
基于超链接和DOM 结构树的网页标题实时抽取方法
2015-11-26 03:00:26张兵,汤进,2,罗斌,2
计算机与现代化 2015年8期
张 兵,汤 进,2,罗 斌,2
(1.安徽大学计算机科学与技术学院,安徽 合肥 230601;2.安徽省工业图像处理与分析重点实验室,安徽 合肥 230039)
0 引言
互联网的发展速度已经远远超出了人们预料的范围,人们迎来了大数据时代[1]。在这些海量数据资源当中蕴含着大量的有用信息,而这些资源中更多的是杂乱无章的无用信息。这些大量的无用信息[2],让人们意识到想要迅速快捷地获取自己所需信息变得更加困难[3-4]。网页标题是一篇网页所要表达信息的最简单明了的概述,对于网页信息的处理以及应用具有重要的意义。文献[5]对国内中文期刊进行的抽样统计表明,自然科学论文的标题反映文章主题的概率高达99%;接着又对3600 篇新闻类文章进行了统计,表明标题可预示文章类别主题的概率达到了95%以上。这足以说明文章标题的重要性,因此如何有效抽取网页文档中的标题,是关系到如何有效快捷地获取目标信息的关键技术之一。
网页标题抽取方法有很多,常用的方法主要集中于基于机器学习和基于规则2 类,如Xue Y 等人[6]从HTML 节点的视觉信息、内容信息和位置信息等方面的特征入手,构建机器学习模型对网页标题进行识别。朱青等人[7]在构建机器学习模型的同时,引入了HTML 结构以及网页DOM 树结构等信息。李国华等[8]考虑到了网页正文内容与标题之间的相关性,通过计算句子相互之间的相似度,从而确定了网页的标题。文献[9]利用了4 个视觉表特征:“<title>”标签对、“<H >”标签对、“<Font >”标签以及网页标题在正文中的位置信息进行标题的抽取,取得了很好的效果。
综合分析当前对网页标题的各类研究,取得了较高的准确率,但是在时间效率上却有些不尽人意。Google 一类的搜索引擎采用的是利用锚点文本内容和“<title >”标签来确定网页标题,时间效率比较高,但是在准确率方面却很低。本文提出一种高效的提取网页标题的方法。一般来说,一篇网页的标题前或后大多会紧跟着发布时间,根据这一特点,首先对目录型网页进行解析,将目录型网页的HTML 源码中的超链接按照自顶向下遍历的方法,结合标题与发布时间相紧邻的特点,设计时间正则表达式,获取对应目录型网页的URL 及锚文本。若获得锚文本不是网页真正的标题,则获得对应的主题型网页的HTML 源码并构建网页DOM 树,采用深度优先遍历DOM 树的原则,利用目录型网页标题抽取算法的结果,并结合网页标题的视觉特点,正确提取网页正文标题。实验结果证明,这种方法对于网页标题的抽取具有很高的效率。
1 Web 信息提取
通常情况,Web 网页是由HTML 语言编写而成[10]。通过对网页HTML 源码分析,将其分为主题型页面和目录型页面2 种[11]。主题型页面是指页面中通过大量的文字对一个或多个事件进行传递,比如常见的新闻网页是典型的主题型网页。目录型网页中超链接比较多且比较密集,大多数是指向其他网页的链接,含有的文本是对所指向网页的内容概要如标题等信息。2 种类型的页面特点见表1。

表1 2 种页面特点对比
目录型网页的信息抽取包括目录标题列表的抽取及对应的超链接,标题即为对应超链接的锚文本,是所指向的主题型网页的简要介绍。主题型网页的信息抽取包括很多方面,比如标题、正文、发布时间、发布地点等信息的抽取。对于网络中某一事件,其发布时间或发布地点等信息的获取一般可以通过正则表达式直接获得,本文不再赘述。
2 基于超链接和DOM 树的网页标题抽取
目录型网页中的锚文本一般即为正文网页的标题,但也不是特别地准确,有的标题超过一定字数网页显示不完全时会以“...”或“…”表示,为了更加准确地提取正文标题,在目录型网页抽取结果的前提下,需对正文HTML 建立DOM 标签树,对DOM 标签树进行遍历,选出有可能成为标题的候选节点,根据网页正文标题的特征,进一步确定网页正文的标题。
2.1 预处理
互联网下载的网页HTML 源码,常常含有大量的噪音,如注释、广告等。这些噪音对于网页信息的准确抽取有很大的影响,所以在进行网页信息抽取之前要对下载的HTML 源码进行清洗,去除噪音[12],具体去噪操作步骤如表2 所示。

