
北京地区高校学生图书馆焦虑测量分析
——基于图书馆焦虑量表的修订与验证
2015-12-03 03:29万云芳贾舒敏冯素洁沈蓉蓉吴雪芝沈鑫郭晓珍李斯
大学图书馆学报 2015年3期
□万云芳 贾舒敏 冯素洁 沈蓉蓉 吴雪芝 沈鑫 郭晓珍 李斯
北京地区高校学生图书馆焦虑测量分析
——基于图书馆焦虑量表的修订与验证
□万云芳 贾舒敏 冯素洁 沈蓉蓉 吴雪芝 沈鑫 郭晓珍 李斯
为了测量与分析北京地区高校学生的图书馆焦虑,以北京航空航天大学(985学校)、北京工业大学(211学校)、首都师范大学(一本学校)、北京联合大学(二本学校)、耿丹学院(民办三本学校)、北工大实验学院(二级独立学院)为抽样对象,运用结构方程模型分析方法修订与验证现有的图书馆焦虑量表,并运用修订后的图书馆焦虑量表对上述六所学校的图书馆焦虑现象进行了统计与分析。
图书馆焦虑 测量 图书馆焦虑量表 修订 北京地区 高校图书馆
1 引言
焦虑是潜伏在我们所观察到的行为背后的一种潜在构念,是个体对某种预期会对他的自尊心构成潜在威胁的情境所产生不安、忧虑、紧张甚至恐惧的情绪状态。图书馆焦虑是读者在使用图书馆时产生的上述不愉快情绪。比如:现代图书馆在提供了高端大气的学习空间、设计布局的同时也会给一些读者带来找不着北无所适从的感觉,先进的自助服务设备在提供便捷的同时也让一些人担心出错而不敢使用,不断改进的检索方式让不少读者都有过不知所措的经历……这些会让一些内向、羞于询问的读者感到为难和困惑,当读者在图书馆遭遇了不顺利、尴尬、没能达到预期目的的经历后,将会对图书馆逐渐失去兴趣、信心甚至产生抵触情绪,最终导致图书馆读者的流失。究竟哪些读者是因为图书馆的服务不足产生焦虑从而降低了利用图书馆的能力?用什么方式来衡量评估焦虑?这些是图书馆改进服务需要研究的问题。
1986 年,美国图书馆学家康斯坦斯·麦仑首次提出了图书馆焦虑的概念,将读者在使用图书馆时产生的心理障碍称为图书馆焦虑( Library Anxiety,LA),开启了LA定性研究阶段。
1992 年, 美国研究者申农·波丝蒂克将LA定义为读者使用图书馆而产生的消极情绪和不舒服的感觉。他在康斯坦斯·麦仑抽象、定性的研究基础上,创建了LA定量研究工具:图书馆焦虑量表(Library Anxiety Scale,LAS),用于定量分析LA 的程度。这开创了LA定量研究的先河,为以后LA定量研究奠定了基础[1]。
LAS是一组能反映焦虑潜在变量(潜在构念)水平的项目,这些项目也被称作测量变量(或观察变量、指标变量、显性变量)。由于LAS是LA研究者针对一定的图书馆背景与环境提出的,有其自身的适用范围,自1992年申农·波丝蒂克创建了5维度43项度LAS以来,先后有众多学者在此基础上按照自己国家和种族图书馆环境与特点或自己的研究方向,重新建立或修订了适合自身的LAS。
2001年,以色列研究者斯纳利斯·肖哈门与戴安娜·米兹拉齐对以色列本科生的LA现象进行了深入的研究,他们将申农·波丝蒂克的LAS翻译成希伯来语,同时结合本民族特点对LAS进行了改进,将量表中的5大因素增加到7 大因素。2003年,美国圣里奥大学多丽丝·范坎彭博士,在申农·波丝蒂克的LAS基础上,根据卡罗尔·库尔梭的信息检索模型,编制了6个维度54个项目图书馆焦虑多维量表,来测量博士研究生在完成学位论文写作阶段使用图书馆过程而产生的LA程度。2004年科威特大学图书馆与情报学系的安瓦尔等三人沿用申农·波丝蒂克的英文版量表,并作了必要的修订,将申农·波丝蒂克量表维度由5个减至4个,项目由43条减至34条。2009年,波兰奥尔什丁瓦尔密亚玛祖里大学的马儒则纳·斯维哥根据波兰的国情,参照已有的LAS,建立了6个维度的适合本土研究的波兰LAS[2]。
