
基于遗传算法的正则表达式规则分组优化
2015-06-24 11:49蔡良伟
深圳大学学报(理工版) 2015年3期
蔡良伟,程 璐,李 军,李 霞
1) 深圳大学信息工程学院,深圳 518060;2)清华大学信息技术研究院,北京 100084

【电子与信息科学 / Electronics and Information Science】
基于遗传算法的正则表达式规则分组优化
蔡良伟1,程 璐1,李 军2,李 霞1
1) 深圳大学信息工程学院,深圳 518060;2)清华大学信息技术研究院,北京 100084
为解决正则表达式匹配问题,提出一种基于正态自适应遗传优化的改进正则表达式分组算法.根据迭代次数的变化,利用正态函数自适应改变交叉概率Pc和变异概率Pm, 采取最优保存策略保证最优个体不被数值大的Pc和Pm破坏.结合Becchi算法和局部寻优算法进一步优化.仿真结果表明,该算法能在全局范围内搜索到更好的解,能有效减少状态总数,降低正则表达式匹配的空间复杂度.
人工智能;正态自适应遗传算法;深度包检测;正则表达式;分组算法;网络安全
随着计算机与互联网的迅速发展,网络安全问题日益严峻.深度包检测(deep packet inspection,DPI)技术已被广泛用于各种网络安全系统中,如防火墙、入侵检测系统和防病毒网关等.传统的DPI技术采用精确字符串进行模式匹配,如AC(Aho-Corasick)[1]、Wu-Manber[2]和Sbom(set backward oracle matching)算法[3]等.但是,随着网络的不断发展,入侵特征日益复杂,传统的精确字符串已经很难满足要求,正逐渐被灵活且表达能力更强的正则表达式(regular expression, RE)所取代.RE正迅速成为描述新一代规则的主要工具,在DPI中获得了广泛应用.
正则表达式匹配通常是将其转换为等价的非确定型有限自动机(non-deterministic finite machine, NFA)或确定型有限自动机(deterministic finite machine, DFA)进行模式匹配.但考虑到匹配效率和准确率的问题,大部分应用都采用基于DFA的匹配技术来完成实时的深度包检测.然而,DFA存在着状态膨胀的问题(某些情况下,DFA状态数目甚至呈指数增长),导致消耗巨大的存储空间,甚至无法生成.因此,如何减少DFA的存储空间消耗,是实现高性能正则表达式匹配的重要问题.通过对正则表达式集合进行分组是解决这一问题的重要方法.目前,已有不少学者对此进行了研究并提出了解决方案.如Yu等[4]指出正则表达式集合的分组问题,并提出一种启发式的分组算法——Fang Yu算法.在计算正则表达式两两之间的冲突后,不断地将与当前分组中冲突作用最少的未分组的正则表达式加入到当前分组,直到该分组的DFA状态数目超过给定的某个阈值,就将其加入到下一分组,最终,得到整个正则表达式集合的分组情况.徐乾等[5]提出了一种基于正则表达式的压缩算法.Becchi等[6-8]提出一种对模式集进行自动分组的策略,适用于合并后的DFA状态数过大的情况,该策略是指循环二分模式集,直到每个分组的DFA状态数都小于预设的阈值σ. 肖武德[9]通过计算正则表达式两两之间的冲突比率,将低于某个数值的表达式提取出来,对剩下的表达式分组,然后将事先提取出来的表达式合理地加进去.张树壮等[10]提出基于猜测-验证的匹配方法.罗青林等[11]通过采集网络数据流,对流量进行统计分析,根据计算出来的概率进行分组.文献[12]提出DFA构造中基于正则表达式相似性的分组算法.通过定义正则表达式相似性的概念和公式,避免了DFA状态剧烈地膨胀,从而有效地生成DFA.文献[13]提出一种基于划分算法的正则表达式分组算法.该算法能够减少DFA状态总数并提高正则表达式匹配性能,从而适于多核处理器.魏强等[14]在Fang Yu算法的基础上,提出基于图划分的正则表达式分组算法.柳厅文等[15]证明了当冲突非负和冲突独立时,正则表达式集合的最优k分组问题是NP-Hard的,且基于局部搜索思想,提出GRELS(grouping regular expression with local searching)分组算法.蔡良伟等[16]提出基于蚁群优化的改进正则表达式分组算法(grouping regular expression with ant colony optimization,GRE-ACO).该算法根据正则表达式分组特点,构建新的信息素更新策略,有效减少了DFA状态总数.付哲等[17]提出一种深度包检测中基于正则表达式的智能分组算法,该算法是遗传算法(genetic algorithm,GA)和蚁群算法相混合的新的分组算法,能有效解决状态爆炸问题,并在内存消耗和组数之间取得全局最优折衷.然而,现有的分组方法效果并不理想,仍有待进一步提升.如Fang Yu算法分组思想简单,易于实现,但搜索范围有限,容易陷入局部解;Becchi算法每次都是按序对正则表达式进行循环二分组,无法在全局范围内得到最优解,有一定的局限性;GRELS分组算法在解决思路上与Fang Yu算法类似,但充分利用了冲突信息并采取了更有效的策略,分组效果相对较好.
