
规则引擎在访问控制中的研究与应用
2015-11-26 03:00:26季开伟乐红兵
计算机与现代化 2015年8期
季开伟,乐红兵
(江南大学物联网工程学院,江苏 无锡 214122)
0 引言
访问控制[1]是通过具体途径来限制或准许主体对客体访问能力及范围的一种方法,自主访问控制(DAC)和强制访问控制[2](MAC)等传统访问控制由于使用相对局限,已无法满是应用系统对于安全性的需求;基于角色的访问控制[3](RBAC)的研究使访问控制进入了完全不同的授权模式,RBAC[4]中权限与角色相关联,用户权限的集合就是其拥有的角色集合;使用控制(UCON)[5]被誉为下一代的访问控制模型,定义了授权、义务和条件3 种决定因素,同时提出连续性和可变性2 种重要特征,但该模型高度抽象且没有统一管理模型,因而难于直接应用[6]。访问控制的核心在于控制策略,策略的判定在于访问请求信息是否满足控制策略的要求,本文将规则引擎技术应用到访问控制中[7],利用规则描述访问控制策略,规则的条件部分是控制策略要求,规则的动作部分则是访问控制的授权结果。然后通过对Rete 规则匹配算法研究,发现其并不适用于访问控制环境,Rete 算法通过保留匹配模式和中间结果来加快匹配速度,更适合多模式多数据的匹配处理。而在访问控制系统中,数据模式没有那么复杂,要处理的数据量也相对较小。所以,本文的规则匹配并没有采用Rete 算法,而是在Rete 算法研究的基础上,提出了基于多规则节点共享的规则匹配算法,规则的条件部分是由一个或多个子条件组合而成,将子条件看作一个节点,由于规则间具有相同的子条件,所以多规则可以共享这个节点,通过对单个节点的计算对多个规则进行处理,从而提高规则的匹配效率。同时Java 反射机制[8]可以动态获取类信息和动态调用对象方法,满足了规则引擎系统动态性的需求,也弥补了传统规则引擎实时性方面的不足,所以本文基于Java 反射技术设计实现了规则引擎系统。
1 规则引擎
1.1 工作原理
规则引擎是由基于规则的专家系统发展而来,通过接受数据输入,解析业务规则,并根据业务规则做出相应决策[9]。规则引擎的引入将业务规则从业务逻辑组件中剥离,具体业务用规则来表示,业务要求的变更无需对逻辑组件进行重新设计,只需对规则进行相应修改,这样不仅减少了系统开发成本,而且方便业务规则管理和系统维护。

图1 规则引擎的工作机制
如图1 所示,规则引擎简单来说有2 个输入(事实的输入和规则的输入),一个输出(匹配结果的输出)[10],规则引擎的简要工作流程如下:
1)把事实数据(Fact)输入到工作内存(Working Memory)中;
2)将静态规则库中的规则(Rule)与工作内存中的数据(Fact)进行模式匹配;
3)相匹配的规则被放入议程(Agenda),如果规则存在冲突,将冲突的规则放入冲突集合中;4)解决规则冲突,然后放入议程(Agenda);5)将规则执行队列中的规则逐条执行。
1.2 反射驱动规则引擎的模块设计
为了满足规则引擎对于实时性的需求,本文基于Java 反射实现规则执行引擎。Java 反射对任何一个类,都可以获取类的所有属性和方法;对任何一个对象,都可以调用其方法;这种动态获取类信息和动态调用对象方法的功能称为Java 反射机制。因此,反射机制可以帮助创建灵活的代码,构建灵活的应用,实现动态的匹配。
规则引擎模块设计如图2 所示。

