
一种基于粗糙集的视觉单词生成方法
2016-03-03 08:34赵鹏坤时恺泽张素兰
太原科技大学学报 2016年1期
关键词:粗糙集
赵鹏坤,时恺泽,张素兰
(1.太原科技大学计算机科学与技术学院,太原 030024;2.内蒙古大学计算机学院,呼和浩特 010021)
一种基于粗糙集的视觉单词生成方法
赵鹏坤1,时恺泽2,张素兰1
(1.太原科技大学计算机科学与技术学院,太原 030024;2.内蒙古大学计算机学院,呼和浩特 010021)
摘要:针对传统BOV(Bag-of-visual words)模型,存在的歧义视觉单词影响分类精度和效率等问题,采用粗糙集属性约简,提出一种视觉单词生成方法。首先,利用BOV模型,生成训练图像集和视觉词典,并将其抽象为决策信息表,其中:决策表中对象按类分别标记作为决策属性,视觉词典中的视觉单词标记为条件属性;然后根据决策表中决策属性的等价集和条件属性的等价集,建立不相容对象等价集,并对决策表中每一个条件属性进行启发式学习,保留能够引起不相容等价集数目变化的视觉单词,形成必要视觉单词集合;其次,根据必要视觉单词集合,结合相对知识粒度,来衡量决策表中不必要视觉单词的重要度,保存重要度值高的视觉单词,消除属性重要度低的视觉单词,形成约简视觉单词集合,从而有效地消除了视觉词包中,存在的歧义视觉单词;最后通过实验验证了该方法对视觉单词约简是有效的和可行的。
关键词:视觉单词;粗糙集;属性约简;知识粒度
基于BOV模型[1]的图像表示方法,因其对图像放缩、旋转以及仿射变换保持不变性,同时对噪声、视觉变化保持一定的稳定性,能够有效表达图像内容成为底层视觉特征与高层语义的桥梁,因而在图像场景分类[2]领域得到广泛应用。典型工作:文献[3]在建立BOV模型的基础上,通过融合空间上下文语义关系和图像块特征相似性,给出了图像场景分类方法,在一定程度上提高了分类精度;文献[4]针对全局特征对超声图像进行描述存在一定局限性,提出了一种利用局部特征描述超声图像,并结合多示例学习对超声图像进行分类。在一定程度上弥补了语义鸿沟[5],提高了场景分类精度。但是,视觉词包中存在有歧义的视觉单词,使得上述基于BOV模型表示图像信息的场景分类效果不理想。因此,对BOV模型中的视觉单词进行约简,形成一种有效的视觉单词集,从而提高分类性能,是一个值得研究的主题。
属性约简[6]是粗糙集理论的核心内容之一,其主要思想是在保持分类能力不变的前提下,消除信息系统(决策表)中不必要的知识。因此该理论在数据的决策与分析、模式识别、机器学习与知识发现等领域得到广泛的应用[7]。为了消除视觉词包中有歧义的视觉单词,本文采用粗糙集属性约简,提出了一种视觉单词生成方法。实验验证了该方法的有效性。
1BOV模型及粗糙集相关概念
1.1 BOV模型
BOV模型最初是用来对文本进行分析和检索,后经过长期的研究与发展研究者将文本处理方法应用于图像识别中。基于视觉单词的词包模型通常表示过程包括局部特征检测、局部特征描述和直方图建立。具体过程如下:首先,采用某种局部特征检测算子确定局部特征的位置、大小和形状;其次,通过局部特征描述算子(如SIFT)提取图像局部特征向量,采用K-means算法对局部特征向量进行聚类,每一个聚类中心对应于一个视觉单词,所有视觉单词集合组成视觉词典;最后,对给定图像将其匹配到距离最近的视觉单词,汇出表示图像视觉单词出现频率的直方图。
设C是一个视觉单词,D1和D2代表两种不同的图像场景语义类别,若经过某种分类模型使得f∶C→D1,C→D2,则称视觉单词C是有歧义的。
1.2 粗糙集相关概念
定义1一个决策信息系统简称决策表T=(U,C,D,V,f),其中U为一个非空有限对象的集合,论域U={X1,X2…Xn},其中f∶U×(CUD)→V是一个二元信息决策表,V为属性值。
定义2设决策表T=(U,C,D,V,f),∀A⊆C∪D,则属性集A 的不可区分关系为IND(A)={(x,y)∈U2:∀a∈A,f(x,a)=f(y,a)},其中IND(A)构成论域上的一个等价划分记为U/IND(A).对任意条件属性C等价划分,称为条件属性等价集U/IND(C)(或条件粒空间);称决策属性D等价划分为决策属性等价集U/IND(D)(或决策粒空间)[8]。
定义3[9]设决策表T=(U,C,D,V,f),c∈C,如果存在xi≠xj且xi,xj∈U对于属性值使得:f(xi,c)≠f(xj,c)并且f(xi,D)≠f(xj,D)成立,则称该系统为不相容决策表,xi和xj为不相容对象。不相容对象集合称为不相容等价集IN(C).
