
基于语料库的汉语词法能产性量化研究:以“儿、子、性、化、家”的派生为例*
2015-11-12 01:10张未然
云南师范大学学报(对外汉语教学与研究版) 2015年4期
张未然
(北京大学 对外汉语教育学院,北京100871)
一、引 言
词汇的构成是有规则的,例如“风声、雨声、雷声、铃声、枪声、歌声、笑声”等词都遵循“表示事物或行为的名词或动词+声”这一构词规则。研究发现,二语学习者在遇到生词时常常会利用构词规则或构词法线索来猜测词义,也就是说,构词规则或者构词法线索能够帮助学习者理解甚至产出新的词汇。
不过,汉语中有些构词规则可以不断构造新词,是能产的,如“X性”,而有些构词规则丧失了活力,已经不再能产,如“X头”。与后者相比,在对外汉语词汇教学中,前者能够帮助学习者根据已有的构词法知识自行类推构词,利于其词汇量的扩大,因此应当成为对外汉语词汇教学的重点。
那么,究竟哪些构词规则或者词法加工过程(morphological process)是能产的,哪些是不能产的?我们需要通过对实际语料的考察才能确定。
研究词法的能产性问题,除了利于对外汉语词汇教学明确教学重点,在对外汉语教材以及学习词典的编写方面也有应用价值。以汉语学习词典的编纂为例,哪些词该收、哪些词不该收是词典编纂者需要重点考虑的问题之一,从利于学生词汇学习的角度来看,能产性高的词法规则或者词法加工过程产生的词汇,应是词典编纂者重点收录的对象。
此外,研究能产性问题,还利于推动构词法研究的进一步发展。在构词法研究中,能产性问题一直是最有争议的问题之一(Bauer 1983①Bauer L.English Word-formation.Cambridge:Cambridge University Press,1983:62.,Dominguez 2009②Domínguez J.F.Productivity in English word-formation:an approach to n+n compounding.Bern,New York:Peter Lang,2009:1.)。汉语的词法能产性研究目前还处于尚未充分发展的阶段,与西方形态学界研究词法能产性多基于语料库的研究方法不同,汉语词法的能产性研究多是对词典、典籍收词进行统计、分析(顾介鑫2010③顾介鑫,杨亦鸣.复合构词法能产性及其神经电生理学研究[J].语言文字应用,2010,(3).),研究结果受词典收词量影响较大。
本文将借助语料库对汉语中部分派生构词的能产性进行量化研究。首先,讨论几个关于词法能产性的理论问题;其次,以汉语中的词缀和类词缀“儿、子、性、化、家”的派生为例,对汉语词法加工的能产性差异进行量化统计;最后,以类词缀“家”的派生为例,进一步分析同一词法范畴内部从语义角度划分出的不同词法模式存在的能产性差异。
二、关于词法能产性的理论纠葛
能产性问题作为构词法研究中最有争议的问题之一,在主体、定义、变量性质以及量化方法等方面都引起了学界的热烈讨论。讨论汉语词法的能产性,在对具体的语言事实进行分析之前,我们有必要先厘清以上几个方面问题。
首先是词法能产性的主体,即究竟是什么有能产性。是词,是某些词缀(particular affixes),还是词法规则(morphological rules),抑或是词法加工过程(morphological processes)?对于汉语来说,把能产性的主体归结到词缀最大的问题在于忽视了复合构词的能产性,例如“整体+部分”这一复合构词模式可以衍生出“车铃、桌腿、房门、瓶盖、手指”等复合词,而复合法是汉语最主要的构词方式,所以汉语词法能产性的主体并不只是某些词缀。把能产性的主体归结到词是索绪尔(1980:234)的观点,他指出“每种语言都有能产的词和非能产的词”,“词由于本身可分解的程度不同,产生其他词的相对能力也不一样,我们可以把各个词按照这相对的能力加以分类”①索绪尔.普通语言学教程[M].北京:商务印书馆,1980:234.,但索绪尔转而又强调,单纯词是非能产的,例如“店员”(magasinier)并非由“商店”(magasin)产生,而是按照“监犯—监狱(prisonnier-prison)”这样的模型构成的,若按这一思路,能产的就是类似“监犯—监狱”这样的模型,而非某个词。Bauer(2001)认为将能产性的主体归结为词法规则或者词法加工实质上并无不同,词法规则本身就是词法加工的运行规则,二者的区别在于一强调语法另一则强调词法加工的存在②Bauer L.Morphological Productivity.Cambridge University Press,2001:13.。不过,我们认为,词法规则本身并不能产,只有其作用于实际的词法加工过程时才具有能产性,所以能产性最直接的主体应该是词法加工过程。
其次是如何界定能产性。此前已有不少学者为“词法能产性”这一术语下过定义,Rainer(1987,转引自Bauer,2001)总结了界定“词法能产性”的几种不同标准,包括所造词的数量、可用的词基数量、某一词法加工真正构成的词在可能构成的词中所占的比例、构成新词的可能性、新形式出现的可能性、某一时期新形式出现的数量等③Bauer L.Morphological Productivity.Cambridge University Press,2001:25.。能产性的定义将直接影响其计算方法,本文的“能产性”采用董秀芳(2004)的界定:“一个特定的形式在构造新词时被运用的可能性程度的大小。”④董秀芳.汉语的词库与词法[M].北京:北京大学出版社,2004:97.
