
自然场景图像中的文字检测综述
2016-12-23 11:18杨飞
电子设计工程 2016年24期
杨 飞
(1.中国科学院上海微系统与信息技术研究所 上海200050;2.上海科技大学 信息科学与技术学院,上海201210;3.中国科学院大学 北京 100049)
自然场景图像中的文字检测综述
杨 飞1,2,3
(1.中国科学院上海微系统与信息技术研究所 上海200050;2.上海科技大学 信息科学与技术学院,上海201210;3.中国科学院大学 北京 100049)
近年来自然场景图像中的文字检测与识别越来越得到人们的关注,主要是因为图像中的文字检测与识别对于理解图片内容、建立图像索引具有重要的意义。本文针对图像文字检测与识别这一领域的核心的问题即文字检测与定位,首先通过介绍了图像中的文字检测的基本概念,然后通过介绍和对比各种图像文字检测的方法的优缺点,我们可以得出这样一个结论即结合深度学习方法和大数据来进行自然场景图像文字检测与识别已经成为一个趋势和热点,文章最后总结了该领域的挑战和最新的发展趋势。
自然场景文字检测;文字识别;深度学习方法
自上世纪90年代,复杂彩色图像中的文本定位课题被提出以来,由于具有巨大的经济效益,该课题已经成为计算机视觉领域和文档分析领域的一个热点,吸引了众多的研究人员持续进行研究。比如从2003年开始,每两年举办一次的国际范围内的鲁棒性阅读竞赛[1],每次比赛国内外都有许多学者及研究人员参与。近年来随着数字多媒体技术的发展,移动互联的发展,数码相机以及智能手机的普及,抓拍的非文档图片越来越多,怎么样才能使得图像、视频检索更加方便、快速,成为了亟待解决的一个课题。其中的一个解决方案就是基于图像语义理解图片内容以及建立索引,从而更利于我们理解图片的内容、使得我们对图像、视频的检索更加方便、高效。正因为文字检测、识别的这个优势,催生了文字检测、识别在诸多行业的应用,如智能手机实时拍照翻译软件、智能交通系统的车牌识别、视频检索系统、结合穿戴式的计算机视觉识别系统、工业自动化以及机器人视觉等。
场景图像中的文字识别不同于文档图像中的文字识别,文本文档一般是白底黑字,背景颜色单一,因而文本文档的识别率早已达到实用的要求,比如常见的OCR应用。而复杂的图像尤其自然场景图像文字检测存在许多的新挑战,比如光照变化、分别率不同、复杂的背景、字体大小不同、文字的位置的变化等[2],这些因素给场景文字的检测、识别造成了很大的干扰,往往检测、识别的准确率不够高,难以达到工业应用的要求。
图片中的文字信息提取的第一步骤是文字检测,而检测的效果直接决定后面的识别结果的好坏,正因为此原因,文字检测显得尤其的重要。如前文所提到的场景图片文字检测、识别存在各种各样的挑战,为了解决这些问题,研究人员已经提出了许多的方法,文章将主要介绍、分析、对比各种文字检测的方法。
1 概 述
1.1 场景文字检测概念
场景文字检测主要是指从图像中提取图片所包含的文字,这些文字本身是图像内容的一部分。场景图像文字检测,首先需要根据文字所具有的特征去确定图像中的文字区域,当然会因为干扰因素的存在错把一些非文字区域判为文字区域,这需要根据一些规则或者候选区域的统计特性等来予以排除非文本区域,从而能准确定位图片中的文本区域。然后还需要对多行文本进行分割,也需要对同一文本行进行字符分割,拆分成一个个单词。

图1 自然图像文字检测
1.2 场景文字检测方法
