
基于参数优化MPE与FCM的滚动轴承故障诊断
2017-07-26 00:53陈东宁张运东姚成玉来博文吕世君
轴承 2017年5期
陈东宁,张运东,姚成玉,来博文,吕世君
(燕山大学 a.河北省重型机械流体动力传输与控制实验室;b.先进锻压成形技术与科学教育部重点实验室;c.河北省工业计算机控制工程重点实验室,河北 秦皇岛,066004)
滚动轴承是旋转机械中应用最广泛,也是最容易出现故障的核心零部件。当轴承出现异常或发生故障时,采集到的振动信号往往具有非线性、非平稳特征,而外界干扰噪声则导致该信号的信噪比很低,故障特征难以提取[1]。因此,传统的线性理论在滚动轴承振动信号分析的应用中存在一定的局限性。
排列熵(Permutation Entropy, PE)是一种检测一维时间序列复杂度的平均熵参数[2],对信号的变化具有较高的敏感性,且算法简单,可以更好地检测复杂系统的动力学突变。排列熵只能检测时间序列在单一尺度上的复杂性和随机性,复杂系统的输出时间序列则在多重尺度上包含特征信息,为研究时间序列的多尺度复杂性变化,在排列熵的基础上提出了多尺度排列熵(Multi-Scale Permutation Entropy, MPE)算法[3],并在故障识别领域得到了很多应用[4-6]。然而,多尺度排列熵算法的结果受自身参数的影响,若参数设置不合理,将无法达到最佳的处理效果。文献[7]提出了基于重构时间序列的最佳相空间来确定排列熵参数的方法,对嵌入维数和延迟时间的确定方法进行了研究,但忽略了时间序列长度。目前,多尺度排列熵尺度因子与时间序列长度的选择仍然仅凭经验,如采用限定的几个经验数据长度值,通过观察不同长度的高斯白噪声的排列熵值确定时间序列长度[4],此种方法虽能达到一定的处理效果,但所给定数据长度值的个数有限,且数值相差较大,难以准确反映原始信号的特征信息。
也有学者保持多尺度排列熵算法中的某一个或某几个影响参数不变,讨论剩余的其他参数对处理结果的影响,但其忽略了参数之间的交互作用。因此,综合考虑参数之间的交互影响,分别采用遗传算法[8]和微粒群算法[9]对多尺度排列熵的参数进行优化,通过对比分析确定多尺度排列熵的最优参数,提高算法的准确性;进而,提出以多尺度排列熵值作为特征参数、结合模糊C均值(Fuzzy C-Means Clustering,FCM)聚类算法[10]进行模式识别的滚动轴承故障诊断方法。
