
基于信息检索的需求跟踪方法综述
2017-11-01 17:14胡成海王帮超
计算机应用与软件 2017年10期
胡成海 彭 蓉 王帮超
(武汉大学计算机学院软件工程国家重点实验室 湖北 武汉 430072)
基于信息检索的需求跟踪方法综述
胡成海 彭 蓉 王帮超
(武汉大学计算机学院软件工程国家重点实验室 湖北 武汉 430072)
需求跟踪作为软件过程管理中的一个重要环节,在保障系统质量、应对需求变更方面发挥着重要作用。利用需求跟踪,软件工程师可以发现制品之间的依赖关系、评估需求覆盖率和计算需求变更的影响。随着软件项目的日益复杂和软件制品数量的增加,跟踪关系的自动恢复和维护日益受到业界关注。近年来,人们对于基于信息检索的需求跟踪自动化技术做了大量研究。针对基于信息检索的需求跟踪技术进行综述,从技术改进、支撑工具和度量指标三个方面进行了深入分析。在此基础上,对其发展趋势和有待深入的研究点进行了展望。
需求跟踪 信息检索 系统文献综述 研究趋势
0 引 言
在系统开发的整个生命周期中,遗失或没有实现的需求常常被遗忘、需求变更的影响常常被忽略,这些细微的疏漏很可能严重影响了整个软件开发的成败[1]。由于需求跟踪研究一方面致力于帮助软件工程师进行跟踪分析,确定是否所有的低层元素(如设计、源码等)都有与之对应的需求。另一方面,可以用于完整性分析和测试覆盖率评估,以明确是否所有的需求都被实现并进行了相应的测试[2],故而成为需求工程中的一个重要研究方向,受到学术界和工业界的广泛关注。
然而在许多实际系统的开发中,人们往往为了节约成本、加快开发进度,放弃建立需求跟踪链接。这一方面是由于相关人员对于需求跟踪重要性的认识不足,在人员紧张、资金不足等情形出现时,往往首先放弃与系统交付无直接关系的任务。其次,是由于现有的需求跟踪方法缺乏强有力的工具支持,往往需要耗费大量的人力、物力实施,而收益却难以在短时间内获得且难以度量。再次,由于需求变更难以避免,相关人员容易由于跟踪链接更新不及时而无法发挥作用。为此,如何改进需求跟踪技术、提高需求跟踪链接恢复的自动化程度、提供工具支持成为学术界和工业界共同追求的目标。
由于包括需求文档、设计文档、代码、测试用例在内的各种软件制品中存在大量文本信息,使用信息检索(IR)技术帮助需求工程师自动或半自动的恢复需求跟踪关系[3-4]是当前需求跟踪研究的一个主要分支。其一般过程通常包括三个阶段:1) 预处理阶段,将待建立跟踪关系的源制品和目标制品均看作文本制品,通过一定的文档预处理方法去除噪声信息,生成便于后续阶段处理的文档表示形式;2) 跟踪链接恢复阶段,利用各种文档相似度计算方法计算二者间的相似度,按照相似度的大小进行排序,根据设定的阈值筛选得到候选跟踪链接;3) 跟踪链接精化阶段,通过人工或半自动方法对候选跟踪链接进行精化,并最终由分析人员对产生的跟踪关系进行确认。
在需求跟踪中使用IR技术的优势在于,能够通过文本分析自动地恢复跟踪关系,对于解决传统需求跟踪活动所面临的人工工作量大、维护困难、容易出错等问题极有帮助。但是由于不同软件制品间往往存在遵循的规范不同、使用的术语不一致等问题,直接应用IR技术产生跟踪链接的效果并不十分理想。因此,近年来许多研究致力于通过改进IR技术(比如,引入同义词典、相关性反馈、聚类等)以提高跟踪链接生成和精化的质量。为了探究IR技术在需求跟踪中的应用现状与未来研究方向,我们对近十年有关基于IR的需求跟踪方法进行了分析和综述。本文的3个研究问题如下:
RQ1:目前,基于IR的需求跟踪方法中使用了哪些IR模型?为了得到更好的跟踪链接恢复效果,进行了哪些改进?
RQ2:现有哪些工具支持基于IR的需求跟踪?它们的自动化程度如何?
RQ3:基于IR的需求跟踪方法评估中常用的度量指标有哪些?它们的评估效力如何?
1 需求跟踪中的IR模型及其改进策略
1.1 IR基本模型
在基于IR的需求链接恢复中,往往将需求文档视作查询条件,通过IR技术自动建立起查询与文档之间的跟踪关系。以下介绍3种基本的IR模型。
向量空间模型(VSM)[5]将文档表示为文档空间向量,通过计算向量之间的相似性来度量文档之间的相似性。因此,在基于VSM的需求跟踪方法中,往往将源文档和目标文档中的特定单元(例如需求文档中的一条需求或代码中的类代码)表示为一个文档空间向量。从源文档中取出任意一个源文档空间向量作为查询向量,与目标文档对应的所有目标文档空间向量集合进行比较,选择相似度最大的向量作为最接近查询内容的(候选)跟踪目标,恢复(候选)跟踪关系。