再次是能产性的变量性质。有学者认为词法加工非能产即不能产,也有学者(Matthews 1974,Jackendoff 1997)认为能产性存在不同等级:非常能产、不能产、中间级(半活跃或半能产)⑤⑥Matthews P.Morphology.Cambridge:Cambridge University,1974:52.,还有学者(Bauer1992)认为能产性是一种连续变量,可在一定范围内取值⑦Bauer L.Scalar productivity and-lily adverbs.In Geert Booij and Jaap van Marle(eds).Yearbook of Morphology 1991.Dordrecht:Kluwer,1992:185~191.。我们认为,汉语中词法加工有能产和非能产之分,同时也存在程度差异,例如词缀“子”和“儿”派生时都是能产的,但二者的能产程度仍不同,通常认为“儿”的派生具有周遍性,“子”的派生则有种种限制,同时“儿”派生后生成的词的数量比“子”多,所以“儿”在派生时比“子”更能产,那么事实是否如此呢?我们将在下文进行验证。
再次,如果将能产性看作一种连续变量,那么应该如何通过量化方式衡量。大体来说,词法能产性的量化方法包括以下几类:(1)考察该词法加工产生的词的数量,由于这一方法统计的是已经存在的词的数量,所以无法说明这一词法加工是否仍有产生新词的能力;(2)考察由词法规则产生的词的数量在该词法规则可能产生的词的数量(可通过考察可能的词基数获得)中所占的比例(Aronoff 1976:36)⑧Aronoff M.Word formation in Generative Grammar.Cambridge,MA:MIT Press,1976:36.,这一方法的问题在于V和S的均不容易明确测量;(3)考察某一词法加工产生的只在语料库中出现一次的词(下文简称Hapaxes)在其产生的所有词的词频总和(token frequency)中所占的比例(p=n1/N)(Baayen and Lieber 1991①BaayenH.&Lieber R.Productivity and English derivation:a corpus-based study.Linguistics 29,1991:803.,Baayen 1992②Baayen H.Quantitative aspects of morphological productivity.In Geert Booij and Jaap van Marle (eds).Yearbook of Morphology 1991.Dordrecht:Kluwer,1992:109~149.);(4)考察某一词法范畴(morphological category,如以“—子”结尾的名词)内的Hapaxes在语料库中全部Hapaxes中所占的比例(Baayen1993)③Baayen H.On frequency,transparency and productivity.In Geert Booij and Jaap van Marle (eds).Yearbook of Morphology 1992.Dordrecht:Kluwer,1993:181~208.;(5)考察某一词法加工过程在语料库中出现的词与词典收录的词之间的数量差异(Bauer2001:156)④Bauer L.Morphological Productivity.Cambridge University Press,2001:156.。本研究我们将借鉴目前学界计算能产性较为通行的方法(3)和方法(4)。这两种计算方法互相补充,前者一般用于判定某一词法加工能产还是不能产,后者可用于为不同词法加工过程的能产性大小排序。
