
中国文学与文化典籍英译的批评标准
2015-12-22 08:30姚振军
当代作家评论 2015年3期
王 焱 姚振军
一、“典籍”与“典籍英译”
“典籍”二字首见于《孟子·告子下》:“诸侯之地方百里;不百里,不足以守宗庙之典籍。”《辞源》和《辞海》中典籍定义为“国家重要的法则文献”。在外语界,杨自俭认为:“典籍”应界定为“‘中国清代末年(十九世纪中叶近现代汉语分界处)以前的重要文献和书籍’为宜。”黄中习则认为“中国典籍”指产生在一九一一年以前、内容是研究中国古代传统文化、方法是中国古代传统著作方式、装帧具有中国古代图书传统装帧形式的经典古籍,如刻本、写本、稿本、拓本等。而广义的“中国典籍”则是在同一时期产生于中国大地而又有传统装帧形式的著作,它不仅涵盖中国人的著作,包括我国少数民族的经典作品,也包括了外国人在中国所写的著作。汪榕培教授根据《辞海》和《孟子·告子下》以及《尚书》等书目对“典籍”一词的阐释指出,典籍主要有两个义项:一是古代重要文献和书籍,二是法典、制度。“典籍”似界定为“中国清代末年一九一一年以前的重要文献和书籍”。重要文献和书籍是指中国的社会科学、自然科学等各个领域的典籍作品。
中国典籍的翻译,从十六世纪末利玛窦用拉丁文翻译《四书》算起,至今已有四百余年。中国学者自觉向西方译介中国典籍也有一百多年的历史。英国有关中国古典文学的书籍出版了三百余种,博士论文三十余篇;美国的中国典籍英译及研究起步较晚,但现有的书籍和博士论文多达一千余种,都问世于二十世纪。在国内,晚清民初时期辜鸿铭和苏曼殊等开始典籍英译活动。前者曾推出《论语》和《中庸》等英译本,后者曾英译古诗一百一十首,其中《诗经》六十一首、唐代李白、杜甫等诗五十一首;二十世纪二十—四十年代,国人英译中国典籍数量不多,最为突出的是林语堂,他翻译了《墨子》、《镜花缘》、《老残游记》、《古文小品选译》、《老子之智慧》和《庄子》等典籍;新中国成立初期,从事典籍英译的代表性人物是杨宪益和其夫人戴乃迭,二人共同英译了《红楼梦》等文学作品,共翻译了上千万字。由于中国典籍蕴含了中华文化的精华,典籍外译也就成为中华文化传播的重要一环。近十年来,在新闻出版总署批准列入国家规划的重大出版工程的《大中华文库》翻译出版工程等一系列政府工程的推动下,大批的中国典籍已经先后被译成英文或者其他语种,在中国文化走出去方面做出了积极的贡献。
二、描述翻译学