本研究提出基于自适应遗传优化的改进正则表达式分组算法(regular expression grouping based on normal adaptive genetic algorithm,REG-NAGA),采用固定分组数目,利用正态函数自适应地改变整个种群的交叉概率Pc和变异概率Pm,并且融合了Becchi算法和局部寻优策略的思想,在全局范围内搜索正则表达式模式集规则分组的最优解.
1 正则表达式分组与GRELS算法
1.1 正则表达式分组
1.1.1 状态膨胀
状态膨胀是指将2条或2条以上的正则表达式合并生成的DFA状态总数,大于其各自单独生成DFA的状态数目之和.假设有2条表达式R1和R2, 它们各自生成的DFA状态数目分别记作size(R1)和size(R2), 合并后的表达式为R12, 生成的合并DFA状态数目记作size(R12),若满足
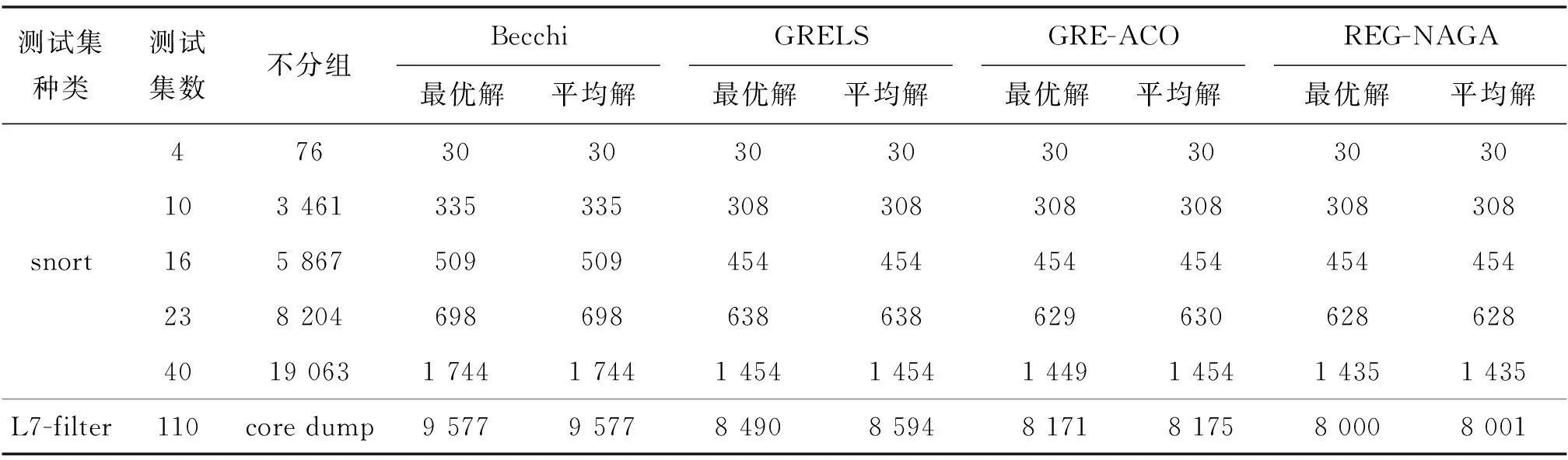
size(R1)+size(R2) (1) 即为状态膨胀. 有些正则表达式生成合并DFA时会急剧膨胀,最坏情况下,甚至可能呈指数增长.如正则表达式r1=(.*ab .*cd)和r2=(.*ef .*gh),它们各自的DFA状态数均为5,如图1[4],将这2条正则表达式生成合并DFA时,状态数膨胀到16,如图2[4].因此,研究正则表达式分组问题的目标是尽量减少DFA的状态数目,即各分组的DFA状态数目总和尽可能多地小于不分组时的DFA状态数目. 图1 正则表达式r1和r2对应的DFA[4]Fig.1 DFA of r1 and DFA of r2[4] 图2 正则表达式对应的DFA[4]Fig. 1.1.2 评价指标 评价正则表达式集合分组效果的指标通常包括DFA的状态总数和分组数目. 1) DFA状态总数主要考虑DFA的内存空间消耗,它主要取决于DFA的状态总数,因此,减少DFA状态总数,就能达到减小DFA所占存储空间的目的,为生成和使用DFA提供便利. 2) 分组数目主要考虑DFA的匹配速度.由于分组数决定了处理1个字符时的状态转移表的访问次数,因此,它成为影响DFA匹配速度的关键因素.分组数目越少,DFA的匹配效率就越高,反之,就越低. 显然,DFA的状态总数和分组数目这2个指标是互相矛盾的.通常分组数目越多,则DFA状态总数就越少;反之,DFA状态总数就越多. 1.2 GRELS算法 1.2.1 分组思想 GRELS算法的分组策略是:将n条正则表达式随机分为k组,对于当前的分组结果,根据式(2)[15],计算每个分组中的冲突状态数F(m,i)(1≤m≤k), 依次判断每个分组中是否存在1条表达式,把它从当前分组中加入到另一分组中会减少冲突状态数目,如果存在,就将它移动到减少冲突数目最多的分组中,然后进行下一次判断;如果不存在,就不移动并进行下一次判断.假设ri和rj分别表示第i和j条表达式,则 (2) 其中,Rm表示第m组正则表达式集合;Mij表示ri和rj合并后的冲突状态数目,满足式(3)[15] Mij=Sij-Si-Sj (3) 其中,Si、Sj和Sij分别表示ri、rj和ri与rj合并后的DFA状态数目. 1.2.2 分组步骤 假设正则表达式集合的规模为n, 固定分组数目为k, 设置1个布尔型变量nochange,并初始化为true. 1)计算正则表达式两两之间的冲突状态数目Mij(1≤i,j≤n), 得到n阶冲突矩阵M, 将n条正则表达式随机不重复地分配到k个分组中,记为{R1,R2,…,Rm,…,Rk}, 其中,Rm(1≤m≤k)表示第m个分组的正则表达式集合. 2)在1个while无限循环中,将nochange赋值为true. 3)按序依次将每1条正则表达式ri尝试加入到k个分组中,根据式(2)和式(3),分别计算F(m,i)(1≤m≤k), 求出使得数组F中元素最小的下标t, 判断ri是否在分组Rt中,若不在,则将ri从原分组中移动到Rt中,并令nochange=false;否则,不移动,然后进行下一次尝试. 4)若i>n且nochange=true,则跳出while循环; 否则, 返回步骤2),并继续下一次while循环. 2.1 遗传算法 1975年,Holland[18]提出的遗传算法(genetic algorithm,GA)是模拟自然界中生物遗传进化过程的一种全局优化算法.GA通常指简单遗传算法(simple genetic algorithm,SGA).SGA因其具有原理简单、易于实现且应用效果明显等优点被广泛用于函数优化、组合优化、自动控制及人工生命等领域.但是,SGA并不能保证全局最优收敛,在求解大规模复杂的实际问题时常出现早熟收敛现象,因此,避免早熟收敛现象是遗传算法研究的主要课题之一. 2.2 自适应遗传算法 基于SGA,Srinivas等[19]提出一种根据适应度动态改变交叉概率Pc和变异概率Pm的自适应遗传算法(adaptive genetic algorithm,AGA).在AGA中,Pc和Pm随个体适应度在种群平均适应度和最大适应度之间进行线性调整.