
无空闲时隙的动态多叉查询树RFID防碰撞算法
2016-07-19 02:07牛爱民
计算机应用与软件 2016年6期
牛 爱 民
(山东英才学院计算机电子信息工程学院 山东 济南 250104)
无空闲时隙的动态多叉查询树RFID防碰撞算法
牛 爱 民
(山东英才学院计算机电子信息工程学院山东 济南 250104)
摘要为了提高RFID系统识别标签的效率,提出一种无空闲时隙的动态多叉查询树RFID防碰撞算法DMQT。该算法根据碰撞位的特征动态调整树分裂的叉数,能够有效地减少碰撞时隙。通过跟踪标签的碰撞位来避免不存在标签的分支,从而可以消除空闲时隙。理论和仿真分析可以看到,该算法具有很小的识别时隙和较大的吞吐率,算法性能优于目前存在的RFID防碰撞算法。
关键词射频识别防碰撞算法多叉查询树
0引言
RFID由于具有非接触性、方便快速、可靠性好等优点,已经广泛地应用于自动识别领域。一个典型的RFID系统包括阅读器、标签和后台服务器。后台服务器与阅读器进行可靠连接,它主要负责管理和处理数据;标签与物品绑定,记录物品的一些信息,每个标签具有唯一的ID号;阅读器通过无线方式读写标签中的信息,当多个标签同时响应阅读器的查询时将发生碰撞,这是由于标签都使用同一无线信道。发生碰撞时阅读器将不能正常读取标签中信息。目前主要存在两类防碰撞算法:基于aloha防碰撞算法[1,2]和基于树防碰撞算法[3-5]。基于aloha防碰撞算法在发生碰撞时,标签随机选择一个时隙进行响应,这类防碰撞算法的识别效率普遍偏低。当存在大量标签时,有些标签可能很长时间不能被识别,这种现象称为“标签饿死”现象。目前这类算法提高识别效率的方法是从估计待识别标签数量出发,采用某种合适的方式让标签选择不同的时隙,以减少再次发生碰撞的概率[6,7]。基于树防碰撞算法是一种确定性的防碰撞算法,不存在“标签饿死”现象。基于树防碰撞算法的基本思路是不断地将标签分成不同组,直到一个组中只有一个标签或者没有标签。查询树防碰撞算法[8-10]是一类非常优秀的基于树防碰撞算法。在查询树算法中,阅读器发送一个查询前缀,标签检测自己的ID号是否包含该查询前缀,如果包含则传送自己的ID,阅读器随后不断更新和发送新的查询前缀,直到识别所有标签。基本查询树防碰撞算法的识别效率不高,但许多研究者在此基础上提出了效率非常高的查询树算法。CT算法[11]是非常优秀的二叉查询树防碰撞算法。CT算法与基本查询树算法的分裂点不同,基本查询树算法是逐位分裂二叉树,CT算法是在最高碰撞位分裂二叉树,并且标签响应不包含前缀的ID剩余位,CT算法的识别效率达到了50%。I4QTA算法[12]是一个基于四叉查询树防碰撞算法,当发生两位连续碰撞时,标签采用位变换的方式来减少空闲时隙,大大提高了识别效率。