
基于内容和信任度的舆情扩散研究
2017-11-01 17:14陈振春刘学军
计算机应用与软件 2017年10期
陈振春 刘学军 李 斌
(南京工业大学计算机科学与技术学院 江苏 南京 211816)
基于内容和信任度的舆情扩散研究
陈振春 刘学军 李 斌
(南京工业大学计算机科学与技术学院 江苏 南京 211816)
为提高微博网络中预测舆情转发规模和扩散深度的准确度,提出一种基于内容和信任度的舆情扩散预测算法。首先,依据微博网络中用户和舆情的内容信息,提取影响舆情扩散的特征指标,同时,结合用户间的信任关系,建立在单一邻居已转发舆情情况下用户转发行为的预测模型。继而,基于该模型和线性阈值模型,对多邻居已转发舆情的情况进行深入分析,最终完成对舆情转发规模和扩散深度的预测。实验结果表明,该算法显著提高了转发规模和扩散深度的预测准确性。
舆情 内容 信任度 转发规模 扩散深度 预测
0 引 言
随着科学技术的发展,社会网络作为一种网络应用,为用户提供了信息共享和交互式服务,逐渐变成了舆情扩散的重要平台。如新浪微博,作为国内最大的社会网络,截止2015年9月30日,仅微博日均活跃用户数(DAU)已达到1亿,月活跃用户数(MAU)达到2.22亿。在微博网络中用户可以通过手机终端在任意时间进行访问和交互,高效的信息交互模式极大地缩短了舆情产生和扩散的时间。
目前主要的舆情扩散预测方法包括基于内容的预测、基于信息扩散模型与内容的预测、基于时间序列的预测等。其中基于内容的预测是目前微博网络上舆情扩散预测研究中所采用的最为重要也是最成功的技术之一,其认为要分析用户的转发行为[1-2],首先要从用户、舆情中提取内容,然后建立用户转发行为的预测模型。基于此模型进行各项研究,如舆情的变化状态(包括舆情的产生、发展和衰落)、舆情分析系统的建立,以及舆情扩散预测等。
目前已有的舆情扩散预测算法在预测接收用户的转发行为时,通常仅仅依靠内容信息,而忽略了接收用户对传播用户的信任关系。且在研究中只考虑在单一邻居已转发舆情的情况下接收用户的转发行为,忽略了已转发了某一舆情的多邻居对接收用户的影响,从而导致预测结果的片面性。针对上述问题,本文从内容信息和用户间的信任关系出发,提出了一种基于内容和信任度的舆情扩散预测算法CT-PODP。
1 相关工作
近年来国内外学者对舆情扩散预测开展了一系列工作。Xu等[3]提出了倾向性预测算法来预测网络舆情的发展状况,作者首先将舆情分为产生、发展、消亡三个阶段,然后用二次方程式方法预测舆情的走向。Hong等[4]提出了基于复杂网络的建模方法,将微博作为研究对象,通过产生边、增加边、随机增加边的方式来反映用户行为和微博舆情传播的特性,于是建立起了微博网络舆情的增长模式;再利用MATLAB工具箱建立起了仿真模型,以便有助于发现传播过程中微博网络舆情增长规律。Zhao等[5]考虑了节点度、社会网络独特的扩散规则以及用户习惯等特性,利用传播学和复杂网络理论,提出了在社会网络中基于SEIR的舆情传播模型。通过用户的参与度和舆情主题的流行度来研究舆情扩散率。周东浩等[6]从多个角度提取信息传播特性,包含节点属性和信息内容的特征,对节点间的传播概率和传播延迟进行建模,基于AsIC模型提出一个细粒度的在线社会网络信息传播模型。Zhao等[7]基于跟随者的意图和影响力提出了信息转发量预测模型BCI。在这个模型中,信息主要来自直接跟随者和间接跟随者,且跟随者的转发量主要由他们的转发意图和影响力决定,通过行为和内容信息来评估直接跟随者的转发意图,用影响力来评估间接跟随者的转发量。Ding等[8]研究了转发活动中所用的反应时间,并引入了时间序列的预测模型,该研究表明反应时间具有重尾分布特性,且对数正态分布能很好地拟合反应时间的数据。在时间序列预测框架下,对于直接的转发者,作者通过解决截断对数正态分布的参数评估问题做出预测;对于间接的转发者,作者基于通用的信息扩散理论做出预测。Hong等[9]等人通过测量信息转发量的方式来研究其流行度的问题,并阐述了在推特上影响信息扩散的因素,进而预测信息是否会被转发。Adali等[10]认为信任是用户间重要的社会关系,在算法上提出了对信任关系的量化标准,即通过观察社会网络中的通信行为来量化信任关系。Hou等[11]基于转发行为的分析,提出了预测信息转发规模和扩散深度的算法,然而该算法没有考虑用户间的信任关系,在多邻居作用下的用户转发预测也需要优化、改进。
本文在前人研究的基础上,改进了舆情转发行为的预测模型,提出了基于内容和信任度的舆情转发规模与扩散深度的预测算法,从而使得预测用户的转发行为、舆情转发规模和扩散深度更准确。本文通过研究三个方面来分析扩散预测效果。第一,微博中转发行为的预测,即用户是否会转发某一舆情;第二,舆情的转发规模,即转发某一舆情的用户总数;第三,舆情的扩散深度,即舆情的最远传播距离。对这三个问题的研究有助于捕捉现实生活中发生的舆情热点,了解微博社会网络中的扩散机制,且在市场应用、舆情监管方面起到重要作用。
