
基于财务公司视角的产业链金融信用风险度量问题研究
——以中国重汽产业链为样本的实证分析
2017-10-25 04:28王安水张晓雯
金融发展研究 2017年8期
于 嘉 王安水 张晓雯 宋 蕾
(1.中国电力财务有限公司山东分公司,山东 济南 250001;2.长城新盛信托责任有限公司,北京 100045;3.中国农业银行山东省分行,山东 济南 250002;4.中国电力财务有限公司,北京 100005)
基于财务公司视角的产业链金融信用风险度量问题研究
——以中国重汽产业链为样本的实证分析
于 嘉1王安水2张晓雯3宋 蕾4
(1.中国电力财务有限公司山东分公司,山东 济南 250001;2.长城新盛信托责任有限公司,北京 100045;3.中国农业银行山东省分行,山东 济南 250002;4.中国电力财务有限公司,北京 100005)
本文围绕产业链企业信用风险度量问题展开研究,以中国重汽产业链中的上市公司为样本,在利用样本公司资本市场公开数据基础上,采用KMV模型预估所选公司违约概率,并进一步借助时间序列分析方法,探讨产业链条上样本公司违约概率的变动关系。结果表明,产业链条上企业的违约概率并不一定随国家宏观经济走弱而上升;相比链条其他企业,核心企业违约概率未必是最低的;核心企业违约概率的变化与链条其他企业违约概率的变化并不存在因果关系,非核心企业间违约概率变化却存在传导可能性。从近三年时间的计算数据来看,产业链上企业的违约概率之间并不存在稳定的均衡关系。
产业链;违约概率;KMV模型
一、引言
长期以来,财务公司在具体业务开发上多以银行作为参考模板。依据银行开展产业链金融服务的市场经验,产业链金融服务遇到的风险问题并不比传统金融服务少。例如,现在的产业链金融主要基于应收账款融资、存货融资和预付款融资三种基本类型,并组合衍生出其他产品,针对不同的产品需要设计不同的授信流程,流程的复杂性增加了操作风险概率。又如,法律制度体系自身存在的空白,不同区域法律执行效率的差异,以及相关合同中涉及的与货物监管、资产处置有关的协议、声明书、通知书等法律形式的多样性,也提高了法律风险管理的难度。而与这些风险类型相比,产业链金融作为一项融资业务,最关注的依然是信用风险。
银行在产业链金融业务领域的探索,一方面为财务公司提供了良好的借鉴,另一方面对财务公司信用风险管理水平提出了更高的要求。但从实际接触来看,财务公司在信用风险管理方面缺乏严格的量化分析。受政策限制,除同业拆借、对外投资、买方信贷等少数业务外,财务公司主要服务对象局限为集团内部成员。集团内部成员与财务公司间信贷资金往来实则暗含了集团对其风险的信用背书。在这样的机制下,财务公司容易缺乏提升风险管理技术的积极性。
相比之下,20世纪70年代以来,国外金融机构风险管理逐步向风险量化管理模式转变,对信用风险的评估和测度均已采用现代违约概率测度模型。而国内财务公司缺乏合理的计量模型,在具体衡量和监测风险时使用的方法仍局限于定性分析和简单的财务比率分析等一些传统方法。其中,定性分析依赖于分析者的直觉经验,由于分析人员的学识、能力不同,必然会导致误差的存在;财务比率分析则受制于数据获取的时效性,很难真实反映企业当前的财务状况。在产业链金融业务背景下,财务公司也会不可避免地接触集团外部企业。对外部企业经济策略选择和管理决策等信息掌握上的劣势,将使财务公司对其授信后,承担相对于内部成员单位更高的信用风险。财务公司如若无法提升风险识别和衡量的准确性,便难以掌握贷款过程蕴含的风险。
