
基于LBP特征和AdaBoost的行人检测方法
2016-09-24 02:13王德才秦亮曦广西大学计算机与电子信息学院计算机系南宁530004
河北软件职业技术学院学报 2016年3期
王德才,秦亮曦(广西大学 计算机与电子信息学院 计算机系,南宁 530004)
基于LBP特征和AdaBoost的行人检测方法
王德才,秦亮曦
(广西大学 计算机与电子信息学院 计算机系,南宁 530004)
行人检测在智能汽车、监控系统和高级机器人等领域有广泛的应用。针对低分辨率和需要实时处理的行人检测应用场景,提出了采用一致化LBP直方图特征结合AdaBoost分类器的高效行人检测方法。在AdaBoost的训练过程中,采用了CART(Classification And Regression Tree)作为弱分类器,并结合基于Gini不纯度的剪枝方法,有效地提高了训练速度和分类器的性能。针对Caltech行人检测数据集的实验结果表明,基于LBP特征和CART弱分类器的AdaBoost分类行人检测方法具有较好的性能。
行人检测;局部二值模式;AdaBoost方法;分类回归树
行人检测[1](Pedestrian Detection)技术是计算机视觉学科中快速发展的一个领域,其研究成果在智能汽车、监控系统和高级机器人应用等方面起着十分重要的作用。行人检测的研究来源于各类应用的真实需求,有很强的应用背景和市场价值,比如在汽车辅助驾驶系统和视频场景监控等领域,行人检测已经开始广泛应用。行人检测的研究成果最终要为应用服务,传统的行人检测平台如车载辅助驾驶系统往往采用复杂和昂贵的采集设备来获取较高质量的视频或图像输入,并且使用专用计算设备来提高处理速度。而近年来计算机硬件能力的快速提高使得嵌入式设备以及移动智能设备已经基本具备实时行人检测的能力,为行人检测系统的小型化和快速普及带来了机遇。本文基于这一考虑,针对低分辨率和实时处理的应用场景,提出了采用一致化LBP直方图特征结合AdaBoost分类器的高效行人检测方法。
1 LBP特征
1.1LBP的基本概念
LBP[2](Local Binary Pattern,局部二值模式)是一种用来描述图像局部纹理特征的描述符(Operator),LBP被提出以来,由于其简单有效的特点,被广泛应用于运动对象检测等场合。
原始的LBP描述符(LBP Operator)定义为在3*3像素的窗口内,以窗口中心即第二行第二列的像素的灰度值为基准,与其相邻的8个像素的灰度值进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0,因此被命名为“二值模式”。
LBP算子有效地提取了图像某一小块区域内的灰度变化特征,这是因为对于恒定的区域,所有方向的灰度值差均为0。对于缓慢的斜边,该算子记录了梯度方向最大的差值,沿着边的方向差值为0。
对于独立于背景的一个斑点,所有方向的差分都很大。总之,对一幅图像提取其原始的LBP值,用所得的LBP值应该仍能有效表示该图片。
1.2一致化LBP模式
LBP描述符经过扩展后将形成不同二进制模式,以最常用的圆形区域LBP描述符为例,在采样区域含有N个像素点的LBP运算符共有2N种模式。由于过小的采样区域无法描述足够的图像信息,常见的N取值都较大,而较大的模式取值范围形成了典型的高维描述符,给进一步有效处理带来了很大困难。同时,过多的模式种类对于纹理的表达是不利的。针对这一情况,学者们提出了多种解决办法。LBP原作者提出的一致化LBP模式[3](Uniform LBP,又称为均匀模式)是其中一种重要方法。这一方法建立在大量统计结论的基础之上,即如果将二进制数字串出现从0到1或者从1到0的一次变化称为跳变,则真实图像中大部分LBP模式二进制字串最多只会出现两次跳变。例如1111111111左移一位还是1111111111,没有跳变,即跳变次数为0,这两个二进制串互为Uniform;000011111左移一位为000111110,跳变次数为2,这两个二进制串互为Uniform;10100000左移一位为01000001跳变次数为3,这两个二进制串不互为Uniform LBP。根据Unifrom的定义,对LBP模式值的定义可以更新为针对Uniform模式的公式(1):

在上式中,函数U被定义为公式(2):