表2 网页去噪具体步骤
2.2 基于超链接的目录型网页标题抽取
对于目录型网页,主要是要获取主题型网页的链接和对应的锚文本。一般情况下,目录型页面中,含有大量的超链接,其中的新闻标题列表是要抓取的内容,相应的新闻标题前后都会包含新闻发布时间,而网页中其它块中是不具有这一特点的。根据这一特点,采用超链接遍历方法对标题进行抽取。在对大量的网站进行归纳总结后,得出一般情况下网页发布时间正则表达式[13],如表3 所示。

表3 年月日正则表达式
由于每个网站的编写者不同,习惯也大不相同,新闻发布时间的格式更是有很大差别,年月日可能会加上一些日期分隔符进行自由组合,如:2000/9/10、2000.9.10、2000-9-10、2000 年9 月10 日、9 月10 日等。本文利用正则表达式,将年月日与日期分隔符进行自由组合,充分地包含了已发现的时间发布格式。在确定了网页发布时间的格式后,还应该确定发布标题与发布时间的先后顺序,这样才能防止错抽和漏抽。在对大量不同网站进行归纳总结的基础上,建立相关词汇库,发现只要上一个超链接的结束标签“/a>”与下一个超链接的开始标签“<a href”之间含有词汇库中的词如:“下一页”,“发布”,“公告”,“首页”等,表明发布时间在标题后面,反之发布时间在标题前面。
对于目录型网页来说,标题列表只可能存在于“<body >”和“</body >”2 个标签对中,所以只需获取预处理过后的这部分的HTML 源码即可。
算法1 目录型网页标题抽取
输入:目录型网页URL 库。
输出:锚文本标题和链入主题型网页的超链接。
1)取得已清洗过的HTML 源码。
2)计算HTML 源码中超链接标签“<a href”的个数,记为Count。
3)判断Count 值是否大于0。
4)自上至下依次遍历HTML,若标签“/a >”和“<a herf”中间的锚文本为空,执行3)。
5)若“/a >”和“<a herf”中间没有与预先设计好的日期正则匹配,执行3)。
6)判断日期与链接之间的先后关系。
7)提取锚文本和超链接。
算法1 的流程如图1 所示。

图1 目录型网页标题抽取算法流程图
上述算法得到的目录型标题列表并不能作为最终的正文标题,在对大量目录型网页标题列表进行分析过后,将目录型网页中标题列表中的标题分为以下3 种情况:
1)与正文网页标题相同,标记为标签Label_1;
2)与正文网页标题完全不同或者字数少于4 个,标记为标签Label_2;
3)是正文网页的一部分,带有省略号“…”或“…”,标记为标签Label_3。
为了正确获取这些实时标题,针对Label_2 和Label_3 这2 种情况,需要通过解析其对应的超链接HTML 源码,获取主题型网页的网页内容,利用基于DOM 树的主题型网页标题抽取算法进行标题的抽取。
2.3 基于DOM 树的主题型网页标题抽取
一般来说,对于主题型网页,映入眼帘的是网页的正文标题。如果把网页进行分块处理的话,从视觉的角度来看,将页面进行分块[14],标题与正文内容的位置信息有3 种情况[11],如图2 所示。

图2 标题与正文内容的位置信息示意图
事实上,网页正文标题还具有很多其他固有的特征。为了进一步发现网页正文标题的特征,通过对大量网页的标题进行观察,结合前辈们的研究成果[15],总结出网页标题的3 方面特点:
1)标题所处位置一般位于网页正文的最上端。
2)标题的一般形式特征表现在网页正文中最大的字,或者在颜色、字形以及标题所处DOM 树中节点的标签与其他网页正文中其他内容是不同的。
3)标题的长度在分词过后一般长度在3~30 之间,并且中间不包含逗号、句号等符号。
对主题型网页HTML 源码进行分析,发现一般较为正规的主题网页的标题位于标签“<title >”和“</title >”中[16],但并不是完全准确,有的网页中的“<title >”标签为空,相应的也会含有一些其他文本内容,有的网页会在“<title >”标签对中添加一些日期信息、网站logo 以及“_”,“/”,“-”等其他符号等[17]。这种不一致性会降低标题抓取的准确率,无法在实际使用中运用。根据上述网页正文标题的特征,有人利用基于规则的方法[15]和基于机器学习的方法[7]来提取网页正文标题,都取得了比较好的效果。本文在上述方法的基础上结合目录型网页提取的结果,对主题型网页建立DOM 树来提取网页正文标题。本文采用HtmlParser[18]工具建立网页DOM树。HtmlParser 是HTML 解析库,能高速解析HTML网页,且不会出错,并针对Label_2 和Label_3 这2 种情况,分别进行处理。实验证明这种方法能够取得较高的准确率,满足实际的需求。具体算法流程如下:
算法2 主题型网页标题抽取
输入:URL 链接:Weburl;锚文本:TitleText;锚文本的标签值。
输出:网页正文标题候选队列。
1)根据目录型网页获取的URL 获取主题型网页HTML 源码并预处理。
2)判断是否为主题型网页,不是则结束。
3)判断URL 标签类型,若为Label_2 执行5);若为Label_3 则执行4)。
4)对HTML 中“<body >”和“</body >”递归建立网页DOM 树,执行6)。
5)对HTML 源码建立DOM 树,获取“<title >”与“</title >”标签对中内容,赋值给TitleText。
6)按照深度优先方式遍历DOM 树各节点,若节点含有文本片段,且其与TitleText 内容的共现度大于80%,则将该文本内容加入标题候选队列ListQue,并记录其对应的特征标签值及共现度值。
7)对ListQue 队列按照共现度值的大小,进行排序。
算法2 的程序流程见图3。
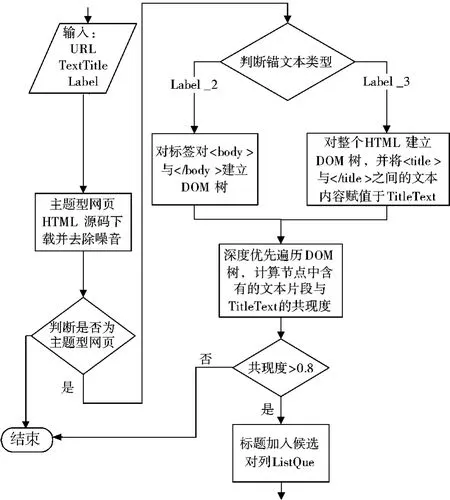
图3 主题型网页标题抽取算法流程图
对于获取的文本片段序列进行预处理,去除一些不符合网页正文标题特征的文本片段。然后依次遍历剩余的各个文本片段,判断其是否满足前述网页标题中部分特征,不满足,则从队列中删除。若最后候选标题个数大于1 个,则选择标题长度最小的那个作为最终的标题。
3 实验结果与分析
3.1 实验环境
实验程序,在.NET Framwork3.5 平台下,使用Visual Studio 2008 开发工具,采用C#编程语言实现,数据库版本为SqlServer2008。
3.2 实验数据
实验数据源主要来自人民网、网易新闻、腾讯新闻、中国新闻网、中华人民共和国中央人民政府网、安徽大学新闻网、合肥工业大学新闻网、中国科学技术大学新闻网以及安徽省内各市县级政府门户网共82个网站。因为每个网站的结构是相同的,所以每个网站只选取一个目录型网页,这些网页主题涉及社会、军事、财经、IT、教育、体育、娱乐以及招标公告、政务新闻、校园新闻公告等,共有所需标题2175 条。数据覆盖性较广,保证了算法的适用性。
3.3 网页标题抽取实验
对数据库中每个目录型网页依次下载其HTML源码,并进行去噪,按照算法1 进行目录型网页锚文本与正文链接提取,若算法1 提取出来的标题被标记为Label_2 或者Label_3 的情况,利用主题型网页抽取算法,即算法2,进一步进行标题的抽取。最后将抽取到的标题信息进行整合。具体的实验结果如表4 所示。
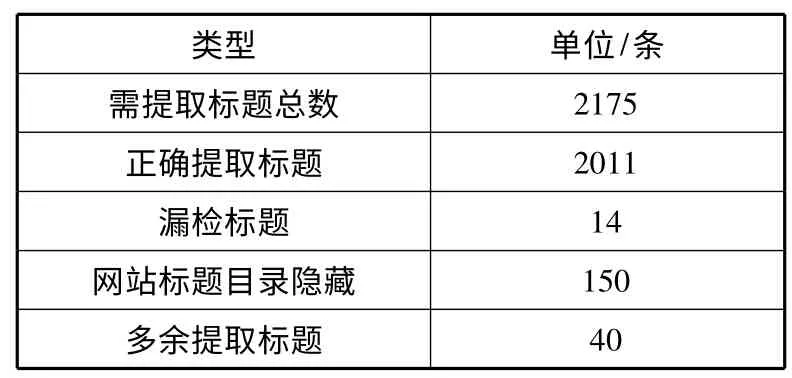
表4 实验结果
3.4 实验结果分析
因为有的网页关键内容是隐藏起来的,所以通过HTML 源码分析的方式是获取不到的。在上述的2175 条标题中,被隐藏的标题数为150 条,漏检的标题数为14 条,总体的准确率为92.46%。如果去掉信息被隐藏的网站,准确率为99.36%。实验中出现多余提取的原因是有的网站在网页的左侧或右侧有文章列表,这些列表前后也恰巧包含了时间信息,或者在网页的导航栏下方有滚动标题,也包含了时间信息。所以在通过HTML 进行标题提取的时候,这些标题也会被抽取出来。
4 结束语
本文提出的基于超链接和网页DOM 结构树的网页标题抽取方法能够取得较高的准确率,数据源来自各个不同的网站,表明算法具有很好的适用性,完全可以在日常使用中运用。文中存在以下2 方面问题尚未解决:有的网页内容是隐藏的,在HTML 中未能显示出来,这部分的网页是获取不到的,无法进行标题的抽取;而有的网页的其他块中也存在着标题加发布时间的这种格式,会对标题抽取的结果造成影响,比如会出现多余提取的现象。下一步将继续研究当网页内容被隐藏后,如何获取网页内容;屏蔽除了正文块中的其他块的影响,以达到更好的标题抽取效果。
