
基于网络搜索数据的区域经济预警研究
2016-09-01 09:47李方一肖夕林刘思佳
华东经济管理 2016年8期
李方一,肖夕林,刘思佳
(合肥工业大学 管理学院,安徽 合肥 230009)
基于网络搜索数据的区域经济预警研究
李方一,肖夕林,刘思佳
(合肥工业大学 管理学院,安徽 合肥 230009)
摘要:网络搜索直接反映了互联网用户的行为与心理,随着用户的不断增长,海量的网络搜索数据对社会经济发展趋势的指示作用不断被发现并研究。文章以安徽省为例,选取区域工业增加值等指标为预测目标,基于经济波动与大数据的相关理论,运用K-L信息量法与时差相关性分析对大量国际国内经济指标与特定关键词的百度搜索指数进行筛选,得到区域经济先行指标,建立区域经济预警模型,并对模型进行了拟合检验和预测检验。结果显示,部分关键词的网络搜索数据能够有效地用于预测区域工业增加值和社会消费品零售额的月度变化,预警模型具有较好的准确性与时效性,可为政府、企业应对经济波动提供决策参考。
关键词:经济波动;先行指标;网络搜索数据;K-L信息量法;区域经济
[DOI]10.3969/j.issn.1007-5097.2016.08.010
一、引 言
随着经济全球化步伐的加快,区域经济受世界经济环境的影响越来越大,经济波动也越来越成为一个普遍的现象。短期的经济波动对未来经济的发展有一定的促进作用,但频繁而剧烈的经济波动会对企业造成负面影响,阻碍经济的健康发展。为了保证经济恢复正常平稳运行,政府会制定相应的财政政策或货币政策,来平抑经济波动,减小经济波动的影响。寻求经济波动的内在规律,对经济波动进行预警,对于提前采取应对措施、实现事后经济迅速恢复具有重要的意义。
近年来,经济先行指标的筛选和验证已逐渐形成一个成熟的研究领域,在宏观经济指标预测的研究中应用较为广泛[1]。国外学者Banerjee等[2]利用先行指标预测欧元区的通货膨胀以及国内生产总值增长率,得出劳动力市场变化、价格、出口以及政府支出这四个因素对预测欧元区甚至是美国的通货膨胀都有所帮助。晏露蓉等[3]从基准指标选取、指标体系构成和先行指数编制等三个方面对国内外经济运行先行指标体系进行了比较分析。陈可嘉和刘思峰[4]选用了能源与原材料类、投资类、生产类、财政类、货币与信贷类、消费类、对外经济类、物价类、指数类等9大类24项指标,应用K-L信息量法进行经济指标时差分析,确定了经济周期波动监测预警的先行指标、同步指标与滞后指标。王海慧和张建平[5]从先行地区、先导行业两个全新的视角展开分析和论证,运用格兰杰因果检验、时差相关分析、主成分分析等方法,构建了经济波动的预测指标。传统的经济先行指标往往来自于统计数据,受到准确性与时效性不足的制约,随着信息技术与互联网的发展,来自于互联网的全样本或大样本数据受到越来越多学者的关注。
