
结合权重因子与特征向量改进的文本聚类算法
2015-05-04 08:07董跃华郭士串
计算机工程与设计 2015年4期
董跃华,郭士串
(江西理工大学 信息工程学院,江西 赣州341000)
0 引 言
文本聚类属于聚类分析范畴,是一种挖掘潜在、隐藏信息的方法[1],但因其非结构化的数据类型和向量空间模型表示后的高维性,使其自身具有特殊性。
通常文本聚类包括两个步骤:第一文本预处理,使文本数据可以通过计算机处理;第二聚类算法选择,针对文本数据的特点进行聚类。长期以来,人们都很热衷于对文本预处理的研究,如有研究者提出一种特征项自动分解的思想[2]提高了文本特征项的选择精度;还有通过类间偏斜度、类内离散度和权重调整因子的配合使用[3]修改了传统的文本预处理方法,提高了文本聚类的精度。在文本聚类算法方面,K-均值因其高效和简单已被广泛应用,但其具有过分依赖初始中心点选取和聚类结果,易陷入局部最优等缺点。目前,很多研究者利用遗传算法的全局优化能力结合K-均值算法对聚类进行优化[4-8]。遗传算法获得最优解的方法就是模拟自然进化的过程,其通过部分结构可反映应用空间较大的区域,具有一定的健壮性,可避免局部最优,同时还便于实时处理。所以,两种算法相结合能更好改善聚类效果。
本文首先通过特征词权重因子和特征向量改进了文本预处理方法,并根据新的文本编码特点结合遗传控制因子对遗传K-均值聚类算法进行算子控制。实验结果表明,本文提出的文本聚类方法提高了文本特征词分类精度并改进了文本聚类效果。
1 文本预处理方案设计
在文本聚类之前,必须要对文本进行预处理,主要包括文本的特征选取和文本编码,经过预处理后能提高文本聚类的效率和准确率。通常文本聚类可描述为:对文本集合D={d1,d2,…,dn}进行聚类,而最终的聚类效果是要得到一个簇的集合C= {c1,c2,…,ck},∪ki=1Ci=D ,其中对每一个di(di∈D),-Cj(Cj∈C),di∈Cj,并且还要使得聚类准则函数Q(C)收敛,其中n为文本的总个数,k是需要的聚类个数,且Cj∩Cl=φ,j≠l。
1.1 特征词权重计算方法
在文 本 聚 类 中 文 本 通 过 VSM (vector space model,VSM)表示,每个文本为一条向量。向量内容为通过TFIDF度量求出的文本中每个特征词t的权重,用来表示特征词t在该文本中的重要性。则文本可表示为
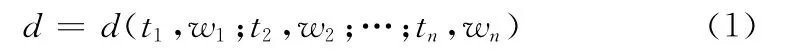
其中特征词tk的权重为wk,1≤k≤n。
