
用户消费行为中选择不明确性挖掘
2017-07-05 13:27韩民琦
重庆科技学院学报(社会科学版) 2017年6期
韩民琦
用户消费行为中选择不明确性挖掘
韩民琦
以数据驱动,挖掘消费者在消费过程中的不明确性。在以数据为驱动的视角下提出自动挖掘不明确性的模型。给出每个行为小节观测到的不明确性的定量化方式。基于这些所观测定量化的不明确性,通过一个概率图模型同时习得潜在消费者的不明确性指数和商品组合中的不明确性指数。分析这类消费者行为中的选择不明确性挖掘在很多方面的潜在应用价值,比如竞争性商品的检测、个性化商品推荐。
消费者行为;概率图模型;个性化推荐;概率矩阵分解
近年来,零售业信息系统的变革使得我们能收集到大量的消费者消费行为记录。这些富含大量有用信息的消费行为日志使得我们有机会挖掘出更加个性化的消费者信息和消费者个人喜好,也因此能发展更好的个性化服务,比如个性化商品推荐。
沿着这个思路,分析并理解消费者的决策过程越发重要。然后,随着消费者可选择的商品数量快速增加,消费者做出决策越来越困难。越来越多的人遭受到犹豫不定的困扰——即消费者在竞争性商品中不能做出快速果断的选择。比如我们也许在微博、朋友圈或者其他社交网络上见过好友在几个类似商品中间不能做出选择,于是发动态寻求朋友建议和帮助,最终做出选择[1]。在日常生活中我们也可以发现商品选择中的犹豫不定确实是一个很常见的问题。同时,每一次对消费者在消费过程中犹豫的分析都能得到这个消费者的一些特征(比如自信或者沮丧),以及消费者对商品的认知、评价。因此,无论在营销、管理和心理学领域对个人犹豫不定的理解都是个重要的研究主题。很多研究者已经对很多相关问题投入大量研究,比如对犹豫不定的衡量、产生犹豫不定的原因以及如何缓解做出决策的困难[2-3]。
尽管以往的研究意义重大,也有很多重要的发现,但是目前科学地从字义上对犹豫不定的理解还是很有限,甚至还没有对犹豫不定作出清晰的定义。为了调查消费者行为中犹豫不定的现象,通常由心理学研究者或者社会学研究人员设计一些问卷,包含类似“我能快速做出决策”的问题或者选项,然后由个人对这些问题的回答来衡量他们犹豫不定的程度,在本次研究中是指不明确性指数。这些基于测量视角的调查问卷通常不仅有很大程度的主观性,对于被调查人员来说也十分繁琐,进一步说基于调查问卷得出的结论可能包含较大的偏见,甚至是误导性的。在没有人工干预时,通过消费者日常的行为日志来自动挖掘不明确,结果会更加精准,即完全以数据为驱动的方式挖掘不明确。对于这个目标,有以下几个问题需要解决。如何在没有统一的标准或问题的情况下有效定义所观测的不明确性程度?如何同时精准地挖掘出潜在的和个性化的每个人和商品之间的不明确性指数?如何利用挖掘出的不明确性来提供更好的服务?
