
基于类比估算的软件项目规模估计
2016-05-30 18:42:44张志伟郭树行
科技创新导报 2016年13期
关键词:估算
张志伟 郭树行


摘 要:针对软件项目规模估算结果准确性普遍偏低的问题,该文提出一种采用类比估算方法的软件项目规模估算策略。首先针对历史项目数据以及现有评价体系,给出利用属性值进行类比估算的模型;其次,给出类比估算操作步骤;最后在理论研究基础上,通过实例验证对目标项目规模进行估算。实验表明,类比方法能有效减少偏差,为项目的成本编制提供有效参考。
关键词:类比方法 软件规模 估算
中图分类号:G64 文献标识码:A 文章编号:1674-098X(2016)05(a)-0092-04
软件成本估算是软件项目管理的重要环节,对项目进度管理、质量管理及采购管理等知识领域有重要影响,是软件项目时间、成本及软件工作规模估算等项目过程的重要环节,是项目成败的关键要素。如何才能准确估算软件项目成本?这个问题长期困扰着产业界和学术界。软件成本估算是软件项目管理过程中的一项非常重要的活动,软件项目进度、成本及工作量的估算作为软件项目过程的重要環节,对软件开发项目的成败起到重要作用。长期以来,准确的成本估算问题一直困扰着产业界和学术界。从20世纪60年代出现的SDC(system development corporation)线性模型开始,到现在已经经历了近50年的发展,但是根据STANDISH组织[1]2004年的公布的数据显示,成功项目只占所有50 000个项目的29%,失败项目占到了18%,并且该报告指出,有89%的项目都有预算超支的情况发生。由此看来,作为解决预算超支问题的重要措施,软件成本估算已经成为软件工程领域的一个重要研究方向。另外,精确的成本估算不但直接有助于做出合理的投资、外包、竞标等商业决定,也有助于确定一些预算或进度方面的参考里程碑,使软件组织或管理者对软件开发过程进行监督,从而更合理地控制和管理软件质量、人员生产率和产品进度。
最早的软件成本估算可以追溯到20世纪60年代,到现在已历经了40多年的发展,各个方面的研究都已经比较深入,产生了很多种估算方法,目前普遍应用的有以下几种方法:专家判断、算法模型和类比方法。
首先,专家判断是一种自上往下的估算方法,用途非常广泛。毫无借鉴的直觉判断,有历史数据支撑的预测,有过程框架和历史清单支持的理性推断,都可以看成是专家判断[2]。当然,这个定义普适性太强、太宽泛,所谓专家判断,太依赖于被认为是专家的人,专家依赖于以往的历史经验,其推断过程不具备重复可模仿性,因而过程是不能复用的;此外,专家判断是主观层面的,理性支撑不足。
其次是算法模型,可采用多种算法模型,提取软件成本变量为主要驱动因子,将这些成本驱动因子组装成函数[3]。这些算法模型有乘法模型、表格模型、线性模型以及复合模型等。这种方法,把成本估算关系作为纽带,将系统特征和项目工作量、项目进度的预测估算值联系起来。不同算法模型,在成本因子的选取上不尽相同,最重要的是会在成本因子关系的表达式上有很大区别。
类比估算法,通常是基于以前完成的一个或多个项目,要求项目的相似度较高,有一定的可参照性,通过对其分析来预测当前项目的进度或成本。在软件项目的成本估算中,我们可以把每个已经完成的软件项目抽象为实例,将当前项目设置为待估算项目。从学术界的研究分析来看,关于类比估算方法的采用越来越多,1989年前发表论文1篇,1990—1999年发表15篇,2000—2004年发表15篇,2005年以来发表23篇。这说明类比估算法正在逐步被学术界和产业界接受,并投入应用实践中。
文章基于以上的研究背景,利用类比估算方法对于实际数据进行实证应用分析,通过实证分析证明,类比估算法能够较为可靠地估算出软件项目的工作量,可以作为一种可行的软件成本估算的手段。
1 类比估算方法研究
类比估算是以过去类似活动的参数值(如范围、成本、预算和持续时间等)或规模指标(如尺寸、重量和复杂性等)为基础,来估算未来活动的同类参数或指标的估算技术。这是一种粗略的估算方法,有时需根据项目复杂性方面的已知差异进行调整,是一种自上而下的专家判断。在项目详细信息不足时,就经常使用这种技术来估算项目的成本或活动持续时间。该方法综合利用历史信息和专家判断,常用在项目的早期阶段。相对于其他估算技术,类比估算通常成本较低、耗时较少,但准确性也较低。如果以往活动是本质上而不只是表面上类似,并且从事估算的项目团队成员具备必要的专业知识,那么类比估算就最为可靠。[13]
1.1 类比估算优势
类比估算相对于其他方法具有如下优势。
(1)用户更愿意接受类比方法生成的结果,因为它和人类解决问题的推理过程一致。
(2)它避免了知识启发、知识提取以及知识系统化等相关问题。
(3)基于类比的系统仅需要处理实际上发生的问题,人们通过分析类比数据库就可以了解类比的可信度。
(4)类比能够用于缺乏理解的领域,人们不需要对相关项目和领域都非常了解,这是因为类比方法使用的是实际存在的信息,这和基于规则的方案相反。