目前,国内已有不少学者开始利用定量模型研究企业信用风险。张玲(2004)利用Z值模型反映上市公司风险及其变化情况,研究结果显示,上市公司最初两年资信品质较为稳定,随后将会大幅度下降;夏立明(2013)认为,如果只是在孤立的时间点上对产业链中小企业进行信用风险评价,容易导致评价结果失真。为此,作者在模型中融入了时间的变化,选用微粒群算法和模糊综合评价方法对供应链中小企业进行风险评价。李倩(2014)则通过实证研究发现,结合主成分分析与最小二乘原理的风险模型更适合产业链信用评估。对已有文献梳理后不难发现,面向产业链,利用资本市场公开数据度量链条企业信用风险的研究寥寥无几。虽有学者利用计量模型对样本公司信用风险进行了测度,但并未随时间的发展计算、跟踪信用风险的变化趋势,无法与宏观经济形势相对照,不能反映产业链自身信用风险变化特点,更未对产业链企业信用风险变化之间的联系进行探讨。鉴于此,本文将立足已有研究成果,探讨适合现阶段财务公司评估产业链金融违约风险的模型,并给出实证分析。
二、模型的选取与建立
(一)对模型选择的思考
无论理论界还是实务界,都对量化信用风险积累了丰富的经验。借鉴以往研究成果,文章结合风险评估过程,将主要方法、模型总结如下:
由图1可知,量化分析贯穿信用风险管理的各个环节。国外对于信用风险测度的研究起于严格假设,后逐渐放松,经历了从定性到定量、从单变量到多变量、从单笔授信到贷款组合的过程,评估方法上不断推陈出新,信用风险判别能力上也越来越强。《巴塞尔协议Ⅱ》强调并鼓励商业银行尽可能利用包括计量模型在内的量化分析技术进行风险管理。财务公司与商业银行在服务类型上有重合之处,但由于初始定位不同,在业务开展的广度、深度上有所差别,因此适合商业银行信用风险管理的工具未必适合财务公司,更不是所有的计量模型都适合产业链金融风险度量。比如Credit Risk+模型,该模型假设在给定期间内,每笔贷款违约概率服从泊松分布。由概率论可知,此时每笔贷款只有违约和不违约两种状态,且每笔贷款违约风险独立于其他贷款,但同一链条的企业往往有稳定的合作关系,相关性较强,这一点与模型前提假设存在冲突;再比如,Credit Metrics模型依据每年评级历史数据估计违约概率,方法虽然简单,但我国缺乏成熟、完备的针对中小企业的信用评级体系,因此在以中小企业大量存在为特征的产业链金融中,Credit Metrics模型也并不适合推广。
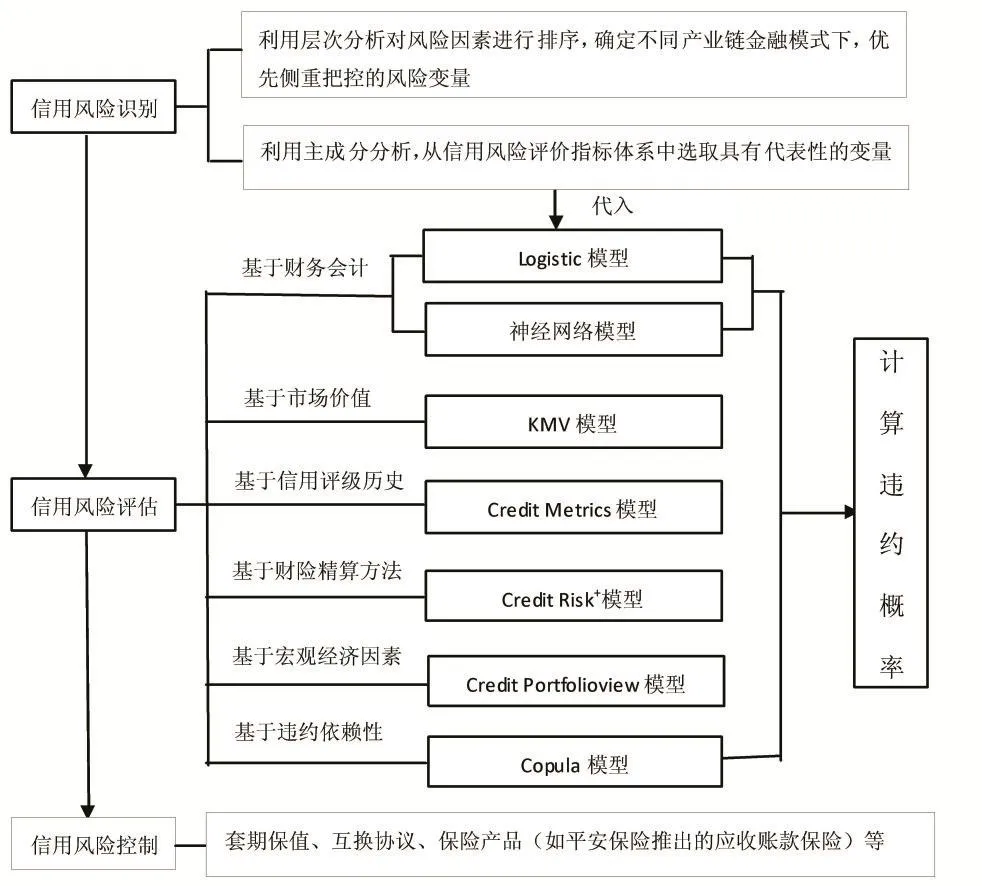
图1:产业链信用风险评价模型
现阶段,logistic二元逻辑回归模型是运用较为广泛的计算违约概率的数量模型(熊熊,2009;田家欢,2013;张志浩。2013)。在实际操作时,财务公司首先需要结合产业链业务特点,构建出反映产业链金融风险特征的指标体系。其中,对于非财务指标,还需借助专家打分予以赋值。然而目前全国只有少数几家财务公司开展产业链金融服务,财务公司对此类业务的认识仍需要经历一个逐渐深入的过程。
