
XML结构化数字出版的特点与流程
2015-05-30 10:48:04白杰杨爱臣
出版广角 2015年5期
白杰 杨爱臣
XML结构化标引是传统出版的数字化转型核心,出版社的图书或期刊资源只有通过XML结构化转换,才是真正意义上的数字化出版,才能为实现数字产业化、知识集成化发展打下坚实基础。
一、传统出版机构XML数字转型的必要性
我国2014年6月发布的数字出版统计数据显示,我国的数字出版产业正处于高速增长阶段。另据数据统计,全国584家出版社中有256家有数字出版相关产品,但其中只有102家设有数字出版机构,这些出版社的数字化进程,以大学出版社、科学技术出版社、教育出版社为代表走在前列。虽然发展势头良好,但由于类型单一、投资规模不大,没有出现像爱思唯尔、施普林格那样的数字出版企业。大多数传统出版企业的数字出版仍然基于传统出版模式,即单纯的纸质内容数字化或电子化,只是载体形式的变化,而不是产品内容结构的变化,出版社没有对内容资源进行多媒体呈现与集成化、结构化处理[1]。
结构化是数字转型的核心,结构化的首要环节是建立数字化标准,知识分类的基本单元不再基于某一篇文章,而是以文章结构以及词语为基本单元,通过语义标签对文章进行结构化处理。所以,结构化标准是数字化过程中的重要标准之一,结构化质量的好坏直接影响数字化的水平。
在学术出版领域,各大数字出版厂商和数字图书馆也开始规划构建用于文献存档的XML规范,如NLM DTD、AIP(美国物理学会)、BMC、PlosOne等。
另外,文档结构化也是出版社实现数字化编辑系统的核心,数字编辑平台无论是在工作效率上,还是在工作质量上,都远远超过传统编辑出版模式[2]。
二、 XML结构化数字转型的特点与优劣性
1.XML结构化的几个重要环节
首先,采用新技术。即对传统出版资源进行结构化整理,按照语义标准进行分类、存储。传统出版的电子版内容资源仅仅是服务、排版与印制,只包含标题、正文等格式控制命令,没有按照语义标准进行结构化整理,也就无法实现语义检索与分类,所以要采用新技术,通过XML结构化语言对原始资源进行加工与整理。
其次,改造出版流程。传统出版机构要大力开展网络出版业务,或设立完全市场化的数字出版公司。数字化出版可以依托传统的编、印、发环节基础,通过新技术改造,加之与互联网整合形成新的产业模式。随着产业融合的逐渐深入,在数字化浪潮的推动下,原本严格区分的行业边界会愈发模糊,内容提供商、技术提供商和渠道运营商之间的相互融合会越来越紧密。
最后,出版资源数字版权授权解决方案。由于数字出版具有海量存储、搜索便捷、传输快速、互动性强、成本低廉等特点,已经成为战略性新兴产业和出版业发展的主要方向。数字出版的特点也是数字版权面临的问题,政府与企业应加快技术创新和标准制定,为版权保护提供有效的技术手段;同时加大对数字版权侵权盗版行为的打击力度,切实保障著作权人合法权益。
2.XML标记语言的特点
结构化的本质就是为文档建立一个描述框架,通过标识符使文档任一部分(任一个元素)都和其他部分保持关联,关联的级数就形成了结构。标识本身的含义与它描述的文档信息相分离。结构化文档(Structured Document)是由标题、章节、段落、图表、公式等框架结构组成。
XML正是具备这一特性的扩展性标识语言。XML文档是由 XML元素组成的,每个XML元素包括一个开始标记(
3.XML结构化优势与劣势
XML最初就是为信息标准化所设计,选择XML作为稿件存储格式有下述优点:
(1)树状层次信息结构存储稿件的内容,可以方便地提取索引。即按照父子关系节点存储文档的内容,可以通过统一的XSL模板对文档稿件进行批处理,经过结构化的稿件可以方便信息的提取与索引。
(2)完全以内容为中心,从而分离了不必要的格式信息。对于每一篇稿件,XML可以以树状信息结构存储稿件的内容,忽略排版格式信息,从而实现语义层面上对文档的定义。
(3)只要设计统一的模板即可格式化为单独期刊具体页面格式。可以依据各期刊和图书体例的统一性设计转换模板,实现XML统一转换。
