
一种两阶段判别分析方法
2016-02-06 00:31曾青松
电脑与电信 2016年5期
曾青松
(广州番禺职业技术学院信息工程学院,广东 广州 511483)
一种两阶段判别分析方法
曾青松
(广州番禺职业技术学院信息工程学院,广东 广州 511483)
为了解决LDA对复杂分布数据的表达问题,本文提出了一种新的非参数形式的散度矩阵构造方法。该方法能更好的刻画分类边界信息,并保留更多对分类有用的信息。同时针对小样本问题中非参数结构形式的类内散度矩阵可能奇异,提出了一种两阶段鉴别分析方法对准则函数进行了最优化求解。该方法通过奇异值分解把人脸图像投影到混合散度矩阵的主元空间,使类内散度矩阵在投影空间中是非奇异的,通过CS分解,从理论上分析了同时对角化散度矩阵的求解,并证明了得到的投影矩阵满足正交约束条件。在ORL,Yale和YaleB人脸库上测试的结果显示,改进的算法在性能上优于PCA+LDA,ULDA和OLDA等子空间方法。
非参数化鉴别分析;CS分解;人脸识别;主成份分析;子空间
1 引言
线性鉴别分析(Linear Discriminant Analysis,LDA)是一种有监督的特征提取方法,其主要思想是求解投影向量使得同类样本变得紧凑,异类样本尽可能分开。LDA使用参数化形式的散度矩阵,且没有包含高阶的统计量,因此无法很好的表达数据的复杂分布。非参数鉴别分析(Nonparametric Discriminant Analysis,NDA)采用非参数形式构造散度矩阵,更多的考虑样本分布的局部结构特征,能更好的刻画分类边界信息,强化分类边界样本的贡献。Fukunaga[1]通过构造非参数化形式的类间散度矩阵来解决两分类问题。Li[2]和Zeng[3]扩展了经典的非参数鉴别分析算法,以支持多类情况,但是基于局部方法构造的类内散度矩阵仍然可能奇异[2]。
LDA提取的特征个数受到类别数的限制,实际使用时会遭遇小样本问题[4]。运用正则化方法,通过矩阵平滑可以使类内散度矩阵Sw变得非奇异[5],但是计算量大。PCA+LDA使用PCA把特征维数从D降到N-M(N是样本数,M是类别数)使Sw变得非奇异[6],但是Sw的维数由D降到N-M会损失一些鉴别信息。LDA/QR[7]首先将人脸样本投影到一个子空间,然后在该子空间中进行线性判别分析,不仅克服了LDA的奇异问题,而且大大降低了计算复杂度,但是由于LDA/ QR的第一步事实上是将人脸样本投影到类间散度矩阵的值空间,从而如果样本均值估计有偏,则会导致LDA/QR识别性能的下降,这就是LDA/QR的所谓对类中心估计敏感的问题。Chen证明了Sw的零空间中包含了大部分的鉴别信息,因而可以在Sw的零空间中来求解最优化问题[8]。杨等人提出了具有统计不相关的图像投影鉴别分析方法[9],Ye对此改进并提出了ULDA(Uncorrelated LDA,ULDA)算法[10],并对ULDA进行正交化约束扩展提出正交LDA(Orthogonal LDA,OLDA)[11],OLDA得到的所有的鉴别向量都是相互正交的,因此即使在散度矩阵奇异的时候都可以执行,最近被广泛的应用和扩展。
文章首先运用样本的局部结构特征,构造具有非参数化形式的散度矩阵,该方法很好的刻画分类边界信息,突出边界样本对分类的贡献,可以应用复杂分布数据的处理。基于局部特征构造的散度矩阵,有效的克服样本均值估计有偏的问题。其次通过SVD分解移除混合散度矩阵的零空间克服类内散度矩阵奇异问题。最后通过应用CS正交分解同时对角化散度矩阵来求解最优化问题,并在计算过程中运用QL分解避免了矩阵求逆操作。
2 非参数散度矩阵的构造
假设样本是d维的,训练集包含c个类C1,C2,…,Cc,其中Ck类有nk个样本,共个样本。设表示来自第k类的第i个样本,则整个训练集表示为