但是传统的TF-IDF只考虑词语频率TF和词语倒排文档频率IDF,在文本集中,通过该方法计算的特征词权重集合能很好的表示一个文本,但此权重在体现文本间的差异性时有明显的局限性。为了解决这一缺点本文提出一种改进方法,在考虑到TF和IDF的情况下,加入特征词权重因子对特征词权重进行加权处理。特征词权重因子(WF)的作用是通过特征词权重提高不同类文本间的区分度,增强同类文本间的相似度,WF的表达式如下
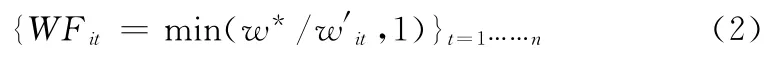
其中w′it为特征词t在除i文本外在文本集其它文本中的权重,w*为此权重集合中的非零最小值,w*∈w′it。由式(2)可以看出通过WF的控制更好体现同一特征词在不同文本中的不同重要性,从而加强文本间的差异性。修改后的度量公式命名WF-TF-IDF,做归一化处理后为
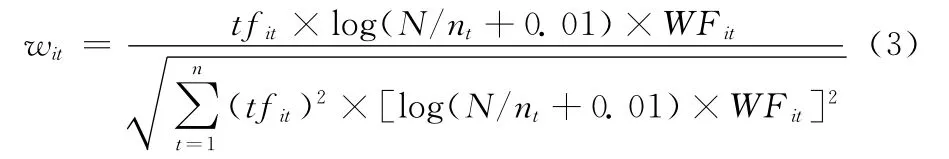
式中:wit为特征词t在文本di中的权重,t=1……n,N为文本集合中的文本总个数,nt为出现特征词t的文本个数。
1.2 文本编码方案
预处理过程中通过WF-TF-IDF对文本特征词权重计算结束后,文本的编码方案也是非常重要的环节。但是在传统的VSM编码方案中,并没有考虑特征词在文本中的位置,而是简单的要求特征词不重复,不考虑在文本中的先后顺序。但是一个特征词出现在文本中的不同部分在表示文本时也有不同的贡献度,比如,同一特征词出现在文本的标题和正文两个部分中,在其表示文本时贡献度就有所不同,所以在对文本编码时应该把特征词出现在文本中的位置考虑在内。
于是本文将传统通过VSM中一个向量表示文本的模式,修改成文本由标题向量dv1、第一段向量dv2、最后一段向量dv3、其它段向量dv4这4个特征向量构成,每个特征向量均包含对应的特征词和权重,由于每个特征向量代表文本的不同位置,因此,对于不同位置的特征向量通过位置权重Lm进行加权处理,修改后的文本表示应为

式中:dvm——文本的特征向量,Lm= {0.4,0.3,0.2,0.1}为位置权重信息,m为特征向量个数,1≤m≤4。
因VSM是实数域的求解问题,并且二进制编码计算量大,所以本文将采用浮点数编码,能加快求解速度。通过以上描述,以chromi= (c1,c2,…,ck)(1≤i≤p,p表示种群的大小,本文设p为偶数)表示染色体。给定一个文本集包括N个文本,对每个文本根据自身的结构生成各自的特征向量。从特征向量中提取的各自特征词,对其不同的特征词构造VSM。通过此过程,每个文本d被认为由向量空间中的,个特征向量组成。如果某个特征词不存在对应的特征向量中,那么在VSM中其对应元素值设为0;否则根据本文提出的基于WF加权的TF-IDF权重计算方法求得该特征词在文本中的权重。其染色体中的cj(1≤j≤k)则是由特征向量构成并与VSM长度相同,表示聚类结果中第j个中心向量。由于对特征向量权值进行了归一化处理,所以进行编码时向量cj中的元素都是0和1之间的实数。
