
基于多特征的关键词抽取算法
2015-03-07 09:24郭建波
合肥工业大学学报(自然科学版) 2015年9期
郭建波, 谢 飞,2
(1.合肥工业大学 计算机与信息学院,安徽 合肥 230009;2.合肥师范学院 计算机学院,安徽 合肥 230061)
0 引 言
人们在生活中越来越多地使用互联网,导致信息来源多样化。面对各种信息来源,在网络和现实生活中快速有效地获得需要的信息也变得更加困难。因此,关键信息的获取变得非常重要,文档的关键词抽取技术也应运而生。所谓文档关键词是可以概括文档主题的1个或多个词语。关键词在多个领域都扮演着非常重要的作用,如信息检索、信息聚类[1]和搜索引擎[2-3]等,关键词的应用可以极大地提高信息检索和搜索引擎等技术的效率。
本文提出的关键词抽取算法是针对英文期刊、会议论文集中的文献。已有的相关算法中,一部分可以归结为有监督的机器学习算法,基本思想是通过训练带有关键词的训练文档,构造分类器,再把该分类器应用于测试集来提取测试文档中的关键词。典型的如Extractor算法[1]和KEA算法4,而这2个系统的不足之处在于需要训练文档,因此需要花费大量的时间用于构造分类器。另一部分可以归结为无监督的机器学习算法,如典型的KP-Miner算法[5],该算法的不足之处在于只应用了文档中候选词丰富的统计信息,而没有应用文档中比较关键的候选词的语义信息。
本文算法属于无监督的机器学习算法,无需训练文档,直接提取单个文档中的关键词。通过定义更多的候选词特征来选择候选词。同时,权重计算时,用更高效候选词属性来计算权重,使得算法的抽取结果和效率都得到很大的提高。
1 相关工作
关键词抽取算法可以分为有监督的算法和无监督的算法。有监督的算法一般把关键词抽取算法看作分类问题,首先通过训练带有关键词的训练集构造分类器,再把分类器应用于测试集,通过分类测试集文档中的词是否为关键词来选择最终的关键词;无监督算法则直接根据对候选词权重的计算给候选词打分来确定最终的关键词。
有监督的算法中,Extractor算法[1]首先扫描文档,去除文档中的停止词和标点符号,得到ngrams,同时删除长度大于3的n-grams,余下的n-grams为候选词。根据候选词的长度和首次出现位置分别计算训练文档和测试文档中的候选词的权重。再利用已确定关键词的训练文档,构造C4.5分类器,把分类器应用到测试文档中,从测试文档的候选词中选出关键词。KEA算法[4]扫描文档,去除标点符号,得到n-grams,删除首尾有停止词的n-grams。与 Extractor[1]不同,KEA算法[4]不认为停止词是分隔符,停止词可以出现在n-grams的中间位置。特征选择时,算法选择词频-逆向文档频率(term-frequent-inverse document frequency,TFIDF)和首次出现位置。另一方面,KEA算法[4]构造朴素贝叶斯分类器。