在经典LDA中,计算类间散度矩阵,只用到每一类样本的均值与整体均值的差,很明显,一类样本的均值反映的是样本的整体信息,没有抓住边界的结构。Zeng等[3]从图论的角度出发,考虑样本点之间的局部邻域结构,提出一种新的矩阵的构造方法来提升非参数鉴别分析,同时强化训练集合中样本点的边界信息和局部结构。可以证明LDA的类间散度矩阵和式等价[12],

定义3Ck类样本的局部混合邻域均值定义为:

定义4Ck类样本的Cl类局部类间邻域均值定义为:

定义3和定义4中 ||·表示集合的基数。根据定义5,在计算Ck类相对于Cl局部类内邻域均值时,首先利用类间邻域的样本计算出的Cl类局部类间邻域均值x,然后以此作为中心求出x的类间邻域Nδ(x,k)的均值。这种计算充分利用边界附近的点来计算类间邻域均值和类内邻域均值,刻画了分类边界的结构。
定义两个矩阵A和B的分块划分:A=[A1,…,Ac],那么,Sb可以看成是所有类别的均值相减,(μk-μl)(μk-μl)T,反映了Ck类和Cl类样本均值之间的差异信息。但是如果某两个类别差别很大,那么这两个类别的均值的差所组成的协方差矩阵可能在Sb中占主导地位,如此得到的投影轴就会过于区分这两个类别,导致无法很好的区分其它相近的类别。因此通过对不同类别的差值引入加权的思想,使得所得到的投影更注重不好区分的类别以及强化分类边界信息。
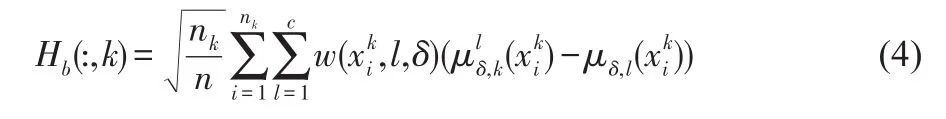


其中α∈(0,∞)是控制参数,用来调节距离比的改变速度,‖‖·表示向量范数。对那些靠近分类边界的样本,逼近0.5,并且当样本远离分类边界的时候趋于零,因此强化了训练样本集的边界信息。图1描述了类别1的样本点P的局部邻域均值

图1 样本点P的局部邻域均值示意图
3 两阶段鉴别分析算法
3.1 预处理步骤
定理1如果A=QR表示 A∈Rm×n的QR分解,A=[a1,…,an] ,Q=[q1,…,qm] 是 列 分 块 矩 阵 ,那 么span{a1,…,ak}=span{q1,…,qk},k=1,…,n。[13]
根据矩阵的知识,St的值空间和Ht的值空间相同。设Ht=QR表示 Ht的QR分解,对任意的正交矩阵W,设
考虑最优化问题


对于小样本问题,Sw的零空间的维数很高,然而Sw零空间中并非所有的向量都能提供有效的鉴别信息。Chen等[8]证明了N(St)=N(Sb)⋂N(Sw),因此Sw的有用的零空间是Sw零空间的一个子集:N(Sw)-N(St),在降维后的子空间中散度矩阵不再奇异,因此可以直接运用经典的LDA方法。
设Ht=QR表示Ht的QR分解,R=UΣVT表示R的奇异值分解,其中U和V是正交矩阵,包含Ht的非零奇异值,其主对角元素按照非递减有序排列,t=rank(Ht)=rank(Sw)。由于,

设 U=(U1,U2)是 U的分块划分,其中 U1∈ℝm×t,U2∈ℝm×(m-t),那么可以通过将数据投影到U1生成的列子空间来消除St的零空间。
综合上述分析,首先构造Ht,然后将最优化问题转化为等价问题的求解,最后通过奇异值分解,移除Ht的零空间得到一个较低维数的子空间,在这个子空间中,散度矩阵是非奇异的,因而可以直接运用经典的LDA方法。预处理的步骤为:
步骤1 构造混合散度矩阵Ht;
步骤2 计算QR分解 Ht=QR,t←rank(Ht);
步骤3 计算SVD分解R=UΣVT;
步骤4 U1←U(:,1:t);
步骤5 输出G←QU1,算法结束。
3.2 LDA/CS算法
正交化约束的LDA方法得到的投影矩阵的列向量互相正交,已有的研究证明这一类方法具有较好的性能[11]。本文提出基于CS分解的鉴别分析方法(LDA via Cos-sin decomposition,LDA/CS)。LDA/CS的目标是求解最优化问题,运用CS分解算法同时对角化散度矩阵,得到正交约束的鉴别矢量,并利用QL分解避免计算过程中矩阵的求逆。
定义6矩阵X的QL分解指矩阵X能够被分解为X=QL,其中Q∈ℝm×m具有列正交向量,L∈ℝm×n是一个下三角矩阵。