今天,更多的研究方法被运用到LA研究中,比如结构方程模型(Structural Equation Modeling, SEM)概念的提出,以及SPSS、LISREL、AMOS等统计软件的开发与成熟,使SEM的理念和技术转化为研究者可以直接使用的工具,为LA研究开创了一个崭新的量化研究范式。更多国家的研究者加入到LA研究行列,比如加拿大、伊朗、马来西来、土耳其、中国[3]。2006年,吉林大学图书馆贺伟根据当时我国的国情将申农·波丝蒂克 LAS进行了中文修订及信效度检验,量表分为5个维度,共计63个项目[4]。2011年,南开大学商学院宋志强等人在已有LAS的基础上,通过调研构建了符合当时图书馆环境的包括7维度40条目的LAS[5]。
随着互联网技术与数字资源的迅猛发展、读者需求的不断变化,图书馆的服务与功能也发生了巨大变革,这些变革会使已有的LAS出现测量变量不足以反映其潜在变量的问题,同时也会有新的潜在变量产生或旧的潜在变量失效的可能,这也是我们修订量表的原因所在。在分析方法上,适合于高校的中文LAS(如吉林大学图书馆贺伟修订量表和南开大学商学院宋志强修订量表)都进行了因素分析及信、效度检验。我们此次修订将采用SEM分析方法,在探索性因素分析(Exploratory Factor Analysis, EFA)、验证性因素分析分析(Confirmatory Factor Analysis, CFA)得出测量模型的基础上,进一步探究了潜在变量间因果关系的结构模型,并运用群组分析求证量表的稳定性和跨群组效度。在样本数据的获取上,为便于实地进行问卷调查确保样本数据的真实可信度,我们选择了北京地区六所不同层次的高校:北京航空航天大学(“985”学校)、北京工业大学(“211”学校)、首都师范大学(一本学校)、北京联合大学(二本学校)、耿丹学院(民办三本学校)、北工大实验学院(二级独立学院)。
2 图书馆焦虑量表的第一次修订
我们此次对LAS的修订是在申农·波丝蒂克的LAS、吉林大学图书馆贺伟修订量表、南开大学商学院宋志强修订量表等基础上进行的。
2.1 编制预试问卷及施测
编制一个高信度、效度的量表是要以初始项目(测量变量)冗余为基础的,初始项目(测量变量)的冗余给量表的修订提供更多的对比和选择的机会,通常初始设计的项目应为量表项目的3-4倍,比如一个10项目的量表,需要有一个40个项目的项目池[6]。因此,重新设计、编制预试问卷,就要尽可能全面地提出有可能使读者产生焦虑的所有方面(潜在变量)、所有问题(测量变量)。为使预试问卷具有一定的内容效度和专家效度,此次编制预试问卷,笔者的具体作法为:1.在上述三个量表基础上筛选、增补初始项目;2.向上述六所学校的图书馆老师征求意见;3.召开读者座谈会,直接倾听来自读者的意见;4.与图书馆助管学生进行讨论。我们在经过上述环节后,结合图书馆实际工作经验反复推敲,最终从读者、馆员、服务、资源、舒适度、管理等六个方面(潜在变量),设计了一份包含56个问题(测量变量)、采用利克特五点计分制的预试问卷。
在问卷调查中,为了使抽样的样本性质能确实反映出总体的属性,学者斯蒂文斯(2002)对于因素分析程序的样本大小与因素可靠性间的关系提出以下看法;样本大小视分析变量数目而定,一般的标准是每个变量(题项)所需的样本数要介于2位至20位之间,但使用者要获得可靠的因素结构,每个变量最少的样本观察值要有5位,因而一份有四十题的量表(不是问卷,一份问卷可能包含数种量表),要进行因素分析时,其样本数最小的需求要有40 x 5=200位。[7]我们编制的预试问卷有56题项,以每个变量不少于5位样本观察值计算,需要样本数应不少于280个。
2013年10月我们统一印制了纸制问卷,在上述六所学校以120份/学校、采取分层随机抽样方式进行了第一次抽样测试。在测试过程中北京航空航天大学老师又自行复印问卷增加发放了40份问卷,相当于实际发放问卷760份。对收回问卷依据测谎题(内容正好相反二道问题)、以及答案出现明显规律的(比如全部题目选A)予以剔除,得到实际有效问卷为712份(详见表1、表2)。全部样本按奇、偶数分为EFA分析样本356个、CFA分析样本356个,二个样本测量题项均采用序列均值方法置换缺失值。

表1 学校

表2 身份
2.2 项目分析