1.3 相似度的设计
1.3.1 改进的余弦夹角度量
在整个聚类过程中,文本彼此间的相似性计算尤为重要,其评价准则对最终聚类效果有直接的影响。目前对于同一特征空间的两个对象进行相似性评价有了很多方法。但是对象的数据类型有所不同有的数据是连续型,有的则是分类型,不是所有的评价标准都适用。文本聚类属于对连续型数据进行处理,目前常用的文本间相似性计算方法有Pearson相关、Jaccard系数[9]以及欧几里德距离等。但在VSM中文本通过向量表示,故文本间的相似性可以通过向量之间的距离表示。因为本文在文本预处理中,采用了基于WF的加权策略和特征向量方法,故在文本相似度计算时采余弦相似度度量最优。又由于本文对文本编码方案做了修改,所以本文结合式 (4)对余弦相似度计算做了修改,其表达式如下
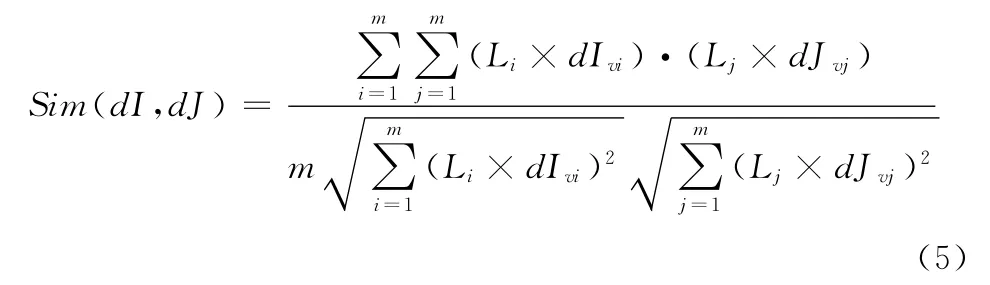
式中:dI、dJ——文本,m为文本特征向量个数。分子和分母分别表示两个特征向量的内积和模的乘积。由于文本向量在进行内积运算时对没有此特征词时做补零处理,且每个特征向量还包含位置权重信息,所以通过式 (5)能更好体现出文本间的差异度。
1.3.2 遗传控制因子 (GCF)
通过研究遗传算法控制算子的方法和新的文本编码的特点,本文提出一种遗传控制因子 (GCF)。GCF在遗传算法中的作用是如何将优质的个体引入下一代,还表示该个体各聚类中心向量间的相似度。如果GCF较小说明此个体聚类中心点彼此间相似度较小,此个体为优质个体;如果GCF较大说明此个体聚类中心点彼此间相似度较大,此个体为劣质个体。GCF主要的设计步骤如下:
(1)计 算 均 值向量VA = {VA1,……,VAm},其 中VAi表示染色体p第i维的平均向量,m为特征向量的个数。
(3)染色体p的GCF计算公式为
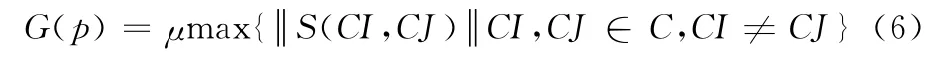
式中:μ∈ (0,1]为随机数;CI、CJ 为染色体p 的中心向量。
1.4 适应度函数设计
由于采用Sim度量文本间的相似度,故Sim值的大小和文本间的相似度成正比。首先由1.2节的编码方案,对生成的染色体随机的产生k个中心向量,再根据Sim求出每个中心向量和各个文本间的相似度,并将各文本放入与之相似度最接近的中心点所在的类中。由此可见,一个中心点与离它越近的对象的相似度越大,否则相似度越小,那么其适应度值就应该越大。所以本文设计的适应度函数f为