使用搜索引擎记录的关键词进行预测具有预测精度较高、数据获取及时、样本统计意义明显等优势,2008年以来,许多学者基于这一类型数据对相关经济问题做出研究[6-8]。国外有关网络搜索数据的研究方面已涉及经济、社会及健康等领域,其中的著名案例是Ginsberg等[9]发现Google中与流感相关的部分关键词搜索量与美国疾病控制和防治中心发布的流感看诊数据有很强的相关性,以此构建了基于Google搜索数据的监测模型,比传统模型提前两周测算流感爆发趋势;Francesco、Amuri等[10]利用Google搜索数据建立工作搜索指数来预测美国的失业率,发现通过搜索指数修正后的模型,预测效果显著高于传统模型;Choi、Varian[11]根据部分网络搜索数据与典型行业当期销售量之间的相关关系,建立了典型行业当期销售量预测模型,取得良好的预测效果。国内学者袁庆玉等[12]引入网络关键词搜索数据,以预测汽车销量;张崇等[13]、孙毅等[14]研究了网络搜索数据与通货膨胀、CPI的关系;彭赓等[15]通过建立基于网络搜索数据的逐步回归改进模型,实证分析预测失业率,最后得出结论,运用网络搜索数据进行失业率预测能显著提高预测准确性。此外,网络搜索数据还应用于房价预测[16]、旅游人数预测[17-18]、股票市场[19]、风险感知[20]、消费者信心指数构建[21]等研究领域。由此可见,网络搜索数据研究逐渐成为指标预测领域一个新的研究方向,并逐步显示出它的优越性。尽管网络搜索数据已经运用到对失业率、CPI及房价指数的预测,但基于网络搜索数据对区域经济波动的预警研究还较为少见,宏观经济研究将是网络搜索数据应用的一个重要的新兴领域。
根据网络信息中心公布的第三十五届中国互联网发展报告,截至2014年12月,我国网民规模达6.49亿,互联网普及率为47.9%[22]。互联网成为众多网民获取信息的主要方式,搜索引擎的广泛使用,其在满足用户信息需求的同时也记录了用户的搜索行为,从而使得基于互联网的搜索数据蕴含着用户的关注及意图,能够映射用户在现实生活中的行为趋势和规律。百度指数是由百度公司2006年推出的一款基于百度海量网民行为的数据分享平台,以关键词为统计对象,科学分析并计算出各个关键词在百度网页搜索中搜索频次的加权和,并以曲线图的形式展现,可以反映与该关键词相对应的某类事物的热门程度和被关注程度。通过筛选一些与经济相关的关键词搜索频率,来反映公众对经济走势的判断,从而预测经济的波动,具有重要的研究意义。
本文基于大量经济指标与百度搜索引擎中的关键字指数,来构建区域经济预警模型,克服传统预测方法信息来源受限、数据公布滞后而造成的预测滞后、解释变量过少、预测误差过大等问题。研究以安徽省为例,选取了工业增加值和社会消费品零售总额等指标来反映区域经济状况,探究区域经济与百度搜索指数间的时差相关关系,然后建立多元线性回归模型,以预测区域经济的发展趋势,达到预警效果。研究成果能为政府与企业决策提供参考依据,及时缓解经济不规律波动对实体经济的冲击。
二、方法与数据
(一)研究思路
研究将分为以下几步:
(1)验证可行性。选取代表安徽省经济状况的核心经济指标,验证其与国际国内经济指标、特定关键词百度搜索指数之间可能存在的时差相关关系,筛选出相关性较强的若干先行指标,从统计关系上论证用关键词搜索指数预测区域经济变化的可行性。
(2)变量筛选。对先行指标,根据最佳滞后阶数进行数据集的调整,生成新的解释变量数据集,进行解释变量与被解释变量间的相关性分析,剔除相关性较弱的备选指标。根据相关性分析,列出相关性矩阵,剔除相关性非常不明显的指标。