项目分析的主要目的在于检验编制量表(预测问卷)个别题项(测量变量)的适切性或可靠性。项目分析的检验是通过探究高低分的受试者在每个题项的差异,以及题项间同质性检验等方法来决定个别题项的保留与否。笔者采取两个独立样本t检验求得的t值作为极端组决断值比较,以个别题项与总分的相关度、校正题项与总分的相关度、个别题项删除后的内部一致性系数α值、共同性、因素负荷量等项的检验作为个别题项的筛选指标,项目分析的判别标准见表3。经检验,最终删除了26题项(测量变量),保留了30题项(测量变量)。
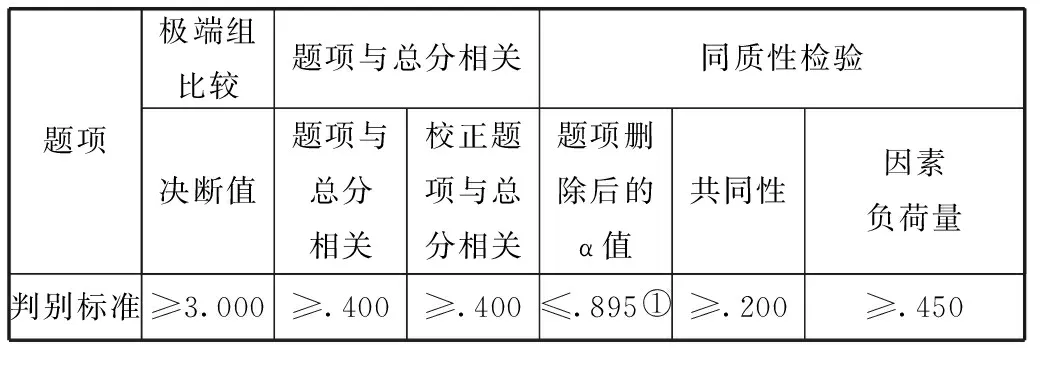
表3 项目分析判别标准[8]
①注:0.895为预测问卷抽样测试内部一致性α系数。
2.3 探索性因素分析(EFA)
测量变量的背后究竟具有几个潜在变量?虽然在量表修订时我们已参考现有量表提出了六个因素构念,但实际数据是否能与我们事先确立的构念相吻合,需要通过因素分析来检验。因素分析的目的即在找出量表潜在的结构,减少题项的数目,使之变为一组较少而彼此相关较大的变量[9]。
因素分析的关键在于保留多少共同因素(潜在变量)。在EFA中,我们将经项目分析保留的30题项全部纳入因素分析变量范围,运用SPSS18.0采用主成分分析法以特征值Kaiser>1、直交转轴的最大变异法提取共同因素,共抽取7个主成分,可以解释的总变异量为56.054%。碎石图(见图1)的检验可以帮助我们决定因素的数目,其判断准则是取坡线突然剧升的因素,删除坡线平坦的因素。从图1看,可以确定抽取三个因素较为适宜。

图1 碎石图
以特征值大于1为判别基准时,有时所抽取的因素过多,或某些因素所包含题项不够适切,不易给因素命名,在探索性因素分析中这是可以理解的。因为受到受试者填答、量表编制过程的严谨性等因素影响,部分量表的因素分析结果常未能完全符合研究者当初编制的层面因素,所以研究者需要删除题项进行第二次、第三次的因素分析,一直不断探索,直到符合理论基础或架构,或达到简单结构目的[10]。经转轴后的成分矩阵分析,笔者保留测量题项较多的构面,删除非归属于原构面中因素负荷量最大的测量题项。经过12次删除题项后,最终抽取“检索困惑”、“环境不适”、“服务不足”三个潜在变量共18个测量变量,三个因素构念可以解释所有观察变量的总变异量的47.848%。在行为及社会科学领域,萃取后保留的因素联合解释变异量若能达到60%以上,表示萃取后保留的因素相当理想,如果50%以上,萃取的因素也可以接受[11]。笔者萃取的结果接近50%,不是很理想。
2.4 测量模型的验证性因素分析(CFA)
测量模型验证检测的是测量变量的因素结构与测量误差。在CFA分析中,笔者采用偶数样本(EFA分析采用奇数样本)运用AMOS17.0进行验证,三个潜在构念均为反映性测量模型,测量模型标准化估计值模型图见图2。
在图2测量模型中参数个数总共有60个,其中固定参数21个,自由参数39个。CFA样本数为356,模型估计样本数为自由参数的9.1倍。SEM参数估计的稳定性和样本大小有关,一般最少的样本需求为200位以上,多数学者观察认为样本大小至少应为假设模型中待估计自由参数的10倍以上[12]。正态性评估偏度系数介于0.007至1.041之间,其绝对值小于2,峰度系数介于0.184至-1.212之间,其绝对值小于2,表示数据符合正态分布假定,因而采用最大似然法对模型各参数统计量进行估计。

图2 测量模型标准化估计值模型图
CFA假设模型路径图的估计结果为:模型可以辨识收敛,非标准化估计值模型误差项或残差项方差均为正数,表示模型参数估计值没有出现不适当解值。标准化估计值模型,没有出现绝对值大于1的标准化回归系数,表示没有违反模型辨认规则。整体模型的自由度为132,模型适配度的卡方值为380.000(p=0.000<0.05),拒绝虚无假设。在大样本情况下,似然比卡方值会膨胀,卡方值显著性通常会小于0.05显著水平,造成正确模型也可能被拒绝的不真实结论,因而在进行假设模型整体适配度检验时,必须再参考其他适配度统计量[13]。其他适配度统计量:卡方自由度比值为2.879(符合<3理想标准),RMSEA值为0.073(符合<0.080理想标准),CFI为0.853(未符合>0.900适配标准),NFI为0.793(未符合>0.900适配标准),GFI值为0.893(未符合>0.900适配标准),AGFI值为0.861(未符合>0.900适配标准),CN值为150(未符合>200理想标准)。假设模型与样本数据适配不佳。
