
面向设计层次优化的软件自动化重构
2017-11-01 17:14高东静赵文耘
计算机应用与软件 2017年10期
高东静 林 云 彭 鑫 赵文耘
(复旦大学软件学院 上海 201203)
(上海市数据科学重点实验室 上海 201203)
面向设计层次优化的软件自动化重构
高东静 林 云 彭 鑫 赵文耘
(复旦大学软件学院 上海 201203)
(上海市数据科学重点实验室 上海 201203)
目前许多研究人员对自动化软件重构进行了探索并开发了一系列重构工具,旨在帮助程序员更高效地完成软件重构任务、提升代码质量。然而,现有的软件重构工具多侧重于局部的设计或编码问题,而非设计层面的问题。另一方面,基于搜索的重构方法往往将改进某一项代码度量指标作为重构目标,而非面向软件的层次化设计。针对这种情况,提出一种新的基于搜索的软件自动化重构方法,该方法使用了基于设计结构矩阵(DSM)的软件模块层次化度量方法,能够自动生成可以得到最优软件模块化设计的重构建议。在此基础上,实现了自动化重构工具DSMRefactoring,并将DSMRefactoring应用于开源系统进行案例研究,初步验证了方法和工具的有效性。
自动化重构 软件设计 模块化 设计层次
0 引 言
软件重构是对软件内部结构的一种调整,目的是在不改变软件行为的前提下提高可理解性并降低修改成本[1]。在现在的企业实践中,软件的需求和设计的频繁修改常常会带来系统依赖过多、结构混乱等“技术债”问题。这些技术债产生的原因可能是缺乏经验的程序员编程时没有遵行合理的编程规范,也可能是某些程序员为了在有限时间内完成任务不得不破坏原有的代码结构。这些技术债牺牲了代码质量,降低了软件后续开发和维护的效率,并将导致软件系统的退化。因此,为了保证软件系统的可理解性和可维护性,对现有代码进行合理的重构变得非常必要。
目前研究人员对软件自动化重构的场景、用户的自动化重构需求以及应当何时采用自动化重构进行了大量研究并开发了相应的工具[2-3]。这些自动化重构工具大都集成在集成开发环境(IDE)中,可以帮助程序员更高效快速地完成局部代码的重构操作。此外,研究人员也进行了大量研究尝试从更高的层面上对软件进行自动化重构。例如,Cinnéide等研究人员[4]实现了一个基于搜索的、度量驱动的软件自动化重构工具Code-Imp,并利用它分析了各种软件度量之间的关系。该工具可以对代码在总体上进行重构,使得整个系统的某一软件度量值变得最优。
高质量的软件设计往往需要具有良好的模块化和层次化的设计,由此能够让软件代码内部依赖关系能够变得清晰且易于维护。然而,现有的两方面重构工作(即,集成于IDE中的局部代码重构和基于搜索的全局代码重构)仍然有所不足。集成于IDE中的局部代码重构无法提供一个设计层面的重构方案;而基于搜索的全局代码重构虽然能够在总体层面上调整软件的组织结构,但是它们仅能使代码在现有的某个度量值上达到最优,无法得到一个用户可见的模块化与层次化设计。
本文提出了一种新的软件自动化重构方法,该方法基于设计结构矩阵(DSM)[9]将软件的模块层次化情况刻画为可度量的模块层次化度量指标,并利用优化搜索的方法找到一个最优的软件模块层次化方案推荐给软件设计人员,由此来提高软件的可维护性。本方法的主要思想是将某些代码元素(如方法,属性等)分配到更为合理的类或接口中以产生一个更具模块层次的设计。此外,我们基于该方法实现了一个重构工具DSMRefactoring,并使用了开源项目进行案例研究,初步验证了方法和工具的有效性。