隐性语义索引(LSI)模型通过分析文本之间隐含的 “语义相关性”来确定关联度。该方法改进了向量空间模型,不仅能够捕捉单个字词的语义,还能捕捉句子、段落以及整个文献的语义[6-7]。基于LSI的需求跟踪方法在检索中考虑了向量之间的“潜在”语义关系,而不仅仅关注原来字面上的字词描述。查询与目标文档之间的相似度是由它们所采用的全部标引词及其使用方式决定的,也即取决于它们中所包含的标引词的意义在多大程度上是一致的。
概率模型(PM)使用文档与查询相关的概率来计算文档与查询的相似度[8]。在基于PM的需求跟踪方法中,以查询中包含的每个检索单元(检索词)为线索,通过统计其在相关文档、不相关文档中出现和不出现的概率,计算出各个检索词的权重。最终根据每个文档与查询中匹配的检索词多少和权重计算出文档的相关性,并据此进行排序。
综上所述,虽然基于IR的需求跟踪方法能够通过信息检索方法自动对文本进行分析,建立候选跟踪链接,减轻了分析人员的工作量,但由于软件制品,特别是需求制品中存在大量自然语言描述,准确的词法、语法、语义及语用分析均面临着巨大的挑战,因此,生成的候选链接精度难以满足需要。如何对其进行改进成为研究者关注的焦点。
1.2 对IR模型的改进
同义词典技术、相关性反馈、聚类等是应用较多的几种策略。除此之外,各种依赖于术语表(如项目术语表、术语分类等)、语法分析、重构、图剪枝的方法也经常被采用。表1按照这些改进策略使用的信息检索模型(VSM、LSI、PM),策略应用的阶段,适用的软件制品(需求制品、设计制品、源码制品、测试制品)和改进策略的基本特征进行了总结。
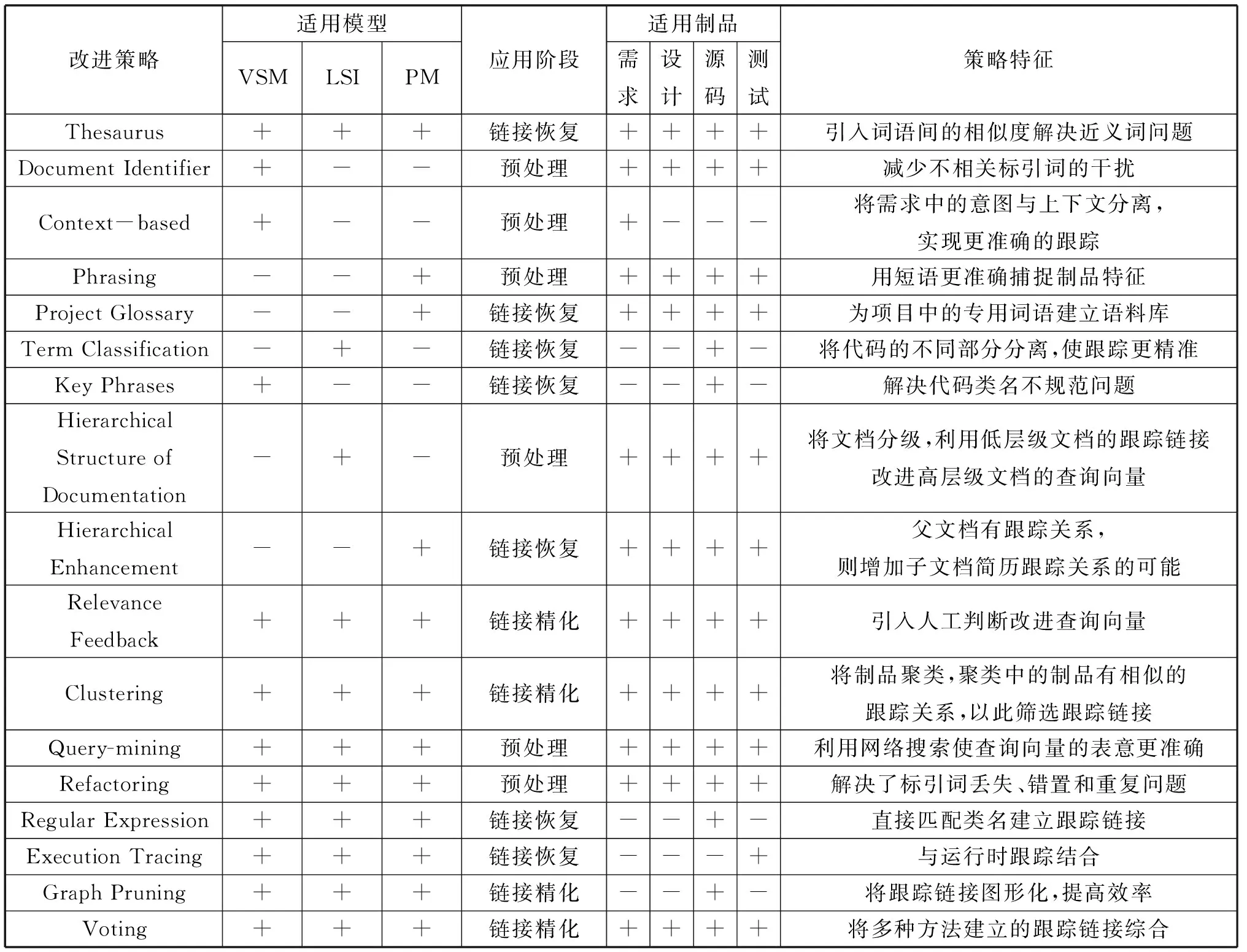
表1 IR模型改进策略汇总
(1) 利用制品文字信息的改进策略
更加充分地利用文档中的文字信息(同义词典、文档标识、短语分析等)直接改进相似度计算模型是提高基于IR的需求跟踪方法的一个主要着眼点。
同义词典是常用的一种利用文字信息的改进方法,在三种模型中均有使用。同义词典法通过在计算标引词权重和向量相似度时考虑单词或短语的同义词或近义词,能在一定程度上降低算法对于选词的敏感性,从而提高了算法的鲁棒性[9-13]。一个同义词典是三元组〈ki,kj,αij〉的集合,其中ki和kj是两个同义词项,αij是它们之间的相似度。词典中的词项可以是单个单词也可以是短语。经修正的相似度计算模型如下:
sim(d,q)=cos(d,q)=
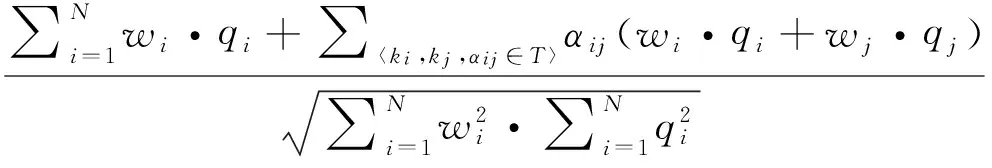
只在需求文档中出现的标引词不会与只在设计文档中出现的标引词产生关联,反之亦然。文献[14-15]在改进VSM时为标引词加上来源文档标识,在向量抽取时只抽取同时具备跟踪源文档和目标文档标识的标引词,从而减少不相关标引词的干扰,以更准确地计算有效标引词的权重,提高算法效率。例如,当恢复需求与设计文档之间的跟踪链接时,只具有“需求文档”或只具有“设计文档”的标引此就会被剔除。
文献[16]提出基于需求上下文的改进策略,通过在预处理阶段引入分析人员将用例需求分为需求意图和需求上下文两部分。并将二者均视作查询条件,利用VSM模型分别计算它们与目标文档之间的相似度,生成意图链接和上下文链接,并最终通过加权求和生成最终的候选跟踪链接集合,从而提高方法的精确率。二者结合方式如下:
sim(cq,iq,d)c=λ×simli(cq,d)n+(1-λ)×
simlj(iq,d)n
其中cq、iq分别为需求上下文和需求意图,文中研究发现λ为0.3时产生跟踪链接的效果较好。
文献[17-19]引入了短语分析技术改进PM模型,在计算文档间存在跟踪关系的概率时,表示文档的最小单位不再是单个单词,而是短语。相对于单个单词,短语在捕捉制品的特征时更为准确,故可以得到更高精确率的跟踪链接。文献[17-18]分析了使用的项目术语表来提高生成跟踪链接精确率的条件和能力。
有一些方法专门针对代码进行处理,文献[12,20]在需求到代码的跟踪关系构建中,将代码中的标引词(类名、注释和一般标识符)分类,计算相似度时,为不同类别的标引词分配不同的权重,以此提高LSI产生跟踪链接的精度。文献[18]从代码评论中抽取关键短语,使得VSM模型在代码类命名不规范或文档中没有明确提到类名时仍能恢复正确的跟踪链接。
(2) 利用制品结构信息的改进策略