对于适配不佳的假设模型要进行修正。当测量变量的因素负荷量小于0.5时,就不能有效反映因素构念,就不能作为因素构念的有效测量变量。因素负荷量等于测量变量路径系数的平方,因此当路径系数小于0.70时应考虑删除。笔者以路径系数<0.65(约等于0.70)为删除门槛,经多次题项删除后得到3维度8题项模型。修正后模型内的自由度等于17,模型适配度的卡方值为56.391( p=0.000<0.05),卡方自由度比值=3.317(不符合<3理想标准),RMSEA值=0.081(不符合<0.080理想标准),CFI=0.949(符合>0.900适配标准),NFI=0.929(符合>0.900适配标准),GFI值=0.961(符合>0.900适配标准),AGFI值=0.918(符合>0.900适配标准),CN值=174(未符合>200理想标准)。假设模型与样本数据尚可适配。
修正后模型有2个维度只有2个测量变量。测量模型的评价目标在于测量变量是否足以反映其相对应的潜在变量,并有一定的信、效度支持。“一般最少的准则为一个潜在构念的指标变量(测量题项)至少要有三题以上,若测量指标题项少于三题,指标变量反映的潜在特质效度不足。”[14]
焦虑量表第一次修订,经项目分析删除26题;经EFA分析删除12题,萃取三个共同因素18个项目;经CFA分析删除路径系数低于0.65(约等于0.70)的10个项目,获得量表包括“检索困惑”、“环境不适”、“服务不足”3个维度共8个项目。量表第一次修订因删除题项过多造成一些潜在变量测量题目不足、抽取共同因素与最初设计差异较大,量表效度需要再重新建构。因此,我们在第一次修订的基础上,围绕 “检索困惑”、“环境不适”、“服务不足”三个维度进行了题项的增补和修改。增补重点为测量变量不足的维度;修改重点为对有一定测量价值但可能因提法使人不愿意承认或读者不易正确理解的测量变量进行了修改或删除,题项数量控制在大多数读者在忍耐限度内能够完成为宜。修改后,笔者编制了25题项的测试问卷并进行了第二次测试。
3 图书馆焦虑量表的第二次修订
2014年3月我们在上述六所学校进行了第二次测试。第二次测试抽样数按各学校在校生规模的十分之一并考虑可能产生无效问卷的比例确定:北京航空航天大学、北京工业大学、首都师范大学、北京联合大学各为260份,耿丹学院、北工大实验学院各为110份。六所学校共发放问卷1260份,收回问卷1211份(详见表4、表5)。

表4 学校

表5 身份
问卷调查的基本信息包括学校、身份、性别、学科、文检课选修情况、去图书馆情况、利用电子资源情况,以便我们针对不同群体读者的焦虑状况进行统计分析。剔除不合格问卷后全部样本按奇、偶数分为二部份,奇数样本作为EFA分析样本,以序列均值替代题项缺失值,样本数为595;偶数样本作为CFA分析样本,直接删除有题项缺失值记录,样本数为562。
3.1 EFA分析
第二次测试,经项目分析删除5题、保留20题。EFA分析采取主成份分析法,以特征值kaiser>1、直交转轴最大变异法抽取主成分,共抽取三个共同因素,经转轴后成分矩阵分析删除2题项后,解释的
总变异量为52.871%(见表6)。因原设计为“服务不足”的题项经删除后保留题项更适合命名为“情感障碍”,EFA分析最终保留“环境不适”、“检索困惑”、“情感障碍”3个因素18题项。
3.2 测量模型CFA分析
经EFA分析萃取的三个潜在构念均为反映性测量模型,分别包括6个效果指标变量。CFA分析样本数为562,参数个数总共有60个,其中固定参数21个,自由参数39个,模型估计样本数为自由参数的14.4倍。假设模型估计结果模型可以识别收敛,模型评估结果的参数没有不适当解值。以测量变量路径系数不低于0.65为删除标准,删除不能足以反映潜在构念的测量变量,修正后测量模型见图3。为了保证每个潜在构念有三个测量变量,我们保留了路径系数为0.62的变量qg16,qg16测量变量还有待改进。