A4PQT算法[13]也是一个基于四叉查询树防碰撞算法,已经证明三叉树是最优的识别树,但不存在三叉树分裂方式。A4PQT算法就是利用三叉树最优分裂原理,剪去四叉树中的某些分支,使之接近一个三叉树,A4PQT算法也达到了非常高的识别效率。OQTT算法[14]也是一种二叉查询树防碰撞算法,该算法由三个部分组成:位估计、最优分裂和查询跟踪树。在识别开始将标签分成比较小的组,避免在识别开始出现过多的碰撞位,在每个组中再采用二叉树分裂方式,由于采用最优的分组方式,该算法的识别效率高于CT算法。
从上面的分析可以看到,目前一些基于查询树防碰撞算法采用了不同叉数的树分裂方式,有效率地提高了识别效率。但是在识别过程中会存在不同的连续碰撞位,这些算法都采用固定的分裂叉数,采用某种固定叉数的树分裂方法可能会增加一些碰撞时隙。基于此,本文提出一个无空闲时隙的动态多叉树防碰撞算法(DMQT)。DMQT算法根据最高碰撞位特征动态调整树分裂叉树,并且采用位跟踪的方式探知标签对应的碰撞位,在下一轮查询中能够避免所有的空闲时隙。从仿真结果可以看到,DMQT算法性能明显优于现有的查询树算法。
1多叉树防碰撞算法的时隙
RFID系统将识别多个标签的时间用时隙来表示,阅读器在查询识别过程中可能存在三种情形:一个标签响应(直接读取标签信息)、多个标签响(发生碰撞,阅读器不能读取标签信息)和无标签响应。对应于识别过程中三种情形,时隙可以分为可读时隙、碰撞时隙和空闲时隙。基于树的防碰撞算法是用树的节点来表示时隙,树的中间节点都是碰撞时隙,叶节点可能是可读时隙,也可能是空闲时隙。减少碰撞时隙和空闲时隙可以提高RFID系统的识别效率。图1显示了采用二叉树、四叉树和八叉树识别5个标签的识别过程。在图1的实例中,识别同样数量的标签,采用二叉树分裂方法会产生3个碰撞时隙、1个空闲时隙;采用四叉树分裂方法会产生2个碰撞时隙、5个空闲时隙;采用八叉树分裂方法会产生1个碰撞时隙、10个空闲时隙。可以看出,增加树分裂的叉数能够减少碰撞时隙,但增加了空闲时隙。因此增加树的叉数也不一定能够减少识别的总时隙,在图1中完全采用二叉树分裂方式总时隙为10,完全采用四叉树分裂方式所需的总时隙为13,完全采用8叉树分裂方式所需的总时隙为17。

图1 不用叉数的防碰撞算法识别过程

(1)


表1 一个完全多叉树分裂所产生的时隙
当树的叉数增加,碰撞时隙减少,空闲时隙增加,这也给我们一个启示:采用多叉树的优点是可以减少碰撞时隙,不足是增加了空闲时隙。如果能够采用某种方式消除多叉树所产生的空闲时隙,那么将大大减少多叉树识别的总时隙。从表1也可以看到,当没有空闲时隙时,采用二叉树识别m个标签的总时隙为2.443m,采用三叉树识别m个标签的总时隙为1.913m,采用四叉树识别m个标签的总时隙为1.720m,采用五叉树识别m个标签的总时隙为1.622m。理论上讲,如果没有空闲时隙,树的叉数越多,总时隙越小,识别效率越高。基于这个思想,本文提出的RFID防碰撞算法在识别过程中,根据碰撞位探知发生碰撞的标签ID信息,在下一轮查询时阅读器可以避开多叉树产生的空闲时隙,从而可以消除空闲时隙,提高RFID系统的识别效率。