(3)建模。根据调整后的数据集建立被解释变量的预测模型,根据模型的检验效果和预测结果,选取最优模型为预警模型。
(4)机制分析。对预测结果精度较高的预警模型,结合经济学相关理论,探讨其预警机制。
(二)时差相关分析
经济波动总是呈周期性的出现波峰和波谷,与之相关的指标在工业增加值或社会消费品零售总额出现波峰、波谷之前、之后或同时存在自身的波峰、波谷特征,由此用于研究的这些指标可以分为三大类:先行指标、同步指标、滞后指标。而本文以预警经济为目的,所以公众的指标数据中选取先行指标用于建模。
首先对收集的所有数据集进行季节性调整,扣除季节性因素的影响。为了保证下一步K-L信息量的求值要求两列数据必须每一个值都大于0,所以采用乘法模型,季节调整的公式如下:

其中,Xt为原序列;St为季节因子;Tt为长期趋势变动;It为不规则变动。对原序列进行季节分解,即先用建模数据计算其对应月份的季节因子,变换序列得到Xt*=Xt/St=Tt+It。后面即对Xt*进行建模分析。
K-L信息量法:运用该方法分别确定与被解释变量相关的先行指标、同步指标和滞后指标,筛选出先行指标,并确定先行期数。
这里主要考察离散变量。设基准指标为y=(y1,y2,…,yn),由于任意满足Pi>0、∑Pi=1的序列p均可视为某随机变量的概率分布序列,因此,基准指标序列记为p,即

设备择指标为x=(x1,x2,…,xn),序列记为q,即
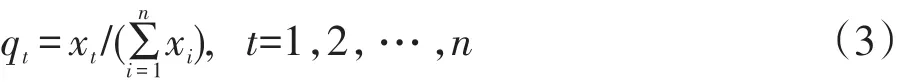
K-L信息量的计算公式为:

当备择指标序列x与基准指标序列y完全一致时,K-L信息量等于0;指标x与基准指标y越接近,K-L信息量绝对值越小,越接近于0。K-L信息量衡量两个概率分布的相似程度,即度量它们之间的距离,越小即代表两者越接近越相似。根据大数据理论,时差相关关系可能是因果关系,也可能是同为结果的关系,但只要信息量足够大,就可以用于预测。分别计算每个被解释变量与备选的解释指标从-12阶至+12阶的K-L信息量值,选取信息量值最小的指标对应的阶数为备选解释指标的最终时差,并进行时差筛选与相关性检验,筛选每个被解释变量对应的解释变量。
(三)多元回归模型的构建与筛选
为了表征区域经济变化,选取安徽省的工业增加值、社会消费品零售总额、出口额与房地产销售额为被解释变量,分别筛选出对应的解释变量,建立多元回归线性模型:

其中,REIk表示选出来的4个区域经济指标;ELIi表示国际国内其他经济指标;BDSj表示百度关键词搜索指数。
由于解释变量较多,无法采用传统的显著性检验来确定最终模型的自变量个数,因此需要制定一定的筛选原则,对所有解释变量进行筛选,同时根据筛选结果的拟合效果、变量显著性与多重共线性程度,筛选出最优预测模型。筛选的原则分别是:全模型(包含所有解释变量)、AIC准则选择出的最佳模型、BIC准则选出的最佳模型、全模型去除多重共线性下的修正模型、AIC准则选择出的最佳模型去除多重共线性下的修正模型、BIC准则选出的最佳模型去除多重共线性下的修正模型。
(四)数据来源