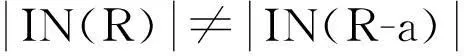
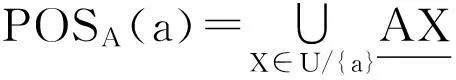
定义5对于给定决策表T=(U,C,D,V,f)若对于条件属性R集存在任意a∈R使:POSR(D)≠POSR-{a}(D)成立,则称是必要属性,否则称非必要属性。所有必要属性的集合称为核属性集[11]简称CORE(C).
定理2设决策表T=(U,C,D,V,f),设R⊆C,∀a∈R存在R是决策表T的最简约简集应满足:1)POSR(D)=POSC(D),2)POSR(D)≠POSR-{a}(D)
定义6[12]设决策表T=(U,C,D,V,f),R⊆C∪D,属性集的粒空间可表示为:U/IND(R)=U={X1,X2…Xi},U/IND(R)的知识粒度可定义为:
定义7[13]设决策表T=(U,C,D,V,f),已知条件粒度空间U/IND(C),和决策粒度空间U/IND(D),则条件属性相对于决策属性的相对知识粒度可定义为:
RG(C;D)=G(U/IND(C))-G(U/IND(C∪D)
定义8设决策表T=(U,C,D,V,f),∀a∈R,R⊆C定义a在决策表中的属性重要度可定义为:
Sgf(a,R,D)=RG(R-{a};D)-RG(R;D)
对于定义8中属性重要度定义可知相对知识粒度度量了条件属性子集粒度空间相对于决策属性力度空间的粗细程度,当条件属性减少时,相对知识粒度增大;反之,随 条件属性增加,相对知识粒度减小。属性重要度度量了条件属性增加或者减少元素前后相对知识粒度变化。
2基于粗糙集的视觉单词生成方法
基于粗糙集的视觉单词生成算法的主要思想:(1)生成基于BOV模型的决策表。首先对训练集图像中局部特征进行描述、提取图像的局部特征向量,通过K-means算法构造初始视觉词典,并对训练图像BOV模型0-1归一化,抽象出决策信息表。其中:图像集标识为对象集,视觉单词标识为条件属性,表中对象按类别标记作为决策属性。(2)根据决策表中决策属性的等价集和条件属性的等价集,建立不相容对象等价集,并对决策表中每一个条件属性进行启发式学习,保留能够引起不相容等价集数目变化的视觉单词,形成必要视觉单词集合。(3)根据必要视觉单词集合,结合相对知识粒度,来衡量决策表中非必要视觉单词的重要度,保存重要度值高的视觉单词,消除属性重要度低的视觉单词,形成约简视觉单词集合,从而有效地消除了视觉词包中有歧义的视觉单词。
根据上述思想,视觉单词生成算法如下:
Step1:生成训练图像基于BOV模型的决策表T=(U,C,D,V,f),标记训练图像集为对象集U={X1,X2…Xi},视觉单词集合C={c1,c2,c3…cn}为条件属性集合,标记不同类别对象为决策属性D={d1,d2,d3…dn}.