根据翻译研究涉及的不同方面,霍尔姆斯将其分为纯翻译研究(Pure)和应用翻译研究(Applied)两大类。前者可以包括理论翻译研究(Translation Theory)和描述翻译研究两个分支。理论翻译研究的目的在于“建立一般性原则,用以解释和预测翻译行为和作品等现象”;而描写翻译研究是一个以目标文本为取向的学科,它包括“对于定义清晰的语料库的精心研究”,具体涉及翻译的抉择过程、翻译的规范、第三语码与翻译普遍特征之类的问题。描述和理论翻译研究之间互为作用,描述翻译研究“在翻译研究理论指导下进行,以最佳方式证明或驳斥,尤其是修改和修正了这一理论”。应用翻译研究主要是指翻译规范在实践中的具体运用,它可以进一步被分为四个范畴:译者培训、提供翻译工具、制定翻译策略、翻译批评。
描述翻译学细分为三个小的分支,(1)“面向译本的描述翻译学”指的是对已有译作进行描述的翻译研究领域;(2)“面向功能的描述翻译学”主要研究译本在译语的社会文化环境中所发挥的作用;(3)“面向过程的描述翻译学”主要研究译者在翻译时的思维运作方式。翻译理论,即利用描述翻译学的研究成果,加上相关学科及专业提供的资料,总结出一些原则、理论和模式,以解释和预测翻译的过程和成果。霍尔姆斯认为描述翻译研究和翻译理论同属纯研究性质。另外,霍尔姆斯还在他写的论文《翻译学的名与实》中补充指出,翻译学的三个分支中还有两个问题尚未提及,翻译史问题和翻译学里面使用什么方法和模式最好的问题。
根据图里等人的论述,可以看出描述性翻译研究重视描述性的方法,考虑翻译和文化背景的结合,并且以译文为取向。而这些特点有进一步决定了描述性翻译研究应该以语料库为研究的基础。
图里认为,如果翻译研究不想再依靠语言学等其他学科,并自身成为一个独立的学科,那么它必须发展一种描述性方法。描述翻译研究不应该是翻译原文和译文的比较分析或例子分析的集合,它必须提供合理的研究方法、明确的调查过程,以便使单独的描述研究的结果可以概括整个翻译行为。也就是说,描述方法的研究结果虽然不是翻译行为的全部,但却可以通过规范、明确的研究方法、实验过程等具体操作,使实验具有可重复性、可推广性、可预测性,进而在一定范围内代表某种翻译现象。所以,方法论是描述翻译的首要条件。描述翻译研究因为有连贯的方法,所以才能够对翻译问题进行可以证实的理论概括。此外,描述翻译研究是允许各种研究方法和平共处、相辅相成的一种研究策略。它将微观上的每一种在一定规范指导下进行的翻译研究仅仅看作一种翻译研究,它坚信各种翻译研究方法之间应该是和平共处的关系。
描述翻译研究认为所有个案研究必须遵循同一个指导原则,将每个问题都置于更高层次的上下文中加以研究;文本、行为方式和文化背景都应该考虑在内。也就是说,翻译要和文本以及当时当地的情况结合起来研究,翻译并不是可以脱离时代而独立存在的。另一方面,描述翻译研究注重文化、上下文对翻译的作用,但却一刻也没有离开过文本研究。描述翻译研究对文化背景的重视并不意味着要离开翻译的本体。