根据指标筛选的全面性、精炼性、可靠性、敏感性、稳定性、时效性等原则,选取备选的解释变量,主要来源于两个方面:一方面来自于安徽省统计局公布的经济指标,涉及投资、生产、消费、金融等经济各个方面13个指标,上海市统计局公布的经济指标10个,国家统计局公布的经济指标22个,美国、欧洲和日本的进出口额、失业率等9个经济指标;另一方面来自于百度搜索引擎提供的关键词搜索指数,关键词的选取依据是可能与区域经济相关、能反映用户需求及认知的全国网络用户或安徽网络用户的搜索关键词,共54个,其中,全国范围内网络用户的搜索关键词26个,安徽省范围内网络用户的搜索关键词28个,包括创业、上市公司、基金、找工作、就业形势、二手房等。
由于百度指数数据只能获取2011年1月之后的数据,而且本文的经济指标都是月度的,所以本文将百度指数周数据合成为月度数据,并选取了2011年1月至2014年12月的数据为研究样本,其中2014年9 月-12月的数据用于预测效果的检验。
三、实证研究
(一)时差相关性分析结果
由于安徽省出口额和房地产投资开发额筛选出的对应备选指标在相关性检验下,大部分指标的相关系数都很小,所以,在建立的预警模型中,解释变量个数偏少,模型的拟合效果不佳,预测误差较大。因此,下文只将安徽省工业增加值和社会消费品零售总额的预测模型纳入预警机制中,而安徽省出口额和房地产开发投资额的预测模型有待后续进一步研究。
通过乘法模型对所有数据指标进行季节性调整,扣除季节因素的影响。安徽省工业增加值和社会消费品零售总额两个指标调整前后的对比如图1所示。
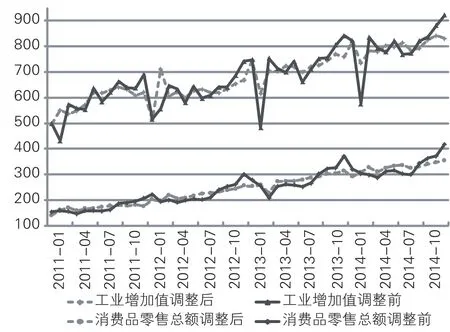
图1 经济指标季节性调整前后对比
从图1中可以看出,在每年的1、2月份会出现较大的季节性波幅,通过季节性调整前后对比,可以看出波幅降低,但不影响整个总体的趋势。

表1 变量间的时差相关分析结果
运用K-L信息量法分别对安徽省工业增加值和社会消费品零售总额以及各解释变量进行分析,确定各个指标的超前或滞后阶数,选取超前的各个指标,即先行指标。然后对各个先行指标与安徽省工业增加值和社会消费品零售总额进行相关性检验,剔除相关性较弱(|R|<0.5)的先行指标。最后筛选的指标见表1所列。
通过K-L信息量法,分别分析解释变量与被解释变量间不同时间段的概率分布,选取了概率分布最近似的移动月数,即-12到+12阶下,每阶对应的K-L信息量值最小的为最佳滞后阶数,K-L信息量值越小越接近于0,表示解释变量与被解释变量间相关关系越密切。另外,根据选取的指标对应的最佳滞后阶数对数据进行月度的平移调整,得到新的数据集,并对新的数据集作了解释变量与被解释变量间的相关性分析,根据实验数据的结果显示,调整后的大部分指标与被解释变量间存在比较明显的相关性。因此,以上筛选出的先行指标,通过相关性检验,可以用来建立回归模型。
(二)预警模型构建
对筛选出的先行指标按照其最佳滞后阶数进行变换,作为自变量,建立回归模型,预测未来一个月的值。根据六种模型的拟合情况、预测误差和方程显著性等筛选出最佳模型,输出模型参数与拟合结果,见表2所列。
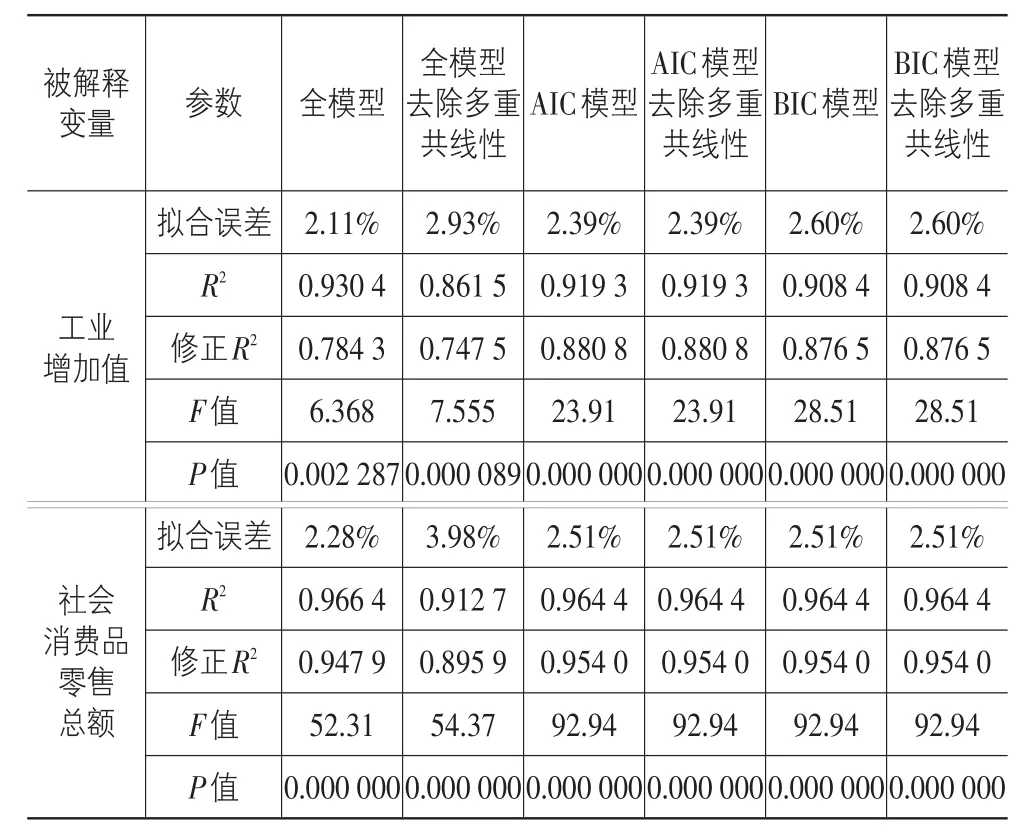
表2 不同模型的拟合与检验结果
据以上模型输出结果,结合方程系数的显著性,筛选出最优的预警模型。安徽省工业增加值筛选的预警模型为BIC准则选出的最佳模型,对安徽省社会零售总额模型进行筛选,其中,多种准则都筛选出同一个最佳模型。模型参数输出结果见表3所列。

