
结合用户生成内容与链接关系的社区发现算法*
2016-11-30 09:43张恩德高克宁
计算机与生活 2016年2期
张恩德,高克宁,张 昱,李 封
东北大学 计算中心,沈阳 110819
结合用户生成内容与链接关系的社区发现算法*
张恩德+,高克宁,张昱,李封
东北大学 计算中心,沈阳 110819
ZHANG Ende,GAO Kening,ZHANG Yu,et al.Community discovery algorithm based on combination of users generated contents and link relationships.Journal of Frontiers of Computer Science and Technology,2016,10 (2):194-200.
社区发现一直是社会网络研究中的热点内容。但是当前社区发现算法更加关注用户与用户之间的链接关系,而对社会网络中用户生成内容(user generated contents,UGC)大数据研究较少。用户生成内容是Web2.0的特点,也是社会网络平台吸引用户的重要原因之一,对社区的形成起着重要作用。提出了一种新的社区发现算法,能够综合利用用户与用户之间的链接关系以及用户生成内容来确定用户的社区划分。该算法用LDA(latent Dirichlet allocation)算法分析用户生成内容中主要的内容形式——文本信息,同时通过谱分析方法分析用户与用户之间的链接关系,并有机结合以发现网络的社区结构。通过分析科学网的真实数据,证明了所提算法能够有效综合利用用户生成内容与用户链接关系,使社区发现的结果更加客观准确。
社区发现;用户生成内容;用户链接关系;社会网络
1 引言
Web2.0的发展以及众多社会网络平台的出现,使用户体验到了网上社交的乐趣。在社会网络平台上,包括博客、微博、即时通讯、交友网络,人们通过这些平台提供的各种应用,通过好友互动、互粉、留言等活动,建立了各种各样的互动聚集现象,并形成了一个个“群集”(cluster),群集的建立有的是基于生活中的好友关系,有的是基于用户兴趣,这些群集无论对于商品推荐还是广告营销等,都有极强的研究意义。这些群集又被称为社区,对于这些群集的发现称为社区发现。
对于社区发现的研究,科研人员已经取得了丰硕的成果。但是,当前社区发现算法更关注于通过社会网络链接结构进行,即通过分析用户与用户之间的链接关系以发现社区结构。可是在实际场景中,社会网络的一个重要特点为用户生成内容,网络上的内容主要由用户生成,每一个用户都可以生成自己的内容,互联网上的所有内容由用户创造,用户加入到某个社区也主要是由社区内容所吸引。社区的形成和特定的目的有关,在不同的社区内部,人们关注不同的内容。例如,在一个博客平台中,某用户甲浏览了用户乙的博文,但是如果用户甲并不是用户乙的好友,用户甲也没有直接在用户乙的博文下面进行回复,而是有感而发写了一篇新的关于相同话题的博文,但是没有直接引用这篇博文。那么在网络结构上看,用户甲和用户乙并没有直接链接,他们很难归为一个社区中,但是如果考虑话题结构,他们应该在一个共同的话题社区内,如果在社区发现中加入关于社区话题的更多信息内容,可以让社区发现结果更加精确。本文提出了一种结合用户与用户之间的链接关系以及用户生成内容的算法进行用户社区发现,其中用户之间的链接关系可以为用户好友关系(如Facebook中的好友关系),用户关注与被关注关系(如Twitter中的follower-followee关系),用户生成内容为所有内容中的主要形式——文本内容。本文通过LDA(latent Dirichlet allocation)算法分析用户文本内容,并利用谱分析方法结合用户链接关系与用户生成内容进行社区发现。在真实数据集上的实验结果表明,本文方法能够有效利用用户链接关系与用户生成内容,社区发现的结果更加客观准确。
本文组织结构如下:第2章介绍相关的工作;第3章对本文算法进行详细讨论;第4章介绍实验结果;最后对本文工作进行总结。
2 相关工作
