
基于LPAL模型的超文本分析
2016-11-12 07:50:56张膂
微型电脑应用 2016年3期
张膂
基于LPAL模型的超文本分析
张膂
PLSA和LDA主题模型主要是研究纯文本内容。最近,开始提出用主题模型处理超文本,所提出的超文本模型是生成模型,引出了词和超链接的关系。由于超文本的文档词分布不仅由文档主题决定,也由引用的文档的主题决定。因此提出了一种基于主题模型的LPAL(Link PLSA And LDA)模型处理超文本的主题发现和文档分类。 和传统的主题模型一样,该主题模型进一步的表示了词的分布。实验结果表明,该模型在主题发现和文档分类要优于传统的LDA和Link-LDA模型。
超文本;LPAL;主题发现;文档分类
0 引言
主题模型是表示文档内容的生成模型。近年来,关于主题模型的研究取得了很大的进展,像PLSI(Hofmann,1999)、LDA(Blei et al, 2003)以及它们的拓展(Griffiths et al,2005; Blei and Lafferty,2006; Chemudugunta et al,2007)。推理和学习算法也同样取得了很大的进展,例如变量的推理(Jordan et al, 1999; Wainwright and Jordan, 2003),期望最大化(Minka and Lafferty, 2002),以及 Gibbs采样(Griffiths and Steyvers, 2004)。在主题发现(Blei et al,2003),文档抽取(Xing Wei and Bruce Croft, 2006),文档分类(Blei et al, 2003),社交网络分析(Mei et al, 2008)等[1]也已经使用主题模型了,但大部分的模型还只是处理纯文本。也有学者(Cohn and Hofmann, 2001; Dietz et al,2007;Nallapati and Cohen,2008; Gruber et al, 2008)已经用主题模型处理超文本。Cohn and Hofmann (2001)介绍了一种基于PLSI框架的超文本主题模型[3]。这个模型结合PLSI和PHITS(Cohn and Chang,2000)模型提出了文档词和超链接的关系。Erosheva et al (2004)对模型PLSI进行改进得到了 LDA[2]。因为符号的一致性,也称为Link-LDA模型。Link-LDA模型的生成过程如图1(b)所示,对应的字母说明如表1所示。词和超链接非常的相似,有相同的主题分布θ,因此这个模型能抽取出共享相同主题的超链接和词的文档。
Link-PLSA和Link-LDA通过随机变量定义成超链接的值。也就是说这些模型获得超链接文档主题聚类的方法与基本的LDA和PLSA模型是相似的,但是这些模型不能建立引用文档和被引用文档之间的关系[4]。很显然,文档d链接另外文档 d’,这两者之间是相关的。因此有人就想通过研究这些额外的信息来获得好的主题及主题之间的影响。Dietz et al (Dietz,Bickel,& Scheffer 2007)提出了一种新的LDA方法,基于从引用文档到被引用文档主题信息流的方法[5]。这种方法中每篇引用的文档都是引用被引用文档的主题来产生自己主题。这个模型仅仅考虑引用文档的影响,但是没有建立引用文档对主题的特定影响。接下来,我们将建立一个新的模型来解决这些问题。
1 模型LPAL生成过程
在主题模型中,每个主题对应词的分布称为混合的潜在主题。该文引入对文献引用的一种扩展的LDA模型。主要的符号及其说明如表1所示:

M Total number of documents M← Number of cited documents
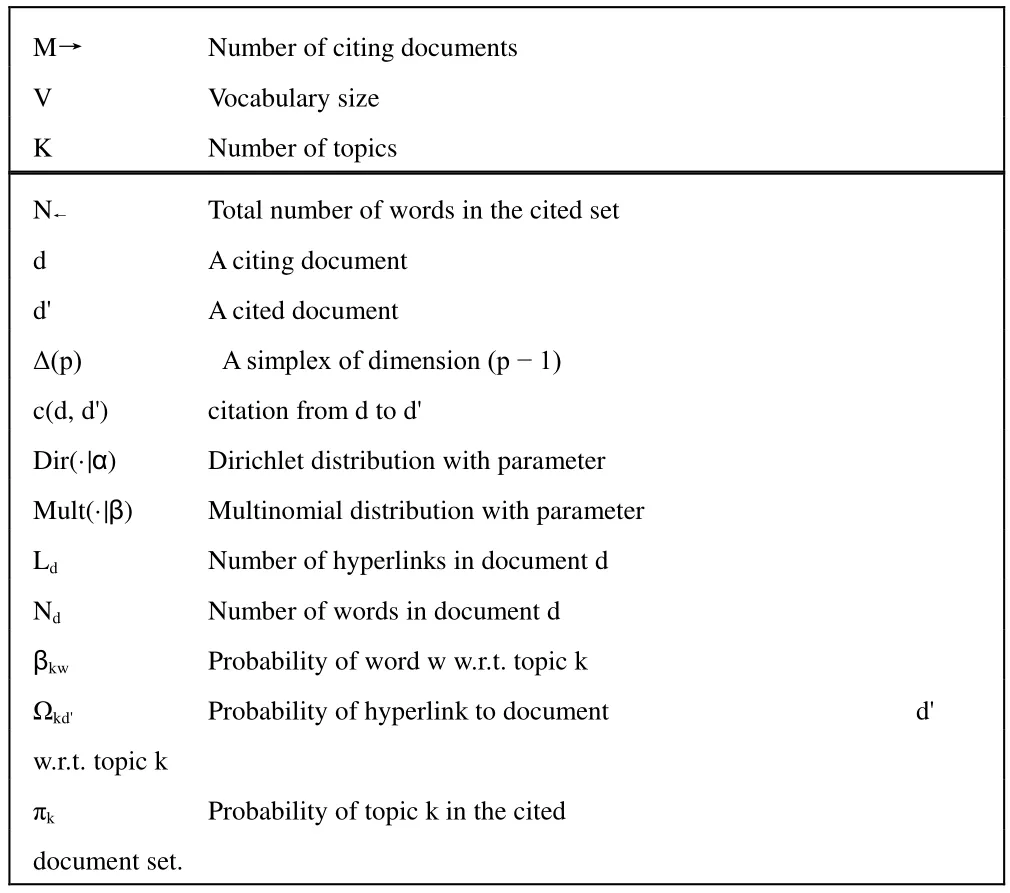
M→ Number of citing documents V Vocabulary size K Number of topics N← Total number of words in the cited set d A citing document d' A cited document Δ(p) A simplex of dimension (p - 1)c(d,d') citation from d to d' Dir(·|α) Dirichlet distribution with parameter Mult(·|β) Multinomial distribution with parameter Ld Number of hyperlinks in document d Nd Number of words in document d βkw Probability of word w w.r.t. topic k Ωkd' Probability of hyperlink to document d' w.r.t. topic k πk Probability of topic k in the cited document set.
传统的LDA模型如图1所示:
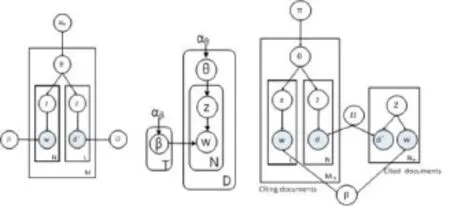
图1 传统LDA模型
其过程有 3步。每篇文档的主题分布服从一个先验的Dirichlet分布服从一个先验的Dirichlet分布,主题的采样是从一个文档的主题分布中采样的,服从一个多项式分布,词的采样根据主题词的分布12图1(b)是Link-LDA模型,其对应的算法伪代码如表2所示:

r each document d=1,2,…,M:Generate θdϵ Δ(K) ~ Dir(·|αθ) For each position n=1,· · · ,NdGenerate znϵ {1,· · ·,K} ~ Mult(·|θd) Generate wnϵ {1,· · · ,V } ~ Mult(·|βzn) For each hyperlink l=1,· · ·,LdGenerate zlϵ {1,· · ·,K} ~ Mult(·|θd)
图1(c)就是LPAL(Link PLSA And LDA)模型。其算法过程如表3所示:

Cited documents:For i=1,…,N←Generate ziϵ{1, · · ·K} ~ Mult(·|π)Sample d'iϵ {1,· · · ,M←} ~ Mult(·|Ωzi) Generate wiϵ {1,· · · ,V } ~ Mult(·|zi) Citing documents:

For each citing document d=1,· · · ,M→Generate θdϵ Δ(K) ~ Dir(·|αθ) For each position n=1,· · · ,NdGenerate znϵ {1,· · ·,K} ~ Mult(·|θd) Generate wnϵ {1,· · · ,V } ~ Mult(·|βzn) For each citation position l=1,· · ·,LdGenerate zlϵ {1,· · ·,K} ~ Mult(·|θd) Generate d'lϵ {1,· · · ,M←} ~ Mult(·|Ωzl
2 模型参数推理和估算
这个模型观测数据的似然函数如下:
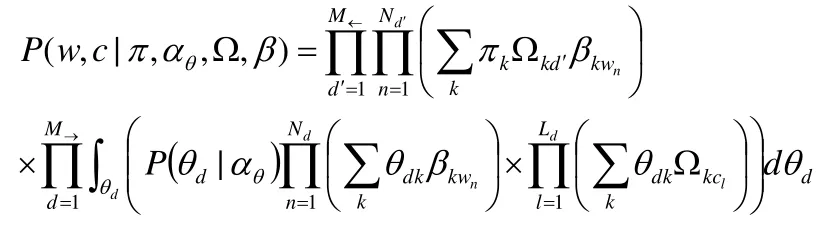
其中w是整个引用文档和被引用文档数,c是被引用文档数,。由于θ,β,Ω成对耦合,这个模型的参数估计和推理是相当困难的。因此,通常使用近似的方法计算,如Gibbs采样(Andrieu et al. 2003)或者变近似值(Wainwright & Jordan 2003)[7]。接下来,我们使用平均场变分近似求解隐变量的后验分布。如图2所示:
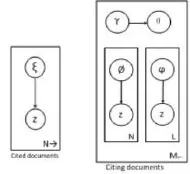
图2 LPAL模型的平均场近似后验分布的图形
对应图的表达式:
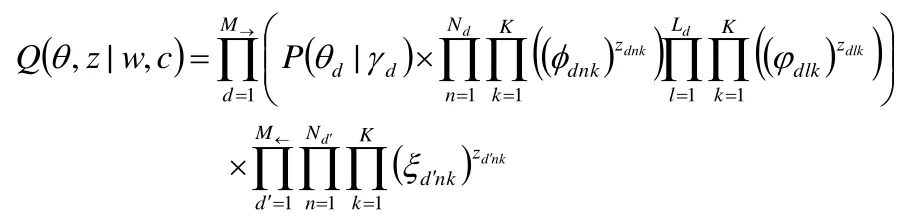
其中:γdk是引用文档d对应的主题k的后验概率;
φdnk是文档d对应的主题k所产生的第n个词的后验概率;
φdlk是文档d对应的主题k被引用的第1个词的后验概率;
ξd'nk是被引用文档d'对应的主题k所引用的第n个词的后验概率。
经 Jensen不等式变化,可以得到观察数据的对数似然函数:
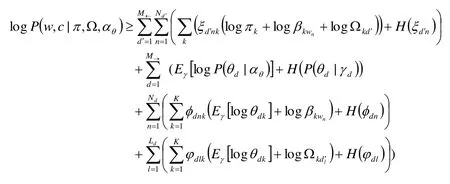
其中H()是其参数分布熵;Ep[ ]表示是下标p参数分布的期望。可以看出不等式左右的区别,相当于是变量后验和隐变量真实后验之间的KL距离。因此最大化最小边界相当于找到最相近的真实后验概率的变分近似法。
对上式每个参数微分并使其等于零,可以通过以下参数更新如公式(1)~(7):

通过迭代更新直到收敛,由上面的公式(1)~(7)可以得出公式(1)公式(3)是相互影响,这些等式进行了内部循环,直到它们收敛。因为公式(1)和公式(4)涉及到变量参数,所以公式(1)称为推理步骤。同理,因为公式(5)和公式(7)是估计模型参数β,Ω,π,所以公式(5)称为估算步骤。αθ的值可以通过上述过程估算得到,但在上述模型中,根据经验一般设其为固定值为0.1。
3 实验结果
分别比较了LDA,Link-LDA,LPAL(Link PLSA And LDA)在主题发现和文档分类的应用。
3.1数据集
首先使用Lemur(狐猴)工具包对文本进行处理以及低频词删除,第一个数据集WebKB包含六大类。有3921个文档和 7359个链接,共有 5019个词。第二个数据集Wikipedia包括四大类:生物,物理,化学以及数学。有2970个文档及45818个链接,共有3287个词。第三个数据集是由研究人员网页和他们的一级外链组成的 ODP(开放式分类目录搜索系统)数据集,随机的选择了认知科学,理论,神经网络,机器人以及统计学等五类,其中有3679篇文档和2872个链接,3529个词。其中WebKB和Wikipedia数据广泛的使用在主题模型研究中,而ODP数据则需要自己收集。
3.2主题发现
在这 3个数据集中,分别建立了 3个主题模型LDA,Link-LDA,LPAL。在ODP数据集中建立了10个主题,在WebKB中建立了12个,在Wikipedia中建立了8个。可以发现LPAL模型比其他的模型更好的理解主题。在ODP数据集中的3种模型的相关主题词如表2、表3和表4所示:

表2 LDA

表3 Link-LDA

表4 LPAL
LPAL模型能相对准确的抽取出 3个主题:Theory,NN,Robot。在LDA和Link-LDA图中有“Mixed”主题。可以看出这 3个主题模型中都把认知科学分了两主题(CogSci-1和 CogSci-2),造成这种的可能原因是主题的多样性。
3.3文档分类
在这3个数据集中用这3个模型进行文档分类。建立文档的特征词向量,同时把数据随机分成 3部分,并进行 3倍交叉验证实验。在每个实验中,对训练集数据进行分类(SVM),通过验证集数据选择模型参数,最后测试集数据评估分类的性能。分类的精度如表5所示:
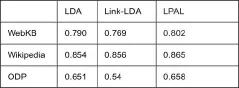
表5 3种模型的3倍交叉验证的精确
可以看到在这3个数据集中,LPAL模型比其他模型的精度要高。
在所有数据集的结果中建立了sign-tests。LPAL模型比LDA,Link-LDA的统计显著更好。结果如表6所示:
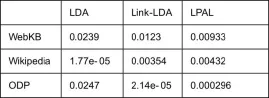
表6 三种模型的sign-test结果
4 总结
超文本的文档词分布不仅由文档主题决定,也由引用的文档的主题决定。在这本文中,提出了一种新的处理超文本的主题模型,是基于LDA模型的基本框架建立本文的模型,并进行学习和推理。该模型比LDA,Link-LDA模型更能准确的表示在超文本中主题沿着超链接反向“传播”,可以自然的模拟人写文档的过程。实验结果说明,在3个数据集中,LPAL模型在主题发现和文档分类优于其他两个模型。
[1] David Blei,Andrew Ng,and Michael Jordan. 2003. Latent Dirichlet allocation[J]. Journal of machine Learning Research,3:993-1022.
[2] 葛琳,季新生等.基于LDA模型的在线网络信息内容安全事件分类[J].四川大学学报(工程科学版),2014,46(3);69-79
[3] 赵宏伟,陈霄,龙曼丽等.基于改进 PLSA分类器的目标分类算法[J].吉林大学学报(工学版),2012,42(sup.1);232-235
[4] 谭文堂,王桢文,殷风景,葛斌等.一种面向多文本集的部分比较性 LDA模型[J].计算机研究与发展,2013,50(9);1943-1953
[5] 姜晓伟,王建民,丁贵广.基于主题模型的微博重要话题发现与排序方法[J].计算机研究与发展,2013,50(sup.l);179-185
[6] 曹建平,王晖,夏有清,乔凤才,张鑫.基于LDA的双通道在线主题演化模型[J].自动化学报,2014,40(12);2877-2886
[7] [7] 江雨燕,李平,王清.基于共享背景主题的Labeled LDA模型[J].电子学报,2013,41(9);1794-1799
Analysis of Hypertext Based on LPAL Model
Zhang Lv
(Faculty of Information Engineering and Automation,Kunming University of Science and Technology,Yunnan 650500,China)
PLSA and LDA topic model is mainly to study the text content. Recently,it began to put forward topic model to deal with hyper text. The proposed hypertext model was generative model,which led to the relationship between words and hyperlink. Because the word hypertext document distribution war determined not only by the document theme,but also by the referenced document theme. This paper presented a new topic model LPAL (Link PLSA And LDA) base on the topic model to process the topic discovery and document classification of hypertext. And similar with the traditional topic model,the proposed topic model can further show the distribution of words. The experimental results show that,LDA and Link-LDA model is better than the traditional model in topic discovery and document classification.
Hypertext; LPAL; Theme Discovery; Document Classification
TP311
A
1007-757X(2016)03-0077-03
张 膂(1988-),昆明理工大学,信息工程与自动化学院,研究方向:自然语言处理,昆明,650500
(2015.11.15)
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
工程数学学报(2020年3期)2020-07-06 07:38:40
长治学院学报(2019年2期)2019-07-24 07:14:04
魅力中国(2018年5期)2018-07-30 11:11:58
雷达学报(2017年6期)2017-03-26 07:53:04
信息安全研究(2016年4期)2016-12-01 06:06:54
生物学教学(2016年10期)2016-08-20 09:50:12
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
21世纪商业评论(2014年16期)2014-04-29 00:44:03
华东理工大学学报(自然科学版)(2014年5期)2014-02-27 13:49:31
