
实时碰撞检测算法中的数据缓存优化技术研究
2016-02-06 00:31殷存举邵小兰
电脑与电信 2016年5期
殷存举 邵小兰
(江苏联合职业技术学院常州刘国钧分院,江苏 常州 213000)
实时碰撞检测算法中的数据缓存优化技术研究
殷存举 邵小兰
(江苏联合职业技术学院常州刘国钧分院,江苏 常州 213000)
在实时碰撞系统中,数据缓存的利用率对性能有极大的影响,本文通过重新设计算法和数据结构,并以一种更具预测性、线性或部分线性的方式访问数据,有效地改善数据局域性特征。达到降低数据尺寸、提高空间和时间局域性特征进而提高数据缓存利用率的目的。
数据缓存;访问频率;优化;数据压缩
1 结构优化
针对数据缓存的改进措施,首先考查结构和类的优化方案,包括以下三点:
(1)降低结构的整体尺寸。使用恰当的位数表示数字,从而可降低缓存单元中匹配数据量以及结构中相关字段的内存读取次数。
(2)在结构内适当地重组字段。结构内的相应字段通常按照其自身含义加以分类,但从本质上讲应以访问模式加以分组,以使字段的访问-存储过程相吻合。
(3)根据数据的使用频率划分结构。由于结构内部相关字段的访问频率不同,可将那些不经常访问的字段置入单一结构中,从而增加频繁受访数据缓存间的一致性,特别在该结构是数组或其他聚合型数据结构的某一部分时。
许多平台上的对齐操作将会迫使编译器对相关结构实施填充操作,即N字节字段将实现N字节对齐。由于填充结构的对齐尺寸往往是该结构中最大N字节字段的某一倍数,因此会浪费一部分内存空间。考虑到填充操作,按降序排序成员变量将在一定程度上节省内存空间。另外,某些编译器会提供相应的警告,以助于检测当前内存空间的消耗状态。
基于MIPS平台的体系结构往往有相应的对齐限制。其中,若定义了下列数据结构:
struct X{
int8 a;
int64 b;
int8 c;
int16 d;
int64 e;
float f;
};
struct Y{
int8 a,pad_a[7];
int64 b;
int8 c,pad_c[1];
int16 d,pad_d[2];
int64 e;
float f,pad_f[1];
};
struct Z{
int64 b;
int64 e;
float f;
int16 d;
int8 a;
int8 c;
};
则多数编译器将会生成如下结果:
Sizeof(X)==40,Sizeof(y)==40,Sizeof(z)==24(这里,假设float类型为4字节)。与排序后的结构Z相比,结构X的填充数据占据了全部内存空间的40%(如结构Y所示)。其他缩减结构尺寸的相关方法如下:
(1)从已存储值可轻易计算得到的数据值则不要存储于结构中,以避免额外的缓存读取操作。
(2)可能的话,尽量使用小尺寸的整型数据。
(3)采用位域表示法而非布尔值。尽量不采用Bool类型的标志变量,可将全部标志封装至某一位域中。Bool变量的尺寸是依赖于机器环境的,其范围从一个字节至长整型数据不等。将多个标志存储于位格式中,可将所需内存空间至少减少至1/8,通常为1/32甚至更少。
(4)采用偏移量而非用于索引数据结构的指针。指针通常为4字节(或更多)固定尺寸变量,而偏移量的尺寸可根据索引项的数量产生变化。例如,2字节偏移量可索引包含216个对象的数组。
由于缓存失效将导致计算开销急剧增加,因此必须谨慎处理压缩/非压缩数据。
需要指出的是,在某些系统结构中,上述方案可能会带来额外的cpu计算开销。例如,附加指令要求针对小尺寸整型数据或位域中的某一位进行操作。随着指令运行数量的增加,缓存压力也将会随之增长,进而会逐渐抵消缓存优势。因此,对代码进行优化测试不失为一种较好的解决方案——理想情况下,可对变化前后的代码分别进行测试,从而采取相应的改进方案。
对相关字段加以记录实现起来并非易事。在某些情况下,多个字段将存储于同一缓存单元中,尤其是多个字段被同时访问时。考查下列情况,位置、速度以及加速字段经常被同时访问,因而对其进行合并存储将会增加执行效率。多数情况下,确定字段的最佳排列方式其过程往往比较复杂。理想情况下,编译器将会参考前次运行信息并在后续编译过程中自动执行相应的字段记录。然而,相应的语言标准很可能并不包含字段记录这一功能,且当前基本不存在相应的编译器能够支持该优化操作。一种较好的字段重组方案是通过访问函数间接地获取结构中的字段。这里,可临时性地设置这些函数,以测试字段的访问频率并记录哪些字段被同时访问。另外,在某些情况下,对结构进行填充操作将会有效改善程序的计算性能,具体体现为:这将使被访问的两个邻接字段位于同一缓存内。
考虑到结构字段的访问频率,可将其划分为两个不同的独立结构:高频被访问字段结构和低频被访问字段结构,应分别对其分配内存空间并加以存储。另外,各个高频字段结构中均嵌入低频字段结构的链接指针。此处,虽然只能对低频字段结构实现间接访问并增加了些许计算开销,但相应的主结构(高频被访字段结构)将变得更加紧凑,并可实现高效的数据缓存。另外,由于结构的访问方式不同,不必一定采用链接指针。例如,使用单独的索引即可同时访问高频被访字段数组和低频被访字段数组。
下面的示例显示了结构的划分过程且不使用链接指针。这里,相关代码用于遍历结构数组,当某元素具有最大值Value时,则增加该元素的count字段值。
struct S{
int32 value;
int32 count;
...