Step2:令CORE(C)=Φ,按照定义3得到关于决策表T的不相容等价集IN(C).
Step3:依据定理2,如果存在ci∈C,使得,IN(C)≠IN(C-ci),则ci为必要视觉单词。
CORE(C)=CORE(C)+{a}
Step4:令R=Ø(1)根据定理1,若满足:1)POSCORE(D)=POSC(D),2)存在b∈CORE(C),使POSCORE(D)≠POSCORE-{b}(D),则R=CORE(C),跳转至Step5;否则转(2);
(2)对每个视觉单词a,对每个a∈C-CORE,计算RG(CORE(C)∪{a};D);
(3)选择视觉单词a满足:
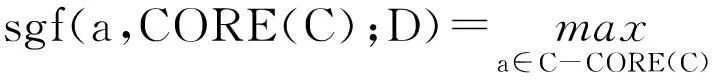
(4)R=CORE(C)+{a}
Step5:输出最简视觉单词集R.
3实例分析
为了验证本文的方法,本文实例选取文献[14]中的实例进行分析,令文献中条件属性a,b,c,e,f,g为BOV模型生成的视觉单词,视觉单词容量为6,d为决策属性,将三类场景图像决策值分别标记为0、1、2.表1为此类训练图像BOV模型的决策信息表。
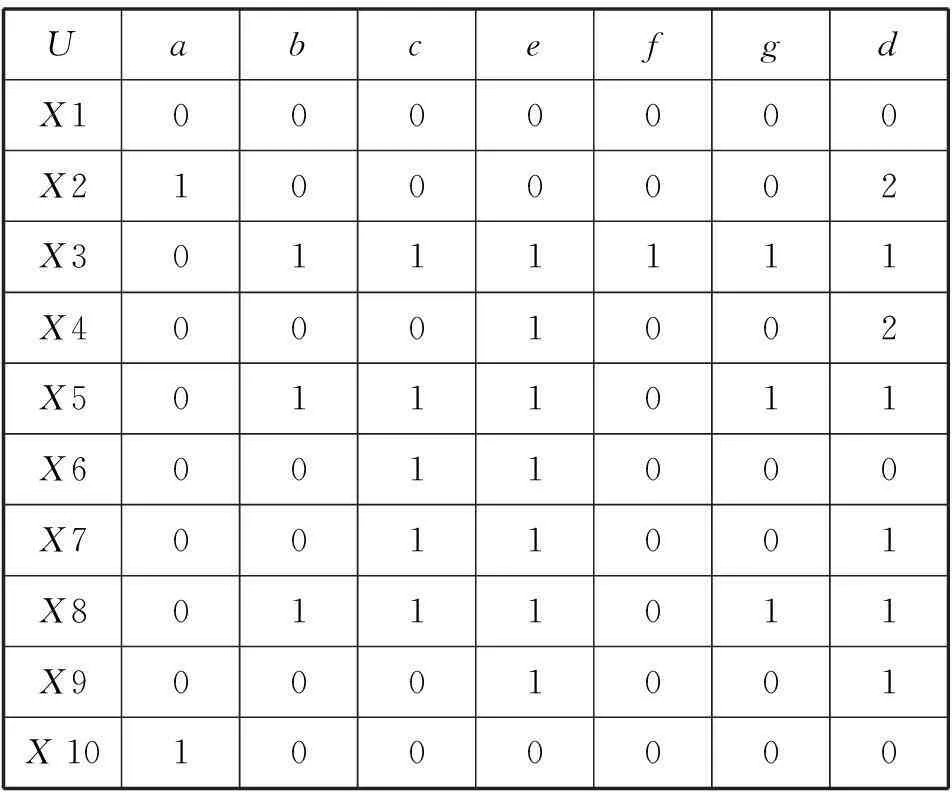
表1 决策表T
(1)计算决策表T中不相容等价集:
U/IND(C)={{X1},{X2,X10},{X3},{X4,X9},{X5,X8},{X6,X7}}
U/IND(D)={{X1,X6,X10},{X3,X5,X7,X8,X9},{X2,X4}}
f(X2,C)=f(X10,C)∧f(X2,D)≠f(X10,D)
f(X6,C)=f(X7,C)∧f(X6,D)≠f(X7,D)
IN(C)={{X9,X10},{X4,X9},{X6,X7}}}
IN(C-a)={{X1,X2,X10},{X4,X9},{X6,X7}}}