目前,关于类比方法的研究已经不断展开,不管是从理论上还是从应用上都有了新的突破。比如,1992年Mukhopadhyay[4]等人提出采用欧几里德距离来度量项目属性的相似度,并且开发出ESTOR估算辅助工具;1996年英国Bournemouth大学的Shepperd[5]等人通过对9个不同数据集的估算结果分析,论证了类比估算方法是一种切实可行的估算方法,并且组织开发了ANGEL估算辅助工具;2006年加拿大Calgary大学的Li Jinzhou和Ruhe[6]等人,根据前人的成果提出了一种新的类比估算解决方案AQUA,并且持续进行了相关的改进研究,研究出QAUA+算法,加入对于存在缺失值的数据集采用RSA(Rough Set Analysis)进行研究。而在现阶段国内很少有人开展类比估算方法应用方面的研究,关于这方面的研究论文也很少。大部分论文只是在列举软件成本估算方法的时候简单介绍了类比估算方法,或者是在论证类比估算应用在软件规模估算上的可行性分析以及算法原理介绍。
1.2 类比估算定义
定义1[7]此文中将项目历史数据集定义为一个三元组: DB=,其中:(1)P为项目集:P={P1,P2,…,Pn}。(2)A为项目的属性集:A={A1,A2,…,Am},A1~Am为项目的属性,其中A1为项目的规模(本文中以工作量—— 人·月表示,下文记为effort);(3)V={V11,…,V1m,…,Vn1,…,Vnm},其中Vij表示项目Pi的属性Aj的值。
设S={sn+1,sn+2,…,sn+k}为待估算的项目集合,假定:(1)S与P具有共同的属性集A;(2)S与P中项目的属性值不存在缺失现象。
则估算模型的问题域为:
定义2 根据项目P1~Pn的属性向量和待估算项目S的属性值计算待估算项目目标值Effort。
1.3 类比估算基本步骤
(1)提取相似项目,描述实例特征。
该步骤的任务是通过相似度量的方法將数据集中的项目逐个进行比较,从历史数据集DB中找到最相似项目集。
(2)决定最相似的N个项目。
该步骤的任务是以前一步骤的结果为基础,从项目集中得出N个最相似项目。
(3)用类似的项目数据得到最终的估算值。该步骤的任务是通过类似项目,作为经验数据来预测当前或未来项目结果,给出估算值,作为未来决策的依据。
(4)估算结果验证。在通过类比估算预测出项目开发成本后,需要在实际项目中对预测值进行验证。如果预测值满足历史数据库对精确度的要求,则可将其添加到历史数据库中。通常情况下,通过这种方法做过筛选的数据,比通过调查问卷得到的数据更加精确。
1.4 类比估算计算方法
根据Richter[7]关于局部全局相似度的度量方法和Wangenheim[8]等人关于各类属性局部相似度的定义,可以把属性分成以下几个类别:数值型、间隔型(或者说是范围型,如[0,1])、二值型、顺序型、无序型、分类型、字符串型和集合型。后来Fenton 和Pfleeger[9]提出,属性类型可以只分为5种类型:nominal、ordinal、interval、ratio和absolute。
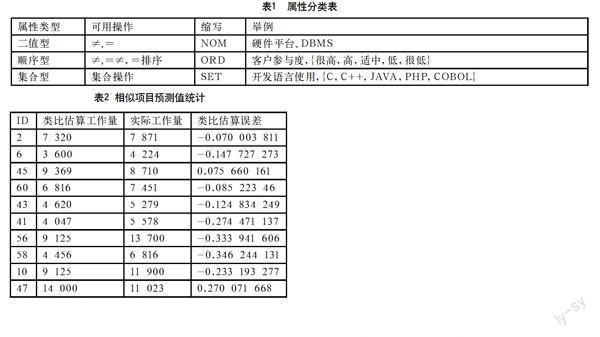
根据类比估算法在实际操作中对局部相似度量的要求,以及该论文历史数据集的数据实际情况对相似度度量中涉及到的属性进行了分类,如表1所示。
该文中计算项目之间的相似性主要是基于局部-全局规则的复合相似度度量方法[10]。主要思想是:两个项目之间的全局相似度是由各个属性的局部相似度加权计算出来的,而各个属性的局部相似度,则需要根据属性的不同类型进行计算。根据表1中所列出各种属性类型,分别给出计算方法如下。
(1)二值型变量。对于此类属性,我们只需关心其数据是否相同,若相同,取值1,否则,取值0。
在选取相似度项目进行调整的过程中,并不是选择的数量越多就越能得出最合理的结论。后增加的案例与目标案例之间的相似度会越来越小,误差会伴随着选取案例数量的增多而增大,所以必须选择数量合理的类似项目[11]。针对相似项目数量选择的问题,Jinzhou Li和Ruhe等人提出[6],以相似项目数量N作为参数,通过调整N来选择最合适的精度,从而确定最相似项目集合R。
在选取相似度项目方面,此文采用选取历史项目集中最小的Pi作为最相似项目,取Pi的工作量为目标项目工作量的估计值。即:
其结果为一个百分比数值。其中,k为MRE小于或等于x的估算次数,N为所有的估算次数。一般常用Pred (0.25)来判断估算模型是否合理。与Pred相比,MMRE和MdMRE比较容易受极端值的影响,因此在实际应用中一般优先考虑使用Pred评判,其次才是参考MMRE或MdMRE。
3 应用验证
3.1 计算验证
在使用类比估算对项目进行规模估计过程中,历史项目数据的数量、真实性、准确性对于目标项目工作量的估计有很大的影响。鉴于此,此文在数据收集过程中除利用前人在研究过程中使用过的成熟历史数据之外,另从中培创成科技有限公司所从事过的历史项目中按照给定属性集对原有的历史数据进行补充。在实际应用过程中,可对历史数据进行不断补充,增加估算的精确度。