给定一个有向无权图G(V,E)来表示微博网络,u∈V是网络中的节点集合,u代表着微博用户,
图1中实心圆表示转发用户,处于传播状态;空心圆表示非转发用户;双圆表示发布用户,即舆情的原创用户。
2 基于内容及信任度的舆情转发预测
在微博网络中,影响舆情扩散的因素有很多,诸如传播用户对接收用户的影响力、接收用户对舆情的喜好程度以及舆情自身的流行度等。除了考虑这些内容因素外,还需要考虑用户间的信任度,且信任度越大,接收用户转发的可能性也就越大。
本文根据影响舆情扩散的因素以及信任关系,综合度量微博用户的转发行为,并给出了具体的计算方法。
2.1 内容提取
传播用户影响力In(u):即传播用户对邻接用户在转发行为方面的影响程度。相关研究表明,传播用户的影响力是影响用户转发行为的重要因素[12],且社会网络中拥有大量跟随者的用户更有可能成为有影响力的节点,这意味着他们的舆情有更大的概率被他人转发。在社会网络中,PageRank算法经常用来评估用户的影响力。因为社会网络中用户的跟随者可被认为网页中的入链,其关注的用户类似网页中的出链,所以算法可使用用户关系特征来测量用户影响力。初始时赋予所有用户相同的影响力权重,In(u)值为1;然后将每个用户的影响力权重按照其关注的人数等量分配;最终根据式(1)计算用户新的影响力值In(u)。PageRank算法是在搜索引擎中确定网页重要性的方法,其计算公式如下:
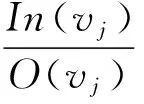
(1)
In(ui)是用户ui的影响力,I(ui)是用户u的跟随者集合,O(vj)是用户vj所指向的用户集合。
d为0~1 之间的一个阻尼系数,取d为0.85[13]使最后结果收敛。
为了避免对度量单位选择的依赖性,需要对数据进行规范化处理,以解决数据指标之间的可比性。记社会网络中用户所拥有最大入度为Max(InDegree),该用户拥有最大的粉丝量。

(2)
接收用户兴趣度Sim(u,w):即接收用户对舆情感兴趣的程度。由于TF-IDF算法简单快速,结果比较符合实际情况。所以本文首先将用户过去一段时间内发布的舆情汇总成一篇文档,用词项的TF-IDF值构建文档向量U。同样的方法也用于构建舆情的文档向量W。采用余弦相似度计算接收用户对舆情的感兴趣程度。
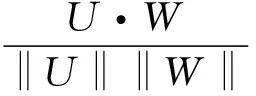
(3)
其中,U、W分别代表用户u和舆情w的文档向量。Sim(u,w)越大,接收用户对舆情越感兴趣;Sim(u,w)越小,接收用户对舆情兴趣度很低或不感兴趣。
舆情流行度Popularity(w):即舆情被微博用户关注的程度,可用当前舆情的转发量Tw(w)进行衡量,因为转发量越大,舆情越流行。微博用户可直接转发或间接转发舆情。因为舆情转发量数值可能会很大,因此需对其进行归一化处理。
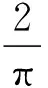
(4)
2.2 信任度Tr(u,v)
在舆情传播的过程中,信任机制也起到了重要作用。当接收用户对传播用户很信任时,该用户越容易转发其舆情;当对传播用户信任度很低或不信任时,其转发舆情的可能性就很小。在一时间段t内,接收用户u转发传播用户v微博的数量与v所有微博数量的比率。
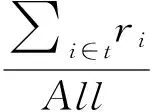
(5)
ri是接收用户在第i天转发微博的数量;All是传播用户在时间段t内所有微博的数量,包括用户v转发、发布、评论等行为产生的微博。
2.3 舆情转发率计算
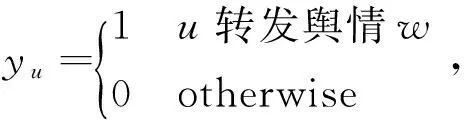
逻辑回归是解决二分类问题一种有效方式,在此我们使用它来对接收用户的转发率进行计算。
g(u)=p(yu|u,v,w)=
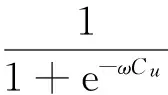
(6)
式(6)考虑内容信息的同时,也考虑了信任度,通过基于内容和信任度的加权融合来对用户的转发行为进行预测。调和级数α表示权重(0≤α≤1)。当α越大时,信任关系在舆情扩散过程中越重要;当α越小时,用户、舆情中的内容在舆情扩散过程中起到主导作用。
在接收用户u、传播用户v,以及舆情消息w已知的条件下,p(yu|u,v,w)就是接收用户u对用户v扩散的舆情w的转发率。
Cu是用户u转发行为的特征集合,包括:传播用户影响力InNomalized(v)、接收用户兴趣度Sim(u,w)、舆情流行度Popularity(w),ω表示其不同特性对转发行为重要性的特征向量;ω可通过比较方便的最大似然函数的方法获得。
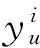
(7)
这位家长称:“名字挺好——《叶问》,一年级才学一个半月,字都写不了几个,要完成科学老师完全没有带过的12页手写项目学习报告,我看,名字还是改成《咋整》吧。”这位爸爸是个工科男,花了整整两天完成作业,“更气人的是,有一项还要收集一棵树不同时期的树叶,坑死了,上哪找去?”