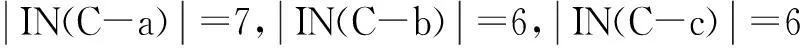
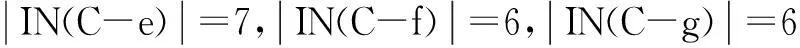
根据定理1可知a,e为必要视觉单词。得到必要视觉单词集合CORE(C)={a,e}
根据定理2验证可知POSCORE(D)≠POSC(D),得到的CORE(C)非必要视觉单词集合。
(3)求最简视觉单词集合:
由(2)可知C-CORE(C)={b,c,f,g},根据定义7,计算必要视觉单词集合的相对知识粒度RG(R;D)=20/91
条件属性相对知识粒度:
RG(R+{b};D)=4/27,RG(R+{c};D)=19/91
RG(R+{f};D)=16/91,RG(R+{g};D)=4/27
依据定义8判断在决策表中属性b,c,f,g重要度:
Sgf(b,R,D)=RG(R-{b};D)-RG(R;D)=8/91
Sgf(c,R,D)=RG(R-{c};D)-RG(R;D)=1/91
Sgf(f,R,D)=RG(R-{f};D)-RG(R;D)=4/91
Sgf(g,R,D)=RG(R-{g};D)-RG(R;D)=8/91
可知b,g对于决策表重要度高,因此可得最简视觉单词集合R={a,b,e,g}.
(4)依据定理1,可验证R为最简属性集。
4实验结果及分析
实验采用Oliva和Torralba提出的8类自然图像场景作为数据集[15],该数据库以下简称为OT库。本文选取OT库中8类每一类100幅图像,对不同视觉词典容量分别进行五次实验验证其性能。
实验在pentium(R)D-3.0 GHZ,CPU,512 MB内存,Windows XP 系统环境,在MATLAB平台下完成实验。实验采取6个不同视觉词典容量{50,100,200,300,400,500}作为数据对象,具体的实验结果如表2、图1、图2所示。