文献[6]提出了构造支持向量机(support vector machine,SVM)模型抽取关键词。文献[7]在抽取关键词时利用boosting and bagging策略。无监督的算法中,典型的 KP-Miner算法[5]在文档中提取n-grams,同样认为停止词不是分隔符,同时该算法删除出现次数小于3次,或者首次出现位置大于400的n-grams。在计算候选词权重时,KP-miner算法提出了在计算词的IDF值时,复合词在文档集中的出现频率比单个词出现的频率小,所以算法对TFIDF计算做了改进,同时计算权重时考虑了首次出现位置;算法最后对提取的关键词做了优化,删除关键词集合中其他关键词子串的关键词,并认为这些关键词是冗余的。
另外,对于无监督的学习算法,文献[8]提出了构建文档语义网络结构来提取关键词;文献[9]提出在提取单个文档关键词时利用和文档距离较近(相似)的文档;文献[10]提出基于语义联系的新闻网页关键词抽取算法,利用《知网》中的词语计算语义相似度;文献[11]提出利用《同义词词林》语义词典和统计信息得到语义扩展度,再结合词汇链等方法计算候选词权重,最终排序得到最终关键词;文献[12]构建词语语义相似度网络并利用居间度密度度量词语语义关键度,以此来度量关键词的权重来获取关键词;文献[13]提出基于图论中心性的概念度量权重提取关键词。
人们不仅在学术文章中提取关键词,在新闻网页和微博博文中也提取关键词。文献[14]利用社会化标签来提高抽取网页关键词的质量;文献[15]首先根据推特中推特内容构建推特的图结构,再根据图中的中心度抽取推文中的关键词;文献[16]提出利用参考文献信息提取关键词;文献[17]提出基于神经网络的中文关键词抽取算法。
2 基于多特征抽取算法
通过对已有算法的分析,本文摒弃了已有算法中的不足之处,设计了一种基于多特征的关键词抽取算法。算法总体上分为候选词选择、候选词权重计算和最终关键词确定3个步骤。
2.1 算法框图
本文算法的整体流程如图1所示。

图1 基于多特征的关键词抽取
2.2 候选词的选择
首先扫描文档,根据特定的截断符号(句号、问号、逗号、数字等)把文档分为若干子句,然后根据指定的n,扫描子句得到n-grams(例如,子句w0w1w2w3w4的 3-grams 有 3 个w0w1w2,w1w2w3,w2w3w4,其中wj表示1个单词),由于包含多个单词的关键词数量很少,因此对n也有限 制,本 文 只 扫 描 得 到 1-gram、2-grams、3-grams。尽管这样,仍然会产生数量非常多的ngrams,所以需要删除一部分不适合作为候选词的n-grams,剩余的n-grams即为候选词。
首先,删除开始或结束位置含有停止词的ngrams。停止词为冠词(a,the)、介词(in,on)、副词(now,here)、连词(and,but)等没有实际意义的词,因此删除这些短语;其次借鉴KP-Miner算法[3],认为越重要的词在文章中出现的次数越多,且越靠前,因此去除出现次数小于3或首次出现在文档中400个单词之后的n-grams。