图3 修正后标准化估计值模型图

成份初始特征值提取平方和载入旋转平方和载入合计方差的%累积%合计方差的%累积%合计方差的%累积%16.11833.99233.9926.11833.99233.9923.32218.45318.45322.02011.22545.2162.02011.22545.2163.31418.41236.86631.3787.65552.8711.3787.65552.8712.88116.00652.8714.9805.44658.317……

图4 因果关系标准化估计值模型
3.3 结构模型的验证
完整的结构方程模型(SEM)包含测量模型与结构模型。结构模型表示的是因素构念间的关系,结构模型检验的重点在于界定模型中变量的因果关系效度,也就是因果结构效度的检验。假设模型中所有变量的因果关系都必须根据理论、实证研究、或合理性经验法则来界定[15]。我们保留的“检索困惑”、“环境不适”、“情感障碍”三个潜在构念,从合理性经验判断,“检索困惑”与“环境不适”应该是引起“情感障碍”的外因,这种因果关系的假设模型见图4。经CFA验证,“检索困惑”与“环境不适”对内因潜在变量“情感障碍”影响的标准化路径系数分别为0.33、0.57,联合解释变异量为57%。其整体适配度统计量检验结果摘要见表7,16个指标有14个指标达到标准,其中6个指标达到良好标准,只有2个指标未达标准,假设模型与样本数据契合度良好,表示假设模型可以获得支持,这样的假设模型理论上是可以接受的。
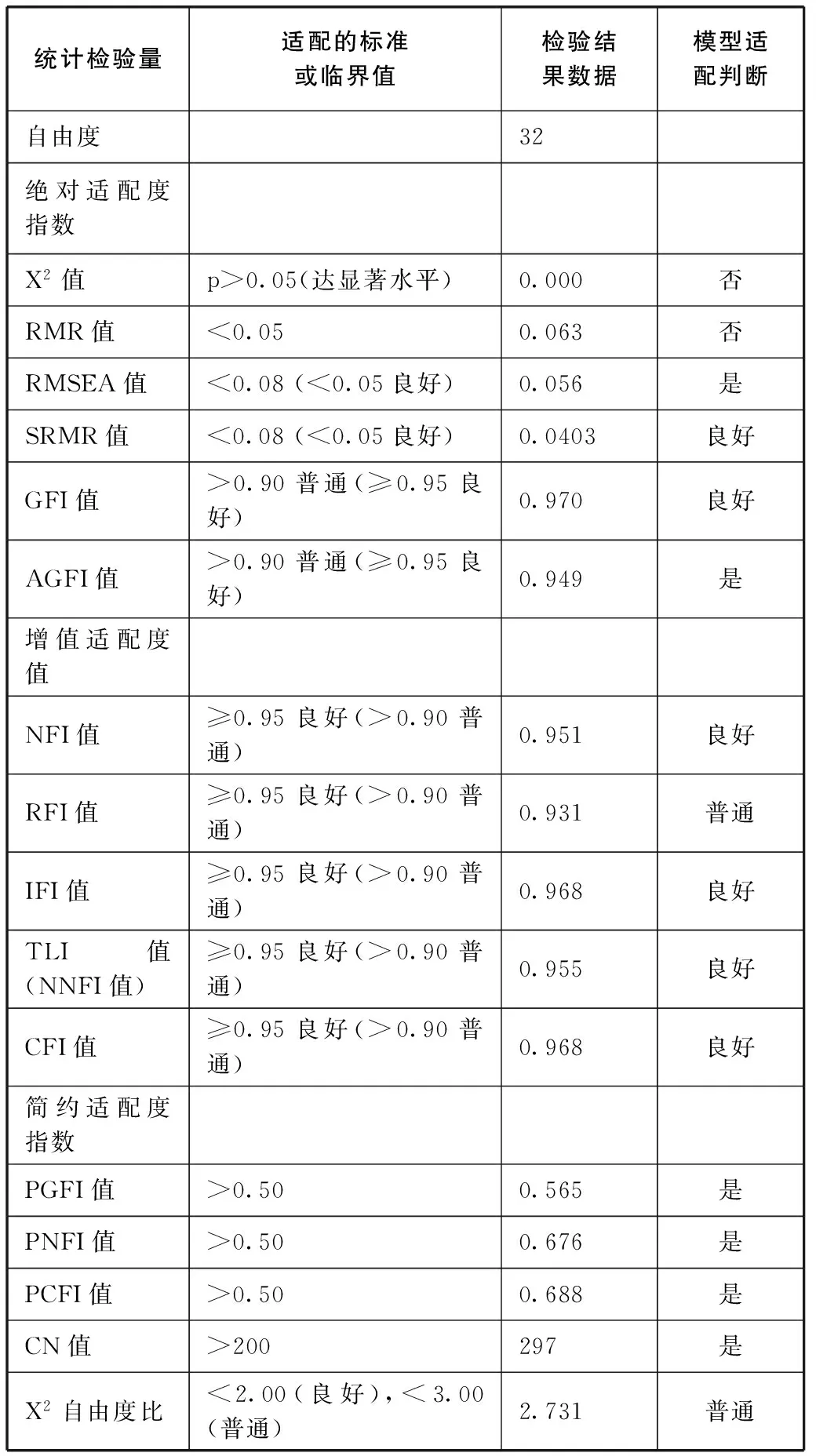
表7 焦虑量表三维度结构模型整体适配度检验摘要表
3.4 模型的聚敛效度与区别效度检验
若结构模型的整体适配度分析显示,假设模型与样本数据可以适配,表示根据观察数据推导的整体协方差矩阵Σ与依据模型推导的隐含总群体协方差矩阵Σ(θ)相等:Σ=Σ(θ),进一步要验证的是量表的聚敛效度与区别效度。
CFA模型的聚敛效度可从因素负荷量、潜在构念信度、平均方差抽取量等方面加以检核。一个因素构念对测量变量具有高的负荷量,表示这些测量变量可以有效反映一个共同因素。因素负荷量的评

表8 结构模型区别效度检验分析摘要表
①注:*ΔX2>3.841,达0.05显著水平,***ΔX2>10.827,达0.001显著水平。
鉴内容为因素负荷量路径系数均达显著(一般应达0.70以上)、因素负荷量数值要高于0.50。

AMOS一般采用卡方差异检验法来判别量表是否具有区别效度,具体通过比较构面间的协方差为自由估计参数和构面间的协方差限制为1两个模型的卡方值差异量是否达到显著水平来判断。卡方值差异量愈大且达到显著水平表示两个因素构念间的关系不是完全相关,说明两个因素构念是有区别的[17]。经验证的结构模型区别效度摘要详见表8,均达到0.001显著水平,说明三个因素间有良好的区别效度。
4 修订模型跨学校稳定性分析
当我们得到的假设模型与样本数据可以契合,可以进一步探究假设模型是否同时适配于此样本中不同学校、学科、性别、身份……的样本组别,比较结构模型中“检索困惑”、“环境不适”与“情感障碍”之间的路径关系对于不同的样本组别是否存在差异。其目的在于检验相似模型在不同群组受试者间的差异,以验证模型稳定效度与跨群组效度。
在群组分析中,我们进行了学科群组与学校群组的检验。关于SEM分析的样本数,“Gorsuch(1983)认为,因素分析中样本量至少应该达到100。Boomsma(1985)也建议,结构方程模型分析时,样本量最少应该大于100,被试多于200个更好。”[18]在学科群组分析中,学科分组样本数分别为工科472、文科400、理科281,样本数均在200以上,学科群组分析指标均达到适配标准,说明假设模型具有跨学科稳定性。学校群组分析,由于第二次测试六个参测学校样本数是按在校生比例确定的,耿丹学院有效问卷仅为97,北工大实验学院有效问卷仅为100,因此,学校群组分析中这两个学校的分析指标适配数据将会受到一定影响。