其中Q1∈ℝm×n,Q2∈ℝp×n,m<n,p<n是一个小样本问题,如果Q是列正交的,那么存在正交矩阵U∈ℝm×m,V∈ℝp×p以及非奇异矩阵W∈ℝn×n和分块对角化矩阵C∈ℝm×n,S∈ℝp×n满足Q1=UCWT,Q2=VSWT,即

其中CTC+STS=I。
如果Sb,Sw,Hb和Hw如前面所定义,设F=QR表示F的QR分解,即
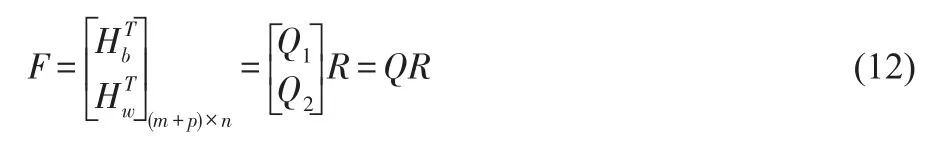
其中Q1∈ℝm×n,Q2∈ℝp×n,Q是列正交的,R∈ℝn×n是一个上三角矩阵,那么通过CS分解,得到Q1=UCWT,Q2=VSWT,其中U∈ℝm×m,V∈ℝp×p是正交矩阵,W∈ℝn×n是非奇异矩阵,C∈ℝm×n和 S∈ℝp×n是满足CTC+STS=I的分块对角矩阵,因此设 Z=(WTR)-1,那么
设Y=RTW,通过QL分解Y=ΦL计算正交矩阵Φ,因而Z=(WTR)-1=(LTΦT)-1=ΦR1,这样避免求逆操作,其中R1=(LT)-1是一个上三角矩阵。因此,J(G)=tr(ZTSwZ)-1(ZTSbZ)= tr((ΦTSwΦ)-1ΦTSbΦ),设Φ*=[Φ1,Φ2,…,Φr],Φi是Φ 的第i列,r=rank(Z),因为span{Z1,…,Zr}=span{Φ1,…,Φr},所以G=Φ*满足最优化问题。LDA/CS的主要特征是鉴别向量相互正交,也就是说变换矩阵是正交的。
考虑参数化LDA问题,由于 St=Sb+Sw,所以ZTStZ=ZT(Sb+Sw)Z=I,因此可以同时对角化Sb、Sw和St,并且是统计无关的。LDA/CS算法的具体步骤为:
步骤2 计算F的QR分解F=QR,其中Q=[Q1;Q2];
步骤3对Q应用CS分解得到矩阵W;
父亲离世时说了两句话:做人要实在,不欺他人,任何时候都无事;同情他人,以礼待人,留下好评,一代一代都会有用。
步骤4 计算Y←RTW;
步骤5 计算Y的QL分解Y=ΦL;
步骤6 输出G←[Φ1,Φ2,…,Φr],算法结束。
3.3 LDA/CS-QR算法
结合预处理和LDA/CS得到二阶段组合算法(Twostage LDA via CS and QR decomposition,LDA/CS-QR),该算法有效的扩展了现有的正交化方法在非参数条件下不能应用的问题,并提高了鉴别分析的准确度。LDA/CS-QR算法的步骤为:
步骤1 构造散度矩阵Hb,Hw,和Ht,t←rank(Ht);
步骤2计算QR分解Ht=QR;
步骤3 计算SVD分解R=UΣVT,U1←U(:,1:t);
步骤6 输出G←QU1G*,算法结束。
算法的第1步根据需要可以构造参数化形式的散度矩阵,也可以构造非参数化形式的散度矩阵。
4 实验结果
本文在ORL、Yale和YaleB人脸数据库上比较LDA/CS、LDA/CS-QR与经典的PCA+LDA、ULDA和OLDA算法。
4.1 实验设置
ORL人脸数据库包含40人共400张面部图像,部分图像包括了姿态、表情和面部饰物的变化。Yale人脸数据库包含15位志愿者的165张图片,包含光照、表情和姿态的变化,其中每个主题包含11张图片。YaleB扩展库包含了38个人的16128幅9种姿态、64种光照的图像。其中的姿态和光照变化的图像都是在严格控制的条件下采集的,主要用于光照和姿态问题的建模与分析。
本文对数据库中的所有图像做如下的处理:图像被归一化为32×32像素并进行直方图均衡化;采用最近邻法分类器。在每个数据库上随机选取P张图像作为训练集,剩余的图像作为测试集。使用20次随机试验的平均识别率。实验中LDA/CS和LDA/CS-QR表示使用参数方法构造散度矩阵,LDA/CS-N和LDA/CS-QR-N表示使用非参数化方法构造散度矩阵,使用非参数方法时,计算时局部邻域参数p=5,公式中α=3。
4.2 分类实验
在ORL库和Yale库上随机选择了P(P=5,6,7)张人脸图片作为训练集,在YaleB库上随机选择P(P=5,10,20)张人脸图片作为训练集,剩余的全部图片作为测试。ORL,Yale和YaleB人脸数据库上的实验结果分别列在表1,表2和表3中。从表1和表3可知LDA/CS-QR-N算法在ORL库和YaleB库上都取得最好的比别率。表2中,在P=6,7时,LDA/ CS-QR-N算法也取得最好的识别率。
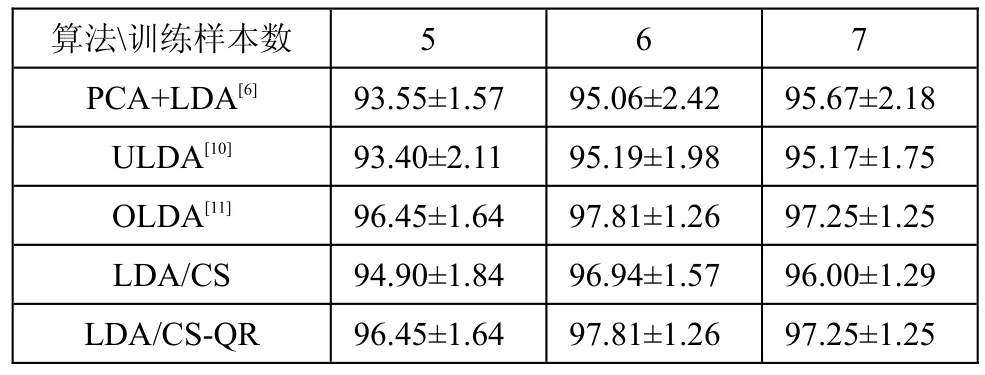
表1 在ORL人脸数据库上的识别率比较

