
护理单元劳动强度和风险定量的评价方法研究及应用
2016-04-11 03:07隆飞曹亚宁陆玉娇王志刚
中国医疗管理科学 2016年1期
隆飞 曹亚宁 陆玉娇 王志刚
作者单位:200120 上海蓬海涞讯数据技术有限公司(隆飞、陆玉娇、王志刚);内蒙古自治区巴彦淖尔市医院(曹亚宁)
护理单元劳动强度和风险定量的评价方法研究及应用
隆飞 曹亚宁 陆玉娇 王志刚
作者单位:200120 上海蓬海涞讯数据技术有限公司(隆飞、陆玉娇、王志刚);内蒙古自治区巴彦淖尔市医院(曹亚宁)
【摘要】目的 期望建立一个客观、公允的护理劳动强度和风险评价模型,作为护理定岗定编和绩效管理的依据。方法利用量表抽样统计和业务数据量化评价相结合的方法,确定不同护理单元的风险等级。参考以资源为基础的相对价值系数,从精神压力、生理负荷、风险程度、技术难度4个维度设计量表。引入量表的信度和效度分析方法,依据效度对量表进行校正。在信度可信的前提下,再使用聚类方法对各护理单元的业务数据进行量化分析,依据结果对抽样统计数据进行校正,计算各等级的对应系数或权重。 结果 该评价模型取得的结果与医院管理者和一线护理人员的预期较为一致;将研究结果用于10余家不同类型医院的护理岗位定岗定编和绩效管理,取得了较好的效果。结论 通过量表抽样统计建立护理风险评价模型具有可行性,关键在于抽样方法科学,量表信度分析结果可靠。由于医院收费数据受到数据采集时点、医院业务特点等因素限制,不能以客观业务数据作为护理单元风险等级的主要依据。如果使用全部临床业务数据,可能会更准确,或者可以考虑替代量表调查的方式建立新的评价模型。
【关键词】绩效管理;护理单元;劳动强度;风险评价;定岗定编
国内医院科室管理中,病区医生和护理单元绑定在一起作为一个专业科室完成各项诊疗活动。这种科室管理模式造成了同一个住院床日和出院人次,在不同专科,如神经外科、重症监护室、眼科等的护理工作强度不一致。无论是从人事管理的定岗、定编要求,还是从绩效管理的工作量评价,都需要区分出这些科室的工作强度和风险的差异。目前,国内同行使用一些具体的工作量数据作为评价依据,如床位使用率、周转率、收治危重病人数、一级护理数等,还有将是否直接接触有毒有害物质、是否有感染传染病危险等作为依据,将护理单元分成四等,再将护理人员绩效与岗位挂钩[1]。也有利用专家问卷调查,结合护理单元执行的具体数据,通过统计方法建模分析以划分不同护理单元的风险等级的办法[2]。通过研究,我们认为可以通过抽样调查结合专家打分,使用一个具有一定效度的量表,对抽样数据进行信度测算,做出较为合理的护理单元劳动强度和风险的分等或分级办法,并建立标准的数学模型。利用算术平均数或层次分析法,可为不同护理单元建立量化的等级系数,再结合各护理单元产生的客观收费数据,对护理执行项目数据进行分析,以较为准确地评价各护理单元的风险和劳动强度。本研究使用了基于资源消耗的相对价值系数(Resource based relative value scale ,RBRVS)的劳动价值相对点数 (Work relative value unit, WORK RVU)对医院信息系统(Hospital Information System, HIS)收费的护理相关数据进行了量化,在此基础上对客观数据进行聚类分析。