自文复杂的彩色图像中的文字检测被首次提出来后,在过去的20年,有许多的文字检测和识别的方法被提出来。专门针对场景文字检测的工作也有许多,尤其近5年来场景图片文字的研究颇多,如其中的部分文献[3-5]都是专门研究场景图片文字检测的。一般来说这些不同的方法可以分为基于边缘特征、基于连通区域、基于纹理特征、基于机器学习、深度学习的方法这四大类,也有文献将这些方法归纳为三类方法即基于连通域、基于纹理和综合方法[6]。基于边缘的方法主要利用了文字有丰富的边缘信息这一特征,一般来说文字具有边缘密度大、文字和背景具有较高的对比度的特点。该类方法常用Canny算子、Sobel算子[7]在来进行边缘检测。基于连通域的方法主要利用文本区域的颜色和背景区域具有强的对比性这一特点,从而将文本区域和背景区域分割开来。基于纹理的方法将文本看成一种特殊的纹理,比如局部像素强度信息、小波变换系数等,利用这些纹理特性将文本区域和背景区域区分开来。如前文提到的场景图片文字检测存在光照、字体颜色和大小、多语言等干扰,这些干扰因素也没有什么规律可循,因此利用机器学习方法来解决这个复杂问题取得了不错的效果,常用的有SVM、卷积神经网络[8]、Adaboost等方法。除了利用上述的单一方法,也有像文献[4]的作者一样综合利用多种方法来进行文字检测和识别的,文献[4]主要利用连通域和纹理特征中的HOG特征来做文字检测。
2 常见的文字检测方法
2.1 基于边缘的文字检测
边缘特征是在文字检测中常用的一种特征,主要是根据文字的边缘信息来区分文本与非文本,这一类方法也是比较早就被学者们提出了。Zhang等[9]在研究从场景文字检测的时候,基于他们的观察——文字区域都是封闭的、文字的边缘都是成对出现,然后在这两个现象上基于边缘的特性计算候选字符区域的能量,然后再利用计算出来的能量的不同来排除非文本。作者假设每个文本包含至少两个字符,然后根据相邻区域的空间关系以及区域的颜色、高度、宽度等信息的相似度求得能量链接,最后也是根据颜色信息、像素强度、尺寸等信息将候选区域连接成文本。印度学者Shivakumara等[10]提出的检测文字的方法比较简单,首先是对输入图像做拉普拉斯变换,然后在大小为3*3的滑动窗内求得最大值与最小值的差作为窗口中心位置的像素值,这样得到和原图同尺寸的MGD图,然后对MGD用k-means方法聚类,均值大的区域认为是文本候选区,最后在利用水平和竖直方向投影,确定文字区域的精确位置,最后利用候选区域的宽度、高度、宽高比、边缘密度等信息排除非文本区域。
基于边缘方法的有点是原理简单易于实现,同时计算速度快,缺点是当背景复杂,边缘检测不到的时候,该类方法就会失效。
2.2 基于连通域的文字检测
基于连通域的方法首先是通过颜色或者区域极值等属性聚类,得到连通域,如最近非常流行的MSER方法,然后再根据人为设置的规则或者机器学习方法学习到的特征来排除非文本区域。文献[3]基于字符的笔画宽度近似常量这么一个假设,设计了SWT特征。作者认为字符的边缘是成对出现的,先是利用Canny算子对灰度图做边缘检测得到一个边缘图,然后从每一个边缘点p沿梯度方向出发,如果达到一个边缘点q,若p和q点的梯度方向近似地在同一直线上,那么p和q之间的距离|p-q|作为这两点之间的笔画宽度,然后将距离|p-q|赋值给线段pq上的每一个像素点,直到它有更小的值则选择更小的值作为当前点的笔画宽度。若没有找到q点,则从p出发的射线被丢掉。在找出所有线段后,再从找出的这些线段上的边缘点出发,选择线段上的中位值作为改线段上的每一个点的像素值,直到线段的上的每一个点都有更小的值为止,得到一个SWT图。最后再利用SWT图中的相邻像素的比值不超过3这一规则构造连通域,然后要求每个连通域的方差的值比较小,以及宽度和高度、高宽比等信息来排除非文本区域。Shi等[11]利用极值稳定区域(MSER)方法,找到原图中MSERs,然后为MSERs区域设计一些特征,利用Graph模型去区分文本和非文本区域。