表3 模型的参数及显著性检验
从模型的检验结果看:日本进口额、M1、美国进口额、关键词创业、通货膨胀、就业形势、增值税的安徽百度指数都在95%的置信水平下对工业增加值产生作用,尤其创业和增值税在99%的置信水平下都很显著。房地产业固定资产投资额、房地产开发投资、关键词理财产品、黄山的全国百度指数、关键词手机排行榜、找工作、中国经济的安徽百度指数在95%的置信区间内对安徽省社会消费品零售总额产生作用。
根据以上分析及结果,安徽省工业增加值和社会消费品零售总额预警模型如下:
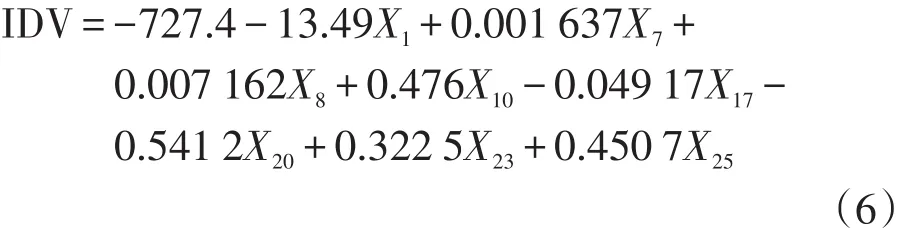

(三)拟合与预测效果检验
根据筛选出的最优模型,得到拟合结果,并预测2014年9月-12月的值,拟合与预测结果如图2所示。根据预测结果给出预警结果,并列出模型的预测误差,结果见表4所列。

图2 模型拟合与预测结果
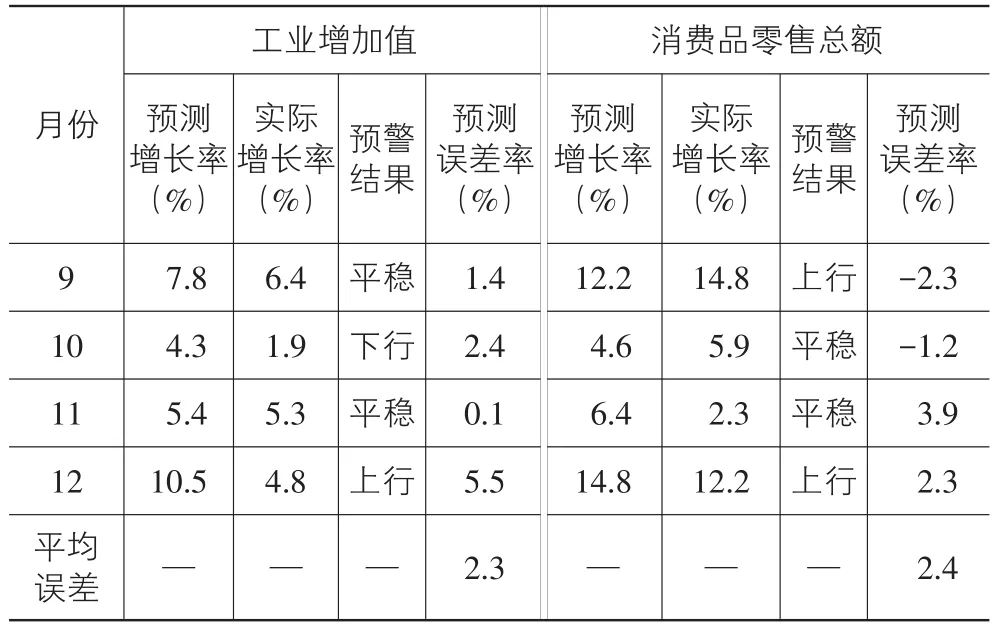
表4 模型预测结果与误差率(2014年9月-12月)
从模型的拟合效果看,安徽省工业增加值的波峰和波谷的拟合出现稍微的偏差,但大体的逆转趋势都能准确地反映;安徽省社会消费品零售总额的拟合效果比较理想,波峰和波谷及增长率的拟合都比较准确。根据两个模型的4个月预测误差来看,平均误差分别是2.3%和2.4%,误差率较低。模型能在统计数据公布一个月之前给出预警结果,可见模型具有较高的精确度与时效性。
基于预测结果可以对区域经济下月的波动进行预警:通过预测本月的增长率,与上月实际增长率对比,若增长率延续原趋势并处于合理区间,则经济是平稳运行;若增长率较低或出现大幅下降,则经济形势恶化或面临下行压力;若增长率较高或大幅上涨,则经济形势较好或加速上行。
四、预警机制分析
(一)工业增加值预警机制
从统计口径上看,工业增加值是企业日常生产的产品总价值扣除生产过程中消耗或转移的物质产品和劳务价值后的余额,是工业企业生产过程中新增加的价值。可以反映工业企业的投入、产出和经济效益情况,为改善工业企业生产经营提供依据,也是衡量宏观经济发展趋势的一个重要指标。由预警模型看出,安徽省工业增加值与美国和日本的进口额存在一定的相关关系,表明安徽省的经济一定程度上存在对出口的依赖,因而可以根据国外市场需求的波动来预测未来经济的走向,提前制定对经济波动的应对措施。
另外,从安徽省的百度搜索指数看,创业和就业形势的搜索量与工业增加值存在一定程度的负相关关系,也就是在经济低迷的时候,大家都比较关注就业方面的信息,政府部门及科研方面人员对当前的形势更为关注,失业人数一旦增加,政府会鼓励创业解决部分失业。尤其自2015年来经济一路下行,在经济仍有巨大下行压力的情况下,李克强总理发出“大众创业、万众创新”的号召,因此近期该有关创业方面的搜索量就会上升,一定程度上与此相关的搜索量上升可能反映该段时间经济的不景气。