社区发现(community discovery),又称社区检测(community detection)、社区识别(community identification)、社区提取(community extraction)。社区发现研究主要分为两类:一类是非重叠社区发现,即一个节点只能属于一个社区;一类是重叠社区发现。对这两类,研究人员均进行了大量工作。针对非重叠社区发现,主要有基于模块度的优化算法、基于谱分析的方法、基于信息论的方法以及基于标签传播的方法。Newman在2004年提出了模块度的概念[1],模块度通过比较真实网络中各社团的边密度和随机网络图中对应子图的边密度之间的差异来度量社团结构的显著性。这一概念的提出引发了社区发现的一个热潮,陆续有研究人员通过优化模块度目标函数来进行社区发现。文献[2]指出模块度优化问题是一个NP难问题。文献[3]提出了CNM社区发现算法,该算法采用堆数据结构来计算和更新网络的模块度,大大提高了计算速度。文献[4]在社区发现迭代过程中引入多步扩展,优化了结果。基于谱分析方法主要的研究工作有文献[5-7],这些算法基于矩阵的谱性质进行社区发现。基于信息论的社区发现方法思想是将网络的模块化描述看作对网络拓扑的一种有损压缩,从而将社区发现问题转化为信息论中的一个问题,即寻找拓扑结构的有效压缩方式,这方面的研究有文献[8-10]。基于标签传播的社区发现方法[11-12]首先将每个节点指定唯一标号,然后每步迭代按照一定规则更新邻居标签,经过若干次迭代后将标签相同的归为同一社区。文献[13]在基于模块度函数的基础上,提出相关分析(correlation analysis)方法,对模块函数进行精巧的修改,能够提高这类方法的应用范围。文献[14]提出了一种热核方法(heat kernel)进行社区发现,该方法通过选取种子节点,使用图扩散方法来发现社区。文献[15]提出了一种能够消除不相关子图的稳健社区发现算法。重叠社区发现认为一个网络中一个节点可能属于不同的社区,相当于图的一个“软分割”。文献[16]可以看作是重叠社区发现的开山之作,它指出了社区有重叠这一现象,并提出了一种基于团渗流(clique percolation)的重叠社区发现算法。对于重叠社区发现的算法还很多,由于本文主要针对非重叠社区发现,这里不再进行介绍。文献[17]针对传统社会网络社区发现只通过节点邻接关系划分社区,使划分出的社区结构只代表一维关系结构,无法反映具有语义关联的语义社区结构问题,提出了FA-SA算法解决多元语义社会网络中的社区发现问题,并对语义社会网络分析进行了深入研究。
由上面的综述可见,虽然在社区发现方面已经有了丰硕的研究成果,科研人员也用不同的理论方法来解决社区发现问题,但是当前的研究还是以对社会网络图结构的分析为基础,没有充分利用社会网络中丰富的用户生成内容。
3 结合网络结构与文本内容的社区发现算法
本文充分利用社区网络中的大数据,包括用户之间的好友关系以及用户生成内容(用户发表文本内容信息),提出了一种结合网络结构与文本内容的社区发现算法。
3.1基于网络结构的社区发现
本节介绍基于网络结构的社区发现算法。网络结构是社区发现的基础,本文拟直接采取当前研究中比较成熟的基于结构的社区发现算法——谱分析社区发现算法[6]。谱分析又称谱聚类,首先将一个图结构转化为对应的拉普拉斯矩阵,给定社会网络图结构G,G的拉普拉斯矩阵的特征值中0特征值出现的次数等于图中不连通区域的个数。对于每一个非连通图,可以对每个连通子图建立拉普拉斯矩阵。事实上,在真实的社会网络结构中,不同社区几乎不可能完全不相连。如果图为连通图,拉普拉斯矩阵只有一个特征值为0。如果整个社会网络图结构由几个不连通的子图构成,那么G对应的拉普拉斯矩阵为0的特征值等于子图的个数。因此可以利用拉普拉斯矩阵的前几个最小的特征值进行聚类,聚类结果中的每一个簇(cluster)就相当于一个社区。算法1是标准谱聚类算法的一般步骤。
算法1基于网络结构信息社区发现算法
输入:社会网络图G=(V,E)。
输出:社会网络的k个聚类(社区)。
(1)根据社会网络图结构,构建拉普拉斯矩阵;
(2)计算拉普拉斯矩阵的特征值和特征向量;
(3)利用前k个特征值对应的特征向量来对社会网络进行聚类;
(4)返回社会网络的聚类结果(社区)。
3.2结合网络结构与文本内容的社区发现算法
3.1节介绍了基于结构进行社区发现可以通过用户节点与用户节点之间的链接关系发现网络的社区结构。但是结构信息只是部分地利用了社会网络上的数据。本文提出了综合利用结构信息与用户生成内容进行社区发现。这类的结构信息指用户与用户之间的链接关系,用户生成内容为用户发表文本信息。利用文本信息进行社区发现能够从话题层次上分析节点的属性,从而能在话题意义上发现社区结构,并且能有效识别出链接的“噪声”,能计算成员在各个话题中的“关系”结构。因此,本节提出了一种能够同时结合网络结构与用户话题的算法进行社会网络社区发现。
