
结合分类方法的并行分形图像编码算法研究*
2015-04-28 03:45卢振坤
湘潭大学自然科学学报 2015年1期
郭 慧, 贺 杰, 卢振坤
(1.梧州学院 信息与电子工程学院,广西 梧州 543002;2.广西民族大学 信息科学与工程学院,广西 南宁 530006)
结合分类方法的并行分形图像编码算法研究*
郭 慧1*, 贺 杰1, 卢振坤2
(1.梧州学院 信息与电子工程学院,广西 梧州 543002;2.广西民族大学 信息科学与工程学院,广西 南宁 530006)
针对分形图像编码计算密集的特点,建立编码步骤的串行-并行转化机制,利用计算统一设备架构CUDA的单指令、多线程执行特性,建立分形编码在图像处理器GPU上的并行计算模型,将耗时量较大的搜索最佳匹配块的串行执行过程并行化处理,并在此基础上结合方差法对值域块进行分类以减少搜索次数.实验结果表明,该文算法与原始算法相比可达到1 200多倍的加速并保持较好的解码图像质量,满足了实时编码的要求.
分形图像压缩;计算统一设备架构;并行计算;分类;方差
分形图像编码方法是一种建立在空间域的有损图像压缩技术,其理论基础是迭代函数系统及拼贴定理.该方法根据自然图像的不同局部之间存在的跨尺度自相似性来进行编码,从而减少图像的数据冗余,具有分辨率无关及解码快速等优点.但分形编码也存在搜索匹配计算量大,耗时长等不足,难以满足实时性需求,因而加速编码过程成为分形编码改进的重要方向.为减少匹配块的搜索时间,刘小丹等人[1]提出了一种改进的 K-means聚类优化的图像分割方法.吴一全、孙子翼[2]则针对K-均值聚类分形编码算法依赖数据分布等问题,提出了一种基于免疫粒子群优化和核模糊聚类的方法,与基本分形编码算法相比可达到6倍的加速.Hui Guo[3]等结合人类视觉系统特性改进了四叉树分形编码方法,以求将解码时的失真控制在人眼无法识别的范围之内,但提速效果最多也只是27倍.屠添翼[4]等人提出一种对小波树进行加权处理,然后进行分形编码的方法来进行加速.Hui Yua等人[5]以前一最佳匹配块为中心、在其邻域搜索当前最佳匹配块,改进了四叉树分形编码方法.Yih-Lon Lin[6]利用边缘形状相似的块集中于某些特定区域这一现象来实现邻域搜索.Wu YG等提出的方差法[7],将值域块分成简单块和复杂块,再结合近邻搜索法来减少搜索的码本.
以上研究都是从编码算法的优化方面来缩短编码时间.分形编码呈现出典型的串行执行特征,其匹配过程是逐个对每个R块进行D块池全局或分类局部搜索,可视为对相同步骤的串行重复执行,因此,将这类步骤并行化执行是一种可行的优化方法.特别是目前已有许多硬件具有并行运算结构,如能将分形编码与某种普及程度高、成本低廉的并行硬件结合,建立相应的实施机制,将会显著提升编码速度.图形处理器GPU具有大量并行的硬件运算单元,适用于对多个数据对象进行并行运算.计算统一设备架构CUDA则是一种处理与管理GPU计算的新型软件架构和编程模型,具有单指令、多数据的执行模式,能够利用CPU处理应用程序的顺序部分,同时通过API在GPU上以线程为基本单位进行计算密集型部分的并行执行[8].
本文提出一种建立在GPU的基础上,利用CUDA架构进行并行编码的快速分形图像压缩算法.该方法由四部分构成:采用四邻域平均法对定义域块进行空间压缩、值域块和定义域块的预处理、值域块的分类、最小均方误差的计算.在对定义域块的空间压缩过程中,使用一种并行执行方案,即GPU的每个线程完成一个定义域块的平均采样工作;在预处理阶段中,GPU的每个线程会分别计算出每个值域块及被搜索的定义域块的像素和;在分类过程中,结合Wu YG等提出的方差法[7]把值域块分为简单块和复杂块,只对复杂块进行编码;在最小均方误差的计算中,每个复杂块均会有对应的独立线程进行匹配搜索和求解最小均方误差.实验结果表明,本文所提出的改进算法与传统的分形图像压缩方法相比,可提速1200多倍,并保持较好的解码图像质量,满足分形编码的实时性要求.
1 传统分形编码方法
Mandelbrot首次提出分形图像是一个迭代函数系统[9],他认为自然界中很多事物的结构都具有相似的部分,并指出一片分形云可以用一个简单的数学函数来描述.1988年,Barnsly 和 Sloan提出分形图像压缩方法,利用图像的局部的自相似性来进行压缩[10].1992年,Jacquin提出的实用分形块编码实现了计算机自动分形编码[11],分形编码方法首先要将图像划分成互不重叠的R×R方块及可重叠的D×D方块,分别称为值域块(R块)与定义域块(D块),定义域块的尺寸要大于值域块.随后对定义域块进行平均采样,使得定义域块与值域块的尺寸一致,所有的定义域块可存放在定义域池SD中.
一幅大小为N×N的图像可划分为i个定义域块和j个值域块,i=0,1,2,…,(N-2R+1)2,j=0,1,2,…,(N/R)2.通过最小平方误差准则为每个值域块从定义域池SD中搜索最佳匹配的定义域块,其仿射变换公式如式(1)所示.
(1)