1 多尺度排列熵参数优化
1.1 多尺度排列熵
多尺度排列熵定义为时间序列在不同尺度下的排列熵。对时间序列{X(i),i=1,2,…,N}进行粗粒化处理,得到粗粒化序列
(1)
式中:N为时间序列的长度;[N/s]表示对N/s取整;s为尺度因子,s=1,2,…。当s=1时,粗粒化序列为原始序列。分别计算每个粗粒化序列的排列熵即可得到时间序列的多尺度排列熵[3-7]。
在粗粒化环节中,尺度因子s的选择尤为重要,若s取值过小,不能最大限度的提取信号的特征信息;若s取值过大,将有可能造成信号之间的复杂度差异被抹除。同时,在多尺度排列熵的计算过程中,若嵌入维数m取值太小,算法的突变检测性能降低;若m取值太大,将无法反应时间序列的细微变化。而且,时间序列长度N与延迟时间τ对多尺度排列熵算法也有不同的影响。可见,多尺度排列熵算法的参数设置影响其最终处理结果。因此,有必要对多尺度排列熵的参数进行优化。
1.2 遗传算法参数优化
遗传算法是一种全局优化的自适应概率搜索算法,其借鉴了生物的自然选择和遗传进化机制,适用于参数的选择和优化。利用遗传算法对多尺度排列熵参数优化的流程如图1所示,其具体实现过程为:1)将优化参数按二进制进行编码;2)根据个体对目标函数的适应情况,选择适应度高的个体,淘汰适应度低的个体;3)交叉、变异操作产生新的个体。若遗传算法进化达到最大进化代数或连续几代的适应度没有明显的变化,则停止进化。否则,重复以上过程继续进化。
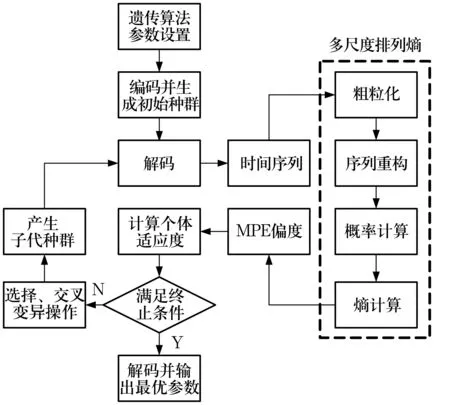
图1 基于遗传算法的多尺度排列熵参数优化流程Fig.1 Procedure of MPE parameter optimization based on GA
适应度函数是用于区分群体中个体好坏的标准,根据目标函数变换得到。一般通过求取均值分析一组数据的总体趋势,但仅凭均值并不能完全表征一组数据的总体概况,此时可求取数据的偏度。偏度越大,均值的效能越有问题;偏度越小,均值越可信赖[11]。因此,选用多尺度排列熵的偏度作为适应度函数。