以学校群组分析为例,六个学校初始模型与群组初始模型的估计结果均为模型可以辨识收敛,模型评估结果的参数没有不适当解值。六个学校北京工业大学、北京航空航天大学、北京联合大学、首都师范大学、耿丹学院、北工大实验学院的初始模型卡方自由度比值分别为1.970、2.409、1.671、1.877、1.690、1.474,除北京航空航天大学达到<3.00适配标准外,其他学校均达到<2.00良好适配标准;群组初始模型适配度卡方自由度比值为1.850,也达到<2.00良好适配标准。
六个学校初始假设模型与多群组初始模型的绝对适配度指标,除耿丹学院RMSEA=0.087、AGFI=0.833、北工大实验学院AGFI=0.857未达标外,其他学校初始模型与群组初始模型均达到RMSEA<0.08、GFI>0.90、AGFI>0.90适配标准。
六个学校初始假设模型与多群组初始模型的增值适配度统计量见表9,其中:IFI、TLI、CFI均达到模型适配标准。NFI四舍五入后均能达到标准,RFI除耿丹学院、北工大实验学院外其它学校四舍五入后均能达到标准。群组初始模型五个增值适配统计量四舍五入后均达到标准。

表9 增值适配度统计
六个学校初始假设模型与多群组初始模型的简约适配度指数PGFI、PNFI、PCFI均达到>0.50适配标准。
“如果模型拟合指标中部分达到了较高的显著性,而其余指标没有,此时需要研究者仔细分析出现这一现象的原因。特别是针对那些不显著的指标、考察其实质含义,分析为什么它们不显著。只要有一定的逻辑和原因,这种情况也是可以接受的。”[19]学校初始模型少数学校适配指标不达标的主要原因应该是样本数≤100造成的。因此,考虑到分学校样本数量的关系,上述适配指标是可以接受的,可以说结构模型在不同学校群组具有一定的稳定效度,即具有跨群组效度。
只有通过EFA分析、CFA验证,确认经观察数据推导的整体协方差矩阵Σ与依据模型推导的隐含总群体协方差矩阵Σ(θ)相等,并经群组分析假设模型具有跨群组稳定效度的LAS,定量分析的数据才能体现LA真实状况。经过本地区验证数据拟合良好的LAS,用于其他地区LA分析仍然需要数据分析与验证,如果经观察数据推导的整体协方差矩阵Σ与依据模型推导的隐含总群体协方差矩阵Σ(θ)不相等,仍然需要重新修订假设模型。
5 对参测六所学校读者图书馆焦虑的测量比较
我们根据理论假设架构编制的预试问卷,经二次测试修订后得到一个包含“检索困惑”、“环境不适”、“情感障碍”3个潜在变量10个测量变量的焦虑量表,并通过多群组分析验证具有跨学校群组稳定效度。于是,我们应用此量表对参加项目的六所学校读者LA状况进行统计分析。量表共有10道题,采用利克特五点计分制,全部问题采用反向题(为避免读者在正、反向题选择答案时容易造成混乱、同为反向题数据分析时不需再进行反向转换),如:“当我遇到问题时,馆员不能给予有效解决”、“使用图书馆查找资料时,检索过程令我不知所措”,按 5分为“同意”、4分为“基本同意”、3分为“不置可否”、2分为“基本不同意”、1分为“不同意”,30分以下者为“不同意”、“基本不同意”或“不置可否”,31分以上者为“基本同意”或“同意”为有LA者。为确保统计的准确性参测人数为删除了有题项缺失值记录的数字,统计结果按有LA读者比例由低至高排列详见表10。

表10 北京高校LA测量统计表
测量结果显示六所学校都存在有LA的读者,有LA的读者占参测读者的比例从10.8%到40.9%。LA占比最低的为民办三本院校耿丹学院。分析其主要原因:第一,其在校生5700人,图书馆面积13000m2,图书馆生均面积2.28米/生,图书馆硬件条件能很好满足读者需求;第二,其读者对图书馆的需求相对其他学校存在一定差距。
“985”学校、211学校有LA者相对人数较少,说明“985”学校、211学校的图书馆建设、规模与学校整体发展需要相适应,能较好满足读者需求。