(8)
(9)
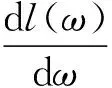
3 基于转发行为的舆情扩散预测算法
通过分析2.3节提出的转发行为预测模型,可以得出如下结论:在微博网络中,当用户接收到某一舆情时,就能获取到其转发该舆情的概率。基于此,本节进一步研究了微博网络中舆情的转发规模和扩散深度。假定微博网络中用户有两种状态:激活状态、免疫转态。实心圆表示用户处于激活状态,即用户转发了舆情;空心圆表示用户处于免疫状态,即用户未转发舆情。距离中间节点最远的传播用户与发布用户的距离代表着舆情扩散的最长路径。为了描述方便,我们定义距离发布用户为1的跟随用户为第1级跟随者;如果距离为m,我们定义其为m级跟随者。
由于舆情沿着用户间关系进行扩散,因此,从发布用户开始,遍历跟随用户来预测每个用户的转发行为,当接收用户的转发率大于给定的阈值时,则判定该用户转发该舆情,反之,则判定其没有转发。然后,对转发舆情的用户进行遍历,重复上面的过程,直到没有传播用户为止,最终获得转发舆情的用户集合。
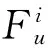
舆情扩散预测的主要流程如图2所示。
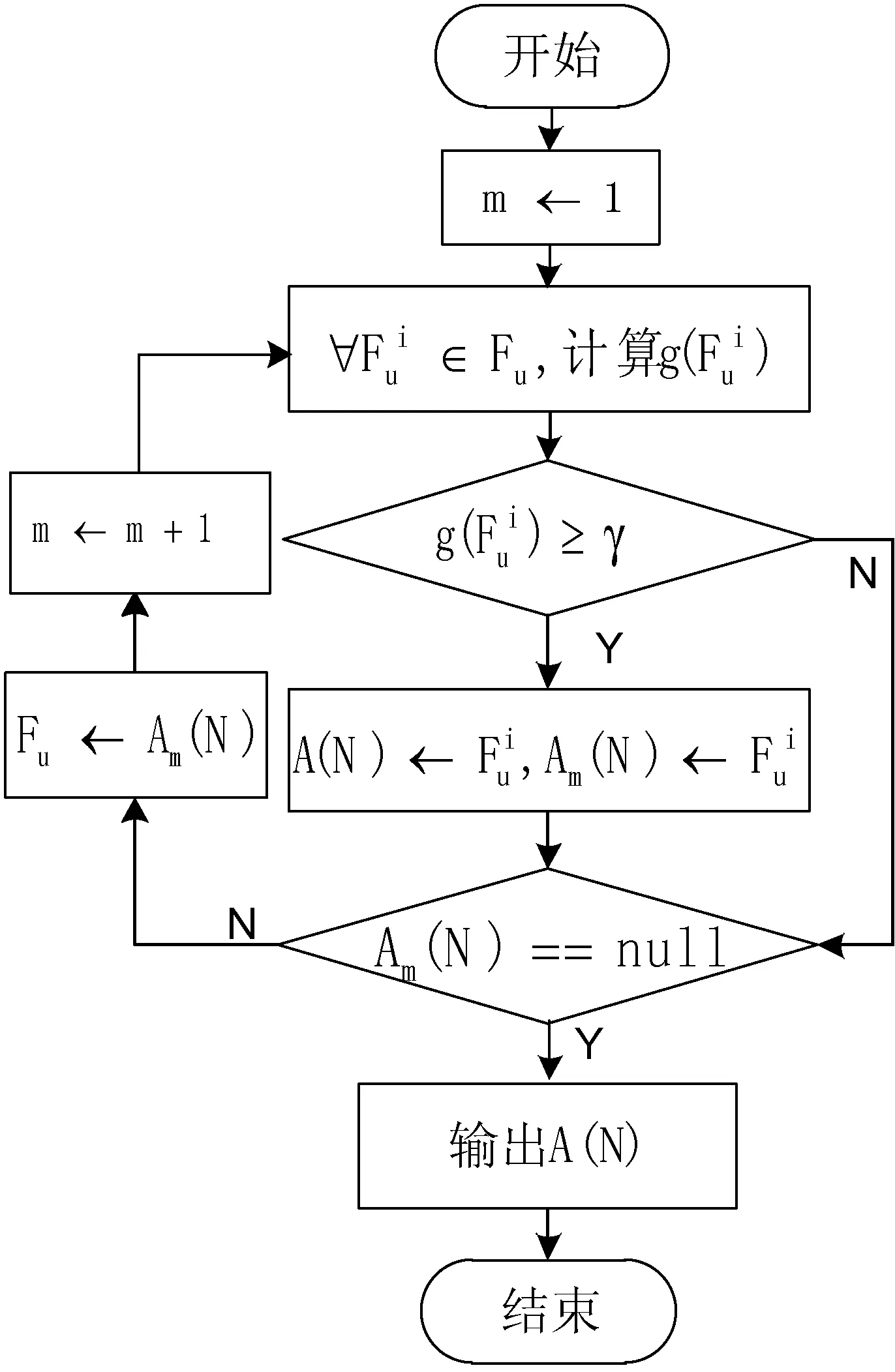
图2 舆情扩散流程
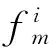
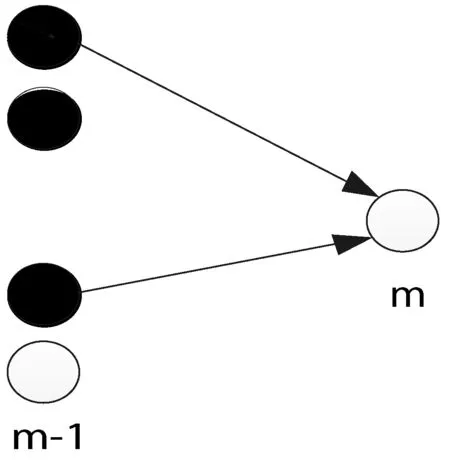
图3 社会网络中多邻居已转发舆情的情形
此时,上节给出的公式并不适用,但为研究多个邻接传播用户情形下计算接收用户的转发率提供了基础。

(10)
(11)
为了使转发率进行归一化,在此引入了2.1节提出的社会网络中最大入度Max(InDegree)。该公式适用于研究一个或多个邻接传播用户影响下接收用户转发舆情的可能性。
因此可以通过比较归一化后的转发率与阈值θ的大小来判断用户是否转发了舆情,同时记录当前舆情的转发量。当用户的转发率满足等式(12),m的最大值就是扩散深度Rd。
(12)