将时间序列X(i)所有尺度下的排列熵组成序列Hp(X)={Hp(1),Hp(2), …,Hp(s)},计算其偏度Ske,得到适应度函数,即
(2)
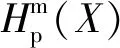
1.3 微粒群算法参数优化
微粒群算法是一种高效的群体智能优化算法,常被应用于求解各种优化问题。微粒群算法进化时,每个微粒的速度与位置不断被更新,其更新方程分别为
vid(t+1)=c1r1[pid(t)-xid(t)]+
c2r2[pgd(t)-xid(t)]+wvid(t),
(3)
xid(t+1)=xid(t)+vid(t+1),
(4)
式中:vid(t+1),vid(t)分别为微粒i第t+1代和第t代的第d维的速度;xid(t+1),xid(t)分别为微粒i第t+1代和第t代的第d维的位置;pid(t)为微粒i第t代个体最优解的第d维;pgd(t)为第t代全局最优解的第d维;w为惯性权重;c1,c2为加速常数;r1,r2为0~1之间相互独立的随机数。
利用微粒群算法搜寻多尺度排列熵参数的最优解时,同样设定适应度函数为多尺度排列熵的偏度计算公式。基于微粒群算法的参数优化流程如图2所示,具体实现步骤如下:
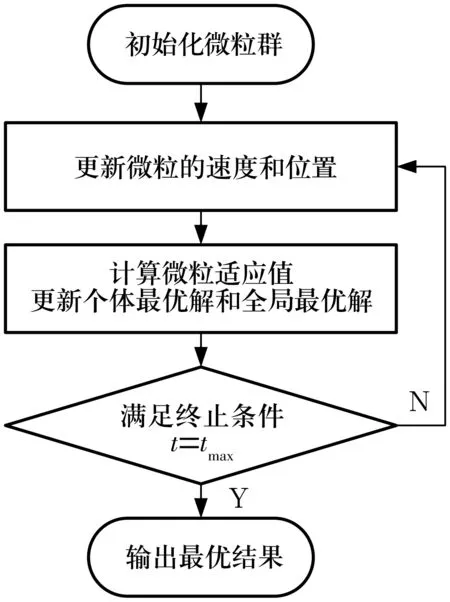
图2 基于微粒群算法的多尺度排列熵参数优化流程Fig.2 Procedure of MPE parameter optimization based on PSO
1)初始化微粒群,随机初始化每个微粒每一维的速度与位置;
2)分别由(3)式和(4)式更新微粒的速度与位置;
3)根据(2)式,即多尺度排列熵的偏度公式计算微粒的适应度,更新任意微粒的个体最优解和全局最优解;
4)判断终止条件,若t=tmax,则执行步骤5),否则返回步骤2);
5)输出优化结果。
2 基于参数优化MPE与FCM算法的故障诊断方法
多尺度排列熵可以度量信号在不同尺度下的复杂度,用多尺度排列熵量化轴承振动信号并将多尺度排列熵值作为特征参数,可提取轴承故障特征。但滚动轴承从正常状态到发生故障是一个渐变的过程,只用特征值辨识不同类型或不同损伤程度的故障具有一定的难度。