以上方法均着重于对文档中文字信息的分析使用,文档的结构也可以用来改进信息检索模型。为了进一步提高LSI产生跟踪链接的精度,文献[12]在计算相似度时不仅引入了同义词典,还利用了文档的层次关系重新构造查询。该方法将所有文档分成两类:高层级的概念文档和低层级的实现文档。低层级的文档通常与源代码相关联,类名、方法名等多在其中出现。低层级文档又可以看作是高层级文档的进一步细化版本,例如,算法的实现、概念的解释和实现的细节等。所以低层级文档可以作为源代码与高层级文档跟踪链接恢复中的桥梁,利用低层级文档与源代码之间正确与错误的跟踪链接重新构造查询向量。修正后的查询向量如下:
文献[23]在改进PN模型时也使用了文档的层次信息。它所基于的一个假设是,如果两个软件制品已经建立了跟踪关系,那么它们的下层制品建立跟踪关系的可能性就大大提高了。可以利用这种层次信息通过增强正确链接的概率的方式修正概率模型的计算公式,过滤掉了错误链接,提高了跟踪链接的正确率。
聚类技术则是利用代码中类之间的继承关系或文档中的层次关系将代码或文档聚类,同一聚类中的代码或文档通常具有相同的跟踪关系。可以利用聚类对候选跟踪链接进行初步筛选,以此来提高跟踪链接精化阶段的效率[12,18,20-23]。
(3) 其他改进策略
近年来有诸多改进方法不再局限于对文字和结构信息的分析,而是利用人工的判断信息或与其他方法(正则表达式匹配、运行时跟踪等)产生的跟踪链接互相比对、结合,提高其跟踪链接恢复的精确率、召回率,这些改进策略也被证明是可行的。
相关性反馈是较早运用的一个技术。它的思想是在跟踪链接产生后,由分析人员判断每个跟踪链接正确与否,再根据这些正确和误报信息对查询向量中的标引词权重进行修正,产生新的查询向量,从而提高方法的精度[10,24-25]。新查询向量的计算方法如下:
新的查询向量是由原有查询向量加上用户反馈的正确的跟踪关系集合中的文档的平均向量,并减去用户反馈的错误的跟踪关系集合中的文档的平均向量而得出的。增加正确跟踪关系的向量提高了查全率,而减去错误跟踪关系的向量则提高了查准率。
此外,还有文献结合其他技术改进IR模型。文献[26]针对需求文档的文本歧义问题,提出用IR结合模型驱动工程(MDE)来实现更准确的跟踪恢复。文献[27]基于网络搜索引擎对原始查询进行修改使其表意更精准。文献[28-29]则使用重构方法解决了标引词丢失、错置和重复问题。文献[18]在构建代码到需求的跟踪关系时,使用正则表达式在需求文档中匹配类名产生跟踪链接,并与VSM产生的跟踪链接组合,提高候选跟踪链接的精确率。文献[30]在构建需求到代码的跟踪链接时,除使用IR技术产生跟踪链接之外,通过基于执行跟踪的关注点定位技术建立需求到代码的跟踪链接,并将两者加权合成更高精度的跟踪链接。文献[23,30]使用图剪枝方法精化跟踪链接。文献[31]则使用了一种投票机制,将多种方法产生的跟踪链接综合,提高跟踪链接精化阶段正确链接的识别率。
2 支持基于IR的需求跟踪工具
基于IR的需求跟踪具有自动化程度高的特点,因此已有一些相对较成熟的工具出现,其中最常用的有RETRO、FacTrace、TraceLab和TraCter等。我们将自动化工具的功能按照IR方法的执行过程分为文本预处理、跟踪链接恢复(自动或手动)、跟踪链接精化和跟踪链接质量评估四个阶段。其中候选链接精化中的功能包括跟踪链接聚类、投票机制、反馈机制、跟踪链接可视化和跟踪链接确认。在表2中我们对工具所支持的功能进行了标注。
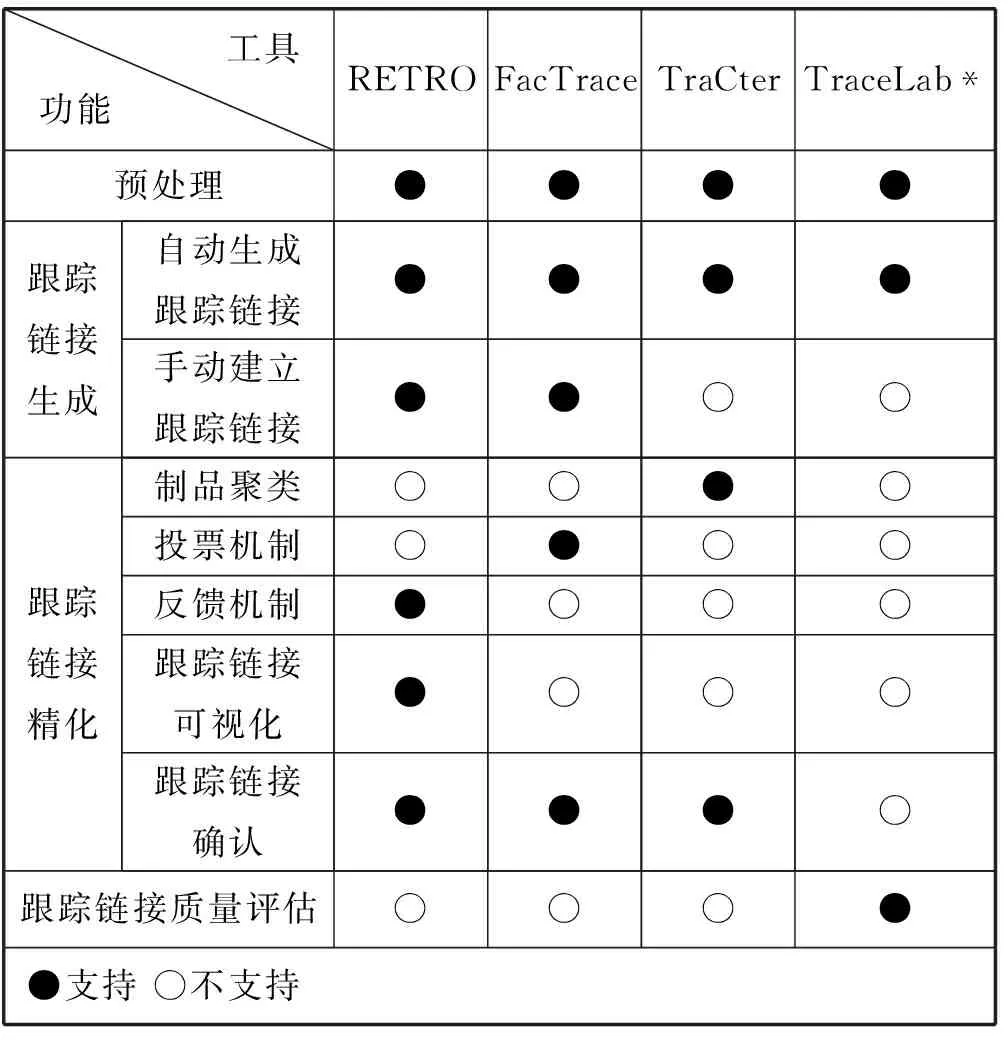
表2 基于IR的需求跟踪中使用的自动化工具
Hayes等开发了RETRO,用于处理非结构化文本制品之间的跟踪恢复[32]。RETRO使用IR技术和文本挖掘技术构建候选链接。目前,该工具已被用于需求文档、设计文档和缺陷报告之间的跟踪链接恢复,能够支持分析人员和维护人员验证与确认自动生成的跟踪链接。该工具包含多种IR方法和文本挖掘方法,并且有一个前端可供分析师在跟踪过程中使用。
Ali等开发了FacTrace,可以帮助软件工程师完成多种任务,如需求获取、需求分析、软件制品的跟踪及跟踪链接的验证等。FacTrace可以实现多种软件制品之间的跟踪,如需求,源码和CVS/SVN变更日志等。专家也可以使用FacTrace手动建立多种粒度的跟踪链接。FacTrace支持候选链接投票机制。五位专家为每一个候选链接投票,若一个链接被三位或三位以上的专家接受,则该链接就被FacTrace标记为有效链接。专家可以在任何时间修改投票意见[33]。
