
网络数据库中隐蔽数据快速挖掘方法研究
2016-12-23 11:18许学添邹同浩
电子设计工程 2016年24期
许学添,邹同浩
(广东司法警官职业学院 信息管理系,广东 广州510520)
网络数据库中隐蔽数据快速挖掘方法研究
许学添,邹同浩
(广东司法警官职业学院 信息管理系,广东 广州510520)
在大型网络数据库构架中,包含有海量的图片、声音、文字等数据信息,由于数据之间的差异性较大以及扰动干扰,导致对待访问的目标数据的隐蔽性较强,对隐蔽数据的快速挖掘是实现网络数据库优化访问的基础。传统方法采用模糊C均值聚类算法进行数据挖掘,算法的抗干扰性不强,动态差异性数据的分类挖掘性能不高。提出一种基于数据时频分布特征点检测的网络数据库中隐蔽数据快速挖掘算法。构建网络数据的数据分布结构模型,进行数据时间序列分析和信号模型构建,对网络数据库中的大数据进行FCM聚类预处理,对聚类输出的数据进行时频分析和特征点检测,实现数据准确挖掘。仿真结果表明,采用该算法进行数据挖掘的准确度较高,快速收敛性较好,展示了较好的性能。
网络数据库;模糊C均值;数据挖掘;时频分析
随着现代网络技术的迅猛发展,大量的图片、声音、文字、音视频等数据信息通过网络数据库进行存储和调度,网络数据库犹如一个庞大的数据加工厂,在网络数据库中,各种信息量不但呈现爆炸式增长,而且各种信息之间相互穿插、包含,特征日趋模糊。网络数据库的构架越来越复杂,随着网络数据库容量的增大,信息处理速度的增加,对其管理难度不断增强。网络数据库中大量的信息数据彼此交叉干扰,目标数据在网络数据库中的隐蔽性较强,信噪比较低,对目标数据的挖掘难度较高,研究网络数据库的隐蔽挖掘算法在提高数据库的优化访问和调度能力方面具有重要意义。
大型网络数据库构架中,由于数据之间的差异性较大以及扰动干扰,导致对待访问的目标数据的隐蔽性较强,对隐蔽数据的快速挖掘是实现网络数据库优化访问的基础。传统方法中,网络数据库的数据挖掘方法主要有粒子群算法、支持向量机算法、模糊C均值算法、语义指向性特征提取算法等[1-3],通过对数据的信号模型构建和分类算法设计,结合特征提取实现数据挖掘,取得了一定的研究成果,其中文献[4]提出一种基于信息流减法聚类的大型Web数据库的语义信息挖掘算法,实现对大型网络数据库的数据索引和挖掘,提高数据库的访问性能,但是该算法需要在高维相空间中进行数据调度,导致计算成本较大,实时性不好。文献[5]提出基于语义本体模型和关联指向性特征提取的数据库信息挖掘算法,实现对低信噪比下的隐蔽数据信息挖掘,降低的误检率,但是该方法在受到冗余数据信息干扰下,容易陷入局部收敛。针对上述问题,文中提出一种基于数据时频分布特征点检测的网络数据库中隐蔽数据快速挖掘算法。构建网络数据的数据分布结构模型,进行数据时间序列分析和信号模型构建,对网络数据库中的大数据进行FCM聚类预处理,对聚类输出的数据进行时频分析和特征点检测,实现数据准确挖掘。最后通过仿真实验进行了性能测试,验证了文中算法在优化数据挖掘性能方面的优越性能,得出有效性结论。
1 网络数据库的数据存储模型分析及隐蔽数据时间序列分析
1.1 网络数据库的数据存储模型及数据挖掘算法的总体设计
为了实现对网络数据库中大数据的优化分类,提高网络数据库的访问和调度能力,需要进行隐蔽数据挖掘,首先分析网络数据库的数据存储模型,在大型网络数据库中,数据库的存储节点将大量的数据信息流分布到融合的空间结构中,通过云存储和Deep Web数据存储方式进行数据库的海量信息融合聚类和数据调度,实现数据库的优化访问[6-9]。假设网络数据库的数据存储模型为一个分布结点为G1=(Mα1,Mβ1,Y1),G2=(Mα2,Mβ2,Y2)的无向图模型,在给定的隐蔽性数据分布的权重指数下,ai的属性值为{c1,c2,…,ck)。数据库的访问接口的信息聚类中心满足G1⊆G2⇔Y1⊆Y2,令A={a1,a2,…,an}为数据包的置信度概念区间,网络数据库的查询向量集集成查询接口、隐蔽信息传输通道和特征提取模块以及查询信息的输出模块,构成网络数据库的分布式存储和传输机制,得到一个采用三元组形式构建的网络数据库的数据存储的本体模型为:
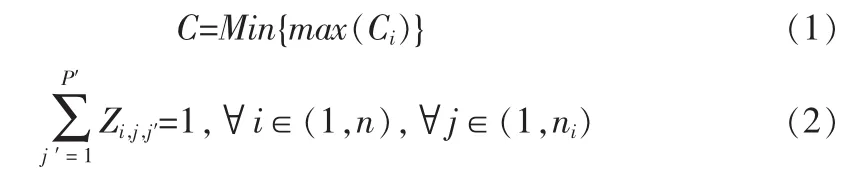
根据上述构建的网络数据库本体模型,构建数据库的Wigner-Ville分布空间,在Wigner-Ville分布空间中进行不同采样时间间隔上的特征信息流分析,现在把有限数据集合X分为c类,假设网络数据库中的隐蔽数据是一种多频微弱的宽带信号,网络数据库中的隐蔽数据的波束形成方向有M个方向集合,通过数据预处理和数据筛选,得到网络数据库的数据存储和调度模型如图1所示。