模糊C均值算法是经典的基于目标函数的聚类算法,其通过极小化所有数据点与各聚类中心的欧氏距离及模糊隶属度的加权和,不断地迭代修正聚类中心和隶属矩阵,直到符合终止准则,将具有相似特性的数据样本聚为一类,具体实现过程可参考文献[10, 12]。因此,提出基于参数优化多尺度排列熵与模糊C均值聚类相结合的故障诊断方法,诊断流程如图3所示,具体步骤如下:

图3 故障诊断流程Fig.3 Procedure of fault diagnosis
1)分别利用遗传算法和微粒群算法对多尺度排列熵的参数进行优化,得到2组优化参数。通过对比分析,确定多尺度排列熵的最优参数组合;
2)将优化得到的最优参数组合重新设置为多尺度排列熵的参数,计算原始信号的多尺度排列熵值并进行分析;
3)由得到的多尺度排列熵值提取合适的特征向量,选取一部分作为已知故障样本,另一部分作为待识别故障样本。利用模糊C均值聚类算法确定已知故障样本的标准聚类中心,由择近原则计算待识别故障样与标准聚类中心的距离,实现滚动轴承的故障分类识别。
3 实例分析
采用美国凯斯西储大学电气工程实验室的滚动轴承试验数据进行分析。测试驱动端轴承为6205-2RS JEM SKF深沟球轴承,采用电火花加工技术在轴承上布置单点故障,通过安装在电动机驱动端轴承座上方的加速度传感器采集轴承的振动加速度信号。
3.1 多尺度排列熵参数优化
选取电动机转速为1 750 r/min时轴承正常状态下的振动信号数据,分别利用遗传算法与微粒群算法优化多尺度排列熵的参数,优化结果见表1,微粒群算法全局最优适应度随进化代数的变化曲线如图4所示。
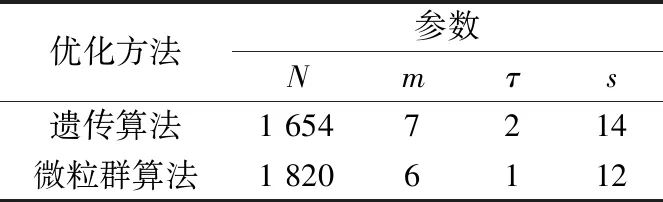
表1 多尺度排列熵参数优化结果Tab.1 Results of MPE parameters optimization
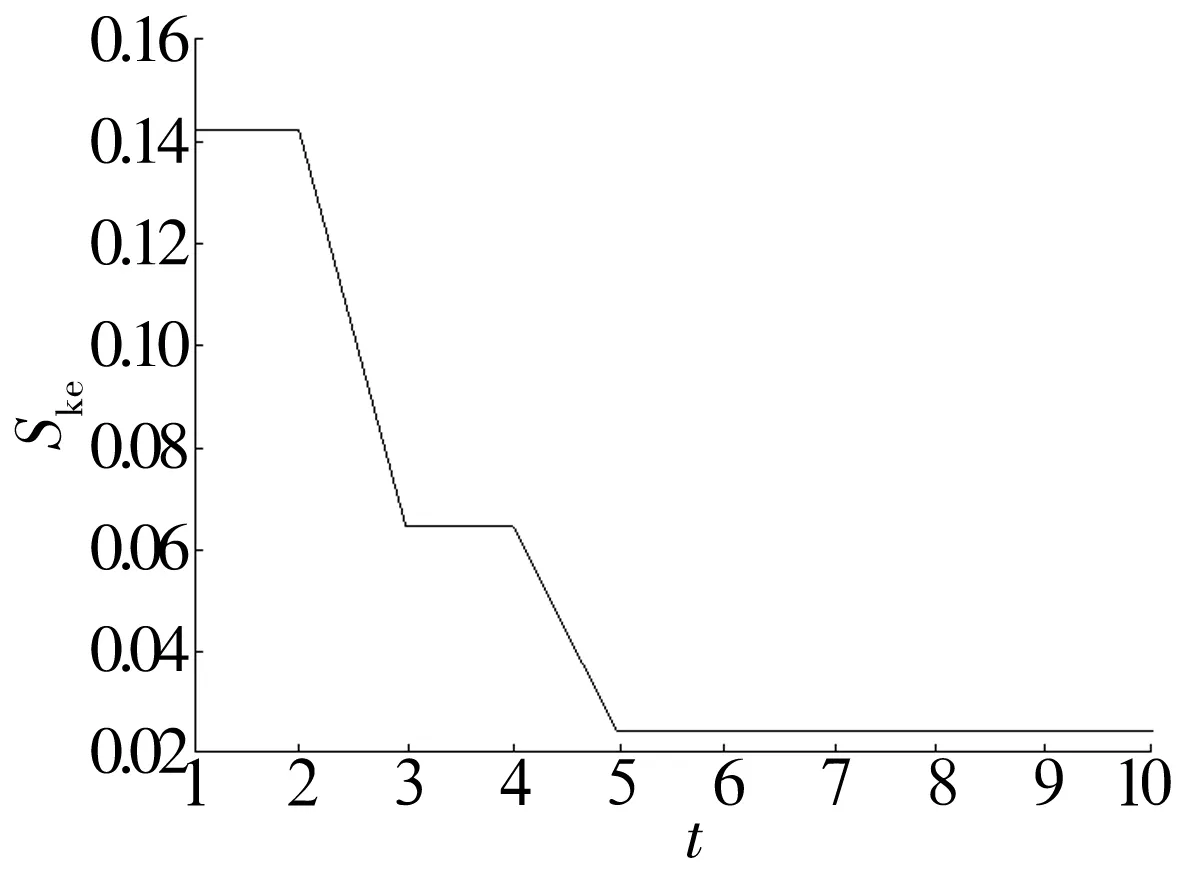
图4 全局最优适应度随进化代数的变化
Fig.4 Variation of global optimal fitness with evolutionary generations
为确定多尺度排列熵的最优参数组合,用模糊C均值聚类的聚类效果对2组参数进行对比,聚类效果可用分类系数F和平均模糊熵H进行检验,分别为
(5)
(6)