Keenan等开发了TraceLab[34]。该工具提供了一个功能完备的实验环境,研究者可以在该环境中利用已有的组件或自定义组件组织实验,可以使用公开的数据集从事研究,并可以使用该工具评估实验的结果。研究者可以自定义组件,然后集成到TraceLab中,以实现软件制品的导入,自然语言制品的预处理,候选跟踪链接的生成和候选跟踪链接质量评估评估等功能。
Mahmoud等开发的TraCter[35]是一个候选链接聚类工具,主要设计意图是通过设计一个友好的用户界面提高分析师的浏览效率。并在执行跟踪链接的精化时,减少分析师的认知负荷,提高分析师的分析效果和效率。文献[36]扩展了该工具,加入了LSI和ESA(Explicit Semantic Analysis,一种基于维基百科的语义相关性度量方法)组件,支持候选链接的自动生成,并提供了一个跟踪链接质量评估组件,可通过种度量指标评价跟踪链接质量。
3 度量指标
信息检索领域的两个最基本的度量值是精确率和召回率,用来评价结果的质量。其中精确率是指检索出的相关文档数与检索出的文档总数的比率,衡量的是检索系统的查准率;召回率是指检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率。在基于IR的需求跟踪技术中,这两个指标也是使用最多的,用于度量生成的跟踪链接的精确率和召回率。由于在追求高精确率和高召回率的过程中往往存在冲突,因此,综合考虑精确率和召回率的指标F-Measure往往也会同时被评估。F-Measure是Precision和Recall加权调和平均。考虑到精确率和召回率之间的权重取值,有F1-Measure和F2-Measure等不同的选择。
索得率(Browsability)[36]表征的是特定呈现方式能够减轻分析人员分析候选跟踪链接工作量的程度。对于一个使用顺序表来呈现结果的跟踪工具或方法来说,不仅要能检索到正确的链接,还要能够以恰当的方式呈现链接,以确保它们能被有效和高效的理解。如图1所示,两个跟踪工具,A和B,产生了两个结果,都有100%的召回率和50%的精确率。A工具生成的列表中误报链接排在真链接之前,B工具生成的列表中则相反。对于精确率和召回率而言,两个跟踪工具的效果相同。然而对于分析人员来说,B工具的效果明显优于A工具。此时,就可以通过若干独立索得率的指标来度量这种差异性。
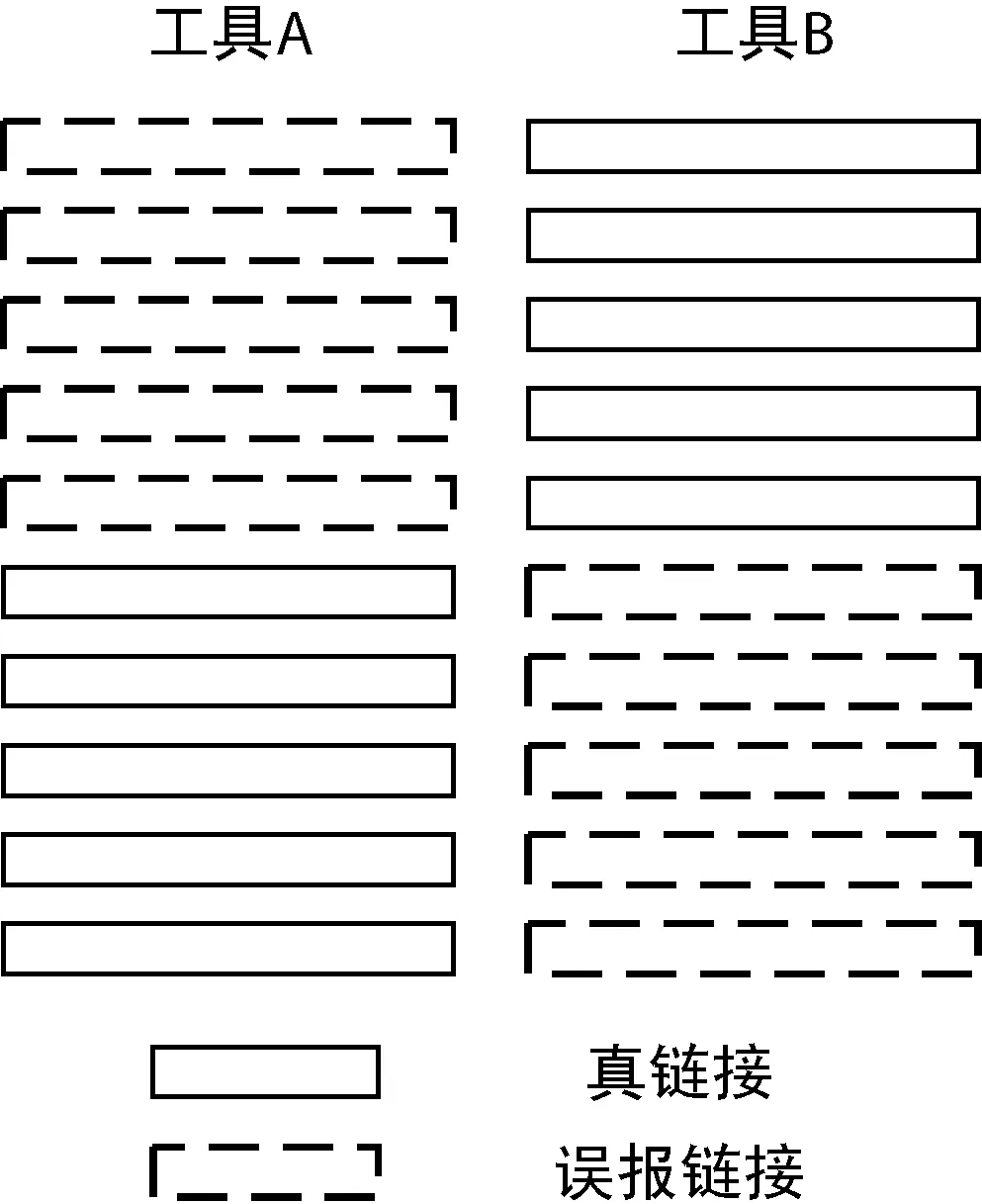
图1 索得率举例
假设h和d分别属于两个软件制品集合H和D,L={(d,h)|sim(d,h)}是候选链接集。则可以通过以下的度量指标来度量索得率:
MAP(Mean Average Precision):用于度量推荐链接列表平均精度的均值。
其中,|H|表示作为“查询”的制品集合的长度,mj表示的所有相关文档的个数。截取推荐链接列表的前项子列表,表示该子列表的精确度。MAP值越高说明方法或工具的效果越好。
DiffAR:用于度量一个顺序表中真链接和误报链接平均相似度间的差异。DiffAR值越高的列表真链接和误报链接之间的区分度越大。
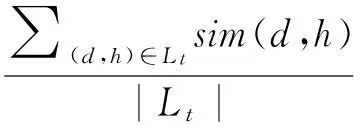
其中,Lt、Lf分别表示列表中的真链接、误报链接集合,sim(d,h)和sim(d′,h′)分别表示任一真假链接制品间的相似度,|Lt|、|Lf|分别表示真链接、误报链接集合的长度。
Lag:描述的是候选链接列表中排在真链接之前的误报链接的平均数。
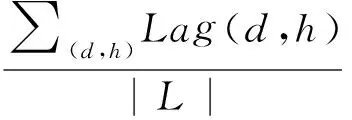
其中,表示候选链接列表中排在真链接前的误报链接的数量,|L|表示候选链接列表的长度。
MAP、DiffAR和Lag在评估推荐链接列表时能够反映链接推荐顺序所带来的差异,对于评估候选链接确认时所需的人工筛选工作量有着重要意义,值得广泛采纳。
此外,Sundaram等[10]在研究中使用了选择率(Selectivity)作为评估指标。选择率度量的是自动化方法相对于人工能够节省工作量的程度。假设软件制品集合H和D中分别有m和n个制品,则最多会产生m×n个跟踪链接。选择率定义为:
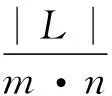
Sundaram等[36-37]将这些指标分为基本度量(Primary Measures)和辅助度量(Secondary measures)(如表3所示)。其中,辅助度量指标可以度量候选跟踪链接列表的内部结构。
