
谱聚类在社团发现中的应用
2016-11-25 05:44彭静廖乐健翟英仇晶
北京理工大学学报 2016年7期
彭静,廖乐健,翟英,仇晶
(1.河北科技大学 信息科学与工程学院,河北,石家庄 050018;2.北京理工大学 计算机学院,北京 100081;3.河北经贸大学 信息技术学院,河北,石家庄 050061)
谱聚类在社团发现中的应用
彭静1,廖乐健2,翟英3,仇晶1
(1.河北科技大学 信息科学与工程学院,河北,石家庄 050018;2.北京理工大学 计算机学院,北京 100081;3.河北经贸大学 信息技术学院,河北,石家庄 050061)
在分析谱聚类原理的基础上,研究了其在社团发现中的应用,提出了快速估计社团数量的新方法. 该方法通过计算和分析Laplacian矩阵特征值的分布来估计社团的数量,利用K-means算法对Laplacian矩阵特征向量构造的向量空间进行聚类,实现社团的发现. 该算法在真实社会网络和合成网络上做了测试,验证了在社团发现中的准确性和有效性.
Laplacian矩阵;谱聚类;K-means算法;社团发现
社会网络是一群人或团体按某种关系连接在一起构成的一个系统[1]. 人与人之间关系如朋友、同事、同学等,这种关系用图来表示,图中节点表示个体,节点之间的边表示个体间的关系. 社团是指整个网络由若干个组构成,组内节点间的连接比较紧密,而组间节点连接比较松散[2],发现网络中的社团结构并对其进行分析是了解整个网络结构、特征和功能的重要途径[3]. 图1表示一个有8个节点分为两个社团的网络.
对于所划分社团的质量,一般采用Girvan和Newman提出的模块度[4]来度量,把划分社团后的网络和相应的零模型比较. 但是,当社区大小差异较大时,模块度方法并不能得到所期望的值[5]. 传导率[6](conductance)是Jaewon Yang提出的评价社团质量函数,该函数在230个已知社团结构的大规模网络中经过验证,鲁棒性和敏感性最好.
本文依据传导率函数定义和谱聚类基本原理,提出分析图的矩阵谱分布估计社团数量的方法,在确定社团数量前提下,利用K-means算法聚类划分社团. 并给出了在真实网络和合成网络上测试结果.
1 网络图与社团划分
1.1 网络图的表示
网络用图来表示,图G=(V,E)是一个节点数为n、边数为m的简单图(没有重边和自环),G的节点集合为V={v1,v2,…,vn},节点数n=|V|,边数m=|E|. 表示图G的邻接矩阵A=(aij)n×n是一个n阶方阵,G是无权图,第i行j列的元素aij定义为
在图论中,图的Laplacian矩阵用L表示,定义为L=D-A,规范化矩阵L得到Lsym,Lsym=D-1/2LD-1/2,Lsym是对称(symmetric)矩阵,其特征谱刻画了图的拓扑结构特征,Lsym有两个重要性质[7].
性质1 对任意向量f∈n满足公式:
性质2 Lsym的特征值是非负实数,从小到大排序,记为0=λ0≤λ1≤…≤λn-1.
1.2 社团的划分与评价指标
在社会网络中,社团的大小和数量是不确定的,社团划分的质量评价是一个难题. Jaewon Yang[6]定义了13个社团评价函数,在230个已知社团结构的大规模的真实网络测试,其中传导率(Conductance)函数在鲁棒性、敏感性方面表现最好,本文从传导率函数入手依据谱聚类的基本原理得出社团划分的方法.

即S内的节点与S外节点之间连边数与S内的节点度的和的比值,f(s)值越小,社团S的质量越高.
由上述定义得出,
为了最小化f(s),根据1.1性质1,定义一个指示向量hj=[h1jh2j… hnj]′,
构造矩阵H,k个指示向量作为矩阵的列,可以计算出:
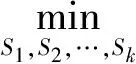
由T和H定义可知,H=D-1/2T,H是n×k的指示矩阵,根据谱聚类的基本原理,通过对H的行聚类[9]就得到k个节点集合:S1,S2…,Sk.
1.3 社团数量的确定
社团数量的确定在社团发现中一个难点,k值如何确定呢?根据1.2的结论,Tr(T′LsymT)>0,T的k列分别对应矩阵Lsym的前k个特征值对应的特征向量,根据1.1性质2,Lsym有n个特征值为:0=λ0≤λ1≤…≤λn-1. λ0=0说明图G是连通图,取k=1,Lsym次小特征值λ1对应的特征向量作为T的一列,T∈n×k,由于特征向量的分量是正交的,特征向量的元素分为正负两部分,正元素所对应的节点是一个社团,负元素所对应的节点是另一个社团. 因此应用Lsym的次小特征值对应的特征向量进行对图进行二分,这就是常用的谱平分法,因此如果分为多个社团,就多次重复该算法,但通常情况下无法知道社团的数量.