对财务公司来说,一方面,选择模型的假设前提与现实环境不可偏离太大;另一方面,从熟悉的领域入手,从易到难更为妥当。谙熟财务指标内在联系,具备较强的财务分析能力是财务公司的优势,因此从财务会计指标类的风险度量模型着手应是较为合理的选择。此外,国内资本市场日益完善,中小板与创业板的推出在一定程度上缓解了中小企业信息不透明问题。基于资本市场数据的计量模型,理论上对企业信用风险的度量更具动态性与时效性。因此,本文拟采用KMV模型对产业链条中企业的信用风险进行度量。KMV模型的数据来源于公开的资本市场,而选择其估算违约概率的隐含逻辑在于,金融资产交易价格反映的是未来净现金流的现值,未来净现金流与行业基本面息息相关,行业基本面的变化通常会影响产业链其他企业的股价。因此运用KMV模型不仅可以测算产业链单一企业主体违约概率,而且还可以对链条企业违约概率方向变动关系进行分析。
(二)模型建立
KMV模型源自莫顿对Black-Scholes期权定价公式的理解与运用。把KMV模型应用于产业链金融信用风险分析时,应把金融机构,包括财务公司对链上企业的借贷关系视为期权买卖关系。此时,期权标的为链上融资企业资产价值,执行价格为链上企业融资债务总额。若企业资产价值低于所需清偿债务的账面价值,企业会选择违约。相反则会选择守约。KMV模型可表示为:
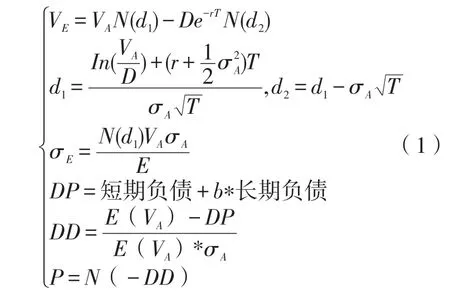
式中各变量含义如表1所示。
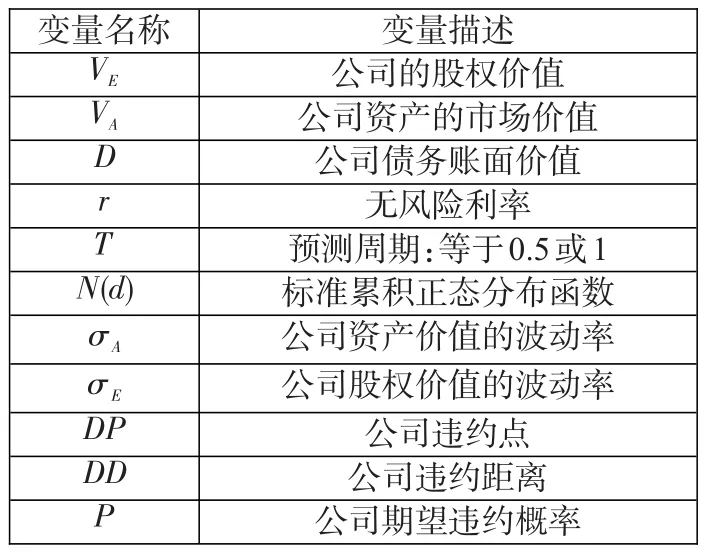
表1:变量定义与描述
运用KMV模型计算信用风险的思路是:通过估算VA、σA,求出违约距离,最终解得违约概率。Black-Scholes模型设定股票价格变化遵循对数正态分布,此时股票日收益率ui为:
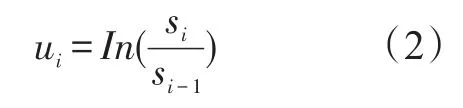
其中si为公司股票第i个交易日收盘价格。
则股票收益的日波动率为:

此外在KMV模型中,违约点的选取有可能对模型计算结果产生直接影响。原始KMV模型将违约临界点设置短期负债加0.5倍长期负债。章文芳(2010)、张能佳(2010)分别采用最小误判法、Matlab编程计算寻找适合于中国上市公司的违约点参数,但所得结果并不一致。本文对此不做重点探讨,在设置违约点参数b时,参考马若微(2015)的做法,令其取值0.1、0.2到1。
三、实证结果分析
(一)样本选取及数据来源
本文以汽车产业链作为研究对象。如此选择主要出于两点考虑:首先,国内较早开展产业链金融业务的原深圳发展银行曾在2010年年度报告中指出,汽车产业链条长,涉及钢铁、机械、销售、维修等数十类产业,产业链金融需求旺盛,已具备实现产业链金融应用的条件。其中,整车制造商在链条中处于主导地位,具有足够的权威性;零部件制造企业及销售企业则处于非核心位置,话语权相对较弱,不得不经常面对因核心企业在货价、账期等方面提出苛刻要求而产生的资金缺口问题。其次,中国重汽是我国重型汽车生产的骨干企业,总部设在山东济南,与山东境内多家同处汽车产业链上的上市企业有密切业务往来。同时,中国重汽所属中国重汽财务有限公司亦是国内较早成立的非银行类金融机构,为更好支持集团发展,希望拓展产业链金融业务。因此,对产业链信用风险的度量研究亦会对这类企业相关业务开展提供一定借鉴意义。剔除上市时间短、未登陆国内资本市场等影响因素,本文最终选择中国重汽(000951)、山东基隆股份有限公司(002363)、山东钢铁(600022)作为研究对象。