三、不同词缀及类词缀派生过程的能产性差异
以上我们分析了词法能产性涉及到的一些理论问题,下面我们将从汉语事实出发,借助语料库,考察汉语中不同词法加工的能产性差异。结合前人成果(吕叔湘1979⑤吕叔湘.汉语语法分析问题[M].北京:商务印书馆,1979.,徐枢1990⑥徐枢.语素[M].北京:人民教育出版社,1990.,陈光磊1994⑦陈光磊.汉语词法论[M].上海:学林出版社,1994.),本次研究我们选取有形式标记的词缀和类词缀“儿、子、性、化、家”为研究对象。语料库我们使用“国家语委现代汉语语料库”⑧语料库网址:http://www.cncorpus.org/CCindex.aspx。,其优点在于规模大(2000万字),语料分布平衡,并且已分词,带词性标注。
首先计算各词缀和类词缀派生的能产性系数(the degree of productivity P),具体操作方法如下:(1)依次检索出带这5个词缀和类词缀的语料,只保留其所构成的词语,将句子的其他部分删掉;(2)利用Excel软件统计带有该词缀或类词缀的Hapaxes的数量(n1)以及带有该词缀或类词缀的词频总和(N);(3)根据Baayen&Lieber(1992)⑨Baayen H.Quantitative aspects of morphological productivity.In Geert Booij and Jaap van Marle(eds).Yearbook of Morphology 1991.Dordrecht:Kluwer,1992:109~149.提出的p=n1/N公式计算n1在 N中所占比例,即可得出各派生过程的能产性系数。例如词缀“儿”语料库中共出现了4311次,其中973个词都只出现了一次,那么词缀“儿”派生的能产性系数为0.226。
最终统计结果如表1所示:
⑩“词频”指的是指的是“词出现的次数”,例如语料库中“宝贝儿”一词出现了3次,那么它的词频就记为3。将该词法加工所构成的词出现的所有次数相加即为词频总和。
根据表1的统计结果,“儿、子、性、化、家”派生的能产性系数分别为0.226、0.353、0.159、0.045和0.035。目前来看,“儿”的能产性系数最高,“家”的能产性系数最低。
不过,Bayyen(1992)指出,确定一个词法加工过程的能产性,除了计算其能产性系数以外,还必须补充考察其所造的词语数量,两者是互相补充的。这一能产性被称为“总体能产性”(global productivity)①Baayen H.Quantitative aspects of morphological productivity.In Geert Booij and Jaap van Marle (eds).Yearbook of Morphology 1991.Dordrecht:Kluwer,1992:109~149.。因此,综合这5个词缀和类词缀派生的能产性系数以及造词数量,我们可以绘制出其派生的总体能产性P*分布图,如图1所示:
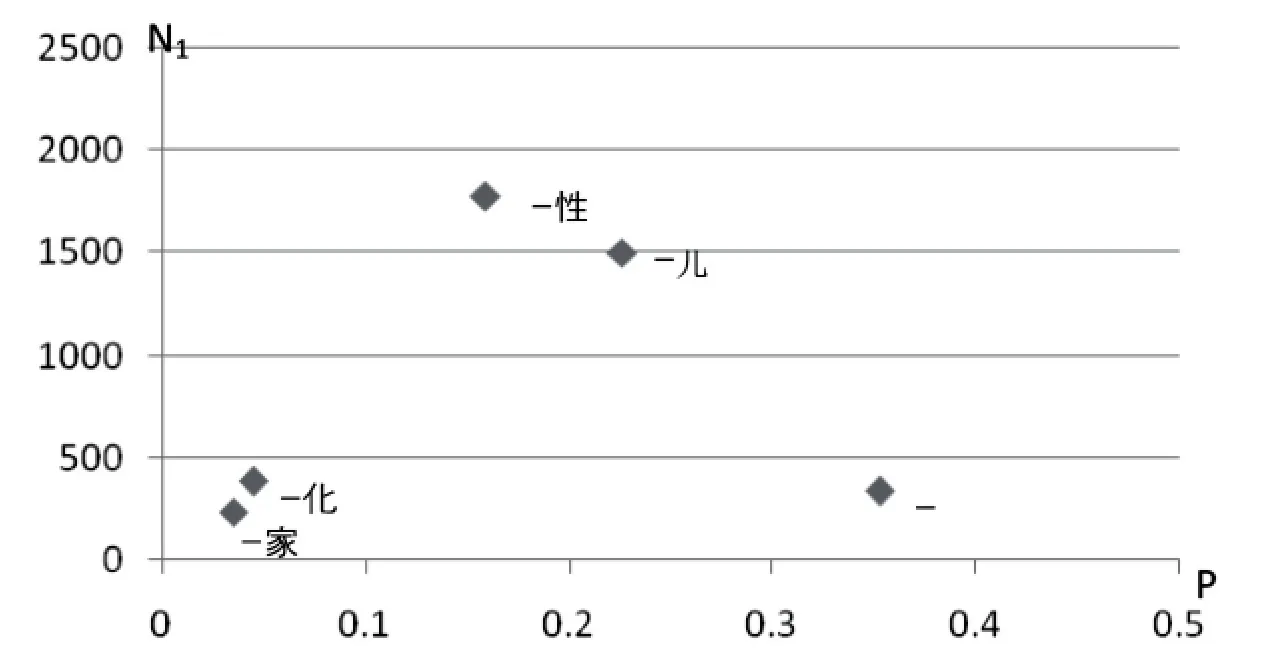
图1 不同词法加工过程的总体能产性P*