LDA/CS-N LDA/CS-QR-N 96.55±1.71 96.75±1.78 97.75±1.32 98.00±1.13 97.08±1.37 97.42±1.39
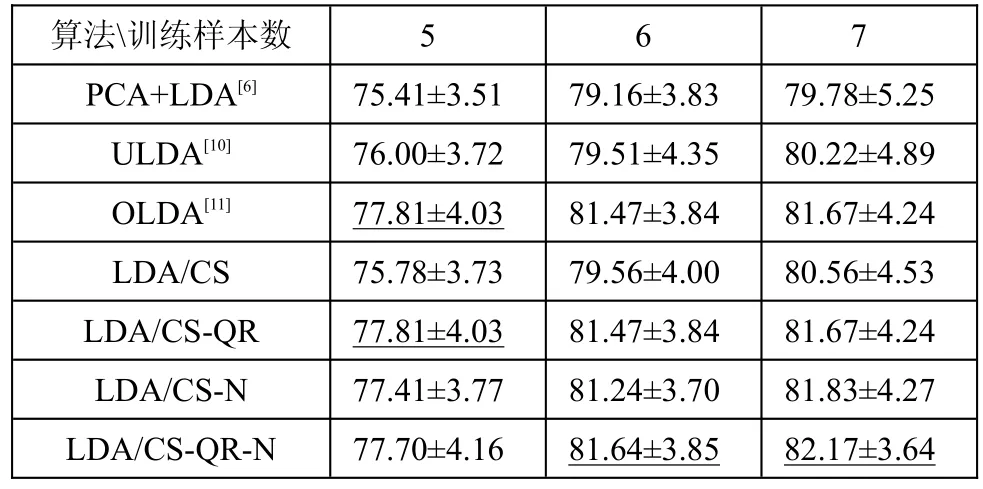
表2 在Yale人脸数据库上的识别率比较

