
社区问答系统中问题推荐机制
2015-11-26 03:00:28蒋宗礼李立新
计算机与现代化 2015年8期
蒋宗礼,李立新
(北京工业大学计算机学院,北京 100124)
0 引言
随着信息技术和互联网的发展,人们能接受、处理和利用的信息范围越来越广,信息量也越来越大。然而随着可用数据资源呈爆炸式增长,大量冗余信息严重干扰了人们对所需信息的正确选择和准确分析,降低了信息使用效率。准确、快速地获取所需信息越来越难,所花时间也越来越多。虽然以百度、谷歌等为代表的传统搜索引擎,在很大程度上为人们从海量数据中找到所需信息提供了极大便利,但难以满足一些用户的信息需求,这导致了基于社区问答模式的发展。百度知道、Yahoo!Answer、知乎等是现在颇受欢迎的基于搜索的互动式知识问答系统,它们充分利用社区用户知识来满足广泛的信息需求。
从目前发展形势来看,社区问答系统尽管吸引了大量用户参与,但仍有许多用户提出的问题没有得到答案。在已解决的问题中,也有相当一部分答案并不能让提问者满意。造成这些现象的原因之一在于虽然有大量用户存在,但即便是有经验的用户,也很难从大量新提交的问题中找到感兴趣并有能力解答的问题。用户通常需要浏览问题的分类结构,从成千上万的开放问题中找到感兴趣的问题,这一耗时费力的过程打消了许多用户参与的积极性。挖掘潜在回答问题的用户,进行有效合理的问题推荐,及时准确地回答系统中用户不断提出的大量新问题,对社区问答系统的发展有着重要意义。
现有的问题推荐算法,大多数只以用户兴趣和权威性作为依据,忽略了用户活跃度,而这一点却是决定该用户成为某一问题最佳回答者的关键。本文通过分析用户活跃指数,并将其融入到问题推荐算法中,以改善推荐效果。
1 用户活跃度表示方法
在社区问答系统问题推荐机制中,除用户对被推荐问题的兴趣之外,用户在系统中的行为活跃度也影响着问题推荐的准确性。一个用户越活跃,对知识的发布和传递越有促进作用,越可能愿意去回答其他用户所提出的、自己感兴趣且擅长的问题。
用户活跃度可以定义为用户各种行为发生的频次之和[1-3],考虑到用户之前活跃并不表示现在依然活跃,用加权和更为恰当。把每一位用户每天的行为看成一个数据流,本文采用一种基于衰减窗口[4]统计的方法来计算用户行为活跃度。
对于最新的元素赋权值为1,然后随着时间的向前推移,权值按照一定的比值不断衰减。令数据流中的元素为a1,a2,…,at,其中a1是最先到达的元素,而at是最新的元素。令c 为一个很小的常数,称为衰减常数。那么,该数据流的指数衰减窗口定义为:

由定义可知,流中元素的权重值取决于距离最新元素的远近,距离时间越远则其权值越小。
社区用户活跃度计算可分为以下步骤:
1)行为数据流统计。
在社区问答系统中,用户参与的行为主要包括提出问题、回答问题和评价问题答案等。多个用户会产生多个行为数据流,所以对每个用户的行为数据流进行统计处理后可得到用户行为矩阵。一般将一天的24 小时分成若干段,统计每个用户在各个时间段提问、回答、评价3 种行为发生的次数。表1 为把一天24 小时分为3 个时间段统计的结果。

表1 某用户在某天的行为次数统计
2)建立用户行为矩阵A(u)。

3)计算用户活跃度矩阵S(u)与用户活跃度Bt(u)。
通常情况下,行为越近,对用户当前的活跃度贡献越大,所以行为发生的时间越晚,权值越大,反之则权值越小,可以利用衰减窗口的方法来计算系统中用户的活跃度。依据某用户u 以时间t 为参数的行为矩阵At(u),用户u 从开始日期(t=1)到结束日期(t=n)所有的行为看作一个矩阵流A1(u),A2(u),…,At(u)。根据衰减窗口定义,给定衰减常数c,此数据流的衰减窗口为:

①用户活跃度矩阵St(u)代表了用户u 在社区问答系统中的一般活跃程度;
②用户活跃度向量Sj(u)为St(u)第j 行元素之和,表示用户u 从开始到结束第j 时段的行为活跃度;
③用户活跃度Bt(u)=,表示用户u 从开始到结束为止的活跃度。
2 融入用户活跃度后的问题推荐
2.1 社区用户兴趣建模
准确地描述和表示用户和用户兴趣对提高问题推荐效率有着非常大的主导作用。潜在狄利克雷分布模型(Latent Dirichlet Allocation,LDA)[5]是文本挖掘研究中较为流行的一种基于非监督学习技术的主题模型。
本文使用与潜在狄利克雷分布模型类似的基本思想对社区用户兴趣度进行建模,并将每个用户的兴趣用提取的潜在主题分布表示。在基于主题的用户兴趣模型中,系统中每个用户都会根据自己感兴趣且擅长的主题选择相关问题进行回答。因此本文将每位用户参与过的问题及答案的文本档案视为潜在语义主题上的随机混合,每个潜在主题表示为在词语上的分布。用户兴趣主题模型的结构如图1 所示。

图1 用户兴趣主题模型的结构
图1 中q 和Uq分别表示一个问题和用户u 回答的问题集合;w 是问题q 中的词语,z 是与问题q 相关的潜在主题;θ 表示文档—主题分布,φ 表示主题—词汇分布(T 所有主题集合),θ 和φ 是模型中主要的变量,都是多项式分布的参数;α 和β 分别是θ 和φ的先验分布,均为Dirichlet 分布。
用户兴趣主题模型的产生分为2 个随机过程,第一个针对潜在主题词语的产生;第二个对每一个用户从问题到主题,主题再到词语的产生。具体如下:
1)从狄利克雷先验分布β 中取样生成主题z(z∈T)的词语分布φ;
2)从狄利克雷先验分布α 中取样生成某用户u的主题分布θ;
3)从主题的多项式分布θ 中取样生成Qu(用户u 的历史问答集合)中某个词汇的主题z;
4)从词语的多项式分布φ 中采样生成词语w。
通过反复迭代得到潜在主题在用户问答档案中的概率分布矩阵和词语在潜在主题上的概率分布矩阵。
用户所参与的历史问答信息很好地反映该用户的兴趣度所在,而用户在回答问题时更倾向于选择自己感兴趣的主题。因此,用户对未解决问题的感兴趣程度E(u,q)可以较准确地表示该用户回答此问题的可能性大小。换言之,就是通过计算用户u 能回答问题q 的条件概率P(u|q),即:

其中w 表示词语,V 表示所有词语的字典集合。P(w|q)表示词语w 和问题q 的相似度,按照公式(3)计算,代入公式(2)得公式(4)。

其中z 表示潜在语义主题,T 表示所有潜在主题集合,条件概率P(u|z)和P(z|w)可从用户兴趣模型中计算得出。
2.2 基于用户兴趣和活跃度的问题回答者推荐策略
给定用户集U={u1,u2,…,um},问题qr∈Q={q1,q2,…,qn},计算用户兴趣和活跃度,对用户进行评价排序,据此推荐适当的用户去回答新问题qr,即:

依据R(ur,qr,t)评分大小降序生成对应用户列表,把未解决问题推荐给评分较高用户。其中E(ur,qr)为用户ur对问题qr的兴趣度,Bt(ur)表示对用户ur 活跃度的归一化处理值。λ∈[0,1]是权重系数,表示用户活跃度对用户综合推荐评分的影响情况。
3 实验与分析
3.1 实验系统模型设计
本文实验系统的工作流程如图2 所示。
1)网页获取:由于目前问题推荐缺少标准的数据集,所以需从现有问答社区中抓取网页内容。本文选择的是Yahoo!Answers 上的网页数据。
2)网页内容抽取:网页内容抽取模块需完成从获取的网页内容中抽取有关问题、答案和用户的文本信息,形成结构化数据。
3)用户信息提取:从网页结构化数据中抽取用户,依据每个用户的历史数据生成所需的该用户的档案文件及行为统计表。
4)用户兴趣计算:将用户档案文件作为输入,按照用户兴趣主题模型,发现用户档案文件中的潜在语义主题。通过模型中反复迭代计算,获取每个用户问答档案文件中兴趣在潜在语义主题上的分布和潜在语义主题在词语上的概率分布。每个用户的档案文件以潜在语义主题上的分布来表示。
5)用户活跃度计算:根据用户行为统计表,建立对应的用户行为矩阵,由此计算该用户的活跃度指数并进行归一化处理。
6)问题推荐:问题推荐模块是综合用户兴趣度、活跃度的评分结果,生成推荐用户列表。
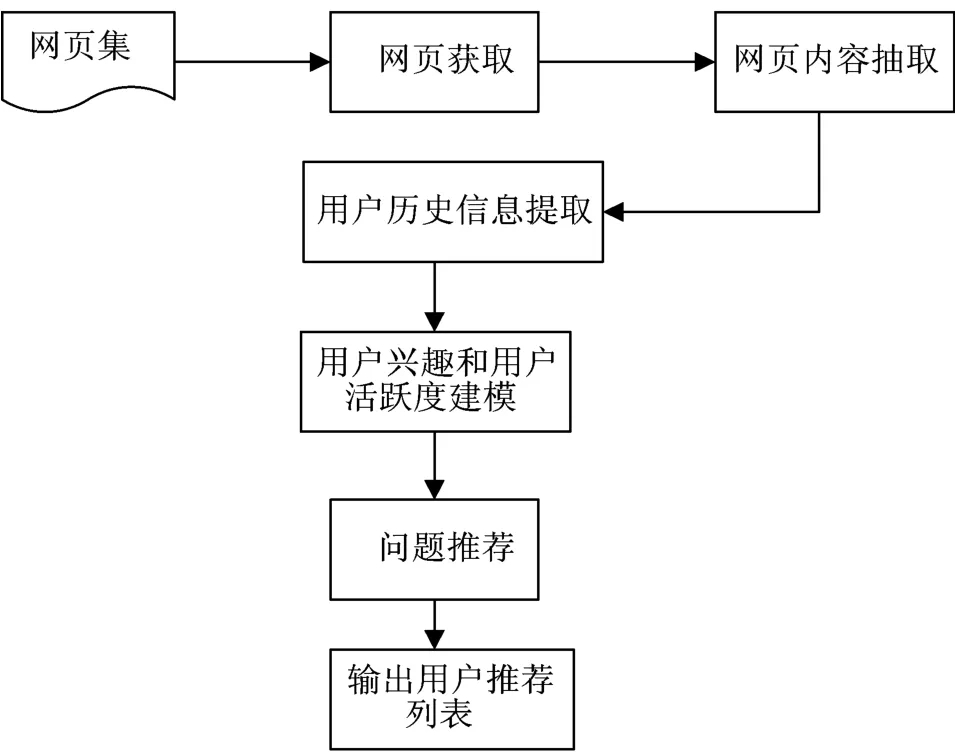
图2 实验系统工作流程图
3.2 实验数据与评价指标
本文实验数据来自社区问答系统Yahoo!Answers[6],共包含216 560 个问题和对应的6 130 801个答案,涉及用户171 656 个。数据集中的所有数据都进行了去除停用词和词根的还原操作。首先从问答数据中获取每位用户各自的历史问答数据文件,然后将问答数据按时间先后顺序划分,前80%的数据视为训练集,后20%的数据作为测试集。
衡量一个推荐算法的性能好坏,有多种测评方法和角度[7-8],本文采用2 种不同的评估标准来进行实验验证:平均准确率(Mean Average Precision,MAP)和前N 个数据的精度(记为P@N)。
3.3 实验参数设置
用户兴趣模型共有6 个参数:狄利克雷先验分布α 和β,用户—主题多项式分布θ,主题—词汇多项式分布φ,潜在语义主题个数NT和模型重复迭代计算的停止条件。预先设定潜在语义主题数为100,为了简化参数估计的步骤,采用Zhou 等人[9]在研究中的实验设计方案,设定先验值α=50/NT,β=0.05。对于参数α 和β,本文通过吉布斯采样(Gibbs Sampling)方法[10]进行估计,迭代计算的停止条件为最大迭代次数2 000。
在计算用户活跃度时,将衰减常数c 记为0.05。
3.4 实验结果分析
本实验通过对加入用户活跃度的前后结果进行对比来验证分析。分别令公式(5)中的λ=0.1,0.2,…,0.6 进行计算,得出在λ=0.2 时实验效果最佳,如图3 所示(其中横坐标表示2 种推荐算法的不同评估标准,纵坐标是相应评估标准的数值)。