1 相关工作
1.1 软件自动化重构
目前,许多研究人员都对软件自动化重构进行了研究。Ge等[2]认为:虽然目前已经有了很多自动化重构工具,但由于开发人员常常不能意识到自己将要或正在进行重构,这些工具并没有在开发过程中得到充分的利用。针对这个问题,他们对开发者的手动重构过程进行了研究,并基于这些研究的发现,实现了一个重构工具BeneFactor来探测用户正在进行的重构操作并提醒和辅助用户完成重构。Vakilian等研究人员在文献[3]中,通过收集和分析程序员的编程数据,研究了软件自动化重构工具的使用情况。他们的调查数据显示,程序员更愿意接受轻量级的自动化重构工具调用方式,而不愿意在使用工具之前先进行配置。调查还发现,有时程序员会忽略重构工具,或者用设计者意料之外的方式来使用工具。Foster等在文献[5]中实现了一个集成在IDE中的重构工具WitchDoctor,该工具可以实时检测一个程序员是否在进行手动的重构工作,如果检测到程序员在手动重构,那么它会在程序员手动完成之前把结果展示出来,并自动完成后续重构工作。与这些针对局部代码设计的重构工作相比,我们的工作侧重于全局的代码重构和调整。
1.2 基于搜索的软件自动化重构
基于搜索的软件自动化重构是目前关于软件自动化重构的研究中的一种常用思想[6-8],这种思想把软件重构问题抽象成属性与方法、属性与类、方法与类之间的组合优化问题,并利用常见的搜索算法来求解。Cinnéide等[4]利用基于搜索的软件自动化重构方法实现了一个重构工具Code-Imp。该工具可以对软件进行设计层面上的重构,实现了类、属性和方法层面上的若干种重构方式,如添加继承关系、取消继承关系、用组合关系代替继承关系等。该工具使用了爬山算法、模拟退火算法和遗传算法等进行优化搜索。Cinnéide等的工作除了对基于搜索的软件自动化重构进行了一次有效的实践外,还分析比较了各种软件度量值之间的相互关系。他们挑选了一些度量值用于研究,通过比较整个重构过程中这些度量值的变化情况,考察了度量值之间的关系与差异。然而,Cinnéide 等的研究工作所考虑的软件度量值都是软件内部的内聚耦合之类的度量值,并没有将软件模块层次化方面的度量纳入研究范围。与这些工作相比,我们的工作侧重于调整出具有良好模块层次化结构的代码。
1.3 软件模块化和层次化研究
在软件设计的相关研究中,研究者们提出了一些重要的思想。其中设计结构矩阵(DSM)模型[9]就是一个十分重要的刻画软件模块化信息的模型,它具有简洁明了的特点。DSM利用矩阵来刻画软件设计空间中的依赖情况,它的每行每列分别代表设计空间中的一个变量,某行某列上的一个标记则代表某行所代表的设计变量依赖于另一列所代表的设计变量。图1中的DSM刻画了一个包含三个设计变量A、B和C的软件设计,其中B和C相互依赖,B同时还依赖于A。从图1我们可以看出,DSM可以用来刻画设计变量的聚类信息:由于B和C相互依赖,B、C可以被划分成一个模块,而A则需要单独划分成另一个模块,图1中的黑线划出了根据设计变量的依赖关系划分出的两个模块。