图1中“—子”、“—儿”、“—性”纵横坐标取值均高于“—化”和“—家”,说明“子”、“儿”、“性”派生时均比“化”和“家”派生时的总体能产性更高。不过,由于总体能产性需要综合考虑能产性系数和造词数量,“—子”派生的能产性系数高于“性”和“儿”派生的能产性系数,但“性”派生造词的数量则多于“儿”和“子”,所以我们此时还无法得出它们三者究竟谁的总体能产性更高的结论。
解决这一问题的方法是,将语料库中全部的Hapaxes看作一个整体,考察不同词法加工过程所派生出的Hapaxes在其中所占的比例,即可得到其“受hapaxes制约的能产性系数”(the hapaxes-conditioned degree of productivity)(P’②Bayyen在原文中使用的是P*,这里为了与总体能产性P*相区分,使用P’。=n1,E,t/h)(Bayyen 1993)③Baayen H.On frequency,transparency and productivity.In Geert Booij and Jaap van Marle(eds).Yearbook of Morphology 1992.Dordrecht:Kluwer,1993:181~208.。由于语料库中 Hapaxes的数量是固定的,也就是说,某一词法加工的能产性大小与其在语料库中派生出的Hapaxes数量成正比。
由此我们就可得出词缀和类词缀“—儿”、“—子”、“性”、“—化”、“—家”派生的能产性排序:
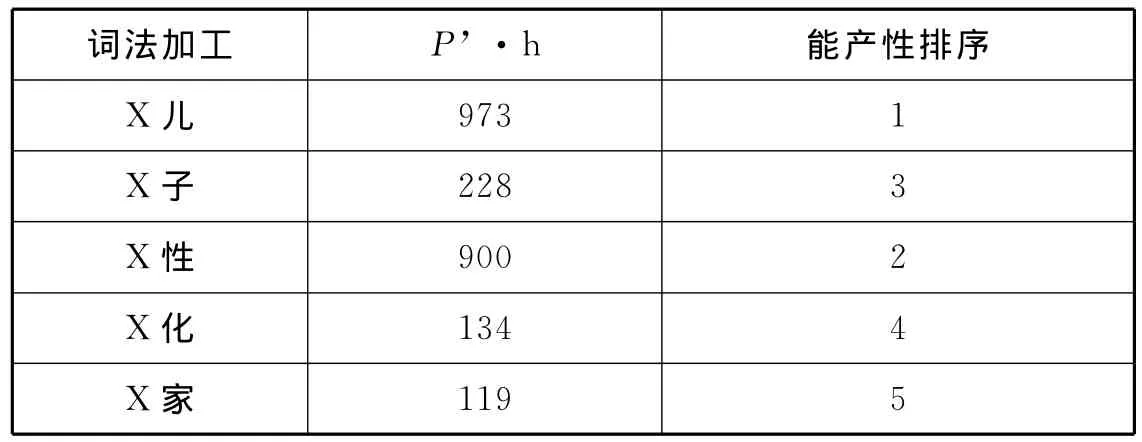
表2 不同词法加工过程的能产性排序
综合全部统计结果,我们可以得出以下结论:
在词缀和类词缀“儿、子、性、化、家”的派生中,“—儿”、“—子”、“—性”的派生相对能产,“—化”、“—家”的派生相对不能产。
词缀和类词缀“儿、子、性、化、家”派生的能产性排序依次为P’(X儿)>P’(X性)>P’(X子)>P’(X化)>P’(X家)。
“儿”作为汉语中最常用的后缀,可以附加在名词、动词、形容词、数词、量词、代词、副词等多种词类之后,表达轻松、亲切、活泼的口语色彩。其构词时的限制较小,既可以附加在单音节之后(如“头儿”),也可以附加在双音节之后(如“板凳儿”)(董秀芳2004:99)①董秀芳.汉语的词库与词法[M].北京:北京大学出版社,2004.,因此参与构词时能产性很高。
词缀“子”和类词缀“性”相比,前者的形成时间可追溯到先秦时期,但是目前已经处于萎缩阶段(刘宇菲2011)②刘宇菲.词缀“子”的形成与发展[D].宁波大学硕士学位论文,2011.,而后者属于汉语中的新兴类词缀,虽然直到现在也未完全词缀化(主要体现在其参与构词时仍可表义),但发展十分迅速,根据李蓓(2001)的统计,类词缀“性”在1979年第1期的《读书》杂志中构成的词语仅为55个,1988年第1期达到82个,1998年第一期则达到177个③李蓓.现代汉语新兴类词缀研究[D].辽宁师范大学硕士学位论文,2004.。能产性考察的是词缀在参与构造新词时可被运用的可能性,因此,作为一个处在萎缩阶段的词缀,“子”派生时能产性低于处于发展阶段的“性”也就不难理解了。
以上我们考察了不同词法加工的能产性差异,那么在同一种词法加工内部是否存在能产性的差异呢?下面我们将以类词缀“家”的派生为例,进一步分析其能产性的内部差异。
既然能产性可以是某一词法范畴(如以词缀“家”结尾的名词)内的Hapaxes在整个语料库中的Hapaxes所占的比例,那么,如果我们将该词法范畴的Hapaxes看作一个整体,考察其下所涉的各次类词法范畴在其中所占的比例,就可以同样得出各次类词法范畴能产性的排序。