现实中产业链融资一般为期限小于1年的短期借款,故将预测周期设定为半年、1年两类。例如,假设一笔贷款于2013年1月1日发放,约定2013年6月30日归还。以往文献通常测算到期日当天违约概率,但贷款违约未必发生在到期日,期间任何一点都有可能。本文通过每日测算,以求出期限内违约概率平均值,稳定性更好。此外,由于财务数据获取时间上具有滞后性,因此同一季度内,样本公司债务面值、短期负债、长期负债均取自上一期公司定期公告。无风险利率取自中证网每日公布的一年期国债收益率。公司收盘价、债务面值、短期负债、长期负债、股权价值等数据则取自锐思数据库。
(二)违约概率的度量结果与分析
本文使用计算机编程软件计算得到中国重汽、山东基隆股份有限公司、山东钢铁2013年1月至2016年6月期间预期违约概率,如表2所示。
首先,在样本期间,预估中国重汽违约概率最小3.84%,最大4.78%,相差0.9%;预估基隆股份违约概率最小4.92%,最大5.19%,相差0.2%;预估山东钢铁违约概率最小2.58%,最大4.27%,相差1%。模型预估值较为稳定。
其次,当参数b分别设定为0.1、0.2到1时,违约点的选择对本次样本违约率计算影响不显著。在相同贷款期间,取不同b值,中国重汽、山东钢铁违约概率大小差异在0—0.2%;基隆股份,则在0%—0.03%。
此外,在研究期间,样本公司预估违约率变化与国家宏观经济运行方向一致,但意义不同(见图2、3)。
近年来国家经济处下行周期,经营困难的企业日益增多,理论上人们对企业违约心理预期逐渐增强。在此形势下,我国汽车产业不可避免地受到了一定冲击。但从中国产业信息网公布的数据来看,我国乘用车总体销量依旧维持增长态势,只是增速自2009—2010年达到顶峰后出现滑落,目前保持在8%—9%区间内。重卡行业,则由于2010年投资扩产,使得随后的五年实际一直处于去库存状态。据统计,2016年初,重卡厂商的平均库存已下降到728台。从行业数据对比观测,汽车业的发展走势未与国家GDP呈现出一致性关系。可以说,汽车市场规模容量及售后服务需求,为产业内企业业绩提供了良好支撑。反映在本文,中国重汽、基隆股份两家样本公司预估违约概率未随宏观经济走弱而恶化,相反,中国重汽预估违约概率在样本期间有小幅下降,而基隆股份则大致保持平稳。
先前钢铁业屡现大面积亏损情况,从理论上说,山东钢铁的违约可能性理应随GDP增速放缓而出现上升。然而在样本期,山东钢铁违约概率却维持在3.3%的低预期水平。对此可能的解释有:第一,山东钢铁地处华东,水路、铁路运输便捷,综合看其物流成本相对其他地区钢厂有一定优势;虽然面临其他地区钢材产品竞争,但在山东境内龙头地位突出,同时,华东地区也是我国钢材主要消费地之一。除2014年净利润呈现亏损,山东钢铁2013年、2015年分别赚取1.58亿元与0.75亿元。第二,钢铁业供给侧结构改革成效初显。万得数据显示,2016年上半年35家钢企利润已达42.79亿元,2015年同期则巨亏40亿元。同时,改革依旧在持续深入。山东省政府已就十三五期间钢铁行业去产能制定出详细计划,并下发《山东省钢铁行业淘汰落后产能实现脱困发展具体实施意见》,山东是继辽宁之后第二个公布具体去产能计划的省份,后续其他钢企所在地区也会有相应政策出台。政策力度加大,为钢铁业未来向好发展提供了基础,而资本市场恰恰反映预期,在业绩反转因素共振作用下,山东钢铁显示的较低预期违约率具有可信性。