2动态多叉树防碰撞算法
2.1算法设计思路
动态多叉树防碰撞算法用曼彻斯特编码跟踪碰撞位,当发生碰撞时,多个标签ID对应位的曼彻斯特编码将不出现跳变,因此曼彻斯特编码可以准确判断哪些位发生了碰撞。根据是否出现连续碰撞位以及连续碰撞位的数量,该算法动态地调整树分裂的叉数。基本分裂原则如下:如果只存在一位最高碰撞位,采用二叉树分裂方式;如果存在最高两个连续碰撞位,则采用四叉树分裂方式;如果存在最高三个连续碰撞位,则采用八叉树分裂方式。同理,如果存在最高n个连续碰撞位,则采用2n叉树分裂方式。从第1节的分析可以看到,如果能够完全消除空闲时隙,树的分裂叉数越多,系统的识别效率越高。由于不可能事先知道所有需要识别标签的ID,所以只能在发生碰撞时用某种方式跟踪标签部分ID分布情况,这样阅读器在下一次查询时可以避免空闲时隙。
2.2算法原理及流程
阅读器在识别过程中使用两类查询,一类是识别标签查询,另一类是当发生碰撞时的位跟踪查询。阅读器用一位标识符来表示这两类查询,在查询的最低位用标志“0”表示识别查询,用标志“1”表示位跟踪查询。标签在接收到阅读器的查询时,首先判断查询的最低位,如果为“0”,表示为识别查询,标签检查自己ID是否包含阅读器的查询前缀(不包括最低标志位),如果包含,标签用不包括查询前缀的ID剩余位响应,否则不响应。如果标签检查到最低查询位为“1”,表示为位跟踪查询,标签将按照下面方式进行响应。
(1) 当只存在一位最高碰撞,阅读器可以知道这些标签在该碰撞位肯定为0和1。采用二叉树分裂方式,在下一次查询时分别增加两个查询前缀,阅读器完全可以避免空闲时隙此时,阅读器不需要额外的位跟踪查询。
(2) 当存在最高n(n≥2)个连续碰撞位时,采用2n叉树分裂方式。阅读器跟踪2n个分支中是否存在标签,位跟踪查询格式为:0…0+1…1+1,其中0…0表示比最高连续碰撞位高的所有位串,连续碰撞的位数用1…1表示,n个连续碰撞位用n个1表示,最后的1位表示探知标志符。标签将与位跟踪查询中1…1对应的ID位转换成十进制数s,标签生成2n长的位串传给阅读器,其中将位串的第smod2n位设置为1,其他位都设置为0。例如当n=2时,采用四叉树分裂方式,一个完全四叉树分裂为00,01,10和11等4个分支。有些分支可能不存在标签,此时阅读器用位跟踪查询:0…0+11+1。