
面向大数据环境的决策信息需求通用描述语言*
2015-03-19 00:34宗士强闫晶晶李友江
计算机工程与科学 2015年8期
金 欣,宗士强,闫晶晶,王 珩,李友江
(1.信息系统工程重点实验室,江苏 南京210007;2.南京电子工程研究所,江苏 南京210007)
1 引言
大数据时代的到来引起了学术界、工业界乃至政府机构的广泛关注[1,2]。其重要特征之一是多样化(Variety)。而其带来的一大问题是异构性(Heterogeneity),令使用者难以采用统一的方法发现、获取和利用这些数据。这为人们从大数据中搜集有用信息和挖掘潜藏价值带来了极大挑战。
在公安、交通、银行、通信、军事等领域中,需要借助大量的数据分析来探寻新的增长点,包括实时/非实时、结构/非结构化、系统内部/互联网上的等等。然而,不同的信息来源有不同的信息组织方式,如关系数据库、网页、文档、格式化元数据和报文等,且在信息内容的表达上带有较强的领域特征,因此体现出较强的异构性。同时,这些异构信息之间在内容上又存在着很多交叉和重叠,例如某条路段的拥堵情况,既可以流量数据的形式存于数据库中,也可以自然语言描述的形式存于文本中,还可以实况记录的形式通过格式化报文发布,对于关注该路段拥堵情况的决策者而言,上述形式的信息都是需要获得的。
面对多样异构的信息来源,为了提高查找效率,用户不得不耗费大量时间在信息需求的表达上,包括仔细斟酌关键词以避免跨领域的歧义,判断目标信息的存储形式(文本、数据库、实时报文等)以选择相应的需求表达形式(搜索关键词、数据库查询语句、报文订阅请求)等。这些工作分散了决策者的精力,导致决策效率低下。如果有一种语言能够统一描述用户的信息需求,并能自动转换成各类信息资源理解的形式,将其反馈的结果汇总给决策用户,无疑将提升用户决策效率。
为此,综合常见信息需求表达形式的特点,设计了一种通用信息需求描述语言GIRL(General Information Requirement Language),能够支持结构化信息查询、结构/非结构化信息搜索、实时信息订阅等各类常见信息使用方式。同时,该语言支持“主体属性”的表达形式,提供了一种相比SPARQL语言较为宽松但适用范围更广的浅层语义描述能力,能够有效屏蔽跨领域的语义异构性。通过GIRL能够实现信息需求的统一规范描述,方便自动化生成,并可保证生成需求描述为各类信息资源正确解析,从而将大数据环境下符合用户需求的多样化信息全部搜集过来。
2 需求生成系统简介
需求生成系统的组成和工作原理如图1所示。决策用户在处理同一类事务时所需的信息类型是基本相同的,例如,银行网点选址需要当地的常住人口、企业商户分布、交通规划等方面的信息。可以将这种潜在的映射关系挖掘出来,变为规则存储在知识库中。在使用中根据实际处理的事务类型调取相应规则,结合实际的决策上下文要素,就可以生成实际的信息需求。当用户输入查询关键词时,也可以根据问题背景、用户身份等上下文信息自动添加一些限定。例如交通行业人员输入“林肯”时加上“汽车”,军事人员输入“林肯”时加上“航母”,外交人员输入“林肯”时加上“总统”等。
信息需求生成之后交由需求发布管理模块,描述为一种通用的语言形式并发布出去。为了解决跨领域的语义异构性问题,需要引入本体技术[3],通过定义领域本体或使用开放的公共本体,利用各种匹配映射技术实现异构数据间的语义映射。因此,需要设计这样一种通用的信息需求描述语言,支持基于本体的语义描述,并能被各类信息资源转换成各自支持的搜索/查询/订阅形式,从而使得一次提交的需求能够同时得到实时/非实时、结构化/非结构化信息源的响应。
3 相关研究
为了提供开放的数据共享,各个领域都在尝试设计通用的信息需求表达方式。
非结构化信息搜索方面,几乎所有搜索引擎都支持关键词组的输入形式。正是基于这一点,一些元搜索引擎能将用户的搜索请求转发给其它搜索引擎,并对它们的结果进行合并,从而提供一个统一的搜索入口[4,5]。
结构化信息查询方面,目前有通用的数据库查询语言SQL(Structured Query Language),但由于书写复杂,一般都为用户提供定制的查询界面。由于不同数据库在字段组成和结构模式的区别,没有通用的数据库查询入口。但是,已有相关研究利用本体技术实现异构数据库间的映射[3,6],并使用SPARQL(Simple Protocol And RDF Query Language)[7]实现基于本体的查询。SPARQL 语言在提供精确语义查询能力的同时,对信息本身的语义表达规范形式要求较为严格,而互联网上的大部分信息并不具备规范的语义表达形式,因此限制了其适用范围。
实时信息服务方面,通常允许用户以订阅请求的形式表达需求。有的支持按主题订阅,有的支持按内容订阅,有明确的报文和订阅格式,如实时气象数据、实时交通状况等。这种发布/订阅系统和数据库类似,也存在领域异构性问题,同样也有语义发布/订阅系统[8,9]的研究。
除了在非结构化信息搜索、结构化信息查询和实时信息订阅等各领域内部统一信息需求表达形式外,三种形式之间也存在着如何统一的问题。随着信息共享渠道的增多,在非结构化、结构化、实时信息之间,不可避免地存在各种各样的内容重叠、交叉,信息内容和表达形式之间的耦合性逐渐减弱。因此,信息表达形式的兼容性,是提高信息综合利用效率不可回避的问题。GIRL 就是针对此目标设计的,它能被解析转换成SPARQL、SQL、关键词组、订阅请求等常用语言格式,从而使得一种表达方式能够为多类信息资源解析,从而通过一次需求的提交就能够将符合需求的实时/非实时、结构/非结构化的信息全部搜集到。
4 GIRL语法规范
GIRL的语法规范如图2 所示,主要由SELECT、WHERE、WHEN 三个字段组成,接下来详细说明。
4.1 SELECT和WHERE
这两个字段沿袭于SQL的语法,但加入了“主体→属性”这样的语义描述。如图3所示,一个主体有多个属性,有的数值已知,有的未知,未知部分放在SELECT 之后,而已知部分则放在WHERE之后。即先通过WHERE 找到符合需求的主体,进而通过SELECT 找到符合需求的属性。属性又分数值属性和对象属性,前者的值为具体数值,后者则关联到另一个主体。通过对象属性可以构造出一条属性链,形如“主体→对象属性1→…→对象属性n→数值属性”,例如“SELECT 苏A12345→驾驶员→所属公交车队→队长→姓名”表示查询公交车“苏A12345”的驾驶员所属车队队长的姓名。