式中:c为聚类中心个数;n为样本个数;uij为第j个样本属于第i类的隶属度。分类系数越接近1,聚类效果越好;平均模糊熵越接近0,聚类效果越好。
分别设置2组优化参数为多尺度排列熵的参数,选取轴承4种状态的振动信号数据各20组,分别计算这些信号的多尺度排列熵值,并将其作为特征向量输入模糊C均值聚类分类器中,根据(5)式和(6)式分别计算2组优化参数的分类系数和平均模糊熵。同时,为验证参数优化的有效性,选取文献[4]中参数以及一组经验参数(N=2 048,m=5,τ=3,s=15)对其聚类效果进行检验,结果见表2。

表2 优化参数聚类效果检验Tab.2 Clustering results of optimized parameters
由表2可知:与文献[4]及经验参数的结果相比,2种优化参数的分类系数较大、平均模糊熵较小,说明优化参数的聚类效果较好。经微粒群算法优化后,其分类系数更接近1,且平均模糊熵更接近0,所以,经微粒群算法优化后的参数聚类效果更好,故设置多尺度排列熵的参数为经微粒群算法优化后的参数。
3.2 同负荷下不同类型故障的诊断
选取电动机负荷2 HP,电动机转速为1 750 r/min时轴承正常、内圈故障、外圈故障和钢球故障4种状态下的振动信号进行分析,4种状态振动信号的局部时域图如图5所示。采样频率为12 kHz,每种状态取40组数据,每组数据长度均为1 820。前20组数据作为已知故障样本,将其多尺度排列熵值作为特征向量输入模糊C均值聚类分类器,求取已知故障的标准聚类中心,后20组数据作为待识别样本,采用Euclid贴近度的择近原则对滚动轴承各种故障进行识别。
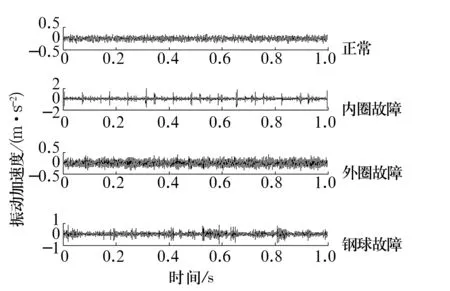
图5 滚动轴承不同状态下振动信号的时域图Fig.5 Time domain of rolling bearing vibration signals under different states
将待识别样本A与标准聚类中心O组成故障诊断集B={b1,b2,…,bz},z为B中样本个数,则A与O的Euclid贴近度δ(A,O)为
(7)
式中:A(bi),O(bi)分别为A与O的隶属度函数。