[1]杨春磊,刘念唐,林雨,等.面向领域的Web 文本结构化分析[J].合肥工业大学学报(自然科学版),2013,36(3):309-314.
[2]胡凌云,胡桂兰,徐勇,等.基于Web 的新闻文本分类技术的研究[J].安徽大学学报(自然科学版),2010,34(6):66-70.
[3]张引,陈敏,廖小飞.大数据应用的现状与展望[J].计算机研究与发展,2013,50(Suppl):216-233.
[4]陆余良,房珊瑶,刘金红,等.Deep Web 站点分类研究进展[J].安徽大学学报(自然科学版),2010,34(1):103-108.
[5]王强,关毅,王晓龙.基于标题类别语义识别的文本分类算法研究[J].电子与信息学报,2007,29(12):2885-2890.
[6]Xue Yewei,Hu Yunhua,Xin Guomao,et al.Web page title extraction and its application[J].Information Processing and Management,2007,43(5):1332-1347.
[7]朱青,吕晓旭.基于机器学习的HTML 标题抽取[J].微计算机信息,2010,26(3):15-16,11.
[8]李国华,昝红英.基于相似度的网页标题抽取方法[J].中文信息学报,2011,25(2):32-37.
[9]Fan Jian,Luo Ping,Joshi P.Title identification of Web article pages using HTML and visual features[C]// Proceedings of the International Society for Optical Engineering,2011.2011,7879.
[10]李军,陈君,王玲芳,等.一种垂直页面分割与信息提取方法的研究[J].计算机应用研究,2013,30(3):844-847,852.
[11]黄玲,陈龙.基于网页分块的正文信息提取方法[J].计算机应用,2008,28(S2):326-328.
[12]周建,汤进,罗斌.基于DOM 结构树的网页正文信息分段方法[J].计算机与现代化,2013(10):229-232.
[13]胡军伟,秦奕青,张伟.正则表达式在Web 信息抽取中的应用[J].北京信息科技大学学报(自然科学版),2011,26(6):86-89.
[14]张乃洲,曹薇,李石君.一种基于节点密度分割和标签传播的Web 页面挖掘方法[J].计算机学报,2015,38(2):349-364.
[15]刘建华,张智雄,谢靖,等.基于规则的网络文本资源标题快速自动识别方法[J].现代图书情报技术,2011(6):27-31.
[16]罗永莲,赵昌垣.突发事件新闻标题与正文提取方法[J].计算机应,2014,34(10):2865-2868,2873.
[17]王海潮.基于网页结构的信息抽取关键技术研究[D].广州:华南理工大学,2011.
[18]Jericho HTML Parser.Jericho HTML Parser[EB/OL].http://jericho.htmlparser.net/docs/index.html,2015-03-10.
猜你喜欢
计算机应用(2023年6期)2023-07-03 14:11:56
计算机时代(2023年6期)2023-06-15 17:49:09
传媒论坛(2022年9期)2022-02-17 19:47:54
科学养鱼(2021年6期)2021-11-30 18:02:10
计算机与网络(2020年17期)2020-10-12 14:46:34
电子制作(2018年10期)2018-08-04 03:24:38
电子制作(2017年2期)2017-05-17 03:54:56
计算机教育(2016年4期)2016-05-20 02:36:05
电子测试(2015年18期)2016-01-14 01:22:58
计算机与网络(2014年7期)2014-03-25 10:57:07