(2)
(3)

(4)
(5)
假设I为原始图像,R为值域块大小,D为定义域块大小.具体算法步骤如下:
Step1:将原图像I分割为互不重叠的值域块Rj,块大小为R×R.
Step2:将原图像I分割为可重叠的定义域块Di,块大小为D×D.
Step3:对定义域块进行平均采样,使得定义域块的大小与值域块一致.
Step4:对于每个值域块Rj,在定义域池SD中找到对应的定义域块Di,确保对Di进行仿射变换后,若得到Rj与Di之间的均方误差值最小,该Di为Rj的最佳匹配块.
Step5:对于每一个值域块Rj,记录变换库wi(dx,dy,n,si,oi)构成的分形码(IFS码):
(1) 搜索到的最佳匹配块Di的左上角坐标dx,dy;
(2) 使Rj与Di成为等距变换编号n(n为0~7);
(3) 对比度调整系数Si和亮度调整系数Oi.
2 分类算法

(6)
(7)

3 结合分类方法的并行分形图像编码算法

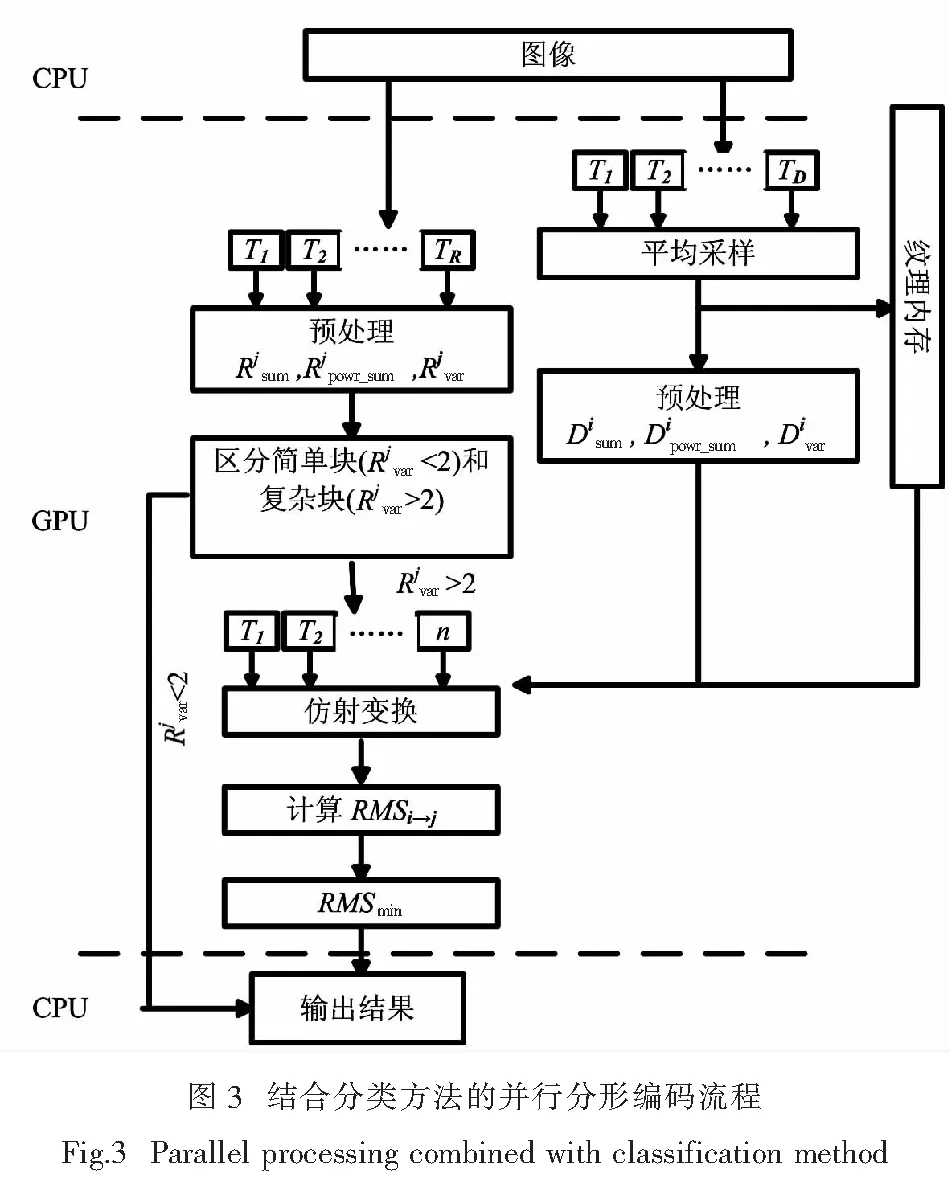
CUDA是一种新的处理和管理GPU计算的硬件和软件架构,应用程序可通过CPU处理顺序执行部分,并通过CUDA相关API在GPU上完成计算密集部分的并行执行,从而更充分发挥显卡的大规模并行计算能力.在程序运行时,CUDA 程序中的并行处理部分由内核函数来完成,运行在GPU上的内核函数的基本单位是线程.CUDA会产生很多地址不同的并行线程,这些线程执行内核函数,实现对数据的并行处理.