当轴承发生故障时,其振动特性发生改变,主要体现在幅值和周期特性上,但时域图所能获取的信息量较少。对轴承4种状态的振动信号进行多尺度排列熵分析,计算得到多尺度排列熵如图6所示。从图6可以看出,不同状态的滚动轴承多尺度排列熵值不同,这是因为当滚动轴承发生故障时,振动信号的随机性发生变化,使排列熵值发生变化。在同一状态下,随尺度增大,粗粒化序列的随机性和复杂性降低,排列熵值的变化幅度减小。
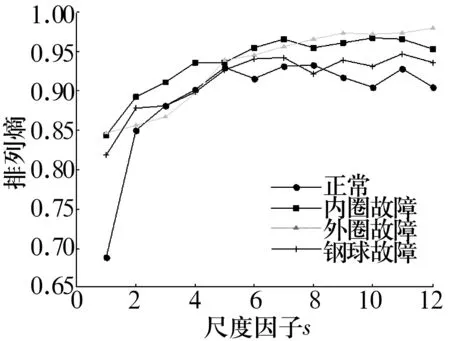
图6 滚动轴承不同状态下振动信号的多尺度排列熵Fig.6 MPE of rolling bearing vibration signals under different states
然而,图6仍不能明显区分滚动轴承的4种状态,故提出以参数优化多尺度排列熵值作为特征参数,结合模糊C均值聚类算法对滚动轴承故障进行识别分类。计算滚动轴承4种状态各40组数据样本的多尺度排列熵值,并选取每种状态前20组数据的多尺度排列熵值进行训练;最后,选取表征振动信号主要信息的前5个尺度的排列熵值作为特征向量,用模糊C均值算法对其进行聚类分析,结果如图7所示。
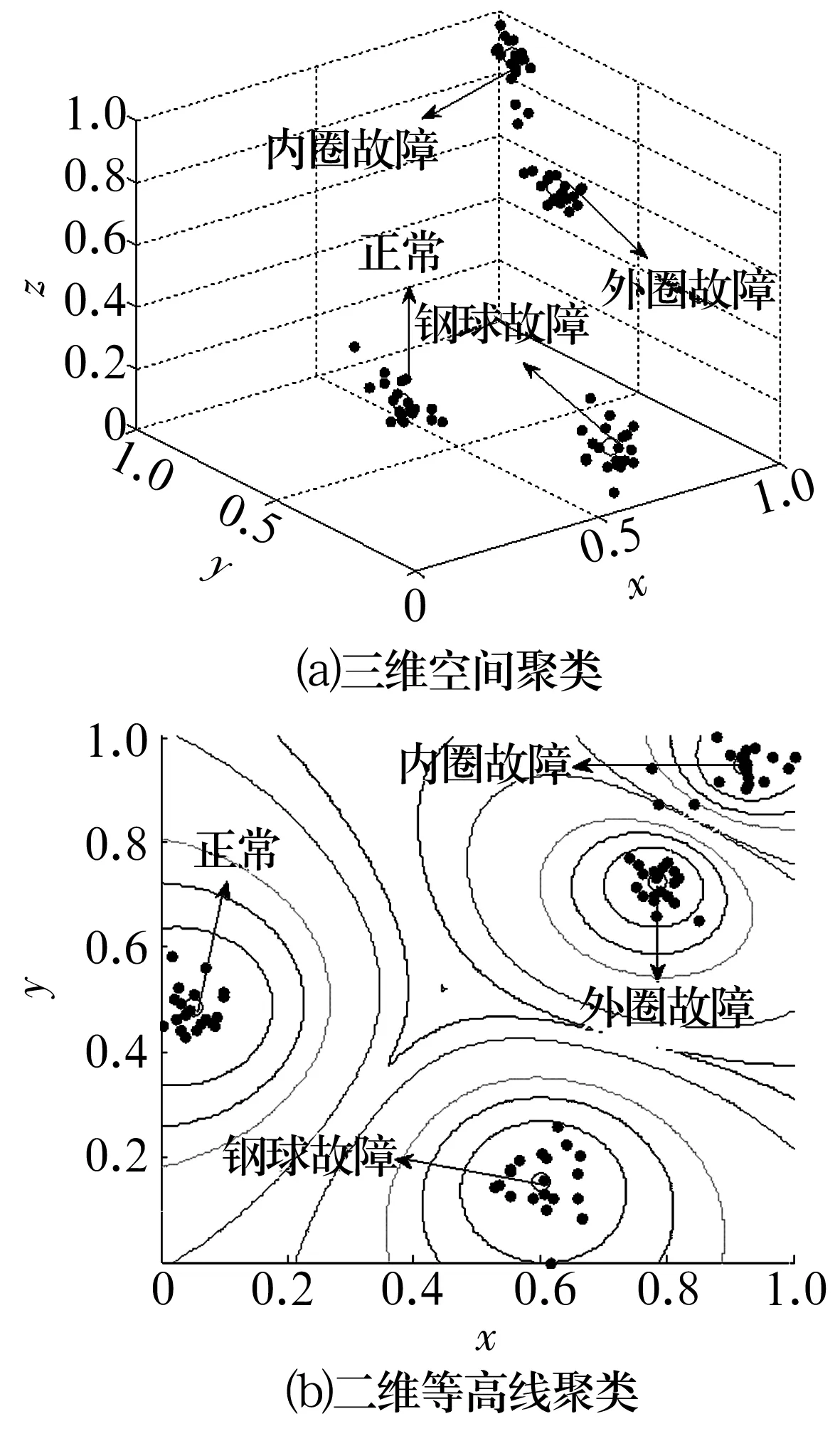
图7 滚动轴承不同状态下振动信号的聚类分析结果Fig.7 Cluster analysis results of rolling bearing vibration signals under different states
从图7可以看出,80组样本数据经过模糊C均值聚类算法处理后,按照故障类型分布在4个聚类中心的周围,说明基于参数优化多尺度排列熵和模糊C均值聚类算法的故障诊断方法具有很好的分类识别效果。取分类得到的4个聚类中心为标准聚类中心,通过计算后20组待识别样本的多尺度排列熵值与标准聚类中心的Euclid贴近度判断滚动轴承故障类型。
为进一步验证上述方法的有效性,分别以单一尺度排列熵和样本熵进行对比分析。依据同样的原理,通过分别计算待识别样本的排列熵、样本熵与标准聚类中心的Euclid贴近度判断轴承故障类型。3种方法的诊断结果见表3。由表3可知:基于参数优化多尺度排列熵与模糊C均值聚类的滚动轴承故障识别率为100%,高于其他2种方法的故障识别率,且多尺度排列熵的分类系数、平均模糊熵均优于单一尺度排列熵和样本熵。