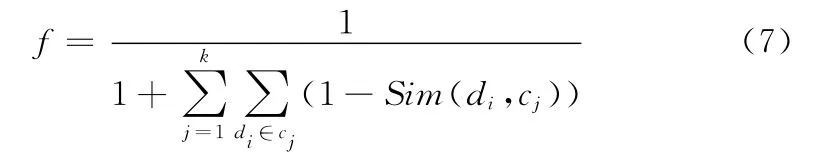
1.5 收敛准则函数设计
根据本文重构的余弦相似度计算公式,所设计的新的遗传K-均值算法的收敛准则函数为
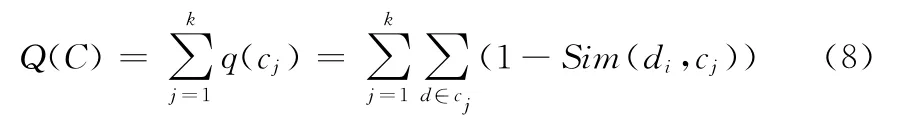
式中:q(cj)——第j类中内部文本与聚类中心的相似度
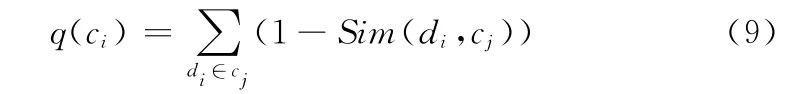
式 (9)的目标函数是基于本文设计的Sim相似度的。
2 用于文本聚类的遗传K-均值算法
为了克服算子操作的低效性,本文将使用GCF对传统的遗传K-均值算法进行算子操作控制,使其能更好的和特征向量方法相结合。本文将此算法称为GGKM。在GGKM算法遗传算子交叉和变异时,GCF的作用如下:
在遗传算子交叉操作时,交叉后新个体的GCF大于原个体的GCF,则说明交叉失败保留原来的个体,否则保留新个体。在算子变异操作时,如果进行一次变异后得到的新个体的GCF大于原来个体的GCF,则说明没有得到优质的新个体,说明变异操作失败需重新进行一次变异,如果进行了Gmax(最大变异次数)次变异后还没有得到小于原来个体的GCF,则说明原来个体为优质个体并保留下来,否则将得到的新个体引入下一代。
2.1 通过GCF控制遗传算子
2.1.1 选择算子
为了保证基因中最优个体一定被选中,并且让个体被选中的概率都与其自身的适应度值有关。所以,文本使用最优保持策略和轮盘赌注选择方法对算子进行选择操作。实现的步骤如下:

还有,最优保持策略的目的是保证当前算子操作阶段出现的最优个体不会在下一步的进化操作中被直接破坏。设Iw为当前种群中适应度最低个体,Ib为当前种群中适应度最高个体,I′b为种群中总的最好个体,具体伪代码如下:

2.1.2 交叉算子
本文在进行遗传算子交叉操作时,采用了自适应可变概率,并在操作时采用单点交叉算子。假设两个配对个体为c1=g1,g2,…,gk和c1=h1,h2,…hk。实现交叉操作的步骤如下:
(1)设favg为当前种群的平均适应度,fmax为当前种群的最大适应度,设f1为c1和c2两者中适应度较大的个体,则本文使用的可变交叉概率Pt为[10]
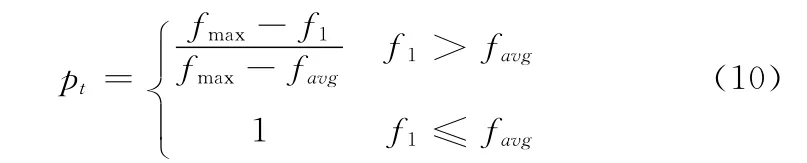
由式 (10)可以看出,当平均适应度大于个体适应度时,说明个体不是优质个体,必须进行交叉操作;而当交叉个体的适应度值比较大时,其交叉概率成反比。