在校生人数较多、图书馆面积不足的学校情况相对严重。以LA占比最高的北京联合大学为例,其校本部馆舍面积8000m2,本部在校生1.3万人,图书馆生均面积0.615m2(普通高校图书馆生均面积标准为2.0 m2/生)。在抽样调查时,北京联合大学读者在“建议留言”一栏反映问题较为突出的有:学生占座、图书馆太吵、冬天室温低、馆员声音大、书车噪音大等等。分析其原因,与图书馆面积不足,采用室内天井式建筑结构,阅览座位密集,借还服务区与阅览区距离过近,动、静区不能有效间隔等因素有关,说明图书馆硬件不足、环境舒适度不高是北京联合大学读者产生图书馆焦虑的主要原因。其结果与我们通过SEM方法获得的结构模型是一致的,结构模型显示“环境不适”路径系数为0.57,“检索困惑”路径系数为0.33,“环境不适”相对于“检索困惑”对读者产生图书馆焦虑影响更大。另据了解,现北京联合大学图书馆新馆正在建设之中,2015年将投入使用。
实际测量结果显示,受试者所得LA分数统计与实际情况吻合并能合理解释受试者的心理特质,说明修正后的量表具有良好的建构效度。
6 结语
LA测试与分析结果表明,导致读者产生焦虑除个人因素“情感障碍”内因外,“环境不适”与“检索困惑”是主要外因。其中,测量变量hj5“读者违反规定现象普遍”的路径系数为0.73、因素负荷量为0.53。当图书馆资源处于紧缺时维持公平秩序至关重要,例如当图书馆阅览座位严重不足而读者占座现象严重时,管理人员的不作为或管理不力会让承载巨大考试压力和课业负担的学生倍感焦虑,这也是hj5成为“环境不适”潜在因素最适切测量变量的原因。“检索困惑”潜在因素因素负荷量最高的测量变量为js10“检索到图书索书号后,我不知道如何按照索书号找书”,其路径系数为0.80、因素负荷量为0.64,一般图书馆的索书号由分类号和种次号组成,各图书馆采取的分类法和种次排序法也不尽相同,大多数读者对此都是一头雾水,正是这些图书馆服务细节的瑕疵引起了读者的困惑,查找过程中的不顺利经历会让读者感觉使用图书馆并不容易,久而久之会失去信心不自觉地回避图书馆。LAS的结构模型和所有测量变量将成为图书馆改进服务的重要参考。图书馆要想解决这些问题,除了像面积严重不足问题要靠学校层面的重视与支持外,工作重点应放在环境建设、检索服务、管理方式等方面上。
环境建设方面,应改变过去阅览室大一统的单一、密集模式,采取动、静分区,建立分安静等级的阅览区;同时,也要注重满足现代读者除学习之外的交流、休闲、娱乐等多种需求,建立规模不一的研讨间、多媒体视听室、舒适的休闲区等;营造多样化、人性化的人文环境和艺术氛围,让读者到图书馆有如到家一样,能放松心情、满足不同需求。
检索服务方面,要从读者角度出发,让不熟悉图书馆的读者能以最便捷的方式解决需求。加强图书馆用户教育、充分利用网络教学、让读者学会如何充分利用图书馆;采用合理的馆藏布局,例如,以主题分区,提供书刊合一、中外文合一、纸本与数字资源相结合的一站式服务,使读者可以在一个区域内获得其所需主题的所有图书馆能提供的文献;采用先进的馆藏管理技术,例如,应用无线射频技术RFID进行馆藏管理,使读者找书时不需要了解图书分类法和种次号;提高馆员业务素养,有效解答读者提问、有效帮助读者。
管理方式方面,实践证明:大量应用先进管理手段,可以使图书馆员从繁重的重复操作中解脱出来,从而有利于提高服务质量、提升管理水平。比如,以北京工业大学图书馆为例,运用自助借还设备,年自助借还量可以占年总借还量的80%以上;运用阅览室座位管理系统可以有效解决读者占座问题,有效弥补因管理不足而给图书馆造成的负面影响、有效降低读者在情感上产生焦虑的可能性。
1 袁琳,吴汉华.国外图书馆焦虑研究综述[J].情报科学,2008(2):311-315
2 徐迅,宋志强.国外图书馆焦虑研究进展[J].图书情报知识,2011(4):40-47
3 王细荣.《图书馆焦虑:理论、研究和应用》的译读与思考[J].图书情报工作,2014, 58(9):143-147
4 贺伟,Doris J.Van Kampen.图书馆焦虑量表的修订及信效度检验[J].图书情报知识,2008(3):52-56
5 宋志强,薛玉,赵微.图书馆焦虑量表的构建与实证分析[J].图书情报工作,2011,55(15):77-81
