
基于分布式并行计算的SIFT算法
2016-09-13 08:49苏勇刚高茂庭上海海事大学信息工程学院上海201306
现代计算机 2016年20期
苏勇刚,高茂庭(上海海事大学信息工程学院,上海 201306)
基于分布式并行计算的SIFT算法
苏勇刚,高茂庭
(上海海事大学信息工程学院,上海201306)
针对SIFT算法处理较大图像库的效率低和检索结果中图像排序不合理的问题,提出一种基于分布式并行计算的SIFT算法,在Spark平台下利用K-means算法对图像特征库进行聚类,将初始图像特征库划分成若干特征簇,每一个特征可由每一类库中的单位特征向量来表示,这样就可以高效地使用多特征的相似性度量进行比较图像间的相似度,即多特征代替单一特征度量来达到优化图像检索结果排序的效果,以改善用户体验。实验结果表明,与SIFT算法相比,改进的SIFT算法在性能上得到显著提高。
SIFT;分布式;相似性度量;图像检索
国家自然科学基金资助项目(No.61202022)、上海市科委科技创新项目(No.12595810200)
0 引言
随着Internet技术的飞速发展,互联网资源从文本逐渐演变成为视频、图像等多媒体形式并存,数据量随之急剧上升,同时呈现飞速增长的态势。如何从这个海量的图像资源中快速准确地检索到用户所需的图像信息,提高图像检索的性能,就成为一个迫切需要解决的问题。
图像检索就是根据对图像内容的描述,在某个目标图像集合中找到具有指定特征或包含指定内容的图像。近年来,基于内容的图像检索技术得到广泛的关注和应用,作为一种主要的基于内容的图像检索算法,SIFT(Scale-Invariant Feature Transform)算法[1]通过求原始图像中的特征点以及尺寸和方向的描述子来得到特征,并进行图像特征点匹配,最终得出图像之间的相似度。这种方法的优势在于SIFT特征主要能够准确地进行匹配且一定程度上不受光照变化、尺寸大小和位置变化等因素的影响。然而,面对海量图像库,SIFT算法检索图像的时间开销也非常巨大,而且,它的单一特征相似性度量也较为粗糙,使得检索出的多个图像有相同的相似度,难以给出合理的排序。
针对海量图像库的检索效率,研究者借助大数据平台已经做了大量研究,例如,为了解决在处理海量数据信息所面临的存取容量和处理速度的问题,文献[2]和[3]基于Hadoop平台分别提出了基于MapReduce实现对数字图像并行化处理和一种基于传统视觉词袋(BoVW)模型结合MapReduce计算模型的大规模图像检索(MR-BoVW)方案,实验证明在处理海量图像库时,借助Hadoop能极大地提高图像检索性能,但它采用离线方式进行批处理,不能实时处理。与Hadoop类似,Spark[4]也是一个大数据平台,采用基于内存计算的并行处理框架且在迭代计算上具有较高的效率,为用户的实时体验提供了有利保障。
在对检索结果图像的排序方面,研究者也提出了很多实用方法,例如,利用视觉特征[5]对图像进行重排序以及引入重排序机制的相关反馈方法[6],重排序方法的改进可提高检索的准确率和满足实时性的要求。
特韦尔斯基(Twersky)认为相似性不能依赖于普通的长度单位来度量,而是定义一个对比模型作为一种参考[7]。本文借鉴对比模型的思想改进相似度度量,借助Spark大数据平台,提出一种基于分布式并行计算的SIFT算法,Spark平台下利用K-means算法对图像特征库进行聚类,将初始图像特征库划分成单位图像特征库,每一个特征可由每一类库中的单位特征向量来表示,这样就可以高效地使用多特征的相似性度量进行比较图像间的相似度,从而提高图像检索效率,最后,在图像相似度上,采用多特征代替单一特征度量来达到优化图像检索结果排序的效果,以改善用户体验。
1 基本概念
1.1相似性度量
图像特征相似性度量技术是基于内容的图像检索的核心。度量图像相似性的方法很多,有的用于专门领域,有的适用于特定类型数据,用于图像检索的相似性度量方法主要分为距离度量和图像特征度量。本文所用的是一种距离度量的直方图距离。
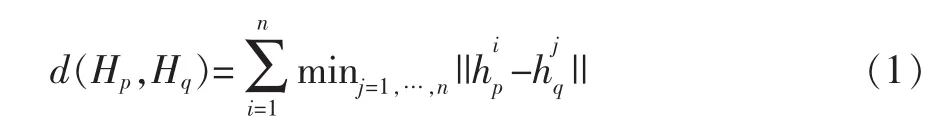