图3 实验结果对比柱状图
从图3 中可以看出,在用户兴趣模型的基础上加入用户活跃度信息后,算法的平均准确率和前1、5、10 个推荐结果的准确率均高于只考虑用户兴趣的推荐算法,获得了更好的性能。由此可以证明,加入用户活跃度因素后问题推荐算法效率有一定提高。
实验结果表明,单方面只考虑用户兴趣的问题推荐算法是不完善的,需要综合其他影响推荐效果的有效因素,本文为此提供了一个简单的思路和实例。用户活跃度的加入可以改善推荐性能,但是该算法仍然存在不足,如用户不同行为种类对活跃度表示的影响和融入用户兴趣的计算方法。这些都是在未来的研究工作中需要进一步改进的。
4 结束语
用户交互式问答社区已经成为信息获取和知识分享的重要媒介,而问题推荐机制则是提问者与回答者之间的纽带,对社区问答系统未来的发展起着很大的促进作用。本文利用用户的历史问答行为来估算用户的兴趣度和活跃度,并由此优化问题推荐算法。实验结果表明本文方法是有效的。
[1]康书龙.基于用户行为及关系的社交网络节点影响力评价[D].北京:北京邮电大学,2011.
[2]王彪.社交网络中的用户影响力分析[D].哈尔滨:哈尔滨工业大学,2012.
[3]邓夏玮.基于社交网络的用户行为研究[D].北京:北京交通大学,2012.
[4]Cohen E,Strauss M J.Maintaining time-decaying stream aggregates[J].Journal of Algorithms,2006,59(1):19-36.
[5]Blei D M,Ng A Y,Jordan M I.Latent Dirichlet allocation[J].The Journal of Machine Learning Research,2003,3:993-1022.
[6]Yahoo.Yahoo!Answers[EB/OL].http://answers.yahoo.com,2015-03-01.
[7]Celma O,Herrera P.A new approach to evaluating novel recommendations[C]// Proceedings of the 2008 ACM Conference on Recommender Systems.2008:179-186.
[8]刘建国,周涛,郭强,等.个性化推荐系统评价方法综述[J].复杂系统与复杂性科学,2009,6(3):1-10.
[9]Zhou Ding,Bian Jiang,Zheng Shuyi,et al.Exploring social annotations for information retrieval[C]// Proceedings of the 17th International Conference on World Wide Web.2008:715-724.
[10]Griffiths T L,Steyvers M.Finding scientific topics[C]//Proceedings of the National Academy of Sciences of the United States of America.2004,101:5228-5235.
[11]张中峰,李秋丹.社区问答系统研究综述[J].计算机科学,2010,37(11):19-23.
[12]百度.百度知道[EB/OL].http://zhidao.baidu.com,2015-03-01.
[13]曲明成.问答社区中的问题与答案推荐机制研究与实现[D].杭州:浙江大学,2010.
[14]Liu Yandong,Bian Jiang,Agichtein E.Predicting information seeker satisfaction in community question answering[C]// Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.2004:483-490.
[15]沈闻.基于问答社区的个性化服务研究[D].扬州:扬州大学,2009.
[16]赵亮,胡乃静,张守志.个性化推荐算法设计[J].计算机研究与发展,2002,39(8):986-991.
[17]Cao Xin,Cong Gao,Cui Bin,et al.A generalized framework of exploring category information for question retrieval in community question answer archives[C]// Proceedings of the 19th International Conference on World Wide Web.2010:201-210.
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29 01:29:00
幼儿园(2021年6期)2021-07-28 07:42:08
小天使·一年级语数英综合(2020年4期)2020-12-16 02:56:32
小学科学(学生版)(2020年3期)2020-03-25 13:31:22
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
当代陕西(2019年16期)2019-09-25 07:28:38
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
作文评点报·低幼版(2016年42期)2017-01-23 11:45:27
现代防御技术(2016年1期)2016-06-01 12:13:27