(2)生成一个随机数R1∈ [0,1)。
(3)if (R1<Pt)
{
(4)产生一个随机整数r并且小于中心点个数k,使其作为交叉操作的交叉点,并将r位到k位之间的对象随机互换。即当i=r+1,…,k时,每次均生成一个随机数μ其取值为0或1,则有gi=μgi+(1-μ)hi和hi= (1-μ)gi+μhi。
(5)用GCF进行个体控制。
}
2.1.3 变异算子
在进行变异操作时,其概率类似于交叉操作也采用可变控制。确定变异概率大小的公式[10]如下

式中:λ∈ (0,1],一般为0.1。由式 (11)可以观察出,种群中个体适应度的值和变异概率成反比。通过式 (11)求得变异概率后,遗传算法变异算子操作步骤如下:首先确定一个范围 [-R,R],计算公式为
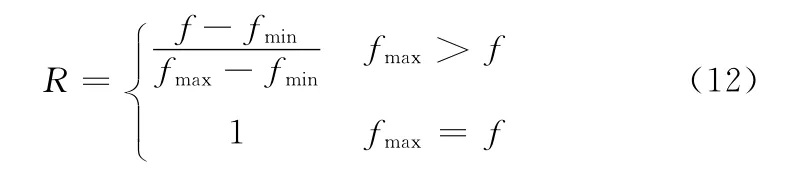
设Ni为个体N在第i位的值,而nimin和nimax为文本集中第i位上的最小值和最大值,设ni为种群进行变异操作后第i位的值,μ为随机数且μ∈ [-R,R],其计算公式如下

实现伪代码为:

用式 (12)、式 (13)进行变异运算;

2.2 算法终止条件
在改进后的文本聚类算法中,采用的终止条件如下:
(1)固定最大迭代次数Itemum。当算法执行了Itemum次遗传进化后停止。
(2)根据算法自身的收敛程度。比如在文本聚类过程中准则函数值连续多代无明显变化,则说明函数值趋向收敛此时算法停止。
2.3 算法步骤及流程图
输入:文本集D(文本数为N,维数为m),遗传种群大小p,交叉概率pt,变异概率pm,聚类个数k,终止条件。
输出:聚类结果。
GGKM算法具体步骤如下:
步骤1 进行文本预处理;
步骤2 通过WF-TF-IDF算法对特征词权重进行计算;
步骤3 对文本进行编码,通过文本自身的特征向量结合VSM表示文本;
步骤4 初始化种群,通过K-均值和Sim随机产生p个染色体,种群可以表表示为p= (chrom1,chrom2,……,chromp);
步骤5 通过重构的适应度函数f求的每个个体的适应度函数值;
步骤6 计算遗传控制因子GCF并进行选择、交叉、变异控制。选择采用最优保持策略和轮盘赌注选择;交叉和变异操作通过每个个体的GCF和自适应可变概率控制,确保优质个体被引至下一代;
步骤7 产生了新一代的遗传种群,通过算法终止条件判断是否终止,是则进入步骤8;否则转步骤5;
步骤8 输出聚类结果。
