
基于网络爬虫和Fuzzing的漏洞挖掘检测工具
2016-11-12 07:50:55裘志庆宦飞
微型电脑应用 2016年3期
裘志庆,宦飞
基于网络爬虫和Fuzzing的漏洞挖掘检测工具
裘志庆,宦飞
如今,随着Web技术的高速发展和互联网的大众化,Web安全领域受到了越来越多的威胁。跨站脚本攻击(Cross-site Scripting ,缩写XSS)是这些安全隐患中危害性比较大,存在范围比较广的一种漏洞攻击。目前已有的XSS漏洞检测挖掘工具和技术还不够完善,存在检测速度较慢、漏报率高等缺点。研究设计了一款基于网络爬虫和Fuzzing模糊技术的漏洞挖掘检测工具。其中对于网络爬虫进行了大幅度的效率优化。并与当前现有的漏洞挖掘工具进行测试对比,证明该工具可以高效的进行漏洞挖掘。
网页前端安全;漏洞挖掘;跨站脚本攻击;模糊测试
0 引言
随着Web技术的高速发展和互联网的大众化,Web安全领域受到了越来越多的威胁。随着Web技术的不断发展、信息化建设的日渐成熟,在电子商务等领域Web应用平台正在得到越来越多的应用,以协同的工作环境、社交网络服务等为代表的Web技术,在很大程度上正在改变人们工作和交流的方式。不过,这些新技术的发展,一方面使商业活动更加方便地发展,但与此同时也带来了巨大的安全隐患。跨站脚本攻击(Cross-site Scripting,XSS)是这些安全隐患中危害性比较大,存在范围比较广的一种漏洞攻击。目前已有的XSS漏洞检测挖掘工具和技术还不够完善,存在检测速度较慢、漏报率高等缺点[1]。
现有的工具如 Acunetix Web Vulnerability Scanner,Paros,xenotix等软件都可以扫描检测Web应用程序存在的XSS漏洞。不过这些软件在功能上均存在一些不足。如Acunetix Web Vulnerability Scanner 对框架式的Web应用程序及含参超链的分析存在着不足。Paros 3.2.13针对可疑点测试时所使用payload较少而且缺乏可定制性,测试不完全,易造成漏报。而xenotix只能针对一个URL进行分析,而且需要人工干预(查看页面是否有对话框弹出),因此功能比较局限。
针对以上问题,本文提出了一种基于漏洞挖掘检测模型设计的工具(下称MJ Vulnerability Mining Tool),包括网络爬虫模块和漏洞扫描模块。它将对多种前端漏洞进行扫描,会对一些可能出现XSS漏洞的切入点进行分析处理。在爬虫部分,针对漏洞挖掘系统的需求进行了优化,省去了很多不必要的页面的爬取,节省了时间和系统资源。在漏洞挖掘部分,使用了自动与人工判断相结合,亦即Fuzzing技术,取得了效率和准确性的平衡。相比于 Acunetix Web Vulnerability Scanner,Paros等工具,降低了漏报率。