1量表设计
1.1样本的抽取
抽取在医院完成轮转的1年~3年的护士及全院所有护士长。抽取这两个群体的原因为:在医院完成轮转的1年~3年的护士年资低,工作在一线,对各科的工作强度和风险具有较为清晰的评价[3],且这些护士大多还没有固定的专业和科室,在评分上会相对客观。而护士长群体代表了护理专家,护理专家对护理工作的强度和风险有更深刻的认识,对全院的护理业务也有较深入的了解,如果能保持评分过程客观公正,数据的信度会比较高。抽样时根据轮转护士的规模确定所要抽取的轮转护士人数,并按照其所在科室,采用分层抽样法,根据所要抽取的轮转护士人数,按照各科室轮转护士人数占轮转护士总比例的方法来确定各科室抽取的轮转护士比例;对于护士长,由于人数不多全部抽取。
1.2量表的结构、内容与评分标准
本量表属于他评量表, 量表评价者为抽取的轮转1年~3年的低年资护士和所有的护士长。量表全部为闭合式问题,医院根据自身情况来选择需要护理分级的科室。每个科室从以下4个维度来描述:精神压力、生理负荷、风险程度、技术难度。
每个维度的评分采用Likerts Scales的形式,评价者根据对工作的认知对各个维度进行评价,从完全不同意到完全同意共5个等级:完全不同意,计1分;不同意,计2分;不确定(中性),计3分;同意,计4分;完全同意,计5分。为方便比较,将各个维度的总分定为100分。轮转护士打分权重与护士长打分权重按照各自量表信度系数的比例来确定。比如C科室的精神压力维度,轮转护士共有a人打分,总得分为A,量表信度为a1;护士长b人打分,总得分为B,量表信度为b1,则C科室精神压力维度得分为:A/5a x 100 x a1/(a1+b1)+B/5b x 100 x b1/(a1+b1)。其他维度得分计算方法相同。
1.3量表的效度和信度
进行问卷式调查研究的统计分析前,应考评问卷的信度和效度,以确保研究结果的可靠性和准确性[4]。
1.3.1效度
效度即有效性,分为3种类型:内容效度、准则效度和结构效度。效度分析有多种方法,其测量结果反映效度的不同方面。常用于调查问卷效度分析的方法主要有以下两种:①内容效度:又称表面效度或逻辑效度,它是指所设计的题项能否代表所要测量的内容或主题。对内容效度常采用逻辑分析与统计分析相结合的方法进行评价。统计分析主要通过计算每个题项得分与题项总分的相关系数,根据相关是否显著判断是否有效[5]。本研究的量表设计由最初的8个指标或维度减少到当前的4个维度,是参考了RBRVS的构建结构设计的量表,经过多家医院多组数据校正,效度较高。②结构效度:是指测量结果体现出来的某种结构与测量值之间的对应程度:分析所采用的方法是因子分析。通过因子分析可以考察问卷是否能够测量出研究者设计问卷时假设的某种结构[6]。在因子分析的结果中,用于评价结构效度的主要指标有累积贡献率、共同度和因子负荷。累积贡献率反映公因子对量表或问卷的累积有效程度,共同度反映由公因子解释原变量的有效程度,因子负荷反映原变量与某个公因子的相关程度。