假设用户发表的内容以文档形式存在(如用户发表的一篇博客就相当于一个文档),利用LDA算法进行话题发现的思想[18],假设D个文档中存在T个话题,则对于文档集中的任一篇文档di,都可以看作是T个话题的多项式分布,而其中每个话题Tk又都可以看作是在文档中i个词汇上的多项式分布。即假设有T个话题,则所给文本中的第i个词汇wi可以表示如下:
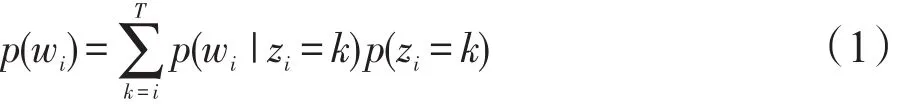
其中,zi是隐变量,表明第i个词(即为wi)取自该话题;p(wi|zi=k)是wi属于话题k的概率;p(zi=k)给出话题k属于当前文本的概率。假定T个话题形成D个文档,并以W个词表示,记表示对于话题k,W个词上的多项式分布,其中w是W个词汇表中的一个词;另表示对于文本d,T个话题上的多项式分布,那么文本d中词汇w的概率如式(2):

式(2)可以进一步表示为:

在计算得到各个文档的话题相关度后,假设每篇文档仅有一个作者用户(这个假设符合绝大部分的社会网络真实情况),因此,对该作者所发表的文档在话题空间上求和,即可得到该作者在话题空间上的潜在分布,即:

根据式(4),即可计算作者用户节点在话题空间上的概率分布,根据不同用户的p(z|u)进一步由式(5)计算不同用户之间在话题空间上的相关性:
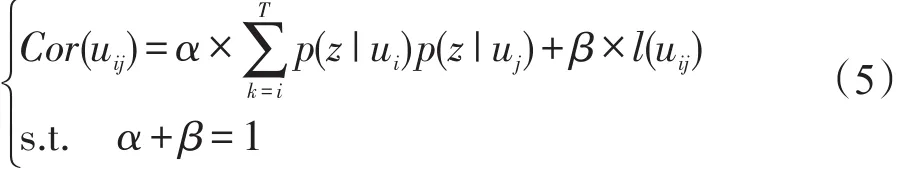
式(5)中,l(uij)表示用户ui与用户uj之间原有的链接关系。
根据用户与用户之间的相关性Cor(uij),可以得到带有权重的拉普拉斯矩阵,在此矩阵上使用谱方法进行社区发现,则同时利用了社会网络上的话题信息以及结构信息,能够更加准确地进行社区发现。因此,本文提出的综合利用网络结构与用户内容的社区发现算法如算法2所示。
算法2结合网络结构与话题信息社区发现算法
输入:社会网络图G=(V,E),用户发表文档集合D以及用户与文档之间的关系。
输出:社会网络的k个聚类(社区)。
(1)基于LDA话题发现方法及图结构信息,计算用户与用户之间的相关性Cor(uij);
(2)根据Cor(uij)信息构建拉普拉斯矩阵;
(3)计算拉普拉斯矩阵的特征值和特征向量;
(4)利用前k个特征值对应的特征向量来对社会网络进行聚类;
(5)返回社会网络的聚类结果(社区)。
4 实验分析
4.1数据描述
在真实数据集科学网博客(http://blog.sciencenet. cn/)上进行算法验证。实验数据来自于研究小组自己编写的爬虫程序所爬取的数据,包括网站上从2007年11月至2014年7月的部分博主信息及博客内容,博主信息包括用户ID、姓名、昵称、好友关系,在数据处理过程中,删除了从未发表博客内容的用户以及博客内容过短的博文。数据集包括用户发表博客内容,以及用户的好友关系。最后得到了3 529个用户以及23 152篇博文。算法通过分析该数据集得到其中的社区结构。在数据集中,科学网博客本身已经对博客用户进行了分类,将科学网博客对用户的分类认为是正确的社区发现结果。算法进行社区发现的准确率与该结果进行比较。按照科学网博客的分类标准,博客用户一共分为8个社区,这8个社区分别为:生命科学(简称life)、医学科学(简称medicine)、化学科学(简称chemistry)、工程材料(简称material)、信息科学(简称information)、地球科学(简称earth)、数理科学(简称mathematics)、管理综合(简称management)。
实验运行在IBM X3500上,机器配置为Xeon Quad双CPU,内存为16 GB,操作系统为64位Linux系统CentOS。程序使用R语言编写,中文分词使用RWordseg包,矩阵的特征值与特征向量计算使用ARPACK包,LDA计算使用吉布斯抽样方法。
4.2实验结果
实验比较了基于结构的社区发现以及基于结构和话题模型的社区发现算法的社区发现准确率。基于结构的算法即基于博客用户与博客用户之间的好友关系使用算法1进行社区发现,以下简称CD-ST(community discovery based on structure);基于结构和话题模型的社区发现算法即通过分析博客用户和博客用户之间的好友关系,以及博客用户发表博文内容,使用算法2进行社区发现,以下简称CD-TS(community discovery based on topic&structure)。因为科学网博客中已知社区结构,所以准确率的公式定义如下:
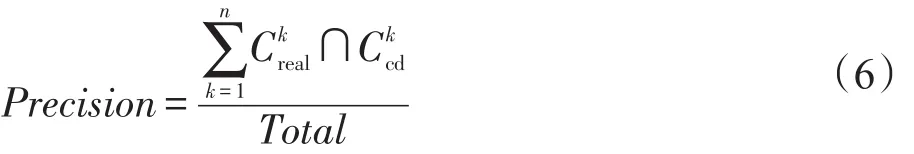
cd表示使用算法发现的博客用户集合;Total为全部用户。
实验比较两种社区发现算法的准确率变化,其中α为式(5)中的调节系数,α值表明在算法2中基于话题与基于结构对应算法结果的贡献程度。α越大,表明算法中话题对于社区发现所占的比重越大;α为0,表示只基于结构进行社区发现;α为1,表明只基于话题进行社区发现。
图1比较了两种算法的准确率,其中CD-ST是基于网络结构的社区发现算法,这里没有调节系数,因此该算法的准确率不随α的变化而变化。
在图1中,CD-TS表示基于话题和结构社区发现算法,可以看出,随着α值的增大,准确率并不一定随之增加。在α=0的时候,表示只基于网络结构进行社区发现,因此两种社区发现算法准确率相同。在α= 0.6的时候,社区发现的准确率最高,这是因为随着话题比重的增加,社区发现越来越依赖用户博客中的话题内容。而实际上,不同学科的博客用户可能讨论的话题有很多相近之处,比如很多博客用户都提到了研究生教育问题、科研经费申请问题、论文发表问题、当前教育体制弊端等共性问题,因此随着话题比重在社区发现算法中的增加,准确率不一定提高。同时也看到了在α=1.0的时候,CD-ST算法社区发现的准确率不如CD-TS。
图2记录了当α值变化时(α=0,α=0.6和α=1.0),各个社区发现结果的准确率。其中α=0相当于只基于结构进行社区发现,α=1.0相当于只基于话题进行社区发现。
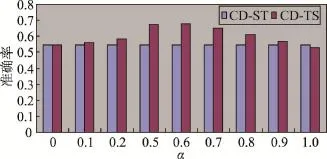
Fig.1 Precision of two algorithms on scientific network data set图1 两种算法在科学网数据集上的准确率
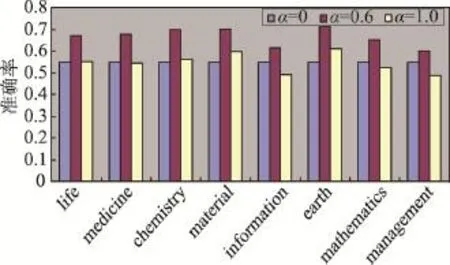
Fig.2 Precision of CD-TS algorithm on different communities图2 CD-TS算法在不同社区上的准确率
从图2中可以看到话题在社区发现结果中所占的比重,对于不同社区发现结果的准确率有一定差别,这是由不同学科的学科话题特点来决定的。举例来说,某个在科学网博客中被划分为{管理综合社区}的博客用户,发表的博客内容中很多是关于“大数据”管理方面的内容,而“大数据”近几年一直是计算机科学研究领域(属于{信息科学社区})的一个研究热点。另外,{管理综合社区}中的博客用户也有研究能源和研究优化的,由于管理科学的特点决定了管理科学与其他学科有很多共同的话题,基于话题的社区发现对管理科学并不是特别适用。同样的,{信息科学社区}、{数理科学社区}也有这样的特点;与之对应的是{地球科学社区},这个学科相对应其他学科来说用语更为专业,像“地震”、“火山”、“洪水”、“厄尔尼诺”等话题几乎不会在其他学科中出现,因此基于话题的社区发现对该社区的发现效果更佳。
5 结束语
科研人员对社区发现已经进行了比较深入和彻底的研究,但这些研究基本都是基于社会网络的网络结构进行的,而针对用户生成内容进行的社区发现很少。事实上,用户加入某个社区,更大的可能性是社区中有兴趣相同的其他用户。因此,本文提出了结合用户文本内容与网络结构的社区发现算法。根据用户发表的内容,使用LDA话题发现技术,发现用户发表内容隐含的话题信息,并且利用这些信息,以及用户与用户之间的链接关系,构建含权的用户网络,利用权重体现用户的话题信息与结构信息。在此网络上,可以使用多种方法进行社区发现,本文使用经典的谱聚类方法进行社区发现。
在科学网博客数据集上进行了实验,因为该数据集本身就已经对用户进行了社区分类,所以实验结果主要考查算法的准确度。实验结果表明,针对不同特点的社区,算法有不同的运行结果,如果有效地利用用户发表的话题信息,确实能提高社区发现的准确度。
References:
[1]Newman M E J.Fast algorithm for detecting community structure in networks[J].Physical Review E,2004,9(6): 066133.
[2]Brandes U,Delling D,Gaertler M,et al.On modularity clustering[J].IEEE Transactions on Knowledge and Data Engineering,2008,30(2):172-188.
