
基于FORTRAN的项目在系统平台移植时的数据挖掘
2016-11-12 07:50:55魏霞郑胜秦雄杰
微型电脑应用 2016年3期
魏霞,郑胜,秦雄杰
基于FORTRAN的项目在系统平台移植时的数据挖掘
魏霞,郑胜,秦雄杰
针对核仿真系统在不同系统平台(由Windows到Linux)转换中异构数据格式的不同,从大量多特征源文件中挖掘所需数据,并转换存储到需求格式文件中的通用方法。主要采用AWK脚本实现对所需数据提取、格式转换、原文件注释等功能的通用性方法。利用此方法,对DCS核仿真严重事故模拟机等多个基于FORTRAN语言的系统,在平台移植时起到了可靠、高效的通用性。
AWK;FORTRAN;多特征;数据挖掘;通用方法
0 引言
资源的缺乏提醒了各国重视核电的发展,现在社会是高效竞争的社会,各国核电装机容量的多少,很大程度上反映了各国经济、工业和科技的综合实力和水平。三哩岛核事故、切尔诺贝利核事故、福岛核事故等事件标示了核仿真严重事故模拟机研发的重要性,为了在更稳的系统平台(Linux)中运行,在此将基于FORTRAN语言的核仿真严重事故模拟机系统从Windows系统平台移植到Linux系统平台。在系统移植过程中最首要、最重要的就是对所需的原数据的挖掘,它影响着下面一步步工作的进度。
同时在平台移植时,异构数据高效挖掘及转换也正是当今众多方面学者研究的热点。其中国外从应用方面(政府管理、商业经营、金融、社保、医学、天文等)研究,并且大量的数据挖掘工具和软件也已经出现,有基于统计分析的软件,如:SAS、SPSS等;有应用于新技术如模糊逻辑、人工神经网络、决策树理论的工具,如:CBR Express、Esteen、Neural network Browser等软件。国内对数据挖掘的研究稍晚,1993年国家自然科学基金首次开始支持对该领域的研究项目,一般集中于学习算法的研究、数据挖掘的实际应用以及有关数据挖掘理论方面的研究。但这些软件与研究并不是包罗万象地应用于任何数据挖掘技术的软件,而是有所侧重[1]。
而本方法则转换思路,不从应用领域,而从系统所基于的语言的角度,利用发现特征、聚类、分类的方式,同时与新平台数据仓库结合。研发出了一个利用AWK脚本,针对大量多特征的 FORTRAN语言的系统平台移植时的数据挖掘的简单的、可靠的、通用的方法。利用本文提出的方法,对 DCS核仿真严重事故模拟机等多个应用领域的基于FORTRAN语言的系统在平台移植时起到了可靠、高效的通用性。
1 研究方法
1.1AWK
和java、c++、c#等高级语言相比,AWK是化难为易的一种简单且优良的工具,它具有编程语言及数据操作脚本具备的一个完整的语言所应具有的几乎所有精美特性。它可以通过简短的程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报表等,高效的为数据库做好准备。同时,AWK还具备有些高级语言而没有的正则表达式功能,正则表达式并非一门专用语言,但它可以让用户通过使用一系列普通字符和特殊字符,构建能明确描述文本字符串的匹配模式。除了简单描述这些模式之外,正则表达式解释引擎还可用于遍历匹配,以智能、高效的方式查找、转换所需文本格式[2]。本方法中则充分利用了其重要价值。
1.2实验思路及具体操作
1.2.1实验思路及步骤
原仿真系统是基于FORTRAN语言,在SimBase[3]仿真支撑软件系统下运行于Windows平台的模块化系统。原系统数据均是分散于各模块中下属子文件中,在新的平台(Linux)下要想使原系统达到同样效果,首先要明确在Linux平台中SimBase仿真支撑软件系统下对FORTRAN所需数据及格式的需求:新平台下要求将所需数据(即全局变量,局部变量不变)按照统一格式放到统一数据库文件中,运行系统时再统一分块加载。其统一数据库所需全局变量数据格式如下:
.desc <输入简短的对加入变量的描述,最多不超过5行,同时不允许直接回车,至少要输入一个空格符再回车>
.unit <输入变量的单位,如:pw>
.sys <输入此变量所属的用户系统>
.type <输入此变量的类型,如:整数—“I,4”,逻辑变量—“L,1”,实数—“R,4”>
.form <输入变量的形式,例如:整数—“i19”,实数—“e16.8”,逻辑变量—“l19”>
.valu <值>,<类型:v-变量;c-常量;p-参数>
.dim <输入此变量的维数>
.pred <输入所属的 global(变量的分类区)>,
基于上述要求,实验的主要处理流程图如图1所示:
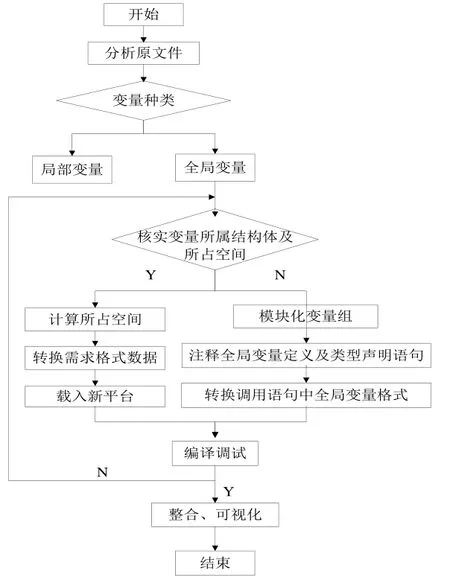
图1 主要处理流程图
依上图思路,实验在满足所需数据、格式且在灵活可变的自规定的前提下分为以下3个步骤:
提取全局变量:一个全局变量的微小改变会影响到整个项目的运行,因此选择在整个项目开展之前,将待处理代码中所有全局变量、所属结构体及数据类型做整体提取工作,并根据是否核实所占空间,将全局变量(包括所属结构体)分别存于不同文件中;
注释全局变量声明语句:依据上述情况可知,在平台中变量主要由DBM统一管理。因此在移植过程中,同时需要将程序中相关变量声明语句注释,以不影响新平台运行调试需求。此方法中采用了将定义全局变量语句和类型说明语句前加上字符“c”,使其所在语句成为注释说明语句;
转换调用语句中全局变量格式:为了记载在原数据所属Fortran文件中显示的变量所属结构体,以满足新平台中数据库文件对结构体的需求,此方法中采用了将调用语句中的所有属于全局的变量前加上变量所属的结构名和下划线“_”。
1.2.2实验具体操作方法及结果
(1)全局变量的提取
提取全局变量时利用AWK的特长:选取不同的字段分隔符、充分利用正则表达式、内置函数(substr()、match())等。如图2所示:
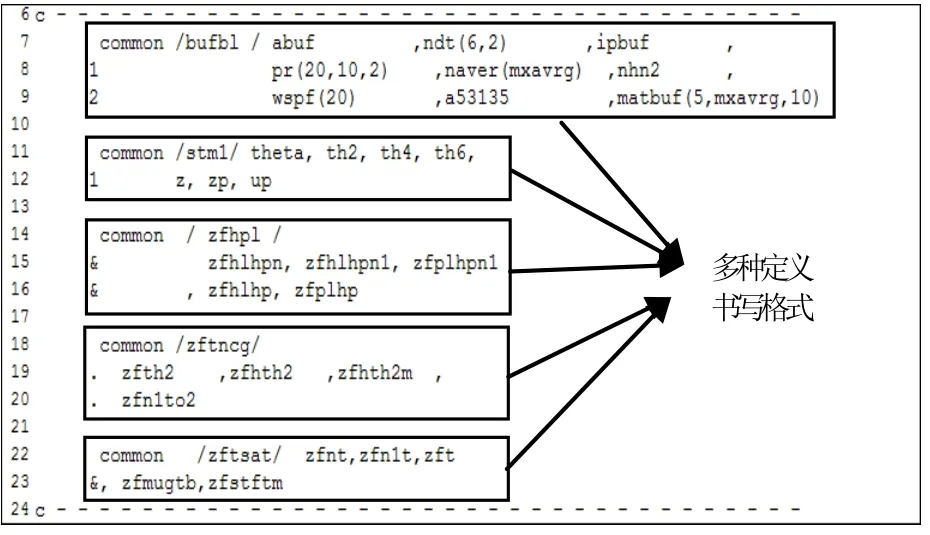
图2 原文件全局变量
从图2中会发现:全局变量有普通变量(如abuf)、一维变量(如 wspf(20)、naver(mxavrg))、二维变量(如ndt(6,2))及多维变量(如pr(20,10,2)、matbuf(5,mxavrg,10))等。这就要求此提取方法要有灵活的通用性,观察全局变量结束标示,用正则表达式查询结束标示,同时注意是否与先前所选择的字段分隔符是否相同,如果先前选择的字段分隔符中包括有逗号,那么逗号就将比如ndt(6,2)、matbuf(5,mxavrg,10)等格式的变量不能按需求提取,那么下步计算变量所占用内存时就不能实现,如果只采用其它字符而不使用逗号为字段分隔符,则逗号将被归属于其中变量(由图2可看出),因此,逗号也被选择为字段分隔符。此时再利用内置函数 match()配合查找需求的变量,用正则表达式查找变量是否结束,其中以易于被忽视的下标括号为重要标示。鉴于此思想,所得结果如图3所示:

图3 不同需求提取结果
当考虑到文件数量的时候,就要再加上批处理的功能。只需在上述代码中加入一个简短循环即可实现。首先可以将所有要处理的文件名放入同一个文件中,然后利用FORTRAN文件扩展名的共性(*.h、*.for)及AWK具有的特色数据结构——哈希数组的特点,将数以万计的文件一次处理完毕,以达到高效的批处理方式[4]。
