
异构环境下Hadoop 推测执行算法
2015-11-26 03:00:26祁鹏年郝君慧许丰平
计算机与现代化 2015年8期
祁鹏年,朱 晋,郝君慧,许丰平
(长沙理工大学经济与管理学院,湖南 长沙 410114)
0 引言
Hadoop 数据节点在降速的过程中,尽管系统依然可以运行,但任务执行的速度很慢[1]。这样虽不会影响任务执行的准确性,但以牺牲整体性能为代价。Hadoop 推测执行算法,在同构环境下通过提高任务执行的效率来有效地提高整体性能,但在异构环境下反而会降低系统性能[2]。人们希望即使在异构环境下,Hadoop 推测执行算法照样可以提高系统性能。本文重点研究Hadoop 推测执行算法在异构环境下所表现出的性能问题以及对应的改进算法。
1 Hadoop 推测执行算法
1.1 基本原理
MapReduce 实现了作业的分割,将待执行的作业分成一些小分片,然后执行每一个小分片,通过作业执行的整体时间小于顺序执行时间来提高作业执行的效率。当MapReduce 接收到任务时,这些任务的执行过程对于用户是完全透明的[3]。在某些分片执行过程中总会存在可用但执行效率较低的数据节点,这类分片被称为掉队者[4]。为了尽可能缩短计算时间,提高整体性能,MapReduce 会启动其他运行效率较高的数据节点来处理掉队者。MapReduce 的这种优化策略被称为推测执行[5](Speculation Execution),被推测执行的任务叫做后备任务。
1.2 任务处理流程
1)用(0,1)之间的数作为任务进度数,该数用于表示任务的进度情况。其中,Map 进度数和Reduce进度数是Hadoop 推测执行算法的2 种进度数。在Map 阶段,执行进度=已完成的数据/输入的数据[6]。而在Reduce 阶段将任务分为输入数复制阶段、排序阶段、归并阶段,每个阶段各占1/3 的进度。每一个任务阶段都会计算出一个进度数来表示任务的完成情况。
2)由设置的阈值来判断掉队者。
当开始执行所有任务时,JobTracker 会分别计算出Map、Reduce 的进度数,设置平均进度数值减0.2为阈值[7]。若某个任务同时满足进度数低于阈值并且至少执行1 分钟这2 个条件,则判断该任务为掉队者。
3)执行后备任务。
JobTracker 会启动一个效率较高的节点来执行该后备任务,若其中一个先执行完,则另一个就被杀死。
1.3 存在的问题
同构环境中推测执行算法默认满足的条件[8]:
1)每一个节点的处理速度相同。
2)在整个运行中,每一个任务的运行速率相同。
3)后备任务的运行不会产生时间和资源上的消耗。
4)Map 阶段,执行进度=已完成的数据/输入的数据。Reduce 阶段将任务分为输入数复制阶段、排序阶段、归并阶段,每个阶段各占1/3 的进度。
5)每一个作业都是批量完成的,所以进度数较小的任务判定为掉队者。
只要满足了以上条件,在机群同构环境中该推测执行算法可以有效提高整体性能,将当前响应时间提高44%。但面对大量存在的异构机群,该策略的高效性将不复存在。甚至会造成以下后果[9]:
1)造成节点效率不佳的原因有很多,导致任务执行效率差异很大。