当适应度越接近最大适应度时,Pc和Pm越小;反之,Pc和Pm越大;当适应度值等于最大适应度时,Pc=Pm=0. 然而,在AGA中,当适应度等于最大适应度时,Pc=Pm=0,容易产生局部最优解.因此,需对AGA进一步改进[20-26]. 为克服SGA的早熟收敛和AGA易陷入局部最优解的缺点,本研究提出一种改进的自适应遗传算法——REG-NAGA.该算法综合考虑了快速收敛和全局收敛这2个要求,采取最优保存策略保证最优个体不被大的Pc和Pm破坏,根据正态函数构造新的Pc和Pm计算公式,并对它们进行优化. 2.2.1 遗传操作的改进 适应度函数是用来判断群体中个体好坏程度的指标,它是根据所求问题的目标函数来进行评估的.通常,适应度函数就等于目标函数.本研究中的目标函数是各分组的DFA状态数目之和.假设正则表达式集合R的k个分组为{R1,R2,…,Rk}, 适应度函数为 (4) 其中,f为适应度; size(Ri)为第i个分组的正则表达式集合的DFA状态数目. 本研究的目标是尽量减少DFA状态总数,即使目标函数(各分组的DFA状态数目之和)越小越好,亦即适应度越小越好.这里,与通常情况有所不同, 适应度值越小, 种群中的个体就越适应环境. 编码采用序号编码,即自然数编码.每个个体用由自然数组成的位串来表示,假设有8条正则表达式, 个体编码对应序号1~8的全排列, 如图3. 图3 染色体序号编码表示Fig.3 Representation of a chromosome number coding 遗传操作主要包括选择、交叉和变异. 1) 选择.该操作符合优胜劣汰原则,即把好的个体直接遗传到下一代或通过交叉和变异产生新个体再遗传到下一代.采用轮盘赌选择算子,根据式(5)和式(6),每个个体被选择的概率与其适应度值呈负相关. (5) (6) 其中,Pi为第i个个体被选择的概率;fi为第i个个体的适应度;fi′为中间变量;n为群体规模.显然,个体适应度越小,其被选择的概率越大;反之亦然. 2) 交叉.它是遗传算法的核心操作,即根据交叉概率将2个父代个体的部分基因进行替换重组生成新个体的操作.通过交叉,可使遗传算法的搜索能力得到相当大的提高.本研究采用多点交叉,如图4,其中,带阴影的数字代表交叉点. 图4 多点交叉Fig.4 Multi-point crossover 3)变异.它遗传算法中的辅助操作,是指根据变异概率对群体中的父代个体的某些基因进行变动而生成新个体的操作.引入变异操作的原因是:①使遗传算法具有局部的随机搜索能力,当遗传算法通过交叉已接近最优解邻域时,利用变异可以加速向最优解收敛,此时,变异概率应取较小值;②使遗传算法能维持群体多样性.防止出现早熟收敛现象,此时,变异概率应取较大值.通常有互换变异和逆序变异2种方式,如图5和图6,其中,带阴影的数字代表变异点. 图5 互换变异Fig.5 Swap mutation 图6 逆序变异Fig.6 Reverse mutation 选择采取最优保存策略,即每一代的最优个体被选择下来进行交叉和变异,如果交叉、变异之后的结果比之前的结果好,就保留之后的结果;否则,就保留之前的结果.这里,主要研究对交叉和变异操作的改进,即对交叉概率Pc和变异概率Pm计算公式的改进. 改进方案如下: 根据式(7)和式(8),Pc和Pm随着迭代次数进行动态非线性自适应调整.整体呈递减的趋势,即迭代次数越大,Pc和Pm越小.令阈值σ=T/3, 则 0≤t≤T(7) 0≤t≤T(8) 其中,t为迭代次数;T为最大的进化代数;Pc、Pcmax和Pcmin分别表示交叉概率、交叉概率最大值和交叉概率最小值;Pm、Pmmax和Pmmin分别表示变异概率、变异概率最大值和变异概率最小值. 由式(7)和式(8)可得Pc和Pm随迭代次数t的变化情况,如图7. 图7 交叉概率和变异概率的自适应调整曲线Fig.7 Adaptive adjustment figure of crossover probability and mutation probability 2.3 Becchi算法 2.3.1 分组思想 Becchi算法的分组策略是:通过设置阈值σ, 然后不断循环二分模式集,直到每个分组的DFA状态数目都小于阈值σ. 即满足 size(group_current)<σ (9) 其中, size()为正则表达式规则集的DFA状态数;group_current表示下一条正则表达式加入当前组后,当前组中的正则表达式集合;阈值σ满足 σ=η{size(group_curr_before)+size(rj)} (10) 这里,η为阈值系数;rj为插入当前组中的下1条表达式;group_curr_before为在表达式rj插入当前组前,当前组中的正则表达式集合. 2.3.2 分组步骤 将正则表达式集合按顺序排成一列,作为第1个未分组的集合. 1) 取未分组的正则表达式集合中的第1条,作为当前组中的第1条. 2) 按序依次遍历未分组集合中的每一条未被访问过的正则表达式,尝试加入到当前组中,如果满足式(9),就加入;否则,就把该条表达式放入下一未分组正则表达式集合中. 