假设有两个标签为tag1(10010011)和tag2(10100001),当这两个标签响应阅读器的识别查询时会发生碰撞,阅读器用曼彻斯特编码识别为10xx00x1,其中x表示碰撞位。由于存在的最高两连续碰撞位,阅读器发送位跟踪查询00111,最后“1”表示位跟踪查询标志。标签在接收到位跟踪查询后,不考虑最后的标志号1和前面的00,位跟踪查询中的11对应标签tag1(10010011)中的ID位是01。如图2所示,转换十进制数为1,标签生成22位响应消息,将第1mod22位设置为1,其他位设置为0,结果为0010。同样tag2(10100001)与位跟踪查询00111所对应的ID位是10,转换十进制数为2,标签将第2mod22设置为1,其他位设置为0,结果为0100。阅读器接收到2个标签的响应后,用曼彻斯特编码可以判断为0xx0,阅读器很容易判断出在4叉树中只存在01和10两分分支,在下一轮查询中阅读器就能避免空闲时隙。
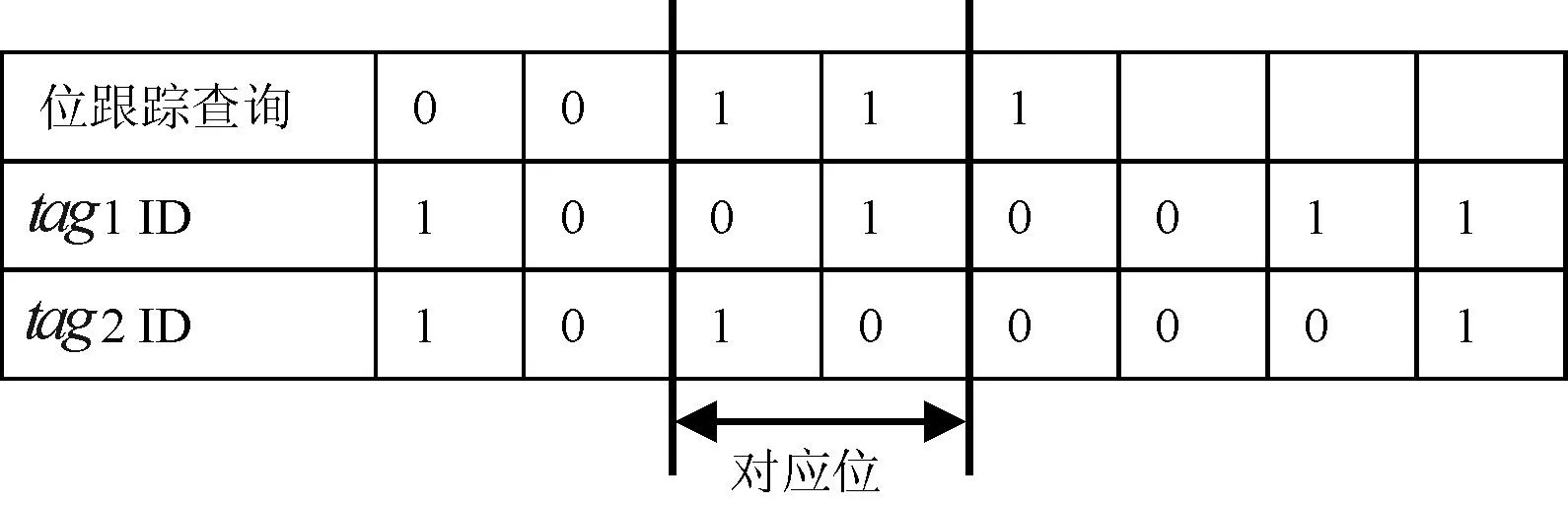
图2 位跟踪查询中连续碰撞位与标签ID的对应位
为了减轻标签对位跟踪查询响应的代价,DMQT算法规定标签响应位长不超过ID位长,假设标签ID位长为l,那么阅读器选取的最大连续碰撞位n应满足:2n≤ l。例如有两个标签0110和1001,同时响应阅读器的识别查询,结果为xxxx,存在最高连续4个碰撞位。由于标签的ID位长为4,所以阅读器位跟踪查询时只能按照2个最高连续位进行查询,标签响应位长为4位(小于或者等于l)。若阅读器的位跟踪查询按照4个最高连续位进行查询,标签则产生16位长的响应消息,这种方式显然增加了标签的通信量。
DMQT算法用堆栈保存阅读器的查询前缀,最初将一个空字符串ε进栈,随后根据碰撞位特征重复地压进新的前缀和推出新的查询前缀。当不存在连续最高碰撞位时,新的前缀在原前缀(qt)的基础上扩展为qt+0和qt+1。如果存在n位连续最高碰撞位,阅读器发送位跟踪查询,阅读器根据标签的响应扩展查询前缀,扩展后的查询前缀包含响应标签所在的分支。在上面的例子中,tag1(10010011)和tag2(10100001)的对阅读器位跟踪查询后的响应分别为0010和0100,那么阅读器在原前缀(qt)的基础上扩展为qt+01和qt+10;不需要按照完全四叉数的方式扩展为qt+00、qt+01、qt+10和qt+11,可见DMQT算法完全消除了空闲时隙。算法的流程如图3所示。

图3 阅读器和标签的操作流程
阅读器操作步骤如下:
① 阅读器初始化查询前缀堆栈,并将空字符串ε压入堆栈;
② 判断查询前缀堆栈是否为空,如果为空,转步骤⑨;
③ 前缀q出栈操作,并广播查询前缀q+0,其中最后的“0”位表示识别查询标志;