为了解决以上提到的几个问题,笔者在以数据为驱动的视角下提出自动挖掘不明确性的模型。第一,分析了消费者在网络上的消费行为,并且提出衡量在每一个消费行为小节中所观测到的不确定性指数的基本定义。基于现有的其他领域对消费者行为中犹豫不定的理解和数据的有效性,本次研究中的不明确性定义主要考虑3个主要特征,比如一个行为小节中的操作长度。第二,以一个概率图模型,能同时习得消费者和商品之间的不明确性指数[4]。以这种方式,每个消费者和每个商品之间的不确定性需要被量化。第三,说明挖掘出的不明确性有很多潜在的应用。比如,对于每个犹豫不定的消费者,为了减少其选择成本,可以推荐给他可能购买的商品组合。或者,对于零售商,可以发掘出相互具有竞争性的商品。本次研究的主要工作如下:
以数据为驱动的方式来定义人的犹豫不定,数据源于百万网络消费者的行为日志。
提出了一个在没有人工干预的情况下自动量化每个行为操作小节的不明确性指数的方法和同时计算用户和商品之间的不明确性指数的基本框架。这个框架不仅仅只限用于电子商务领域,同样适用于其他领域的类似问题。
深入分析对于被挖掘出的不明确性可能的应用。不明确性挖掘可以应用于为零售商发现并提供竞争商品的信息,预测消费者的购买决策,为消费者提供更好的推荐服务。
一、相关论文综述
本节回顾以往对决策和决策的制定、心理学、管理学和市场营销的研究,总结目前对消费者行为中犹豫不定的理解。
第一阶段对犹豫不定研究的主要方向在基于行为特征来衡量消费行为的不明确性。事实上,目前科学地从字义上对犹豫不定的理解还是很有限,甚至还没有对犹豫不定的清晰定义。不过,几个对于犹豫不定基本尺度的定义已经被讨论过,这些框架可被用于研究犹豫不定的特殊特征。这些尺度包括Frost and Shows’ Indecisiveness Scale(FIS), Germeijs and De Boeck’ Indecisiveness Scale(GIS),调查问卷中的问题通常由心理学研究者或者社会学研究者设计。比如,问题可能是“我对自己做出的决定十分确定”或者 “在做出决定之前我要花很长时间去权衡利弊”,每个问题都被作为一种论证,表明受试者对相应问题的一致程度。这些不明确性的程度的特性(比如它们的准确性)由一些经验性结论来论证,通常这些经验性结论由心理计量表测试得到[5-6]。
在第二阶段,研究的主要方向集中在产生犹豫不定的原因(比如个体的认知因素)。比如,在如今竞争越发激烈的市场下,消费者面临越来越多的可选商品,有必要分析可供的选择过多和消费行为犹豫不定之间的关系。通过分析以往的研究发现,由于可选商品数量的不断增加而导致消费者选择困难的说法并不十分靠得住。做出一个简单决策困难与否并不依赖于选择本身,更多地和决策制定者的心理状态有关。有学者提出做出选择的难易程度根据做出选择的人的心理关注点的变化而变化,比如当为自己做决定时,人们心理状态常常是防御性心理,而为他人出决定时,常常是促进性心理。但是,也有学者发现可选商品的数量对消费者的判断和决策过程有影响。还有学者研究了可选商品的数量和其他因素(比如决策目标)的影响,发现这些因素可能会导致消费者的决策不明确。E.Rassin等人发现个体之间的差异(比如性别的不同)和决策带来的风险都会对消费行为中的犹豫不定有较大影响[5]。近来,R.Dhar等人基于双系统理论提出了一个全面理解喜好形成过程的框架[6]。