1.2图像检索性能评价指标
评价图像检索性能指标的是查准率和査全率,这两个指标是图像检索领域最基本的评价指标,分别反映检索系统的两个最重要侧面。查准率是对图像检索系统信噪比的衡量指标,即检索结果中与查询样例内容相关的图像数目与检索出的图像总数目的比例;査全率是对检索系统成功率的衡量指标,即检索结果中与查询样例内容相关的图像数目与图像库中全部相关图像数目之比,如式(2)所示。

式(2)中,A为检索结果中与目标图像准确相关的图像数量,B为检索结果中与目标图像不相关的图像数量,C为图像库中与目标图像相关,但未检索到的图像数量。
1.3Spark平台介绍
Spark是 UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用并行框架,由加州大学伯克利分校AMP实验室开发,可用来构建大型的、低延迟的数据分析应用程序。Spark作为一种并行处理框架,具有Hadoop的一些优点,而且,它有更好的内存管理机制,在迭代计算上具有比Hadoop更高的效率。尽管创建Spark是为了支持分布式数据集上的迭代作业,但是实际上它是对Hadoop的补充,可以在Hadoop文件系统中并行运行。
2 基于分布式并行计算的SIFT算法
1999年,Lowe[8]首次提出了SIFT特征的概念,随后在2004年得到完善。SIFT算法是一种机器视觉的算法,它可用来提取和描述图像的局部特征。SIFT特征主要能够准确地进行匹配且一定程度上不受光照变化、尺寸大小和位置变化等因素的影响。SIFT算法的主要思想是将图像之间的相似性度量转化成特征点向量之间的相似性度量。SIFT算法具有广泛的应用,其中主要包括图像检索、视觉跟踪和三维重建等。
2.1SIFT算法及其分析
根据SIFT算法的概念,SIFT算法的基本步骤如下:
第1步,生成尺度空间。
目前,相关研究者们大多运用Lowe[5]的高斯差分尺度空间来作为二维图像的尺度空间,其公式为:
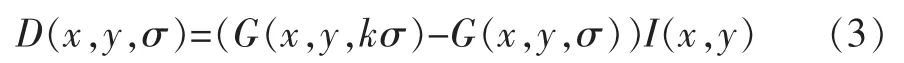
式(3)中,G(x,y,σ)是尺度可变的高斯函数;采用高斯差分尺度空间来寻找极值点,是为了有效检测到关键点。
第2步,检测尺度空间极值点。
每一个样本点和它周围同尺度的8领域点进行比较是否为极值点。
第3步,精确定位极值点。
为了精确定位极值点,可通过拟合泰勒公式展开的三维二次函数达到此效果;这样同时也可以去除不稳定的边缘噪点和低对比度的关键点,也即提高抗噪能力。
第4步,为每个关键点指定方向参数。
每个关键点方向为参数是由关键点领域像素的梯度方向分布特性决定的,一个关键点可能会被分配多个方向,其中一个是主方向,其他的是辅助方向,这样可以增强图像特征匹配的鲁棒性。
第5步,生成关键点描述子。
指定完每个关键点的方向,然后接下来为关键点生成描述子;其中描述子一般是由4×4×8维向量特征,也即是4×4组8个方向的梯度方向直方图;对于一个关键点产生32个数据,即最终形成128维的SIFT特征向量。一般需要对特征向量的长度进行归一化处理,则可以去除光照变化的影响。
第6步,根据SIFT特征向量来计算两幅图像的相似度。

图1 SIFT算法的图解过程
下面以一个实例图解SIFT算法来计算两幅图像的相似度,设有两幅大小一致的红花朵图像,如图1所示。
若相似度系数越接近0,则表示两幅图像越相似。
分别利用SIFT算法对两幅图像进行特征提取,然后利用两幅图像的描述子 (分别是k1×128维和k2× 128维),将其每个描述子按照梯度大小(scale)来映射到直方图的各个方向的的局部子直方图中,如图1所示,红花a图对应的描述子直方图集合另一幅图红花b图对应的描述子直方图集合Hb=则计算Ha和Hb的距离公式为:
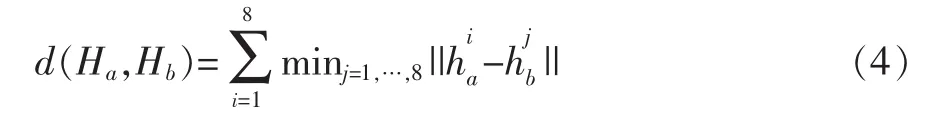
那么它们的相似度系数为:

参照文献[9]以及本文的实际情况,
若,0≤α≤0.4则两幅图像相似。
若α≥0.4,则两幅图像不相似。
最后通过计算得到它们的相似度系数为0.14,则说明两幅图像相似。