表3 在YaleB人脸数据库上的识别率比较
为揭示训练样本数量对识别率的影响,在ORL和Yale数据库中随机选择P(P=3,4,5,6,7,8)张图像作为测试集。图2(a)和图2(b)分别列出了各种算法在ORL和Yale库上的比较结果。分析图2得出:所有算法随着训练样本的增加,识别率都稳定上升。图2(a)表明选择不同的数量的训练样本时,LDA/ CS-N和LDA/CS-QR-N算法的识别率高于PCA+LDA和ULDA算法,但是与OLDA算法相当。图2(b)显示在训练样本较多的时候,LDA/CS-QR-N取得比OLDA更好的识别率。

图2 ORL库和Yale库上识别率随鉴别矢量个数的变化趋势
4.3 鉴别向量数量对分类准确度的影响实验
从表1~表3的结果发现OLDA算法和LDA/CS-QR算法的最佳识别率在所有数据库中测试结果相同,但是由于选择不同数量的鉴别向量会对识别率差生一定的影响。为进一步揭示两个算法的区别,在ORL库和Yale库随机选择P=7幅图像作为训练集,YaleB库随机选择P=10幅图像作为训练集,其它全部图像作为测试集。比较了选择不同数量的特征向量LDA/CS和LDA/CS-QR算法的性能,并与PCA+LDA、ULDA、OLDA算法比较。图3(a)、图3(b)和图3(c)分别列出了ORL、Yale和YaleB库上的比较结果。分析图3,发现LDA/CS和LDA/CS-QR算法在选择较少的特征向量就能达到比较稳定的识别率,并且LDA/CS-QR算法在选择较少特征向量时比其它算法识别率更高,并且识别率曲线的斜率比较大,说明随着选择的特征向量数量的增加,识别率更快的趋于稳定的值。

图3 特征向量数量与识别结果之间的关系
4.4 参数化方法与非参数化方法比较
分析表1-3的结果,发现使用参数化方法和非参数化方法构造散度矩阵时,尤其是在非参数化条件下,改进的算法性能更好。
如图4所示,LDA/CS-N和LDA/CS-QR-N在特征向量较少时识别率更高。在ORL和Yale库等很少样本的数据库中测试,如图4(a)和(b)所示,非参数方法比参数方法性能更好。