ABCABXXCX
图1 DSM示例
在此基础上, Wong等提出了设计规则层次(DRH)理论[10]。在DRH中,一个软件中的各个设计变量和它们之间的依赖关系通过DSM来刻画,此外,该DSM中的行和列被重新排序以构成一定的层次结构。图2展示了一个被划分成四层DRH的DSM,图中的细边矩形代表模块,粗边矩形代表层次。DSM模型和DRH理论是软件模块化和层次化方面十分重要的理论,它们对软件特征的刻画十分清晰。此外,利用矩阵来刻画软件结构使得设计一个度量值来度量软件的模块化和层次化变得可行。本文设计实现的面向设计层次优化的软件自动化重构工具所使用的度量值就是基于这套理论所设计的。这些工作的主要贡献在于呈现出代码的模块化信息,而我们的工作侧重于解决如何将代码变得更模块层次化的问题。
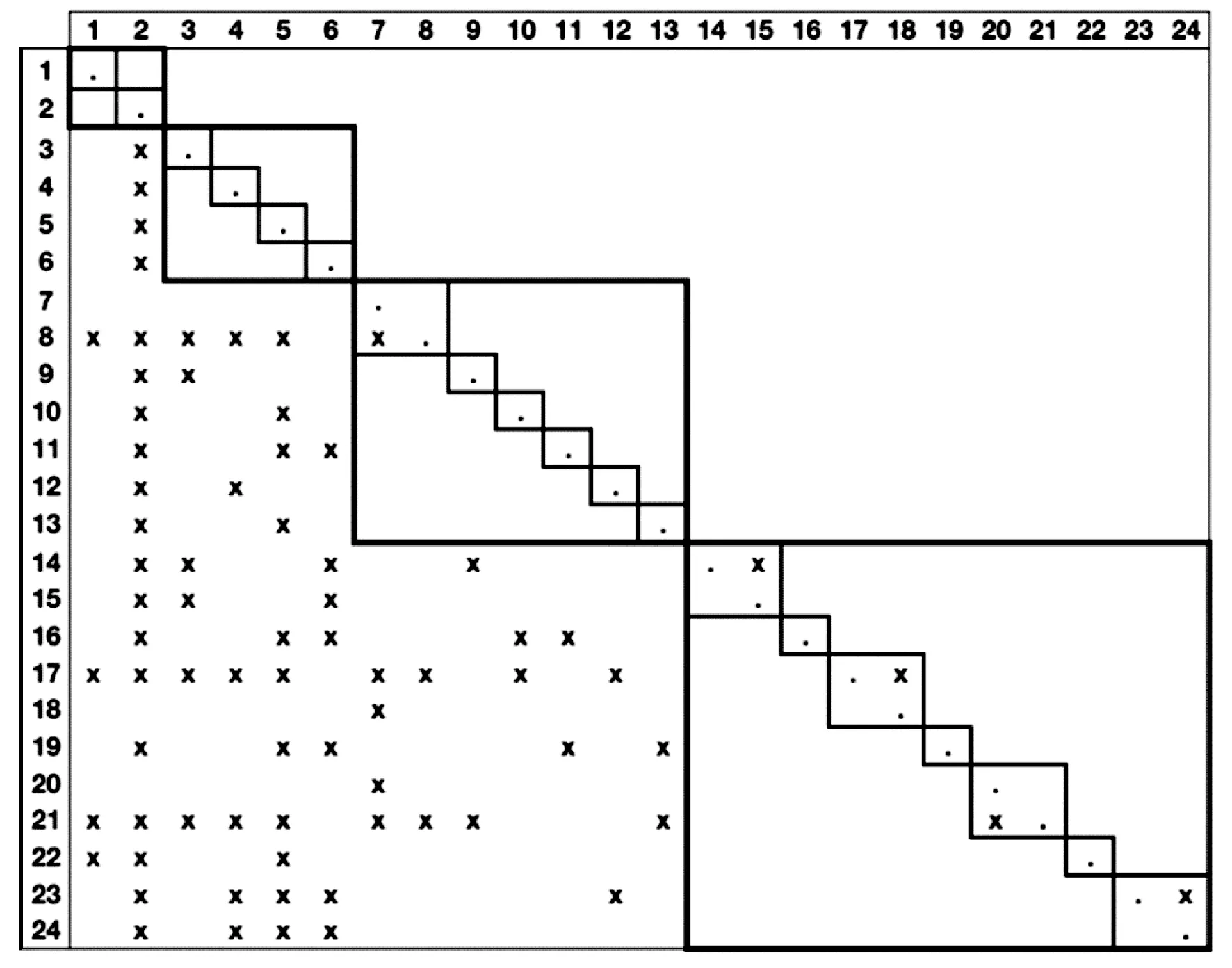
图2 被划分成四层DRH的DSM
2 面向设计层次优化的软件自动化重构方法
DSMRefactoring通过改变代码类之间的依赖关系来改善软件的层次化结构。我们方法的输入是某一个项目的源代码,输出是针对该项目代码的重构建议。首先,我们对项目的源代码进行内部依赖关系的分析以得到程序元素之间(类、方法和属性之间)的依赖关系。然后,我们通过调整类成员(方法或属性)与类之间的映射关系(即,哪个类成员应属于哪个类)来提高项目源码的模块化程度。在这个过程中,我们利用遗传算法和基于DSM矩阵的模块层次化度量方法来计算出类成员对各类的最优映射关系。最后,我们对比现有的类成员与类的映射关系和遗传算法计算出的最优类成员与类的映射关系,由此生成重构建议并展示给软件开发人员。
2.1 基本思想
本文将Java类之间的依赖关系作为软件模块化和层次结构的一个重要依据,而Java类之间的依赖关系实际上是通过类中的属性和方法之间的相互依赖产生的,因此,我们可以通过改变类成员与类之间的映射关系来改变Java类之间的依赖关系,从而改变整个Java项目的层次结构。如图3所示,A、B、C三个类本具有相对复杂的依赖关系(图3(a)),通过从类B中移动方法m3()到类C中能够解耦A、B之间的互相依赖(图3(b)),而再通过从类B中移动属性b1到类C中,则可以得到一个比较好的层次依赖结构。因此,我们旨在通过调整类成员与类之间的映射关系来改善原项目代码的模块化层次结构。
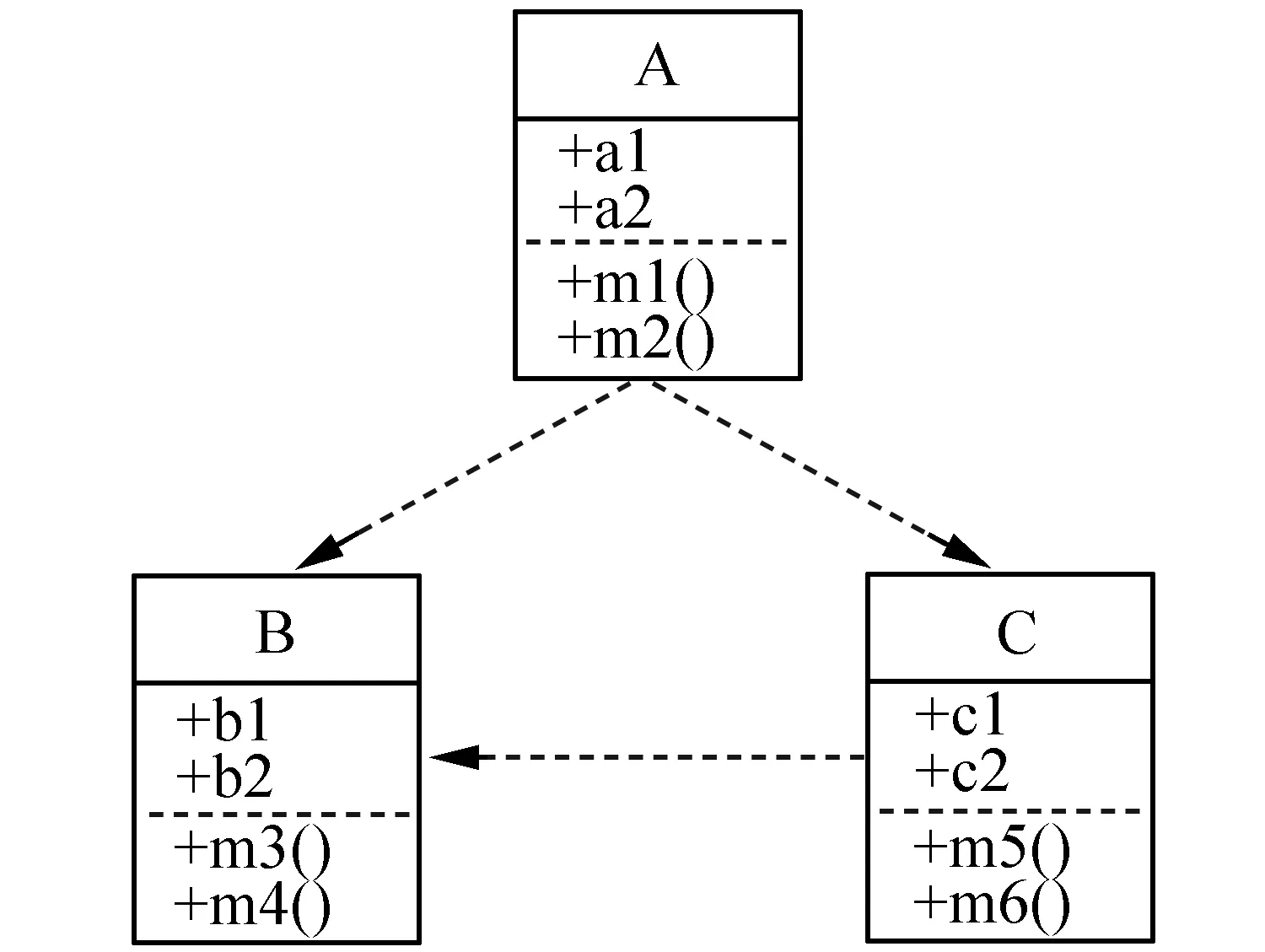
(a) 初始类图
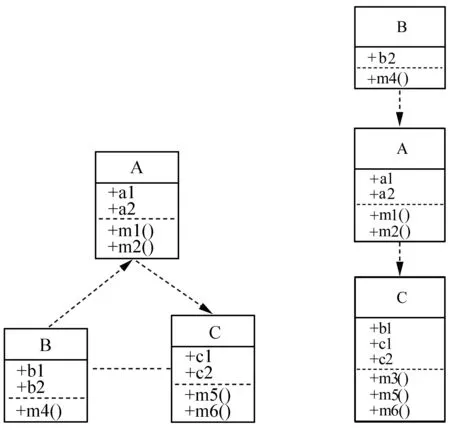
(b) 移动m3之后的类图 (c) 移动b1之后的类图图3 通过改变成员与类的映射关系改变设计的层次结构
2.2 算法过程
基于上述思想,我们利用遗传算法通过不断改变各个类成员与各类之间的映射关系,计算和比较软件结构对应的模块层次化度量值(由此来判断某一结构的优劣),来对软件结构进行优化。该重构遗传算法的搜索空间是各个类成员和类之间所有可能的映射方式(即,哪个类成员应处于哪个类之中),软件的模块层次化信息通过DSM来刻画,并通过度量值L(Layering)来度量,具体的度量方法在下一节中详述。算法中使用的个体代表了类成员和类的映射关系,个体中的每一个基因位代表一个类成员,而基因位的值代表对应类成员所在的类。