根据上述SIFT算法的基本步骤,分析了SIFT算法的不足:一是,提取出每幅图像的SIFT特征比较单一和粗糙(局部的图像特征代替整个图像特征);二是,随着图像库容量的迅猛增长,SIFT算法的计算效率也随之大大下降。
2.2基于分布式并行计算的SIFT算法
由于SIFT算法利用局部的图像特征来进行图像的检索,也就说用局部的图像特征代替整个图像特征,从而导致查准率降低了;为了提高查准率,这就需要对图像进行分块以及再对分块的图像提取SIFT特征,但在这个过程中图像分块和提取各分块图像的SIFT特征会大大降低图像检索效率。为了提高检索效率,本文通过Spark平台处理大规模的数据集图像来并行提取SIFT特征,从而降低算法的复杂度,这就是所谓的并行计算策略。
改进的SIFT算法具体的过程如下:
第1步,特征集的提取。
此步骤中包含了SIFT算法的第一到第五步,这里就不在详细地描述。为了实现分布式的提取SIFT特征,即需要对原始图像进行分块,图像分块原则是将图像分成每块大小为N×N像素的块图像,这样有利于比较块图像之间的相似性,再对每一块图像进行生成高斯差分尺度空间,再检测极值点和计算描述子,最终实现了特征提取。如图2所示。
第2步,特征库构建。
特征库指的是SIFT特征向量的集合,也就将第一步中输出的结果进行保存。构建特征库是为了节约磁盘容量和提高图像检索的效率,因为随着图像库容量的增长,检索的效率会大大下降,同时数据存储成本也越来越大。特征库的建立可以将这些特征向量集一一对应着图像库中的每幅图像,也即达到了节约存储容量的效果。
第3步,特征库归类。为了进一步节约存储成本和较快匹配特征,就需要将这些特征向量进行分类。由于SIFT的特征向量一般是128维向量,也是基于欧氏空间的。K-means主要用于基于距离进行聚类的算法,即可以对这些特征向量集进行分类。特征库中的所有特征向量经过K-means算法聚类后生成基本映射特征库S,该特征库集合可表示为:
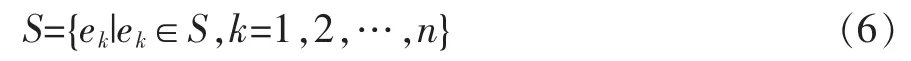
其中ek表示任意一个单位映射特征,n表示单位映射特征总数。由此可看出每个单位映射特征是基于欧氏空间的128维特征向量,特征库被分成了n个簇,也即第特征向量可有表示为:

其中,αiei表示单位映射特征ei在第特征向量中出现的αi次。
第4步,特征匹配。
依据上述的特征表示公式得知,第β个特征向量可有ek表示为:

则两个特征的匹配公式如下所示:


图2 SIFT特征集的提取
参照文献[10]以及本文的实际情况,
若0≤p(α,β)≤0.4,则两个特征相匹配。
若p(α,β)>0.4,则两个特征不相匹配。
第5步,输出匹配的结果。
一般一幅图像包含多个特征,即图像间的匹配就意味着图像的多特征匹配。
本文采用的是匹配原则是以一个主特征为主,其余的特征为辅。
3 实验过程与分析
Corel图像库是一个人为整理且根据先验知识对图像进行划分的图像库,它被研究者们当作图像检索领域的测试图像标准库。Corel图像库的种类繁多,目前包含了数十万幅图像。从实验的硬件环境出发,在Corel图像库[10]中选取10000幅图像,进行测试与分析,这些图像分为十个类别,每类1000幅,分别为花、巴士、食物、大象、建筑、骏马、恐龙、人脸、天空和雪山。对于本文提出的基于内容的检索算法所要处理的图像库而言,首先将已分类好的图像库进行打乱,为了使其满足本文算法的图像库要求。实验硬件平台为2.67GHz主频的CPU,可用内存3.87G,软件开发工具Eclipse,开发语言Java,并基于Spark平台对原图像库中的每幅图像进行分块并行计算提取SIFT特征。
3.1实验过程
实验分成三个对照实验,将SIFT算法与改进的SIFT算法进行比较,从而验证改进的SIFT算法比SIFT算法有更好的性能并且用户的体验效果更佳。实验一:将这两种算法分别运用基于内容的图像检索基本系统,然后分别在其中查询相同的目标图像,最后比较它们的查准率,目的是为了通过评价它们检索的性能来验证改进的SIFT算法性能更优;实验二:改进的SIFT算法与传统SIFT算法在不同规模的图像库下,通过对比其平均检索时间来比较它们的时间复杂度,目的是为了验证改进的SIFT算法在检索大规模图像集的图像库时的时间复杂度较低,即在用户可接受范围之内;实验三:传统SIFT算法与改进的SIFT算法分别应用于基本的内容的检索系统中,查询相同的目标图像,通过对比返回的候选检索结果排序,目的是为了验证改进的SIFT算法检索出的图像页面排序更合理和便于用户友好的交互。