基于连通域方法的优点是提取出来的连通域的数目相对较少,方法比较有效,同时具有尺度不变性、对文字大小不敏感等优点,因为该类方法成为了一个主流的方法,尤其近年来SWT,MSER方法非常普遍,也有许多文献是基于这两种方法的,比如文献[5]就是对SWT的改进,使得该方法能检测任意方向的文字。缺点是这一类方法需要得到好的连通域,而自然场景图中文本和非文本往往很难根据颜色、亮度等信息区分开,从而导致该方法在有复杂背景的自然场景图像中有时表现不太好。
2.3 基于纹理的文字检测
基于纹理的方法将字符看成一类特殊的纹理,然后根据局部的强度信息、Gabor变换、小波变换以及傅里叶变换等来检测文本的纹理,然后根据检测到的纹理的特性来区分文本和非文本。可以利用水平空间的方差信息来对文本进行定位,首先对整个图像做一个边缘检测,常用Canny算子做边缘检测,然后对每一行计算空间方差,方差比较大的为候选文本行,方差小的为非文本行,在得到文本候选区域后,再利用颜色信息来排除非文本区域。主要根据候选区域的局部极值来构建连通域,根据连通域内文本的像素比较接近,从而排除非文本区域。Kim等[12]直接利用原图的像素的值作为SVM分类器的输入,根据有标签的训练数据来学特征,区分文本与非文本,得到的候选区域再用自适应的meanSIFT算法进行连通域纹理分析,最后得到文本区域。
基于纹理的方法的有点在于对字体、大小有比较好的鲁棒性,但是计算复杂度高,耗时长,尤其很多结合机器学习算法如SVM,Adaboost等,需要大量的有标签的训练数据来训练分类器,制作这些有标签的数据成本高。
2.4 基于机器学习的文字检测
自然场景图像最大的一个特点就是背景复杂,文字的位置、颜色、大小等没有规律地变化,有时还是多语言的,这些因素使得自然场景图片中的文字检测非常麻烦,而机器学习算法在解决自然场景图片的文字检测常常有不错的结果,这也是最近几年为什么机器学习尤其深度学习在场景图片文字检测应用中越来越行得原因。文献[12]采用SVM来训练分类器,得到文本候选区域。Kung等[13]也使用了SVM,只不过文章中没有像其他的研究人员使用传统的特征比如边缘、脚点、纹理等,而是提取了新的特征。首先利用一种用于检测文本的笔画滤波器排除了干扰强的非文本区域,然后还利用了形态学操作。然后文章中设计了两种特征即归一化后的灰度和常量梯度,把这两种特征作为SVM的输入来训练分类器,筛选出候选文本区域,最后为了增强效果还做了文本增强的处理。Huang等[14]在2014年的研究中,先利用MSER检测到文字候选区域,然后利用卷积神经网络(CNN)来做分类器,从而区分开文本和非文本区域,MSER和CNN结合取得了比之前其他研究人员更好好的结果。
3 公开数据集
随着文字检测这个领域的研究不断进展,有越来越多的公开数据集可供研究人员用来检验他们自己所提出的方法的性能。最常见的数据集有国际文档分析识别大赛的ICDAR03,ICDAR05,ICDAR11,ICDAR13,最具难度的IIIT 5K-Word以及微软的MSRA-TD500等。这些数据的特点如表1所示。

表1 常用数据集
4 评 估
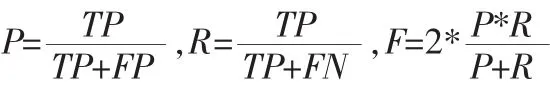
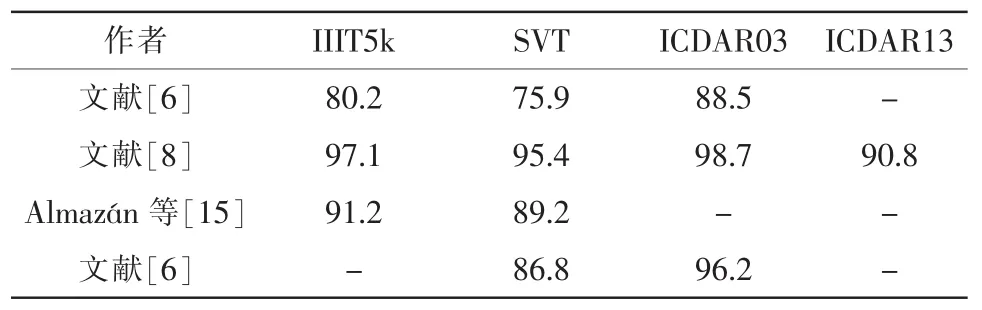
表2 不同算法在场景文字中的检测识别准确率(%)