图1 网络数据库的数据存储和调度模型
在图1所示的网络数据库的数据存储和调度模型中,进行数据挖掘算法设计,数据挖掘中首先进行数据信息流的信号模型构建,进行数据分类和数据信息流的调制解调处理,对干扰数据进行抗干扰滤波,采用分类算法进行数据分类实现数据的准确挖掘,数据挖掘的实现过程总体描述如图2所示。

图2 网络数据库的隐蔽数据挖掘实现的总体结构框图
1.2 网络数据库中数据的信息流模型
在上述进行了网络数据库的数据存储和调度模型设计的基础上,进行网络数据库的隐蔽数据的信息流模型构建,采用信号处理方法进行数据流的信息特征提取和数据挖掘,通过构建一个包含n个矢量属性集合进行数据库的隐蔽信息的语义状态信息,网络数据库的隐蔽数据为一个窄带宽平稳的随机过程,存储空间中的本中模块表示为一组复包络形式,可写作:
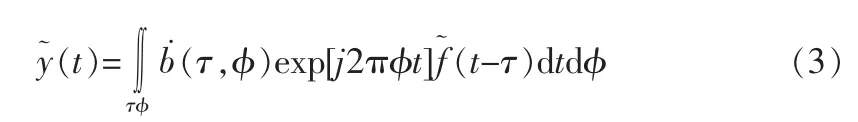
其中,b(τ,φ)是网络数据库中隐蔽数据的窄带信息流的干扰扩展函数,(t)为各频率分量的时变非平稳特征参量,τ为网络数据库中隐蔽数据的能量密度谱,选择特定的窗函数形式:

上式中,N(z)是网络数据库频谱图的频率分辨率,它的零点在处频域的分辨率下降,D(z)为尺度因子,ψ(t)由尺度参数经时间轴平移和伸缩得到数据的包络特征为:
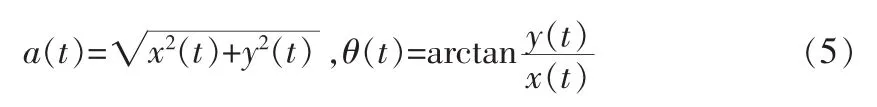
其中,θ(t)为时频分辨率的频移特性,可得网络数据库中隐蔽数据信息流的交叉项,在语义特征的本体模型中,数据库存储中的包络信息为一个标量时间序列为:

采用傅里叶变换对上述数据信息流进行信息融合,对待挖掘的数据信息流的傅里叶变换过程为:
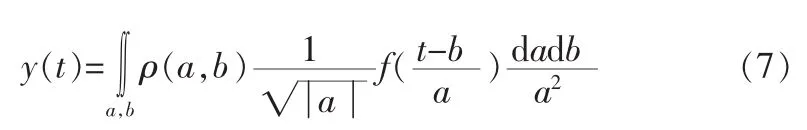
上式中,f(t)为网络数据库的非平稳态瞬时相位特征值,ρ(a,b)为时频联合分布,a为尺度参数,b为加窗的Fourier谱。隐蔽数据x(t)出现在加窗的Fourier谱中两次,并不包含任何窗函数,经过前馈调制滤波,得到网络数据库的边缘性状态函数表示为:
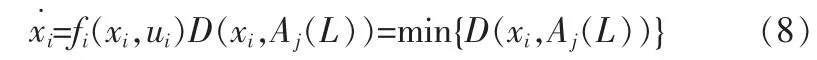
式中,xi∈Rn,代表网络数据库的锥形核分布状态矢量,ui∈Rm为一个锥形核分布输入矢量。在上述进行网络数据库中数据的信息流模型构建的基础上,采用非线性时间序列分析方法进行数据特征提取和数据挖掘。
2 算法改进设计与实现
2.1 网络数据库的数据信息聚类处理及特征提取
在上述进行了大型网络数据库构架和数据信息流的时间序列分析模型构建的基础上,进行网络数据库中的大数据信息聚类处理,实现数据的快速挖掘算法改进,传统方法采用模糊C均值聚类算法进行数据挖掘,算法的抗干扰性不强,动态差异性数据的分类挖掘性能不高。为了克服传统方法的弊端,文中提出一种基于数据时频分布特征点检测的网络数据库中隐蔽数据快速挖掘算法。对网络数据库中的大数据进行FCM聚类预处理,假设网络数据库中的大数据信息流的时频参量x(n)为网络数据库中的隐蔽数据预测的时间序列组合,〈x(n)〉代表对x(n)取均值:
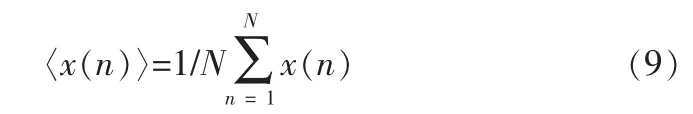
在上述进行了网络数据库中的隐蔽数据调度信息流时间序列重构的基础上,进行流量监测的频率响应配置,得到网络数据库中的隐蔽数据时间序列的特征向量幅值和自相关特征状态为:
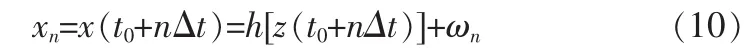
其中,M是d维的差异性时间窗口特征函数,计算网络数据库中的隐蔽数据时间序列的几何不变量,得到的该状态空间中网络数据库中隐蔽数据信息特征的干扰向量模型表达式为:

上式中,a(t)为网络数据库中的隐蔽数据的信息幅度,称为复信号z(t)的瞬时幅度。采用FCM算法进行聚类分析,构建网络数据库中的隐蔽数据预测相关函数,假设网络数据库中隐蔽数据的有限数据集:

在网络数据库的定量递归矢量空间集合中含有n个样本,其中样本xi,i=1,2,…,n的表示网络数据库隐蔽数据标量时序为:

结合模糊C均值聚类,现在把有限数据集合网络数据库特征空间X分为c类,其中1<c<n,定义数据流的相空间轨迹,得到模糊聚类中心矩阵为:

其中Vi为有限数据集聚类中心的第i个特征空间,(第i个聚类中心矢量)。采用自相关特征配准方法对数据信息的分布区间进行模糊划分,划分矩阵表示为:
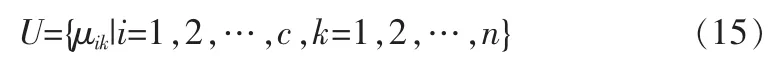
通过FCM聚类的定义,得到FCM聚类下网络数据库的大数据信息聚类的目标函数为(定义聚类目标函数):