1.3.2信度
信度即可靠性,多以相关系数表示,大致可分为3类:稳定系数(跨时间的一致性)、等值系数(跨形式的一致性)和内在一致性系数(跨项目的一致性)。信度分析的方法主要有以下4种:①重测信度法。该方法是用同样的问卷对同一组被调查者间隔一定时间重复施测,计算两次施测结果的相关系数。重测信度>0.7时,显示量表具有较好的时间稳定性[7]。②复本信度法。复本信度法是让同一组被调查者一次填答两份问卷复本,计算两个复本的相关系数。③折半信度法。该方法是将调查项目分为两半,计算两半得分的相关系数,进而估计整个量表的信度。折半系数>0.8时,认为量表具有较好的折半信度。④α信度系数法。该信度分析方法是目前最常用的方法,本文中使用Cronbach's α系数作为信度依据。
其公式为: α=k/(k-1) x (1-∑Sii^2/ST^2) 。
其中,k为量表中题项的总数,Sii^2为第i题得分的题内方差,ST^2为全部题项总得分的方差。Cronbach's α系数与信度水平的关系为:Cronbach'sα系数为0.9~1.0代表信度水平为十分可信;0.7~0.9为很可信;0.5~0.7为比较可信;0.4~0.5为可信;0.3~0.4及0.3以下代表勉强可信和不可信。
2数据分析和利用
此量表曾在国内10余家不同级别、不同类型的医院中使用,为了准确描述该量表,本文挑选其中一家医院的数据进行分析。共调查了24个科室,发放问卷100份,护士长20份,轮转护士80份,收回问卷80份,其中护士长20份,轮转护士60份。1个月后再次发送80份给第一次收回的80人,收到80份。
2.1数据预处理
在轮转护士和护士长评价各个科室护理情况时,对于自己科室的调查结果,可以采用以下方式处理:①删除自己科室的数据;②插入平均数或众数作为自己科室的数据;③可插入3分(分值是1分~5分)。对于问卷中有部分空值或异常值(任一科室任一维度连续13个得分完全一致,可将此完全相同的值视为异常值),可以插入本列数据的众数、平均数或给予3分。所有的空值只能采取其中一种方式处理。
2.2效度分析
在做效度分析时,我们选择了内容效度和结构效度对量表进行分析。
2.2.1内容效度分析
使用统计分析方法对内容效度进行分析,结果显示各个维度与总得分的相关性较高,见表1。
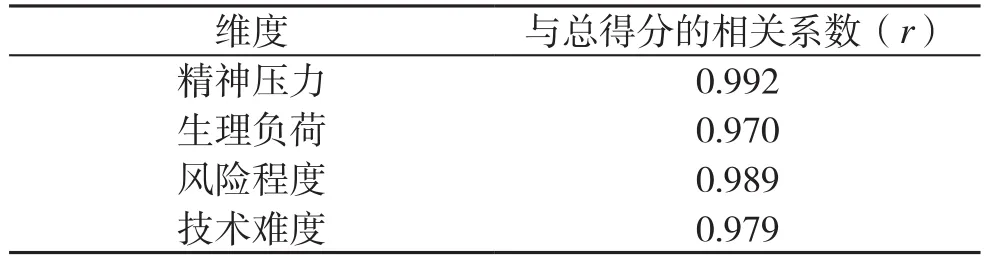
表1 各维度得分与总得分相关系数
2.2.2 结构效度分析
因子分析是检验量表结构效度的常用方法,应用因子分析评价一个量表的结构效度,说明效度好通常要符合公因子应与调查表设计时的结构假设的组成领域相符,且公因子的累积方差贡献率至少在0.7以上。以上每个条目都应在其中一个公因子上有较高的负荷,而对其他公因子负荷值较低[8]。本量表因子分析结果显示,经KMO和Bartlett检验,KMO统计量为0.780,球形检验值为180.590,显著水平为0.000,表明用因子分析是适宜的。