图2 展示了CUDA的基本执行原理,用CUDA编程实现的应用程序主要构成有两部分:主机端(Host)代码和设备端(Device)代码.运行在CPU上的串行处理部分为主机端代码,而设备端代码(即内核kernel)则是运行在显示芯片GPU上的并行处理部分.Host端代码一般主要是负责调度总体和逻辑性强的串行运算,如初始化GPU以及数据交换等;而Device端代码主要负责程序中并行化程度高的并行数据处理.
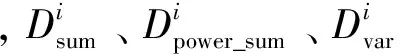
从图3可知,在进行搜索匹配之前,先要对定义域池中的D块进行平均采样,这部分的计算工作是平均分配到各个线程上去计算完成的,将处理好的数据存到纹理内存中.平均采样的具体过程如图4所示.
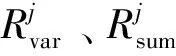

(8)
(9)
(10)
(11)
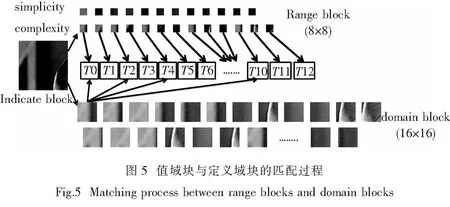
结合分类方法的并行分形图像编码算法的具体步骤如下:
输入:一幅大小为N×N灰度图像,象素灰度为8 比特量化,N一般为2 的方幂.
输出:分形码,即wi(dx,dy,n,si,oi).
Step 1:在CPU端读入图像数据,将原图像I分割为互不重叠的值域块Rj,块大小为R×R;将原图像I分割为可重叠的定义域块Di,块大小为D×D.并将这些数据传输到设备内存中.
Step 2:进行平均采样,构成码本.将每个定义域块的平均采样工作分配给每一个线程,即一个定义域块的子采样工作由一个线程去完成.