④ 等待标签响应,若无标签响应,转步骤⑨;若有标签响应,判断是否发送碰撞,如果没有发生碰撞,转步骤⑧;如果发送碰撞,判断是否存在连续最高碰撞位,如果不存在连续最高碰撞位,阅读器产生新前缀q0,q1,并压入堆栈;若存在n(n≥2)个连续最高碰撞位,转步骤⑤。
⑤ 发送位跟踪查询0…0+1…1+1,其中,0…0表示比最高连续碰撞位高的所有位, 1…1表示n个连续碰撞位,最后的“1”位表示位跟踪查询标志;
⑥ 接收到标签响应,用曼彻斯特编码判断哪些分支存在标签,根据有标签响应的分支产生新的查询前缀,新前缀=原前缀+分支位串,并压入堆栈;
⑦ 重复上面步骤②-步骤⑥;
⑧ 识别一个标签;
⑨ 结束。
标签操作步骤如下:
① 等待查询;
② 根据最后标志位判断阅读器的查询类型,若标志位为“1”,转步骤④;若标志位为“0”,转步骤③;
③ 检测查询前缀是否匹配自己的ID,如果不匹配,转步骤①;如果匹配,传送不包括前缀后的ID剩余位;
④ 标签根据位跟踪查询0…0+1…1+1,找出1…1与ID中的对应位,并转换成十进制数s,生成2n长的位串,将smod2n,位设置为1,其他位设置为0,并传送给阅读器。
2.3DMQT算法举例
现举例说明动态多叉树防碰撞算法的识别过程,假设存在6个标签分别是:t1(11000001)、t2(11100011)、t3(10110101)、t4(11010001)、t5(11110010)和t6(10010010)。当阅读器用空字符串ε查询时,所有标签响应,阅读器用曼特斯特编码判断结果为1xxx0xxx,其中x表示碰撞位。由于存在3位最高连续位,阅读器发送位跟踪查询01111,最后一位“1”表示位跟踪查询的标志位。标签接收到探知查询后,去掉探知查询标志位后选取与“111”对应的ID位,t1对应的ID位为100(十进制数4),将4 mod 23设置为1,其他位设置为0,结果为00010000。同样,t2转换为01000000,t3转换为00001000,t4转换为00100000,t5转换为10000000,t6转换为00000010。阅读器在接收到标签响应后,生成新的查询前缀,如此继续,直到识别所有标签。识别过程如表2所示,对应的识别树如图4所示。

表2 DMQT算法识别标签过程

图4 DMQT算法的识别树
3DMQT算法性能分析
RFID防碰撞算法的性能指标主要包括总时隙和吞吐率。DMQT算法识别标签过程中采取的分裂叉数是动态的,这里首先分析算法最小总时隙和最大总时隙。假设标签数量为m,标签ID长l=96位,可以发现最大分裂的连续碰撞位数n满足2n≤l,可得n=6,由于动态多叉树RFID防碰撞算法能够避免所有空隙时隙,并且n当越大时,碰撞时隙越少,显然当n=6时所需要的总时隙最小。当n=6时,算法按照26=64叉树分裂,算法的满64叉树的内部节点度为64,叶节点度为0,用m1表示度为64的节点。由于不存在空闲时隙,叶节点数与待识别标签数m相等。因此满64叉树的总节点数为:M=m1+m。另外,度为64的节点有64个孩子,加上一个根节点,那么满64叉树的总节点数也可以表示为:M= 64m1+1。因此有:m1+m=64m1+1,m1=(m-1)/63。