最后计算集合A(N)中的用户总量,转发规模Rs=count(A(N))。
根据上述算法思想,结合图2中舆情扩散流程,给出基于内容和信任度的舆情扩散预测算法(CT-PODP)如下:
输入:G(V,E),发布用户u,舆情w,转发u的舆情的用户集合A(N),u的第m级转发舆情的用户集合Am
输出:转发规模Rs,扩散深度Rd
Begin
1)A(N)←φ,Am(N)←φ,Rs←0,Rd←0,m←0,t←1;
2)Am(N)←u;
3) For each userj∈Am(N)
4)Fj←j的跟随着集合;
5) For each userk∈Fj
6) 根据式(11)计算转发率g(k);
7) If(g(k)≥θ)
8)At(N)←k;
9) End for
10) End for
11)A(N)←At(N);
12) If(At(N)==∅)
13) 根据式(12)获取Rd;
14)Rs←count(A(N));
15) Else
16)m←t;
17)t←t+1;
18) 重复步骤3;
End
4 实验结果与分析
4.1 数据集
本实验数据来自新浪微博开放的API接口(http://open.weibo.com/wiki/微博API)。从指定用户出发,获取其用户信息和发布的舆情。接着对他的跟随者做同样的爬虫行为。通过不断地重复以上步骤,最终获取到数据集。本实验获取从2015年4月1日至2015年4月30日的微博数据,统计出用户数量是7 000,微博总量是330 763,其中原创微博数量是110 157。
数据按时间分为两部分。一部分为训练集,它包括4月1日至4月15日所爬取的数据,微博数量为175 114,这些数据用于建立转发行为的预测模型。另一部分作为测试数据来测试模型的性能,微博数量为155 649,转发量为98 385,剩余的就是未转发微博的数量。
4.2 权重的取值实验
为了评估转发预测模型的影响,本文采用混淆矩阵展示预测结果。
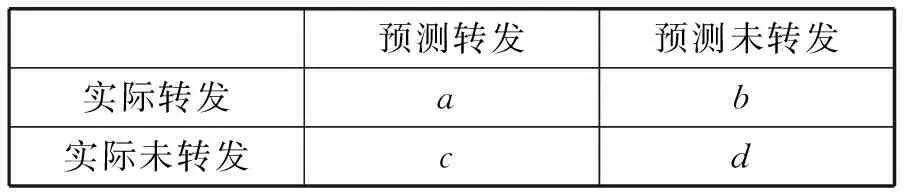
表1 混淆矩阵
其中a、b、c、d分别表示每种情况的百分比。我们采用准确率Acc来评估预测效果,作为选择阈值α的标准。