上述提取的全局变量是可以统计内存空间的变量,而当在新系统平台中不需要统计变量所占空间,只要单纯的全局变量名时,此方法中则舍掉采用的通俗方式:在上述得到的变量文件中去掉内存说明(即下标)。因为如果在第一步中有错,则会影响此步结果。在此则用潜在的性能提升的方式:短路方式(仍然从原文件中直接提取)。区别与上面的重要之处是:首先判断此变量是否属于普通变量,如果属于普通变量则直接提取,如果属于数组变量,则要以左括号为标示,利用正则表达式截取出所需变量名,同时以右括号为标示以判断此变量的结束,以防如matbuf(5,mxavrg,10)类似的变量,而将“mxavrg”误认为是全局变量。所得结果如图3中右半部分所示。
(2)注释全局变量定义和类型声明语句
通过上述的方法,两种全局变量顺利提取后,原文件中全局变量定义语句已在新系统平台中失效,其中为了提高效率,则仍然用短路方式直接查看原文件中哪行包含“common”,再选用(1)中类似的标示(flag、fflag)配合检查语句的结束,可快速将全局变量定义语句注释,如图4所示:

图 4 注释全局变量定义说明语句
观察图5上图可以发现变量类型声明语句的多样性,而为了达到注释全局变量类型说明语句的通用性,则需用AWK灵活处理文本的优势,配合图3右部分提取出的全局变量,与原文件类型说明语句中包含的变量完全匹配,且结合上面提取变量时用到的重要标示(括号)及短路方式,辨别出是否是全局变量类型说明语句,将其转换成注释语句,以消除原全局变量类型声明语句障碍。结果如图5下图。其中图5中25行—30行没有改变成注释语句,原因是其中的变量是局部变量,并没有要求其改变成注释语句。
(3)转换call语句(调用语句)中全局变量格式

图5 变量类型声明语句前(上部)后(下部)
如图6所示:

图6 加结构体前(上部)后(下部)
从图6中会发现同一个call语句可以同时调用全局变量和局部变量,而需求是将属于全局的变量名前加上变量所属的结构名和下划线“_”,局部变量仍没有被要求其格式转换。此时要配合步骤(1)中提取的全局变量和其所属结构体,以及再次利用语句结束标示,即call语句中的括号,且结合AWK的特色数据结构——哈希数组,先将变量及所属结构体依据哈希数组建立关系,为下一步为变量加载结构体名做准备,同时判断是否输入哈希数组中的全局变量。即可顺利完成步骤(3),结果如图6下部。
2 实验结果及评价
Fortran不只在目前的热门行业——核电行业中占优势地位,在工程计算中的应用、在结构动力分析中的应用、在大地电磁测探中得到应用、在计算程序图形界面中等大数量项目中独自或结合其它软件至今仍得到广泛的应用。在DCS核电仿真严重事故模拟机系统平台移植及其它几个大型模块化项目在挖掘所需数据的实验中,均证实了此方法的简单有效性。大量的数据表明:此方法在基于FORTRAN语言被应用的各领域移植中均可使用。
3 总结
在使用AWK时要注意不可忽视的小知识点,比如:所提取的对象所在行的特性、循环语句while和for的不同效果、分隔符(空格与“ ”、“,”)的不同使用环境、哈希数组中下标类型超出了一般语言的限制等,在此方法中有重要的影响。那么,在此方法完备的基础上,再结合跨平台Qt,将其整合成可视化的易于操作的小工具,则是下一步研究的具体工作,达到即使对FORTRAN文件和AWK操作不熟悉,也可以利用此工具轻松挖掘数据的目的。
[1] 陈卓民.数据挖掘技术在国内外的研究和发展现状[J].青年文学家.2009,(16):122-123.
[2] [2] Jeffrey E.F.Friedl编著.精通正则表达式[M].电子工业出版社.2009.07
[3] ] 仿真支撑软件 SimBase使用手册[M].中核武汉核电运行技术股份有限公司.
[4] 江松波,倪子伟.浅谈自底向上的Shell脚本编程及效率优化[J].计算机与现代化.2011,(2):73-76,80.
[5] 尚力,陈根土.Unix/Linux环境下实用程序awk的简要分析及应用[J].金融科技时代,2013,(10):56-57.