通货膨胀和增值税的搜索量与工业增加值之间存在正相关的关系,反映该关键字搜索量的上升,工业增加值也随之上升,由此可以看出,公众在经济景气的时候可能对这方面的指标比较关注。例如,对通货膨胀的认识源于公众平时对物价利率的反映,思考货币购买力是否降低,为了印证这种猜测,在百度中搜索相关证据,一旦搜索量上升,则反映普遍的人认为物价在上涨,通货膨胀开始发生。这种反映在互联网上超前于统计上描述的经济现象发生的认识,成为新一代的数据集,为研究提供了更多的数据基础。
(二)社会消费品零售总额预警机制
社会消费品零售总额是批发和零售业、住宿和餐饮业以及其他行业直接售给城乡居民和社会集团的消费品零售额,是一项反映最终消费的指标,与宏观经济波动的方向趋于一致。不仅是反映我国拉动内需政策效果、制定新政策和新计划的重要指标,而且是各企业制定生产规划、个人投资者决策参考的重要指标。
从最优预警模型可以看出,安徽省房地产投资额与社会消费品零售总额之间呈正相关关系,而房地产开发投资是指在房地产经营业务中,对于统筹待建、拆迁还建等目前未存在的各类建筑物及配套和服务设施的建设投入,投资完成后,是作为商品进入销售领域,以获取预期利润为目的,因此,与消费品零售额之间可能存在一个正向的相关关系。
检验结果还表明,安徽省与经济相关关键字的搜索量与消费品零售额存在相关关系,在模型预测效果不错的条件下,有关百度指数的解释变量系数检验非常显著,由此可以得出结论,网络搜索数据与社会消费品零售总额存在相关关系。相关研究表明网络搜索数据与景区实际游客量之间具有正相关性[18],而“黄山(全国百度指数)”与社会消费品零售总额之间的正相关,可能反映社会消费品的零售总额与旅游业形势存在一定的相关关系。
(三)小结
综上所述,结合模型的系数显著性、方程显著性、方程的拟合优度及预测效果分析等,以及基于经济理论的预警机制分析,本文构建的预警模型存在一定的合理性。因此,安徽省工业增加值与社会消费品零售总额的预警模型,可作为指示安徽省经济波动的预警模型。
根据预警模型来预测这两大指标未来趋势走向,可以从生产和消费两个方面分析未来经济的增长率,提前应对经济波动,制定企业和政府的相关政策。在经济低迷时,实行经济促进政策,及时拉动内需、适当增加投资;反之则需要减少经济刺激政策,注重产业结构调整目标的实现。
五、结论与展望
本文基于对大量传统经济指标与百度搜索指数之间的时差相关关系分析,建立区域经济预警模型,通过对模型拟合与预测结果的检验,结合预警机制研究,认为预警模型具有较好的精确度与时效性。研究结果较精确的预测出安徽省工业增加值和社会消费品零售总额未来一月的变化趋势;研究通过引入百度搜索指数,筛选先行指标来建立回归模型,证实了网络搜索行为与经济波动存在一定的相关性,弥补了由于统计数据公布滞后性造成的数据时滞性的缺陷;基于互联网的搜索数据集容易获取,在预警模型的基础上,通过观测相关数据的变化,能够为政府部门和企业应对经济波动提供参考。
在大数据时代,数据搜集、存储和更新的成本更低,为复杂动态模型研究提供了条件,而指标数量越多,包含的信息越丰富[23-25]。随着移动互联网和大数据分析技术的快速发展,基于大数据分析的预测方法将改变传统的预测模型,而以百度指数为代表的网络大数据将为未来的研究提供更多更有价值的数据。