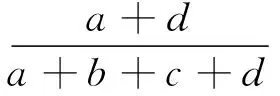
(13)
本文在计算接收用户转发舆情的概率时引入了权重α,通过研究α调节内容和信任机制所占的比重,以获得最优扩散预测效果。因此选择恰当的权重α对预测扩散准确率起着至关重要的作用。我们以权重α的取值为横坐标,纵坐标为准确率Acc。
从图4可以看出,当α=0.18时,准确率Acc最大,值为0.902,扩散预测效果最好。当α=0时,即只考虑内容,忽略用户间的信任关系,此时准确率Acc不是很高;随着α的逐步增加至0.18时,Acc值逐步增大;权重α继续逐步递增,并越来越趋向于1,准确率又逐步递减,在α=1时达到最小值0.51。准确率始终高于α=1和低于α=0.18时的Acc值。通过实验,我们认为权重α在舆情扩散中起着重要作用,只有选择恰当的α才能获取最佳扩散效果,准确率才能最高。在接下来的实验中,将权重α的值均设置为0.18进行实验。
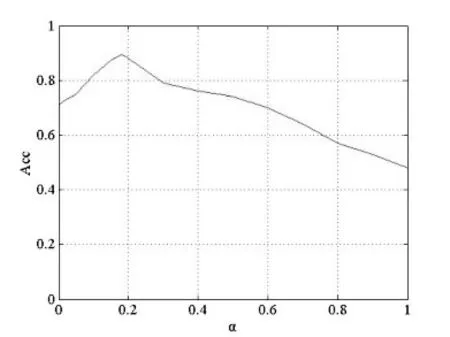
图4 准确率Acc随着权重α的变化
4.3 预测用户转发准确率
与上述评估标准一样,本节也采用Acc作为选择阈值θ的标准。且社会网络中最大入度取值500,即爬取的社会网络中用户所拥有的最大粉丝量为500个。
图5显示了准确率Acc和阈值θ之间的关系。随着θ值的增长,准确率Acc在θ取值0.001 6时到达最大值,值为90.2%。随后,随着θ的增长和转发率的归一化,准确率急剧下降。这个现象显示了存在一个合理的θ值使预测性能最优。因此,我们选择0.001 6作为阈值θ的值。实际的预测结果在表2中展示出来。
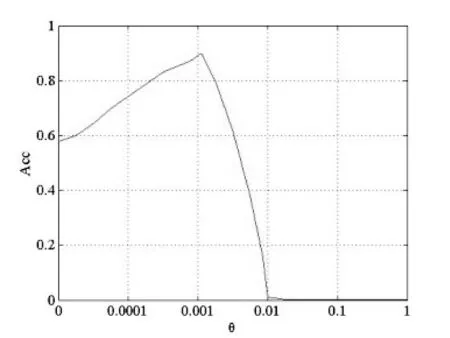
图5 准确率Acc随着阈值θ的变化
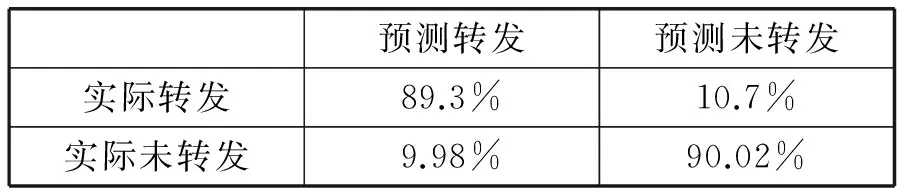
预测转发预测未转发实际转发89.3%10.7%实际未转发9.98%90.02%
从表2中,我们可以发现正式事件的预测准确率为89.67%。