在发现消费者犹豫不定行为的原因之后,研究者在第三阶段试着去研究减轻决策制定困难的方法。不同个体之间犹豫不定的程度有很大差别。对于同一个个体来说,在不同时间和地点,犹豫不定的程度相对稳定,在没有特殊的训练和干预下,很难使一个优柔寡断的人变得果断。改变决策行为是一个更为现实的尝试。沿着这个思路,改进推荐系统对缓解信息过载的情况有很大帮助,比如改变商品分类或者提供推荐标记(比如“销量最高”)。如果推荐的商品依然十分相似,提升商品潜在特征的多样化能减轻决策的苦难。再充分、理性的决策的制定也是基于优先情绪加工的,改变决策制定者的决策行为十分困难。
除了不明确性之外,消费者在消费过程中仍然表现出几种类型的心理特征。比如,对新颖事物的寻找、兴趣的扩张以及一些偶然下的发现,这些都会给消费者带来兴奋和满足感。不断加深对这些个体行为的理解,不仅对科学研究意义重大,而且对商业的成功也十分重要。比如,引导消费者行为和提供更加准确的个性化推荐。近年来随着信息技术的快速发展,越来越多的消费者数据能被收集到,进行更加深度的研究也变得越来越容易。
二、不明确性挖掘
提出基于消费者行为的日志数据,挖掘消费者行为中的不明确性。首先,理清消费者行为记录的一般格式。其次,介绍量化所观测的不明确性的方式。然后,提出得到潜在不明确性指数的模型方法。最后,分析其潜在的应用。
(一)数据的预处理
我们的目标在于基于消费者在线消费行为记录自动地习得消费者和各商品之间的不明确性指数。消费者在线消费行为记录格式例子如表1所示。消费者所有对商品的操作,包括购买操作以及在作决定过程中涉及(比如点击、收藏、加入购物车等)的都被记录在内。对这些数据进行预处理,将单个消费者对商品的操作分为不同小节,比如将在1个小时内没有操作的部分分割为单独的小节。表2列出一些操作小节的例子,其中的“商品束”的定义如下:
定义1:商品束。给定一个消费者和他的操作小节,其操作小节对应的商品组合由操作小节里所有商品的子集构成。即一个操作小节通常有多个商品组合,比如,在表2小节,其商品操作顺序为 {a,b,c, a },对应的商品束为
由于空间限制,表2不同小节只给出最大的商品束。因此,商品束越大,表示消费者在这一小节浏览过的商品数量越多。如果某几个商品常常出现在不同的操作小节里面,那么这些商品会组成频繁商品束,这些频繁商品束可以由频繁模式挖掘算法得到。通常来说,在一个频繁商品束里的商品要么为竞争关系,要么为互补关系。事实上,商品之间的互补关系在市场营销领域有大量的研究。比如,在亚马逊上,那些经常被一起购买的商品会被一起推荐给消费者。在消费者操作小节中的商品更有可能是竞争关系,问题是如何量化这些商品之间的竞争关系。从表2我们可以看到,消费者U1在选择C1类的商品时有很强的不明确性,而消费者U2在做决定时更为果断。不失一般性,我们只考虑每个操作小节中同一分类的商品,并不对消费者操作作不同类型的区分,即将点击和收藏都视为用户操作,不作进一步的区分。表3为论文中所涉及到的符号注释。