鉴于很多情况下数据收集成本很高,此文在估算与验证过程中,使用的一部分历史数据集是Maxwell博士在《软件管理的应用统计学》附录中提到的数据集[10],另外一部分是由中培创成科技有限公司在实施的历史项目中按照Maxwell博士项目集中属性表进行填充,此文基于验证需要将无用参数从该数据集中剔除。
根据Maxwell博士在书中表述,Project 13与Project 14因为均为“客户应用程序”开发项目,没有应用数据库,数值为空,所以在计算验证过程中将其剔除。另据书中所述,语言是以任意顺序输入,而不是按照重要顺序排序,所以lan1空缺的由lan2递补。
鉴于区域不同会产生人工等成本的差异,在实际估算软件成本时,该文采用工作量等同于软件成本。另该文选取数据集中Project 2、Project 6、Project 45、Project 60、Project 43、Project 41、Project 56、Project 58、Project 10、Project 47作为目标项目进行估计,则该文参照项目数为90。
按照类比估算计算步骤,经过计算,得到目标项目与历史项目集各项目之间类似项目集合,如表2所示。
3.2 对比研究
为验证此文估算的精确度,此文应用中培创成科技有限公司在实践中进行软件项目规模估算方法对此文数据集中Project 2、Project 6、Project 45、Project 60、Project 43、Project 41、Project 56、Project 58、Project 10、Project 47进行工作量估算,将类比估算和专家估算两种方法预测值进行对比,发现应用类比估算的工作量估计值相较专家估算工作量更趋近于实际工作量。
此外,将类比估算和专家估算误差对比可知,采用类比估算时目标项目规模估算值与实际工作量之间差别较小,估算结果可信度较高。
上述研究将类比估算实际应用于软件成本估算过程中,根据类比估算的4个步骤,利用现有历史数据集进行实际操作。通过估算实践证明,类比估算方法作为一种可行的软件成本估算手段,能够成功估算软件规模,并将误差控制在可接受范围之内。
类比估算误差较小,说明类比估算结果可以较好地应用在软件项目规模估算实践中,从而在基线合理定义的提前下,有效地控制软件项目规模或项目范围的不断膨胀,增加了软件项目规模和范围控制的科学性,从而在项目实践中起到降本增效的作用。
3.3 总体分析
软件项目规模估计问题必须充分考虑软件项目进行过程中可能出现的各种约束,因为可能会面临数据不充分、团队成员经验缺乏或者估计出的数据不可信等问题。因此,在现实情况中,根据实际适用条件,选择软件规模估算方法是非常必要的。通过对大多数软件规模估算场景的分析,在借鉴前人研究的基础上,此文提出采用类比估算方法的软件项目规模估算策略。首先,在估算过程中采用历史项目数据,作为现有评价体系的输入,演化出利用属性值进行类比估算的模型;其次,通过实证研究,验证类比估算具体操作步骤,并以数据说明其在真实案例中的适用性,揭示其操作可行性;最后,通过对估计结果误差进行分析,分析类比估算时目标项目规模估算值与实际工作量之间的差别,得出估算结果可信度较高的结论。因此,类比估算可作为一种在大多数场景下都比较适用的估算方法,能够辅助我们的项目决策。
4 结语
针对目前软件项目规模估算中出现的问题,本文探索了基于类比估算的软件项目规模估计方法。针对历史项目数据以及现有评价体系,给出利用属性值进行类比估算的模型;给出类比估算操作步骤;在理论研究基础上,通过实例验证对目标项目规模进行估算。通过实证表明,类比方法能有效减少偏差,为项目的成本编制提供有效参考,该方法能够为软件项目规模估计和项目基线的定义提供一种有效实用的手段,辅助项目决策,提高项目管理质量。
此文尝试在前人理论研究成果基础上,将类比估算应用于软件项目规模估计实践中,利用历史数据的估算,充分地预测了未来软件项目成本及软件规模。同时,由于基础数据样本具有代表性,能够可靠地评估预测风险,从而对置信度进行有效评判,避免了结论的主观性。
虽然此文在估算结果方面取得比较满意的结果,但是还存在一定的不足,文章文在前期对数据集进行一定的处理,剔除掉数据有缺失的项目,加拿大Calgary大学的Li Jinzhou和Ruhe等人在其研究成果中剔除可以利用Rough set analysis方法来解决数据缺失问题,在接下来的进一步研究中可以进一步加以应用。另外,关于参数的相似度贡献系数的确定方面,此文并未找出一种更合理的确定方法,需要改进。
参考文献
[1]The Standish Group.2004 the 3rd Quarter Research Report[EB/OL].http://www.standishgroup.com.
[2]Delany SJ,Cunningham P,Wilke W.The limits of CBR in software project estimation. In: Gierl L,Lenz M, eds.Proc. of the 6th German Workshop on Case-Based-Reasoning[M].Berlin: Springer-Verlag,1998.