图2 规则引擎模块设计
1)规则库(Rule)用XML 语言定义并存储业务规则,程序设计中,创建LeftHandSide 类封装规则的条件部分(LHS),LHS 由一个或多个约束条件组成;创建RightHandSide 类用于封装规则的结论部分(RHS),RHS 即满足所有LHS 约束条件后规则的执行动作;Rule 类则是用于封装规则的LHS 和RHS,Rule 类、LeftHandSide 类和RightHandSide 类之间属于聚合关系。
2)规则解析(RuleParser)模块用于对规则库中规则进行解析,该模块采用Jdom 解析XML 规则文件[11],将规则LHS 中所有约束条件和RHS 中所有执行动作都用HashMap 形式进行封装。
3)信息获取模块(GetFacts)通过Java 反射获取当前业务对象的事实属性,同样用HashMap 形式进行封装。
4)模式匹配器(PatternMatcher)将规则的约束条件与对象的事实属性进行匹配,匹配成功的规则放入matchedRules 中。
5)议程(Agenda)用于管理与当前对象事实匹配的规则集的执行次序。
6)规则执行引擎(ExecutionEngine)是规则引擎重要的组成部分,通过Java 反射调用执行当前对象的方法,即用Method.invoke()方法执行匹配规则RHS 部分要执行的动作。
2 基于规则引擎的访问控制
2.1 基于属性的访问控制
基于属性的访问控制[12](ABAC)不是对用户主体直接授权,而是将主体属性、资源属性和环境属性作为授权策略的控制基础。本文根据主体属性制定访问控制策略,利用规则引擎实现了基于属性的访问控制。为了方便用户管理,本文引入角色[13]属性,角色是权限的载体,将用户属性和角色相关联,当用户属性值满足角色规定的属性要求时,对应的角色被激活,用户获得该角色所对应的权限。访问控制模型如图3 所示。

图3 访问控制模型
2.2 规则的管理
访问控制的核心是授权策略,授权策略是用于确定一个主体能否访问客体的一套规则,规则用XML[14]语言来表示,可以动态建立授权规则,规则解析模块用Jdom 解析XML 规则文件。规则的基本结构如下所示:

<rule ></rule >节点是rule 的根节点,<rule></rule >中的name 表示规则名Rule,class 属性可以判定用户对象的类型,规则匹配时可以先过滤与业务对象相关的规则。<lhs ></lhs >节点表示规则条件部分(condition),即用户属性约束;<attribute ></attribute >节点表示具体的属性约束条件,可以是一个或多个约束条件;<rhs ></rhs >节点表示规则动作部分(action),即授权结果;<rhs ></rhs >中name 是所要反射调用的对象方法名,<prm ></prm>表示方法的参数,即执行User 对象setRole()方法分配用户相应的角色。
2.3 基于多规则节点共享的规则匹配算法
Rete 算法是由美国卡内基大学Charles.L.Forgy教授提出的前向链接推理算法[15],算法通过保存规则匹配的历史结果来加快匹配速度,只对更新的数据进行重新匹配,且通过复用Rete 网络节点减少规则条件的重复判断,Rete 算法针对多数据多模式,数据变化相对较少的规则匹配具有很好的性能,但访问控制环境中的规则匹配需要处理的数据相对较少,数据模式也相对简单,且进行一次匹配即可,所以Rete 算法对于访问控制中的规则匹配并不适用。
通过对Rete 算法设计思想和实现方式的研究,尽管Rete 算法不适用于访问控制系统中的规则匹配,但也有可借鉴之处,如Rete 算法节点共享的思想[16],不同的规则可能拥有相同的Alpha 节点或Beta 节点,Rete 算法通过共享这些节点,从而减少重复的模式匹配,提高匹配效率。
Rete 算法主要通过事实数据在Rete 网络中流动过滤而实现,根节点(RootNode)是所有的对象进入网络的入口,对于每个事实,通过类型节点(ObjectType-Node)的过滤使事实到达正确的AlphaNode,按照此节点对应的模式对事实进行匹配,如果匹配成功记录此事实,将事实沿着Rete 网络到达对应的BetaNode,BetaNode 从左右两端收到事实进行匹配,如匹配成功就将它们绑定记录下来,然后将绑定后的事实沿着Rete 网络到达下一个BetaNode,最后到达合适的TerminalNode。Rete 网络如图4 所示。
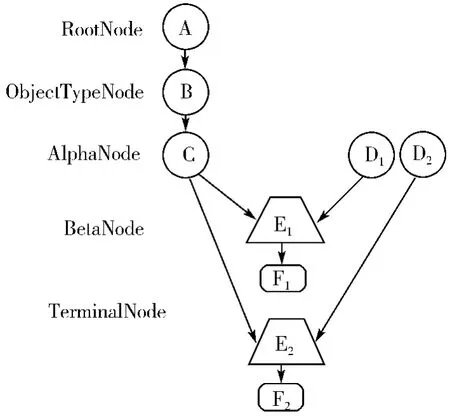
图4 节点共享
现有规则1 和规则2,如图4 所示,规则1 有C和D1两个条件,规则结果为F1;规则2 有C 和D2两个条件,规则结果为F2,即C and D1→F1;C and D2→F2;在构建Rete 网络时,Alpha 节点C 作为Beta 节点E1、E2的左输入,D1、D2分别是Beta 节点E1、E2的右输入,2 个规则导向不同的Terminal 节点F1、F2,从图中可以看出规则1 和规则2 共享Alpha 节点C,Beta节点不共享,通过节点共享可以简化匹配网络模式,匹配过程中通过复用该节点减少规则条件的重复判断,从而提高规则的匹配效率。
规则1 和规则2 判断如下:

其中,userType:用户类型(管理员01,普通用户02);workArea:工作范围(部门01,小组02)。
基于多规则节点共享规则匹配算法则首先将规则的子条件看作一个节点,如rule1 中有2 个节点:userType=="01"和manageArea=="01",rule2 中也有2 个节点:userType=="01"和manageArea=="02",而后将节点和对应的规则进行索引,如(userType=="01")→rule1;(manageArea=="01")→rule1;(userType=="01")→rule2;(manageArea=="02")→rule2,并放入索引列表中。然后对规则中的每个节点进行计算,如依据对象事实判断userType=="01"的真假,如果为真,则匹配规则中下一个节点;如果为假,则该节点对应的所有规则都不匹配,若userType=="01"判断为假,则该节点对应的rule1和rule2 两条规则都不匹配,将rule1 和rule2 放入删除集中,这样当完成rule1 匹配后,就无需对rule2 进行匹配,在这2 个规则匹配的过程中,将节点user-Type=="01"作为rule1 和rule2 的共享节点,多规则节点共享的应用加快了规则的匹配效率,相比按照规则队列中的规则逐条匹配的方式性能优势更加明显。

图5 规则匹配算法流程图
算法流程描述如下:
1)将规则的每个节点P 和P 所对应的每条规则R 放到索引列表map 中。
2)逐条取出规则R,判断其是否在删除集not-MatchedRules 中,若是则无需对该规则进行匹配。
3)对于规则R 的每个节点P,如果P 未计算,则计算并保存结果。
4)如果P 已计算且结果为真,则匹配下一个节点P。
5)如果P 已计算且结果为假,则将索引列表map中相关的所有规则R 删除,且更新到删除集not-MatchedRules 中。
6)如果规则rule 所有节点都判断过且为真,则规则R 匹配成功,将其放入matchedRules。
规则匹配算法流程如图5 所示。
算法优点:
1)对于访问控制系统来说,多规则间有很多相同的子条件,保存子条件的匹配结果则可以不用重复计算,大大减少匹配时间。
2)只要某一子条件为假,则包含该子条件的所有规则不用匹配则可判定规则无效,大大减少需要匹配的规则数。
假设规则中一共有50 个子条件,随着相同子条件个数的增加规则引擎匹配平均时间如表1 所示。

表1 基于对规则节点共享匹配算法

图6 共享子条件个数与匹配时间关系
如图6 所示,实验数据表明随着相同子条件个数的增加,规则引擎规则匹配的时间逐渐减少,所以规则的匹配效率与多规则中相同子条件的个数有关,相同子条件个数越多,运用多规则节点共享的概率就越高,规则匹配的平均时间就越少,从而规则引擎的执行效率就越高。
2.4 规则执行
当规则条件部分(LHS)定义的所有约束条件匹配成功时,便将相应的规则放入议程中,对于议程中的每一条规则,规则执行引擎将反射调用规则动作部分(RHS)定义的对象方法setRole()方法,授予该访问用户对应的角色,即授予用户该角色对应的访问权限。
3 对比分析
Drools 是一款为Java 语言定制的开源规则引擎[17],可以和Java 系统无缝集成,基于Rete 规则匹配算法,支持热部署规则和“人类语言”的规则编辑,通过使用DSL 可以实现用自然语言来描述业务规则,使得业务分析人员也可以看懂业务规则代码,拥有比较完善的管理系统和开发环境。
Drools 与反射驱动的规则引擎的属性对比如表2所示。