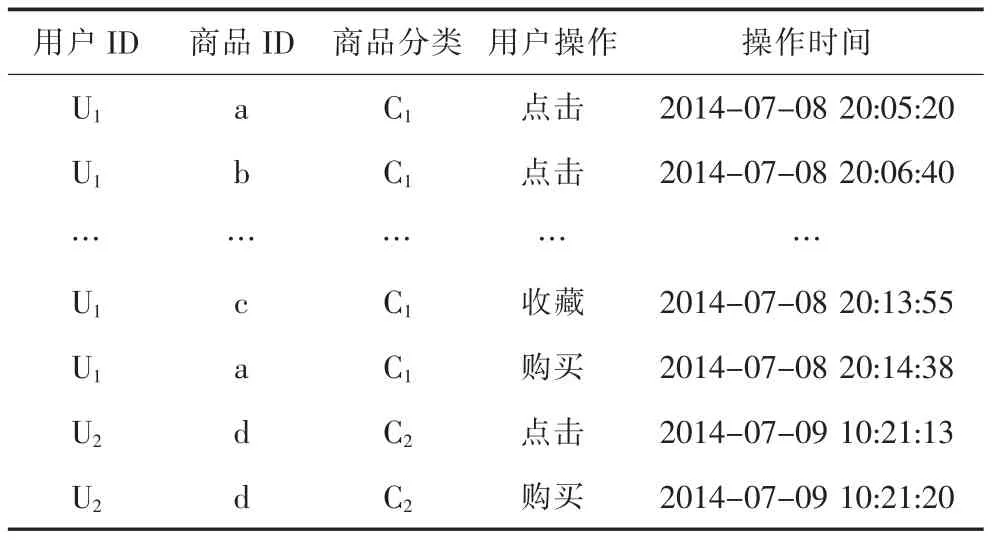
表1 消费者在线消费行为记录格式示例

表2 消费者操作小节示例

表3 符号注释
(二)不明确性的量化
本小节给出对用户操作小节不明确性指数量化的正式定义。
根据心理学中的定义,“犹豫不定”意味着花费更长时间作出决策以及搜寻更多的相关信息。基于现有对“犹豫不定”的理解以及现有可获得的在线消费者行为数据,我们主要基于下面4个假设关注每个行为小节中的4个特征值。
(1)在一个行为小节中,用户对商品的操作次数越多,相应的不明确性指数越高。
(2)对不同商品的操作次数分布越均匀,不明确性指数越高。
(3)在不同商品之间操作的转变越多,即用户重复考虑得越多,不明确性指数也越高。
(4)在每个商品上面所花的时间越均匀,即花费在每个商品上的时间越多,不明确性指数越高。花费在每个商品的时间为从此次操作到下次操作的时间间隔的总和。
基于以上假设,我可以定量化每个行为小节的不明确性为其特征值的函数,具体如下。
定义2:定量化的选择不明确性。给定一个消费者U1和这个消费者的一个操作行为小节Sj,相应的商品束为Bk。我们将每个小节中的“犹豫不定”程度定量化为:
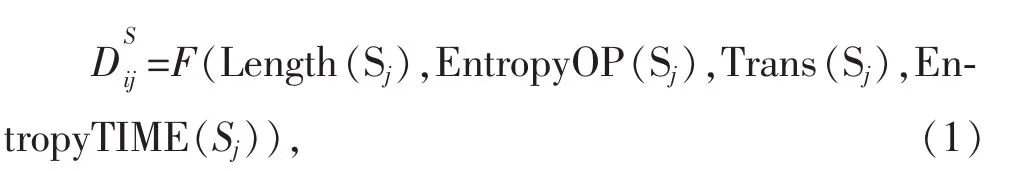
式中:F(·)可以是任何函数;Length(Sj)表示 Sj中操作次 数 的 对 数 即 Log(操 作 次 数 );EntropyOP(Sj)为用来衡量对不同商品操作次数的分布,其中Pj(a)表示商品a在Sj小节中出现的概率;Trans(Sj)表示转移操作在不同商品之间的次数除以总的转移操作次数;EntropyTIME(Sj)为用来衡量对不同商品操作时间的分布,其中Ptj(a)表示花在商品a的时间的比例。 比如,表 2 中 S1的 Length(Sj),EntropyOP(Sj),Trans(Sj)分别为 lg(10),(-0.4*lg(0.4)-0.6*lg(0.6))/lg(2),5/9。 假设 EntropyTIME(Sj)中 Ptj(a)和 Ptj(b)为0.2 和 0.8,则对应值为-0.2*lg(0.2)-0.8*lg(0.8)。
如果 F(Length(Sj),EntropyOP(Sj),Trans(Sj),EntropyTIME(Sj))表示四者的相乘即 Length(Sj)*EntropyOP(Sj)*Trans(Sj)*EntropyTIME(Sj),则 S1不明确性指数大约为0.035 3。为了平衡以上4种特征值的权重,我们在使用各项特征值之前可以规范化使得它们的值在[0,1]之内。以这种方式,只要消费者作出决策的过程被记录下来,我们就可以定量化消费者“犹豫不定”的程度,即本文中不明确性指数越高则表示“犹豫不定”的程度越高。据以上定义,不明确性指数值域可能会较大,我们可以使用最小—最大规范化使其值在[0,1]之内。
(三)不明确性挖掘
我们通过一个概率图模型来同时获得消费者和商品间的不明确性指数。