图2:GDP增长率变化曲线

图3:样本公司违约概率变化
产业链金融理论认为,核心企业能够利用自身良好资信状况为中小类非核心企业提供融资担保,两者信用质量存在差别。从本文估计结果来看,中国重汽违约概率小于基隆股份违约概率亦是对这一点比较好的佐证。相比零部件制造商对整车制造商较强的依赖性,虽然同处汽车产业链上游端,但汽车领域对钢材的需要仅占钢铁行业下游需求的7%;同时,由于汽车业本身竞争激烈,单一整车制造商对国有大型钢铁企业并不具备信用优势。因此,本文所选山东钢铁预估违约概率并未高于中国重汽。

表2:样本公司KVM模型计算结果
(三)样本公司违约概率间的联系
由于本文以日数据计算违约概率,每家样本公司获得1094组数据,因而可采取时间序列分析方法研究变量间的相互关系。在对时间序列数据进行计量操作时,为避免出现虚假回归,首先要对各个变量进行平稳性检验。本文采用ADF检验来确定样本公司违约概率数据的平稳性。结果显示,原始数据经一阶差分后平稳。由于样本公司同处一条产业链,需关注其中一家公司违约概率的变化是否可以引起其余公司违约概率的变化。对此,本文采用格兰杰因果检验进行探究。经过多次试验,差分序列滞后7期AIC最小,为-43.31756,滞后1期SC最小,为-43.26211,两种滞后期选择标准显示不一致。此时应考虑用LR检验取舍,LR统计量为=-2×(23533.27-23587.43) =108.32。其中 23533.27 和23587.43分别表示滞后1期和7期时模型的对数似然函数值。在零假设下,统计量服从卡方分布,其自由度为VAR(7)到VAR(1)对模型参数施加的零约束个数。经计算,该检验相伴概率值大于0.05,表明采用1期滞后更为合理。在此基础上,格兰杰因果检验结果显示,重汽预估违约概率的变化并不是产业链合作企业基隆股份与山东钢铁违约率变化的原因;基隆股份违约概率的变化会引起山东钢铁违约概率的变化,反之则不成立。可能的原因是基隆股份产品60%以上出口国外,重汽虽与之有业务往来,但总量有限,因此一方的“负面”也很难实质性地影响另一方;进一步通过方差分解(见图4),发现山东钢铁违约概率变化的变动方差80%以上由自身变动导致,基隆股份对其影响第一期约为10%,从第2期稳定在12%附近,重汽的影响则几乎为0。这也从侧面支持了格兰杰因果检验的结果。

图4:山东钢铁违约概率变化方差分解
另外,三家样本公司数据同为1阶非平稳时间序列,有条件进行协整检验。本文利用Johansen方法,在5%显著性水平下,对样本公司违约概率进行了检验,结果如表3所示。
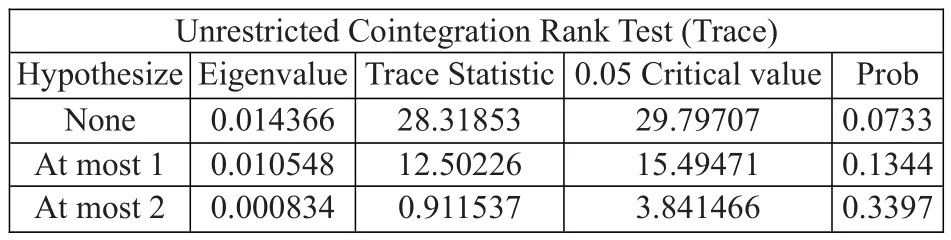
表3:样本数据协整检验结果