2.2.1 目标函数
1) 目标函数度量介绍
本方法所采用的目标函数基于DSM模型和DRH理论。给定一个个体,即类成员与类的映射关系,我们可以通过类成员之间的依赖关系来得到它们所在类之间的依赖关系。本节所使用的DSM中,行和列代表的设计变量都是Java类(如图4),设计变量之间的依赖关系也就是Java类之间的依赖关系,Java类之间的依赖关系则通过类中的属性和方法之间的调用关系来决定。

(a) 5个Java类组成的DSM (b) DSM中的层次结构图4 DSM示例
图4(a)展示了一个由5个Java类组成的DSM样例,图中第i行第j列的1表示类i依赖于类j,0则表示没有依赖。每个Java类与它本身的依赖关系不需要考虑。根据DRH理论,DSM的行和列可以被重新排序来展示层次结构,图4(b)就展示了(a)中的DSM所代表的层次结构,其中每个加粗的矩形代表一个层次,下层依赖于上层。
在此基础上,软件层次结构的好坏用度量值Layering(L)来度量,一个DSM(M)的L值被这样定义如下:
L=4×l2-4×n-m
(1)
其中l是DSM的行数,也就是Java类的个数,n是DSM中右上角的1的个数,m是DSM中左下角不符合层次化约束(在下文中将介绍层次化约束的具体定义)的1的个数。在Java类的个数l一定的情况下,L的值越大表示软件的层次化结构越好。度量值L的定义可以分成三部分:4×l2,-4×n和-m。其中4×l2是一个由l个类组成的软件的L度量值的最大值;-4×n和-m则分别是对软件中可能存在的两种违背层次化要求的结构(反向依赖情况与跨层依赖情况)采取的惩罚措施。
• 反向依赖情况
4×n针对的是DRH的第一个特征:DSM沿对角线形成的右上角为空。DSM矩阵中呈现的模块依赖应该是偏序的(即右下角的模块应依赖于左上角的模块,反之不然),因此,如果DSM的右上角上出现了依赖关系,则说明软件中出现了反向依赖的模块,违背了软件层次化的要求,会使L值降低。我们认为由于DRH的这一偏序要求十分必要,违背了这个要求的软件,其层次化结构往往容易腐化,所以本节的算法赋予了这种依赖关系更高的权重,它们会更直接地影响L的值。
• 跨层依赖情况
m针对的则是另一种层次化约束,这一约束是相对于DRH的另一个特征:设计中的第n层只依赖于第1到第n-1层提出的。在本文中,模块将进一步被划分层次,依赖关系只应该存在于相邻的层次之间,而不应该存在于跨级层次之间。即,本文认为,当一个具有好的层次结构的软件设计被划分成若干层之后,设计中的第n层并不能依赖于第1到第n-1的所有n-1层,而是只能依赖于第n-1层,也就是说好的层次结构应当如图5所示。图5中的细边矩形代表模块,粗边矩形代表层次。
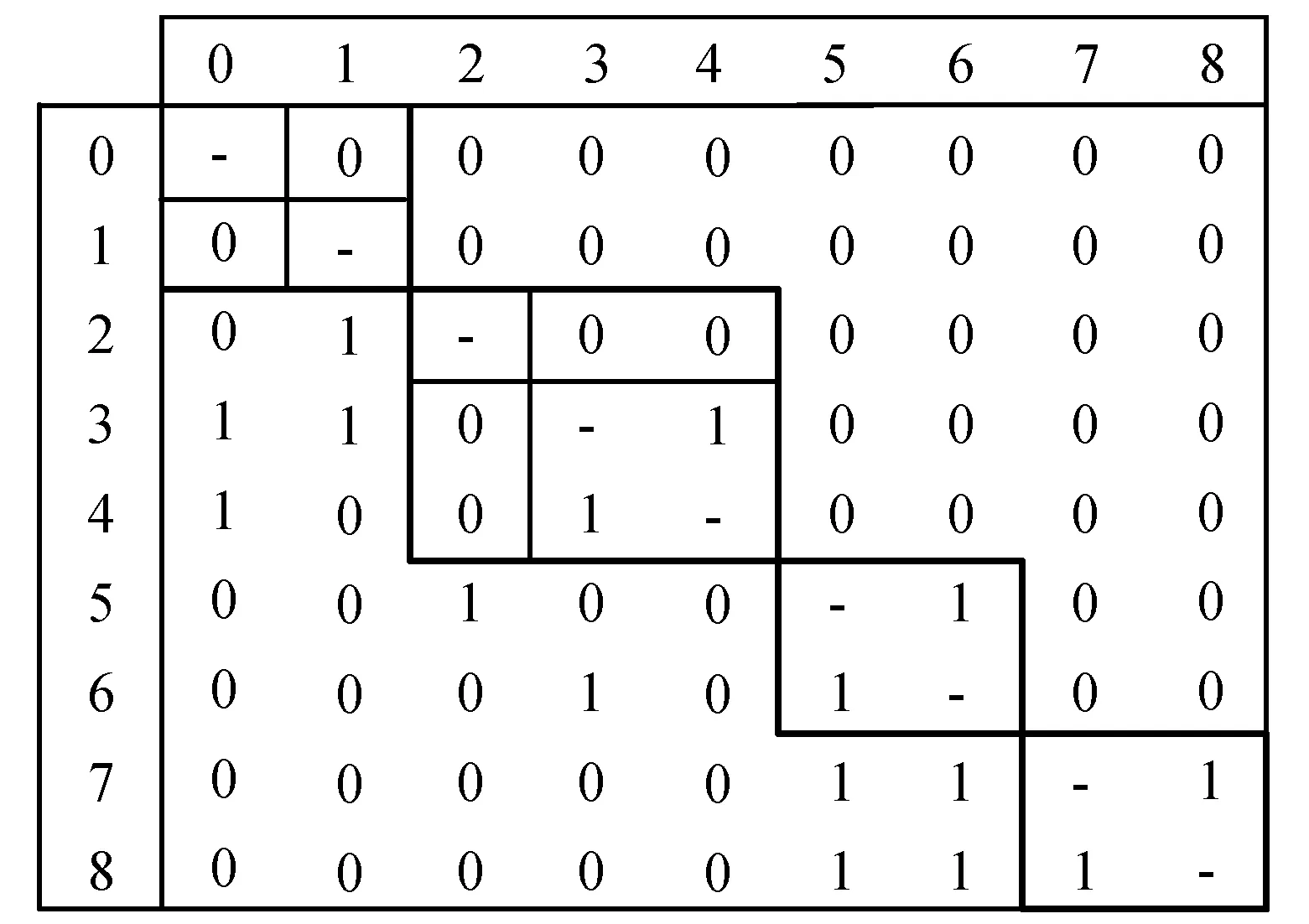
图5 符合层次化约束的DSM
2) DSM矩阵L值计算