[3]Clauset A.Finding local community structure in networks[J]. Physical Review E,2005,72(2):026132.
[4]Schuetz P,Caflisch A.Multistep greedy algorithm identifies community structure in real-world and computer-generated networks[J].Physical Review E,2005,78(2):026112.
[5]Donetti L,Munoz M.Detecting network communities:a new systematic and efficient algorithm[J].Journal of Statistical Mechanics,2004.doi:10.1088/1742-5468/2004/10/ P10012.
[6]Capocci A,Servedio V D P,Caldarelli G,et al.Detecting communities in large networks[J].Physical A:Statistical Mechanics and ItsApplications,2005,352(2/4):669-676.
[7]Newman M E J,Girvan M.Finding and evaluating community structure in networks[J].Physical Review E,2004,69 (2):026113.
[8]Rosvall M,Bergstrom C T.Maps of random walks on complex networks reveal community structure[J].Proceedings of the National Academy of Sciences,2008,105(4):1118-1123.
[9]Rosvall M,Bergstrom C T.An information-theoretic framework for resolving community structure in complex networks[J].Proceedings of the National Academy of Sciences, 2007,104(18):7327-7331.
[10]Lancichinetti A,Fortunato S.Community detection algorithms:a comparative analysis[J].Physical Review E, 2009,80(5):056117.
[11]Raghavan U N,Albert R,Kumara S.Near linear time algorithm to detect community structures in large-scale networks[J].Physical Review E,2007,76(3):036106.
[12]Leung I,Hui P,Lio P,et al.Towards real-time community detection in large networks[J].Physical Review E,2009,79 (6):66107.
[13]Palla G,Derenyi I,Farkas I,et al.Uncovering the overlapping community structure of complex networks in nature and society[J].Nature,2005,435(7043):814-818.
[14]Duan Lian,Street W N,Liu Yanchi.Community detection in graphs through correlation[C]//Proceedings of the 20thACM SIGKDD International Conference on Knowledge Discovery and Data Mining,New York,USA,Aug 24-27, 2014.New York,USA:ACM,2014:1376-1385.