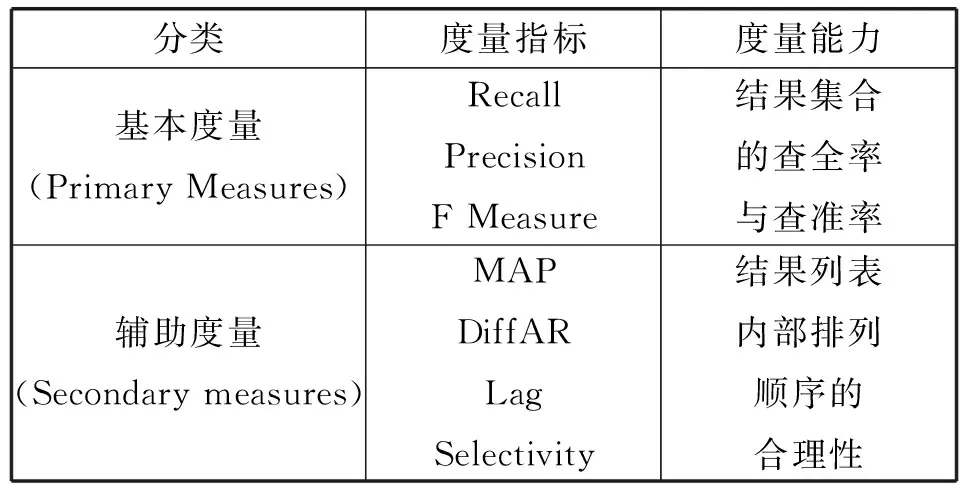
表3 度量指标分类
目前,度量一个工具或方法的效果时最常用的度量指标是精确率和召回率,即度量其查准率和查全率。然而在分析人员分析候选链接时,候选链接列表内部的排列方式对分析人员的效率也会产生影响。好的工具或方法能够通过合理呈现候选链接,以提高分析人员的效率。此时则需要使用上文提到的辅助度量指标。
从我们的研究中可以看出辅助度量指标较少被使用,这也从一个侧面说明目前对基于IR的需求跟踪技术的改进多集中理论层面,即关注于精确率、召回率的提高,而对于其实际使用效能的关注较少,即对于其结果多大程度能够减少分析人员工作量的研究较少,说明本项技术离实用还存在一定距离。另一方面索得率的提高也对跟踪链接的生成提出了更高的要求,即不仅要区分一个候选链接是否正确,还要能够准确地估算出其正确的可能性,因此,这也将成为该类研究的一个重要的研究方向。
4 效度分析
本文从结构效度和结论效度两个方面分析本文的效度。
(1) 结构效度
本研究中结构效度面临的问题涉及到能否找到与本研究相关的所有文献。本文采用了以下方法规避这种威胁:① 通过构造测试集对使用的搜索字符串的筛选能力进行验证,并且检索文献时我们使用了5个主要的文献检索数据库(EI、Elsevier ScienceDirect、IEEE、Springer和ACM)。② 通过滚雪球的方式发现可能遗漏的文献,进一步提升了文献的覆盖率。
(2) 结论效度
本研究中的结论效度主要关注其他研究者基于选择的文献能否得出相同的结论。本文采取的方法则是由两名研究者同步进行数据抽取工作,之后对两人抽取的数据和形成的结论进行比对,对于不一致的数据由两位研究者同第三位研究者共同修正。在研究中我们用量化数据呈现了许多分析结果,其他研究者可以通过本研究中公开的文献验证本文结论。
5 结 语
在需求跟踪中应用IR技术可以自动或半自动地恢复跟踪链接,减少跟踪链接建立和维护人员的工作量,因而得到学术界和工业界的广泛关注。针对链接生成时精确度不高、链接精化时人工工作量大等问题,近年来各种基于IR的需求跟踪方法采取了多种策略进行改进,具体如图2所示。
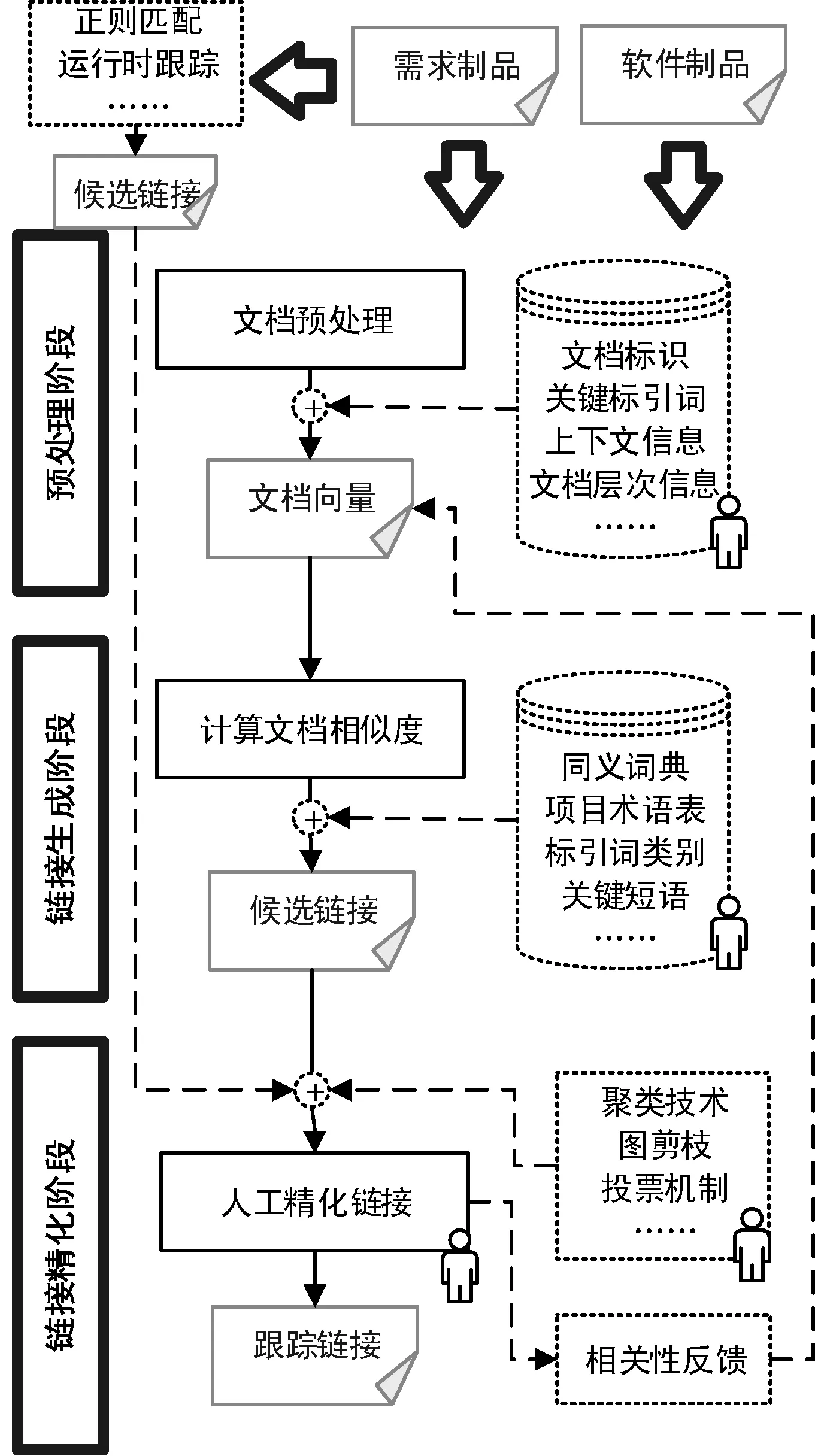
图2 改进的基于IR的需求跟踪过程
在预处理阶段,在构造文档表示时,除了采用的分词、取词根、词性标注等常用手段外,还常常使用文档标识、关键标引词和上下文环境分析等手段,使从文本文档中抽取的特征更具有代表性,提高检索的效能,降低算法复杂度。
在链接恢复阶段,除了根据制品特征选择最佳IR模型外,当前研究还注重利用同义词典、项目词汇表和标引词分类等技术,提高链接恢复的精确率与召回率。
在链接精化阶段,常采用的增强策略是相关性反馈和聚类等。因为这些技术是在候选跟踪链接列表的基础上所做的改进,所以针对不同的IR模型、不同的软件制品都可以使用。
还有另一类改进方案着重利用非IR技术生成跟踪链接,然后与使用IR技术产生的跟踪链接相比对,通过投票或加权的方式产生最终跟踪链接,以提高其精确率。
在上述阶段中,为了获得更好的效果,常常采用轻量级的人工辅助。如在预处理阶段,利用分析人员标示出标引词的来源文档[14]。在链接恢复阶段,利用分析人员区分需求文档的需求意图和需求上下文[16]。在链接精化阶段,利用分析人员分辨出真假跟踪链接,以提高模型的分辨能力[24]。
通常,文献中提出的改进方法会在不同阶段使用上述的多种增强策略,以取得更好的链接恢复效果。
虽然近年来基于IR的需求跟踪技术研究取得了长足的进步,但仍然在以下方面存在不足:
(1) 往往忽略了跟踪关系的性质。根据性质不同,可以将跟踪关系分为精化关系、目标-方法关系或者需求-测试关系等。跟踪关系性质不同的软件制品间术语的关系也存在较大差异。缺乏针对跟踪关系性质的设计,将影响基于IR的需求跟踪技术的实施效果。
(2) 往往忽略了不同类型的制品使用的语言可能不同。例如,高层需求中使用市场行销术语,而设计文档中使用技术术语。在这种情况下,仅仅依靠语义相似度并不能产生令人满意的结果。
(3) 对已有的跟踪链接利用不足。一般而言,基于IR的需求跟踪技术往往将每一个新的制品当作一个全新的“查询”,利用IR技术生成新的候选链接,从零开始构建跟踪关系。如果能够对已有跟踪链接进行有效利用,一定能够提升方法的效能。
综上所述,基于IR的需求跟踪方法可以从以下方面开展研究:
(1) 新的IR技术的应用。目前需求跟踪恢复所使用的主流IR模型仍然是VSM、LSI和PM等经典模型,其链接恢复的效果往往受到模型本身检索能力的限制。近年来,IR技术取得了长足进展,产生了诸如专门针对短文本检索的LDA模型[38],能处理更多更复杂的特征向量的基于排序学习的IR模型[39]等。如果能够针对需求跟踪链接恢复涉及的软件制品的特征,选择最佳检索模型,有望取得更好的效果。例如,虽然需求文档往往描述相对完整,但图形类制品、代码注释类制品等往往具备典型的短文本特征,如何利用适合于短文本分析等的各类新型IR检索模型提高跟踪链接恢复的效能值得研究。
(2) IR技术与其他技术的结合。需求跟踪链接往往涉及到不同软件开发阶段产生的软件制品。不同类别的软件制品由于涉众知识背景不同、制品描述重点不同,往往会出现使用不同层次、不同粒度的术语描述同一对象,造成生成的跟踪链接效果不佳的问题。本体技术、机器学习技术、自然语言处理技术都能为基于IR的需求跟踪方法应对这类挑战提供有力支撑。
(3) 注重发挥规范的作用。由于各类软件制品在产生过程中势必要遵循某种规范,如国际标准、国家标准、行业标准、公司规章等。这些规范从文档结构到命名规则都有相应的限定。在恢复跟踪链接时合理利用这些规则配合IR模型,将能起到事半功倍的作用。
(4) 注重建立完善的评价体系并发挥评估指标的指导性作用。基于IR的需求跟踪技术优劣很大程度是依据各种度量指标进行定性、定量评估而得出的。目前,对基于IR的需求跟踪技术的改进多关注于精确率、召回率的提高,对于其对于分析人员使用的便利程度等方面的度量指标还很少。而健全的评价体系不仅能够评估当前方法的优劣,而且还能为方法的改进指出方向。因此,进一步从实用角度出发,从借鉴信息检索等相关领域评价指标和发展适应需求跟踪领域自身需要的评价指标两个方面同时开展研究,将大大促进基于IR的需求跟踪技术的发展。
(5) 提高工具的灵活性、集成度和自动化程度。基于IR的需求跟踪技术的自动化程度较高,具有广阔的应用前景,但只有强大的支撑工具支持,才能真正受到工业界的青睐。由于需求跟踪涉及到的制品种类繁多、样式各异、遵循的规范各有不同,目前的需求跟踪工具难以满足不同企业的实际需要。因此,提供具有开放架构的需求跟踪工具,允许不同的第三方开发人员将其需求跟踪技术集成于其中,并提供统一的质量评估,才能满足工业界的实际需要。因此,研发一个综合能够支持第三方扩展、支持多种软件制品分析、支持多种分析模型和多种改进策略的高效自动化需求跟踪恢复平台,将会具有重要的实用价值。
[1] Jarke M.Requirements Tracing[J].Communications of the Acm,1998,41(12):32-36.
[2] Hayes J H,Dekhtyar A,Sundaram S K.Improving after-the-fact tracing and mapping:Supporting software quality predictions[J].Software,IEEE,2005,22(6):30-37.
[3] Antoniol G,Caprile B,Potrich A,et al.Design-code traceability for object-oriented systems[J].Annals of Software Engineering,2000,9(1):35-58.
[4] Antoniol G,Canfora G,Casazza G,et al.Recovering Traceability Links between Code and Documentation[J].IEEE Transactions on Software Engineering,2002,28(10):970-983.
[5] Kitchenham B,Charters S.Guidelines for performing Systematic Literature Reviews in software engineering[J].Engineering,2007,45(4):1051-1052.
[6] Burstein R,Yarnitsky D,Gooraryeh I,et al.Modern Information Retrieval[M].Addison Wesley,2011:26-28.