3)判断未分组的正则表达式集合是否为空,如果为空,就输出分组结果,否则,就返回步骤1),继续进行分组. 2.4 局部优化 由于遗传算法局部搜索能力不强,虽然能较快到达最优解附近,但要取到最优解需要花费很长的时间甚至无法取到,因此,要加入局部优化算法,来增强局部搜索能力.优化思想是:尝试对已分好组的正则表达式集合进一步优化,依次取各个分组中的每一条表达式,尝试加入到另一个分组,判断DFA状态总数是否减少,如果减少,就把该条正则表达式加入到使DFA状态总数减少最多的分组中;否则,就取下一条正则表达式进行判断. 2.5 REG-NAGA算法框架 REG-NAGA算法流程图如图8. 图8 REG-NAGA算法流程Fig.8 REG-NAGA algorithm REG-NAGA算法实现的具体步骤为: ① 输入.设n为正则表达式条数,最大进化代数为T, 种群规模为N, 交叉概率的最小值为Pcmin、最大值为Pcmax,变异概率的最小值为Pmmin、最大值为Pmmax,阈值系数为η,多点交叉的交叉点数为pot,最大分组数为k. ② 初始化种群.对代数计数器进行初始化,即设t=0. 随机生成N个个体作为初始种群P(0);相应地随机生成N个个体的分组情况作为初始分组G(0). 计算冲突矩阵Mn×n(第i行第j列元素Mij根据式(3)得到). ③ 个体评价.计算种群P(t)中每个个体的适应度fi.将最小适应度fmin所对应的个体及分组情况保留下来. ④ 轮盘赌选择.当前群体中适应度较小的个体更有机会遗传到下一代.个体i被选择的概率为pi,累积概率为qj, 循环N次,每次随机生成一个[0,1]区间的随机数,记第i个随机数为numi, 判断numi≤q1, 若成立,则选择第1个个体参与下面的操作;否则,继续判断qj ⑤ 自适应交叉.循环N次,每次随机生成一个[0,1]内的随机数,记第i个随机数为numi,根据交叉概率Pc的公式, 判断numi ⑥ 自适应变异.循环N次,每次随机生成一个[0,1]内的随机数,记第i个随机数为numi,根据变异概率Pm的公式,判断numi ⑦ Becchi算法.对选择、交叉和变异后得到的种群中的每个个体使用固定分组的Becchi算法.通过设置阈值σ,不断的循环二分模式集,得到k个分组情况.另外,设置禁忌数组tabu[n],记录每次添加到当前分组的正则表达式序号,判断tabu.size() ⑧ 局部优化.对已分好组的正则表达式集合,进行进一步优化.针对Becchi优化后得到的种群中的每个个体的k个分组进行局部优化,即依次将每个分组中的每条正则表达式尝试加入到另一个分组中,判断DFA状态总数是否减少,若减少,则将该条正则表达式加入到使DFA状态总数减少最多的分组中;否则,进行下一次尝试.然后判断最优个体是否进一步优化,若已优化,则更新最优个体为相应的值;否则,保持原值不变.由于局部优化是以牺牲时间复杂度为代价来换取DFA状态总数的减少,因此,如果对效率要求较高,就可以只对最优个体进行局部优化. ⑨ 终止条件判断.循环代数t′=t+1, 其中t为上一轮循环代数,t′为当前循环代数.判断t′ 为验证REG-NAGA的有效性,本实验分别从snort和L7-filte两个开源系统中抽取若干条正则表达式作为测试集.以Becchi开源正则表达式匹配引擎(Becchi Michela.Regular expression processor.http: //regex.wustl.edu/)为工具生成DFA.实验环境为Intel Pentium(R)Dual-Core cpu E5800 @3.20 GHz,2 GB内存,操作系统为ubuntu10.04.设置交叉概率的最小值Pcmin=0.65, 最大值Pcmax=0.90; 设置变异概率的最小值pmmin=0.1,最大值pmmax=0.3;设置阈值系数η=1.0.对每个规则集的各种算法都进行5次实验,得到最优解和平均解. 表1为分别从snort和L7-filter测试集中抽取若干条规则的不同实验的数据汇总,包括不分组时的DFA状态总数,采用Becchi算法、GRELS算法、GRE-ACO算法和REG-NAGA各自进行5次实验得到的最优解和平均解. 表1 实验结果比较Table 1 Comparison of experimental results for several algorithms 由表1可知: 1)Becchi算法分组结果固定,但分组效果并不理想;GRELS算法通过对已随机分为k组的正则表达式集合进行局部搜索,因此,得到的分组结果是局部最优的,无法收敛到全局最优解.另外,在一定程度上,它的解依赖于初始分组数k及初始分组结果;GRE-ACO算法是基于蚁群优化的分组算法,每次均能收敛到一个比较稳定的值. 2)REG-NAGA是一种基于遗传算法的规则分组优化算法,该算法通过自适应调整交叉、变异概率,充分利用遗传算法的全局收敛性,并融合局部寻优的思想,使每次实验均能收敛到一个相当稳定的全局较优解.