本文认为关键词大多表现为名词短语。文献[18-19]提出选择名词短语为候选词,选择名词短语为候选词比简单地考虑短语的统计特征为候选词的效果要好。由于本文是提取论文中的关键词,名词短语能够更好地表明文章的主题,而形容词短语等可以更好地表达情感,对于文章主题没有加成作用。因此,本文在选择候选词时同样选择名词短语作为候选词。实验中选择Stanford分词工具[20]对文章中的单词作词性标注,从而选出其中的名词短语。
2.3 候选词的权重计算
权重计算阶段是选取特定的特征计算候选词的权重。这一步是关键词抽取算法中最重要的一步,很多算法都是通过添加更多特征或改进一些特征来提取更优的关键词。其中最重要的特征是候选词的TFIDF值和首次出现位置。
(1)在计算权重时考虑到首次出现位置。因为一般出现在文档前面的词语比较重要,对于科学类文档来说,摘要和引言部分都在文章靠前的位置,而这两部分中的内容,基本上可以概括文章的主题,因此越靠前的词,重要性一般越高,权重也应该越大。首次出现位置值计算公式为:

其中,position(P,D)为候选词P在文档D中的首次出现位置,即出现在第多少个单词的位置;size(D)为文档D中的单词总数。
在别的大城市里没有这种情形,而在我家乡里往往是这样,坐了马车,虽然是付过了钱,让他自由去兜揽生意,但是他常常还仍旧等候在铺子的门外,等一出来,他仍旧请你坐他的车。
(2)在计算候选词权重时加入出现频率(TF)。候选词在文档中的出现频率是候选词最重要的统计特征,文档中反复出现的词或者短语成为关键词的概率非常大。TF的计算公式为:
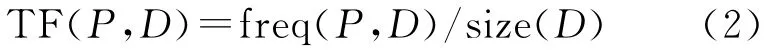
其中,freq(P,D)为文档D中候选词P的出现次数;size(D)为文档D中的单词总数。
(3)长度越长的候选词的重要性可能更高。因为短语的长度越长,其表达的意思一般更加精确,如“keyphrase extraction algorithm”比“keyphrase extraction”可能更适合作为该篇文章的关键词。因此,在计算候选词权重时,对不同长度的候选词赋予不同的权重Wl,其计算公式为:

2.4 最终关键词的选择
根据候选词的以上3个特征的权重计算公式可计算候选词的最终权重,计算公式为:

其中,W(P,D)为文档D中候选词P的最终权重。计算得到每个候选词的最终权重后,排序候选词的最终权重,排名靠前的K个候选词即为最终提取的Top-K个关键词。由于本文算法已经对候选词的长度作了限制,因此,在最终的关键词中,存在包含关系的关键词的数量会非常少。最终的关键词选择阶段,不对提取的最终关键词作优化。
由于本文算法只需要扫描1遍文档即可得到候选词,而在候选词权重计算和关键词确定部分都不需要扫描文档,因此,该算法的时间复杂度为O(n),其中n为文档中的单词数。
3 实 验
3.1 数据集
本文采用2010年举办的关键词抽取比赛(SemEval-2010)中的数据集,其中包括训练集144篇英文文章和测试集100篇英文文章。数据集的特征见表1所列。

表1 数据集的特征
3.2 实验结果与比较