由表2可知,实验采用本文方法约简后视觉单词数目明显减少,验证了本文方法能够消除词包中歧义性视觉单词。同时由图1(a)、(b)可知,相同初始视觉词典条件下约简后比约简前分类所需时间减少,这是由于初始视觉词典属性约简后视觉单词数量减少,使得测试图像的视觉单词与训练图像视觉词典中视觉单词之间匹配所需要的时间也将会减少,使得分类的效率比约简前提高。
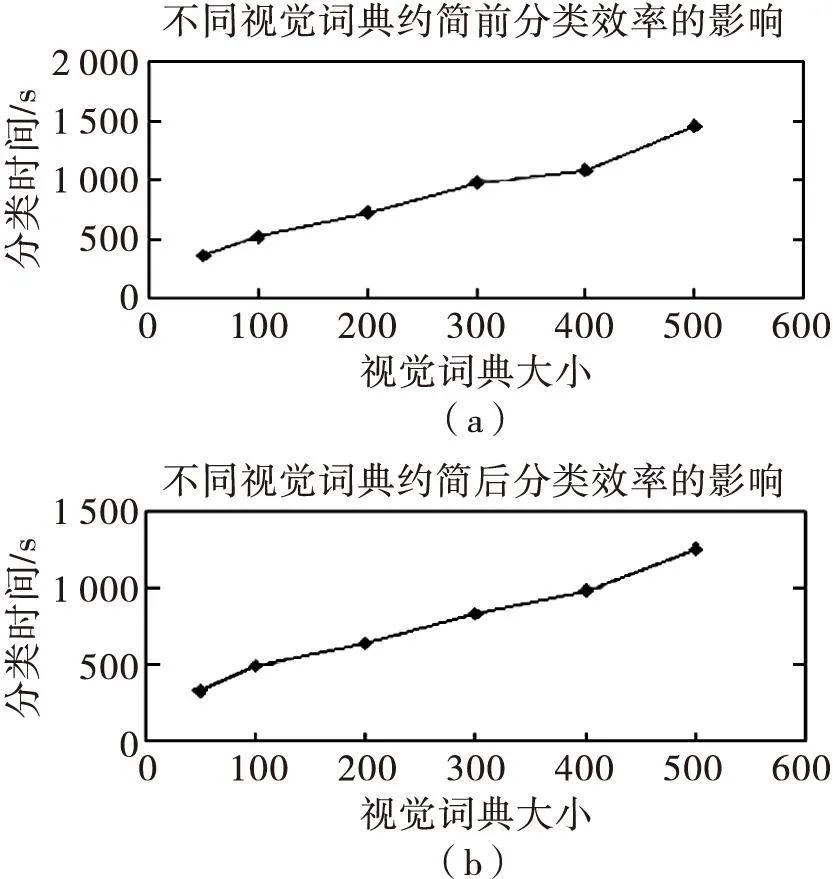
图1 视觉词典约简前后对分类的影响
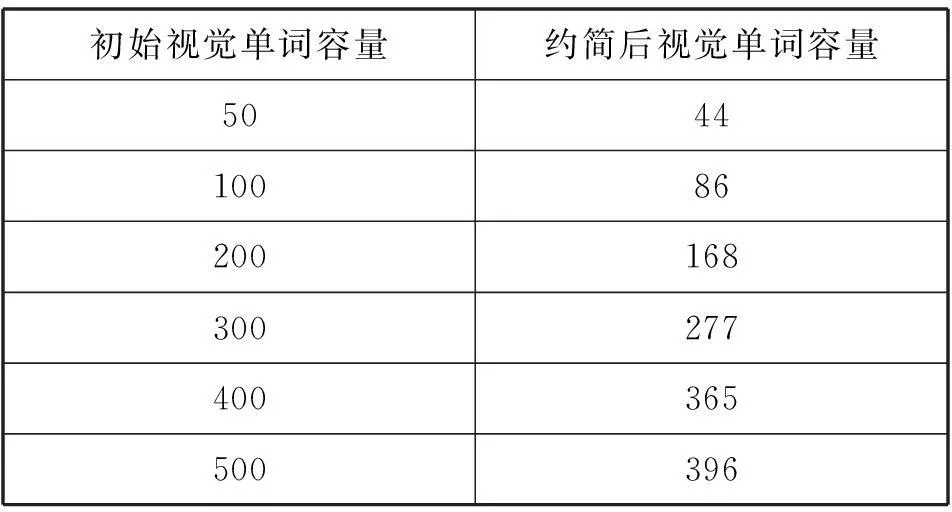
初始视觉单词容量约简后视觉单词容量504410086200168300277400365500396
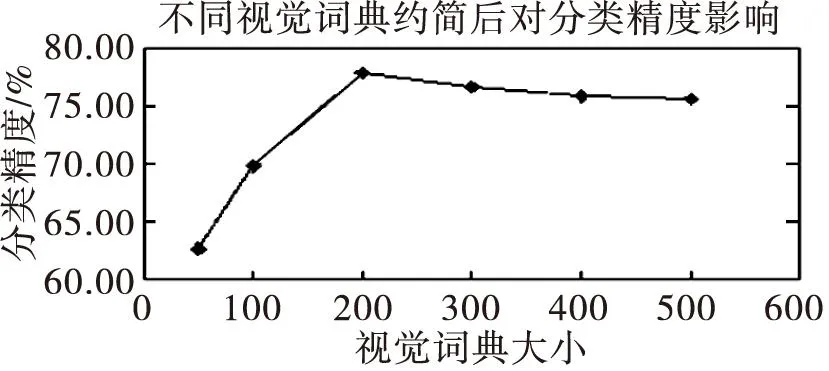
图2 不同视觉词典约简后对分类精度的影响
由图2可知,当初始视觉词典容量较少时,不同的视觉单词容易被表述为同一类别,造成歧义性现象,使得测试图像视觉单词与训练图像视觉单词容易出现错误识别,导致分类精度降低;随着视觉词典容量的逐步增加分类精度逐步最高。但当视觉词典容量超过200之后分类精度逐渐降低,这主要是视觉词典增大容易造成词包中出现冗余问题,使得分类精度会逐渐降低趋于平稳。
为了进一步验证本文方法对图像分类精度的影响。实验选取相同的数据集,将本文的方法分别与文献[16]及文献[17]的方法进行比较。比较结果从表3中可以看出:本文采用粗糙集属性约简,可以更有效的消除视觉词包中存在歧义性的问题,提高图像场景分类精度,进而验证本文方法的有效性。
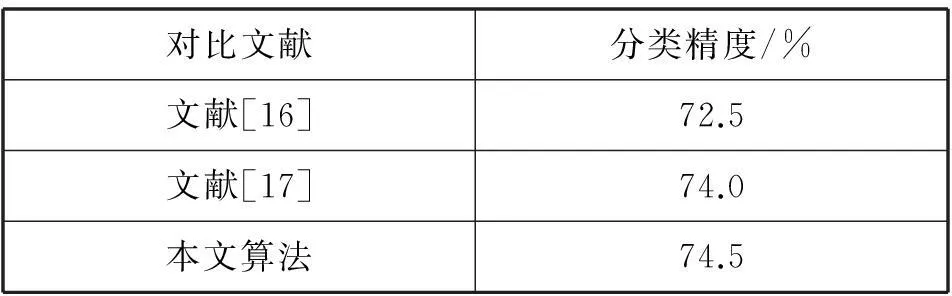
表3 与其他文献方法的对比
5结论