对于中小规模的测试集snort,采用REG-NAGA所得到的DFA状态总数都比采用其他3种算法(Becchi算法、GRELS算法以及GRE-ACO算法)的更优.当规则集数目较小时,差别为0;随着规则集数目的增多,差别越来越明显;而对于大规模的测试集L7-filter,REG-NAGA所获得的DFA状态总数要明显优于其他3种算法. 3)Becchi算法的鲁棒性最强.REG-NAGA的鲁棒性优于GRELS算法,在处理snort测试集时,两者的鲁棒性均很强,每次均能收敛到一个相当稳定的全局较优解;但在处理大规模的L7-filter测试集时,REG-NAGA要优于GRELS算法.此时,GRELS算法每次求得的解几乎都不同,鲁棒性较差;REG-NAGA的鲁棒性也优于GRE-ACO算法,在处理snort测试集时,当规则集数目较小时,两者的鲁棒性均很强,但随着规则集数目的增多,GRE-ACO的稳定性越来越差;然而对于大规模的测试集L7-filter,GRE-ACO算法相对较稳定,略差于REG-NAGA. 图9为23条snort测试集的DFA状态总数收敛曲线图.由图9可知,随着迭代次数的递增,DFA状态总数呈递减趋势,当迭代次数为3时,DFA状态总数为628,此后维持该值不变.即经过3代运行基本能收敛到问题的解.由此说明,REG-NAGA能较快的收敛到全局较优解. 图9 DFA状态总数收敛曲线图Fig.9 Convergent graph of the total number of DFA states 为解决多正则表达式生成合并DFA的状态膨胀问题,提出一种新算法——基于正态自适应遗传优化的改进正则表达式分组算法.该算法通过自适应的改变种群的交叉和变异概率,采用最优保存策略,并融合Becchi算法及局部优化算法来进一步优化.实验结果表明,该算法充分利用遗传算法的全局收敛性,能有效减少状态总数,降低正则表达式匹配的空间复杂度,在处理大规模测试集时,能快速收敛到全局最优解,具有很强的鲁棒性. / References: [1] Aho A V,Corasick M J. Efficient string matching: an aid to bibliographic search[J].Communications of the ACM, 1975,18(6): 333-340. [2] Wu S,Manber U. A fast algorithm for multi-pattern searching[R].TR-94-17.Tucson(USA):University of Arizona,1994. [3] Allauzen C,Crochemore M,Raffinot M. Factor oracle: a new structure for pattern matching[C]// SOFSEM’99: Theory and Practice of Informatics.Berlin: Springer,1999: 295-310. [4] Yu F,Chen Z F,Diao Y,et al.Fast and memory-efficient regular expression matching for deep packet inspection[C]// Proceedings of the 2006 ACM/IEEE symposium on Architecture for networking and communi-cations systems.New York(USA):Association for Computing Machinery,2006:93-102. [5] Xu Qian,E Yuepeng,Ge Jingguo,et al.Efficient regular expression compression algorithm for deep packet inspection[J].Journal of Software,2009,20(8): 2214-2226.(in Chinese) 徐 乾,鄂跃鹏,葛敬国,等.深度包检测中一种高效的正则表达式压缩算法[J].软件学报,2009,20(8): 2214-2226. [6] Becchi M,Cadambi S.Memory-efficient regular expression search using state merging[C]// The 26th IEEE International Conference on Computer Communications.Anchorage(USA):IEEE Press,2007:1064-1072. [7] Becchi M, Crowley P. A hybrid finite automaton for practical deep packet inspection[C]// Proceedings of the ACM CoNEXT