1 系统架构
系统架构如图1所示:
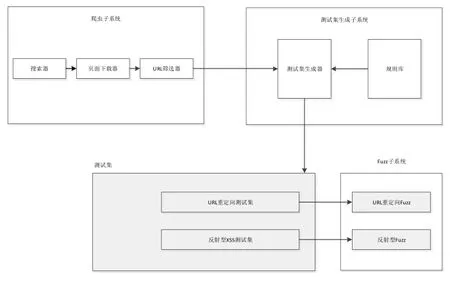
图1 MJ Vulnerability Mining Tool的系统架构
包括爬虫子系统、测试集生成子系统、测试集、Fuzz子系统四部分组成。出于对效率的考虑,子系统都使用了多线程。
爬虫子系统(下称MJ Crawler)包含了搜索器,用来进行URL的检索和提取。页面下载器,用来发送HTTP请求并且接收网页的响应数据。URL筛选器,对不属于挖掘范围的URL进行过滤,提高整体效率。
测试集生成子系统主要是通过一个既定的规则库来对爬虫爬取的URL进行一个分类,生成对应的测试集。
测试集子系统包含两个测试集。分别为URL重定向测试集、反射型XSS测试集,分别对应了两种不同的漏洞。
Fuzz子系统则是非常关键的一个部分,因为它对于挖掘的结果有着最为直接的影响。这里对于不同的测试集有不同的Fuzz系统。
2 爬虫子系统
网络爬虫(Crawler)是指通过网页中的超链接地址来遍历寻找网页的程序,它从网站的某一个页面开始(通常是主页),读取网页的内容,检索出网页中的所有超链接地址,然后将这些链接地址加入队列中,寻找下一个网页,如此一直循环下去,直到便利抓取这个网站的所有网页。爬取网络的策略大致分为两种:深度优先和广度优先[2]。
2.1模块结构
页面获取模块:读入起始URL,然后开始搜索。搜索完成后发送GET/POST请求数据,将相关的response下载下来。一般通过多线程实现以提高运行效率。
页面分析模块:得到下载下来的response,对其进行分析,将页面中所包含的链接提取出来。
链接过滤模块:分析页面分析中提取到的链接信息,例如删除重复URL、无关URL等。
链接队列模块:包含一个由URL组成的队列。
2.2页面分析
对于Web页面的分析是整个爬虫流程的重点,如图2所示:
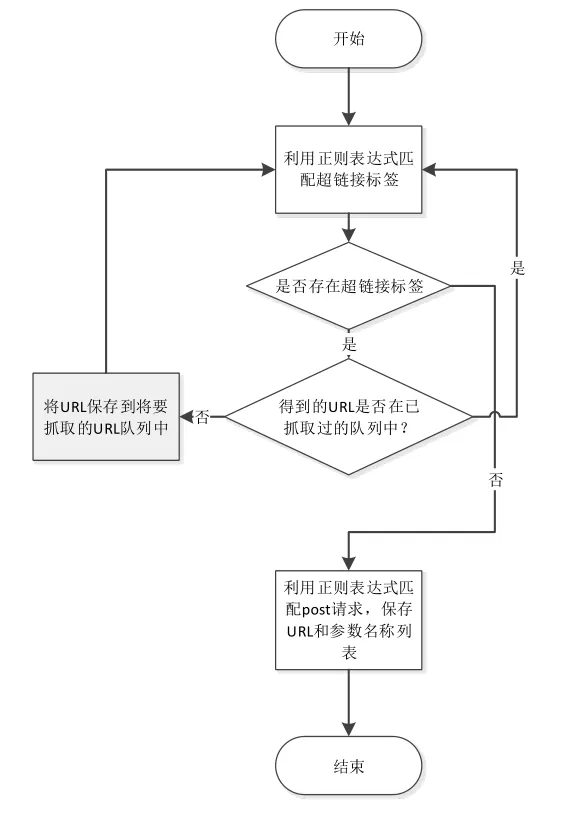
图2 爬虫的页面分析部分流程图
常用的方法是在服务器返回的HTML响应中查找超链接标签。缺点在于效率不高,而且可能无法正确处理表单,对Web的页面的分析产生偏差或者是错误。而本文设计的工具在分析Web页面时通过正则表达式来匹配,以匹配出需要的信息,无论从效率还是准确性的角度上来说都更胜一筹。
例如在处理这类链接时,使用如下的正则表达式:
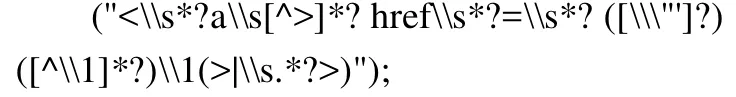
在提取出该标签中的URL后,再进一步对其进行处理将其转换为绝对路径。然后需要对这个绝对路径进行一个过滤操作,将不属于需要挖掘的站点的URL过滤掉。对于页面中的表单同样采取自定义的正则表达式进行处理从而获取所需要的数据。
标签