4.4 CT-PODP算法与其他扩散算法的比较
根据文献[8,11],我们可以得知转发规模的分布极不平衡,具有长尾分布的特征,且其符合幂率分布。因此在预测舆情转发规模时,可以定义一个范围来评价预测结果。
假设实际转发规模是Np,预测规模是Nf。当精度满足式(14)时,则认为预测的转发规模是可接受的。
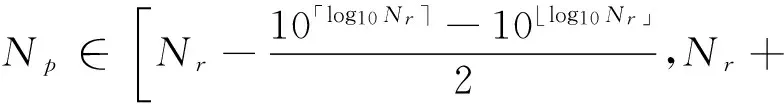
(14)
其中「·⎤表示向上取整,⎣·」表示向下取整。
首先,我们选择1 800名用户,他们的微博已经被转发且转发规模相当大。于是我们基于所提出的算法,对被选择用户的20 017条原创微博做出预测,计算了每个用户的预测准确率。图6显示了按式(13)得到的转发规模准确率分布。
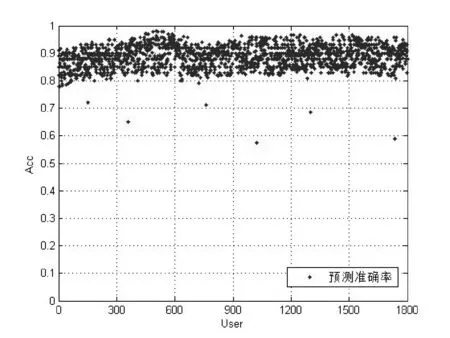
图6 转发规模预测的准确率
在图6中,蓝色点是各种用户的准确率分布,可见,对于这些用户的预测准确率绝大多数都在81%以上,算法对93%的用户有较好的预测,只有对一小部分用户的预测效果是不理想的,对这1 800个用户预测的准确率平均值是89.3%。我们根据式(14)评价转发规模的精度,上述预测精度是可接受的。
平均绝对偏差MAE(Mean Absolute Error)[7]是一种统计精度的度量方法,同时也是最常用的一种预测扩散效果的度量方法。因此采用MAE对这1 800个转发规模大的用户在转发规模和扩散深度方面和其他算法进行衡量。
(15)
n表示被选择用户总共发布的微博数量,且用户数量依次取值200、400、600、800、1 000、1 200、1 400、1 600、1 800。针对图7,式(15)中pi是第i条微博转发规模的预测值,ri是转发规模的实际值;针对图8,式(15)中pi是第i条微博扩散深度的预测值,ri是扩散深度的实际值。MAE越小,算法的效率越高,也就是说预测值越接近实际值。
本实验的目的是评价CT-PODP算法预测转发规模和扩散深度的准确性,将本文提出的基于内容和信任度的舆情扩散算法(CT-PODP)与基于用户行为、推文内容、跟随者影响力的预测算法(BCI)[7]和基于对数正态分布的转发预测算(Log-Normal)[8]进行了实验对比,实验结果如图7、图8所示。