由于不存在空闲时隙,中间节点数m1等于碰撞时隙数。当存在最高连续碰撞位时,DMQT算法增加了一次位跟踪查询,因此,总的位跟踪查询次数等于碰撞时隙数。可以得到满64叉树的总时隙为:碰撞时隙+可读时隙+位跟踪查询时隙,即为:
(2)
最小连续碰撞位是2位,当只存在最高两位连续碰撞位时,DMQT算法采用4叉树分裂方式。这时也需要采用位跟踪查询,与满64叉树分析类似,可以得到满4叉树的总时隙为:碰撞时隙+可读时隙+位跟踪查询时隙,即为:
(3)
当只存在一位最高碰撞位时,DMQT算法采用二叉树分裂方式,阅读器不需要额外的位跟踪查询。这时内部节点度为2,叶节点度为0,总节点数为:M=m1+m。其中m1表示度为2的节点,m表示叶节点,也是待识别标签数。度为2的节点有2个孩子,加上一个根节点,总节点数也表示为:M= 2m1+1。可以得到中间节点数m1=m-1,因此算法所需要的总时隙为:碰撞时隙+可读时隙,即为:T2=m-1+m=2m-1。
吞吐率表示单位时隙内识别标签数,DMQT算法的吞吐率表示为:S=m/T。
下面通过实验仿真比较几个算法的识别性能,随机生成96位长的标签,标签数量范围为100~1000,比较DMQT算法与CT、A4PQT和OQTT等算法的总时隙和吞吐率。仿真结果如图5、图6所示。

图5 DMQT算法与CT、A4PQT和OQTT等算法的总时隙
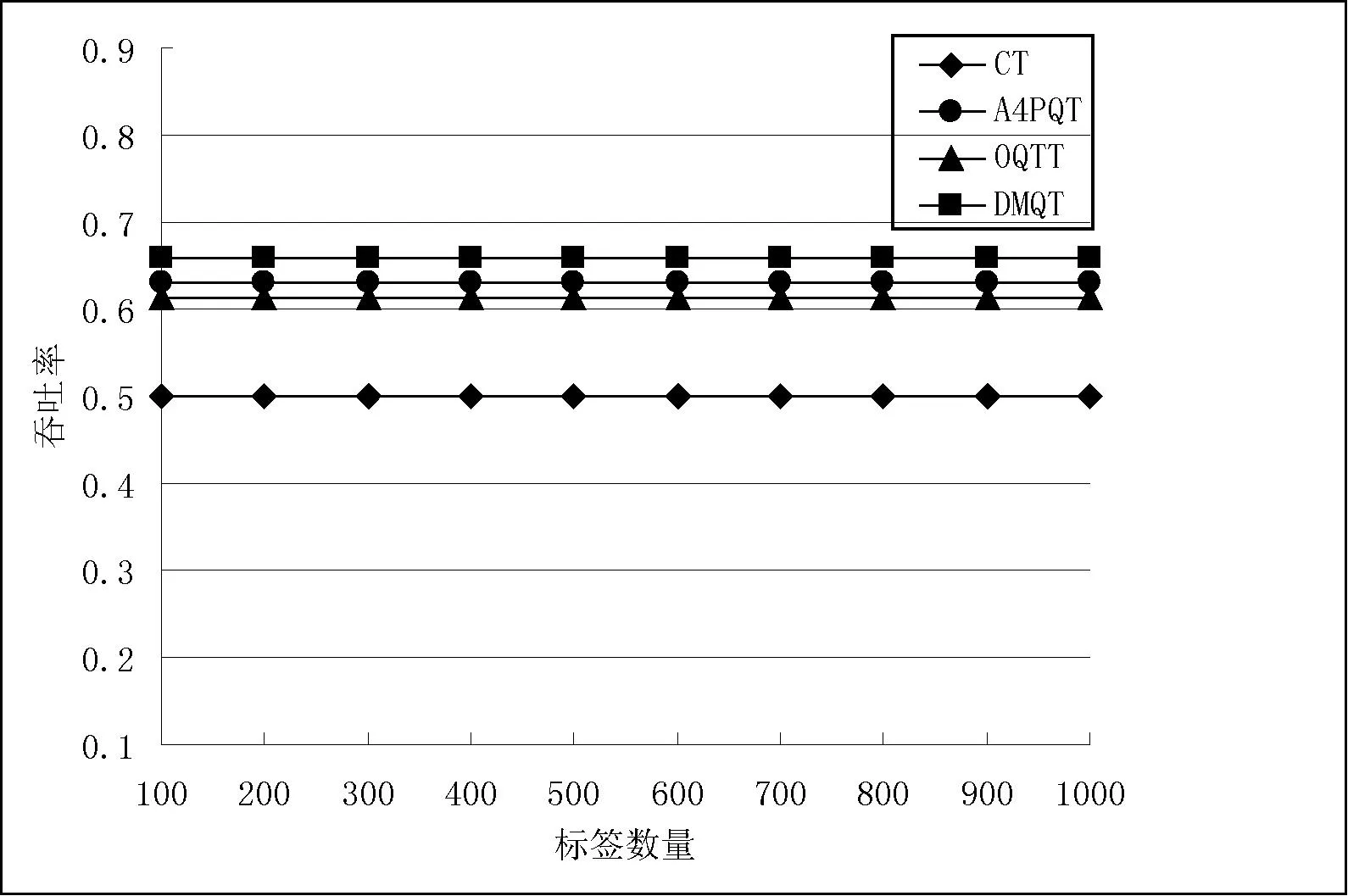
图6 DMQT算法与CT、A4PQT和OQTT等算法的吞吐率
从图5中可以看到,DMQT算法识别相同的标签所需要的总时隙少于CT、A4PQT和OQTT等算法的总时隙。当识别1000个标签时,DMQT算法所需要的总时隙约为1510,CT算法的总时隙约为2000,A4PQT算法所需要的总时隙约为1590,OQTT算法所需要的总时隙约为1630。究其原因可以发现,CT算法是一个二叉树防碰撞算法,当发生碰撞时,在最高碰撞位将标签分裂成2组,CT算法的最大优点是能够消除所有的空闲时隙,但由于采用二叉树分裂方式,所以存在较多的碰撞时隙。OQTT算法为了减少过多的碰撞位,对待识别标签进行最优分组,其识别总时隙小于CT算法,但由于OQTT算法还是基于二叉树分裂方式,因此存在过多的碰撞时隙。A4PQT是基于四叉树防碰撞算法,基于四叉树防碰撞算法比基于二叉树防碰撞算法具有较少的碰撞时隙,但增加了空闲时隙,A4PQT算法采用剪枝的方式消除部分空闲时隙,因而其总时隙少于CT和OQTT算法的总时隙。