3.2结果与分析
实验一是SIFT算法与改进的SIFT算法对图像库中三类(花、大象、骏马)的查准率,见表1。

表1 传统SIFT与改进的SIFT对某几类图像库的查准率对比
从表1可知,改进的SIFT算法对各类平均查准率较传统SIFT算法高约20%,说明改进的SIFT算法优势明显。
实验二是改进的SIFT算法与传统SIFT算法在不同规模数据量时的时间复杂度进行对比,结果详见图3。
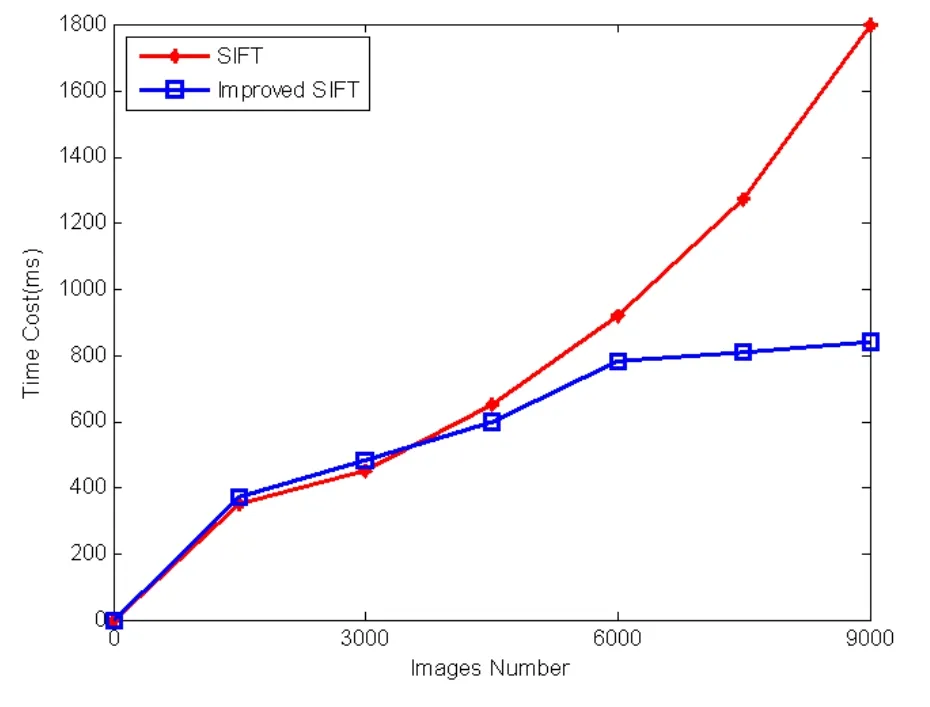
图3 SIFT算法与改进的SIFT算法运行时间对比
从图3可以看出,随着图像库的规模增大,传统SIFT算法时间代价增长较快,而改进的SIFT算法时间代价增长相对较缓,改进的SIFT算法的运行效率明显优于传统SIFT算法。
实验三为传统SIFT算法与改进的SIFT算法对候选检索结果排序的对比,结果详见图4。
图4为待查询图像为红色花朵图像b(如图1)时的候选检索结果,图4(a)的SIFT算法页面查询结果中的候选图像根据比较单个SIFT特征值来排序,从而导致图像的排序比较粗糙和单一,即会影响到用户的友好体验;而图4(b)的改进的SIFT算法页面查询结果中候选图像则依据图像的多个SIFT特征值的相似度大小来排序,从而会使图像的排序更加合理和多样化,最终会改善用户的体验。
4 结语
本文提出了基于分布式并行计算的SIFT算法,该算法不需要用户对检索结果评价的样本,也不需要控制图像库数据集大小,运用了分布式的并行计算框架,对分块的图像并行地提取各自的SIFT特征值,然后对提取出来的SIFT特征值利用K-means进行聚类,找出每个类库中的单位特征向量,使得每个SIFT特征向量可由单位特征向量组成,然后在计算图像间的相似度时,利用多特征代替单一特征度量,不仅适应海量图像的检索,而且检索结果的图像排序也更加合理。实验结果表明,这种基于分布式并行计算的SIFT算法有效地解决了图像检索的数据集扩张局限和候选图像集的不合理排序等问题,从而便于有效地提高了用户交互体验。

图4 两种算法候选结果排序
[1]ZK Wen,WZ Zhu,Quyang-Jie,et al.A Robust and Discriminative Image Perceptual Hash Algorithm[C].2010 Fourth International Conference on.IEEE,2011∶709-712.
[2]田进华,张韧志.基于MapReduce数字图像处理研究[J].电子设计工程,2014.
[3]朱为盛,王鹏.基于Hadoop云计算平台的大规模图像检索方案[J].计算机应用,2014.
[4]Zaharia M,Chowdhury M,Franklin M J,et al.Spark∶Cluster Computing with Working Sets[J].Book of Extremes,2010,15(1)∶1765-1773.
[5]陈畅怀,韩立新,曾晓勤,等.基于视觉特征的图像检索重排序[J].信息技术,2012
[6]杨德三,李明,刘玲.一种新的基于重排序的相关反馈图像检索方法[J].计算机工程与应用,2008
[7]A.Twersky.Features of Similarity.Psychological Review,84,No 4∶327-352,July 1977.
[8]David G.Lowe.Object Recognition from Local Scale-Invariant Features[C].International Conference on Computer Vision,Corfu,Greece,1999.9.