采用主成分分析法进行因子分析,从因子分析中提出前2个因子,累计贡献率达到98.585%,每一个维度与因子的共同度都达到0.7以上,并且每一个维度与因子的载荷系数都能达到0.55以上,具体见表2、表3。说明量表的每一个维度都能有效解释总得分,每一个维度的选取有意义。因此,量表的结构效度较好。
2.3信度分析
信度分析采用Cronbach's α系数测量内在的一致性,结果显示,Cronbach's α标准化系数为0.989;采用重测信度测量量表的跨时间稳定性,即对同一批轮转护士和护士长1个月后又进行了同一份问卷的测试,两次问卷总量表的重测信度系数为0.972,精神压力、生理负荷、风险程度、技术难度4个维度的重测信度系数分别为0.979、0.979、0.965、0.959,总量表及各个维度的重测信度系数均大于0.9,说明此量表具有非常好的时间稳定性,是可信的。

表2 解释的总方差
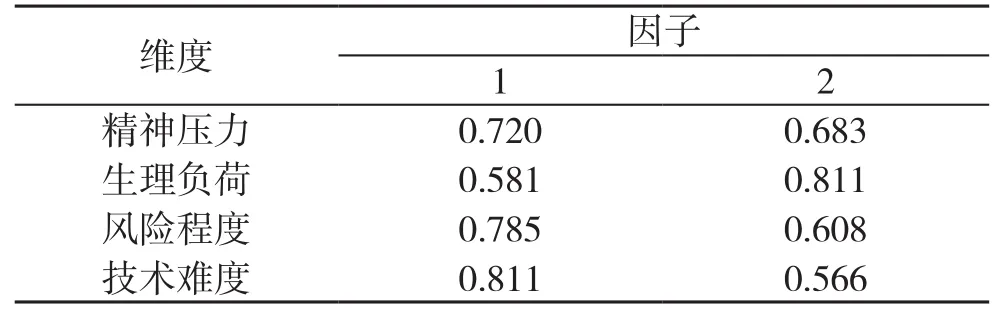
表3 旋转成份矩阵a
2.4信度低的矫正方法
当用此量表进行信度检验显示信度较低时,可采用以下方法进行矫正:①补充问卷和增大样本量。当信度较低时,继续使用分层抽样法再抽取部分轮转护士,用同样的问卷进行测试,之后再次计算信度。②剔除相关性低的维度。计算出每一个维度分值与总分分值的相关系数,相关系数过低时,可酌情剔除此维度。③补充新的问卷。当信度较低时,可以补充新的问卷,采用分层抽样法对轮转护士和护士长进行测试。新的问卷仍应保持效度稳定,与旧的问卷除表述方式不同外,在内容、格式、难度和对应题项的提问方向等方面要完全一致,而在实际调查中,很难使调查问卷达到这种要求,因此采用这种方法者较少。④使用客观数据来矫正。通过HIS收费记录及病案首页记录等客观数据对量表得分进行矫正,如可采用一、二、三级不同级别护理的护理率;侵入性护理如鼻饲管指标、导尿指标、各类引流等;生命支持护理如机械通气、气管切开、气管插管、心肺复苏等。将这些客观数据用聚类等方法对科室护理单元的量表调查数据进行校正,医院可根据这些客观数据来对量表中已分类的存在争议的科室进行调整。
2.5利用量表的数据测算护理单元的等级系数
当数据的效度稳定、信度可信时,可对量表数据进行测算,计算出不同护理单元的等级系数,在管理实践中使用这些数据。对于系数的计算,可采用算数系数法、改进的算数系数法及聚类分析法。
2.5.1算数系数法
算术系数法是将4个维度看成同等重要,即4个维度的得分按照权重为“1”相加得到总得分,用每一个科室的总得分除以所有科室的平均得分来算出各科室的系数;再将所有科室分为8个等级,每等级3个科室,取同等级内3个科室的科室平均系数作为等级系数,见表4。
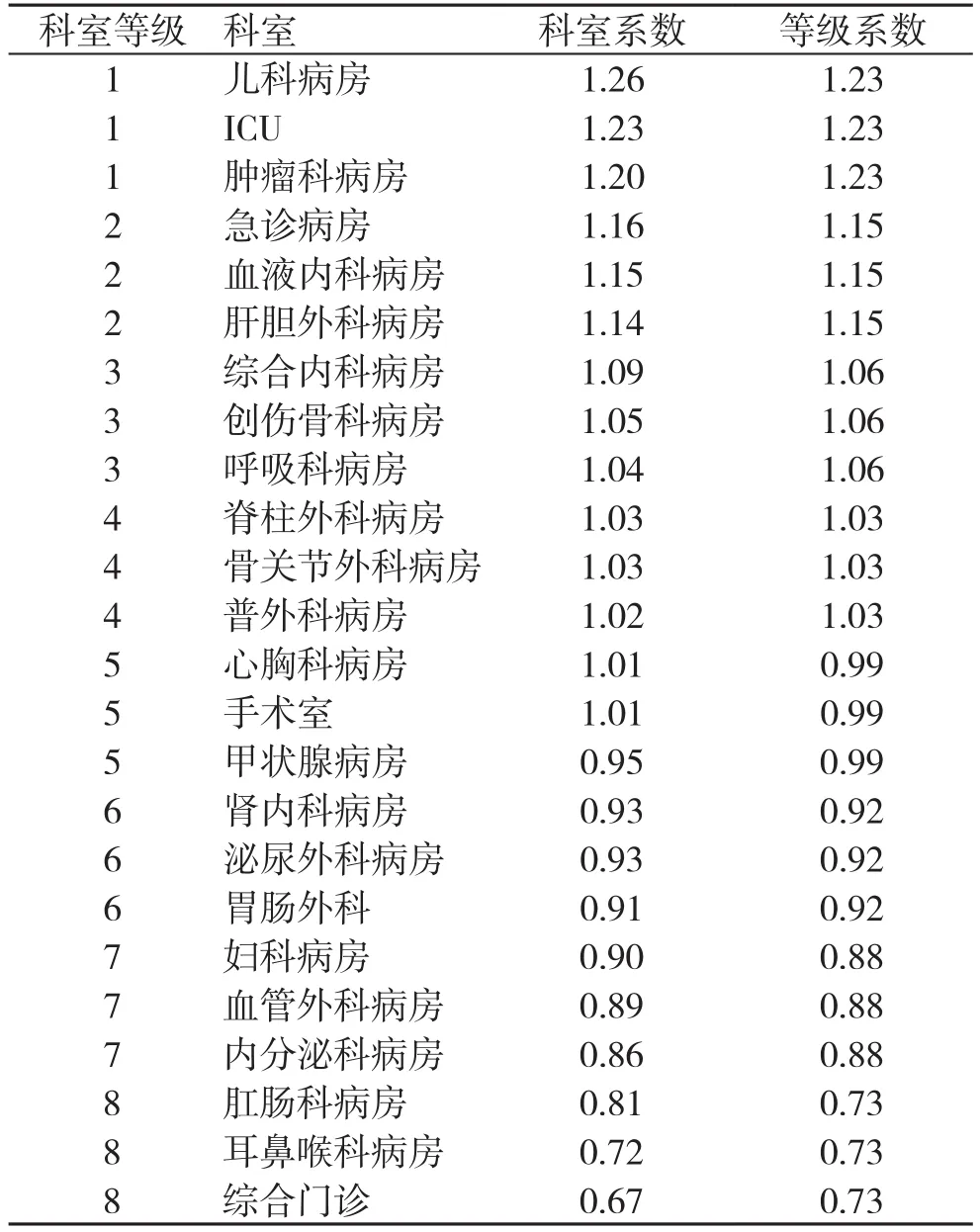
表4 某市级医院科室等级算术系数