2)一台计算机上运行若干个虚拟机,在这些虚拟环境中使用一个固定的阈值来判断掉队者,会导致同一时刻出现大量的掉队者,出现竞争资源和消耗时间的状况。
3)异构环境中的节点可能存在差异,执行任务时也可能不是一个批次,执行过程中可能会出现旧批次的某个任务比新批次的进度数要高,但是执行速度却比新任务慢,而在调度后备任务时可能会先调度新任务,造成有些掉队者任务一直无法执行。
所以,该策略在异构环境中会导致过度重复执行掉队者任务,使得整体性能比没有使用该策略时的性能更差。因此,Hadoop 推测执行算法在同构环境下可以发挥优势,但在异构环境下可能无法判断真正的掉队者。
1.4 异构环境下的解决方案——SALS 算法
为了弥补Hadoop 推测执行算法在异构环境下的诸多弊病,有人提出了自适应负载调节算法(SALS),它可以在一定程度上提高Hadoop 性能[10]。其核心思想如下:
1)利用公式(1)求得此刻所有运行任务的剩余时间,并将其存放在TaskQueue 中。

其中,PS 指历史进度数,t 为历史运行时间,而PR=PS/t,为任务执行的历史平均速度。
2)利用公式(2)求得阈值(NodeThreshold),将每一个任务请求节点的进度值与该阈值相比较,小于阈值的节点存放到Queue 队列中。

3)利用式(3)、式(4)分别求出系统平均负载和当前系统负载。并利用式(5)求得当前系统可计算后备任务数量sTask(其中,blocksize 是每一个Map 任务所处理的数据量)。

4)从TaskQueue 中读取sTask 个后备任务,交给Queue 队列中的前sTask 个任务执行。
由以上可知,该算法采用了更精确的方式来判断掉队者并且充分考虑了系统负载的情况[11],利用当前负载量自动调节后备任务的数量,来实现系统的负载均衡。但依然存在问题,如将所有任务都放在TaskQueue 中会造成资源的浪费、忽略Reduce 任务,造成系统负载不准确、仅采用Map 处理的数据量作为衡量系统负载的标准等问题[12]。
2 Hadoop 推测执行算法优化
由于Hadoop 推测执行算法不适合应用在异构环境下,而SALS 算法在异构环境中也存在诸多问题[13],如:判断掉队者时浪费了大量的内存空间且存在系统负载均衡问题。所以本文改进了Hadoop 推测执行算法,简称为ESE(Enhanced Speculation Execution)算法,ESE 算法采用了不同的掉队者判断方法和新的负载均衡算法。利用当前系统负载量自动分配后备任务执行,以此均衡系统负载。
2.1 ESE 算法的核心思想
跟SALS 算法利用剩余时间判断掉队者一样,推测执行算法利用进度数判断异构环境下的掉队者也存在一定的盲目性。但是ESE 算法依然采用了Zaharia 利用历史平均剩余完成时间来估算剩余时间的思想。与SALS 算法不同点在于,该算法会将任务剩余时间大于20%的任务标识为掉队者。任务剩余时间通过公式(1)求出。为了防止任务数量过多时,使用SALS 算法将所有任务信息都存储到TaskQueue中,造成内存浪费,并且受Hadoop 推测执行算法的启发,ESE 算法仅将Tleft(任务剩余时间)大于20%的任务信息存到TaskQueue 中,有效减少了内存开销。根据请求任务节点的阈值(NodeThreshod),将其分为快节点和慢节点,而改进后的ESE 算法会选择性能较好的快节点执行后备任务,使得掉队者获得比原来更快的执行速度。利用Zaharia 的LATE 算法[14],取节点平均速度的1/4 作为阈值,该值可以使用式(6)求得:

其中n 为节点个数,m 指每一个节点已经完成和正在执行的任务的总和。PS[i][j]表示第i 个节点上,第j 个任务的历史平均进度值。Task[i][j]指第i 个节点的第j 个任务,值一般设置为1,对阈值没有影响。
式(7)可求出每一个节点的进度水平:
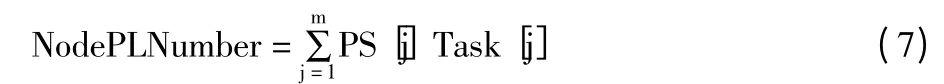
其中,m 是该节点上的任务总和(m=已完成任务数+没有完成的任务数)。Task[j]则是该节点上的某个任务,其值也可以设置为1。如果满足NodePLNumber >NodeThreshold,即为快节点否则为慢节点。
系统负载量一般指的是,当系统同时运行Task和Reduce 时的负载量。用Map 和Reduce 任务的数量值来确定系统的负载量,分别记为TaskNumber、ReduceNumber。故在t 时刻系统需要处理的负载量为:

系统平均负载是由从作业开始执行到此刻已经完成和正在执行的数据量的总和的平均值,由式(9)求出。

系统在某时刻的负载量低于系统平均负载量时,允许申请新节点,否则不允许,直至低于系统平均负载量为止。
2.2 改进后算法的执行流程
1)当同时有多个节点发出请求时,首先要将每一个节点的进度水平与阈值进行比较,进而忽略慢节点的请求。然后判断快节点是Map 请求还是Reduce请求,随后加入到对应的MNodeQueue 或RNode-Queue 队列中并按照节点进度排序。C1、C2 分别用于2 个队列的计数。
2)获得请求任务分配的信息后,根据公式计算此刻正在运行的所有任务,大概估算每个任务的剩余时间,将剩余时间大于0.2 的任务按剩余时间排序并根据任务类型放入MTaskQueue 队列或RTaskQueue队列中。
3)计算某一时刻的系统负载值L 和平均负载值,若L 小于平均负载值,执行步骤4),否则一段时间后继续执行步骤3)。
4)计算sTask 的值(sTask=系统负载-系统平均负载),以及Map 可以分配到的任务数量x=× sTask 和Reduce 分配到的任务数量y=×sTask。将MTaskQueue 的前x 个任务分配给MNodeQueue 队列中的前x 个节点,而RTaskQueue也是同理,并分别更新队列中的信息。
3 ESE 算法的实验证明
本文通过实验证明新Hadoop 推测执行算法的可行性。在异构环境下搭建分布式平台,整个集群由8个节点组成,其中一个节点为主控节点(Master),而剩余节点为工作节点(Slave)。在该配置下对改进后的新算法,原推测执行算法以及SLAS 算法进行性能比较,由此得出一些重要的结论。
3.1 实验环境搭建及参数配置
将这8 个节点组成一个小型局域网,相关参数如表1 所示。