Conference.New York(USA):Association for Computing Machinery,2007,1:1-12. [8] Becchi M, Franklin M, Crowley P. A workload for evalu-ating deep packet inspection architectures[C]// IEEE International Symposium on Workload Characterization. Seattle (USA): IEEE Press , 2008: 79-89. [9] Xiao Wude.An efficient regular expression grouping algorithm[J].Network and Computer Security,2010(4):57-59.(in Chinese) 肖武德.一种正则表达式的高效分组算法[J].计算机安全,2010(4):57-59. [10] Zhang Shuzhuang,Luo Hao,Fang Binxing,et al.An efficient regular expression matching algorithm for network security inspection[J].Journal of Computers,2010,10: 1976-1986.(in Chinese) 张树壮,罗 浩,方滨兴,等.一种面向网络安全检测的高性能正则表达式匹配算法[J]. 计算机学报,2010,10: 1976-1986. [11] Luo Qinglin.Algorithms to speeding up multiple regular expressions matching for application traffic classification[D]. Beijing:Capital Normal University,2011.(in Chinese) 罗青林.适合应用层协议分类的多正则表达式匹配方法研究[D].北京:首都师范大学,2011. [12] Yao Tie,Xu Qiang,He Jin.A grouping algorithm based on regular expression similarity for DFA construction[C]// IEEE 13th International Conference on Communication Technology(ICCT).Jinan(China):IEEE Press,2011:671-674. [13] He Gang, Wang Yang, Wu Xiaochun.A regular expression grouping algorithm based on partitioning method[C]// The 3rd IEEE International Conference on Network Infrastructure and Digital Content (IC-NIDC).Beijing (China):IEEE Press,2012:271-274. [14] Wei Qiang,Li Yunzhao,Chu Yanjie.Regular expression grouping algorithm based on graph partitioning[J].Computer Engineering,2012,38(18):137-139.(in Chinese) 魏 强,李云照,褚衍杰.基于图划分的正则表达式分组算法[J].计算机工程,2012,38(18):137-139. [15] Liu Tingwen,Sun Yong,Bu Dongbo,et al.1/(1-1/k):optimal algorithm for regular expression grouping[J].Journal of Software,2012,23(9):2261-2272.(in Chinese) 柳厅文,孙 永,卜东波,等.正则表达式分组的1/(1-1/k):近似算法[J].软件学报,2012,23(9):2261-2272. [16] Cai Liangwei,Liu Siqi,Li Xia.Regular expression grouping algorithm based on ant colony optimization[J].Journal of Shenzhen University Science and Engineering,2014,31(3):279-285.(in Chinese) 蔡良伟,刘思麒,李 霞,等.基于蚁群优化的正则表达式分组算法 [J].