根据上述定义可以推导出在256位的LBP模式中,Uniform格式占85%~90%,而256位LBP模式下,Uniform LBP共有58个特征。所以256位的LBP分类特征向量可以由256维降为58维+1维共59维,多出来的1维指代所有不是Uniform LBP的特征向量。
Ojala等人的研究指出,Uniform LBP在局部纹理描述上取得了较好的描述效果,原因在于,U-niform LBP的各种模式占据了图像中所有模式的绝大部分。不同采样半径和周围像素点个数会不同,但大量统计证明,Uniform LBP占据了所有模式的50%~95%。
1.3LBP直方图
在基于LBP的行人检测过程中,虽然可以考虑将LBP模式特征直接作为弱分类器中的训练特征,但出于特征降维等考虑,一般都是采用图像中LBP模式的统计直方图作为该图像的特征向量,即建立一个直方图,以LBP的种类为横轴,以每个种类出现的次数为纵轴。在实践中,通常采取的步骤为:
(1)将图像划分为S*S的图像子块,计算每个子块中每个像素的LBP值。
(2)对每个子块进行直方图统计,得出S*S图像子块的直方图。
(3)利用S*S个子块的直方图,描述该图像的纹理特征。
上述过程如图1所示。

图1 分块LBP特征级联形成图像特征
2 AdaBoost方法
2.1AdaBoost方法
在机器学习中,Boosting通常代表一类能够提高任意给定学习算法准确度的方法,也就是说具有很强的通用性。Boosting算法最早出现在Valiant提出的PAC(Probably Approximate Correct,近似精确)学习模型中[3]。Valiant和Kearns提出了两个概念,即“弱学习方法”和“强学习方法”,前者指代在二值判断问题中,准确率仅略微高于随机猜测,即正确率略微高于50%的判别方法;后者则具有较高的准确率,并能在多项式时间内完成。
在Boosting算法的基础上,Freund和Schapire进一步提出了自适应增强的Boosting算法,简称AdaBoost[4]。其算法的一般流程如表1所示。

表1 AdaBoost算法流程
从上述算法描述中可以看到,弱分类器在AdaBoost中起着关键作用。一个弱分类器由一个特征y,阈值t和指示不等号方向的p组成,如公式(3)所示。

在AdaBoost中选取一个最佳弱分类器,就是选择那个对所有训练样本的分类误差在所有弱分类器中最低的那个弱分类器。许多能有效解决数据分类问题的算法,都可以被AdaBoost算法用作弱分类器,其他常用的弱分类器包括CART(Classification And Regression Tree,分类回归树)、GD (Gradient Descend,梯度下降方法)、SVM(Support Vector Machine,支持向量机)等等。
本文将采用改进的CART作为AdaBoost的弱分类器。
2.2CART弱分类器
CART[4]的基本原理是通过二分递归分割技术生成二叉树。过程是通过每次决策将当前的样本集分为两个子样本集,使得生成的决策树的每个非叶子节点都有两个分支。决策树的叶节点表示决策,内部每个分支都是决策过程。从根部开始,每个决策结果指向下一层决策,最后到达叶节点,得到最终的决策结果。
下面讨论CART算法的两个主要步骤,即建树过程和剪枝过程。
2.2.1CART建树过程
前面已经提到CART算法的基本原理是运用递归划分技术生成二叉树。这里假设待分类的样本有n维特征,表示为向量X(x1,x2,x3,…,xn),而Y为所属类别。具体递归划分过程为:
第一步:选择特征中的一维,在其取值范围中选取一个阈值delta,以该阈值为分割点,将n维特征空间划分为两部分。
第二步:递归上述步骤,即选取特征中新的一维,再次划分,直至将n维空间全部划分完毕。
上述过程的关键在于如何选取划分点。对于本文所述的图像LBP特征来说,判断待检测图像包含或不包含行人特征是典型的分类问题,于是在应用CART算法进行分类时,需要先列出划分为两个子集的所有可能组合,并通过计算某种度量(Metrics)来比较每种组合划分的优劣。可用作CART划分判断的度量有多种,如信息增益(In formation Gain)、方差约简(Variance Reduction)等,但最常用的是采用Gini Impurity(Gini不纯度)来表示当前分类的杂乱情况。具体计算时,Gini impurity衡量的是从一个集合中随机选择一个元素,基于该集合中标签的概率分布为元素分配标签的错误率。对于任何一个标签下的元素,其被分类正确的条件概率可以理解为在选择元素时选中该标签的概率与在分类时选中该标签的概率。
对于有m类样本的集合,设i∈{1,2,…,m},令fi表示属于第i类,则Gini Impurity的计算方式如公式(4)所示:

在公式(4)中,即1减去所有分类正确的概率,得到的就是分类不正确的概率。当IG(f)为0时,当前分支下的所有样本已经属于同一类。
在划分点选择时,计算不同选择的Gini不纯度,选择使该不纯度较小的划分方式,即可不断递归生成CART分类树。
2.2.2CART剪枝过程
在CART的建树过程中,由于训练数据中的噪音或孤立点,许多分枝反映的是训练数据中的异常,即产生了过拟合(Over Fitting)。使用这样未经处理的决策树对类别未知的数据进行分类,分类的准确性不高。因此需要通过一定的方法检测并删去这些分支,这一过程被称为剪枝(Pruning)。与常见的剪枝方法不同,CART的剪枝是已经建立决策树后,再去掉不必要的分支或子树,即所谓后剪枝(Later Pruning)。通过有效的剪枝,可以简化决策树的区分过程,实现快速分类,并且解决过拟合问题造成的泛化能力下降问题。有研究表明,剪枝过程对于生成最优决策树十分关键。
CART常用的剪枝方法包括错误率降低剪枝、悲观剪枝以及代价复杂度剪枝等,其中代价复杂度剪枝方法所生成的决策树性能较好,其算法步骤如下:
第一步:输入为由CART算法所生成的一棵原始决策树T0,并设k=0,T=T0,α=+∞。
第二步:从子树序列中,根据树的真实误差估计选择最佳决策树,具体做法是:自下而上对CART树中的各个内部节点t计算R(t)=r(t)*p (t),其中r(t)为节点t的误差率,p(t)为节点t上的数据占所有数据的比例。然后以R(t)带入下式计算每一个内部节点作为根所对应子树T的误差值alpha,如公式(5)为:

第三步:自上而下的访问各个内部节点t,如果有

则剪去t为根的子树,并对剩下的叶节点t以多数表决法确定其类。
第四步:调整k=k+1,αk=α,Tk=T
第五步:如果T还有叶子节点,则继续第三步的判断和剪枝过程。
第六步:采用交叉验证法在子树序列T0,Tk1,Tk2,…,Tn中选取最优子树 T0作为剪枝的输出结果。
由于CART方法在生成树中引入了不纯度进行判断,并在剪枝过程中引入CCP代价复杂度,因而在处理高维特征以及样本包含缺失值、异常值等情况下比简单Decision Stump方法更为稳定;同时,算法规则较为简便,运行效率高,适合用于作为AdaBoost算法中的弱分类器。
3 分类器检测过程
通过分类器训练过程得到级联分类器后,就可以用于行人检测。级联分类器的检测过程如图2所示。