Figure 2 GIRL grammar图2 GIRL语法
关系数据库中虽未明确定义主体,但隐含主体的概念。一张表代表一类主体,一行代表一个主体,一列代表一个属性,外键代表对象属性,其它代表数值属性,如图4所示。基于内容的发布/订阅系统中定义了订阅条件(Request)和报文内容(Content)两组键值对,可以映射为一组关系模式,如图5所示。订阅条件对应已知属性,用于限定报文类型,报文内容对应未知属性,它们对应同一个主体,隐藏在报文主题中。因此,发布/订阅系统与数据库非常类似,只是报文内容是动态变化的,并且是整条发来的,不像数据库查询可以只返回某个字段的值。非结构化文本中通常没有定义主体和属性,它们隐含在文本中。例如“江苏省的省会是南京”隐含了“江苏省→省会=南京”这样一条属性关系。

Figure 3 Subjects and properties图3 主体与属性
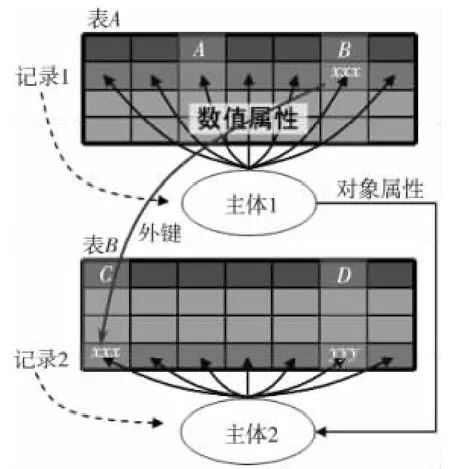
Figure 4 Subjects and properties in relational database图4 关系数据库中的主体和属性