改进后的文本聚类流程如图1所示,首先通过特征词权重因子 (WF)修改了传统的权重计算公式,得出的特征词权重值能更好的体现特征词在文本中的价值。再利用特征向量的概念和VSM对文本进行编码,重新编码后的文本由自身特征向量组成,每个特征向量表示文本的不同位置。再此基础上利用式 (5)进行相似度计算,能更好的提高同类文本的相似度,增加不同类文本的差异度。最后,根据本文的文本编码方案特点结合遗传算法操作算子的思想,提出一种遗传控制因子 (GCF)。通过GCF对遗传K-均值算法的算子操作进行控制,使交叉和变异效率更高,从而得到较理想的聚类效果。
3 实验及结果分析
本文实验采用的原始数据来自于中文自然语言处理开放平台网站的新闻样本。其中训练样本和测试样本共有2516个。样本有12个类别,分别为财经、体育、教育等,采用信息增益和基于文档统计并取1000个特征词,数据集称为Chs2516。实验的硬件环境为Intel Core i3 2.4GH,内存2G,操作系统是32位 Windows7,仿真软件为Matlab 2012b。
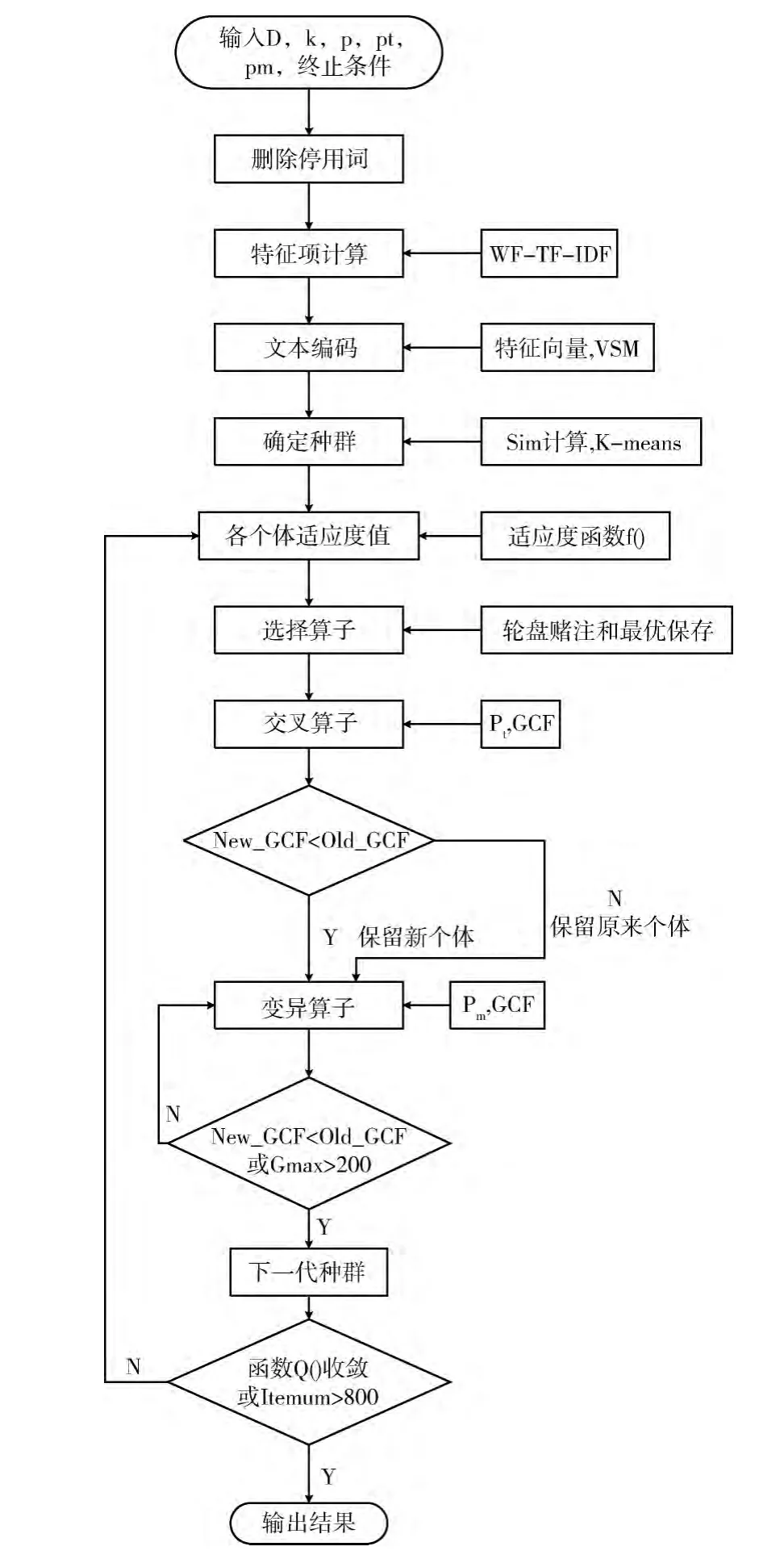
图1 改进后的文本聚类流程
3.1 实验评价标准
文本预处理阶段首先在支持向量机算法下进行特征词分类实验,通过WF加权的TF-IDF方法对特征词权重进行计算,每次实验结束都会计算出此次特征词分类的查全率(Pe)和查准率 (Pr),对每20次结果求Pe和Pr平均值,而Pe和Pr是F1-measure的重要参数,对特征词分类精度的评估有很重要的影响。评估指标F1-measure在文本聚类有效性评价中的使用非常频繁,在各种文献检索系统中都有运用[11]。其表达式如下

在文本聚类效果方面,采用Huang提出的聚类精度度量来衡量文本聚类结果的准确性,其公式为

式中:ai——对象出现在类Ci和其相应标记类中的总和。并把终止条件设为:Gmax为200,Itemum为800,当Itemum大于800或函数Q()收敛时,算法结束。
3.2 实验结果分析
在文本特征词提取阶段采用支持向量机算法,将传统的 TF-IDF算法、BOR-TFIDF算法[12]、SI-TFIDF算法与WF-TF-IDF改进算法进行比较。每种算法运行100次。表1和图2分别表示4种算法对同一类特征词的测试结果和实验效果图。通过表1的数据可以看出,通过WF加权的WF-TF-IDF算法和其它3种算法相比在特征词分类效果方面具有较高的准确率。图2表现出了4种算法对不同类特征词的分类效果,其中TF-IDF和BOR-TFIDF算法的分类精度比较低,SI-TFIDF优于前2种算法,而 WF-TF-IDF算法在传统算法优点的基础上,结合权重因子WF对特征词权重进行加权处理使得分类精确度最高。