表3 不同类型故障的诊断结果Tab.3 Results of fault diagnosis in different types
3.3 同负荷下不同损伤程度故障诊断
选取电动机负荷2 HP,电动机转速为1 750 r/min时轴承正常、内圈轻微损伤和内圈严重损伤3种故障类型进行验证,其中,轻微损伤直径为0.177 8 mm,严重损伤直径为0.533 4 mm。
同样,对不同损伤程度的轴承振动信号分别选取40组数据,数据长度均为1 820,其多尺度排列熵和聚类分析结果分别如图8、图9所示。

图8 不同损伤程度多尺度排列熵Fig.8 MPE of different damage degree
从图8可以看出,轴承正常与内圈严重损伤故障区分较为明显,轴承正常与内圈轻微损伤、内圈严重损伤与内圈轻微损伤则不能明显区分出来。而从图9可以看出,经模糊C均值聚类分类后,轴承不同损伤程度的故障被有效区分。同样对上述3种方法进行对比分析,结果见表4。由表4可知:在不同损伤程度的轴承故障诊断中,基于参数优化多尺度排列熵与模糊C均值聚类方法的故障识别率仍优于其他2种方法,而分类系数与平均模糊熵亦可证明该方法的优越性。
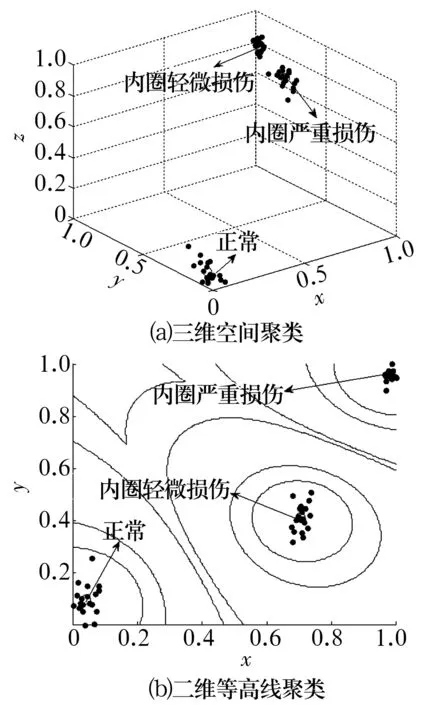
图9 不同损伤程度轴承振动信号的聚类分析结果Fig.9 Cluster analysis results of rolling bearing vibration signals in different damage degree
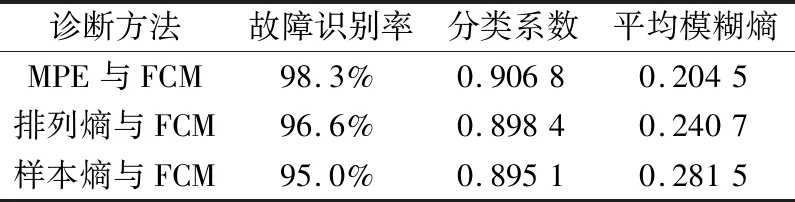
表4 不同损伤程度故障诊断结果Tab.4 Results of fault diagnosis in different damage degree
3.4 不同负荷下的故障诊断
在故障诊断的实际应用中,获得所有工况下的不同故障类型数据比较困难,因而利用已有工况故障数据识别其他工况的故障类型具有一定的实际意义。为此,利用电动机负荷为2 HP时的标准聚类中心,对其他负荷工况进行故障诊断,进而评估该方法的适用性。