我们使用了迭代的方式来计算一个代码结构DSM的L值,过程如下:(1) 对DSM中的设计变量进行聚类(即重新排列DSM矩阵的行及其相应的列),将某些相互依赖的设计变量划分成一个模块,图6(a)就表示了图5中的DSM对应的模块划分。(2) 对上一步产生的模块进行层次划分,将相邻的所有相互独立的模块划分到一个层次中,并计算对应的L值,图5、图6(b)就分别表示了该DSM中的一种模块聚类情况,以及对应的层次划分结果,图6(b)中的阴影标明了这种排列中对应的违背要求的项,其中,图5中的DSM变形对应的L5=4×l2-4×n-m=4×92-4×0-0=324,而图6(b)对应的L6b=4×l2-4×n-m=4×92-4×5-4=300。在这一步计算中,本文采用的做法是对所有可能的模块排列顺序都进行一次层次划分并计算对应的L值,以确保L值计算的准确性。(3) 迭代(1)、(2)中所有排列取最大值作为该DSM最终的L值,并记下对应的设计变量的排列顺序,例如上述举例中的DSM最终的LD=L5=324,对应的设计变量的排列顺序如图5所示。值得注意的是,这个例子中的L5达到了9个类组成的软件的最大L值,当发现当前的L值已经达到最大值时,则重构算法直接结束。
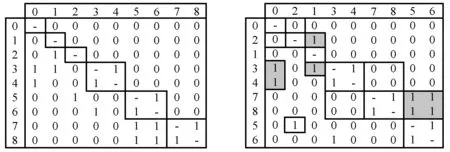
(a) 图5的模块分割 (b) 另一种可能的变体图6 计算一个DSM的L值
完成聚类之后,需要根据聚类产生的模块排列顺序来对模块进行分层,连续的所有两两相互独立的模块都属于同一个层次。在计算L值时,实际算法使用的DSM的每一行(列)代表的都是划分之后的一个层次,图7展示了图5在实际计算时对应的DSM。每个层次用大括号表示,大括号中的数字表示这个层次中包含的Java文件,矩阵中的数字表示一个层次中依赖于另一个层次的Java文件的个数。

图7 计算时使用的DSM
2.2.2 选择算子
在遗传算法中,选择算子的作用是从同一代的个体中选择出合适的个体来产生下一代,其目标是把优胜的个体(或问题的解)直接遗传到下一代,或者让这些优胜的个体或解通过产生后代的方式遗传到下一代。在本节中,选择算子的目标就是从同一代的各种软件结构中,选择出对应DSM的L值最大的来产生下一代。
DSMRefactoring中使用的选择算子是最基本的比例选择算子(轮盘赌选择):同一代中的每个个体被选中的概率与它对应的DSM的L值的大小成比例,L值越大被选中的概率也越大。假设每代有n个个体,其中第i个个体对应的DSM的L值为Li,则它被选中的概率Pi为:
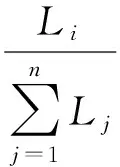
(2)
2.2.3 交叉算子
在遗传算法中,交叉算子起到了提高算法搜索能力的核心作用。交叉算子通过将选择算子选择出的两个父代个体的部分结构进行重组来产生下一代中的新个体。在本节中,交叉算子的作用是将通过选择算子选择出的父代中的软件结构进行交叉重组,生成新一代的软件结构,在搜索空间中搜索最优解。
DSMRefactoring采用了均匀交叉的方法。具体实现中使用的交叉概率是0.5,这样从概率上来说,两个父代个体产生的下一代个体的软件结构中,来自两个父代个体中的软件结构各占一半。交叉算子的实现如下:两个父代个体代表了两种软件结构,各自分别用对应的类成员列表来表示,列表中的每个成员都记录了当前所在的Java类,在执行交叉之前,分别对两个父代个体进行克隆,然后分别对克隆个体的列表中的每个成员进行如下操作:(1) 比较两个克隆个体中该成员所在的类是否相同,若相同,结束对该成员的操作。(2) 如果在这两个克隆个体中,该成员所在的类不同,则随机产生一个布尔值,如果该值为真,那么就将两个克隆个体中该成员所在的Java类互换,否则,结束对该成员的操作。