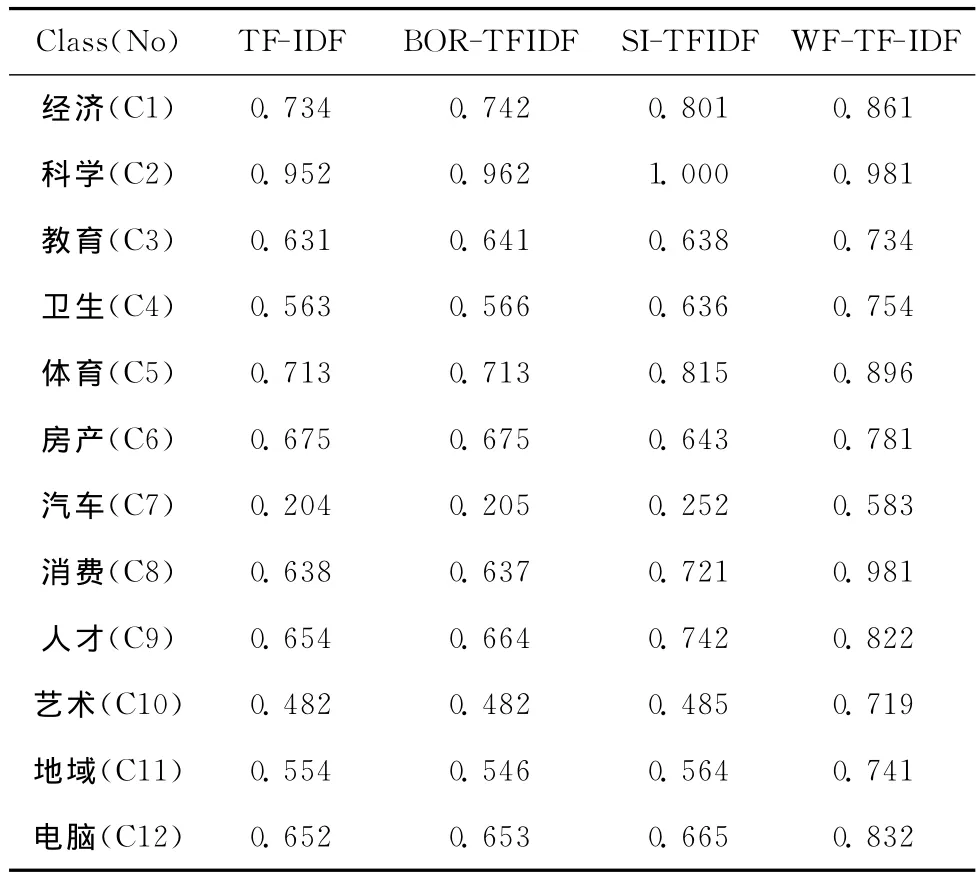
表1 基于支持向量机的测试结果
在文本聚类阶段,将传统K-均值聚类算法、改进的混合聚类算法[13]与改进算法GGKM进行比较。表2对应3种聚类算法对数据集Chs2516进行聚类后的聚类精度 (表中的顺序号为100次实验中随机挑选的8组),从表2中可以看出GGKM算法相比其它两种算法有更高的聚类精度且聚类精度波动幅度相对较小,这都说明GGKM算法的聚类结果更加的准确和稳定。图3为3种算法的平均聚类精度对比,更加直观的显示GGKM算法的聚类效果更优。
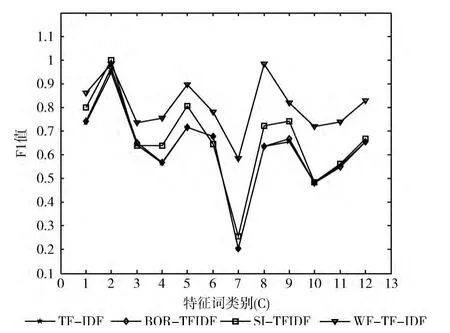
图2 基于支持向量机的实验效果比较
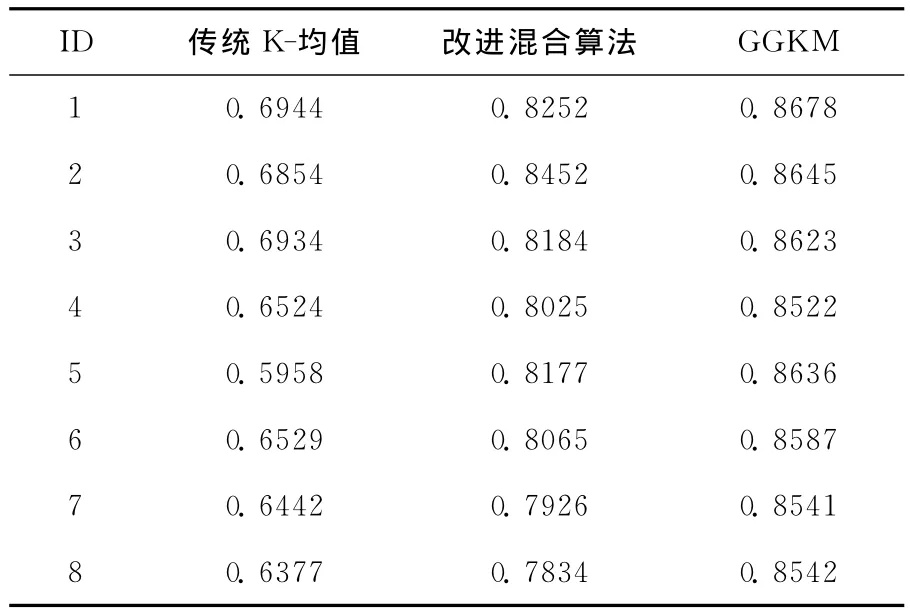
表2 文本聚类精度值
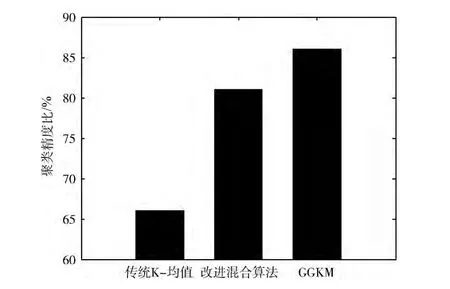
图3 文本数据集聚类精度对比
综上所述,本文提出的以WF加权的WF-TF-IDF特征词权重计算方法,在继承了传统算法优势的同时,并根据特征词在表示文本时对文本的重要性进行权重的加权和降权处理,以体现特征词对区分文本的贡献度。从而更好的变现了同一特征词在不同文本中的不同重要性,确保了文本分类效果的稳定。而结合了特征向量思想和遗传控制因子的遗传K-均值聚类算法GGKM,相比其它两种文本聚类算法,能更好的适应文本提出的文本编码方案,从以上实验数据可以看出,本文改进的文本聚类算法,不但对特征词的权重计算和特征词分类做出了改进,还使得文本聚类精度得到提高,聚类效果不易受到干扰。
4 结束语
首先通过研究传统特征词权重计算的缺陷,从加强一个特征词在不用文本中重要性的角度出发,结合权重因子WF的方法,提出了改进算法 WF-TF-IDF。并对文本编码做了修改,使用特征向量的思想修改了相似度计算公式,使文本之间的差异度更加明显。还针对改进的文本预处理方案,提出通过遗传控制因子改进遗传K-均值文本聚类算法。实验结果表明,本文提出的结合权重因子与特征向量改进的文本聚类方法较之其它改进方法,具有更好的特征提取和文本聚类效果。
[1]LIN Li.Application research of text clustering based on noumenon [D].Tianjin:Tianjin University,2011 (in Chinese).[林利.基于本体的文本聚类的应用研究 [D].天津:天津大学,2011.]