从负荷1 HP工况下抽取30组不同类型故障数据作为待识别样本,通过计算与标准聚类中心的Euclid贴近度进行故障识别,结果见表5。
由表5可知:参数优化多尺度排列熵与模糊C均值聚类结合的诊断结果中只有内圈故障与钢球故障被错分,而其他2种方法除内圈故障与钢球故障容易被错分外,外圈故障也易被诊断为内圈故障。这是由于变负荷下轴承故障信号发生明显变化,导致变负荷下的故障识别率降低。而多尺度排列熵在引入尺度因子后,能够从不同尺度上更好地反映轴承振动信号的动力学突变,丰富故障特征信息,在变负荷工况下仍可获得较高的故障识别率,说明其具有很好的适用性。
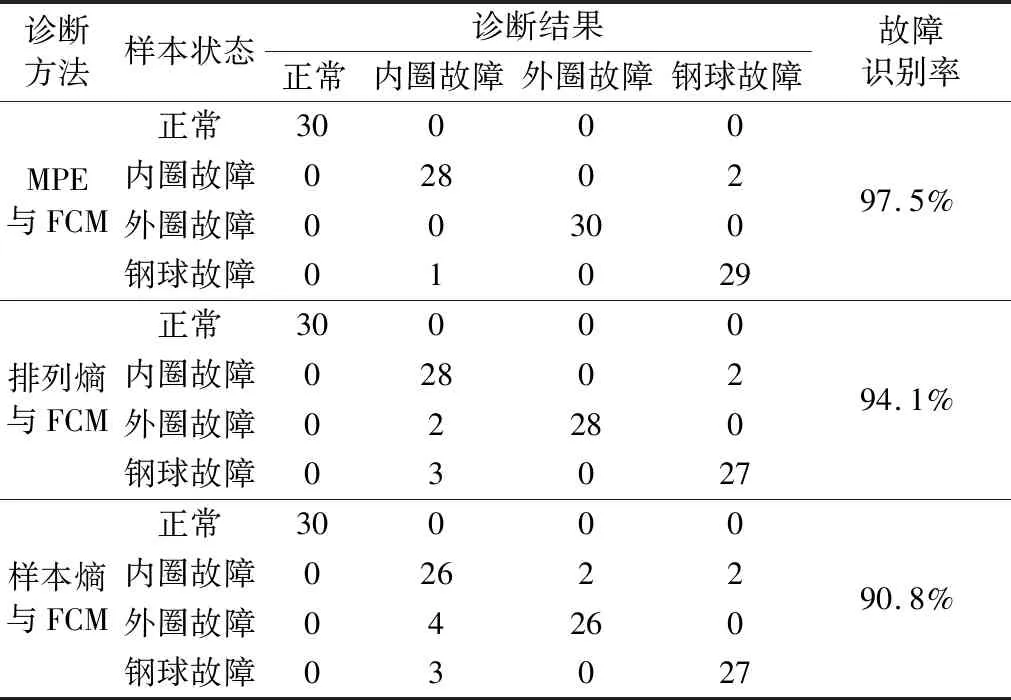
表5 负荷1 HP工况下不同故障类型诊断结果Tab.5 Results of fault diagnosis in different types under 1 HP load condition
4 结束语
针对多尺度排列熵算法的最佳参数确定问题,充分考虑参数之间的交互影响,以多尺度排列熵偏度作为适应度函数,基于遗传算法和微粒群算法综合求解优化多尺度排列熵的参数;进而利用参数优化多尺度排列熵对滚动轴承振动信号进行特征提取,与未优化参数的对比分析证明,参数优化多尺度排列熵进行特征提取具有更好的分类识别效果。
将参数优化多尺度排列熵与模糊C均值聚类相结合,应用于同负荷与变负荷工况下滚动轴承的故障诊断,通过与单一尺度排列熵、样本熵结合模糊C均值聚类的方法进行对比,结果表明:上述方法在同负荷与变负荷工况下的故障识别率均高于后两者,分类识别效果较好,为实际应用中故障数据不完整情况下的故障诊断提供了一条有效途径。
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
心肺血管病杂志(2019年12期)2019-05-20
中国有色金属学报(2018年2期)2018-03-26
疯狂英语·新悦读(2017年6期)2017-06-24
太空探索(2016年5期)2016-07-12
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
时代英语·高三(2014年5期)2014-08-26
郑州大学学报(理学版)(2014年4期)2014-03-01