(4)有利于资料的共享和标准化。经过转换的所有文档,可以方便地建立全文数据库,实现内容资源的统一管理,实现知识提取、知识比较、知识关联。并针对选题策划等各种任务需求实现资源共享,实现个性化、片段化、碎片化出版。
(5)可以方便地转换为任意的格式,如HTML、PDF 、RTF等格式,实现多渠道出版。
选择XML作为稿件存储格式有下述缺点:
(1)出版商要把原有的文献电子版本转换为带语义标记的结构化文档,要再投入人力物力,增加新的工作量。
(2)中文元素定义不完整。NLM DTD中元素、属性以及参数实体的定义只满足于描述英文文献,如果对中文文献进行格式转换还需要扩充元素库,并且保证元素定义符合兼容性以及颗粒度的要求。
(3)中文符号问题。NLM DTD定义的内容中所有符号均采用UTF—8编码,因此,所有的中文符号必须经过处理,例如双字节的逗号、分号、引号、括号、罗马数字等,都必须转换成单字节的相应符号。另外,在XSLT进行转换时,再把单字节符号重新转换成双字节符号。
(4)市场上缺少支持中文的、成熟的XML编辑器。
三、XML结构化数字出版技术流程分析
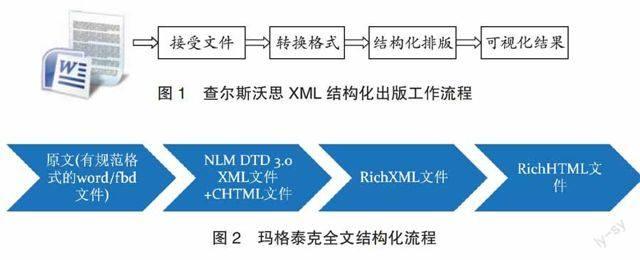
1.查尔斯沃思·中国(The Charlesworth Group )案例
查尔斯沃思的XML排版,是使用集团自主研发的自动转换软件(包括AutoProof)及Arbortext Advanced Print
Publisher (3B2),该软件能为客户提供包括全文SGML、XML、HTML、网络版PDF文件及图片在内的各种电子文件。
其工作流程为先从客户端接收文档文件,然后通过转换软件转换为XML格式文件,再通过模板控制的平台进行结构化排版,经过一次性加工完成,内容可重复利用,适应多种传播媒介,覆盖读者面广,节约成本。其 XML工作流程如图1所示。另外还有短期解决方案,是在原有流程上增加转换步骤,优点是不需要改变现有的生产流程,缺点是费时费力,要根据不同平台的要求重新制作文件,容易造成新的错误。优点是专业性强,缺点是价格偏高,大约$15—30 /页。
2.北大方正、玛格泰克数字出版流程分析
北大方正的书畅系统是以多媒体资源库为中心,面向作者和编辑使用,实现结构化内容的编纂、审校、管理和动态出版的全流程数字化出版生产系统解决方案,支持出版社、期刊社数字内容加工的出版流程。整个系统平台在文稿的创建、协同创作、系统配置、控制和发布5个环节全面支持XML结构化数据标准,支持从内容源头开始的基于内容对象的数字内容创作,可生成多形态数字终端产品(如PDF、EPUB等),实现内容一次制作多元产品发布功能。
该系统通过生产管理平台、模板设计、动态发布引擎、智能化客户端、交互式编排软件等模块,实现从出版任务管理→交互式版式设计→基于XML技术的隐式结构化标引→多格式的内容发布等操作环节。该系统优点是可以处理期刊和图书等多种出版物,在出版过程中构建编辑部、作者以及排版公司之间的协同与合作,有效完成收稿、编辑加工以及排版等核心业务;缺点是价格偏高,大约10万元/套,多刊购买可以优惠。
玛格泰克稿件处理(论文采编)系统是期刊行业的主要平台之一,为出版社、期刊社推出了整体的解决方案。目前已经在遍布全国的1600多家杂志社、十几家出版社得到应用,研发了元数据提取服务,用于网刊发布系统。完成了从方正书版排版结果(FBD文件)、word文件和Latex排版文件中,自动获取每篇文章的基本元数据和扩展元数据,并可以自动发布到网刊系统,并实现参考文献的自动连接,同时自动生成Pubmed、Linkout、 XML数据。对非Magtech 的网站系统,其元数据自动提取系统可以形成Excel文件和XML文件,用于一键式发布。优点是专业性强、价格适中,约1500元/期,缺点是处于起步阶段,有待上升到产业规模。
玛格泰克制作流程首先是原文转换,目前支持 word(doc/docx)、方正书版小样文件(fbd),其次是CHTML结构化,用于检查生成的XML文件的准确性,主要是参考文献的准确识别、文中引用的识别和标记,图表的处理等。其结构化流程如图2所示。