表2 属性对比
Drools 与反射驱动规则引擎对于不同规则数(个)的平均执行时间(ms)对比如表3 所示。

表3 执行时间对比 单位:ms
经过比较,Drools 作为一款功能很强大的开源规则引擎,也有其不足之处,首先,Rete 算法尽管具有很好的性能,但并不适合所有的应用环境,若事实库不稳定,保存的中间结果也相对不稳定,所以用空间换取时间反而是得不偿失,不仅占用大量内存,而且算法设计和实现较为复杂,在Drools 规则引擎中,必须要先建立数据模型,还要对规则库中的规则进行编译工作,而Java 反射驱动的规则引擎则相对灵活,无需预先建立数据模型,可以在规则定义后执行规则,无需进行规则编译工作,提高了应用的广泛性。实验数据表明,反射驱动规则引擎的规则匹配执行效率更高。
4 结束语
利用规则引擎实现基于属性的授权访问控制,用规则描述访问控制策略,通过增减规则的约束条件,可以改变控制策略的细化程度,从而满足控制因素全面性和控制策略灵活性的要求,规则引擎实现策略与机制分离,则满足系统通用性的需求,所以规则引擎的引入将访问控制提升到了一个全新的局面。基于反射机制又可以动态加载和执行规则,增强了访问控制的动态性和实时性。基于多规则节点共享的匹配算法又可以在多规则中存在相同子条件的情况下提高规则匹配效率,所以,相比Drools 规则引擎,反射驱动的规则引擎更适用于访问控制系统。
[1]刘宏月,范九伦,马建峰.访问控制技术研究进展[J].小型微型计算机系统,2004,25(1):56-59.
[2]Sandhu R S.Lattice-based access control models[J].IEEE Computer,1993,26(11):9-19.
[3]Sandhu R S,Coyne E J,Feinstein H L,et al.Role-based access control models[J].IEEE Computer,1996,29(2):38-47.
[4]洪帆,何绪斌,徐智勇.基于角色的访问控制[J].小型微型计算机系统,2002,2(2):198-200.
[5]Park J,Sandhu R.Towards usage control models:Beyond traditional access control[C]// Proceedings of the 7th ACM Symposium on Access Control Models and Technologies.2002:57-64.
[6]袁磊.使用控制模型的研究[J].计算机工程,2005,31(12):146-148.
[7]王辉.基于规则引擎的访问控制研究[J].计算机安全,2011(6):37-39.
[8]费延伟,刘淑芬,屈志勇,等.Java 反射驱动的规则引擎技术研究[J].计算机应用,2010,30(5):1324-1326.
[9]王李军,陶明亮,张曙,等.面向业务规则的规则引擎研究[J].计算机工程,2007,33(24):52-56.
[10]王晓光,杨丹.规则引擎在分布式环境下应用的研究[J].计算机应用究,2009,26(5):1825-1827.
[11]李雯,谢辅雯,邹道明.XML 数据交换技术的应用与研究[J].计算机与现代化,2008(1):91-93.
[12]程相然,陈性元,张斌,等.基于属性的访问控制策略模型[J].计算机工程,2010,36(15):131-133.
[13]熊智,徐江艳,王高举,等.基于角色和规则引擎的UCON 应用模型[J].计算机工程与设计,2013,34(3):831-836.
[14]傅海英,李晖,王育民.XML 及相关安全研究进展[J].计算机应用研究,2004,21(2):86-88.
[15]Forgy C L,Shepard S J.Rete:A fast match algorithm[J].AI Expert,1987,2(1):34-40.
[16]朱会兵.基于Drools 的信息管理与决策系统的研究与实现[D].武汉:武汉理工大学,2012.
[17]刘伟.Java 规则引擎-Drools 的介绍及应用[J].微计算机应用,2005,26(6):717-721.
猜你喜欢
能源工程(2020年6期)2021-01-26 00:55:22
山东冶金(2019年3期)2019-07-10 00:54:04
消费导刊(2018年10期)2018-08-20 02:57:02
商周刊(2017年22期)2017-11-09 05:08:31
中国公共安全(2017年11期)2017-02-06 05:28:08
通信学报(2016年11期)2016-08-16 03:20:32
现代工业经济和信息化(2016年19期)2016-05-17 05:38:20
通信电源技术(2016年1期)2016-04-16 04:57:26
信息安全研究(2016年10期)2016-02-28 20:18:36
河南电力(2015年5期)2015-06-08 06:01:46