}elem[1000];
//Find the index of the element with largest value
int index=0;
for(int i=0;int<1000;i++)
if(elem[i].value>elem[index].value)index=i;
//Increment the count field of that element
elem[index].count++;
如果上述基于结构数组的搜索过程视为核心操作,则应将结构S划分为高频受访字段结构(S1)和低频受访字段结构S2.上述代码可改写为:
//Hot fields of S
struct S1{
Int32 value;
}elem1[100];
//Code fields of S
struct S2{
Int32 count;
...
}elem2[1000];
//Find the index of the element with largest value
int index=0;
for(int i=0;int<1000;i++)
if(elem1[i].value>elem1[index].value)indexer=i;
//increment the count field of that element
elem2[index].count++;
因此,全部value字段在内存皆呈现连续排列状态,即不再被结构S中的count字段和其他字段分割。因此,最大值value的搜索速度将提高2倍。(除了count字段,如果还能析取出其他低频受访字段,搜索速度还有更大的提升空间)。
类似于结构的低频/高频划分,编译器和链接器同样也可以根据该原理对代码进行重组,因而可对调用频率较低的函数或部分函数进行移动,降低调用函数-被调函数之间的冲突,将会减少指令缓存中的操作次数。一类优化算法则是使用了“软件着色技术”这一概念并对代码(或数据)进行排列,进而将受访频率较高的数据项映射至不同的缓存单元中(各缓存单元可视为彼此不同的颜色值)。但目前为止,还很少有相应的编译器能够实现缓存着色技术。虽然该方案可实现手工处理,但一旦代码产生变化,全部过程也需要重新处理。
2 顶点数据的量化操作和压缩操作
针对碰撞检测代码,除去数据结构自身之外,顶点的表达方式也是十分重要的,因为它们构成了数据的主要组成部分。虽然顶点的x、y、z值常采用浮点数加以存储,但也可对其实施量化操作。例如,可使用3个16位的整型值加以表示。相应的量化计算可有效地实现网格顶点的对齐操作,因此须谨慎处理以避免四边形或其他大型碰撞测试图元产生共面现象。
在某些情况下,还可以对顶点数据实现进一步的编码。例如,对于小型场景世界,顶点可编码位32位整型数据,其中顶点的x、y值分别占据11位,z值则包含10位,如图1所示。
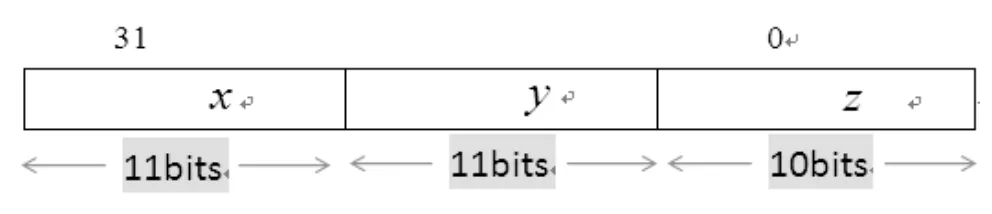
图1 量化为32位整型数据的顶点值
当采用相对于前一顶点的偏移量来表示其他顶点时,顶点数据将会占用更少的内存空间。例如。在计算由顶点表示的AABB时,可将其中心点作为固定原点,并根据该原点计算其他顶点的偏移距离。这里,额外开销仅为采用全精度表示的原点,其他顶点通过较少的几个数据位即可实现。
例如,考查下列5个16位整型随机顶点:A=(30086,15857,9358),B=(30189,15969,9285),C=(30192,15771,9030),D=(29971,15764,9498),E=(30304,15888,9133)。上述顶点也可以采用基于顶点(30138,15866,9264)的16位偏移量加以表示:(-52,-9,121)、(51,103,21)、(54,-95,-234)、(-162,-102,234),(166,22,-131)这里,量化顶点可采用9位数值加以存储,相对于原点格式,这节省了大量的内存空间。
若原点可在顶点间浮动,则还能够进一步地节省内存空间。亦即,可通过前一顶点计算偏移量,因而能够有效地实现数据压缩。该方案适用于索引网格,其中,顶点顺序可实现随机混合,这将有助于获取较好的压缩率。综上所述,可对顶点A~E按照D、A、B、E、C这一顺序加以重组,首顶点表示为(29971,15764,9498),且后续顶点分别为(115,93,-113)、(103,112,-100)、(115,-81,-122)、(-112,-117,-73)。因此,顶点分量可采用8位数据加以表示。