四、XML文档结构化规范
1.NLM DTD与中文扩展
NLM DTD包含3个规范:Archiving Tag Set(文献存档标签集),Journal Publishing Tag Set(期刊出版标签集),NCBI Book Tag Set(图书标签集)。目前,最广为接受的是Journal Publishing Tag Set[3]。
其他的数字出版厂商也发布了各自的文献XML描述规范,例如AIP(美国物理学会)、BMC、PlosOne等,经过比较,大家普遍认为NLM DTD在标签定义的规范性、整个体系的完整性以及普适性等方面具有非常大的优势。因此,虽然最初是为生物医学文献而设计的NLM DTD,也逐渐被其他领域的学术文献出版机构和存档机构所接受,例如BMJ、PNAS等。
NLM DTD中定义了235个元素,127个属性,557个参数实体,这些内容足于描述英文文献的全部内容。但对中文来说,还不够,还需要进行扩充,扩充原则是首先尽可能兼容NLM DTD,其次是颗粒度尽可能小。
中文元素标签,统一在对应的标签前加Vernacular。例如
2.元数据自动提取
是指利用计算机软件,采用模式识别智能算法,从排版后的最终文件中自动、准确提取期刊所有文章的元数据,并形成各种可重复利用的结构化数据文件,如Excel、XML文件,并可以一键发布到网刊系统,在网刊的基础上,形成各种个性化的应用文件,如Linkout、 XML文件等。
文字处理文档包含输入的文本、图形和表格。文档转换为结构后,其中的每个组件和用于驱动发布过程或控制格式的特定信息,都可以被识别。文档各部分成为 XML 元素,并当作数据库中的字段处理(可以被定位、被排序、用于检索以及进行其他操作),还可以根据上下文嵌套它们的父元素或文档树中在它们层次之上的元素(祖先)。
3.文档的处理方法
分析现有文档内容,并确定文档暗含的结构。例如,某一篇论文文档可能包含文本章节、插图、表格、程序、参考文献属性等。文本可能分为标题、作者、单位、内容摘要、主体段落、列表和重点短语。
(l)版面分析、规范处理。先对刊物进行版式特征识别。如:位置、字体、字号、颜色、辅助信息、版式风格等,辅以语义分析,提取版式数据的逻辑结构,将无序、无结构的数据,组织成有序、有结构的数据。例如,从期刊版面中提取必要的文字和排版信息,自动判定排版方向、合并正文块,自动还原正文阅读顺序,自动关联附图与图注、附表与表注。
(2)文档结构分析、字段提取。首先对刊物进行文档特征提炼。在此基础上,分析文章或章节结构,生成各期目录列表,以及文章标题层次信息。期刊字段包括标题、作者、作者单位、内容摘要、关键字、文章编号、参考文献、基金项目以及作者简介等,自动完成字段的标引。
(3)分类集成、词语索引。建立刊物的词典,对文章以及知识点进行分类汇总,实现基于内容的数据挖掘。包括自动归类、语义标引、专业术语校对等。
标记一个论文(部分)的例子:
< SubmitDate >投稿日期< /SubmitDate >
< DocTitle >
< DocTitleCn >面向创新人才培养的教学改革探索
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
纺织科学研究(2021年6期)2021-07-15 08:41:36
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
福建基础教育研究(2019年1期)2019-09-10 07:22:44
福建基础教育研究(2019年1期)2019-05-28 08:39:49
信息安全研究(2016年4期)2016-12-01 06:06:54
中国卫生(2016年2期)2016-11-12 13:22:30
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
计算机工程(2015年8期)2015-07-03 12:20:35