通过分析Lsym的特征值分布,采用基于距离的启发式方法,取数值变化比较平缓的前k个较小特征值,比如,发现第1~m的特征值都比较小,到了m+1突然变成较大的数,那么就可以选择k=m. 对应的特征向量构造矩阵T,T∈n×k,计算H=D-1/2T,得到指示矩阵H,H∈n×k.
2 算法描述
根据1.3的结论,计算图G的Lsym,求出Lsym的特征值,按从小到大排序,找到k个较小特征值和对应的特征向量,构造矩阵T,T∈n×k,计算H=D-1/2T,H的n行对应n个节点的k个属性,通过k-means算法计算n个的节点的k个聚类,进而发现k个社团.
输入:图G的邻接矩阵A=(aij)n×n,聚类的数量k.
① 计算G的规范化拉普拉斯矩阵Lsym;
② 计算Lsym的特征值并排序,0=λ1≤λ2≤…≤λn;
③ 计算λ1,λ2,…λk-1对应的特征向量u1,u2,…,uk;
④ 以特征向量u1,u2,…,uk为列构造n×k矩阵U;
⑤ 计算H=D-1/2U;
⑥ i=1,2,…,n,令向量yi∈k为矩阵H的第i行,应用K-means算法对(yi)i=1,2,…,n聚类,分别为C1,C2,…,Ck.
输出:节点集合S1,S2,…,Sk,Si={j|yj∈Ci}.
3 实验结果
3.1 Zachary空手道俱乐部网络
是一次行业峰会,李若认识了邵南。她10厘米高的鞋跟卡在了电梯的门缝里,穿着超短裙的她也不好意思低下身子去拔鞋,一电梯的人都停在那里,是邵南帮她拿了出来,这并不足以让她感动,感动的是当他用手托着那双鞋轻轻地给她穿上的时候,李若有了石破天惊的感觉,她觉得自己真的成了灰姑娘,那一双GUCCI鞋成就了她。
Zachary空手道俱乐部网络[10](Zachary’skarateclubnetwork)是验证社团划分算法常用的“基准网络”,从1970~1972年,Zachary通过3年时间观察了美国一所大学空手道俱乐部成员间的社会关系,构造出了含有34个节点和78条边的网络,每一个节点表示俱乐部的一个成员,节点之间的连接表示两个成员经常出现在俱乐部活动之外的其他场合. 在Zachary研究这个俱乐部成员社会关系期间,由于教练Hi(节点0)和俱乐部主管John(节点33)之间意见分歧,该社会网络分裂成两个分别以教练Hi(节点0)和主管John(节点33)为核心的两个社团.
分析该网络的Lsym的特征值分布如图2所示,可以看到有4个较小特征值.
分别取分别选择k=2,3,4时的聚类结果分别如图3所示.
k=2时检测结果和实际相符,k=3和k=4时,检测到了较小规模的社团,说明大社团中存在更小的社团,与传统模块度的检测方法得到的社团结果相同.
3.2 社团质量的评价
使用传导率来衡量社团划分的结果,聚类结果中平均传导率如图4所示,f(s)越小,社团结构越明显.
为了验证划分社团结果的准确性,利用谱聚类算法计算k=2~10的社团划分,计算每个划分结果的传导率的平均值,k=2时,传导率值最小,表明发现的是两个核心社团,k=3、4传导率值平缓增加,可以理解为除了这两个核心社团之外存在两个小的社团.k的取值从4到5,传导率均值有较高的突变,k≥5时f(s)的值趋于稳定,表明没有新的社团. 因此可以认为k取值为4是比较合理的,验证了估计社团数目的正确性.
实验中还使用计算机生成了9个网络,该网络是Girvan与Newman提出的均质社团结构测试网络[11-12](GN合成网络),该网络含有128个节点,4个社团,每个社团的节点数为32. 在该网络中,同一个社团的2个节点以概率Pin随机连边,不属于同一社团的2个节点以概率Pout连边.Zin为节点与社团内部节点连边数目的期望值,Zout为节点与社团外节点连边数目的期望值,Pin和Pout的取值,保证2个节点的度期望值为16,即Zin+Zout=16.Zout取值从0~8分别生成9个网络,Lsym的特征值分布如图5所示.
已知测试网络的社团为4,λ0=0.Zout从0~8,λ1,λ2,λ3的值逐渐增加,Zout=7、8的时,λ1,λ2,λ3接近λ4,说明社团的结构不再明显.Zout=0时,λ1=λ2=λ3=0,网络有4个社团,社团之间没有连接;Zout=1,2,3,4时,λ1,λ2,λ3较小,距离较近,随着Zout增大,λ3,λ4的值在逐渐增大;Zout=7,8时λ1,λ2,λ3的值接近λ4,网络没有明显的社团结构,验证了k值选择方法是正确的.
通过谱聚类对该9个网络划分社团,准确率如图6所示.
Zout≤6时正确率超过90%,因为测试网络的社团结构比较明显;Zout≥7,8时正确率低于80%,因为社团没有明显社团结构了. 应用GN模块度的算法的结果是Zout≤6时有90%以上的节点被正确划分,与该算法的划分结果一致.