图4 参数化与非参化数构造散度矩阵的识别率比较
5 结束语
本文从样本的局部邻域出发,利用样本局部结构信息构造散度矩阵,通过强化分类边界结构有效的提取鉴别信息。对于人脸识别等小样本问题,通过局部方法构造的类内散度矩阵可能是奇异的,因此文章提出了一种两阶段的非参数鉴别分析算法,通过去除混合散度矩阵的零空间有效的解决散度矩阵奇异问题,并通过QL分解有效的避免计算过程矩阵求逆问题。在ORL,Yale和YaleB人脸库上的实验结果说明算法比PCA+LDA,ULDA和OLDA有更高的识别率。
[1]Fukunaga K,Mantock J M.Nonparametric Discriminant Analysis [J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,1983,5(6):671-678.
[2]Li Z,Lin D,Tang X.Nonparametric discriminant analysis for face recognition[J].Pattern Analysis and Machine Intelligence,IEEE Transac⁃tions on,2009,31(4):755-61.
[3]Zeng Q,Wang C.NPDA/CS:Improved Non-parametric Dis⁃criminant Analysis with CS Decomposition and its Application to Face Recorgnition[C].Image Processing(ICIP),2010 17th IEEE International Conference on,Hong Kong,2010:4537-4540.
[4]Zheng Yujie,Yang Jingyu,Xu Yong,et al.A New Feature Extrac⁃tion Method Based on Fisher Discriminant Minimal Criterion[J].Journal of Computer Research and Development,2006,43(7):1201-1206.(郑宇杰,杨静宇,徐勇,等.一种基于Fisher鉴别极小准则的特征提取方法[J].计算机研究与发展,2006,43(7):1201-1206.)
[5]Dai D-Q,Yuen P C.Regularized discriminant analysis and its ap⁃plication to face recognition[J].Pattern Recognition,2003,36(3):845-847.
[6]Belhumeur P N,Hespanha J P,Kriegman D J.Eigenfaces vs.Fish⁃erfaces:recognition using class specific linear projection[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,1997,19(7):711-720.
[7]Ye J,Li Q.A two-stage linear discriminant analysis via QR-de⁃composition[J].IEEE Trans Pattern Anal Mach Intell,2005,27(6):929-41.
[8]Chen L.A new LDA-based face recognition system which can solve the small sample size problem[J].Pattern Recognition,2000,33(10):1713-1726.
[9]Yang Jian,Yang Jingyu.Uncorrelated image projection discrimi⁃nant analysis and face recorgnition[J].Journal of Computer Research and Development,2003,40(3):447-452.(杨键,杨静宇.具有统计不相关的图像投影鉴别分析及人脸识别[J].计算机研究与发展,2003,40(3):447-452.)
[10]Ye J,Li T,Xiong T,et al.Using Uncorrelated Discriminant Anal⁃ysis for Tissue Classification with Gene Expression Data[J].IEEE/ACM Transactions on Computational Biology and Bioinformatics,2004,1(4):181-190.
[11]Ye J.Characterization of a Family of Algorithms for Generalized Discriminant Analysis on Undersampled Problems[J].J.Mach.Learn.Res.,2005(6):483-502.
[12]Price J R,Gee T F.Face Recognition Using Direct,Weighted Linear Discriminant Analysis and Modular Subspaces[J].Pattern Recogni⁃tion,2005,38(2):209-219.
[13]Golub G,Van Loan C.Matrix computations[M].Johns Hopkins University Press,1996.
ATwo-stage DiscriminantAnalysis Method
Zeng Qingsong
(School of Information and Technology,Guangzhou Panyu Polytechnic,Guangzhou 511483,Guandong)
In order to tackle the problem of representing the distribution of complicated data using LDA,this paper proposes a novel method for constructing the non-parametric scatter matrix.Compared to classical LDA,our method can describe the classification boundary in a better way while preserving more useful information for classification.Since the non-parametric within-class scatter matrix may be singular for small sample-size problem,we propose a two-stage discriminant analysis method to optimize the criterion function.The human face images are projected onto the principal component subspace of the mixture scatter matrix via SVD so that the within-class scatter matrix in the projection subspace is singular.Via CS decomposition,we theoretically analyze the problem of solving the diagonal scatter matrix and prove that the projection matrix satisfies the orthogonally constraint.The experimental results on three face databases,i.e.,the ORL database,the Yale database and the YaleB database,demonstrate the improvement of the proposed method over the traditional subspace methods.
non-parametric discriminant analysis;cosine-sine decomposition;face recognition;PCA;subspace
TP391.41
A
1008-6609(2016)05-0014-06
曾青松,男,湖南邵东人,博士,副教授,研究方向:模式识别,数据挖掘。
广东省自然科学基金:基于图像集的人脸识别若干关键技术研究,项目编号:2015A030313807。
猜你喜欢
数学年刊A辑(中文版)(2022年1期)2022-08-20
农业工程学报(2022年7期)2022-07-09
四川大学学报(自然科学版)(2021年4期)2021-07-15
吉林大学学报(理学版)(2020年3期)2020-05-29
计算机工程(2020年3期)2020-03-19
数学物理学报(2019年6期)2020-01-13
中国听力语言康复科学杂志(2019年3期)2019-06-24
自动化学报(2018年7期)2018-08-20
中国交通信息化(2018年3期)2018-06-13
装甲兵工程学院学报(2017年3期)2017-07-05