根据我们在“国家语委现代汉语语料库”中检索出的仅出现一次的带词缀“家”的词,首先按照词基的不同语法属性,可划分“V—家>N(指人)”、“N—家>N(指人)”两类次级词法范畴;再根据词基以及所造词的语义划分出三级词法范畴,共5类:V—家>在某一领域有一定成就的人、N(学科名)—家>在某一领域有一定成就的人、N(科学或艺术领域)—家>在某一领域有一定成就的人、人称N—家>一类人、N(贬义)—家>专门从事某种(不好的)活动的人;最后统计出语料库中各三级词法范畴中Hapaxes的数量(n1,E,t),分别计算它们在语料库里带词缀“—家”的Hapaxes(根据表1统计,共119个)中所占的比例,即可得出各三级构词范畴的能产性排序。
具体统计结果如表3所示:

表3 同一构词范畴的能产性内部差异
④ 如“学生家”、“姑娘家”、“娃娃家”等,这一类词中的“家”已经是标准意义上的词缀了,表现为其意义的虚化以及语音的弱化。
根据表3的统计结果,能产性最高的为“学科名+家>表示在某一领域有一定成就的人”,其后依次是“N(科学或艺术领域)—家>在某一领域有一定成就的人”、“V—家>在某一领域有一定成就的人”、“人称N—家>一类人”,“N(贬义)—家>专门从事某种(不好的)活动的人”的能产性最低。
实际上,类词缀“家”可以放在几乎所有学科名的后面,例如“词汇学家、天文学家、医学家、力学家”等,这一构词加工过程具有周遍性,因此能产性最高。而“N(贬义)—家>专门从事某种(不好的)活动的人”最不能产,这是因为词语的贬义色彩与“家”语素常带的褒义色彩不一致,因此能产性最低。
这说明,即使在同一词法加工过程中,受词基和派生词的语义影响,也存在能产性的内部差异。
四、结 语
我们对汉语中的常用词缀和类词缀“儿、子、性、化、家”派生构词的量化研究,证明了汉语中不同词法加工(派生)存在能产性的差异,P’(X儿)>P’(X性)>P’(X子)>P’(X化)>P’(X家)。通过对类词缀“家”派生构词的进一步研究,发现在同一类词法范畴内部也存在能产性差异,“学科名+家>表示在某一领域有一定成就的人”的能产性最高,“N(科学或艺术领域)—家>在某一领域有一定成就的人”、“V—家>在某一领域有一定成就的人”、“人称N—家>一类人”能产性次之,“N(贬义)—家>专门从事某种(不好的)活动的人”的能产性最低。
本文的量化研究主要针对汉语的派生构词,在汉语中占绝对优势的复合构词的能产性如何借助语料库进行量化研究是未来仍需进一步探索。除此之外,在面向对外汉语教学的词法能产性研究方面,我们还可从以下角度展开:通过实证研究证明词法的能产性是否会对留学生的词汇识别产生影响;如果词法的能产性会对留学生的词汇识别产生影响,汉语中最能产的、能够促进留学生词汇习得的词法模式(复合、加缀)有哪些;如何利用能产的词法模式更好地教学等。
猜你喜欢
海外文摘·学术(2022年3期)2022-05-07
红河学院学报(2021年4期)2021-11-19
外语学刊(2021年1期)2021-11-04
鸭绿江·下半月(2019年7期)2019-11-05
小说月刊(2017年16期)2017-12-01
科技经济市场(2017年5期)2017-09-16
西夏研究(2017年1期)2017-07-10
长江学术(2016年3期)2016-08-23
中学语文(2012年34期)2012-08-15
中学生英语高效课堂探究(2011年4期)2011-07-07