描述翻译研究是一种以译文为取向的学科。图里认为,“翻译就是在目的系统当中,表现为翻译或者被认为是翻译的任何一段目的语文本,不管所根据的理由是什么”。描述翻译研究是后瞻式的,它是“从目标语出发,拿目标文本质量与源文质量做比较。通过对两者的比较,可以辨别生成目标文本的各种表达过程,并确定这些过程在多大程度上充分地实现了预期目标”。可见描述翻译研究对目标文本的重视。
描述性翻译研究与语料库语言学的结合为二十世纪九十年代语料库翻译研究的兴起和发展奠定了基础。语料库翻译研究(CTS)的主要内容就是用语料库语言学方法研究翻译作为社会文化现象的特征。英国曼彻斯特大学翻译与跨文化研究中心主任Mona Baker是语料库翻译研究的创始人之一。她最早提出了将语料库语言学工具用于对翻译的过程和经过进行描述性的研究,她可以被称作是“语料库翻译研究之母”。。Mona Baker在一九九三年发表的“Corpus linguistics and translation studies:implication and application(《语料库语言学与翻译研究:启示与应用》)”一文中首先对传统翻译学的两大基本倾向:原文为中心和与之相伴的翻译对等观提出了质疑,然后论述了当代翻译理论发展的总体趋势。她认为当代翻译学的两个总体趋势是——原文与译文语义对应观的衰落;原文地位和将翻译视为原文译文的静态对等观的衰落。研究翻译规范必须对特定语言或文化的具有代表。Baker指出Toury的描写翻译学是翻译学成为独立学科的必经之路,而语料库研究为描写翻译学提供了直接、可靠的数据来源。翻译是两种语言、两种文化间的转换活动。前苏联翻译理论家费道罗夫认为“翻译就是用一种语言把另一种语言在内容和形式不可分割的统一中业已表达出来的东西,准确而完全地表达出来”。
运用语料库进行翻译研究是对中国文学与文化典籍英译批评标准的一种有益探索。
三、中国文学与文化典籍英译的分类及批评标准
中国文学与文化典籍英译的分类可以参照中国传统的“经、史、子、集”四部分类法。“经”主要指儒家的典籍以及古代社会中的政教、纲常伦理、道德规范的教条等,例如,《周易》、《周礼》、《尚书》、《礼记》、《仪礼》、《诗经》、《春秋左传》、《春秋公羊传》、《孟子》、《论语》、《孝经》、《尔雅》、《春秋谷梁传》等。“史”是各种体裁历史著作,分为正史、编年、别史杂史、纪事本末、诏令奏议、传记、地理、载记、时令、史钞、职官、政书、目录、史评十五类。例如,《山海经》、《国语》、《穆天子传》、《战国策》、《史记》等。“子”是诸子百家及释道宗教著作,分为儒家、兵家、法家、医家、农家、天文算法、术数、艺术、诸录、杂家、类书、小说家、释家、道家十四类。