[7] Deerwester S.Indexing by latent semantic analysis[J].Journal of the Association for Information Science and Technology,1990,41(6):391-407.
[8] Landauer T K,Foltz P W,Laham D.An Introduction to Latent Semantic Analysis[J].Discourse Processes,1998,25(2):259-284.
[9] Di F,Zhang M.An Improving Approach for Recovering Requirements-to-Design Traceability Links[C]//Computational Intelligence and Software Engineering,2009.International Conference on.IEEE,2009:1-6.
[10] Sundaram S K,Hayes J H,Dekhtyar A.Baselines in requirements tracing[J].Acm Sigsoft Software Engineering Notes,2005,30(4):1-6.
[11] Kong W K,Hayes J H.Proximity-based traceability:an empirical validation using ranked retrieval and set-based measures[C]//Empirical Requirements Engineering (EmpiRE),2011 First International Workshop on.IEEE,2011:45-52.
[12] Wang X,Lai G,Liu C.Recovering Relationships between Documentation and Source Code based on the Characteristics of Software Engineering[J].Electronic Notes in Theoretical Computer Science,2009,243:121-137.
[13] Leuser J,Ott D.Tackling semi-automatic trace recovery for large specifications[M]//Requirements engineering: foundation for software quality.Springer Berlin Heidelberg,2010:203-217.
[14] Udagawa Y.An Augmented Vector Space Information Retrieval for Recovering Requirements Traceability[C]//Data Mining Workshops (ICDMW),2011 IEEE 11th International Conference on,Vancouver,BC,Canada,December 11,2011.2011:771-778.
[15] Udagawa Y.Enhancing information retrieval to automatically trace requirements and design artifacts[C]//Proceedings of the 13th International Conference on Information Integration and Web-based Applications and Services.ACM,2011:292-295.
[16] Zhou J,Lu Y,Lundqvist K.A Context-based Information Retrieval Technique for Recovering Use-Case-to-Source-Code Trace Links in Embedded Software Systems[C]//Software Engineering and Advanced Applications (SEAA),2013 39th EUROMICRO Conference on.IEEE,2013:252-259.