此方法的优点是每个科室都有具体的系数,同一等级内的系数相同,对于科室的风险等级评价而言非常具体,缺点是对每个维度都赋予同样的权重,在实际应用中未必公允。因此,对部分科室等级临界的科室,分等是否合理,会有一定的争议。
2.5.2改进的算术系数法(使用层次分析法进行改进)
由于算术系数法是将各个维度看成同等重要,而在实际应用中,各个医院对护理分级的侧重点有所不同,所以各个维度的权重也有所不同,对此,可使用层次分析法对各个维度赋予权重,之后再使用算术系数法进行计算,从而进行修正。此方法的优点是对科室的评价非常具体,同时医院可根据自身情况调整各维度的权重,从而更为客观真实地反映护理工作强度。缺点是各权重的评定存在主观因素,如何客观地对各维度间的重要性进行比较有一定难度。
层次分析法是美国运筹学家T.L.Satty教授于20世纪70年代初期提出的一种简便、灵活而又实用的多准则决策方法。它是一种将决策者对复杂系统的决策思维过程模型化、数量化的过程。层次分析法的步骤如下[9]。
(1)建立递阶层次结构:应用层次分析法分析决策问题时,首先要把问题条理化、层次化,构造出一个有层次的结构模型。如果是原始数据都需要我们先按量表的评分,然后再建立两两比较距阵。距阵的建立需要组织护士长按层次分析法的要求进行打分,参加人数不少于30人。
(2)建立两两比较的判断矩阵:对相关元素之间相对重要性进行比较,一般采取此形式,见表5。
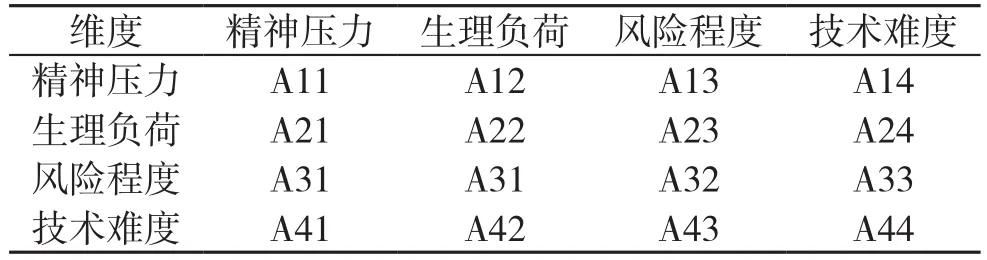
表5 某市级医院科室等级算术系数
判断矩阵中的 Aij是医院根据自身的情况研究后确定。
(3)层次分析法权重向量W的计算:计算某一层有关元素对上一层元素的权重值,最常用的方法是和积法和方根法。
然后将归一化后的各列相加;最后将相加后的向量除以 n 即得权重向量,即:
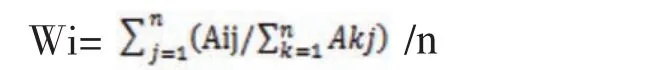
方根法(几何平均法):首先将 A的元素按行相乘得一新向量;然后将新向量的每一个分量开 n次方;最后将所得向量归一化即为权重向量,即:
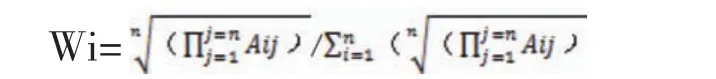
在层次分析法确定权重后,再将权重因素加到算术系数法的计算中。
2.5.3聚类分析
使用聚类分析法对所有量表数据进行处理,通过聚类分出等级。由于聚类数据所分出的组别,每组内的科室数量不确定,理解聚类的算法和数据代表的意义需要一定的统计学基础知识,较难向临床护理人员解释此结果,实践中,多用于在确定系数前的分析和校正使用。
(1)k-均值聚类:此算法是一种基于划分的经典聚类算法之一,采用欧式距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法的核心思想如下:首先从所给n个数据对象中随机选取k个对象作为初始聚类中心点,然后对于所剩下的其他对象则根据它们与所选k个中心点的相似度(距离)分别分配给与其最相似的聚类,然后重新计算所获聚类的聚类中心(该聚类所有对象的均值),不断重复这一过程直到标准测度函数开始收敛为止。 k-均值聚类较容易解释,聚类效果好,处理大数据时效率很高,所以应用较为广泛。主要缺点是初始聚类中心的选择对聚类结果有较大的影响,一旦初始值选得不好,可能无法得到有效的聚类结果。具体分为几类,各医院可根据自身的情况而定。利用SPSS 19.0将某省级医院护理分级分为6类,测算结果见表6。