例如,《老子》、《庄子》、《淮南子》、《韩非子》、《列子》、《墨子》、《荀子》、《孙子兵法》、《吕氏春秋》等。“集”是指历代作家一人或多人的散文、骈文、诗、词、散曲等的集子和文学评论、戏曲等著作,分为楚辞、别集、诗文评、诗词五类。例如,《楚辞》、《六朝文契》、《唐诗三百首》、《古文观止》、《诗品》、《文心雕龙》、《西厢记》、《窦娥冤》、《牡丹亭》等。
汪榕培教授在《中国典籍英译》一书中对典籍英译的分类进行了论述,认为“典籍”主要有两个义项:一个是古代重要的文献、书籍;另一个是法典、制度。典籍似界定为中国清代末年一九一一年以前的重要文献和书籍。汪榕培教授的分类方法中主要侧重的是中国古代的文学典籍,因此,汪教授将“典籍”分为古典散文、古典诗歌、古典戏剧和古典小说,并以“传神达意”为标准加以分别论述。
首先,汪教授认为古典散文是一个内涵和外延都相当模糊的范畴,我国古代将不押韵、不重排偶的散体文章称为散文,与韵文和骈文对举;又曾将散文和诗歌并举,泛指不讲究韵律的小说及其他抒情记事之作。
基于此,汪榕培教授认为古典散文的英译基本原则是“传神达意”。这一翻译标准也是典籍英译批评的主要标准之一。“达意”是出发点,译者在自己的译文中必须准确地体现自己对原文文本的理解和阐释。单纯“达意”还不够,必须是“传神达意”。“传神”既要包括传达外在的形式,也要包括传达内在的意蕴,如语篇的背景、内涵、语气乃至关联和衔接等。古典散文英译的最高境界是再现原文的韵味。译者需要加强语言、文化和审美方面的修养,通过准确而富有文采的英文将原作的艺术内涵表现出来。
其次,我国典籍中的诗歌传统源远流长,并且在不同时代都会有代表其独特风格的诗歌形式和丰富多彩的诗作。从诗歌产生和发展的历史来看,上古的谣、谚则是我国诗歌的最早源头。唐代是我国诗歌的鼎盛时代,其特点是诗作多、诗人多、风格流派多、质量高,是诗歌成就最大、收获最多的时代,出现了中国诗坛前无古人、后无来者的大诗人。宋代的诗歌亦有其独特的特点,总的倾向是喜用典故、议论过多、句法散文化等。汪榕培教授认为,中国古典诗歌的翻译标准应该是“传神达意”,更具体为“传神地达意”。“达意”是翻译的出发点,就是表达思想的意思,字、词、句、章各个层次都存在达意的问题。单纯的“达意”还是不够的,必须是“传神地达意”,因为“传神”是翻译文学作品,特别是诗歌作品的精髓。
