
基于概念与词根双特征互助文本分类模型
2015-11-26 03:00:28吴庭君文静云
计算机与现代化 2015年8期
古 平,吴庭君,文静云
(重庆大学计算机学院,重庆 400030)
0 引言
目前互联网资源呈现海量增长趋势,应用信息检索、数据挖掘技术有效组织和利用海量信息逐渐成为备受关注的问题。其中,文本分类在自然语言处理、信息检索和管理方面都有着广泛的应用。文本分类的意义在于能够组织和处理大规模数据,从而缩小信息检索的范围,增强检索要求与检索对象的相关性[1]。
文本分类研究面临的主要问题是有标注的样本资源非常稀少,获取代价较高,而无标注样本资源十分丰富,获取代价相对低廉,却没有得到充分的利用,若这些信息能够被充分利用,将有效提高分类算法的性能[2]。针对该问题,半监督学习思想[3]应运而生,半监督学习是监督学习和无监督学习相结合的一种学习方式,主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题。目前,已经有基于直推支持向量机、基于最大期望的方法、基于图的方法、基于协同训练的方法[4]应用于半监督文档分类研究。上述大多数方法均建立在单一词根特征的基础上,忽略了概念(语义)特征的重要性,实际上词与词之间大量存在的一词多义、多词一义现象,以及潜在的语义关系往往对文本理解、分类具有更高的价值。
因此,本文在协同训练算法的基础上,提出一种新的融合概念与词根双特征互助的半监督分类模型。协同训练思想已经在自然语言处理中的句法分析[5]、名词识别[6]、信息提取[7]、计算机辅助医疗诊断[8]和垃圾邮件识别[9]等领域得到了广泛应用。与传统的协同训练算法[10]不同,本模型建立在文本的概念和词根2 个不同的特征视图上,利用本体库作为外部知识,对传统的向量空间模型进行语义映射,得到与原特征向量空间互补的一种概念特征表示,进而满足协同训练过程中对视图独立、互补性的要求。对于文本分类中的一词多义、语义相关问题,本文提出一种新的语义相似度表示与计算方法,较好地解决了在语义空间中的文本分类问题。
1 基于Co-training 的协同训练算法
Co-training 是一种多视图自助式的半监督学习算法[11],基本思想是:利用小规模标注样本集,从2个相对条件独立的视角构造2 个分类器,并利用这2个分类器对大量未标记样本进行标注。Co-Training的形式化定义如下:
定义实例空间X=X1×X2,其中X1和X2是同一实例的2 个观察角度,因此实例x 可以由(x1,x2)来表示。假设每个角度观测出来的信息都足够对其进行正确分类。设X 的分布为D,C1和C2分别为在X1和X2上定义的概念类,假设在分布D 下实例所有概率不为0 的标注都与目标函数f1和f2一致,f1∈C1,f2∈C2。即对于任意实例x=(x1,x2)如果有标注l,则f(x)=f1(x1)=f2(x2)=l。对于实例(x1,x2),如果f1(x1)≠f2(x2),则在D 下该实例概率为0,称函数f=(f1,f2)∈C1×C2与分布D 是相容的[12]。
对于X 的一个给定的分布D,如果分布D 赋予零概率值给那些f1(x1)≠f2(x2)的实例(x1,x2),则认为目标函数f=(f1,f2)∈C1×C2与分布D 是相容的。为了能够获得更好与目标概念相容的目标函数,需要利用更多的未带标注的样本。找到目标函数f,这样能减少学习算法所需要的带标实例的数目[13]。
Co-training 算法的关键是要从2 个不同的视角定义出2 组特征集,且满足2 个条件:1)每个视角选取的特征集可以描述问题;2)每个视角选取的特征集相互独立。
与本文思想最接近的研究来自文献[10],其在海洋文献分类中基于摘要和文本内容2 个视角构建了2 个不同的特征集,并通过Co-training 算法实现对海洋文献的分类。实验表明该方法非常有效,但不是所有文档都具有2 组自然的特征表示,因此,该方法不具有普适性。本文认为:只有词根和概念才是文档表示中2 个最本质的特征,不仅适用于所有文档,而且具有相对的独立性和互补性(词根在特征空间中是正交的,而在语义空间中是斜交的),因此,以词根和概念为特征的视图形式更适用于文档的协同训练与分类。
2 基于概念与词根双特征文本分类模型
为将文本向量空间中的词根进行语义映射,并在概念空间进行表示,必须用到特定的本体库。本体库揭示概念之间以及概念及其相关属性之间的关系,描述对象为汉语或英语中词条所代表的概念,基本定义如下:
定义1 本体库是由元组R:=(C,≤)组成的一组C,C 代表概念的集合,C 中元素称为概念标识符,≤代表概念间的上下位关系[14]。
定义2 如果c1<c2,且c1,c2⊂C,则c1是c2下位,c2是c1的上位。如果c1<c2,且没有c3⊂C 使c1<c3<c2,则c1是c2的直接下位,c2是c1的直接上位。定义为c1≺c2[14]。
定义3 本体库中的词典是由元组L:=(S,Ref)组成的一组S,S 中元素称为概念结点,关系Ref⊆S×C 称为词典与概念的对应关系,对于每个c∈C∩S 有(s,c)∈Ref。基于Ref 定义,对s∈S,有Ref(s):={c∈C|(s,c)∈Ref},对c∈C,有Re f-1(c):={s∈S|(s,c)∈Ref}[14]。
常用的本体库包括Hownet、WordNet、FrameNet、VerbNet,其中WordNet 资料最为丰富也最常用,本文以WordNet 为例进行研究与实现。
2.1 词根与概念双特征表示
2.1.1 基于词根的向量空间表示
语义概念分析使文本中的词与词之间尽量达到正交。特征词被表示成词频的集合,一个文本库可以表示成一个m×n 词的文本矩阵A,这里每个文本中不同的词对应于矩阵A 的一行,而每一个文本则对应于矩阵A 的一列。表示为:

式中,aij为非负值,表示第i 个词在第j 个文本中的权重。分类时,每个特征项所带的文本信息量不一样,对于分类的重要程度也不一样,所以需要考虑对特征项进行加权,这里选用TF-IDF 方法,公式如下:

式中,Wi表示第i 个特征项权重;TFi表示第i 个特征项在文本中出现的次数;IDFi表示第i 个特征项的逆文本比例,N 是整个文本集的文本个数,ni是包含该特征项的的文本个数[15]。
2.1.2 基于概念的特征向量表示
在构建概念和特征词的双视图完成之后,需要构建概念特征向量空间模型。首先,需要定义以下概念:
定义4 概念的文本频度:概念在某文本中出现次数。假设特征词的集合为(X1,…,Xn),用公式(2)表示概念ci的文本频度:

其中,F(ci,Xi)表示概念ci是否为特征词Xi在文本库中概念或者上层概念,n 表示文章预处理后特征词的个数。
定义5 概念的类别频度:概念在某个类别中出现的总次数。用公式(3)表示概念ci的类别频度:

其中,FCDF(ci,j)表示概念ci在文本j 中出现次数,n表示类别中的文章总数。
定义6 概念的概括度:概念的覆盖范围。一个概念的层次越高,它的抽象度就越大,涵盖的范围就越广。概念的涵盖范围太广,对分类的意义就不大。本文用FR(c)表示概念的概括度如下:

其中F(Si)表示子概念自身及全部所属子概念在文章中出现的次数,n 表示概念c 的子概念总数。
定义7 概念的反类别频度:用于衡量概念所包含的类别个数,与它包含类别个数呈反向变化。本文用FCICF(c)表示概念的反类别频度:

其中,N 为类别总数,n 为概念c 出现至少一次的类别数量。
定义8 概念的特征加权函数:

其中FCDF(c)、FCICF(c)、FR(c)分别是概念的文本频度、反类别频度、概括度。
构建语义概念向量模型,首先对文本进行分词和预处理后得到文本集,然后利用WordNet 文本库对特征进行概念映射。构建算法描述如下:
输入:文本TC。
输出:文本TC 语义概念向量TC={(S1,W1),(S2,W2),…,(Si,Wi)}。
步骤1 使用Lucene 3.0 的StopAnalyzer 分词系统对TC进行分词后得到TC={x1,x2,…,xi}。
步骤2 利用式(1)初步提取TC 特征后得到TC={d1,d2,…,dn}。
步骤3 依次查询WordNet 本体库,进行概念映射(定义3)和多义词语义类定位。
步骤3.1 查询WordNet 本体库,若TC 的特征词di有唯一的概念定义,则跳转至步骤4;
步骤3.2 若特征词di包含多个语义类,选择本体库中排在最前面那个语义类,依次计算TC 中所有特征的概念,得到集合TCS={(d1,S1),(d2,S2),...,(dn,Sn)}。
步骤4 对TCS按照概念定义进行合并得到:TCS={(S1,(d1,…,di)),(dh2,(S2,…,dj)),...,(Sq,(dl,…,dk))},其中Sq为TCS集合中无重复的概念,q,i,j,k≤m,l <k//语义概念映射。
步骤5 顺序扫描TCS,利用式(6)计算概念Si的权重,直至TCS扫描结束。
步骤6 根据步骤5 中计算概念的权重选取有意义概念,输出文本TC 对应语义概念向量TC={(S1,W1),(S2,W2),…,(Si,Wi)}。
2.2 基于朴素贝叶斯的双视图互助协同训练
本文在基于Co-training 的框架下,选择朴素贝叶斯模型(Naïve Bayes)作为分类器。朴素贝叶斯模型具有计算高效、精确度高的特点并且具有坚实的理论基础,已经得到了广泛的应用,其基本思想如下:
设每个数据样本用一个n 维特征向量X=(x1,x2,x3,…,xn)表示,分别描述在n 个属性A1,A2,A3,...,An上的值。假定有m 个类,分别用C1,C2,C3,...,Cm表示,给定一个未知的数据样本X,根据贝叶斯定理:

由于p(X)对于所有类为常数,最大化后验概率p(Ci|X)可转化为最大先验概率p(X|Ci)p(Ci),朴素贝叶斯分类模型中的属性独立假设假定所有属性都是相互条件独立,即有:

先验概率p(x1|Ci),p(x2|Ci),...,p(xk|Ci)均可以从训练数据集中求得。
据此,对于待分类样本X,可以先分别计算出X属于每一个类别Ci的概率p(X|Ci)·p(Ci),然后选择其中概率最大的类别作为其类别,即朴素贝叶斯分类模型为:
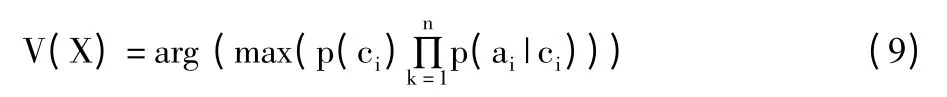
如果直接将上述模型应用于基于概念特征的文本分类,可能产生分类性能的下降,其原因在于:基于概念加权的分类模型考虑了概念对于分类的重要性,但忽略了概念之间的联系。例如,术语“pussy”和“cat”都可以表示“猫”,如果只根据“cat”作为分类特征,则同义词”pussy”的出现不会对“animal”类别的判别产生任何影响,语义之间的关系仍然没有考虑,会影响分类效率。
要考虑概念之间的关系,需要定义概念之间的相似度,定义如下:
定义9 语义之间的相似度:WordNet 本体库中2 个概念之间的相似程度。WordNet 中计算2 个概念ci,cj相似度公式如下:

其中,r 是概念ci,cj之间的最短距离,h 为归入在层次语义网络上的深度。α≥0,β >0 是分别为缩放最短路径长度和深度参数[16]。本文约定,若r >2,则表示概念之间的联系很小,sim(ci,cj)=0。
考虑概念之间的关系后,基于概念与词跟双特征互助的文本分类模型的计算公式如下:

算法描述:
输入:训练样本库YT,测试样本集S,待分类文本T。
输出:待分类文本T 的分类结果Ct。
1)将训练样本库YT 划分为2 部分:标注训练样本为L,未标注样本为U。
2)For L 中每个样本do:
2.1)基于2.1.1 节和2.1.2 节算法描述构建基于词根的特征向量和语义概念向量;
2.2)统计并计算特征词和概念所属的分类概率,分别获得分类器A,B。
3)For S 中每个样本do:
3.1)基于2.1.1 节和2.1.2 节算法描述构建基于词根的特征向量和语义概念向量;
3.2)计算它们在分类器A,B 中的分类结果,最终求得A,B 准确率。
4)For U 中每个样本do:
4.1)基于2.1.1 节和2.1.2 节算法描述构建基于词根的特征向量和语义概念向量;
4.2)用式(9)和式(11)计算每个文本的分类结果
5)while |Aacc_i-Aacc_j| >ε or|Bacc_i-Bacc_j| >ε(ε 为给定阈值,Aacc_i,Aacc_j,Bacc_i,Bacc_分别为分类器A,B 在第i,j 次的准确率)do:
5.1)将step3 中分类器A,B 的计算结果最高的10 个样本加入到对方训练集中;
5.2)重复步骤2)~4)一次。
6)将待分类文本T 表示成语义概念向量;
7)用式(11)计算T 所属类别Ct,输出Ct。
3 实验分析
3.1 实验准备
实验数据使用来自20-Newsgroups 文本数据集。20-Newsgroups 是一个具有20 个类别新闻的英文文章集合。库中文档放在20 个目录下,每个目录的名字就是类别的名字,每个类大约有1000 篇。
实验目的是要验证基于概念与词根双特征互助的文本分类模型的有效性,实验采取基于概念与词根双特征和仅以词为特征的文本分类模型比较其分类效果。评价分类器的好坏通常从准确率和召回率[17]这2 个标准来衡量。
3.2 实验结果与分析
实验环境是Win7 操作系统、i5 处理器、4 G 内存的PC 机一台,在Eclipse 平台下编码。实验数据集的每个分类下都有1000 篇文本,这个数据量虽不大,但在PC环境下运行效率低,所以对实验数据集做如下处理。
第一次从每个分类中随机选取50 篇文本作为训练集,计算不同模型下的分类效果;第二次从每个分类中随机选取100 篇文本作为训练集,计算不同模型下的分类效果;下一次实验在上一次的基础上每个分类增加50 个样本,进行10 次,每次采用二重交叉验证。
Co-training 框架下基于词根的分类模型(Rootbased Classification Model)建立:
1)利用2.1.2 节中步骤1 和步骤2 处理得到文本T 的特征项。
2)将T 中特征项随机分成2 份,构建2 个相互独立的基于词根的特征向量。
3)Co-training 框架下利用朴素贝叶斯算法训练这2 个数据集。
Co-training 框架基于概念与词双特征互助的分类模型(Classification Model Based on Concept and Root)建立:
1)利用2.1.2 节中步骤1 和步骤2 处理得到文本T 的特征项。
2)利用2.1.2 节中步骤3 至步骤6 处理得到T对应语义概念向量TC。
3)Co-training 框架下用朴素贝叶斯方法训练这2个数据集。
在Co-training 框架下采用朴素贝叶斯分类算法训练上述数据集得到一个分类器。再用这个分类器对测试数据集进行分类,记录其准确率和召回率。实验结果如表1 所示。