3.2.1 提取关键词的效果
在SemEval-2010数据集中,训练集和测试集中的每篇文档均指定了关键词。在训练集和测试集中都做了实验,并与作者指定的关键词做比较,分别对准确率(P)、召回率(R)和F1值进行比较。其中P、R、F1值的计算公式分别为:

提取训练集144篇、测试集100篇文档中关键词的算法比较见表2所列。的学习算法效率更高,可以验证在计算候选词权重时,舍去IDF带来的时间效率的提高,并没有降低抽取效果。
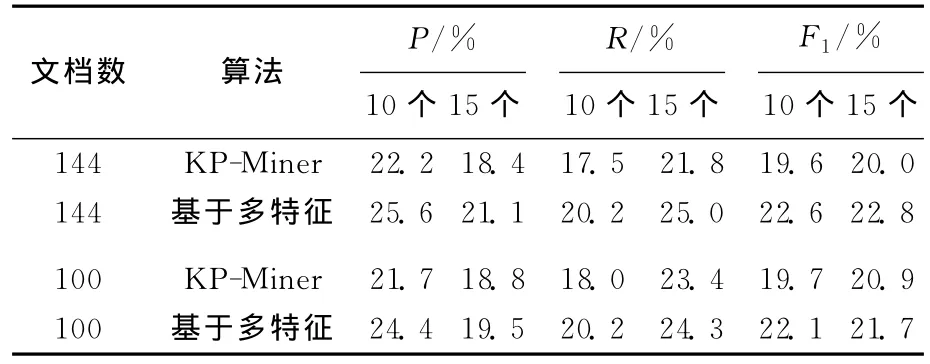
表2 提取不同篇数文档中关键词的效果
3.2.3 参数调节
针对候选词长度不同赋予不同的权重参数做一组实验来说明参数选择的正确性。实验中选择长度为1的候选词的权重范围为[0.1,1.0],长度为2的候选词权重范围为[1.1,2.0],长度为3的候选词权重范围为[2.1,3.0],间隔都为0.1。对于不同长度的各个权重,在SemEval-2010的训练数据集上做了1 000组实验,最终选择候选词权重计算部分的长度权重。不同长度的权重确定后,本文固定其中2个长度的权重,测试另一长度的权重变化对实验结果的影响,实验选择训练集文档,每篇文档抽取15个关键词,实验结果如图2所示。
从表2可以看出,本文算法在提取关键词时,明显比KP-Miner算法要好,在候选词选择时综合考虑不同的特征对候选词的选择进行优化,同时,在候选词权重计算时对不同长度的候选词赋予不同的权重,从而限定是有效的。
3.2.2 时间效率的比较
由于在计算TFIDF值的IDF值部分时需要多遍扫描文档,需要耗费大量时间。为了验证本文算法中没有计算IDF值是否带来时间效率的提高,本文做了如下对比实验,在SemEval-2010训练数据集上对本文算法和KP-Miner算法进行比较,可得抽取所有文档关键词的总时间,见表3所列。

表3 不同算法的时间效率比较
从表3可以看出,本文算法比典型的无监督
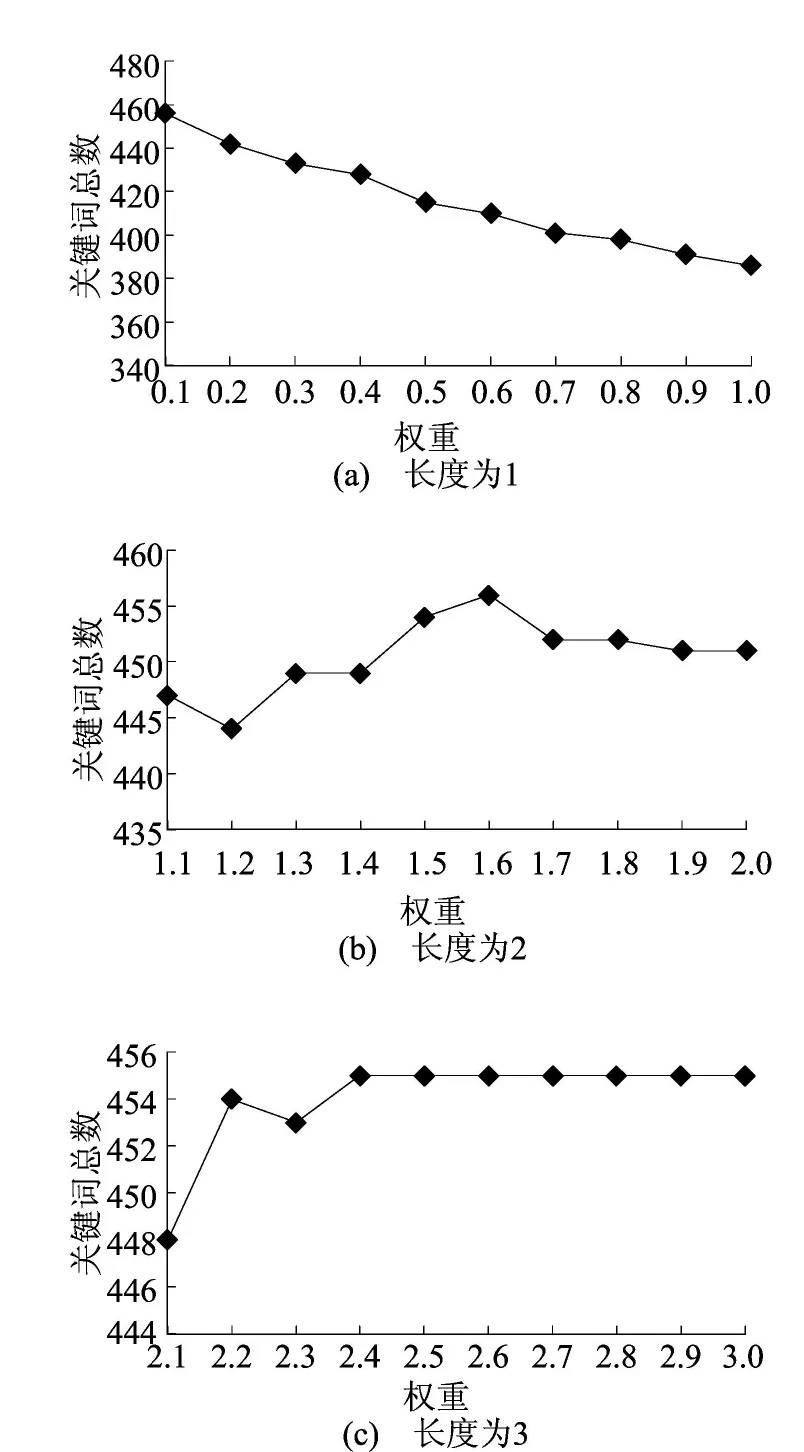
图2 不同长度候选词的权重变化
由图2可以看出,候选词长度的限定对最终关键词选择的影响很大,对于长度为1的候选词,如果赋予更高的权重,算法的提取效果明显降低。因此,本文直接对同长度的候选词给定不同的权重是有效的。
4 结束语
本文提出了一种基于多特征的无监督关键词抽取算法,结合候选词的统计特征对其进行评估,根据最终候选词得分确定关键词。实验表明,在提取关键词时,优于现有的无监督的抽取算法,同时在抽取效率上,该算法也优于其他算法。但是在算法中仅用到很少的词性信息,所以更多地利用词性特征将是进一步研究的重点。另外,门户网站的大量涌现,使得在网络中浏览新闻变得非常普遍,因此,下一步将研究抽取新闻网页中新闻关键词的抽取算法。
[1] Turney P D.Learning algorithms for keyphrase extraction[J].Information Retrieval,2000,2(4):303-336.