[3]B.W.Boehm.“Software Engineering Economics”IEEE Trans[D].Software Eng.,1984.
[4]Mukhopadhyay T,Vicinanza S S,Prietula M J.Examining the Feasibility of a Case Based Reasoning Model for Software Effort Estimation[J].MIS Quarterly,1992(6):155-171.
[5]Shepperd M,Schofield C.Estimating Software Project Effort Using Analogies [J].IEEE Trans on Software Engineering,1997,23(12):736-743.
[6]Li J,Ruhe G,Al2Emran A,etal.A Flexible Method for Effort Estimation by Analogy[J].Empirical Software Engineering,2006,12(1):65-106.
Angelis L,Stamelos I.A Simulation Tool for Efficient Analogy Based Cost Estimation[J].Empirical Software Engineering,2000,5(1):35-68.
[7]Richter M M.On the Notion of Similarity in Case-Based Reasoning[C]//Della Riccia Getal ed.Mathematical and Statistical Methods in Artificial Intelligence,1995:171-184.
[8]Wangenheim C G,Alt hoff K,Barcia R M.Goal-Oriented and Similarity-Based Retrieval of Software Engineering Experience ware[C]//Proc of t he 11th Intl Conf on Software Engineering and Knowledge Engineering,Learning Software Organizations,Methology and Application, 1999:118-141.
[9]Fenton N E,Pfleeger S L.Software Metrics: A Rigorous & Practical Approach [M].2nd Edition.Boston:PWS Publishing Company, 2000.
[10]Briand L C,Emam K,Bomarius F.COBRA:A Hybrid Method for Software Cost Estimation, Benchmarking and Risk Assessment[C]//Proc of the 20th Intl Conf on Software Engineering,1998:390-399.
[11]Angelis L,Stamelos I.A Simulation Tool for Efficient Analogy Based Cost Estimation[J].Empirical Software Engineering,2000,5(1):35-68.
[12]Maxwell K D.軟件管理的应用统计学[M].张丽萍,梁金昆,译.北京:清华大学出版社,2006.
[13]Project Management Institute.项目管理知识体系指南[M].5版.许江林,译.北京:电子工业出版社,2013:169.
猜你喜欢
数学教学通讯·小学版(2016年12期)2017-02-07 03:30:38
数学学习与研究(2016年18期)2017-01-07 09:24:22
科技创新导报(2016年23期)2016-12-23 10:41:08
教学研究与管理(2016年9期)2016-11-15 07:21:03
启迪与智慧·教育版(2016年8期)2016-10-20 15:56:21
课程教育研究·学法教法研究(2016年19期)2016-09-07 14:35:45
课程教育研究·学法教法研究(2016年19期)2016-09-07 14:34:51
科技传播(2016年1期)2016-03-22 00:42:32
新课程·上旬(2015年12期)2016-01-27 19:57:55
科技视界(2015年30期)2015-10-22 12:23:01