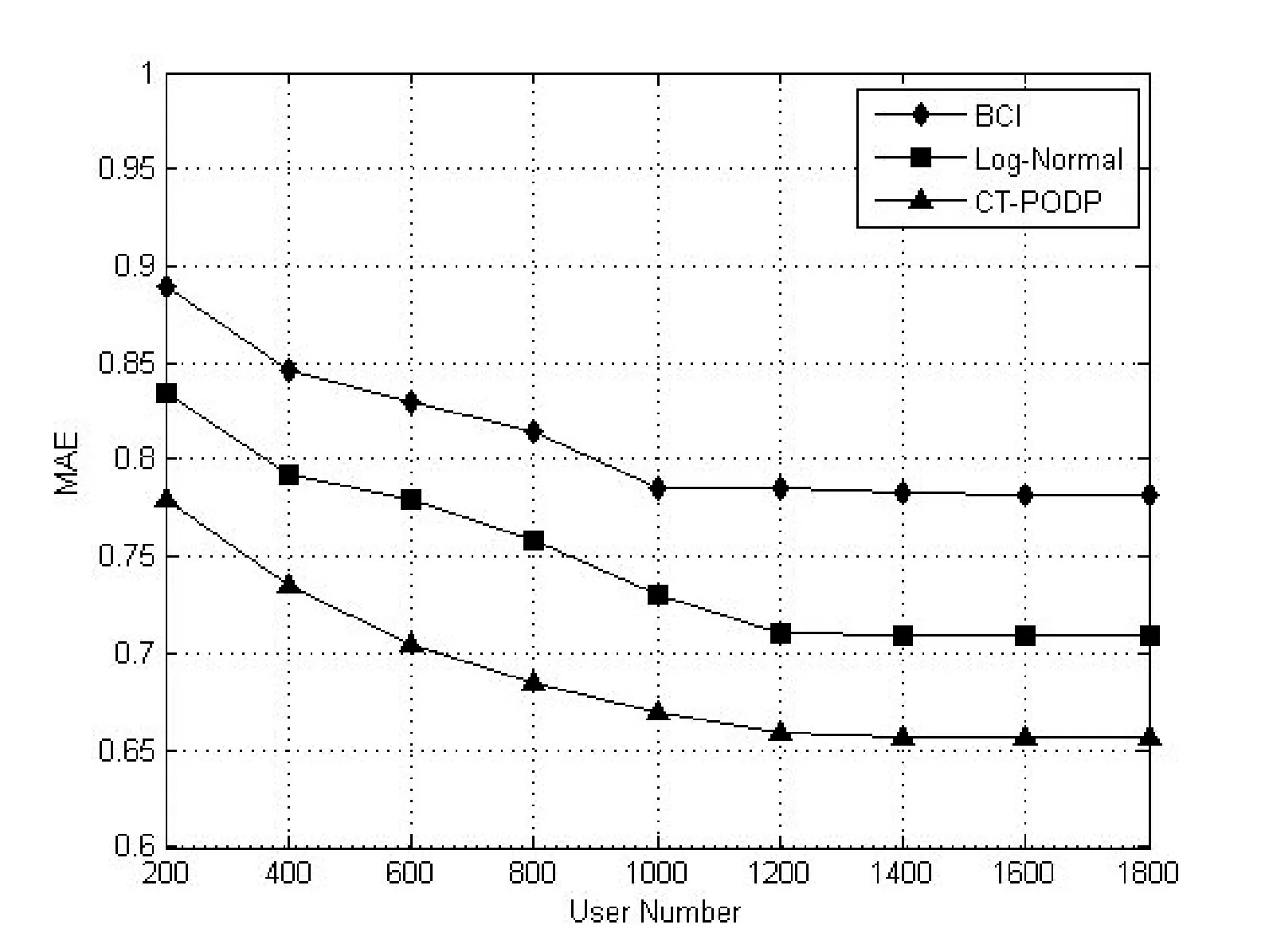
图7 CT-PODP算法与其他扩散算法在转发规模方面的比较
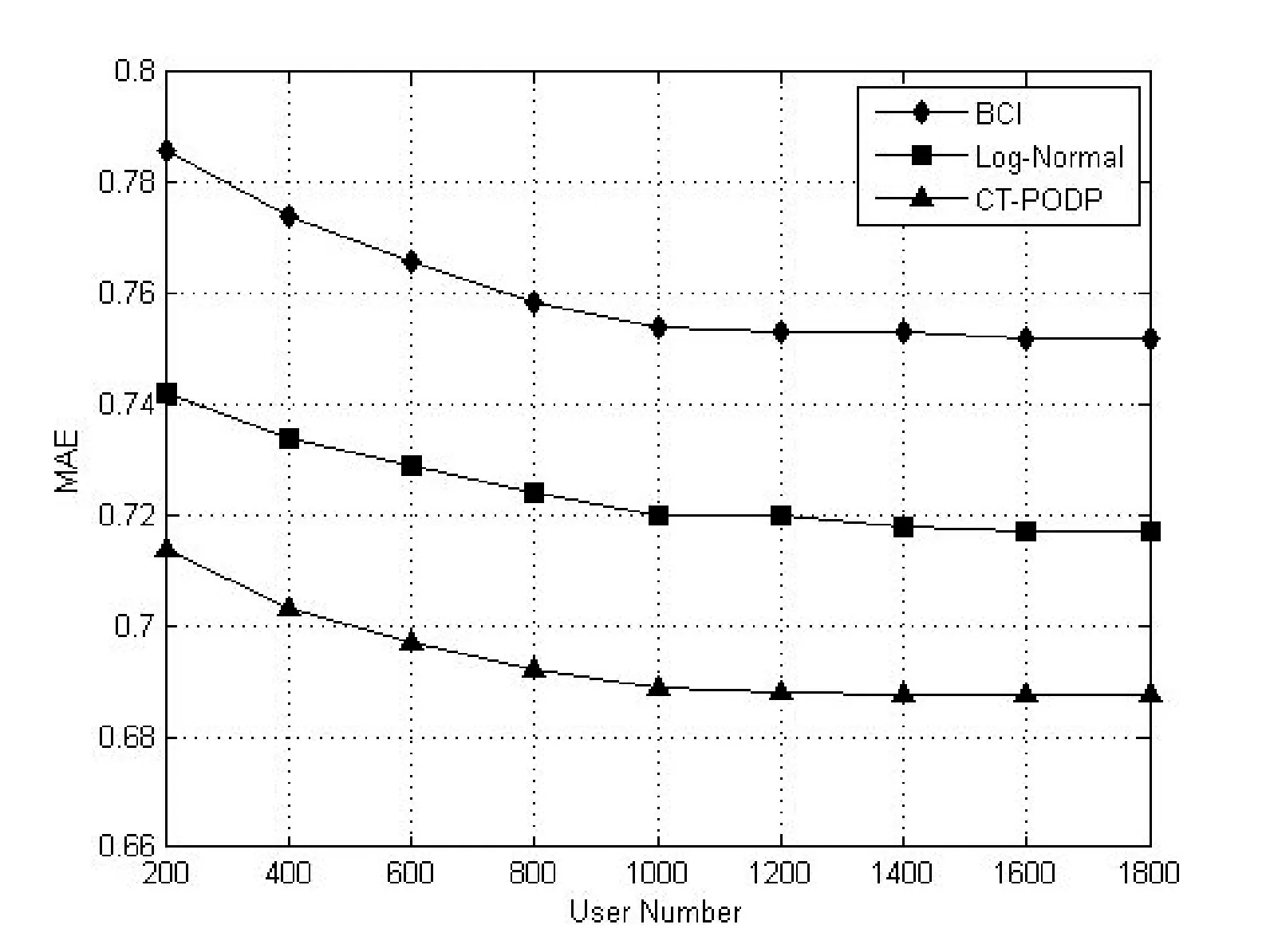
图8 CT-PODP算法与其他扩散算法在扩散深度方面的比较
从图7、图8可以看出,随着用户数量增加,在预测转发规模和扩散深度上的MAE值逐步减小,且更趋于稳定化,且CT-PODP的 MAE值都明显小于BCI、Log-Normal。由此可见,采用内容和信任度的扩散预测算法的预测效果都优于BCI、Log-Normal,说明了将用户间的信任度引入到舆情转发预测模型中,结合线性阈值模型研究转发率,可以改善转发规模和扩散深度的预测效果。因此,我们得到结论:同时使用内容和用户信任度的预测算法比单独使用内容的预测算法更有效果,即本文提出的基于内容和信任度的舆情扩散预测算法CT-PODP取得的效果最优。
5 结 语
随着互联网的迅速发展,现在已有的舆情扩散算法在其预测精度上已远远不能满足用户的需求,为此本文提出了一种基于内容和信任度的舆情扩散预测算法。从内容信息出发,结合用户间的信任机制来完成对转发行为的预测,运用线性阈值模型改善多个邻接传播用户已转发舆情的情形,并给出了CT-PODP算法的具体实现过程,该算法有效地提高了预测精度。
本文所提出的算法适用于中小型网络,对提高大型网络中舆情转发规模及扩散深度的准确率和效率将是下一步的研究重点。
[1] Yang Z,Guo J,Cai K,et al.Understanding retweeting behaviors in social networks[C]//Proceedings of the 19th ACM international conference on Information and knowledge management.ACM,2010:1633-1636.