式中,m为权重指数,(dik)2为干扰向量xk与Vi的相空间分布间隔距离,用欧式距离表示数据时频分布特征点为:

其中,数据时频分布特征点的分布有效性的置信空间为:

对上述网络数据库的数据信息聚类目标函数进行优化求解,采用数据时频分布特征点方法进行数据挖掘优化。
2.2 改进算法的实现步骤描述
根据上述算法描述,对聚类输出的数据进行时频分析和特征点检测,进行数据挖掘优化实现,实现过程描述为:
1)初始化。算法的初始化,首先进行时频控制参数的初始化,包括聚类输出迭代次数、相空间嵌入维数、信息融合区间、扰动范围大小等参数的初始化,通过初始化选出隐蔽数据挖掘和特征聚类的初始最优个体和全局最优个体;
2)网络数据库中的隐蔽数据的自相关序列按照时频检测进行差分进化(DE,differential evolution)实现隐蔽数据的亮点检测;
3)设定阈值ζ,计算网络数据库中的隐蔽数据的多样性因子mf,并结合定量递归分析进行阈值比较,若mf<ζ,则进行下一步(第4步),如果mf>ζ,进入(5)步;
4)把网络数据库中的隐蔽数据时间序列加入到扰动序列中。产生随机矩阵z,为c×D维的,其均衡调度控制分量都在(0,1)之间。根据于数据时频分布特征点的映射形式,得到NP个于数据时频分布特征点序列分量:

5)加入网络数据库中的隐蔽数据的扰动变量,得到优化数据挖掘输出分量:

6)如果G=Gmax,那么迭代停止并得到有限数据集下数据挖掘的适应度值,如果不是,则G=G+1继续迭代进入第2)。并对数据归一化处理过程为:

通过上述算法改进设计,实现数据快速挖掘,降低迭代步数。
3 仿真实验与结果分析
为了验证文中算法在实现网络数据库中隐蔽数据快速挖掘中的性能,进行仿真实验。验的硬件环境为:处理器Intel(R)Core(TM)2 Duo CPU 2.94 GHz,内存:8.00 GB。采用Matlab仿真软件,参数设定为Gmax=30,D=12,c=3,NP=30,F=0.5,CR= 0.1,m=2,网络数据库中的隐蔽数据的初始采样频率f1=2.1 Hz,终止频率f2=0.23 Hz,时频分布特征点检测权重系数ω设定为0.82,根据上述仿真环境和参数设定,进行网络数据库隐蔽数据挖掘仿真,首先进行数据的时间序列分析和原始数据采样,得到采集的原始数据点分布如图3所示。