第三,中国古代戏剧以“戏”和“曲”为主要因素,故称“戏曲”。中国古典戏曲是中华民族文化的重要组成部分,其富于艺术魅力的表演形式为历代人民所喜闻乐见,而且在世界剧坛上也具有独特的位置。译戏如演戏,不同的是,演员只需要本人进入要演的角色,译者却要进入剧中所有的角色。中国古典戏剧在英美等国家的传播有三难:翻译难、表演难、接受难。针对这些问题,该文学体裁英译的原则仍然是“传神达意”。“达意”是翻译的出发点,译者在自己的译文中必须准确地体现自己对原文文本的理解和阐释。单纯的“达意”是不够的,“传神”既要包括传递外在的形式,也要包括传达内在的意蕴。
第四,“小说”一词最早并非指一种文学体裁,而是那些无关大道的浅薄琐屑之谈,因而不被正史家看重,地位很低。我国古典小说的萌芽和发生最初是和古代神话、历史传说密不可分的。明代是我国古典小说全面丰收、也是小说登上艺术之巅峰的时代,其中最有成就的是四大长篇小说的产生。清代小说是明代之后的又一个高峰。其表现为长篇巨著和具有多种风格的作品出现。中国古典小说具有其自身的特点,其英译也应视作一种特殊的文体来研究。中国古典小说英译中,再现原文文学风格和艺术美确实是一个艰难曲折的过程,不仅涉及语言运用的艺术问题,还与语言之外的诸多文化现象有着密切的关系。从总体上说,其英译的标准仍然是“传神达意”。
另外,在典籍英译的英语分类中,每种文本都将被赋予不同的维度。例如,科技文本中的医学文本将具有语言维、医学维和哲学维等。语言维度的批评将关注语言是否自然流畅、生动形象;医学维度的批评将要求翻译的术语准确性和无歧义性,从而保证翻译和原作具有同等的医学价值;而哲学维度的批评将重点考查译文是否传达了中国典籍文本中的哲学思想等。由此而进行的翻译批评将会是多视角、多维度的,因而是更加全面的。
四、中国文学与文化典籍英译的描述性批评标准
描述翻译研究离不开语料库,描述性翻译研究视野下的翻译批评理也离不开语料库。王克非指出,语料库翻译学有两方面理论发展的支持:其一,语义观转变为情境观,突破了传统的“对等”,将其视为一定社会文化情境中语言使用的对应;第二,描写翻译研究范式打破了原作的主宰地位。描述翻译研究是“对于定义清晰的语料库的精心研究”。语料库的建立也是描述翻译研究方法论的一个主要体现。目前的翻译研究需要不断扩大、完善的语料库,虽然“语料库越大、越杂,研究者在具体提炼或概括数据的过程中会遇到越大的困难”,但是没有不断系统、扩大的语料库,描述翻译研究就很难继续发展,因为它需要描述的对象以及进一步预测、验证的对象,而这些必须由系统的语料库来提供。现代语料库语言学与描写翻译学的研究成果为语料库翻译研究提供了坚实的理论基础。作为一种实证研究方法,语料库翻译研究以现实的翻译文本作为研究对象,采用科学的统计与分析方法,客观地描述翻译活动本身的规律。该研究方法被广泛运用于研究翻译普遍性、翻译规范、译者文体等方面,是一种新的研究范式。