Figure 5 Subjects and properties in publish/subscription system图5 发布/订阅系统中的主体和属性
SELECT 和WHERE项中的属性链可以有多条,相互逻辑关系用“&”、“||”表示,代表“与”、“或”。
4.2 WHEN
WHEN 字段描述的是用户对信息的时效性要求,可以分为持续型和一次型两类。
持续型需求指用户在一段时间内需要获得持续更新。START 和END 用于描述持续时间段,PERIOD 和REPEAT 用于描述实时信息的更新频率和非实时信息的查新周期。对于实时信息源,前三个字段对应于订阅请求中的起始时间、结束时间、发送间隔;对于非实时信息源,要求按照REPEAT 中设定的周期从START 到END 期间,定期提交重复的需求以实现增量搜索/查询。
一次型需求只有一次结果反馈过程。可以用LAST 字段描述信息的新旧程度要求,例如1个月内或1天内发布的信息,要求信息源支持按更新时间搜索/查询。
START、END、PERIOD、REPEAT、LAST 每个字段的值都可以缺省,但LAST 与其它四个字段不可以同时有值,因为一个需求不可能既是持续型的又是一次型的。
5 GIRL解析转换
5.1 基于本体的转换
(1)非结构化文本的语义搜索。
针对非结构化文本如网页,通常需要人为地或者借助一些工具[10]对文本进行语义标注,从而生成一段语义描述,而后就可以使用SPARQL 进行语义搜索,方法参见文献[11]。只要将GIRL 转换成SPARQL就可以实现对非结构化文本的语义搜索,规则如表1所示。

Table 1 Translation rules from GIRL to SPARQL表1 GIRL向SPARQL的转换规则
(2)关系数据库的语义查询。
使用SPARQL同样可以实现针对关系数据库的语义查询,方法分基于本体匹配和基于本体-关系模式映射两类。
基于本体匹配的方法如图6所示。①各个数据库根据自己的关系模式建立领域本体,方法参见文献[12];②与用户领域本体进行匹配建立映射关系,方法参见文献[13];③将收到的GIRL 格式的需求转换成SPARQL 格式,根据建立的映射关系通过查询重写机制转换成自己领域本体中的术语,再转变为适合其关系模式的SQL 语句,方法参见文献[14]。
基于本体-关系模式映射的方法如图7 所示。①维护一套公共本体,各个数据库在自己的关系模式和公共本体之间建立映射关系,方法参见[15];②用户端基于公共本体生成SPARQL 查询语句;③各数据库将GIRL格式的需求先转换成SPARQL格式,再通过查询重写机制转换成适合其关系模式的SQL语句,方法同上。

Figure 7 Ontology to relationship mode mapping based method图7 基于本体-关系模式映射的方法
第②种方法比第①种省掉了一步转换,但需要领域权威机构制定公共本体,并要求资源端和用户端都要遵照该标准,适用于军事、公安等领域;而第①种方法通过本体匹配维护不同领域本体间松耦合的映射关系,适用于开放领域。
(3)基于本体的语义订阅。
定义1(关系数据模式) 对于一个关系数据库D,其关系数据模式可以用一个二元组〈RD,ΣD〉表示,其中RD表示关系的集合。对于任意关系r∈RD由一组属性Ar=(a1:T1,a2:T2,…,an:Tn)组成,每个属性有特定的数据类型Ti。ΣD表示各关系及关系之间所要满足的完整性约束。
定义2(发布订阅模式) 对于一个发布订阅系统P,MP为其可订阅报文类型集合。每一个报文类型m∈MP的发布订阅模式可以用一个二元组〈Cm,Rm〉表示。其中Cm表示报文内容字段的集合,Rm表示订阅条件字段的集合。
首先,为发布/订阅系统P建立对应的数据库关系模式〈RD,ΣD〉:针对每一个m∈MP,依据〈Cm,Rm〉生成一个r∈RD,取报文类型的名称,且对任意c∈Cm,有c∈Ar,对任意r′∈Rm,有r′∈Ar。由于报文类型之间的关联关系在大多数发布/订阅系统中都没有明确定义,因此ΣD设置为空。
接着实现基于本体的语义订阅:①将GIRL 转换成针对RD的SQL语句,方法同上;②根据SQL语句生成报文类型筛选条件,如表2所示,其中表格名称X对应于报文类型名称,Do(X.Rm.B)表示字段B的值域;③根据SQL 语句生成针对该报文类型的订阅请求,如表3所示,其中X.Rm()是X类报文订阅请求的构造函数。

