召回率较低。因此在基于规则的事件抽取中,语法规则库的设计和完善是提高抽取正确率和召回率的关键。
4 结束语
事件抽取是从文本中获取领域数据的重要途径,本文针对GATE在中文事件抽取中的不足,利用ICTCLAS中文分词工具开发了GATE处理组件,进行中文分词与词性标注、设计地缘事件的分类体系和事件词表、构造地缘事件抽取规则,进行地缘事件信息的抽取。基于模式匹配的事件抽取方法的一个主要问题是抽取模式不能完全覆盖全部句式,本文基于语料中国际政治事件的表达句式总结了若干条抽取规则,但这些规则的覆盖面仍不能完全覆盖全部事件。本文的下一步工作是对事件模式进行扩展完善,通过种子规则来实现启发式的规则扩展,以提高事件抽取的召回率。
[1]Qian Liu.Hui Jiao.Hui-Bo Jia.Research on Approaches of Information Extraction System[J].Application Research of Computers.2007,24(7):6-9.(刘迁、焦慧、贾惠波.信息抽取技术的发展现状及构建方法的研究[J].计算机应用研究,2007,24(7):6-9.)
[2]Gang Wu.Research and Application on Chinese Topic Event Extraction[D].Suzhou:Soochow University,2009.(吴刚.基于主题的中文事件抽取技术研究及应用[D].苏州:苏州大学,2009.)
[3]Aone Chinatsu,Ramos-Santacruz Mila.REES:a largescale relation and event extraction system[C].Association for Computational Linguistics,2000.
[4]Arendarenko Ernest.Kakkonen Tuomo.Ontology-Based Information and Event Extraction for Business Intelligence[C].Varna,Bulgaria:2012.
[5]Han Liang.Qun-Xiu Chen.Ping-Bo Wu.Information Extraction System Based on Event Frame[J].JOURNAL OF CHINESE INFORMATION PROCESSING.2006(02):40-46.(梁晗、陈群秀、吴平博、基于事件框架的信息抽取系统[J].中文信息学报,2006(02):40-46.)
[6]Ping-Bo Wu、Qun-Xiu Chen、Liang Ma.Research on Extraction and Integration of Developing Event Based on Analysis of Space-time Information[J].JOURNAL OF CHINESE INFORMATION PROCESSING.2006(01):21-28.(吴平博、陈群秀、马亮.基于时空分析的线索性事件的抽取与集成系统研究[J].中文信息学报,2006(01):21-28.)
[7]Rong Sun,Wen Zhou,Zong-Tian Liu.Using Rules to Extract Event Information from Sentences[J].Journal of Chinese Computer Systems.2011(11):2309-2314.(孙荣、周文、刘宗田.用规则抽取句子中事件信息[J].小型微型计算机系统,2011(11):2309-2314.)
[8]Li Long,Hongshen Pang.JOURNAL OF LIBRARY SCIENCE.2008,30(5):13-16.(龙丽、庞弘燊.国外Web信息抽取研究综述[J].图书馆学刊,2008,30(5):13-16.)
[9]Zhen-Feng Wang.Geographic Event Inofrmaiton Retrieval Based on ontology[D].Wuhan:Wuhan University,2009.(王振峰.基于本体的地理事件信息检索 [D].武汉:武汉大学,2009.)
[10]Xiaoya An、Ying Li、Qun Sun等.Research on Geographical Event Model for Spatial Data Active Updating[J].Acta Scientiarum Naturalium Universitatis Pekinensis.2011(03):491-498.(安晓亚、李颖、孙群等.面向空间数据主动更新的地理事件模型研究 [J].北京大学学报 (自然科学版),2011(03):491-498.)
[11]Dongxing Xu.A Gate-based lnformation Extraction System:Research and Implementation[D].Shanghai:East China Normal University,2007.(徐东兴.基于Gate框架的信息抽取系统的研究与实现 [D].上海:华东师范大学,2007.)
[12]Lan Chen.Research and Implementation of Ontologybased lnformation Extraction System[D].ChengDu:University of Electronic Science and Technology of China,2004.(陈兰.基于ontology的信息抽取系统的研究与实现[D].成都:电子科技大学,2004.)
[13]Sa Li.The Implementation of the Chinese Information Extraction System Based on GATE[D].Beijing:Graduate U-niversity of Chinese Academy of Sciences,2006.(李飒.基于GATE的中文信息抽取系统的开发和实现 [D].北京:中国科学院研究生院,2006.)
[14]Jing Chen.Research of Ontology-based lnformation Extraction[D].Suzhou:Soochow University,2007.(陈静.基于本体的信息抽取研究[D].苏州:苏州大学,2007.)
[15]Cunningham Hamish,Maynard Diana,Bontcheva Kalina,et al.Developing Language Processing Components with GATE[EB/OL].2014.
[16]Analysis of State-of-the-Art Knowledge Extraction Technologies[J].NEW TECHNOLOGY OF LIBRARY AND INFORMATION SERVICE.2008(08):2-11.(张智雄、吴振新、刘建华等.当前知识抽取的主要技术方法解析[J].现代图书情报技术,2008(08):2-11.)
[17]Bilong Wen,Yunjing Li,Qichao Wang等.Oil Field Information Extraction Based GATE[J].Computer&Digitial Engineering.2014(07):1223-1227.(文必龙.李云静.王琪超等.基于GATE的油田信息抽取技术研究 [J].计算机与数字工程,2014(07):1223-1227.)
[18]Hui Nie,Guipeng Huang.Automatic Web Information Extraction Based on GATE Semantic Annotation[J].2010(05):110-114.(聂卉、黄贵鹏.基于GATE语义标注的Web信息的自动抽取[J].图书情报工作,2010(05):110-114.)
[19]Xu-Yang Xu,Yong-Feng Han,Wen-Zheng Song.Overview and Prospect of Event Extraction Technology[J].Journal of Information Engineering University.2011(01):113-118.(许旭阳、韩永峰、宋文政.事件抽取技术的回顾与展望[J].信息工程大学学报,2011(01):113-118.)
Study on the Chinese Event Extraction Method based on GATE
HUANG Hai1,ZHANG Haiyu2
(1.Guangdong peizheng college office,Guangzhou Guangdong 510830;2.Tai Yuan University of Technology,Taiyuan Shanxi 030024)
Event extraction is one of the most important research field in information extraction.Aiming at the key problem of Chinese event extraction in the web page document,a method of Chinese event extraction with General Architecture for Text Engineering (GATE)is proposed.The procedure of GATE Chinese event is designed,several GATE plug-in are developed to solve key technologies of Chinese word segmentation and part of speech tagging,domain dictionary and Chinese extraction rule design.This paper take five category political events extraction for instance,make an events extraction experiment.The result shows that Chinese event extraction method based on GATE can apply universally and have a good result.
information extraction;GATE;event extraction;Chinese tokenizer;rule matching
TP391 文献标识码:A 文章编号:2095-7327(2017)-05-0041-06
黄海(1987-),男,江西南昌人,广东培正学院教师,研究方向:计算机科学与技术。
张海玉(1978-),女,山西临县人,太原理工大学财经学院副教授,硕士,研究方向:人工智能,物联网。
编辑:董刚
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
校园英语·月末(2021年13期)2021-03-15
英语世界(2021年13期)2021-01-12
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
信息安全研究(2016年4期)2016-12-01
国家图书馆学刊(2016年2期)2016-10-09
图书馆建设(2012年3期)2012-10-23