本文以《典籍英译研究》(第一、二、三辑)为主要数据来源,运用基于语料库的描述性翻译研究的思想,应用文献计量学和数理统计学方法对该刊二○○五-二○○七年发表的论文作者进行统计分析。分析指标主要有作者合作情况、地区分布、系统分布、核心作者分布、多产机构分布,希望从该刊作者的构成情况来了解典籍英译论文的特点和趋势。
本文以汪榕培教授作为第一主编的《典籍英译研究》前三辑(二○○五年五月河北师范大学出版社,二○○六年一月大连理工大学出版社,二○○七年十月吉林大学出版社)为研究对象,借用语料分析的方法,研究典籍英译的核心作者和高被引作者,为探索中国文学与文化典籍英译的描述性批评标准奠定基础。
作为全国典籍英译研讨会的会议成果论文集,《典籍英译研究》共收录了学术论文一百三十六篇(本文统计中未包括第二辑中“译界新秀论文集锦(光盘版)”中所录论文)。作为专业会刊类论文集,《典籍英译研究》较为全面地反映了典籍英译的理论与实践的研究情况,客观地展现了本领域研究中的最新研究成果,具有相应的代表性和权威性。
本文提出的计算频度的公式如下:
P=N+100L+100F
其中N是候选术语在检索文献中出现的总次数,L是候选术语的支持度即候选术语所属文章的计数,F是候选术语的最高频繁级别(即候选术语所属的最大的频繁项集)。一百是F和L的权重。通过这个公式计算候选术语的得分P,P值越高的候选术语是术语的可能性越高,P值越低则可能性越低。通过这个公式计算候选术语是术语的可能性,就避免了单纯计算频率造成的术语丢失的问题;同时由于引入了支持度和频繁项集的概念,将术语识别的范围由单个文章上升到整个领域的所有文章,更关注文章与文章的关系,使得术语的识别更可靠。
最后,将候选术语按P值由高到低返回给用户,由人进行术语的最终识别。
本文重点关注了翻译批评的客体之一的译者,从而确定译者的影响力,以下是系统自动报告的结果节选:
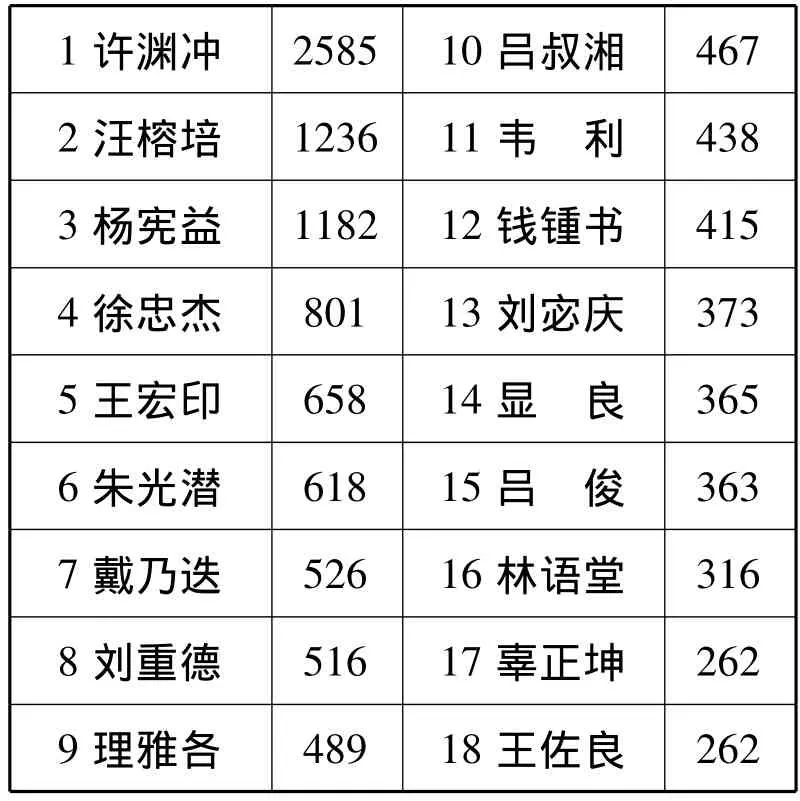
1许渊冲 2585 10吕叔湘467 2汪榕培 1236 11韦 利438 3杨宪益 1182 12钱锺书415 4徐忠杰 801 13刘宓庆373 5王宏印 658 14显 良365 6朱光潜 618 15吕 俊363 7戴乃迭 526 16林语堂316 8刘重德 516 17辜正坤262 262 9理雅各 489 18王佐良
同时,我们可以依据普赖斯所提出的计算公式进行了统计核心作者群的方法来计算核心译者。核心作者群是指那些发文量较多,影响较大的作者集合。普赖斯公式为M=0.749(Nmax)1/2,式中 M 为论文篇数,Nmax为所统计的年限中最高产的那位作者的论文数,只有那些发表论文数在M篇以上的人,方能称为核心作者,也即多产作者。