(2)系统聚类法:系统聚类法是将样品分成若干类的方法,其基本思想是先将样品各看成一类,然后规定类与类之间的距离,选择距离最小的一对合并成新的一类,计算新类与其他类之间的距离,再将距离最近的两类合并,这样每次减少一类,直至所有的样品合为一类为止。优点是能灵活控制不同层次的聚类力度,增强聚类能力,缺点是不能回溯处理,影响结果准确性。
2.6测算数据应用
以上各方法都有自身的优缺点,医院可根据自身情况选择其中一种方法对结果进行处理。使用算术系数法及修正的算术系数法时,算出来的系数可用于护理的出院人次、占床日数的护理工作量评价上,护理工作量可在基础值上乘以算术系数,以反映不同护理单元之间劳动强度的差异。
对于聚类法算出的类别,医院需先根据自身需要确定护理单元分成几等的数据,每一等级数对应不同的护理费用,以反映不同护理级别之间费用的差异。
2.7客观数据的统计分析
以上量表是采用人为的主观因素来对科室的各个维度进行评价,可以较准确断定护理单元分级的方法。但在实践中,仍有个别护理单元可能会在临界点上,向上或向下浮动一档,可能会更为合理。是否可以浮动,需要除量表以外的数据支持,为此我们增加了客观数据分析,对其加以校验,同时也可以参考客观数据,对量表中相邻护理单元最终等级进行修正。2.7.1客观数据的内容
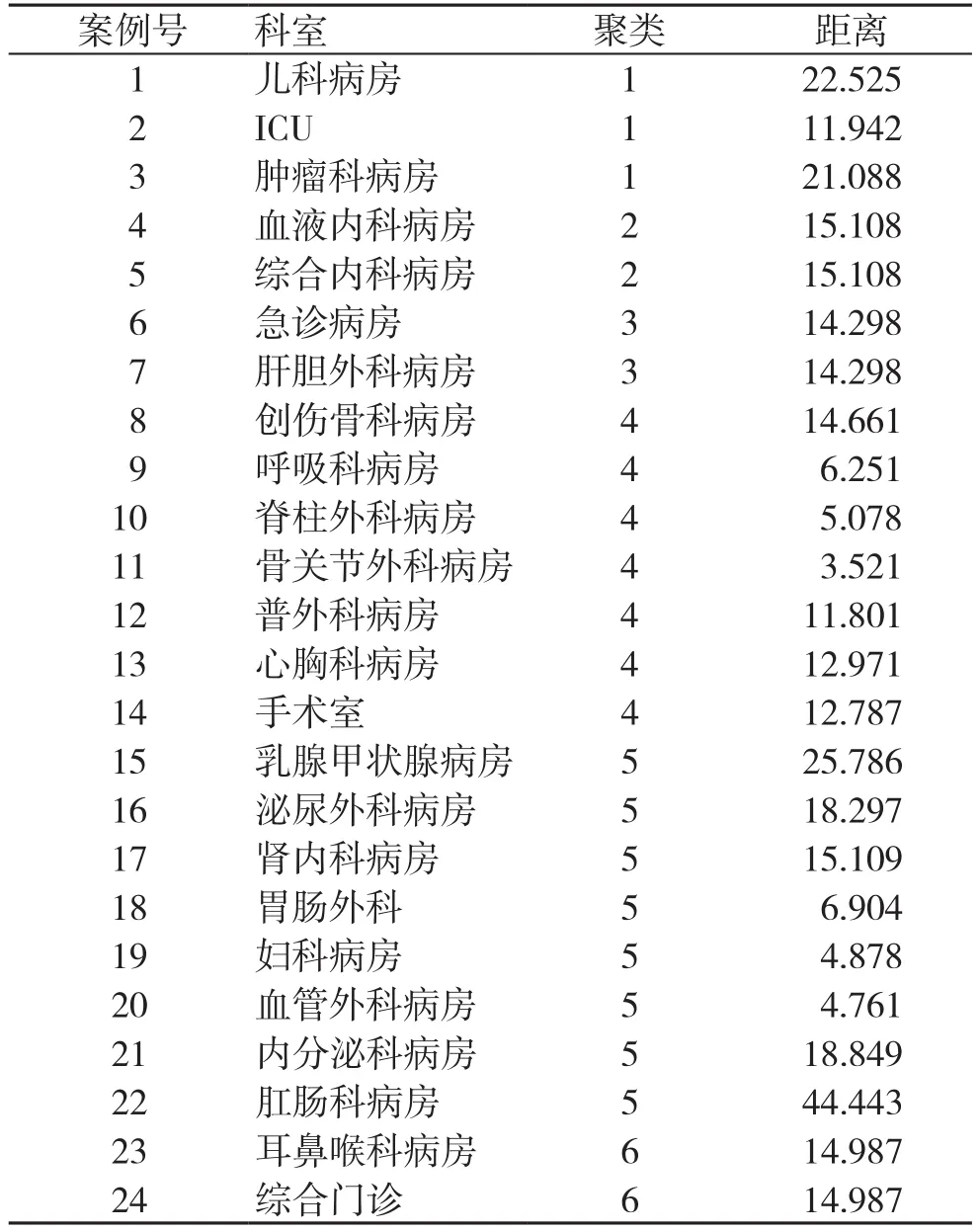
表6 聚类成员
为了客观地对护理单元风险和劳动强度进行分析,我们根据护理工作内容,采集了护理工作的客观数据,主要分为以下几个维度和客观的收费数据。①等级护理指标:一级护理、二级护理、三级护理、新生儿护理、重症监护;②生命支持护理 :气管插管、气管切开护理、有创机械通气、人工膜肺、床旁透析或血液灌流、心电监护、动态血压监测;③侵入性护理指标:导尿管留置导尿、肛管排气;④引流指标:负压引流、引流管引流、持续膀胱冲洗;⑤静脉治疗指标:静脉穿刺置管术、静脉切开置管术、中心静脉穿刺置管加测压、动脉穿刺置管术(测压加收);⑥输液工作量指标:静脉输液2瓶及以上、静脉输液微量泵或输液泵加收、小儿头皮静脉输液2瓶及以上。
2.7.2数据预处理
通过收费系统采集到上述客观数据,对上述数据使用RBRVS的WORK RVU赋值。由于RBRVS 的WORK RVU是一种评价医务人员劳动付出的较为公平的方法[10],可以用于评价不同护理项目需要护理人员付出的劳动时间以及对护理人员的技能要求,较使用项目价格更为可靠。针对不同项目数据的数量级大小不一致,所以先对数据进行标准化处理。本研究采用的是MIN-MAX标准化,将每一个数据映射到0~1内。公式为:(Xi-MINxi)/(MAXxi-MINxi)。同时每一个维度的得分为每一个维度下各项目的客观数据与此项目所对应的RBRVS分值的乘积之和。