提出一种基于粗糙集的视觉单词约简方法,利用该方法生成不同容量大小的约简视觉单词,消除存在歧义的视觉单词,提高了分类精度。实验表明通过该方法对视觉单词约简是有效且可行的。下一步研究工作是将粗糙集分类应用在图像场景分类中。
参考文献:
[1]褚萌,张素兰,张继福.一种新的基于频繁加权概念格的视觉单词生成方法[J].太原科技大学学报,2012,33(6):421-425.
[2]SANCHEZ J,PERRONNIN F,MENSINK T,et al.Image classification with the fisher vector:Theory and practice[J].International journal of computer vision,2013,105(3):222-245.
[3]刘硕研,须 德,冯松鹤,等.一种基于上下文语义信息的图像块视觉单词生成算法[J].电子学报,2010,38(5):1156-1161.
[4]丁建睿,黄剑华,刘家锋,等.局部特征与多实例学习结合的超声图像分类方法[J].自动化学报,2013,39(6):861-867.
[5]ZHANG D,ISLAM M M,LU G.A review on automatic image annotation techniques[J].Pattern Recognition,2012,45(1):346-362.
[6]陈昊,杨俊安,庄镇泉.变精度粗糙集的属性核和最小属性约简算法[J].计算机学报,2012(5):1011-1017.
[7]WANG C,HE Q,CHEN D,et al.A novel method for attribute reduction of covering decision systems[J].Information Sciences,2014,254:181-196.