Step 6:将分形码由设备端传输到CPU端.
Step 7:输出分形码wi(dx,dy,n,si,oi).
本文算法的解码流程跟传统算法的解码流程基本一致,仅多了一个是否是简单块的判断条件,对于简单块,直接取其像素平均值覆盖该块;对于复杂块,则读取分形码进行迭代解码.
4 实验数据及结果分析

为了验证算法的有效性,本文采用256×256×8的Lena、Pepper、 Cat、Rose、Heci这5幅标准测试图像进行测试,这5幅图像在纹理及边缘细节的均衡与变化等方面均有代表意义,能很好的测试各种图像处理算法.所有待测试图像均设定值域块大小为4×4,定义域块大小为8×8.程序开发环境为Microsoft Visual Studio 2010+ CUDA6.0+Opencv2.3,系统为64位Windows 8.1,内存为4 GB,显卡为Nvidia Geforce GT 630M,CPU为Core I3.下面分别采用传统分形编码算法、并行分形编码算法、结合分类的并行分形编码算法对这5幅图像进行编码,在解码的时候,创建一个空白的矩阵,经过9次迭代,即可逼近原图,实验结果如图6~图8所示.
由图6~图8可知,从肉眼来看,采用这三种算法的解码图像的效果是基本一致的,这证明了并行算法的可行性.表1是采用这三种算法进行编码的时间T、解码图像的PSNR值及加速比.

表1 使用三种算法的实验数据
由表1的数据可知,并行算法与传统分形编码算法相比,编码时间要要明显少于传统的分形编码算法,最大的加速比可达135倍,其PSNR值与传统算法一致.这是因为在并行算法中,利用了图形处理器GPU的并行硬件运算单元,将耗时量较大的搜索最佳匹配块的串行执行过程并行化处理,从而缩短了编码时间,并保证了解码图像的质量不变.
随后在并行算法的基础上,加入对值域块的分类机制,构成结合分类方法的并行分形编码算法,这比采用单一的并行算法提速更快,与传统算法相比较,加速比最大可达1 222倍,而解码图像的PSNR值只是略有下降,这是由于简单块在解码过程中采用像素平均值代替原像素值导致的.因此,利用CUDA架构对分形图像压缩的编码过程进行并行化执行,并在此基础上对算法进行优化,可使编码时间达到毫秒级,基本满足实时编码的要求.
传统分形编码方法压缩比C的计算公式为:C=256×256×8/(h×(8+8+3+5+7)),其中h表示值域块的总数,定义域块的左上角坐标dx和dy分别被量化为8 bit,等距变换的矩阵号n被量化为3 bit,灰度对比度因子S被量化为5 bit,灰度亮度因子O被量化为7 bit.当设定值域块大小为4×4时,对图像进行分割后所获得的值域块的总数是一个固定值:h=256/4×256/4=4 096,压缩比C=4.13.而采用本文的分类并行算法时,压缩比C的计算方法为:C=256×256×8/(S1×(1+8)+S2×(7+7+3+5+7)),这里S1表示简单块的总数,S2表示复杂块的总数.对简单块,在矩阵中用0做标记,量化为1比特,像素平均值被量化为8 bit;复杂块左上角坐标dx和dy分别被量化为7 bit,其他参数与传统算法一致.