2.7.3数据分析
(1)K-均值聚类:对以上数据聚类分析,案例号代表科室,聚类代表分类类别号,距离数据是参考数据。如同为1类的ICU和儿科病房,其代表共同的聚类类别识别物征,说明将这两个科室分在一个等级中是有客观数据支持的。分类数据如表7所示。
(2)客观数据聚类与量表系数的对比分析:我们将表7的数据与表4的量表数据进行合并对比分析,可以发现肿瘤科病房在量表调查中得到的系数较高,但是在聚类分析中,其客观数据特征与综合内科、创伤骨科更为接近,实际上,可以将其下调到下一等级,即等级系数为1.15,将急诊科调整到上一等级,等级系数为1.23,这样的调整,事实上与医院管理层的预期也较为一致。量表数据分级与客观数据聚类类别比较分析见表8。
3结论
我们通过量表与客观数据相结合的方式,期望利用有效、可信的量表,结合客观数据建立一个公允的护理劳动强度和风险评价方法及数学模型,科学合理地对护理单元的劳动强度和风险进行分级。通过量表数据,建立不同护理单元的等级系数,为绩效管理和定岗定编提供科学、客观的依据。
通过对国内10余所不同规模、不同级别的医院进行护理分级的尝试,发现此量表和客观数据较能公允、客观地反映护理劳动强度,各家医院的系数相对稳定,与各病区护理劳动强度基本匹配。
为了更为客观科学地评价不同护理单元的劳动强度,此量表在设计上从多个维度反映护理劳动强度,摆脱了目前单一以病人出院人次或床位使用率对护理单元进行工作强度分级的局限性。在对量表的发放上,遵循了统计抽样方法;在量表分析阶段,为了科学评估测量结果,对量表进行了效度和信度分析,以确保数据真实有效并且能客观反映护理劳动强度;在量表处理阶段,也给出了不同的处理方法,包括算术系数法和聚类法,更为科学地对数据进行处理。通过一系列严谨的处理方法,以尽可能地使量表能够更为真实客观地反映护理劳动强度。
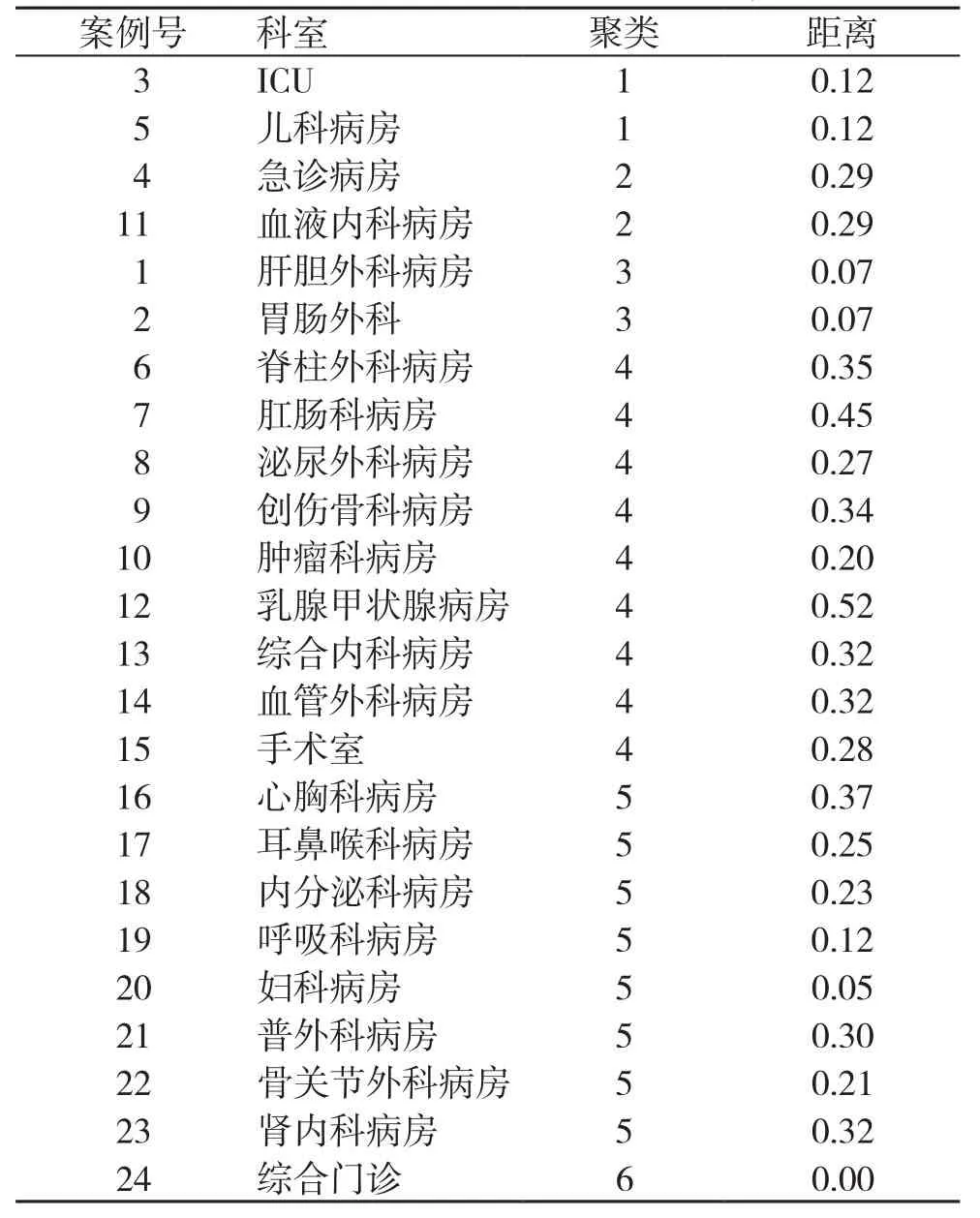
表7 各科室客观数据K均值聚类

表8 量表数据分级与客观数据聚类类别比较分析
然而此量表还有很多不足的地方:①量表虽然从多个维度来考察护理分级,但由于个体差异,每个人对各个维度的理解有偏差,会对结果产生一定影响。②量表考核护理的工作量有一定延迟性,量表的考核内容是基于护理人员对过去劳动强度的认知,与现在的劳动强度无法完全符合。③在对量表的处理方法上,每一种方法都有一定的缺点,很难精准地评估结果。
在使用客观数据对量表进行修正时,也存在一些问题。①所有的工作量并不能完全用客观数据来体现,由于各护理单元(科室)专业分工的差异,客观数据的选择对聚类分析的结果影响较大。同时部分客观数据并未完整记录,完全使用现有的客观数据会对结果产生一定偏差。②客观数据的记录不一定完全准确,同时收集客观数据也会产生一定的成本。③使用聚类分析客观数据,分析过程不够直观,临床护理人员易对结果的客观性产生怀疑。
参考文献
[1] 肖晓玲,张东华, 高建智,等. 护理岗位分类管理的方法与效果[J].护理管理杂志,2011, 11(10) : 733.