从表2中的数据我们可以看到,准确率已经从5年前的文献[6]中的75.7%增长到2014年的文献[8]中的90%以上。通过阅读文献,我们发现在文献[8]中利用了深度学习和大数据的方法,从而大大提高了准确率。同时从最近5年发表的论文来看,借助深度学习、大数据等方法的论文越来越多。
5 研究趋势
从前文的论述我们可以知道,场景文字检测和识别是一个非常热的研究领域。尽管由于自然图片背景复杂多变,给场景文字检测与识别带来了巨大的挑战。但是在近年来也取得了非常快速的发展,比如针对ICDAR2011这个数据集,检测结果的F指数从2011年的0.58增长到2014年的0.78,针对更有难度的数据集IIIT 5K-Word已经从2012年的0.555增长2014年的0.802[16]。场景文字检测虽然取得了大进步,但是仍然面临很多挑战。研究趋势和热点也正从单一的方法、单一方向的文字检测、单一语言文字的检测研究,转向如文献[5]等多方向或者任意方向的文字检测,这更具有实际应用价值,因为现实中,水平方向的文字只占很小的一部分,大多数情况下场图片中文字的方向是多方向的。现有的研究大多是针对英语这种语言研究的,但是现在研究不同语言的文字检测也正在变为一个趋势,如文献[5]中有汉字的检测,比如有涉及韩文等的检测。而实际应用中比如拍照翻译软件,需要的是多种语言的检测、识别。另外的一个大的研究趋势就是结合深度学习和大数据方法的端到端的文字检测、识别系统的研究[17],也更接近实际应用的要求,如文献[8]中就使用了深度学习和大数据的方法,取得了非常好的效果。
6 结束语
文字具有高层的语义信息,而语义信息能用于许多自动化的应用,因而具有非常大的经济价值,这导致关于自然场景图片中的文字检测与识别成为了研究热点。但是由于自然场景图片具有复杂的背景,这给文字检测识别带了非常大的干扰,为了解决这一难题,许多的研究人员不断提出新方法,从而不断改善了场景文字检测与识别的效果。文章总结了最近几年国内外同行在该领域的主要方法,同时对不同类别的方法进行了分析和对比,同时还展望了该领域未来的研究趋势即使用深度学习和大数据结合的方法,希望能对国内的该领域的学者了解国内外该领域的研究有所帮助。
[1]Ye Q,Doermann D.Text detection and recognition in imagery: A survey[J].2014.
[2]Chen X,Yang J,Zhang J,et al.Automatic detection and recognition of signs from natural scenes[J].Image Processing,IEEE Transactions on,2004,13(1):87-99.
[3]Epshtein B,Ofek E,Wexler Y.Detecting text in natural scenes with stroke width transform[C]//Computer Vision and PatternRecognition(CVPR),2010IEEEConferenceon.IEEE,2010:2963-2970.
[4]Pan Y F,Hou X,Liu C L.A hybrid approach to detect and localize texts in natural scene images[J].Image Processing,IEEE Transactions on,2011,20(3):800-813.