Table 2 Translation rules from SQL to subscription request表2 SQL向订阅请求的转换规则

Figure 6 Ontology match based method图6 基于本体匹配的方法

Table 3 Translation rules of GIRL without ontology support表3 GIRL无本体支持转换规则
5.2 无本体支持的转换
基于本体的方法能解决跨领域异构性问题,但需要信息资源端在现有基础上做一些工作,包括本体构建、关系模式映射等,有一定工作量,不一定能广为接受。因此,GIRL 还应当能够为那些不支持本体技术的普通信息资源解析转换,虽然会损失掉一部分语义,仍然能够获得它们的响应。表4中是GIRL在无本体支持的情况下向SQL、关键词组和订阅请求的转换规则。
6 方法验证
为了验证上述方法的可行性,开展了测试实验。作为实验环境,以某交通系统为例构建了一个标准数据集,包含20个数据库、10个发布/订阅系统以及两个内部搜索引擎。其中,针对五个数据库、四个发布/订阅系统建立了领域本体,同时建立了一个用户领域本体,共计定义概念84 个,关系28个,实例约2 000个,其中部分本体及相互映射关系如图8所示。两个搜索引擎中有一个支持语义搜索,同时还针对部分源文档建立了语义描述。
针对实验的开展,从交通领域中选取了50余种常见的决策信息需求,例如:某时段某路段的平均单向/双向车行流量、某片区内拥堵情况发生频率较高的路段和时段、某限行路段内交通事故的发生频率及常见事故类型和事故造成的死亡人数等,由于篇幅原因不一一列举。以“近30日内早高峰时段中山东路路段的平均单向/双向车行流量”为例,GIRL形式的需求描述如表4所示。

Table 4 Example of information requirement description表4 信息需求描述示例
在依据该需求搜集到的118 条结果中,有60条是来自于两个不同交通信息数据库的结构化数据,其中每条数据代表某日统计的平均车行流量;有48条是来自两个交通实况发布系统的交通实况通报报文;还有10条是通过两个搜索引擎获得的文本格式的路况报道。由此可证明,使用GIRL 语言统一描述的信息需求被提交后能够得到关系数据库、搜索引擎、实时信息发布系统三种类型信息来源的响应,将符合需求的结构化、非结构化、实时信息全部搜集到。

Figure 8 Part of mapping relationships among ontologies built from different relationship modes图8 依据不同关系模式建立的本体及其间的映射关系截取
为了验证准确性,选取了20个典型决策信息需求进行了两组实验,一组有本体支持,一组没有,针对每一组查询结果计算查全率和查准率。GIRL语法中虽然提供了“主体属性”的语义描述形式,但要保证被正确解析还需要本体的支持,因此以有无本体为开关,对比用和不用语义的区别。在表4对应的实验中,“平均单向车行流量”被映射成“平均单方向行驶流量”、“单向行车流量均值”等多种表达形式,分别对应不同数据库、发布系统中的表达形式。实验结果如图9所示,有本体支持的查全率和查准率都有不同程度的提高,表明基于本体的方法能够有效屏蔽多源信息的异构性,提升信息搜集的全面性和精准性。由于数据集规模较小,无法模拟真实的大数据环境,但数据集的异构特性是模仿大数据环境设计的,因此实验结果在一定程度上能够说明问题。
7 结束语
大数据时代的到来,使得决策信息的搜集更加困难。本文提出了一种通用信息需求描述语言,设计了其语法规范及其为常用信息资源解析转换的方法。其优点在于:面向大数据环境,用户无需确知其所需信息的来源和存储、组织形式,也无需考虑跨领域的语义异构性问题,而是采用一种通用的形式表达其信息需求,并统一搜集、汇聚符合需求的、多来源的、多样化信息,从而提高用户面向决策获取信息的效率。下一步将研究用户决策事务与所需信息类型之间的映射关系,以实现GIRL形式需求的自动生成。