首先,很有必要弄明白每个行为小节中所观测到的不明确性背后的原因。在本次研究中,主要考虑2种观测不到的原因:消费者因素和商品因素。笔者使用“不明确性指数”来表示这些因素。即,不明确性指数越高的消费者(即难以作出决策的性格)在其操作小节所观测到的“犹豫不定”程度越高,不明确性指数越高的商品束(即有些商品本身很难选择,比如三星手机和苹果手机)也同样对导致观测到的“犹豫不定”的程度越高。
本次研究中,我们使用Yi和来分别表示消费者Ui和操作小节Sj的不明确性指数。其中操作小节Sj的不明确性指数由Sj中的商品束决定。Sj中的商品束为比如,表2中S4对应的商品束为换句话说,在商品a,b,c中作出选择或者对他们的对比导致我们在操作小节中所观测到的“犹豫不定”的程度。 因此,Sj的不明确性指数取决于 SB(j)中所有商品束的不明确性指数。即:

于是,对于所观测到的所有操作小节的不明确性指数DS的条件概率为:
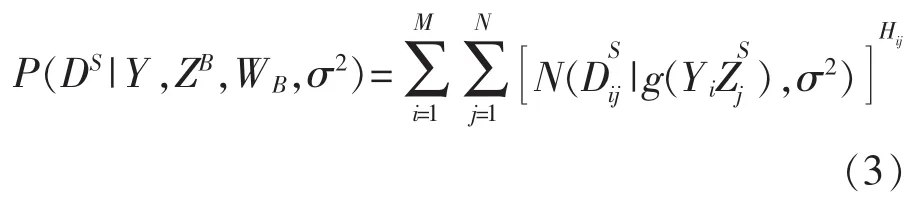
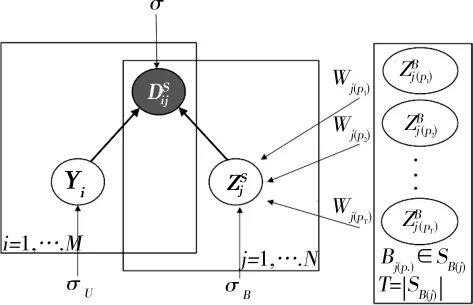
图1 不明确性指数的概率图模型
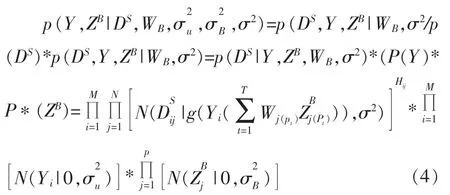
最大化上述概率,可以通过已有的所观测到的DS来估计出Y和ZB。为了方便计算对后验概率取对数:

由于后验概率中的方差都是预设好的常数,所以每1项中只有第2项与待优化的Y和ZB有关,所以最大化上述对数后验概率,等价于最小化如下函数:
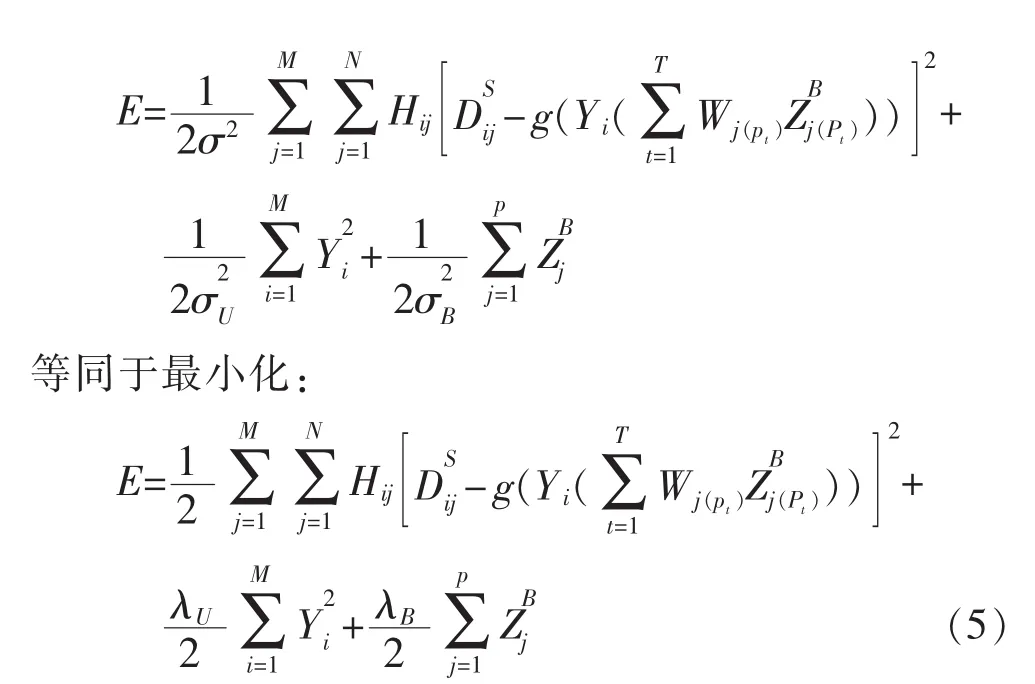
我们把对不明确性学习的概率矩阵分解模型称为IPMF模型。的确,作为概率图模型的1种[7],我们的模型和以往的有些模型很相似,比如RSTE模型[8]、IMF 模型和 SocialMF 模型[9]。 然而,IPMF 模型仍然和传统的一些模型不同。比如,在IPMF模型中,有3种潜在因素,其中每个小节的影响因素Bj(pt)是由其内在小部分决定的;而RSTE模型和SocialMF模型都只有2种潜在因素。这意味着其中内在的推论过程有很大的不同,并且本模型更加适用于不同的背景和领域。
最后,为了更好地解释,我们故意简化了模型,比如,把不明确性指数只作为标量。事实上,不明确性指数可以作为1个向量,其中每1个实数可以作为消费者对商品的其中1个方面的不明确性指数,比如对价格方面的不明确性指数。并且,我们目前只针对2个商品以上的商品束,但我们的模型同样适用于单一商品的商品束。
三、潜在应用
不明确性挖掘可以有很多潜在的应用,比如对于消费者“犹豫不定”的分析有助于更好地理解消费者的喜好。由于消费者的很多特征无法获得,比如年纪和性别,我们主要针对2种应用,即竞争商品性的检测和商品束的推荐。
(一)竞争性商品的检测
在现有的营销策略中,为了得到更好的销售量,那些经常被一起购买的商品会被推荐给消费者。然而,在本次研究中,消费者同一行为小节中一起出现的商品更可能是竞争性的。换句话说,本次研究所呈现的对不明确性的挖掘能为网络零售商提供一种检测竞争性商品的方法。详细来说,我们可以运用IPMF模型来获得频繁商品束以及这些商品束的不明确性指数。假设商品a是某零售商提供的一种商品,那么那些和商品a在同一商品束里的商品就能被定义为商品a的竞争性商品,尤其是哪些有非常大的不明确性指数的商品。这样就能以数据驱动的方式来获得竞争性商品的信息,其结果能帮助零售商更好地完善自己的商品和制定营销策略。