经过上述操作,原本的两个克隆个体就变成了两个新个体,经过下一节的变异算子的操作后,就会成为下一代中的两个个体。
2.2.4 变异算子
变异算子通过对个体中的某些结构进行改动,提高了遗传算法种群的多样性,由此避免了遗传算法往局部最优解收敛的情况。在本节中,交叉算子的作用就是对需要变异的软件结构中的某些结构进行改变,产生新一代的软件结构。DSMRefactoring中使用的变异算子是这样设计的:(1) 根据变异概率来判断每个个体是否需要变异。(2) 从需要变异的个体的类成员列表中,随机选择一个属性或方法将它根据一定的概率移动到另一个类中。
3 案例分析
本文使用DSMRefactoring对若干个Java项目进行了自动化重构实验,并通过实验数据对DSMRefactoring进行了评估。我们使用的实验项目包括了开源计算器软件Calculator (http://plugins.jedit.org/plugins/?Calculator)。在实验过程中,我们主要根据两方面的实验结果来对DSMRefactoring进行评估,验证该工具的有效性:(1) 遗传算法是否能有效地得到最优(次优)解;(2) 最终的重构建议是否合理有效。
3.1 遗传算法的有效性
DSMRefactoring在对Calculator开源项目进行重构的过程中,共产生了256代个体,每代包括1 280个个体。为了分析重构过程中的收敛情况,DSMRefactoring在重构过程中对每一代个体都计算了最优目标函数值、平均目标函数值和目标函数值的标准差,表1展示了其中的部分数据结果。

表1 Calculator重构过程中的迭代数据
从表1的数据中我们可以看出:总体来说,每一代中的最优目标函数值一直在变大,但也存在一些例外,有些时候会出现最优L值先变大再变小的情况,而且最优L值的变化幅度在重构刚开始和快结束时比较小,在中期比较大;每代的平均目标函数值一直处于稳步的上升中;目标函数值的标准差则是先变大再变小。
由此可以看出:在整个重构过程当中,Calculator每一代的软件结构整体上来说都在变好,最好的软件结构也基本上在越变越好,但有一些特例,不同的软件结构之间的差距则是先变大后变小。通过上述分析,我们可以看出:DSMRefactoring在对项目进行重构的过程中,项目的结构是在不断向更好的方向收敛的,本节实现的重构方法是合理有效的。
3.2 重构结果的合理性
我们通过观察重构建议的结果与经典的设计结构进行比较,来验证重构建议的合理性。为了避免因为人的主观因素而影响评估结果,我们只针对经典的设计结构进行观察,例如MVC架构、观察者模式、访问者模式等。根据我们对Calculator项目最初的软件结构的观察,它的结构主要包括四个部分:界面、监听器、计算功能和辅助功能。用户通过在界面上点击不同的按钮触发不同的监听器,继而调用不同的功能,这是一个典型的MVC架构,Calculator中的界面部分对应MVC中的View模块,监听器部分对应MVC中的Controller模块,计算功能和辅助功能部分则对应MVC中的Model模块,他们之间理想的依赖关系应当如图8所示。