原假设None表示没有协整关系,该假设下计算的统计值为28.31853,小于临界值29.79707,且概率值为0.0733,表示无法拒绝原假设。因此,基于本文样本数据,无法认为中国重汽违约概率与其合作企业违约概率间存在规律性变化轨迹。
四、结论与建议
现阶段,财务公司对产业链金融风险度量能力偏弱。在综合有关产业链金融风险的研究现状和主要观点的基础上,本文认为基于财务会计指标与市场价值指标的计量模型更适合目前财务公司产业链金融信用风险度量。随后,本文选择汽车产业链为研究对象,采用KMV模型估算了中国重汽、山东基隆股份有限公司与山东钢铁三家样本公司违约概率,并在已估算违约概率的基础上,利用时间序列分析方法,研究了样本违约概率之间的变动关系。
(一)产业链条上企业的违约概率不一定随国家宏观经济走弱而提升
每一个行业都有其自身发展的规律周期,每一家企业也有应付危机的方法与手段。经济发展速度放缓的确使一些企业的经营状况陷入了困境,但在衡量信用风险时,不能简单依赖经济环境变化判断信用风险的高低。
(二)相比链条其他企业,核心企业违约概率未必最低
产业链核心企业对中小类非核心企业具备更优异的信用质量,反映在违约概率上,预期核心企业违约概率低于中小类非核心企业。但类似汽车产业链这般牵扯众多企业的长链条,除了中小类非核心企业,也有同核心企业体量相当的非核心企业,如本文的中国重汽与山东钢铁。政策支持与业绩改善,可能使得这类企业基于资本市场数据反映出的违约概率,较核心企业更低。
(三)核心企业违约率的变化与链条其他企业违约率的变化并不存在格兰杰因果关系,非核心企业间违约率变化存在传导可能性
从近三年时间的计算数据来看,产业链企业违约概率值之间并不存在稳定的均衡关系。
过往研究仅把St、*St、暂停上市三种类别上市公司其中一类视为违约样本对比参照,但实际三者违约风险逐次升高。理论上,如果能够分别计算三类公司违约概率,那么原本正常类公司违约概率一旦进入其中一类区间值,其信用风险等级应随之提高。本文在此不再展开研究。但通过实证分析不难发现,以计量操作为代表的量化分析有助于财务公司更好认识产业链金融风险。鉴于此,本文有如下建议:
第一,财务公司管理者应主动学习金融风险相关专业知识,提升风险度量能力。产业链金融的复杂性对管理者的专业能力提出了更高的要求,不仅要掌握传统的财务知识理论,还要对金融业务及其带来的风险有深刻认识。财务公司可以从外部吸收风险管理专业人才,也可以将对公司内部业务熟练、素质较高的员工选送到其他更具风险管理经验的金融机构学习,管理者专业水平决定了财务公司风险管理整体大环境。
第二,发展初期,财务公司可以参照其他金融机构的先进经验,根据业务要求选择合适、已成熟的模型工具。同时,由于一般模型本身基于训练样本的数据而建立,因此在引入测试样本判别结果时,要将模型的设立和验证相分离,并在获取最新数据后及时检测模型是否失效。
第三,完善数据库建设。在开展产业链金融的最初几年,企业数据的缺乏会是财务公司遇到的第一个问题,也会影响量化分析工具效用的发挥。对此,财务公司一方面必须切实做好收集、储存、整理与产业链相关的企业财务信息、交易信息等工作;另一方面,应积极与银行开展数据信息交流、共享,早日建立自己的产业链数据库。
[1]张玲,曾维火.基于Z值模型的我国上市公司信用评级研究[J].财经研究,2004,(6).