[2] Gutwin C,Paynter G,Witten I H,et al.Improving browsing in digital libraries with keyphrase indexes[J].Decision Support Systems,1999,27(1):81-104.
[3] Gong Zhiguo,Liu Qian.Improving keyword based web image search with visual feature distribution and term expansion[J].Knowledge and Information Systems,2009,21(1):113-132.
[4] Witten I H,Paynter G W,Frank E,et al.KEA:practical automatic keyphrase extraction [C]//Proceedings of the Fourth ACM Conference on Digital Libraries.ACM,1999:254-255.
[5] El-Beltagy S R,Rafea A.KP-Miner:a keyphrase extraction system for English and Arabic documents[J].Information Systems,2009,34(1):132-144.
[6] Zhang Kuo,Xu Hui,Tang Jie,et al.Keyword extraction using support vector machine[M]//Advances in Web-Age Information Management.Berlin:Springer,2006:85-96.
[7] Lopez P,Romary L.HUMB:automatic key term extraction from scientific articles in GROBID[C]//The 5th International Workshop on Semantic Evaluation Association for Computational Linguistics,2010:248-251.
[8] Wan Xiaojun,Xiao Jianguo.Single document keyphrase extraction using neighborhood knowledge[C]//Proceedings of the 23nd AAAI Conference on Artificial Intelligence,2008:855-860.
[9] 谢 飞,吴信东,胡学钢,等.基于语义联系的新闻网页关键词抽取[J].广西师范大学学报:自然科学版,2009,27(1):145-148.
[10] Huang Chong,Tian Yonghong,Zhou Zhi,et al.Keyphrase extraction using semantic networks structure analysis[C]//Data Mining,2006,ICDM’06,Sixth International Conference on.IEEE,2006:275-284.
[11] 刘瑞阳,王良芳.结合语义扩展度和词汇链的关键词提取算法[J].计算机科学,2013,40(12):264-291.
[12] 王丽霞,淮晓永.基于语义的中文文本关键词提取算法[J].计算机工程,2012,38(1):1-4.
[13] Lahiri S,Choudhury S R,Caragea C.Keyword and keyphrase extraction using centrality measures on collocation networks[EB/OL].[2014-01-25].http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.433.3540&req=rep1&type=pdf.
[14] 李 鹏,王 斌,石志伟,等.Tag-TextRank:一种基于 Tag的网页关键词抽取方法[J].计算机研究与发展.2012,49(11):2344-2351.
[15] Lu Y,Li R,Wen K,et al.Automatic keyword extraction for scientific literatures using references[C]//Innovative Design and Manufacturing (ICIDM),Proceedings of the 2014International Conference on.IEEE,2014:78-81.
[16] Abilhoa W D,de Castro L N.A keyword extraction method from twitter messages represented as graphs[J].Applied Mathematics and Computation,2014,240:308-325.
[17] 白晓雷,黄广君,段建辉.一种基于BP神经网络的关键词抽取方法[J].合肥工业大学学报:自然科学版,2014,37(7):808-811,896.
[18] Hulth A.Improved automatic keyword extraction given more linguistic knowledge[C]//Proceedings of the 2003 Conference on Empirical Methods in Natural Language Processing Association for Computational Linguistics,2003:216-223.
[19] Hulth A,Megyesi B B.A study on automatically extracted keywords in text categorization[C]//The 21st International Conference on Computational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics.Association for Computational Linguistics,2006:537-544.
[20] Starford NLP Group.Stanford分词工具[EB/OL].[2014-09-08].http://nlp.stanford.edu/software/tagger.shtml.
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
计算机应用(2017年4期)2017-06-27
信息安全研究(2016年4期)2016-12-01
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
海峡姐妹(2016年2期)2016-02-27
中原工学院学报(2014年4期)2014-04-01