[8]苗夺谦,王国胤,刘清,等.粒计算:过去,现在与展望[M].北京:科学出版社,2007.
[9]苗夺谦,徐菲菲,姚一豫,等.粒计算的集合论描述[J].计算机学报,2012,35(2):351-363.
[10]王国胤,张清华.不同知识粒度下粗糙集的不确定性研究[J].计算机学报,2008,31(9):1588-1598.
[11]张清华,王国胤,刘显全.基于最大粒的规则获取算法[J].模式识别与人工智能,2012,25(3):388-396.
[12]张明,唐振民,徐维艳,等.可变多粒度粗糙集模型[J].模式识别与人工智能,2012,25(4):709-720.
[13]桑妍丽,钱宇华.一种悲观多粒度粗糙集中的粒度约简算法[J].模式识别与人工智能,2012,25(3): 361-336.
[14]黄国顺,曾凡智,文翰.代数约简的知识粒度表示及其高效算法[J].控制与决策,2014,29(8):1354-1362.
[15]OLIVA A,TORRALBA A.Modeling the shape of the scene:a holistic representation of the spatial envelope[J].International Journal of Computer Vision,2001,42(3):145-175.
[16]EMRAH E,NAFIZA A.Scene classification using spatial pyramid of latent topics∥Pattern Recognition (ICPR),2010 20th International Conference on.Istanbul,Turkey:IEEE Computer Society,2010:3603-3606.
[17]钟利华,张素兰,胡立华,等.基于概念格层次分析的视觉词典生成方法[J].计算机辅助设计与图形学学报,2015(1):136-141.
A Generation Method of Visual Words Based on Rough Set
ZHAO Peng-kun1,SHI Kai-ze2,ZHANG Su-lan1
(1.School of Computer Science and Technology,Taiyuan University of Science and Technology,Taiyuan 030024,
China;2.School of Computer Science and Technology,Inner Mongolia University,Huhehaote 010021,China)
Abstract:A method of generative visual words based on rough set attribute reduction was proposed for solving the problem that visual word ambiguity affects accuracy and efficiency of classification in the traditional BOV Bag-of-visual words model.First of all,the training image set and visual dictionary were generated by using BOV model,and were abstracted as decision information table.Besides objects in the decision table was labeled as decision attribute separately according to the class,visual words in the dictionary was labeled as condition attribute.Then incompatible object equivalence sets were established according to decision attribute in decision table of equivalent set and equivalent condition attribute set,and the necessary visual words collection were generated by using heuristic learning for each condition attribute of decision table and keeping the vision of the change of incompatible equivalent set number words.Secondly,ambiguous visual words in the visual words package were eliminated effectively by measuring the importance degree of decision making unnecessary visual words in the table so as to save high importance value of visual words according to the necessary visual words collection and relative knowledge granularity,thus eliminating the low visual word of attribute importance,forming the reduction of visual word set.In the end,experimental results validate the effectiveness and feasibility of the method.
Key words:visual words,rough set,attribute reduction,knowledge granularity
中图分类号:TP391.4
文献标志码:A
doi:10.3969/j.issn.1673-2057.2016.01.001
文章编号:1673-2057(2016)01-0001-05
作者简介:赵鹏坤(1988-),男,硕士,主要研究方向为图像语义标注。
基金项目:校博士启动基金(20132005)
收稿日期:2015-03-25
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
聊城大学学报(自然科学版)(2022年5期)2022-10-29
科教导刊·电子版(2021年6期)2021-05-06
湖南城市学院学报(自然科学版)(2020年1期)2020-01-16
计算机与数字工程(2019年8期)2019-09-03
计算机与生活(2019年3期)2019-04-18
统计与信息论坛(2018年3期)2018-03-20
数码设计(2017年1期)2017-10-13
智能系统学报(2016年4期)2016-09-27
现代计算机(2016年17期)2016-02-28