深圳大学学报理工版,2014,31(3):279-285. [17] Fu Zhe, Wang Kai, Cai Liangwei,et al.Intelligent grouping algorithms for regular expressions in deep inspection[C]// The 23rd International Conference on Computer Communication and Networks (ICCCN).Shanghai (China):IEEE Press,2014:1-8. [18] Holland J H.Adaptation in natural and artificial systems:An introductory analysis with applications to biology,control,and artificial intelligence[M].Ann Arbor(USA):The University of Michigan Press,1975. [19] Srinivas M,Patnaik L M.Adaptive probabilities of crossover and mutation in genetic algorithms[J].IEEE Transactions on Systems,Man and Cybernetics,1994,24(4):656-667. [20] Xing Yingjie, Chen Zhentong, Sun Jing,et al.An improved adaptive genetic algorithm for job-shop scheduling problem[C]// The 3rd International Conference on Natural Computation.Haikou(China):[s.n.],2007,4:287-291. [21] Sun Zhongyue,Guan Zhongliang, Wang Qin.An improved adaptive genetic algorithm for vehicle routing problem[C]// International Conference on Logistics Systems and Intelligent Management.Harbin(China):Springer,2010,1:116-120. [22] Wang Fujun,Li Junlan,Liu Shiwei,et al.An improved adaptive genetic algorithm for image segmentation and vision alignment used in microelectronic bonding[J].IEEE/ASME Transactions on Mechatronics,2014,19(3):916-923. [23] Hu Baofang,Sun Xiuli, Li Ying, et al.An improved adaptive genetic algorithm in cloud computing[C]// The 13th International Conference on Parallel and Distributed Computing, Applications and Technologies (PDCAT).Beijing:IEEE Press,2012:294-297. [24] Wang Wanliang,Wu Qidi,Song Yi.Modified adaptive genetic algorithms for solving job-shop scheduling problems[J].System Engineering Theory and Practice,2004,24(2):58-62.(in Chinese) 王万良,吴启迪,宋 毅.求解作业车间调度问题的改进自适应遗传算法[J].系统工程理论与实践,2004,24(2):58-62. [25] Shen Bin,Zhou Yingjun,Wang Jiahai.Research of job-shop scheduling problem based on self-adaptive genetic algorithm[J].Computer Application,2009,29(z2):161-164.(in Chinese) 沈 斌,周莹君,王家海.基于自适应遗传算法的job shop调度问题研究[J].计算机应用,2009,29(z2):161-164. [26] Jin Jing,Su Yong.An improved adaptive genetic algorithm[J].Computer Engineering and Application,2005,41(18):64-69.(in Chinese) 金 晶,苏 勇. 一种改进的自适应遗传算法[J].计算机工程与应用,2005,41(18):64-69. 