6 罗伯特.F.德维利斯.量表编制:理论与应用[M].重庆:重庆大学出版社,2010:63
7 吴明隆.问卷统计分析实务—SPSS操作与应用[M].重庆:重庆大学出版社,2010:207
8 同7,192
9 同7,194
10 同7,268
11 同7,232
12 吴明隆.结构方程模型—Amos实务进阶[M].重庆:重庆大学出版社,2013:9
13 同12,12-13
14 同12,38
15 同12,202
16 同12,61-63
17 同12,80-95
18 吴瑞林.基于结构方程模型的测验分析方法[M].北京:北京大学出版社,2013:103
19 林嵩.结构方程模型原理及应用[M].武汉:华中师范大学出版社,2008:127
Measurement and Analysis on the Library Anxiety of University Students in Beijing—Based on Revision and Verification of Library Anxiety Scale
Wan Yunfang Jia Shumin Feng Sujie Shen Rongrong Wu Xuezhi Shen Xin Guo Xiaozhen Li Si
In order to measure and analyze library anxiety of university students in Beijing, the following six institutions have been selected as sample objects: Beihang University, Beijing University of Technology, Capital Normal University, Beijing Union University, Geng Dan College and The Pilot College of BJUT. By adopting structural equation modeling, revision and verification have been carried out on the basis of current library anxiety scale, on which statistics and analysis have been finished aiming at library anxiety of the above six institutions.
Library Anxiety;Measurement;Library Anxiety Scale;Revision;In the Beijing Area;The University Library
北京工业大学图书馆,北京,100124
北京工业大学图书馆,北京,100124
北京工业大学图书馆,北京,100124
北京航空航天大学图书馆,北京,100191
首都师范大学图书馆,北京,100037
北京联合大学图书馆,北京,100101
北京工业大学实验学院图书馆,北京,101101
耿丹学院图书馆,北京,101301
2014年10月20日
*通讯作者:万云芳,ORCID:0000-0003-2857-0243,wanyunfang@bjut.edu.cn。
猜你喜欢
教育观察(2020年20期)2020-09-01
中国非营利评论(2019年1期)2019-06-18
重庆与世界(教师发展版)(2018年8期)2018-09-04
山西青年(2017年6期)2017-03-15
中国卫生标准管理(2015年1期)2016-01-15
心理学探新(2015年4期)2015-12-10
心理学探新(2015年4期)2015-12-10
心理学探新(2015年4期)2015-12-10
外语教学理论与实践(2015年1期)2015-06-11
集美大学学报(教育科学版)(2015年5期)2015-02-28