图2 级联分类器行人检测过程
在图2中,待检测的图像在经过降噪等预处理之后进入检测过程。这一过程的细节如下:
(1)先以一定的比例将原始大小的图像缩小为若干不同尺度,一般可将原图像每次缩小60%~80%。
(2)用n×n的滑动窗口遍历每个尺度的图像,并循环将滑动窗口覆盖区域送入级联分类器分类。
(3)分类器实现对n×n大小子图片的分类判断,并记录相应位置。
(4)进行重叠区域合并等后期处理,形成最后的检测结果。
4 实验和结果分析
实验的硬件环境为一台浪潮服务器,n×n型号为 NF5270M4,CPU为双 IntelXeonE5-2600V3,内存192 G,磁盘1T SATA*2。软件操作系统为Linux,发行版本为CentOS 6.5。
训练和测试数据集均采用加州理工行人检测数据集[5](Caltech Pedestrian Detection Dataset)。
为了比较不同弱分类器对AdaBoost训练过程的影响,本文对比了采用单层决策树(Decision Stump)、CART决策树和支持向量机(SVM)作为弱分类器进行AdaBoost训练所得级联分类器的性能。其中CART弱分类器的决策过程和剪枝过程如前文所述,而SVM分类器采用了文献[5]中的设置,采用线性SVM分类。
本实验从Caltech行人检测数据集的set0-set5中选择了3 000张图像作为训练集进行分割,并根据Annotation文件中的Ground Truth信息分离出正负例样本进行分类器训练。图3显示了这三种弱分类器所训练的级联分类器ROC曲线。
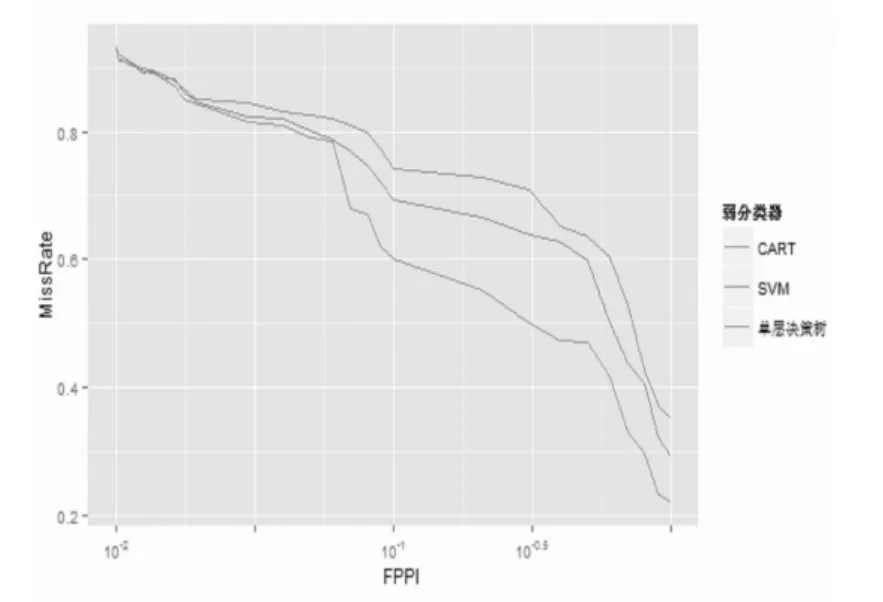
图3 三种弱分类器训练结果性能对比
从图3可看出,当弱分类器采用CART时,性能明显优于单层决策树和SVM。
5 结论
近年来,随着计算机硬件能力的快速提高,嵌入式设备以及移动智能设备已经基本具备实时行人检测的能力,为行人检测系统的小型化和快速普及带来了机遇。本文针对低分辨率和实时处理的应用场景探讨行人检测的新方法,提出基于LBP特征和CART弱分类器的AdaBoost分类行人检测方法。实验结果证明该方法具有一定的有效性。
[1]苏松志,李绍滋,陈淑媛,等.行人检测技术综述[J].电子学报,2012,04:814-820.
[2]Ojala T,Pietik&#,Inen M,et al.Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2002,24(7):971-987.
[3]Freund B Y,Schapire R.A decision-theoretic generalization of n-line learning and an application to boosting[J]. Journal of Computer&System Sciences,2010,55(7):119-139.
[4]Zhang J,Li X,Wu B.Forest Cover Estimation based on Classification and Re gression Trees of Miyun Reservoir Upstream Area[J].Remote Sensing Technology&Application,2014.
[5]Dollár P,Wojek C,Schiele B,et al.Pedestrian detection: an evaluation of the state of the art.[J].IEEE Transacti ons on Pattern Analysis&Machine Intelligence,2012,34 (4):743-761.
Method of Pedestrian Dection based on LBP Features and AdaBoost
WANG De-cai,QIN Liang-xi
(Department of computer,School of computer and electronic informatiobn,Guangxi University,Nanning 530004,China)
Pedestrian detection is rapidly evolved in intelligent vehicles,surveillance,and advanced robotics.In this work we introduce a pedestrian detection method of combining LBP(Local Binary Pattern)feature of images and AdaBoost process together to aim at low resolution pedestrian detection application scenarios which need real time processing.In the training process of AdaBoost,the CART (classification and regression tree)as weak classifiers is used,and combined with the pruning method based on Gini impurity the training speed and classification performance is effectively improved.Results of the experiments show that our method is not only efficient in processing speed but also obtain fairly accuracy.
pedestrian detection;LBP;AdaBoost;CART
TP391.41
A
1673-2022(2016)03-0051-04
2016-06-30
王德才(1982-),男,海南安定人,工程师,计算机工程硕士研究生,研究方向为计算机视觉、机器学习。
猜你喜欢
保健医苑(2022年5期)2022-06-10
成都信息工程大学学报(2021年6期)2021-02-12
计算机应用(2020年5期)2020-06-07
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
天津诗人(2017年2期)2017-03-16
光学精密工程(2016年4期)2016-11-07
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