图8 理想的MVC架构
但是,在Calculator原本的实现中,一些对计算功能的调用被直接放在了CalculatorPanel类中的方法中,这导致CalculatorPanel类对实现了计算功能的类(如Op、Num等)产生了直接的依赖,也就是图8中的View模块对Model模块直接产生了依赖关系,这破坏了原本的MVC架构。而在DSMRefactoring的重构结果中,这些依赖关系都被去除了,下文将详细地描述这一结果。为了更清楚简洁地描述这一过程,下文将只分析界面、监听器和计算功能三个模块之间的结构,其中界面模块只表示CalculatorPanel一个类,监听器模块表示ZeroOpListener、BinaryOpListener和UnaryOpListener三个类,计算功能模块表示Op和Num两个类。
Calculator原本的设计结构可以用图9中的类图表示,从这个类图中我们可以看出,由于CalculatorPanel类对Op和Num类产生了直接的依赖,整个软件的结构比较混乱,类与类之间的依赖关系很复杂,无法看出任何层次关系或设计架构。图10表示了对应的DSM图,其中模块和层次的表示方法如前文,阴影部分标出了图中违背结构要求的依赖关系。
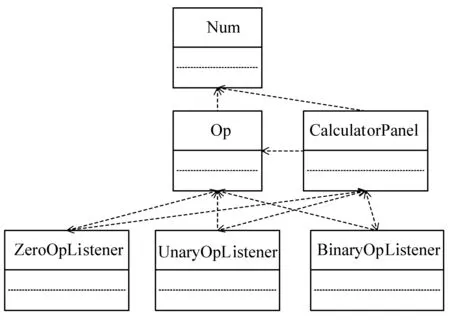
图9 重构之前的类图

图10 重构之前的DSM
图11则表示了重构之后Calculator的软件结构,从图11我们可以看出,经过重构,Calculator显示出了良好的层次结构,类与类之间的依赖关系十分清晰,整个软件层次分明,结构良好。
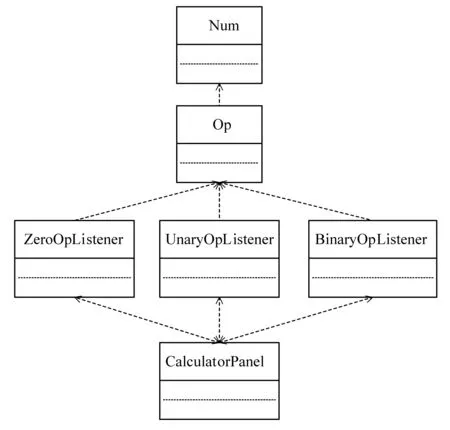
图11 重构之后的类图
图12表示了对应的DSM图,表示方法同图10,从图中我们可以看出,DSM中各Java类之间的依赖关系都符合层次化约束,但仍然存在违反偏序要求的依赖关系(即最优的重构方案依然可能违反DSM偏序关系)。在Calculator项目中,View模块会调用Controller模块,Controller模块也需要把Model模块的处理结果显示在View中,这两者之间无法解耦。这也说明,并不是在每次重构中,最终的重构结果对应的L值都能达到最大值。通过该案例研究,我们可以初步得出本文所提出的面向设计层次优化的软件自动化重构方法有一定实用价值。

图12 重构之后的DSM
4 结 语
关于软件自动化重构的研究有很多,但现有重构工具多侧重于局部代码的重构或针对某些度量值的重构,很少考虑提高代码模块化质量的全局性重构。本文实现了一个面向设计层次优化的软件自动化重构方法,该方法基于遗传算法和DSM矩阵度量公式来调整类成员与类之间的映射关系,并向软件开发人员提出重构建议。同时,我们实现了相应工具DSMRefactoring,并通过案例研究初步证明了方法的有效性。
[1] Fowler M. Refactoring: improving the design of existing code[M]. Boston: Addison-Wesley Professional, 1999.