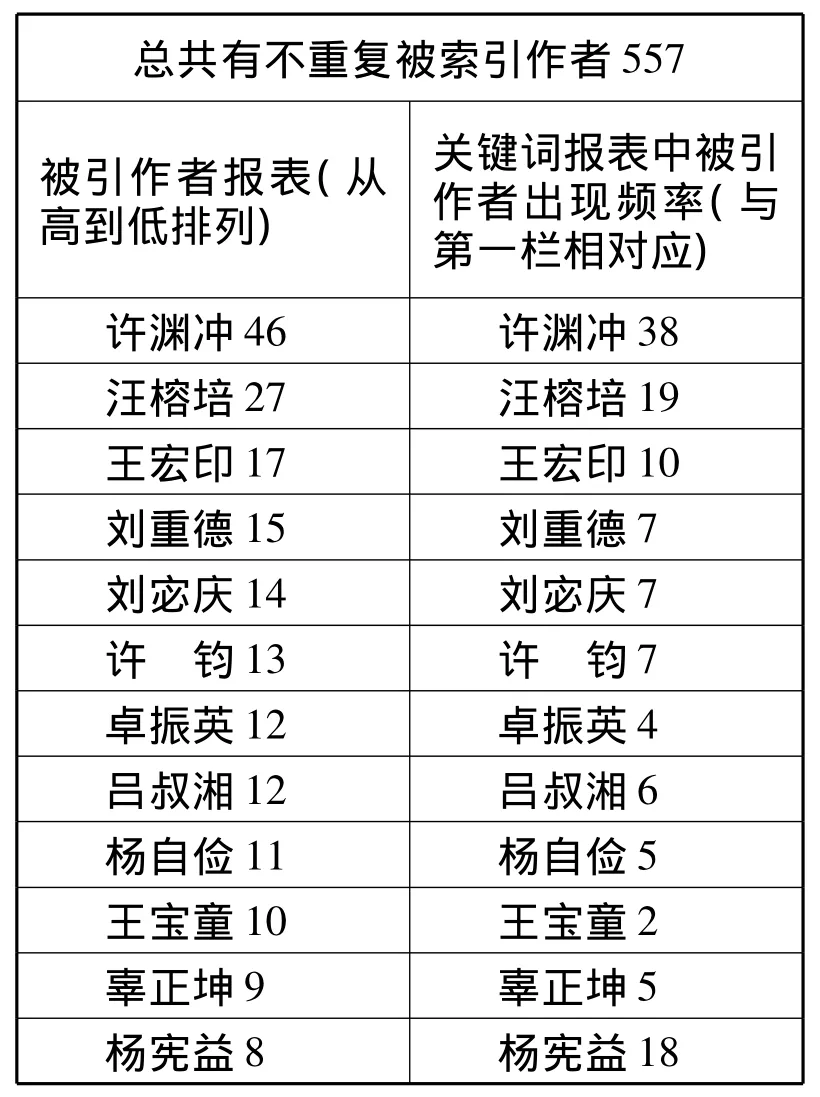
王宝童10 王宝童2辜正坤9 辜正坤5杨宪益8 杨宪益18
根据上表,在本文所统计的时间段内,《典籍英译研究》的Nmax=46,代入公式M=0.749 ×461/2,求出 M 值为 17.22 次,在实际应用中,按照取整的原则,取M值数为17,即在《典籍英译研究》上被引用17以上的那些作者为该论文集中的核心译者,1在《典籍英译研究》上被引用17以上的译者为3人,共计被引用90次。被引用3次以上的译者包括:
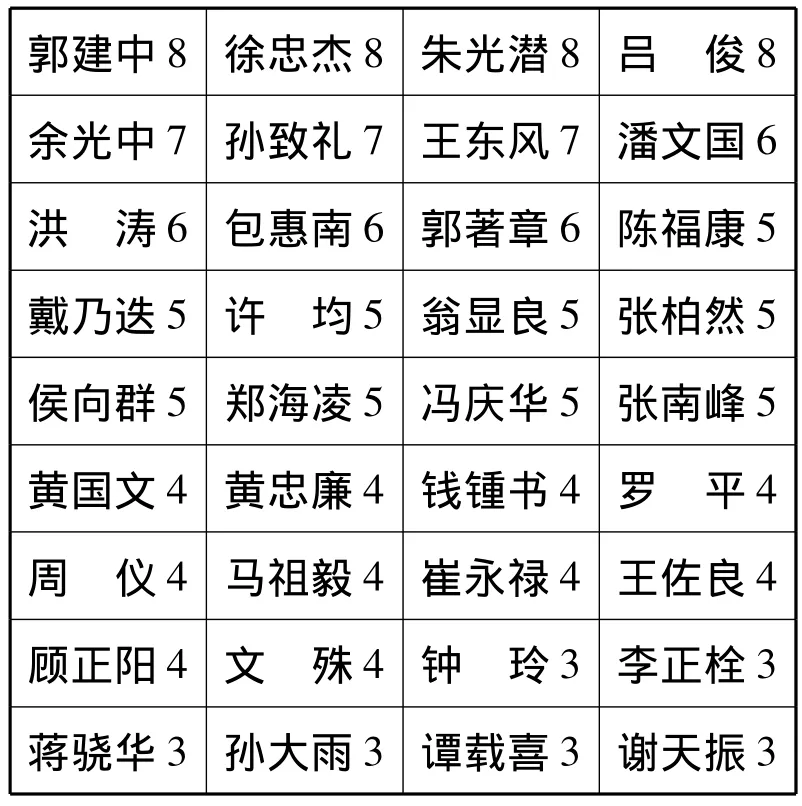
郭建中8徐忠杰8朱光潜8吕 俊8余光中7孙致礼7王东风7潘文国6洪 涛6包惠南6郭著章6陈福康5戴乃迭5许 均5翁显良5张柏然5侯向群5郑海凌5冯庆华5张南峰5黄国文4黄忠廉4钱锺书4罗 平4周 仪4马祖毅4崔永禄4王佐良4顾正阳4文 殊4钟 玲3李正栓3蒋骁华3孙大雨3谭载喜3谢天振3
五、结论
任何经验学科如果没有描述分支的存在,就不能称之为完整的相对独立的学科。描述的研究方法是形成理论的最好方法,其中包括检验、否定、修正并完善理论的过程。描述分支和理论分支之间的关系是相辅相成的,在这种相互作用中产生的研究成果更完善、更具有意义,有助于深刻理解研究内容,并使学科应用成为可能。因此,翻译批评研究应该建立在描述研究的基础之上,后者在实际研究中积累丰富的事实根据,不仅对翻译行为做出详尽的描述和解释,从而有充足的根据做出合理的预测,而且为前者的理论建设奠定了基础。
典籍英译的研究在不断深入,典籍英译批评却显得相对薄弱,特别是点评式、印象式和随感式的评论方式以及“标准——分析——结论”的规定性批评模式仍然占据主导地位。本文从描述翻译学视角出发,论述典籍英译批评的理论基础和体系,尝试性地构建描述翻译学视角下的典籍英译批评体系和中国文学与文化典籍英译的描述性批评标准,以期进一步完善典籍英译实践,丰富典籍英译研究的理论。
猜你喜欢
——鲁迅藏中外美术典籍展
中华书画家(2022年6期)2022-11-04
英美文学研究论丛(2022年1期)2022-10-26
国际商业技术(2021年9期)2021-05-27
知识文库(2019年22期)2019-11-11
红楼梦学刊(2019年2期)2019-04-12
师道·教研(2017年11期)2017-12-10
阅读(中年级)(2016年10期)2016-12-10
改革与开放(2010年6期)2010-06-04
中学英语园地·初二版(2008年12期)2008-01-14
云南大学学报法学版(2004年4期)2004-02-03