Figure 9 Comparison of performance图9 性能对比
[1] Big data across the federal government[EB/OL].[2012-10-02]. http://www.unglobalpulse.org/projects/BigDataforDevelopment.
[2] Qian K,Cheng G.Application of cloud computing technology in information systems[J].Command Information System and Technology,2012,3(4):51-54.
[3] Rahm E,Bernstein P A.A survey of approaches to automatic schema matching [J].The International Journal on Very Large Databases,2001,10(4):334-350.
[4] Wrubel L,Schmidt K.Usability testing of a metasearch interface:A case study[J].College and Research Libraries,2007,68(4):292-311.
[5] Sadeh T.Transforming the metasearch concept into a friendly user experience[J].Internet Reference Services Quarterly,2007,12(1):1-25.
[6] Anhai D,Alon Y H.Semantic-integration research in the database community:A brief survey[J].AI Magazine,Special Issue on Semantic Integration,2005,26(1):83-94.
[7] Eric P,Andy S.Sparql query language for rdf w3crecommendation[EB/OL].[2008-10-23].http://www.w3.org/TR/rdf-sparql-query/.
[8] Buchmann A,Bornhovd C,Cilia M,et al.DREAM:Distributed reliable event-based application management[M]∥Levene M,Poulovassilis A,eds.Web Dynamics,Berlin:Springer-Verlag,2004:319-352.
[9] Wang Jin-ling.Research on key technologies in internet-scale publish/subscribe systems[D].Beijing:Institute of Software,the Chinese Academy of Sciences,2005.(in Chinese)
[10] Dill S,Eiron N,Gibson D,et al.SemTag and seeker:Bootstrapping the semantic web via automated semantic annotation[C]∥Proc of the 12th International Conference on World Wide Web,2003:178-186.
[11] Li Hui-ying,Qu Yu-zhong.Keyword-based search on semantic web data:The state of the art[J].Computer Science,2011,38(7):18-23.(in Chinese)
[12] Astrova I.Towards the semantic web-An approach to reverse engineering of relational databases to ontologies[C]∥Proc of the 9th East-European Conference on Advances in Databases and Information Systems,2005:111-122.
[13] Hu W,Qu Y,Cheng G.Matching large ontologies:A divideand-conquer approach [J].Data & Knowledge Engineering,2008,67(1):140-160.
[14] Enrico F,Volha K,Nhung N.Exact query reformulation with first-order ontologies and databases[C]∥Proc of JELIA’12,2012:202-214.
[15] Hu W,Qu Y.Discovering simple mappings between relational database schemas and ontologies[C]∥Proc of the 6th International Semantic Web Conference and the 2nd Asian Semantic Web Conference,2007:225-238.
附中文参考文献:
[9] 汪锦岭.面向Internet的发布/订阅系统的关键技术研究[D].北京:中国科学院软件研究所,2005.
[11] 李慧颖,瞿裕忠.基于关键词的语义网数据查询研究综述[J].计算机科学,2011,38(7):18-23.
猜你喜欢
汽车电器(2022年9期)2022-11-07
小学教学研究(2022年5期)2022-04-28
河北理科教学研究(2021年4期)2021-04-19
铁道通信信号(2020年4期)2020-09-21
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
中国外汇(2019年11期)2019-08-27
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
铁道通信信号(2016年8期)2016-06-01