[9]David G.Lowe.Distinctive Image Features from Scale-Invariant Keypoints[J].International Journal of Computer Vision,2004.
[10]Wang J Z's Research Group,The Pennsylvania State University.Test Image Database[EB/OL].[2005-10-08].
Sift;Distribution;Similarity Measure;Image Retrieval
SIFT Algorithm Based on Distributed Parallel Computing
SU Yong-gang,GAO Mao-ting
(College of Information Engineering,Shanghai Maritime University,Shanghai 201306)
To overcome the problem that the SIFT algorithm handles large amount of images in lower efficiency and the sequence of the result images is unreasonable,proposes SIFT algorithm based on distributed parallel compute,the new algorithm utilizes K-means algorithm to cluster initial image feature library,divides these features into several feature clusters,every feature can be expressed by each unit feature vector in every cluster so that it can effectively use multi feature similarity measures compare the similarity between images,namely multi feature instead of a single feature to optimize the sort of the retrieved image set and improve the user's experience.Experimental results show that compared with the SIFT algorithm,the improved algorithm has been significantly improved in performance.
1007-1423(2016)20-0018-06
10.3969/j.issn.1007-1423.2016.20.004
苏勇刚(1992-),男,江苏盐城人,硕士,研究方向为图像处理、数据挖掘
高茂庭(1963-),男,江西九江人,博士,教授,研究方向为智能信息处理、数据库与信息系统
2016-04-25
2016-07-05
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
上海文化(文化研究)(2022年3期)2022-06-28
保定学院学报(2022年2期)2022-04-07
河北画报(2020年8期)2020-10-27
五邑大学学报(自然科学版)(2019年3期)2019-09-06
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
数学学习与研究(2018年15期)2018-11-12
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