[2] 强万敏,王盈,胡晶敏,等.临床科室护理风险分级的测评及应用[J].护士进修杂志,2013, 28(23) : 2139.
[3] 丁炎明.护士对生活护理认识现状的研究[J].中华护理杂志,2005, 40(2) : 120-122.
[4] 刘朝杰. 问卷的信度与效度评价[J]. 中国慢性病预防与控制, 1997, 3 : 81.
[5] 柯惠新.调查研究中的统计分析法[M].北京:北京广播学院出版社,1996 : 361-363.
[6] 马文军,潘波.问卷的信度和效度以及如何用S A S软件分析[J].中国卫生统计,2000, 17(6) : 364-365.
[7] 曾五一,黄炳艺.调查问卷的可信度和有效度分析[J]. 统计与信息论坛,2005, 20(6) : 11-15.
[8] 巫秀美,倪宗瓒. 因子分析在问卷调查中信度效度评价的应用[J] .中国慢性病预防与控制,1998, 6(1) : 28-31.
[9] 何钦成,王孝宁,韩大勇.群组判断中求权向量的一种新方法[J].中国卫生统计,2003, 20(2) : 72-75.
[10] Sherry L Smith, Susan Clark. Medicare RBRVS 2014:The Physicians Guide[M]. Chicago: Americal Medical Asociation, 2013.
·绩效管理·
Study and application of evaluation methods for labor intensity and risk quantification in nursing unit
Long Fei, Cao Yaning, Lu Yujiao, et al. Shanghai Palline Data Technology Co., Ltd. (Long Fei, Lu Yujiao, Wang Zhigang), Shanghai 200120; Bayinnaoer City Hospital, Inner Mongolia Autonomous Region (Cao Yaning), China
Corresponding author: Wang Zhigang, Email: zg_wng@139.com
【Abstract】Objective The paper aims to build an objective and fair evaluation model for nursing labor intensity and risk as the basis for the definition of work posts and personnel quota and the performance management of nursing. Method Scale sampling statistics and business data quantification and evaluation are combined to determine the risk ranks of different nursing units. The scale is designed based on four dimensions, namely, mental stress, physiological load, risk degree, and technical difficulty, by reference to the resource-based relative value scale (RBRVS). Reliability and validity analysis is introduced into the scale to correct it on the basis of validity. On the premise of reliability, clustering method is used to quantitatively analyze the business data of nursing units. The statistical data of sampling are corrected based on the analysis result to calculate the coefficient or weight corresponding to each rank. Result The result obtained by the evaluation model is basically consistent with the expectation of hospital managers and frontline nursing personnel. Relatively good effect is achieved when the study result is applied in the definition of nursing work posts and personnel quota and the performance management of over 10 hospitals of different types. Conclusion The nursing risk evaluation model built through scale statistics and sampling is feasible, and the key lies in the scientific sampling method and the reliable analysis result of scale reliability. Because the data of hospital charges are restricted by factors like data acquisition time, hospital business characteristics, and so on, it is not advisable to take objective business data as the main basis for risk rank of nursing unit. If all clinical business data are adopted, the result may be more accurate; or we can consider building a new evaluation model by replacing scale survey.
【Key words】Performance Management;Nursing unit; Labor intensity; Risk evaluation; Definition of work posts and personnel quota
收稿日期:(2015-12-15)
通信作者:王志刚,Email:zg_wng@139.com
猜你喜欢
中国科技纵横(2016年20期)2016-12-28
绿色科技(2016年20期)2016-12-27
科学与财富(2016年29期)2016-12-27
中国市场(2016年36期)2016-10-19
中国市场(2016年36期)2016-10-19
商(2016年27期)2016-10-17
科学与财富(2016年28期)2016-10-14
科技视界(2016年24期)2016-10-11