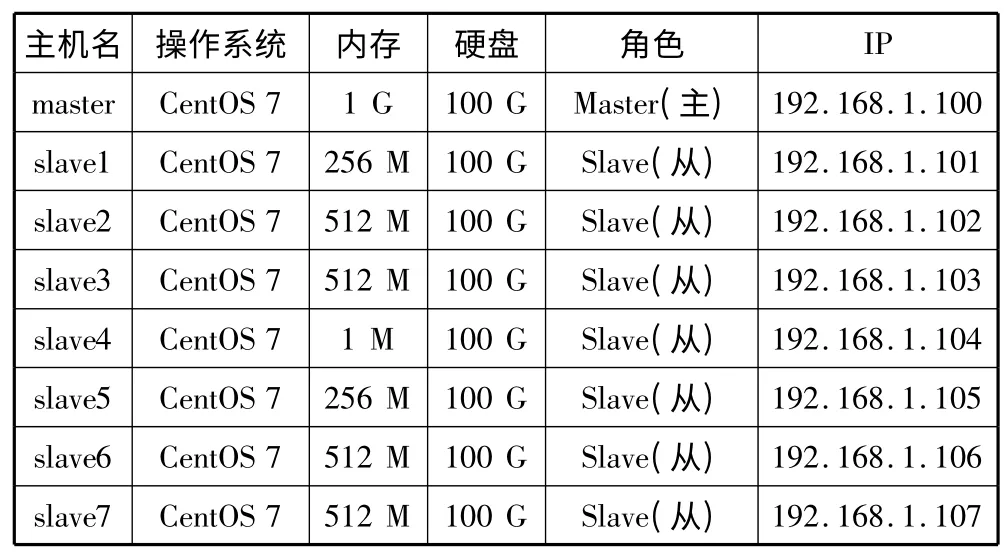
表1 集群相关参数
安装完操作系统、JDK 等相关软件之后再安装Hadoop 并实现相应的配置。首先为每一个节点创建一个用户组hadoop-user,并在该用户组下创建Hadoop 用户。然后修改每个节点的/etc/hosts 目录并在NameNode 节点的配置文件中添加集群中所有节点的IP 地址和主机名。最后需要配置SSH 以及在所有的电脑上完成Hadoop 的配置。
3.2 实验结果分析
本实验借助Hadoop 自带的字数统计程序,对改进后的推测执行算法、SALS 算法、Hadoop 推测执行算法以及不使用推测执行算法在实验中的响应时间以及每个节点的负载情况进行对比。基本思想是:先统计输入文件中的所有单词数目信息,然后汇总所有的统计结果[15]。本实验将3 个job 同时提交,并保证其他所有的参数都相同,得到了图1 的实验结果。

图1 异构环境下各算法性能对比
由图1 可知:在异构环境下Hadoop 自带的推测执行算法处理数据的能力远低于SALS 算法和改进后的推测执行算法甚至低于不使用推测执行时的数据处理能力。这一事实说明Hadoop 推测执行算法不适合应用于异构环境中[16]。除此之外,还可以得知改进后的Hadoop 推测执行算法在处理job1、job2、job3 时所耗费的时间明显比SALS 算法少。这是因为将任务写入TaskQueue 中时,有一部分经过判断不需要写入队列,因此节省了操作时间。虽然改进后的Hadoop 推测执行算法相比于SALS 算法响应时间只有小部分提高,但整体来看比SALS 算法更高效。
根据实验结果,进一步对比分析了各个节点在执行任务中所需的时间,如图2 所示。
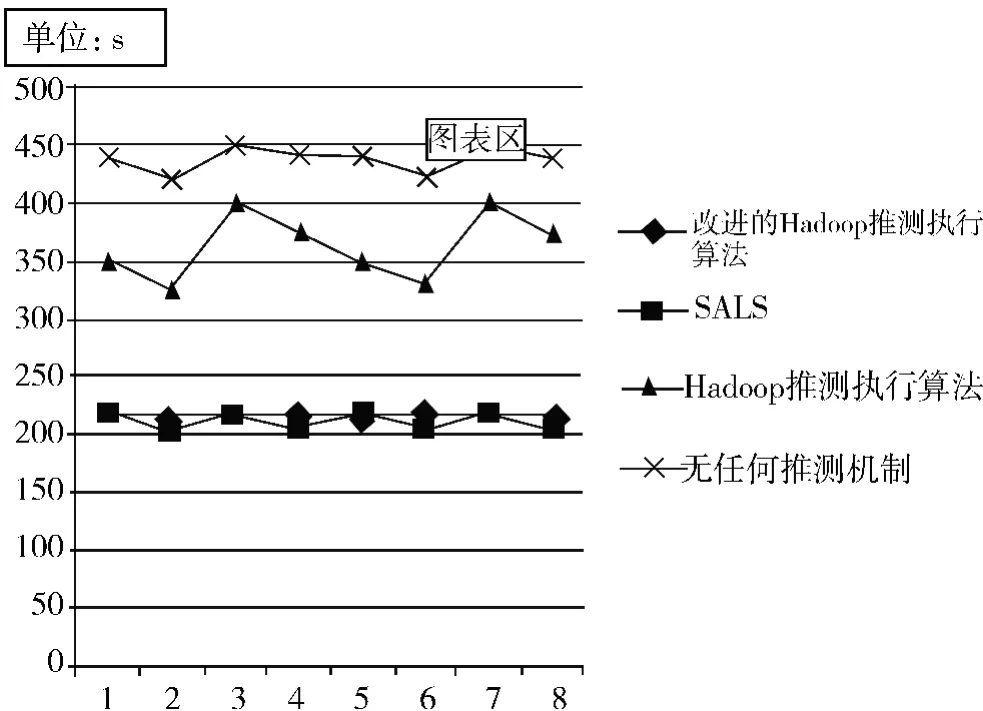
图2 各个节点在job3 上的执行时间对比
由图2 可知:虽然job3 执行的时间是固定的,但该任务在每一个节点上的执行时间幅度较大,导致系统负载不均衡,使得有些节点任务过重而有些节点过早完成。使用Hadoop 推测执行算法与不使用相比较得知,不使用时尽管运行时间较长但各节点基本同步,所以比使用该算法有更好的负载均衡。这进一步证明,异构环境下不适合启用推测执行算法。此外,比较改进后的推测执行算法与SALS 算法,可以知道二者作业执行的时间相同,但在每个节点上执行的时间上下波动,改进后的算法比SALS 更平稳,这就说明改进后的Hadoop 推测执行算法在解决系统负载均衡方面明显优于SALS 算法。同时也证明了改进后的推测执行算法确实具有高效性。
4 结束语
本文提出了一种适用于异构环境下的Hadoop 推测执行算法,该算法避开了原算法在异构环境下的种种弊端,用一种全新的机制实现了推测执行策略;并搭建了分布式平台验证新算法的性能,结果进一步证明了新算法的合理性和可行性。本文所有结论皆由实验验证,具有一定的科学依据。
[1]Apache Software Foundation.Hadoop 0.20.2 API[DB/OL].http://hadoop.apache.org/common/docs,2015-03-01.