本文在研究框架和方法上还存在一定的不足,相关研究还有待继续深入和完善。首先,单从百度指数方面来考虑公众对经济的判断存在一定的局限性,百度指数反映的数据只是用户生成内容的一部分,并不涵盖所有的用户内容生成数据,譬如搜狗、360搜索引擎以及社交网络等,一些代表用户对经济的预期和看法的高频数据每天在微博、新闻评论等媒体上也有生成,未来需要将这些结构化与非结构化的数据进行整合。其次,尽管可选的网络搜索关键词数量巨大,由于多元回归模型的自变量数量过多会影响回归模型的效果,需要限制网络搜索关键词的数量,筛选的方式往往是根据经济学理论与相关研究的经验,存在信息的遗漏,未来需要引进大数据的最新研究方法,从网络大数据中提取更多关于宏观经济形势的有用信息。
参考文献:
[1]杨岚.中、美、日宏观经济监测中的先行指标、同步指标和滞后指标简介[J].西安金融,2004(10):29-30.
[2]Banerjee A,Marcellino M,Masten I.Leading Indicators for Euro-area Inflation and GDP Growth[J].Oxford Bulletin of Economics and Statistics,2005,67(12):785-813.
[3]晏露蓉,吴伟.建设先行指标体系的科学方法[J].金融研究,2006(6):128-135.
[4]陈可嘉,刘思峰.基于K-L信息量法的经济指标时差分析[J].江南大学学报:自然科学版,2010,9(6):45-49.
[5]王海慧,张建平.短期经济波动预测方法研究——基于先行地区与先导行业的视角[J].上海金融,2010(8):16-20.
[6]Kulkarni R,Haynes K,Stough R,et al.Forecasting housing prices with Google econometrics[R].GMU School of Public Policy,2009.
[7]Suhoy T.Query Indices and a 2008 Downturn:Israeli Data [R].Bank of Israel,2009.
[8]Konstantin K A,Podstawski M,Siliverstovs B,et al.Google searches as a means of improving the nowcasts of key Macro-economic Variables[R].Discussion Papers of Diw Berlin,2009.
[9]Ginsberg J,Mohebbi M,Patwl R,et al.Detecting influenza epidemics using search engine query data[J].Nature,2008,457(19):1012-1014.
[10]Francesco,Amuri D.Predicting Unemployment in Short Samples with Internet Job Search Query Data[R].Working Paper of the Economic and Social research Council,2009.