(二)商品个性化推荐
推荐系统的目标在于在任何时候和任何地方准确地把商品推荐给需要它的消费者。然而,当消费者已经受到“犹豫不定”困扰的时候,传统的推荐算法看起来很难起到作用。首先,如果推荐的商品类似于消费者正在浏览的商品,会使得消费者更难作出购买决策。其次,如果推荐的商品和当前浏览的商品无关,没有任何类似,消费者将毫无兴趣,因为此推荐已经超出她当前所关心的内容[10]。
尽管如此,当消费者在“犹豫不定”的时候依然需要推荐服务。假设消费者目前正在浏览商品如果我们能预测其最终的购买决策会在商品束} 中,即要么买a要么买b,那么我们就可以只推荐a,b给此消费者,以此来减少消费者所做的无用操作。从消费者的视角来说,他们会有更多的精力来作出最终的购买决策。从推荐服务提供者的视角来看,他们可以引导消费者作出对的选择,即通过提供选择过滤来减轻消费者“犹豫不定”的程度使得消费者会有更高的概率作出最终的购买决策,服务提供者可因此获得更高的利润。然而,传统推荐算法并不能完成以上分析的任务。为此,本次研究提出一个鼓励消费者消费的商品推荐概念,即当消费者在某几个商品“犹豫不定”时,我们把消费者最可能购买的商品推荐给她。对于消费者Ui的其中一个行为小节 Sj,其所要推荐的商品束为 SB(j),而这些商品束的商品数量通常比行为小节中商品数量少得多,也因此能减少消费者的选择成本,以此来使得消费者更容易作出购买决策。
基于以下假设,我们来解释基于不明确性挖掘的商品推荐。
对于某一消费者的一个行为小节,此行为小节由几个商品束组成,商品束的不明确性指数越高,消费者最终购买的商品出现在这个商品束里面的概率越大。
换言之,消费者的购买概率和不明确性指数的值有正相关关系。例如,行为小节中有商品{a,b,c,d } ,其中频繁商品束为其不明确性指数分别为0.8、0.2、0.6和0.3,则其消费大概率在{a,b,c } 中,则我们可以把d去除而把a,b,c推荐,来缓解消费者的“犹豫不定”。
四、总结与分析
本次研究给出消费者行为中选择不明确性的定量化方式。基于这些所观测到的定量化的不明确性,我们提出一种模型同时习得潜在的消费者的不明确性指数和商品组合中不明确性指数。由这些所得到的不明确性指数,我们分析这类消费者行为中的选择不明确性挖掘在很多方面有潜在的应用价值,比如竞争性商品的检测、个性化商品推荐。本次研究相比以往模型在消费行为中选择不明确新的定量化方式上有所改进,使得量化后的不明确性指数和实际情况更加匹配。不明确性挖掘可以应用于为零售商发现并提供竞争商品的信息,以及预测消费者的购买决策,为消费者提供给更好的推荐服务。
[1]王升升,赵海燕,陈庆奎,曹健.基于社交标签和社交信任的概率矩阵分解推荐算法[J].小型微型计算机系统,2016(5).
[2]曹佳丹,邵琰芳,李飞巧.犹豫不决者在决策中的风险偏好[J].现代商业,2010(27).
[3]RASSIN E,MURIS P.Indecisiveness and the interpretation of ambiguous situations[J].Personality and individual differences, 2005(7).