由于叶节点中的数据一般仅跨越场景世界中的某一小部分,因而空间划分算法可与量化格式的叶节点数据结合使用。另外,局部数据的量化操作不但可以节省内存空间,还能够实现坐标值的全范围表示。如果相关叶节点数据待压缩后实现缓冲存储,其额外的压缩消耗通常可以分摊的方式加以抵消。令叶节点数据相对于某一原点(该原点表示父节点的空间位置)实现存储,则可增加该处理过程的健壮性。此时,相关计算将围绕此原点进行,从而可实现较高的精确度。
3 结论
本文从结构优化和顶点数据的量化操作和压缩操作两个方面论述了如何有效地改善数据局域性特征。达到降低数据尺寸、提高空间和时间局域性特征,进而提高数据缓存利用率的目的。对提高碰撞检测系统的性能有一定的指导意义。
[1]张国飚,张华,刘满禄,等.基于空间剖分的碰撞检测算法研究[J].计算机工程与应用,2014,50(07):46-49.
[2]宋城虎,闵林,朱琳,等.基于包围盒和空间分解的碰撞检测算法[J].计算机技术与发展,2014(01):57-60.
[3]谢世富,马立元,刘鹏远,等.虚拟环境下运动线缆碰撞检测算法研究与实现[J].系统仿真学报,2013,25(8):1865-1870.
[4]付跃文,梁加红,李猛,等.基于多智能体粒子群的快速碰撞检测算法研究[J].系统仿真学报,201325(8):1876-1880.
[5]张应中,范超,罗晓芳.凸多面体连续碰撞检测的运动轨迹分离轴算法[J].计算机辅助设计与图形学学报,2013,25(1):7-14.
[6]陆睿,刘卉.基于完全二叉树BVH的自碰撞检测算法[J].计算机应用与软件,2012,29(12):282-285.
Research on Data Cache Optimization of Real-time Collision DetectionAlgorithm
Yin Cunju Shao Xiaolan
(Changzhou Liu Guojun Vocational Technology College,Changzhou 21300,Jiangsu)
In the real-time collision system,data cache utilization rate has a great effect on the performance.This paper redesigns the algorithms and data structures and access to data in a more predictive,linear or partially linear way.It effectively improves data locality characteristics.It achieves to reduce the data size,to improve the spatial and temporal characteristics,and to improve the efficiency of data cache.
data cache;access frequency;optimization;data compression
TP333
A
1008-6609(2016)05-0054-03
殷存举,男,山东费县人,硕士,副教授,研究方向:智能信息处理。
猜你喜欢
江苏科技信息(2022年16期)2022-07-17
汽车工程师(2021年12期)2022-01-17
铁道通信信号(2020年10期)2020-02-07
铁道通信信号(2020年7期)2020-02-06
计算机与网络(2019年9期)2019-10-21
系统工程与电子技术(2016年7期)2016-08-21
中国工程咨询(2016年12期)2016-01-29
图书馆建设(2015年10期)2015-02-13
新世纪图书馆(2014年7期)2014-09-19
组合机床与自动化加工技术(2014年10期)2014-03-01