[11]Choi H,Varian H.Predicting the Present with Google Trends[J].Economic Record,2009,88(S1):2-9.
[12]袁庆玉,彭赓,刘颖,等.基于网络关键词搜索数据的汽车销量预测研究[J].管理学家:学术版,2011(1):12-24.
[13]张崇,吕本富,彭赓,等.网络搜索数据与CPI的相关性研究[J].管理科学学报,2012,15(7):50-59.
[14]孙毅,吕本富,陈航,等.大数据视角的通胀预期测度与应用研究[J].管理世界,2014(4):171-172.
[15]彭赓,苏亚军,李娜.失业率预测研究——基于网络搜索数据及改进的逐步回归模型[J].现代管理科学,2013 (12):40-43.
[16]董倩,孙娜娜,李伟.基于网络搜索数据的房地产价格预测[J].统计研究,2014,31(10):81-88.
[17]姜东民,崔丽敏,管田超.基于网络搜索量的世园会客流量预测[J].中国管理信息化,2013,16(8):44-47.
[18]任乐,崔东佳.基于网络搜索数据的国内旅游客流量预测研究——以北京市国内旅游客流量为例[J].经济问题探索,2014(4):67-73.
[19]刘颖,吕本富,彭赓,等.网络搜索对股票市场的预测能力:理论分析与实证检验[J].经济管理,2011,33(1):172-180.
[20]王炼,贾建民.突发性灾害事件风险感知的动态特征:来自网络搜索的证据[J].管理评论,2014,26(5):169-176.
[21]孙毅,吕本富,陈航,等.基于网络搜索行为的消费者信心指数构建及应用研究[J].管理评论,2014,26(10):117-125.
[22]中国互联网络信息中心.中国互联网络状况统计报告[R].北京:中国互联网络信息中心,2015.
[23]李国杰,程学旗.大数据研究:未来科技及经济社会发展的重大战略领域——大数据的研究现状与科学思考[J].中国科学院院刊,2012(6):647-657.
[24]俞立平.大数据与大数据经济学[J].中国软科学,2013 (7):177-183.
[25]杨善林,周开乐.大数据中的管理问题:基于大数据的资源观[J].管理科学学报,2015,18(5):1-7.
[责任编辑:余志虎]
肖夕林(1993-),男,江苏南通人,硕士研究生,研究方向:区域经济与可持续发展;
刘思佳(1992-),女,山西运城人,硕士研究生,研究方向:企业管理。
中图分类号:F207
文献标志码:A
文章编号:1007-5097(2016)08-0060-07
收稿日期:2016-05-20
基金项目:安徽省自然科学基金项目(1508085QG146);中国博士后科学基金项目(2014M551792)
作者简介:李方一(1985-),男,湖南常德人,副教授,博士,研究方向:区域经济与可持续发展;
Research on Early-warning of Regional Economy based on Web Search Data
LI Fang-yi,XIAO Xi-lin,LIU Si-jia
(School of Management,Hefei University of Technology,Hefei 230009,China)
Abstract:As the number of Web users continues to grow,the function of Web search data for indicating social and economic development is discovered and studied,since Web Search Data directly reflects the users'behavior and psychology.Taking Anhui province as an example,we selected industrial value-added and other indicators as forecast targets in this paper.Based on the theories of economic fluctuation and Big Data,we used K-L information method and time difference correlation analysis to screen a series of international and domestic economic indicators and Web search data of specific keywords.After that a series of leading indicators were screened out to build a regional early-warning model.The results show that Web search data of certain keywords can be used to forecast monthly change of regional industrial value-added and total retail of consumer goods based on fitting test and predicting test,and the early warning model,with good accuracy and timeliness,can provide references for government and enterprises to reply to economic fluctuations.
Keywords:economic fluctuation;leading indicator;Web search data;K-L information method;regional economy
猜你喜欢
人民论坛(2016年23期)2016-12-13
时代金融(2016年23期)2016-10-31
职业(2016年10期)2016-10-20
中国市场(2016年36期)2016-10-19
商场现代化(2016年22期)2016-10-18
中国市场(2016年33期)2016-10-18
商(2016年27期)2016-10-17
大众理财顾问(2016年3期)2016-06-13