[15]Kloster K,Gleich D F.Heat kernel based community detection[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York,USA,Aug 24-27,2014.New York,USA:ACM, 2014:1386-1395.
[16]Wu Yubao,Jin Ruoming,Li Jing,et al.Robust local community detection:on free rider effect and its elimination[J]. Proceedings of the VLDB Endowment,2015,8(7):798-809.
[17]Yang Jing,Xin Yu,Xie Zhiqiang.Semantics social network community detection algorithm based on topic comprehensive factor analysis[J].Journal of Computer Research and Development,2014,51(3):559-569.
[18]Blei D M,Ng A Y,Jordan M I.Latent Dirichlet allocation[J]. Journal of Machine Learning Research,2003,3:993-1022.
附中文参考文献:
[17]杨静,辛宇,谢志强.基于话题综合因子分析的语义社会网络社区发现算法[J].计算机研究与发展,2014,51(3): 559-569.

张恩德(1980—),男,辽宁海城人,2014年于东北大学计算机科学专业获得博士学位,现为东北大学计算中心教师,CCF会员,主要研究领域为社会网络,机器学习等。

高克宁(1963—),女,辽宁沈阳人,2006年于东北大学计算机科学专业获得博士学位,现为东北大学计算中心教授,CCF高级会员,主要研究领域为语义网络,信息系统等。

ZHANG Yu was born in 1980.He is a Ph.D.candidate and lecturer at Northeastern University.His research interest is data mining in social networks.
张昱(1980—),男,辽宁沈阳人,东北大学博士研究生,东北大学计算中心教师,主要研究领域为社会网络中的数据挖掘。

LI Feng was born in 1981.He is a Ph.D.candidate and lecturer at Northeastern University.His research interest is data mining in social networks.
李封(1981—),男,辽宁沈阳人,东北大学博士研究生,东北大学计算中心教师,主要研究领域为社会网络中的数据挖掘。
Community Discovery Algorithm Based on Combination of Users Generated Contents and Link Relationships*
ZHANG Ende+,GAO Kening,ZHANG Yu,LI Feng
Computing Center,Northeastern University,Shenyang 110819,China
+Corresponding author:E-mail:zed@cc.neu.edu.cn
Community discovery has been an attractive field in social networks research.However,in current community discovery algorithms,more attention is attracted to the link relationships between users and little attention is paid on big data of user generated contents(UGC).User generated content is a special feature of Web2.0,and also is an important reason to attract users,which plays an important role to form communities.This paper presents a new algorithm to solve the community discovery problem,which comprehensively utilizes the link relationships between users and user generated contents.This algorithm uses latent Dirichlet allocation(LDA)algorithm to analyze text information generated by users,and uses spectral analysis method to analyze the link relationships between users, and combines them to discovery communities.By analyzing real world data—science network site data,the proposed algorithm is proved to effectively utilize the user generated contents and link relationships between users,and the results are more objective and accurate.
community discovery;user generated contents;user link relationships;social networks
2015-04,Accepted 2015-06.
ZHANG Ende was born in 1980.He the Ph.D.degree in computer science from Northeastern University in 2014.Now he is a lecturer at Northeastern University,and the member of CCF.His research interests include social network and machine learning,etc.
GAO Kening was born in 1963.She the Ph.D.degree in computer science from Northeastern University in 2006.Now she is a professor at Northeastern University,and the senior member of CCF.Her research interests include semantic network and Web information system,etc.
10.3778/j.issn.1673-9418.1506046
*The National Natural Science Foundation of China under Grant No.61402093(国家自然科学基金青年基金);the MOE-Intel Special Fund of Information Technology under Grant No.MOE-Intel-2012-06(教育部-英特尔信息技术专项科研基金);the Scientific and Technological Projects of Liaoning Province under Grant No.2013217004-1(辽宁省科技攻关项目).
CNKI网络优先出版:2015-06-29,http://www.cnki.net/kcms/detail/11.5602.TP.20150629.1544.002.html
A
TP311
猜你喜欢
幼儿园(2021年6期)2021-07-28
小学科学(学生版)(2020年3期)2020-03-25
当代陕西(2019年16期)2019-09-25
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
智能系统学报(2015年4期)2015-12-27
博客天下(2015年2期)2015-09-15
中央社会主义学院学报(2012年4期)2012-03-20
博客天下(2009年12期)2009-08-21