表1 实验结果
从实验结果可以看出:
1)同Co-training 框架下,同训练样本情况下,基于概念与词根双特征互助的分类模型始终比基于词根的分类模型具有更高的准确率和召回率,尤其在训练样本数量比较少时,表现得更为明显。
2)分类器的性能都随着训练样本的数量的增大而提高,且在某一区域内增长明显,随后增长率慢慢减小。
3)当训练文本数量比较小时,概念与词根双特征互助的分类模型准确率比仅有词根的分类模型高很多。因为在训练语料不足的情况下,前者很好地解决了数据稀疏问题。
4)随着训练语料的增多,基于词根的方法克服了数据稀疏问题,因此与基于概念与词根双特征互助的模型之间性能差距就越来越小。
4 结束语
本文引入了语义概念向量模型来表示文本,提出了基于概念和词根双特征互助的文本分类算法,该算法考虑了语义对文本分类的重要性。实验结果表明,基于语义和词根双特征互助模型相对单一词根的分类效果更好。
但本文的研究仍存在以下不足之处:
1)语义消歧问题,若出现一词多义情况,本文只选择了WordNet 中排在最前面的语义类,过于牵强。
2)概念向量模型的建立充分依赖WordNet,WordNet 本身的一些缺点不可避免,如:漏词现象、专业领域知识缺乏等。
[1]Sebastiani F.Machine learning in automated text categorization[J].ACM Computing Surveys,2002,34(1):1-47.
[2]Chen Haibin,Tan Pangning.Semi-supervised learning with data calibration for long-term time series forecasting[C]//Proceeding of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.2008:133-141.
[3]Zhou Xiaojin.Semi-supervised Learning Literature Survey[DB/OL].http://pages.cs.wisc.edu/~jerryzhu/pub/ssl_survey.pdfb,2008-07-19.
[4]周志华.基于分歧的半监督学习[J].自动化学报,2013,39(11):1871-1878.
[5]Pierce D,Cardie C.Limitations of co-training for natural language learning from large datasets[C]// Proceedings of the 2001 Conference on Empirical Methods in Natural Language Processing.2001:1-9.
[6]Steedman M,Osborne M,Sarkar A,et al.Bootstrapping statistical parsers from small datasets[C]// Proceedings of the 10th Conference on European Chapter of the Association for Computational.2003:331-338.
[7]Li Ming,Li Hang,Zhou Zhihua.Semi-supervised document retrieval[J].Information Processing & Management,2008,45(3):341-355.
[8]Li Ming,Zhou Zhihua.Improve computer-aided diagnosis with machine learning techniques using undiagnosed samples[J].IEEE Transactions on Systems,Man,and Cybernetics,Part A:Systems and Humans,2007,37(6):1088-1098.
[9]Mavroeidis D,Chaidos K,Pirillos S,et al.Using tri-training and support vector machines for addressing the ecmlpkdd 2006 discovery challenge[C]// Proceedings of the ECML-PKDD Discovery Challenge Workshop,2006.2006:39-47.
[10]徐建良,姜亦宏,张巍,等.一种基于Co-training 的海洋文献分类方法[J].中国海洋大学学报(自然科学版),2010(2):105-110.
[11]刘世岳.基于Co-training 方法的中文组块识别的研究[D].沈阳:东北大学,2004.
[12]Blum A,Mitchell T.Combining labeled and unlabeled data with co-training[C]// Proceedings of the Workshop on Computational Learning Theory.1998:92-100.
[13]沈新宇.基于直推式支持向量机的图像分类算法研究与应用[D].北京:北京交通大学,2007.
[14]Hotho A,Staab S,Stumme G.WordNet improves text document clustering[C]// Proceedings of Semantic Web Workshop of the 26th Annual International ACM SIGIR Conference.2003:541-544.
[15]陈伟萍,王琳,封化民,等.一种基于语义概念的中文文本分类方法[C]// 第一届建立和谐人机环境联合学术会议(HHME2005)论文集.2005:401-405.
[16]Li Chenghua,Yang Juncheng,Park S C.Text categorization algorithms using semantic approaches,corpus-based thesaurus and WordNet[J].Expert Systems With Applications,2012,39(1):765-772.
[17]Han Jiawei,Kamber M.数据挖掘:概念与技术[M].范明,孟小峰,译.2 版.北京:机械工业出版社,2007:263-266.
猜你喜欢
英语世界(2023年11期)2023-11-17 09:24:50
英语世界(2023年10期)2023-11-17 09:19:18
英语世界(2023年6期)2023-06-30 06:29:38
英语世界(2022年9期)2022-10-18 01:11:48
开放教育研究(2020年2期)2020-03-31 01:54:14
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