[2]Tom White.Hadoop 权威指南[M].周敏奇,王晓玲,译.2 版.北京:清华大学出版社,2011.
[3]陈国良.并行计算[M].北京:高等教育出版社,2003.
[4]陆嘉恒.Hadoop 实战Hadoop Action[M].北京:机械工业出版社,2011.
[5]Anderson T E,Culler D E,Patternson D A.A case for NOW[J].IEEE Micro,1995,15(1):54-64.
[6]李鑫.Hadoop 框架的扩展和性能调优[D].西安:西安建筑科技大学,2012.
[7]Chuck Lam.Hadoop in Ation[M].Manning Publications,2010.
[8]曹英.大数据环境下Hadoop 性能优化的研究[D].大连:大连海事大学,2013.
[9]赵书兰.典型的Hadoop 云计算[M].北京:电子工业出版社,2013.
[10]韩晶.大数据服务若干关键技术研究[D].北京:北京邮电大学,2013.
[11]张密密.MapReduce 模型在Hadoop 实现中的性能分析及改进优化[D].成都:电子科技大学,2010.
[12]沈案.异构分布式系统中基于DVS 的节能调度算法研究与实现[D].长沙:湖南大学,2013.
[13]冯艳红.实时多任务集成调度算法的研究[D].保定:华北电力大学,2005.
[14]王峰.Hadoop 集群作业的调度算法[J].程序员,2009(12):119-121.
[15]周锋,李旭伟.一种改进的MapReduce 并行编程模型[J].科协论坛(下半月),2009(2):65-66.
[16]孙广中,肖锋,熊曦.MapReduce 模型的调度及容错机制研究[J].微电子学与计算机,2007,24(9):178-180.
[17]曹廷.一个异构多核调度算法及其实现[D].西安:西安电子科技大学,2011.
[18]余利华.分布式数据存储和处理的若干技术研究[D].杭州:浙江大学,2008.
[19]王意洁,孙伟东,周松,等.云计算环境下的分布存储关键技术[J].软件学报,2012,23(4):962-986.
[20]李建江,崔健,王聃,等.MapReduce 并行编程模型研究综述[J].电子学报,2011,39(11):2635-2642.
猜你喜欢
化学工程师(2023年1期)2023-02-17 15:09:48
小学教学研究(2022年5期)2022-04-28 21:29:36
汽车工程师(2021年12期)2022-01-17 02:29:50
现代畜牧科技(2021年4期)2021-07-21 06:12:56
理化检验-化学分册(2020年12期)2021-01-26 00:41:38
冰雪运动(2020年2期)2020-08-24 08:34:22
中国果树(2020年2期)2020-07-25 02:14:28
上海农业科技(2019年1期)2019-02-22 01:51:28
电信科学(2016年11期)2016-11-23 05:07:56
通信电源技术(2016年6期)2016-04-20 06:21:36