表2 使用两种算法的压缩比
5 总 结
本文提出了结合分类方法的并行分形编码算法.这种并行的分形图像压缩方法结合Wu YG[7]等提出的分类方法,充分利用GPU上的线程把分形编码中对匹配块的搜索并行化执行,使编码时间达到毫秒级.实验结果表明,与传统的分形图像压缩方法相比,本文算法在保持较好的解码图像质量的基础上可达到1 200多倍的加速,且压缩比更高.在今后的工作中,将进一步开发使用GPU去优化CPU代码缩短编码时间、提高解码图像质量,并把这些方法用于其他领域中,如动态图像的编码等.
[1] 刘小丹,牛少敏.一种改进的K-means聚类彩色图像分割方法[J].湘潭大学自然科学学报,2012, 34(2):90-93.
[2] 吴一全,孙子翼. 免疫粒子群核模糊聚类快速分形图像编码[J] .北京邮电大学学报,2011,34(1):69-74.
[3] GUO H,ZHENG Y P,HE J. A new HVS-based fractal image compression algorithm[J].Lecture Notes in Electrical Engineering,2012,138:753-759.
[4] 屠添翼,石跃祥.基于小波域的加权分形图像编码[J].湘潭大学自然科学学报,2004,26(2):25-28.
[5] YU H,LI L D,LIU H,et al.Based on quadtree fractal image compression improved algorithm for research[C]// E-Product E-Service and E-Entertainment,2010: 1-3.
[6] LIN Y L,WU M S.An edge property-based neighborhood region search strategy for fractal image compression[J]. Computers & Mathematics with Applications, 2011, 62 (1):310-318.
[7] WU Y G,HUANG M Z,WEN Y L.Fractal image compression with variance and mean[C]//Proc IEEE ICME. Maryland,2003: 353.
[8] 马巍巍,孙东,吴先良. 基于GPU的高阶辛FDTD算法的并行仿真研究[J]. 合肥工业大学学报:自然科学版,2012,35(7):926-929.
[9] MANDELBROT B B. The Fractal Geometry of Nature[M].2 ed.New York:Times Books,1982.
[10] BARNSLEY M,SLOAN A. A better way to compress images[M].BYTE, 1988.
[11] JACQUIN A E. Image coding based on a fractal theory of iterated contractive image transformations[J].IEEE Trans, Image Processing,1992,1(1):18-30.
责任编辑:龙顺潮
Research on Parallel Fractal-Image Coding Algorithm Combined with Classification Method
GUOHui1*,HEJie1,LUZhen-kun2
(1.School of Information and Electronic Engineering, Wuzhou University, Wuzhou 543002;2.College of Information Science and Engineering, Guangxi University for Nationlities,Nanning 530006 China)
Directed against the characteristic of computational intensity of fractal image encoding, a serial-parallel transfer mechanism is built for encoding procedures. By utilizing the properties of single instruction and multithreading execution of compute unified device architecture (CUDA), the parallel computational model of fractal encoding is built on the graphic processor unit(GPU) in order to parallelize the considerably time-consuming serial execution process of searching for the block of best match, on which base to classify the blocks of range in combination with the variance method in order to reduce the frequency of search. The experimental result indicates, the algorithm in this paper, as compared with the original algorithm, can achieve an acceleration of 1 200 and more times and keep the decoded image in good quality, which addresses the demand for real-time encoding.
fractal image compression; compute unified device architecture; parallel computing; classification; variance
2014-03-25
国家自然科学基金项目(61362038);广西自然科学基金青年项目(2013GXNSFBA019276,2013GXNSFBA019275,2014GXNSFBB118005);广西高校科研项目(2013YB227, 2013YB228)
郭慧(1981— ),女,广西 梧州人,副教授.E-mail:guohui928@qq.com
TP391
A
1000-5900(2015)01-0097-06
猜你喜欢
语数外学习·高中版上旬(2022年2期)2022-04-09
新世纪智能(数学备考)(2021年9期)2021-11-24
山西电子技术(2021年3期)2021-06-28
新世纪智能(数学备考)(2020年9期)2021-01-04
数理化解题研究(2020年19期)2020-07-22
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
读写算(2019年5期)2019-09-01
中学生数理化·高一版(2018年10期)2018-11-08
理科考试研究·高中(2017年10期)2018-03-07