图3 原始数据采样分布
对采样的数据进行数据FCM聚类处理,实现数据的时频分布特征点检测,得到检测结果如图4所示。

图4 数据的时频分布特征点检测
通过上述检测结果可见,采用文中方法进行隐蔽数据挖掘的聚焦性能较好,时频域的特征点分布明显,说明挖掘效能较高,为了定量分析文中方法的性能,采用文中方法和传统方法,以数据挖掘的速度为测试指标,得到仿真对比结果如图5所示,从图可见,采用文中方法进行数据挖掘的精度较高,速度较快,收敛性较好,展示了文中方法的优越性。
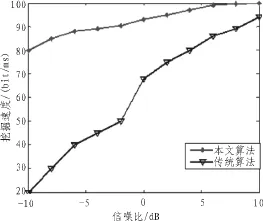
图5 数据挖掘性能对比
4 结束语
文中研究了网络数据库的隐蔽数据挖掘问题,提出一种基于数据时频分布特征点检测的网络数据库中隐蔽数据快速挖掘算法。构建网络数据的数据分布结构模型,进行数据时间序列分析和信号模型构建,对网络数据库中的大数据进行FCM聚类预处理,对聚类输出的数据进行时频分析和特征点检测,实现数据准确挖掘。仿真结果表明,采用该算法进行数据挖掘的准确度较高,快速收敛性较好,展示了较好的性能,具有较高的应用价值。
[1]陆兴华,陈平华.基于定量递归联合熵特征重构的缓冲区流量预测算法[J].计算机科学,2015,42(4):68-71.
[2]王小英,刘庆杰.关系型数据库中数值数据的密文检索模型研究[J].计算机仿真,2013,30(11):409-411.
[3]Chong F T,Heck M J R,Ranganathan P,et al.Data center energy efficiency:improving energy efficiency in data centers beyond technology scaling[J].IEEE Design&Test,2014,31(1):93-104.
[4]WANG Lin,ZHANG Fa,Arjona Aroca J,et al.GreenDCN: a general framework for achieving energy efficiency in data center networks[J].IEEE Journal on Selected Areas in Communications,2014,32(1):4-15.
[5]卫星,张建军,石雷,等.云计算数据中心服务器数量动态配置策略[J].电子与信息学报,2015,37(8):2007-2013.
[6]侯森,罗兴国,宋克.基于信息源聚类的最大熵加权信任分析算法[J].电子学报,2015,43(5):993-999.
[7]罗亮,吴文峻,张飞.面向云计算数据中心的能耗建模方法[J].软件学报,2014,25(7):1371-1387.
[8]章登义,吴文李,欧阳黜霏.基于语义度量的RDF图近似查询[J].电子学报,2015,43(7):1320-1328.
[9]魏利峰,纪建伟,王晓斌.云环境中web信息抓取技术的研究及应用[J].电子设计工程,2016,24(4):29-31.
[10]陈永峰.大数据背景下数据挖掘在高校固定资产统计中的应用研究[J].河北软件职业技术学院学报,2015,17(2):6-9.
[11]关阳,金力,朱李凡.数据挖掘中的数据预处理问题分析[J].数字技术与应用,2015(8):200.
[12]张跃,李葆青,胡玲芳,等.基于Web数据挖掘技术研究[J].电脑知识与技术,2015,11(9):106-115.
[13]宋志秋.大数据时代营销中的数据挖掘技术[J].数字技术与应用,2015(3):209-209.
[14]吴晓英,明均仁.基于数据挖掘的大数据管理模型研究[J].情报科学,2015,32(11):131-134.
[15]戴春娥,陈维斌,傅顺开,等.通过GPU加速数据挖掘的研究进展和实践[J].计算机工程与应用,2015,51(16):109-116.
[16]王祥瑞,韩成浩.一种基于云计算的数据挖掘平台架构设计与实现[J].数字技术与应用,2015(9):164.
Research on fast mining method of hidden data in network database
XU Xue-tian,ZOU Tong-hao
(Department of Information Administration Guandong Justice Police Vocational College,Guangzhou 510520,China)
In the framework of large network database,contains a mass of pictures,voice,text,etc.data information,because the difference between the data and disturbance,resulting in treat access the target data of strong concealment,the rapid excavation of hidden data is network database access optimization based.Traditional method uses the fuzzy C means clustering algorithm for data mining,the anti interference of the algorithm is not strong,the classification of dynamic differential data mining performance is not high.A fast data mining algorithm for hidden data in the network database based on the feature point detection of the data time frequency distribution is proposed.Data network data distribution structure model,time series analysis and data signal model is constructed and of FCM clustering preprocessing network database in the data and the output of the clustering of data frequency analysis and feature point detection,to achieve accurate data mining proposed.Simulation results show that the proposed algorithm is of high accuracy,fast convergence and good performance.
network database;fuzzy C means;data mining;time frequency analysis
TP391
A
1674-6236(2016)24-0015-04
2016-04-28 稿件编号:201604270
广东省前沿与关键技术创新项目(2014B010110004);广东省产学研合作项目(503036363071)
许学添(1984—),男,广东揭阳人,硕士研究生,讲师。研究方向:数据挖掘、生物信号处理。
猜你喜欢
大众投资指南(2021年35期)2021-02-16
军事运筹与系统工程(2020年1期)2020-09-11
铁道通信信号(2018年12期)2019-01-31
军事运筹与系统工程(2018年1期)2018-11-10
宇航计测技术(2018年3期)2018-09-08
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
军事运筹与系统工程(2015年3期)2015-09-08
舰船科学技术(2015年8期)2015-02-27
振动、测试与诊断(2014年6期)2014-03-01