[5]Yao C,Bai X,Liu W,et al.Detecting texts of arbitrary orientations in natural images[C]//Computer Vision and Pattern Recognition(CVPR),2012 IEEE Conference on.IEEE,2012:1083-1090.
[6]Zhu Y,Yao C,Bai X.Scene text detection and recognition: Recent advances and future trends[J].Frontiers of Computer Science,2016,10(1):19-36.
[7]Sun Q,Lu Y.Text Detection from Natural Scene Images Using Scale Space Model[M]//Advances on Digital Television and Wireless Multimedia Communications.Springer Berlin Heidelberg,2012:156-161.
[8]Jaderberg M,Simonyan K,Vedaldi A,et al.Reading text in the wild with convolutional neural networks[J].International Journal of Computer Vision,2014:1-20.
[9]Zhang J,Kasturi R.Character energy and link energy-based text extraction in scene images[M]//Computer Vision-ACCV 2010.Springer Berlin Heidelberg,2011:308-320.
[10]Phan T Q,Shivakumara P,Tan C L.A Laplacian method for video text detection[C]//Document Analysis and Recognition,2009.ICDAR'09.10thInternationalConferenceon.IEEE,2009:66-70.
[11]Shi C,Wang C,Xiao B,et al.Scene text detection using graph model built upon maximally stable extremal regions[J].Pattern Recognition Letters,2013,34(2):107-116.
[12]Kim K I,Jung K,Kim J H.Texture-based approach for text detection in images using support vector machines and continuously adaptive mean shift algorithm[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,2003,25(12):1631-1639.
[13]Jung C,Liu Q,Kim J.A stroke filter and its application to text localization[J].Pattern Recognition Letters,2009,30(2):114-122.
[14]Huang W,Qiao Y,Tang X.Robust scene text detection with convolution neural network induced msertrees[M]//Computer Vision-ECCV 2014.Springer International Publishing,2014:497-511.
[15]Almazán J,Gordo A,Fornés A,et al.Word spotting and recognition with embedded attributes[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,2014,36(12): 2552-2566.
[16]张翔,徐洪平,安雪岩,等.液体火箭发动机稳态运行故障数据聚类分析研究[J].火箭推进,2015(2):118.
[17]张少博,王乃世,陈海峰,等.基于声压测量的阀门故障检测方法研究[J].火箭推进,2015(4):100.
Detecting text in natural scence images were reviewed
YANG Fei1,2,3
(1.Shanghai Institute of Microsystem and Information Technology,Chinese Academy of Sciences,Shanghai 200050,China;2.School of Information Science and Technology,ShanghaiTech University,Shanghai 201210,China;3.University of Chinese Academy of Sciences,Beijing 100049,China)
In recent years,natural image scene text detection has attracted more and more attention.Scene text detection is of significant value for comprehending content of image and retrieving image.To detect and locate text in image is the key problem in image text recognition.First,the paper introduces the basic concept of scene text detection and recognition.Then the paper analyzes,compares,and contrast different methods.So we can learn about the advantages and disadvantages of different methods.Naturally,we can conclude that the combination of deep learning and big data has become a trend for researchers because of the obvious of big data.At the end of the paper,it summarizes the challenge and trend in natural image scene text detection and recognition.
scene text recognition;natural scene text recognition;deep learning
TN911.73
A
1674-6236(2016)24-0165-04
2015-12-15 稿件编号:201512159
杨 飞(1988—),男,湖南邵阳人,硕士研究生。研究方向:图像视频中的文字检测识别、数据挖掘。
猜你喜欢
小天使·一年级语数英综合(2021年9期)2021-09-22
小雪花·小学生快乐作文(2020年6期)2020-10-13
软件(2020年3期)2020-04-20
文苑(2020年12期)2020-04-13
摄影之友(影像视觉)(2018年12期)2019-01-28
Coco薇(2017年8期)2017-08-03
通信产业报(2016年44期)2017-03-13
Coco薇(2015年5期)2016-03-29
互联网周刊(2009年13期)2009-07-29
雕塑(1999年2期)1999-06-28