[4]刘维湘,郑南宁,游屈波.非负矩阵分解及其在模式识别中的应用[J].科学通报,2006(3).
[5]RASSIN E,MURIS P.To be or not to be indecisive:Gender differences, correlations with obsessive compulsive complaints,and behavioural manifestation[J].Personality and individual differences, 2005(5).
[6]DHAR R,GORLIN M.A dual-system framework to understand preference construction processes in choice[J].Journal of consumer psychology, 2013(4).
[7]程强,陈峰,董建武,徐文立.概率图模型中的变分近似推理方法[J].自动化学报,2012(11).
[8]MA H,KING I, LYU M R.Learning to recommend with social trust ensemble[C].Athens:Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval,2009.
[9]JAMALI M,ESTER M.A matrix factorization technique with trust propagation for recommendation in social networks[C].Athens:Proceedings of the fourth ACM conference on recommender systems,2010.
[10]孙光福,吴乐,刘淇,朱琛,陈恩红.基于时序行为的协同过滤推荐算法[J].软件学报,2013(11).
(编辑:唐龙)
F064.1
:A
:1673-1999(2017)06-0039-05
韩民琦(1993—),男,安徽财经大学管理科学与工程学院2015级在读硕士研究生,研究方向为数据库系统与数据处理。
2017-03-20
2016年安徽财经大学研究生科研创新基金项目“用户消费行为中选择不明确性分析——以天猫数据为例”(ACYC2016163)。
猜你喜欢
——以羌族舞歌《叶忍》为例
戏剧之家(2021年17期)2021-06-18
作文大王·笑话大王(2021年2期)2021-02-21
——《幽默曲》赏析
黄河之声(2019年15期)2019-12-17
刑法论丛(2018年3期)2018-10-10
消费导刊(2018年10期)2018-08-20
现代园艺(2018年3期)2018-02-10
北方音乐(2018年23期)2018-01-24
考试周刊(2016年39期)2016-06-12
中国市场(2016年44期)2016-05-17
现代企业(2015年4期)2015-02-28