[2]夏立明,边亚男,宗恒恒.基于供应链金融的中小企业信用风险评价模型研究[J].商业研究,2013,(10).
[3]李倩.基于PCA-LSFSVM的供应链金融信用风险评估模型研究[D].华南理工大学硕士研究生论文,2014.
[4]管百海.通过供应链金融提高供应链的整体竞争力[J].西南金融,2017,(4).
[5]熊熊,马佳,赵文杰,王小琰,张今.供应链金融模式下的信用风险评价[J].2009,(12).
[6]田家欢.供应链金融及其信用风险控制[D].浙江工商大学硕士研究生论文,2013.
[7]张志浩.供应链金融违约风险评估及防范[D].东华大学,2013.
[8]章文芳,吴丽美,崔小岩.基于KMV模型上市公司违约点的确定[J].统计与决策,2010,(14).
[9]张能福,张佳.改进的KMV模型在我国上市公司信用风险度量中的应用[J].预测,2010,(5).
[10]马若微.违约风险的动态测度与解除[M].北京:经济科学出版社,2015.
A Study on the Credit Risk Measurement of Industrial Chain Finance Based on the Perspective of Financial Company——Take China National Heavy Truck Group(CNHTC)as an Example
Yu Jia1WangAnyong2Zhang Xiaowen3Song Lei4
(1.Shandong Branch of China Power Finance Co.LTD,Shandong Jinan 250001;2.Changcheng Xinsheng Trust Limited Liability Company,Beijing 100045;3.Shandong Branch of Agricultural Bank of China,Shandong Jinan 2500002;4.China Power Finance Co.LTD,Beijing 100005)
Focusing on the credit risk measurement of industrial chain corporations and taking the listed companies in CNHTC industrial chain as samples,this paper has used the KMV model to estimate the default probability of the selected companies based on the data published in the capital market of the sample companies.Furthermore,it has explored the changing of sample companies'default probability by time series analysis.The results show that the default probability of enterprises in the industrial chain does not necessarily increase as the national macro-economy weakens;compared with other enterprises in the chain,the default probability of the core enterprise is not necessarily the lowest;there is no causal relationship between the change of the default probability of core enterprises and that of other enterprises,while the changes of default probability among non-core corporations are likely epidemical.From the recent three years'calculated data,there is no stable equilibrium of default probability among the enterprises in the industrial chain.
industrial chain,default probability,KMV model
F830
B
1674-2265(2017)08-0034-07
2017-06-30
本文仅代表作者个人观点,文责自负。
于嘉,男,山东济南人,经济学博士,供职于中国电力财务有限公司山东分公司,研究方向为国民经济学;王安水,男,山东济南人,供职于长城新盛信托责任有限公司;张晓雯,女,山东济南人,经济学博士,供职于中国农业银行山东省分行,研究方向为财务管理;宋蕾,女,山东青岛人,供职于中国电力财务有限公司,研究方向为金融信息工程。
(责任编辑 耿 欣;校对 WJ,GX)
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
纺织科学研究(2021年9期)2021-10-14
今日农业(2021年13期)2021-08-14
中学生数理化·高三版(2021年3期)2021-05-14
中学生数理化·高三版(2021年3期)2021-05-14
现代电子技术(2021年3期)2021-02-02
当代陕西(2019年13期)2019-08-20
智富时代(2018年2期)2018-05-02
智富时代(2018年2期)2018-05-02