DMQT算法则动态调整分裂树叉树,采用跟踪标签碰撞位的方法消除空闲时隙,因此DMQT算法的总时隙小于其他3个算法。从图6也可以看到,DMQT算法吞吐率也明显高于其他3个算法,DMQT算法吞吐率约为0.66,CT、A4PQT和OQTT等算法的吞吐率分别约为0.5,0.63和0.61。
4结语
在RFID系统中,设计一个有效的防碰撞算法能够提高对标签识别的效率。本文提出了一个无空闲时隙的动态多叉树防碰撞算法,DMQT算法在识别过程中根据碰撞位特征动态调整查询树分裂叉数,能够有效地减少了碰撞时隙。在碰撞发生时,跟踪标签对应的碰撞位,这样阅读器在下次查询时能够避免不存在的分支搜索,从而消除了空闲时隙。从理论分析和仿真实验可以看到,DMQT算法具有较小的总时隙和较大的吞吐率,性能优于其他防碰撞算法。
参考文献
[1]ZhuL,YumTP.Optimalframedalohabasedanti-collisionalgorithmsforRFIDsystems[J].IEEETransactionsonCommunications,2010,58(12):3583-3592.
[2]EomJB,LeeTJ,RietmanR,etal.Anefficientframed-slottedALOHAalgorithmwithpilotframeandbinaryselectionforanti-collisionofRFIDtags[J].IEEECommunicationsLetters,2008,12(11):861-863.
[3]LaiYC,HsiaoLY,LinBS.AnRFIDanti-collisionalgorithmwithdynamiccondensationandorderingbinarytree[J].ComputerCommunications,2013,36(17):1754-1767.
[4]LaiYC,LinCC.Twoblockingalgorithmsonadaptivebinarysplitting:singleandpairresolutionsforRFIDtagidentification[J].IEEE/ACMTransactionsonNetworking(TON),2009,17(3):962-975.
[5]LandaluceH,PerallosA,AnguloI.ManagingtheNumberofTagBitsTransmittedinaBit-TrackingRFIDCollisionResolutionProtocol[J].Sensors,2014,14(1):1010-1027.