[2] Ge X, Dubose Q L, Murphyhill E. Reconciling manual and automatic refactoring[C]// International Conference on Software Engineering. IEEE, 2012:211-221.
[3] Vakilian M, Chen N, Negara S, et al. Use, disuse, and misuse of automated refactorings[C]// 34th International Conference on Software Engineering (ICSE), Zurich, 2012. Piscataway: IEEE Press, 2012: 233-243.
[4] Cinnéide M ó , Tratt L, Harman M, et al. Experimental assessment of software metrics using automated refactoring[C]// Acm-Ieee International Symposium on Empirical Software Engineering and Measurement. IEEE, 2013:49-58.
[5] Foster S R, Griswold W G, Lerner S. WitchDoctor: IDE support for real-time auto-completion of refactorings [C]//Proceedings of the 2012 International Conference on Software Engineering, Zurich, 2012. Piscataway: IEEE Press, 2012: 222-232.
[6] Harman M, Tratt L. Pareto optimal search based refactoring at the design level[C]// Proceedings of the 9th Annual Conference on Genetic and Evolutionary Computation, London, 2007. New York: ACM, 2007: 1106-1113.
[7] O’Keeffe M, Cinnéide M. Search-based refactoring: an empirical study[J]. Journal of Software Maintenance & Evolution Research & Practice, 2008, 20(5):345-364.
[8] O’Keeffe M, Cinnéide M. Search-based refactoring for software maintenance[J]. Journal of Systems & Software, 2008, 81(4):502-516.
[9] Cai Y, Sullivan K. A formal model for automated software modularity and evolvability analysis[J]. ACM Transactions on Software Engineering and Methodology (TOSEM), 2012, 21(4): 21.
[10] Wong S, Cai Y, Kim M, et al. Detecting software modularity violations[C]// Proceedings of the 33rd International Conference on Software Engineering, Hawaii, 2011. New York: ACM, 2011: 411-420.
AUTOMATICSOFTWAREREFACTORINGTOWARDSTHEOPTIMIZATIONOFDESIGNHIERARCHY
Gao Dongjing Lin Yun Peng Xin Zhao Wenyun
(SchoolofSoftware,FudanUniversity,Shanghai201203,China)(ShanghaiKeyLaboratoryofDataScience,FudanUniversity,Shanghai201203,China)
At present, many researchers have explored automated software refactoring and developed a series of refactoring tools designed to help developers conduct refactoring tasks with more efficiency and improve the code quality accordingly. However, existing software refactoring tools mainly focus on improving the code quality from a local perspective instead of an overall design perspective. On the other hand, search-based refactoring approaches usually aim at improving some specific code metrics instead of modularized and layered software design. This paper proposes a novel search-based automatic software refactoring approach, which leverages DSM-based code metric to modularize code. This approach is able to generate refactoring suggestions to achieve an optimal modularized and layered software design. This paper also introduces a proof-of-concept tool, DSMRefactoring, and applies the tool on an open-source system. The results validate the effectiveness of both the approach and its proof-of-concept tool.
Automatic refactoring Software design Modularity Design hierarchy
TP311
A
10.3969/j.issn.1000-386x.2017.10.002
2016-12-22。国家自然科学基金项目(61370079);国家高技术研究发展计划(2012AA011202)。高东静,硕士,主研领域:软件自动化重构,缺陷预测,程序分析。林云,博士。彭鑫,教授。赵文耘,教授。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
上海文化(文化研究)(2022年3期)2022-06-28
吉林大学学报(信息科学版)(2022年1期)2022-01-14
五邑大学学报(自然科学版)(2019年3期)2019-09-06
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