[17] Zou X,Settimi R,Cleland-Huang J.Evaluating the Use of Project Glossaries in Automated Trace Retrieval[C]//Software Engineering Research and Practice,2008:157-163.
[18] Chen X,Grundy J.Improving automated documentation to code traceability by combining retrieval techniques[C]//Proceedings of the 2011 26th IEEE/ACM International Conference on Automated Software Engineering.IEEE Computer Society,2011:223-232.
[19] Zou X,Settimi R,Cleland-Huang J.Phrasing in dynamic requirements traceretrieva[C]//Computer Software and Applications Conference,2006.COMPSAC’06.30th Annual International.IEEE,2006,1:265-272.
[20] Shao J,Wu W,Geng P.An Improved Approach to the Recovery of Traceability Links between Requirement Documents and Source Codes Based on Latent Semantic Indexing[M]//Computational Science and Its Applications-ICCSA 2013.Springer Berlin Heidelberg,2013:547-557.
[21] Niu N,Mahmoud A.Enhancing candidate link generation for requirements tracing:the cluster hypothesis revisited[C]//Requirements Engineering Conference (RE),2012 20th IEEE International.IEEE,2012:81-90.
[22] Rempel P,Mader P,Kuschke T.Towards feature-aware retrieval of refinement traces[C]//Traceability in Emerging Forms of Software Engineering (TEFSE),2013 International Workshop on.IEEE,2013:100-104.
[23] Cleland-Huang J,Settimi R,Duan C,et al.Utilizing supporting evidence to improve dynamic requirements traceability[C]//Requirements Engineering,2005.Proceedings.13th IEEE International Conference on.IEEE,2005:135-144.
[24] Kong L,Li J,Li Y,et al.A Requirement Traceability Refinement Method Based on Relevance Feedback[C]//Software Engineering and Knowledge Engineering,2009:37-42.
[25] Yadla S,Hayes J H,Dekhtyar A.Tracing requirements to defect reports: an application of information retrieval techniques[J].Innovations in Systems and Software Engineering,2005,1(2):116-124.
[26] Sannier N,Baudry B.Toward multilevel textual requirements traceability using model-driven engineering and information retrieval[C]//Model-Driven Requirements Engineering Workshop (MoDRE),2012 IEEE.IEEE,2012:29-38.
[27] Gibiec M,Czauderna A,Cleland-Huang J.Towards mining replacement queries for hard-to-retrieve traces[C]//Proceedings of the IEEE/ACM international conference on Automated software engineering.ACM,2010:245-254.
[28] Mahmoud A,Niu N.Supporting requirements to code traceability through refactoring[J].Requirements Engineering,2014,19(3):309-329.
[29] Mahmoud A,Niu N.Supporting requirements traceability through refactoring[C]//Requirements Engineering Conference (RE),2013 21st IEEE International.IEEE,2013:32-41.
[30] Eaddy M,Aho A V,Antoniol G,et al.Cerberus:Tracing requirements to source code using information retrieval,dynamic analysis,and program analysis[C]//Program Comprehension,2008.ICPC 2008.The 16th IEEE International Conference on.IEEE,2008:53-62.
[31] Ali N,Guéhéneuc Y G,Antoniol G.Requirements traceability for object oriented systems by partitioning source code[C]//Reverse Engineering (WCRE),2011 18th Working Conference on.IEEE,2011:45-54.
[32] Hayes J H,Dekhtyar A,Sundaram S K,et al.REquirementsTRacing On target (RETRO):Improving software maintenance through traceability recovery[J].Innovations in Systems & Software Engineering,2007,3(3):193-202.
[33] Ali N,Guéhéneuc Y G,Antoniol G.Trust-based requirements traceability[C]//Program Comprehension (ICPC),2011 IEEE 19th International Conference on.IEEE,2011:111-120.
[34] Keenan E,Czauderna A,Leach G,et al.TraceLab: An experimental workbench for equipping researchers to innovate,synthesize,and comparatively evaluate traceability solutions[C]//International Conference on Software Engineering.IEEE,2012:1375-1378.
[35] Mahmoud A,Niu N.TraCter:A tool for candidate traceability link clustering[C]//Proceedings of the 2011 IEEE 19th International Requirements Engineering Conference.IEEE Computer Society,2011:335-336.
[36] Mahmoud A,Niu N,Xu S.A semantic relatedness approach for traceability link recovery[C]//Program Comprehension (ICPC),2012 IEEE 20th International Conference on.IEEE,2012:183-192.
[37] Sundaram S K,Hayes J H,Dekhtyar A,et al.Assessing traceability of software engineering artifacts[J].Requirements Engineering,2010,15(3):313-335.
[38] Lu Y,Mei Q,Zhai C X.Investigating task performance of probabilistic topic models:an empirical study of PLSA and LDA[J].Information Retrieval,2011,14(2):178-203.
[39] Li H.Learning to Rank for Information Retrieval and Natural Language Processing[J].Synthesis Lectures on Human Language Technologies,2011,4(1):113.
ASURVEYOFREQUIREMENTTRACKINGMETHODBASEDONINFORMATIONRETRIEVAL
Hu Chenghai Peng Rong Wang Bangchao
(StateKeyLaboratoryofSoftwareEngineering,SchoolofComputer,WuhanUniversity,Wuhan430072,Hubei,China)
Requirement tracking, as an important part of software process management, plays an important role in ensuring system quality and responding to requirement change. Using requirement tracking, software engineers can find dependencies among products, assessing demand coverage, and calculating the impact of changes in requirements. With the increasing complexity of software projects and the increase in the number of software products, the automatic recovery and maintenance of tracking relations has attracted more and more attention. In recent years, people have done a lot of research on requirement tracking automation technology based on information retrieval. We summarize the requirement tracking technology based on information retrieval, and carry out in-depth analysis from three aspects: technical improvement, support tools and metrics. On this basis, we look forward to its development trend and further research.
Requirement tracking Information retrieval Systematic literature review Research trend
TP311
A
10.3969/j.issn.1000-386x.2017.10.004
2016-12-02。国家自然科学基金项目(61170026)。胡成海,硕士生,主研领域:需求工程,软件工程。彭蓉,教授。王帮超,博士生。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
客联(2022年3期)2022-05-31
食品安全导刊(2021年21期)2021-08-30
中国新闻周刊(2021年26期)2021-07-27
五邑大学学报(自然科学版)(2019年3期)2019-09-06
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
中成药(2017年6期)2017-06-13
电脑爱好者(2017年7期)2017-05-06