[2]YU Yonghong,BAI Wenyang.Text clustering based on automatic partition of feature item weight [J].Computer Engineering,2011,37 (11):25-27 (in Chinese). [余永红,柏文阳.基于特征项权重自动分解的文本聚类 [J].计算机工程,2011,37 (11):25-27.]
[3]ZHANG Yu,ZHANG Dexian.Improved feature weight algorithm [J].Computer Engineering,2011,37 (5):210-212(in Chinese). [张瑜,张德贤.一种改进的特征权重算法[J].计算机工程,2011,37 (5):210-212.]
[4]Roy D K,Sharma L K.Genetic k-Means clustering algorithm for mixed numeric and categorical data sets [J].International Journal of Artificial Intelligence & Applications,2010,1 (2):23-28.
[5]Laszlo M,Mukherjee S.A genetic algorithm that exchanges neighboring centers for k-means clustering [J].Pattern Recognition Letters,2007,28 (16):2359-2366.
[6]Chang D X,Zhang X D,Zheng C W.A genetic algorithm with gene rearrangement for K-means clustering [J].Pattern Recognition,2009,42 (7):1210-1222.
[7]Hwang C,Chang T.Genetic k-means collaborative filtering for multi-criteria recommendation [J].Journal of Computational Information Systems,2012,8 (1):293-303.
[8] Martis R J,Chakraborty C.Arrhythmia disease diagnosis using neural network,SVM,and genetic algorithm-optimized k-means clustering [J].Journal of Mechanics in Medicine and Biology,2011,11 (4):897-915.
[9]Shameem M U S,Ferdous R.An efficient k-means algorithm integrated with Jaccard distance measure for document clustering[C]//First Asian Himalayas International Conference on Internet.IEEE,2009:1-6.
[10]Chavent M,Lechevallier Y,Briant O.DIVCLUS-T:A monothetic divisive hierarchical clustering method [J].Computational Statistics &Data Analysis,2007,52 (2):687-701.
[11]Agarwal A,Xie B,Vovsha I,et al.Sentiment analysis of twitter data [C]//Proceedings of the Workshop on Languages in Social Media.Association for Computational Linguis-tics,2011:30-38.
[12]SHEN Zhibin,BAI Qingyuan.Improvement of feature weighting algorithm in text classification [J].Journal of Nanjing Normal University (Engineering and Technology Edition),2009,8 (4):95-98 (in Chinese).[沈志斌,白清源.文本分类中特征权重算法的改进 [J].南京师范大学学报 (工程技术版),2009,8 (4):95-98.]
[13]LAI Yuxia,LIU Jianping,YANG Guoxing.K-means clustering analysis based on genetic algorithm [J].Computer Engineering,2008,34 (20):200-202 (in Chinese). [赖玉霞,刘建平,杨国兴.基于遗传算法的K均值聚类分析 [J].计算机工程,2008,34 ( 20):200-202.]
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
计算机仿真(2022年8期)2022-09-28
保定学院学报(2022年2期)2022-04-07
计算机技术与发展(2018年8期)2018-08-21
许昌学院学报(2018年4期)2018-05-02
郑州大学学报(工学版)(2018年2期)2018-04-13
中国机械工程(2017年22期)2017-12-02
中华建设(2017年1期)2017-06-07
中国塑料(2016年11期)2016-04-16
中文信息学报(2015年4期)2015-04-21