[2] Xu Z,Yang Q.Analyzing user retweet behavior on twitter[C]//Proceedings of the 2012 International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2012).IEEE Computer Society,2012:46-50.
[3] Xu B,Zhou H,Ge Y.Quick tendency forecast on Internet public opinions[C]//Fuzzy Systems and Knowledge Discovery (FSKD),2010 Seventh International Conference on,2010:2493-2497.
[4] Jia H Y,Hao J W,Qiu C Z.A model for studying public opinion hotspot growth regulation in microblog network[C]//Management Science and Engineering (ICMSE),2013 International Conference on.IEEE,2013:173-178.
[5] Zhao J,Cheng J,Gao H.Public Opinion Propagation Model on Social Networks[C]//Computational Sciences and Optimization (CSO),2014 Seventh International Joint Conference on.IEEE,2014:325-328.
[6] 周东浩,韩文报,王勇军.基于节点和信息特征的社会网络信息传播模型[J].计算机研究与发展,2015,52(1):156-166.
[7] Zhao H,Liu G,Shi C,et al.A Retweet Number Prediction Model Based on Followers’ Retweet Intention and Influence[C]//IEEE International Conference on Data Mining Workshop.IEEE,2014:952-959.
[8] Ding H,Wu J.Predicting Retweet Scale Using Log-Normal Distribution[C]//IEEE International Conference on Multimedia Big Data.IEEE Computer Society,2015:56-63.
[9] Hong L,Dan O,Davison B D.Predicting popular messages in twitter[C]//Proceedings of the 20th international conference companion on World wide web.ACM,2011:57-58.
[10] Adali S,Escriva R,Goldberg M K,et al.Measuring behavioral trust in social networks[C]//Intelligence and Security Informatics (ISI),2010 IEEE International Conference on.IEEE,2010:150-152.
[11] Hou W,Huang Y,Zhang K.Research of micro-blog diffusion effect based on analysis of retweet behavior[C]//Cognitive Informatics & Cognitive Computing,2015 IEEE 14th International Conference on.IEEE,2015:255-261.
[12] Cha M,Haddadi H,Benevenuto F,et al.Measuring User Influence in Twitter:The Million Follower Fallacy[C]//International Conference on Weblogs and Social Media,Icwsm 2010,Washington,Dc,Usa,May.DBLP,2010.
[13] Gupta S,Duhan N,Bansal P,et al.Page ranking algorithms in online digital libraries:A survey[C]//Reliability,Infocom Technologies and Optimization (ICRITO)(Trends and Future Directions),2014 3rd International Conference on.IEEE,2014:1-6.
[14] 李栋,徐志明,李生,等.在线社会网络中信息扩散[J].计算机学报,2014,37(1):189-206.
PUBLICOPINIONDIFFUSIONPREDICTIONALGORITHMBASEDONCONTENTANDTRUSTDEGREE
Chen Zhenchun Liu Xuejun Li Bin
(CollegeofComputerScienceandTechnology,NanjingTechUniversity,Nanjing211816,Jiangsu,China)
To improve the public opinion’s retweet scale and diffusion depth of prediction accuracy in microblogging network, a public opinion diffusion prediction algorithm based on content and trust degree is proposed. First, according to the content about users and public opinions from microblogging networks, the characteristic index influencing public opinion diffusion is extracted. Meanwhile, the algorithm obtains the trust relationship between users. Thus, the model of predicting user’s retweeting behavior is established with only single neighbor who had retweeted the public opinion. Based on the above public opinion diffusion model and linear threshold model, a deep research on many neighbors who had retweeted the public opinion is done. Finally, the prediction about retweet scale and diffusion depth is completed. Meanwhile, the experimental results show that the algorithm improves the accuracy of predicting retweet scale and diffusion depth obviously.
Public opinion Content Trust degree Retweet scale Diffusion depth Prediction
TP301
A
10.3969/j.issn.1000-386x.2017.10.010
2016-10-29。国家自然科学基金项目(61203072);江苏省重点研发计划(社会发展)项目(BE2015697)。陈振春,硕士生,主研领域:舆情分析,数据挖掘。刘学军,教授。李斌,讲师。
猜你喜欢
环球时报(2018-01-23)2018-01-23
中国广播(2017年9期)2017-09-30
领导决策信息(2017年13期)2017-06-21
—— 瓮福集团PPA项目成为搅动市场的“鲶鱼”
当代贵州(2017年24期)2017-06-15
诗潮(2017年5期)2017-06-01
领导决策信息(2017年9期)2017-05-04
消费电子(2016年12期)2017-01-19
中南财经政法大学学报(2015年5期)2015-04-07
汽车维护与修理(2015年5期)2015-02-28
IT经理世界(2014年5期)2014-03-19