【中文责编:英 子;英文责编:雨 辰】 2014-12-23;Accepted:2015-03-14 Regular expression grouping optimization based on genetic algorithm Cai Liangwei1†, Cheng Lu1, Li Jun2, and Li Xia1 1) College of Information Engineering, Shenzhen University, Shenzhen 518060, P.R.China 2) Research Institute of Information Technology, Tsinghua University, Beijing 100084, P.R.China An improved optimization method based on normal adaptive genetic algorithm (NAGA) is proposed to solve the matching problem of regular expression grouping (REG), in which the crossover probability and the mutation probability are adaptively changed by a normal function according to the number of iterations. And the optimal preservation strategy is used in REG-NAGA to ensure that the best individual is not destroyed by largePcandPm. Additionally, Becchi algorithm and the local optimization algorithm are integrated into REG-NAGA for further optimization. Simulation results show that REG-NAGA can search a better solution in the global scope and reduce the total number of states and the space complexity of regular expression matching effectively. artificial intelligence;normal adaptive genetic algorithm; deep packet inspection; regular expression; grouping algorithm; network security :Cai Liangwei,Cheng Lu,Li Jun,et al.Regular expression grouping optimization based on genetic algorithm[J]. Journal of Shenzhen University Science and Engineering, 2015, 32(3): 281-289.(in Chinese) TP 391;TP 393 A 10.3724/SP.J.1249.2015.03281 国家自然科学基金资助项目 (61171124) 蔡良伟(1964—),男(汉族),广东省阳江市人,深圳大学教授.E-mail:cailw@szu.edu.cn Foundation:National Natural Science Foundation of China (61171124) † Corresponding author:Professor Cai Liangwei.E-mail:cailw@szu.edu.cn 引 文:蔡良伟,程 璐,李 军,等.基于遗传算法的正则表达式规则分组优化[J]. 深圳大学学报理工版,2015,32(3):281-289.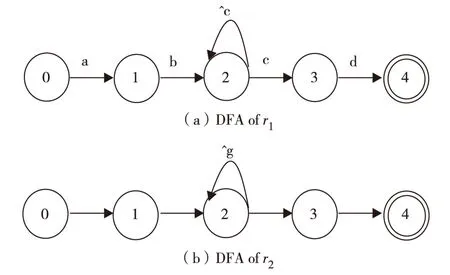


2 基于遗传算法的正则表达式规则分组优化





3 结果与分析

结 语
猜你喜欢
计算机仿真(2022年8期)2022-09-28小猕猴智力画刊(2021年6期)2021-08-05初中生世界·八年级(2019年6期)2019-08-13郑州大学学报(工学版)(2018年2期)2018-04-13小学生导刊(低年级)(2016年9期)2016-10-13小学生导刊(低年级)(2016年6期)2016-07-02中国民族医药杂志(2016年5期)2016-05-09中国塑料(2016年11期)2016-04-16作文大王·低年级(2016年3期)2016-03-11振动、测试与诊断(2014年6期)2014-03-01