Data Mining of Project Based on FORTRAN in the Porting of System Platform
Wei Xia1,2,Zheng Sheng1,Qin Xiongjie3
(1.Science College,China Three Gorges University,Hubei 443002,China; 2.Zhoukou Vocational and Technical College,Henan 466000,China; 3.China Nuclear Power Operation Technology Corporation,LTD,Wuhan 430223,China)
In this paper the nuclear simulation system in different system platforms (from windows to Linux) conversion has different heterogeneous data formats,so it researches the common method how to mine the needed data from a large number of multi features source files and save them in the needed formats after conversion. The general method of data extraction,format conversion,and annotation of the original file function is implemented by AWK script. Using the method proposed in this paper,the DCS nuclear simulation system and other several FORTRAN-based systems are reliable and efficient for the platform transplantation.
AWK;FORTRAN; Multi Feature;Bracket Marking; Short Circuit Method; Data Mining
TP311.1
A
1007-757X(2016)03-0070-03
魏 霞(1978-),女,三峡大学、周口职业技术学院,讲师,硕士研究生,研究方向:数字图像处理,周口,466000;
郑 胜(1965-),男,三峡大学,教授,博士,研究方向:图像处理、目标识别、神经网络与智能控制,宜昌,443002;
秦雄杰(1989-),男,中核武汉核电运行技术股份有限公司,助理工程师,硕士,研究方向:核电仿真,湖北,430223
(2015.09.14)
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29 02:17:10
大众投资指南(2021年35期)2021-02-16 01:06:26
河北理科教学研究(2020年2期)2020-09-11 06:15:48
新世纪智能(语文备考)(2020年4期)2020-07-25 02:28:50
作文评点报·低幼版(2017年44期)2017-11-16 08:24:58
电力与能源(2017年6期)2017-05-14 06:19:37
信息通信技术(2015年6期)2015-12-26 01:16:46
数学年刊A辑(中文版)(2015年2期)2015-10-30 01:56:14
新高考·高二数学(2014年7期)2014-09-18 00:42:02
语文知识(2014年4期)2014-02-28 21:59:52