[6]EomJB,LeeTJ.Accuratetagestimationfordynamicframed-slottedALOHAinRFIDsystems[J].IEEECommunicationsLetters,2010,14(1):60-62.
[7]MotaRPB,BatistaDM.AdynamicframeslottedALOHAanti-collisionalgorithmfortheinternetofthings[C]//Proceedingsofthe29thAnnualACMSymposiumonAppliedComputing.ACM,2014:686-691.
[8]ChoiJH,LeeD,LeeH.Querytree-basedreservationforefficientRFIDtaganti-collision[J].IEEECommunicationsLetters,2007,11(1):85-87.
[9]LiuX,QianZ,ZhaoY,etal.Anadaptivetaganti-collisionprotocolinRFIDwirelesssystems[J].ChinaCommunications,2014,11(7):117-127.
[10]YehMK,JiangJR.ANovelQueryTreeProtocolBasedonPartialResponsesforRFIDTagAnti-Collision[C]//ProceedingsoftheInternationalConferenceonParallelandDistributedSystems(ICPADS).IEEE,2013:617-622.
[11]JiaX,FengQ,YuL.Stabilityanalysisofanefficientanti-collisionprotocolforRFIDtagidentification[J].IEEETransactionsonCommunications,2012,60(8):2285-2294.
[12]KimY,KimS,LeeS,etal.Improved4-aryquerytreealgorithmforanti-collisioninRFIDsystem[C]//ProceedingsoftheInternationalConferenceonAdvancedInformationNetworkingandApplications.IEEE,2009:699-704.
[13]ZhangW,GuoY,TangX,etal.AnEfficientAdaptiveAnticollisionAlgorithmBasedon4-AryPruningQueryTree[J].InternationalJournalofDistributedSensorNetworks,2013,11(12):1-7.
[14]LaiYC,HsiaoLY,ChenHJ,etal.AnovelquerytreeprotocolwithbittrackinginRFIDtagidentification[J].IEEETransactionsonMobileComputing,2013,12(10):2063-2075.
[15]HushDR,WoodC.AnalysisoftreealgorithmsforRFIDarbitration[C]//ProceedingsoftheIEEEInternationalSymposiumonInformationTheory,1998,107-116.
DYNAMIC N-ARY QUERY TREE RFID ANTI-COLLISIONALGORITHMWITHOUTIDLETIMESLOTS
Niu Aimin
(School of Computer Electronics and Information Engineering,Shandong Yingcai University,Jinan 250104,Shandong,China)
AbstractIn order to improve the efficiency of RFID system in identifying tags,this paper presents a dynamic n-ary query tree RFID anticollision algorithm without idle timeslots (DMQT).DMQT adjusts dynamically the number of branches of the tree according to the characteristics of collision bits,and is able to reduce effectively the collision timeslots.DMQT avoids some branch that tags do not exist by tracking the tag collision bits,so that it can eliminate all the idle timeslots.It can be seen from theoretical and simulation analyses that DMQT has a small total timeslots and larger throughput,its performance outperforms existing RFID anti-collision algorithms.
KeywordsRFIDAnti-collision algorithmN-ary query tree
收稿日期:2014-11-11。山东省高等学校科技计划项目(J13LN55)。牛爱民,讲师,主研领域:物联网,人工智能。
中图分类号TP309
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.06.066
猜你喜欢
电子设计工程(2022年15期)2022-08-17
现代计算机(2021年14期)2021-07-09
英语世界(2020年10期)2020-11-06
英语世界(2020年2期)2020-03-08
小读者之友(2019年9期)2019-09-10
东坡赤壁诗词(2018年6期)2018-12-22
意林·少年版(2018年1期)2018-02-07
武汉轻工大学学报(2016年4期)2017-01-16
武汉轻工大学学报(2016年3期)2016-10-27
CHIP新电脑(2016年3期)2016-03-10