4 结束语
通过分析评价社团划分质量的传导率函数的定义,依据谱聚类的基本原理,研究了谱聚类在社团发现中的应用,提出了根据Laplacian矩阵特征值的分布快速估计社团数量的方法. 通过Laplacian矩阵特征向量构造向量空间,应用K-means算法聚类发现社团,在真实的社会网络中应用传导率函数验证了该算法是有效的,在GN合成网络中用准确率验证了该算法的正确性.
[1] 汪小帆,李翔,陈关荣.网络科学导论[M].北京:高等教育出版社,2012.
Wang Xiaofan,Li Xiang,Chen Guanrong. Network science: an introduction[M]. Beijing: Higher Education Press,2012. (in Chinese)
[2] Girvan M,Newman M E J. Community structure in social and biological networks[J]. Proceedings of the National Academy of Sciences,2002,99(12):7821-7826.
[3] Ng A Y,Jordan M I,Weiss Y. On spectral clustering: Analysis and an algorithm[J]. Advances in Neural Information Processing Systems,2002,2:849-856.
[4] 黄发良,肖南峰.用于网络重叠社区发现的粗糙谱聚类算法[J].小型微型计算机系统,2012,2:263-266.
Huang Faliang,Xiao Nanfeng. Rough spectral clustering algorithm applied to overlapping network communities discovery[J]. Journal of Chinese Computer Systems,2012,2:263-266. (in Chinese)
[5] 蔡晓妍,戴冠中,杨黎斌.基于谱聚类的复杂网络社团发现算法[J].计算机科学,2009,9:49-50.
Cai Xiaoyan,Dai Guanzhong,Yang Libin. Community-finding algorithm in complex networks based on spectral clustering[J]. Computer Science,2009,9:49-50. (in Chinese)
[6] Yang J,Leskovec J. Defining and evaluating network communities based on ground-truth[C]∥Proceedings of the ACM SIGKDD Workshop on Mining Data Semantics. [S.l.]: ACM,2012:3.
[7] Sole-Ribalta A,De Domenico M,Kouvaris N E,et al. Spectral properties of the Laplacian of multiplex networks[J]. Physical Review E,2013,88(3):032807.
[8] Gu M,Zha H,Ding C,et al. Spectral relaxation models and structure analysis for k-way graph clustering and bi-clustering[R]. Philadelphia, USA: University of Pennsylvania,2001.
[9] Bach F R,Jordan M I. Learning spectral clustering,with application to speech separation[J]. The Journal of Machine Learning Research,2006,7:1963-2001.
[10] Zachary W W. An information flow model for conflict and fission in small groups[J]. Journal of Anthropological Research,1977,33(4):452-473.
[11] Malliaros F D,Vazirgiannis M. Advanced graph mining for community evaluation in social networks and the web[C]∥Proceedings of the Sixth ACM International Conference on Web Search and Data Mining. [S.l.]: ACM,2013:771-772.
[12] Newman M E J. Spectral methods for community detection and graph partitioning[J]. Physical Review E,2013,88(4):042822.
(责任编辑:刘芳)
Spectral Clustering for Community Detection
PENG Jing1,LIAO Le-jian2,ZHAI Ying3,QIU Jing1
(1.School of Information Science and Engineering,Hebei University of Science and Technology,Shijiazhuang, Hebei 050018,China; 2.School of Computer Science,Beijing Institute of Technology,Beijing 100081,China; 3.School of Information and Technology,Hebei University of Economics and Business,Shijiazhang, Hebei 050061,China)
In this paper spectral clustering was applied to detect the community in social network,and a new method was proposed to estimate the number of communities. According to this new method,the number of communities was estimated by calculating and analyzing the eigenvalues distribution of Laplacian matrix. K-means algorithm was used to clustering vector space which was constructed by eigenvectors of Laplacian matrix. The method was tested on a range of examples,including real-world and synthetic networks. Experimental results show that the method for community detection is accurate and effective.
Laplacian matrix; spectral clustering; K-means algorithm; community detection
2014-12-10
国家“九七三”计划项目(2013CB329605);国家自然科学基金资助项目(61300120);河北省自然科学基金资助项目(F2012208016);河北省教育厅资助项目(YQ2013032)
彭静(1970—),女,副教授,E-mail:pengjing70@163.com.
廖乐健(1962—),男,教授,博士生导师,E-mail:liaolj@bit.edu.cn.
TP 305
A
1001-0645(2016)07-0701-05
10.15918/j.tbit1001-0645.2016.07.008
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
北京航空航天大学学报(2022年8期)2022-08-31
网络安全与数据管理(2022年3期)2022-05-23
保定学院学报(2022年2期)2022-04-07
计算机应用与软件(2021年7期)2021-07-16
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
烟台大学学报(自然科学与工程版)(2020年1期)2020-02-08
数学学习与研究(2018年15期)2018-11-12
舰船电子对抗(2017年6期)2018-01-11
课程教育研究·新教师教学(2016年18期)2017-04-12
